تم إطلاق Claude Opus 4.7 في 16 أبريل 2026، وخلال يومين فقط، تحولت آراء المجتمع حوله من "ترقية شاملة" إلى "ترقية انتقائية". المشكلة لا تكمن في نتائج الاختبارات الرسمية، بل في حقيقة تم التحقق منها مراراً: Opus 4.7 هو ترقية مخصصة فقط لـ "وكلاء كتابة الأكواد" (Code Agents)، وهو بمثابة تراجع في الأداء لجميع السيناريوهات الأخرى.
هذا المقال يضع النقاط على الحروف ويجيب مباشرة على السبب الحقيقي وراء عدم كفاءة Claude Opus 4.7: لماذا نرى شريط استهلاك رصيد Max Plan 20x ينخفض بسرعة أكبر من ذي قبل؟ ولماذا أصبح أداء RAG للمستندات الطويلة أسوأ مقارنة بـ 4.6؟ ولماذا تعطي الموجهات (Prompts) القديمة نتائج أقل جودة عند استخدامها مع هذا الإصدار؟
القيمة الجوهرية: بعد قراءة هذا المقال، ستعرف بوضوح متى يجب عليك الانتقال فوراً إلى 4.7، ومتى يجب عليك البقاء مع 4.6، وكيف يمكنك استعادة التوازن بين التكلفة والجودة من خلال ثلاثة إجراءات ضبط بسيطة.

الأسباب الجوهرية لعدم كفاءة Claude Opus 4.7
لفهم شعور "عدم الكفاءة" هذا، نحتاج أولاً إلى التمييز بين أمرين: تغير قدرة النموذج وتغير الفوترة/الرصيد. لقد أجرى Opus 4.7 تعديلات في كلا البعدين، وهذه التعديلات كانت مفيدة لنطاق ضيق فقط؛ فالمستخدمون الذين يعتمدون حقاً على قدرات "الوكلاء" (Agents) هم فقط من حصلوا على فائدة إيجابية، بينما تحمل معظم المستخدمين العاديين تكاليف إضافية.
الفئات المستفيدة فعلياً من ترقية Opus 4.7
ذكرت Anthropic في مدونتها الرسمية بوضوح أن Opus 4.7 صُمم للسيناريوهات التي كانت تتطلب "مساعدة يدوية" (hand-holding) في الإصدار 4.6: مثل سير عمل البرمجة الوكيلة طويلة الأمد، والمهام الإنتاجية للمكتبات البرمجية الضخمة متعددة الملفات، واستخدام الحاسوب (computer use)، وغيرها.
| الفئة المستفيدة فعلياً | مدى ترقية Opus 4.7 | السيناريو النموذجي |
|---|---|---|
| مطوروا Claude Code | ⭐⭐⭐⭐⭐ | إعادة هيكلة ملفات متعددة، حلقات الوكلاء |
| مستخدمو Cursor | ⭐⭐⭐⭐⭐ | مهام البرمجة الحقيقية داخل بيئة التطوير |
| تطوير سلاسل أدوات الوكلاء | ⭐⭐⭐⭐ | MCP-Atlas يتفوق على جميع النماذج |
| معالجة المستندات المرئية | ⭐⭐⭐⭐ | تحليل بدقة عالية 3.75 MP |
| الكتابة/صناعة المحتوى | ⭐ | ترقية غير محسوسة تقريباً |
| RAG للمستندات الطويلة | تراجع | MRCR 78.3% ← 32.2% |
| البحث عبر الويب/BrowseComp | تراجع | 83.7% ← 79.3% |
| الأمن السيبراني | تراجع | CyberGym 73.8% ← 73.1% |
| الإنتاجية الحساسة للتكلفة | تراجع | تضخم الـ Tokenizer بنسبة 0-35% |
🎯 نصيحة الانتقال: إذا كنت لا تنتمي للفئات الأربع الأولى، ولكن عملك يتطلب استدعاء 4.6 و 4.7 في آن واحد، يُنصح باستخدام منصة APIYI (apiyi.com) لتوجيه الطلبات حسب السيناريو. تدعم هذه المنصة واجهة موحدة لاستدعاء سلسلة نماذج Claude بالكامل، مما يجنبك تراجع الأداء الناتج عن الانتقال "الشامل" غير المدروس.
الأسباب الثلاثة الرئيسية لعدم كفاءة Claude Opus 4.7
السبب 1: إعادة هيكلة الـ Tokenizer أدت إلى تضخم استهلاك الـ Token
يستخدم Opus 4.7 مُجزئ نصوص (Tokenizer) جديداً تماماً. نفس النص المدخل، سيتم تقسيمه في 4.7 إلى ما يعادل 1.0 إلى 1.35 ضعف من الـ Token. يختلف هذا المعدل بشكل ملحوظ حسب نوع المحتوى:
- المحادثات باللغة الإنجليزية البحتة: تقترب من 1.0×
- المحتوى باللغة العربية: 1.1–1.2×
- مقتطفات الأكواد: 1.15–1.25×
- بيانات JSON/هيكلية: 1.2–1.35×
- سيناريوهات اللغات المختلطة: 1.25–1.35×
السبب 2: تفعيل مستوى الاستدلال xhigh افتراضياً في Claude Code
مع إطلاق 4.7، قامت Claude Code برفع مستوى الاستدلال الافتراضي لجميع الباقات من high إلى xhigh. يقع مستوى xhigh بين high و max، ويستهلك "رموز تفكير" (thinking tokens) أكثر في نفس المهام، ويتم احتساب هذا الاستهلاك مباشرة ضمن فاتورتك.
السبب 3: رصيد Max Plan 20x يُحسب بناءً على الـ Token
على الرغم من أن باقة Max Plan 20x تُسمى اسمياً "20 ضعف رصيد Pro"، إلا أن جوهر الحد الأقصى هو الـ Token وليس عدد الطلبات. عندما يحدث تضخم الـ Tokenizer مع تفعيل xhigh افتراضياً في آن واحد، فإن العمليات نفسها ستستهلك رصيدك بشكل أسرع. أفاد العديد من المستخدمين: عند استخدام Opus 4.7 في 17 أبريل، كان شريط رصيد Max Plan ينخفض بشكل أسرع بكثير مما كان عليه عند استخدام 4.6 في 15 أبريل.
نظرة شاملة على أداء Claude Opus 4.7 في سيناريوهات الاستخدام
للحكم على ما إذا كان تحديث Opus 4.7 يمثل ترقية أو تراجعاً بالنسبة لسيناريوهات عملك، لا ينبغي الاعتماد فقط على المقاييس المعيارية التي تختارها الشركة. يقيّم هذا القسم الأداء عبر 7 سيناريوهات استخدام واقعية.

السيناريو 1: وكيل الترميز (ترقية ملحوظة)
هذا هو الملعب الأساسي لـ Opus 4.7. وقد أكدت عدة بيانات هذه الحقيقة:
| معيار الترميز | Opus 4.6 | Opus 4.7 | GPT-5.4 xhigh | تحسن Opus 4.7 |
|---|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | غير معلن | +6.8 نقطة |
| SWE-bench Pro | 53.4% | 64.3% | 57.7% | +10.9 نقطة |
| CursorBench | 58% | 70% | غير معلن | +12 نقطة |
| MCP-Atlas | 75.8% | 77.3% | 68.1% | +1.5 نقطة |
| OSWorld-Verified | 72.7% | 78.0% | 75.0% | +5.3 نقطة |
حقق Opus 4.7 الفوز في 6 مواجهات مقابل تعادل واحد وخسارتين أمام GPT-5.4 في 9 معايير للمقارنة المباشرة، مستعيداً بذلك لقب الأفضل في مجال البرمجة الوكيلية (Agentic Coding) من GPT-5.4 لأول مرة.
🚀 نصيحة لسيناريو الوكلاء: إذا كنت تقوم ببناء وكلاء بمستوى الإنتاج، ننصحك باستدعاء Claude Opus 4.7 مباشرة عبر منصة APIYI (apiyi.com). توفر المنصة واجهة متوافقة تماماً مع Claude الرسمي، وتدعم ميزات جديدة مثل فئة xhigh وميزانيات المهام (Task Budgets).
السيناريو 2: الرؤية الحاسوبية Vision (ترقية نوعية)
تعد الرؤية (Vision) سيناريو آخر شهد ترقية حقيقية:
- أقصى دقة للصور: 1.15 ميجابكسل ← 3.75 ميجابكسل (بزيادة 3 أضعاف)
- بكسلات الجانب الأطول: من التوسعة المعتادة إلى 2576 بكسل
- معيار التعرف البصري: 54.5% ← 98.5%
بالنسبة للسيناريوهات التي تتطلب قراءة مباشرة للمخططات المعمارية، مسودات التصميم، مستندات PDF الممسوحة ضوئياً، أو لقطات واجهة المستخدم، فهذه قفزة نوعية ملموسة.
السيناريو 3: استرجاع سياق المستندات الطويلة RAG (تراجع حاد)
هذا هو موضع الشكوى الأكثر شيوعاً في المجتمع. معيار MRCR (استرجاع السياق متعدد الجولات) هو المعيار القياسي لقياس قدرة استرجاع السياق الطويل:
- Opus 4.6: 78.3%
- Opus 4.7: 32.2%
- الفارق: -46.1 نقطة
هذا الرقم يفسر سبب تقارير المطورين: "عندما أُغذي 4.7 بوثيقة سير عمل من 800 سطر، يدعي أنه قرأها، لكن المحتوى الذي يولده ليس له أي علاقة بالوثيقة".
إذا كان عملك الأساسي يعتمد على الإجابة عن الأسئلة من مستندات طويلة، أو تحليل العقود، أو فحص قواعد الأكواد الضخمة، فإن Opus 4.7 يمثل تراجعاً واضحاً، لذا ننصح بالبقاء على نسخة 4.6.
السيناريو 4: البحث عبر الويب و BrowseComp (تراجع طفيف)
يقيس BrowseComp أداء مهام البحث عبر الويب:
- Opus 4.6: 83.7%
- Opus 4.7: 79.3%
- GPT-5.4 Pro: 89.3%
في سيناريوهات "وكلاء البحث" (Research Agent) التي تتطلب تصفحاً عميقاً للويب وتوليف المعلومات، يظل GPT-5.4 Pro هو الخيار الأقوى، في حين أن Opus 4.7 لا يضاهي حتى أداء 4.6.
السيناريو 5: الكتابة العادية والمحادثة (تغيير غير ملحوظ تقريباً)
بالنسبة للكتابة اليومية، توليد النصوص، ومهام المحادثة، فإن الفروقات الذاتية بين Opus 4.7 و 4.6 محدودة جداً. ولكن نظراً لتضخم "المجزئ" (Tokenizer)، فإن استهلاكك الفعلي للـ Token في كل محادثة سيكون أعلى بنسبة 10-20% مقارنة بـ 4.6.
الخلاصة: استخدام 4.6 في سيناريوهات الكتابة أكثر توفيراً، حيث أن ترقية القدرات في 4.7 غير محسوسة هنا.
السيناريو 6: توافق الموجهات (Prompt) القديمة (تراجع محتمل)
أصبح اتباع التعليمات في Opus 4.7 أكثر "حرفية" – فهو لم يعد يقرأ "ما بين السطور" بذكاء كما في 4.6. هذا يعني:
- الموجهات (Prompts) التي تعتمد على النوايا الضمنية ستخرج بجودة منخفضة.
- عند استخدام توجيهات غامضة مثل "ساعدني في تحسين هذا"، يميل 4.7 للتنفيذ الحرفي الصارم.
- تحتاج إلى إعادة صياغة القيود الضمنية إلى قيود صريحة (مثل: "قيد عدد الكلمات بـ 500 كلمة"، "يجب أن يتضمن العنصر X").
إذا كان لديك مكتبة ضخمة من الموجهات من عصر 4.6، فستحتاج إلى اختبارات تراجع منهجية قبل الانتقال.
السيناريو 7: الأمن السيبراني (تراجع طفيف)
CyberGym (معيار محاكاة الثغرات الأمنية السيبرانية):
- Opus 4.6: 73.8%
- Opus 4.7: 73.1%
أقرت Anthropic رسمياً بأن هذا هو الثمن المدفوع مقابل آليات الحماية السيبرانية المضافة. بالنسبة للفرق التي تعمل في أبحاث الفريق الأحمر (Red Teaming) والتدقيق الأمني، يمثل هذا تراجعاً طفيفاً ولكنه حقيقي.
💡 نصيحة لاختيار السيناريو: يعتمد اختيار Opus 4.7 أو 4.6 بشكل أساسي على سيناريو تطبيقك المحدد ومتطلبات الجودة. ننصحك بإجراء اختبار مقارنة فعلي عبر منصة APIYI (apiyi.com)، حيث تدعم المنصة واجهات موحدة لمجموعة متنوعة من النماذج الرائدة، مما يسهل التبديل والتحقق بسرعة.
تحليل استهلاك رصيد Claude Opus 4.7 Max Plan
هذا القسم مخصص للإجابة على سؤال: "لماذا ينفد رصيد الاستخدام بسرعة أكبر؟"
آلية استهلاك رصيد Max Plan 20x
يعتمد نموذج Claude Max Plan 20x في جوهره على قياس عدد الـ Token، وهناك نوعان من القيود الأساسية:
- حد نافذة السياق (5 ساعات): لمنع الاستدعاءات المكثفة في وقت قصير.
- الحد الأقصى للرسائل الأسبوعية: لحماية الاستخدام العام.
بعد إطلاق Opus 4.7، لم تتغير القيم المطلقة لهذه الحدود، ولكن بسبب الـ Tokenizer وإعدادات xhigh الافتراضية، ارتفع متوسط استهلاك الـ Token لكل رسالة بشكل ملحوظ.
مصادر تضخم استهلاك الـ Token
| مصدر التضخم | نطاق التأثير | نسبة التضخم التقديرية |
|---|---|---|
| مُحلل الرموز (Tokenizer) الجديد | جميع المدخلات | 0% – 35% (يعتمد على نوع المحتوى) |
| إعداد xhigh الافتراضي | مخرجات مهام الاستنتاج | 20% – 60% (مقارنة بـ high) |
| حل المشكلات الأكثر صرامة | حلقات الوكيل (Agent) | 10% – 30% (زيادة في عدد الخطوات) |
النتيجة الملموسة بعد دمج العوامل الثلاثة: عند إنجاز نفس المهمة على Claude Code، يستهلك إصدار 4.7 رصيداً أكثر بنسبة تتراوح بين 30% إلى 80% مقارنة بـ 4.6. هذا هو التفسير الرياضي لسبب شعورك بأن "شريط الرصيد ينفد بسرعة".
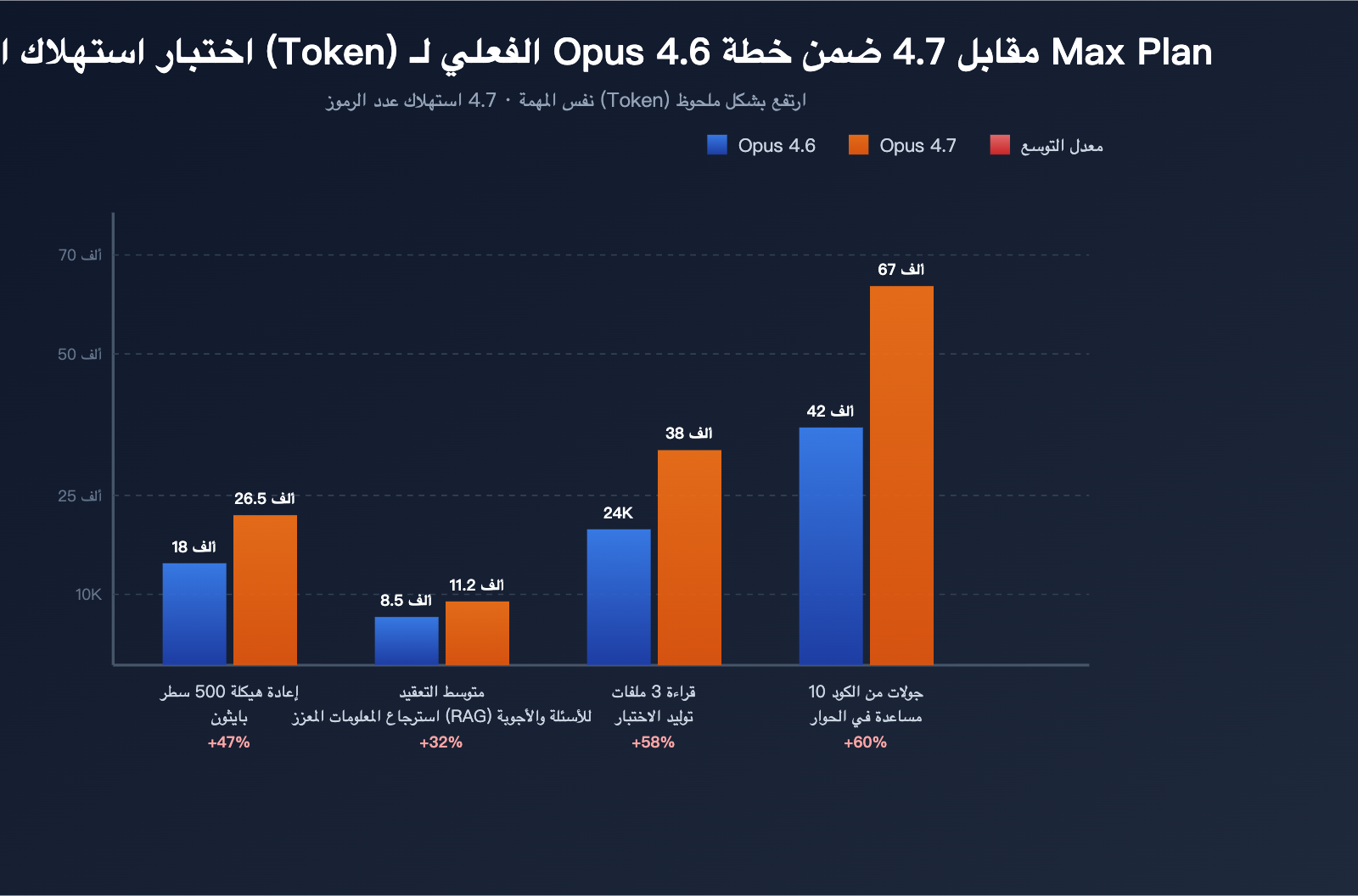
بيانات الاختبار الفعلي (3 مهام نموذجية)
استناداً إلى ملاحظات المجتمع:
| مهمة الاختبار | استهلاك 4.6 (Token) | استهلاك 4.7 (Token) | معدل التضخم |
|---|---|---|---|
| إعادة هيكلة وحدة Python من 500 سطر | ~18,000 | ~26,500 | +47% |
| الإجابة على سؤال RAG متوسط التعقيد | ~8,500 | ~11,200 | +32% |
| قراءة 3 ملفات وتوليد اختبارات | ~24,000 | ~38,000 | +58% |
| 10 جولات من المساعدة البرمجية في محادثة طويلة | ~42,000 | ~67,000 | +60% |
تؤكد هذه البيانات أن: عدم استمرارية Opus 4.7 ليست مجرد وهم، بل هي تغيير منهجي قابل للقياس والتحقق.
لماذا تدعي Anthropic أن "الأسعار لم تتغير"؟
أوضحت Anthropic في إعلانها أن:
- سعر المدخلات: 5 دولار / مليون Token (لم يتغير)
- سعر المخرجات: 25 دولار / مليون Token (لم يتغير)
هذا الكلام دقيق من حيث سعر الوحدة، لكنه "تلاعب لفظي" كلاسيكي؛ فسعر الوحدة لم يتغير، لكن عدد الـ Token المستهلكة لإنجاز نفس المهام قد زاد، مما يعني أن الفاتورة النهائية سترتفع بطبيعة الحال. وتصف منصات تحليل التكاليف مثل Finout هذه الظاهرة بأنها "قصة التكلفة الحقيقية خلف سعر لم يتغير".
💰 نصيحة للتحكم في التكاليف: للبيئات الإنتاجية الحساسة لتكاليف الـ Token، نوصي بشدة بإجراء اختبار مقارنة للفاتورة مع حركة مرور حقيقية عبر منصة APIYI (apiyi.com) قبل الترحيل. تدعم المنصة إحصائيات استدعاء دقيقة وتحليلاً للتكاليف، مما يسهل قياس التأثير الحقيقي للترحيل على ميزانيتك.
إليك ترجمة المحتوى مع الحفاظ على التنسيق والرموز المطلوبة:
ثلاثة إجراءات لحل مشكلة استهلاك Claude Opus 4.7 السريع
إذا قمت بالفعل بالترقية إلى الإصدار 4.7، أو لم تتمكن من الرجوع إلى إصدار سابق مؤقتاً، فإليك ثلاثة إجراءات يمكنك تنفيذها فوراً لإعادة استهلاك الرصيد إلى نطاق يمكن التحكم فيه.
الإجراء 1: خفض مستوى الجهد (effort) يدوياً إلى medium أو high
قام Claude Code بضبط xhigh كإعداد افتراضي لتحسين الأداء في "مهام البرمجة الأكثر تعقيداً"، ولكن بالنسبة لمعظم المهام اليومية، فإن مستوى medium أو high كافٍ تماماً.
يمكنك تحديد ذلك صراحةً في استدعاءات API:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "أعد هيكلة هذا الكود"}],
extra_headers={
"reasoning-effort": "medium"
}
)
عرض مقارنة فعلية لاستهلاك التوكنز بناءً على مستويات الجهد المختلفة
import time
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
TEST_PROMPT = """
يرجى تحليل مشاكل الأداء في الكود التالي وتقديم اقتراحات للتحسين.
(أدرج هنا 200 سطر من كود Python)
"""
results = {}
for effort in ["medium", "high", "xhigh", "max"]:
start = time.time()
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": TEST_PROMPT}],
extra_headers={"reasoning-effort": effort},
max_tokens=8192
)
results[effort] = {
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
"latency": round(time.time() - start, 2)
}
for effort, data in results.items():
print(f"{effort}: {data}")
نصيحة: استخدم high للمساعدة البرمجية اليومية، وmedium للمحادثات البسيطة، ولا تستخدم xhigh إلا عند التعامل مع عمليات إعادة هيكلة معقدة للغاية تتضمن ملفات متعددة.
الإجراء 2: توجيه الطلبات لنماذج مختلفة حسب السيناريو
لا تقم بترقية كل شيء إلى 4.7 بشكل عشوائي. إليك استراتيجية توجيه معقولة:
| سيناريو العمل | النموذج الموصى به | السبب |
|---|---|---|
| برمجة الوكيل (Agentic) لملفات متعددة | Opus 4.7 (xhigh) | ملعب الوكلاء |
| توليد كود لملف واحد | Opus 4.7 (high) | استفادة واضحة من الترقية |
| تحليل الصور عالية الدقة | Opus 4.7 (high) | نقلة نوعية في الرؤية |
| RAG للمستندات الطويلة | Opus 4.6 | تجنب انهيار MRCR |
| وكيل أبحاث الويب | GPT-5.4 Pro | يتفوق في BrowseComp |
| الكتابة العادية / المحتوى | Opus 4.6 أو Sonnet | تكلفة Tokenizer أقل |
| محادثة بسيطة | Haiku / Sonnet | أفضل قيمة مقابل السعر |
الإجراء 3: تفعيل ميزانيات المهام (Task Budgets) لتقييد الاستهلاك
تعد ميزانيات المهام (Task Budgets) الجديدة في Opus 4.7 (في مرحلة الاختبار العام) أداة قوية للتحكم في تكلفة دورات الوكيل:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "أكمل مهمة إعادة الهيكلة بالكامل"}],
extra_headers={
"task-budget-tokens": "30000",
"reasoning-effort": "high"
}
)
سيرى النموذج الميزانية المتبقية في كل جولة استجابة، ويقوم تلقائياً بتعديل استراتيجيته بناءً عليها؛ حيث يعطي الأولوية للمهام الأساسية عندما تكون الميزانية محدودة، ويتعمق في التفاصيل عندما تكون الميزانية كافية.
🎯 نصيحة شاملة: بالنسبة للفرق الحساسة تجاه ميزانية التوكنز، نوصي بإدارة استدعاءات Claude Opus 4.7 بشكل موحد عبر منصة APIYI (apiyi.com)، حيث توفر المنصة مراقبة فورية للرصيد وقدرات توجيه متعددة النماذج، مما يساعدك على تحويل الشعور بـ "عدم كفاءة الاستهلاك" إلى منحنى تكلفة يمكن التحكم فيه.
مقارنة بين Claude Opus 4.7 و GPT-5.4 xhigh
ذكر بعض المستخدمين في تعليقاتهم: "في اختباراتي الفعلية، يبدو أن Opus 4.7 لا يزال أقل من مستوى GPT-5.4 xhigh". هذا حكم يحتاج إلى مناقشة بناءً على السيناريوهات.

مقارنة مباشرة لـ 9 معايير
| المعيار | Opus 4.7 | GPT-5.4 | الفائز |
|---|---|---|---|
| SWE-bench Pro | 64.3% | 57.7% | Opus 4.7 (+6.6) |
| MCP-Atlas | 77.3% | 68.1% | Opus 4.7 (+9.2) |
| CyberGym | — | — | Opus 4.7 (+6.8) |
| OSWorld-Verified | 78.0% | 75.0% | Opus 4.7 (+3.0) |
| GDPVal-AA (معرفة المؤسسات) | Elo 1753 | Elo 1674 | Opus 4.7 |
| التعرف البصري | 98.5% | — | Opus 4.7 |
| BrowseComp (أبحاث الويب) | 79.3% | 89.3% | GPT-5.4 Pro (+10.0) |
| RAG للسياق الطويل | 32.2% | لا يوجد انهيار | GPT-5.4 |
| تكلفة التوكنز | 1.0–1.35× | مستقرة | GPT-5.4 |
حقق Opus 4.7 الفوز في 6 من أصل 9 معايير مع تعادل واحد وخسارتين، ولكن في السيناريوهات التي تهمك أكثر، قد تكون النتيجة معاكسة تماماً:
- إذا كان سيناريو عملك يعتمد بشكل كبير على أبحاث الويب (مثل وكلاء الأبحاث، وأتمتة المتصفح)، فإن GPT-5.4 xhigh يتفوق بالفعل في BrowseComp بنسبة 10 نقاط مئوية.
- إذا كنت تقوم بـ RAG لمستندات طويلة، فإن GPT-5.4 لا يعاني من مشكلة انهيار MRCR.
- إذا كنت تسعى لاستقرار تكلفة التوكنز، فإن Tokenizer الخاص بـ GPT-5.4 لم يتغير.
لذا، فإن الشعور بأن "Opus 4.7 ليس بمستوى GPT-5.4 xhigh" هو شعور منطقي تماماً لسير عمل معين.
مصفوفة اتخاذ القرار لاختيار النموذج
| احتياجك الأساسي | النموذج المفضل | الخيار البديل |
|---|---|---|
| برمجة الوكيل (Agentic) لملفات متعددة | Opus 4.7 xhigh | Opus 4.6 |
| مهام البرمجة الفعلية داخل IDE | Opus 4.7 high | GPT-5.4 |
| وكيل الأبحاث (أبحاث الويب) | GPT-5.4 Pro | Opus 4.7 |
| أسئلة وأجوبة حول معرفة المؤسسة | Opus 4.7 | GPT-5.4 |
| فهم المستندات الطويلة / RAG | Opus 4.6 | GPT-5.4 |
| فهم الصور عالية الدقة | Opus 4.7 | Gemini 3.1 Pro |
| حساسية عالية جداً للتكلفة | Opus 4.6 / Sonnet | GPT-5.4 mini |
💡 نصيحة لنشر نماذج متعددة: من الصعب على تطبيقات الذكاء الاصطناعي الحديثة تغطية جميع السيناريوهات بنموذج واحد. نوصي بالوصول الموحد إلى نماذج Claude وGPT وGemini الكاملة عبر منصة APIYI (apiyi.com)، وتوجيه الطلبات بذكاء حسب السيناريو. توفر هذه المنصة القدرة على استدعاء جميع النماذج الرئيسية باستخدام مفتاح API واحد، مما يقلل بشكل كبير من تعقيد نشر نماذج متعددة.
الأسئلة الشائعة حول استهلاك Claude Opus 4.7
س1: هل Claude Opus 4.7 أقل كفاءة في استهلاك الرصيد فعلياً مقارنة بـ 4.6؟
نعم، ولكن يجب فهم "عدم الكفاءة" من بُعدين:
-
مستوى الرصيد: هو أقل كفاءة بشكل واضح. توسع الـ Tokenizer بنسبة 0-35% بالإضافة إلى إعداد
xhighالافتراضي في Claude Code يؤدي إلى زيادة استهلاك الرموز (Tokens) بنسبة 30-80%. أفاد مستخدمو باقة Max Plan 20x في الاختبارات العملية أن شريط الرصيد ينفد بسرعة أكبر. -
مستوى القدرات: يعتمد على سيناريو الاستخدام. هو أقوى بوضوح في مهام وكلاء البرمجة (Agent)، الرؤية الحاسوبية، واستخدام الأدوات؛ بينما هو أضعف أو متساوٍ في مهام استرجاع المعلومات (RAG) من المستندات الطويلة، البحث عبر الويب، والكتابة العامة.
إذا كنت لا تستخدم هذه الأنواع من مهام الوكلاء، فإن Opus 4.7 بالنسبة لك هو مجرد "أكثر تكلفة".
س2: لماذا تقول Anthropic إن “السعر لم يتغير” بينما أصبحت فاتورتي أغلى؟
ما أعلنته الشركة رسمياً هو أن سعر الوحدة لم يتغير: 5 دولارات لكل مليون رمز إدخال، و25 دولاراً لكل مليون رمز إخراج. لكن الـ Tokenizer الجديد في Opus 4.7 يجعل النص نفسه يستهلك 1.0–1.35 ضعف من الرموز، بالإضافة إلى تضخم رموز الإخراج بسبب xhigh، مما يجعل الفاتورة النهائية أعلى بنسبة 20-50% مقارنة بعصر 4.6.
للتحكم في التكاليف، يمكنك إجراء اختبارات مقارنة فعلية لحركة البيانات عبر منصة APIYI (apiyi.com)، حيث تدعم المنصة الاستدعاء المتوازي لسلسلة Claude الكاملة مع إحصائيات دقيقة للتكاليف.
س3: استهلاك رصيد Max Plan 20x أصبح سريعاً، ما الإجراءات التي يمكن اتخاذها؟
ثلاثة إجراءات يمكنك تنفيذها فوراً:
- تقليل الجهد (effort) إلى high أو medium: أغلق إعداد
xhighالافتراضي في Claude Code، فإعدادhighكافٍ للمهام اليومية. - إيقاف خطوات التفكير غير الضرورية: في المحادثات الطويلة، عند مواجهة أسئلة بسيطة، اطلب من النموذج صراحةً تخطي التفكير العميق.
- التبديل إلى Sonnet أو Opus 4.6 للمهام غير المتعلقة بالوكلاء: الكتابة، الأسئلة البسيطة، والترجمة لا تتطلب استخدام Opus 4.7.
هذه الإجراءات الثلاثة مجتمعة يمكن أن تعيد استهلاك رصيد Max Plan إلى مستويات عصر 4.6 أو حتى أقل.
س4: لقد انتقلت بالفعل إلى Opus 4.7، هل يستحق الأمر العودة إلى 4.6؟
يعتمد ذلك على سير عملك الأساسي:
- إذا كنت تعمل بشكل أساسي على برمجة الوكلاء متعددة الملفات: لا تتراجع، فإصدار 4.7 أقوى حقاً.
- إذا كنت تعمل بشكل أساسي على RAG للمستندات الطويلة / تحليل العقود: تراجع فوراً إلى 4.6، حيث أن أداء MRCR سيء جداً في 4.7.
- السيناريوهات المختلطة: لا داعي للتراجع الكامل، يمكنك التوجيه حسب السيناريو؛ استخدم 4.7 لمهام الوكلاء الثقيلة، و4.6 أو Sonnet للبقية.
في استدعاءات API، العودة بسيطة جداً، فقط قم بتغيير معامل model من claude-opus-4-7 إلى claude-opus-4-6.
س5: هل Opus 4.7 أقوى من GPT-5.4 xhigh في جميع السيناريوهات؟
لا. تظهر البيانات الرسمية أن Opus 4.7 تفوق في 6 من أصل 9 معايير مقارنة مباشرة، لكنه خسر في سيناريوهين حاسمين:
- BrowseComp (البحث عبر الويب): GPT-5.4 Pro حقق 89.3% مقابل 79.3% لـ Opus 4.7.
- RAG بالسياق الطويل: لم يظهر GPT-5.4 انهياراً مشابهاً لـ MRCR.
لذا، فإن قول المستخدمين "في اختباراتي لا يزال Opus 4.7 لا يرقى لمستوى GPT-5.4 xhigh" قد يكون صحيحاً تماماً، بشرط أن يكون سيناريو عملك الأساسي هو البحث عبر الويب أو المستندات الطويلة.
من خلال منصة APIYI (apiyi.com)، يمكنك استدعاء Claude وGPT في نفس المشروع، والتوجيه حسب السيناريو، وهذا هو النهج الأكثر واقعية حالياً.
س6: جودة مخرجات الموجهات (Prompts) القديمة انخفضت على Opus 4.7، ماذا أفعل؟
هذا أثر جانبي لكون 4.7 "أكثر حرفية" في اتباع التعليمات. مبادئ إعادة الكتابة:
- تحويل النية الضمنية إلى قيود صريحة: بدلاً من "اكتب بشكل احترافي أكثر" → استخدم "يجب استخدام مصطلحات الصناعة وتجنب التعبيرات العامية".
- تحويل القيود الغامضة إلى قيم رقمية: بدلاً من "لا تجعلها طويلة جداً" → استخدم "يجب أن تكون في حدود 300 كلمة".
- إضافة قيود الأمثلة السلبية: أخبر النموذج بما هي المخرجات غير المقبولة.
هذا العمل يتطلب جهداً، وبالنسبة لمكتبات الموجهات الكبيرة، يُنصح بإجراء اختبار A/B أولاً لتحديد الموجهات التي تحتاج إلى إعادة كتابة.
ملخص مزايا وعيوب Claude Opus 4.7
المزايا الحقيقية (نقاط القوة)
- قفزة في قدرات وكلاء البرمجة: SWE-bench Pro بنسبة 64.3%، وCursorBench بنسبة 70%، متفوقاً على GPT-5.4.
- تغير نوعي في الرؤية (Vision): دقة عالية تصل إلى 3.75 ميجابكسل، ومعايير بصرية بنسبة 98.5%.
- الأقوى في سلسلة أدوات MCP-Atlas: بنسبة 77.3%، متصدراً جميع النماذج المتاحة للجمهور.
- اتباع تعليمات أكثر دقة: مخرجات أكثر تحكماً للموجهات ذات القيود الكاملة.
- ميزانيات المهام (Task Budgets): توفر قدرة على إدارة تكاليف الوكلاء.
القيود الحقيقية (نقاط الضعف)
- توسع الـ Tokenizer بنسبة 0-35%: غطت لغة التسويق على الارتفاع الحقيقي في التكاليف.
- إعداد xhigh الافتراضي يرفع استهلاك رموز الإخراج: أصبح رصيد Max Plan 20x ضيقاً بشكل ملحوظ.
- انهيار MRCR في السياق الطويل: انخفض من 78.3% إلى 32.2%، مما يجعل RAG للمستندات الطويلة غير قابل للاستخدام.
- تراجع في BrowseComp: خسر أمام GPT-5.4 Pro في مهام البحث عبر الويب.
- تراجع طفيف في CyberGym: انخفاض طفيف في المهام المتعلقة بالأمن.
- مشاكل توافق الموجهات القديمة: الموجهات التي تعتمد على النوايا الضمنية تحتاج إلى إعادة كتابة.
ملخص
يُعد نموذج Claude Opus 4.7 ترقية نموذجية للغاية لما يمكن تسميته بـ "التخصص في سيناريو محدد". فكل التحسينات التي طرأت عليه تهدف إلى غاية واحدة: استعادة Anthropic لصدارة المشهد في مجال البرمجة باستخدام الوكلاء (Agentic Coding). لقد نجح النموذج في تحقيق هذا الهدف، لكن الثمن كان أن مستخدمي "جميع السيناريوهات الأخرى" هم من يدفعون ضريبة هذه الترقية.
إذا كنت تعمل في بناء الوكلاء، أو كنت من المستخدمين المكثفين لـ Claude Code أو Cursor، فإن الانتقال إلى Opus 4.7 يستحق العناء فوراً. أما إذا كانت مهامك الأساسية تتمحور حول الكتابة، أو استرجاع المعلومات المعزز بالتوليد (RAG)، أو الأبحاث عبر الويب، أو إذا كنت تهتم بحساسية التكلفة، فننصحك بما يلي:
- احتفظ بـ Opus 4.6 للمهام غير المتعلقة بالوكلاء.
- اخفض مستوى الجهد (effort) الافتراضي في Claude Code من xhigh إلى high.
- اعتمد التوجيه الذكي للنماذج حسب السيناريو، ولا تعتمد على نموذج واحد لكل شيء.
عبارة "السعر لم يتغير" ليست القصة كاملة أبداً. فالتكلفة الحقيقية تكمن في الـ Tokenizer، والإعدادات الافتراضية، وعمق الاستدلال. نموذج Opus 4.7 ليس سيئاً، بل هو غير مصمم ليكون عاماً؛ وبمجرد فهمك لهذه النقطة، ستتمكن من استغلال قيمته الحقيقية.
نوصي باستخدام منصة APIYI (apiyi.com) لإدارة استدعاءات نماذج Claude بالكامل بشكل موحد. توفر المنصة توجيهاً ذكياً متعدد النماذج، ومراقبة فورية للرصيد، وواجهة برمجة تطبيقات (API) متوافقة تماماً مع الواجهة الرسمية، مما يجعلها الأداة الأكثر عملية للتعامل مع مشكلة "التخصص في سيناريو محدد" لنموذج Opus 4.7.
المراجع
-
إعلان Anthropic الرسمي: تقديم Claude Opus 4.7
- الرابط:
anthropic.com/news/claude-opus-4-7 - الوصف: تعريف القدرات الرسمي وسيناريوهات الاستخدام الموصى بها.
- الرابط:
-
وثائق Anthropic الرسمية: دليل الانتقال إلى Opus 4.7
- الرابط:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - الوصف: تغييرات الـ Tokenizer وشرح مستوى xhigh.
- الرابط:
-
تحليل التكلفة من Finout: التكلفة الحقيقية وراء ثبات السعر
- الرابط:
finout.io/blog/claude-opus-4.7-pricing-the-real-cost-story-behind-the-unchanged-price-tag - الوصف: تحليل تكاليف من طرف ثالث وتفكيك للفواتير.
- الرابط:
-
مقارنة Artificial Analysis: مواجهة بين GPT-5.4 xhigh و Claude Opus
- الرابط:
artificialanalysis.ai/models/comparisons/gpt-5-4-vs-claude-opus-4-6 - الوصف: بيانات مقارنة مستقلة من طرف ثالث لعدة نماذج.
- الرابط:
-
GitHub Issue #23706: ملاحظات مستخدمي خطة Max حول استهلاك الـ Token
- الرابط:
github.com/anthropics/claude-code/issues/23706 - الوصف: تجربة مباشرة من مستخدمي Claude Code Max Plan.
- الرابط:
المؤلف: الفريق التقني لـ APIYI
تاريخ النشر: 18 أبريل 2026
النماذج المشمولة: Claude Opus 4.7 / Claude Opus 4.6 / GPT-5.4 xhigh
للتواصل التقني: نرحب بكم عبر منصة APIYI (apiyi.com) للحصول على رصيد اختبار للنماذج المتعددة، وتجربة الفوارق الحقيقية في الأداء بين السيناريوهات المختلفة بأنفسكم.