“هل يدعم gemini-3.1-flash-lite-image وضع الاستدلال أم لا؟” هذا من أكثر الأسئلة التي طُرحت مؤخرًا في مجموعات استدعاء API. الإجابة نعم، وليس هذا مجرد تخمين — فقد راجعنا الوثائق الرسمية من Google، وأجرينا ثلاث مجموعات من التجارب المقارنة عبر بوابة APIYI، وحصلنا على بيانات فعلية لاستهلاك الرموز والكمون. في هذا المقال سنشرح مفتاح thinkingLevel من ثلاث زوايا: بنية المعاملات، ونتائج القياس الفعلية، وقواعد الفوترة.
القيمة الأساسية: بعد قراءة هذا المقال، ستعرف بوضوح كيف تفعّل وضع الاستدلال في gemini-3.1-flash-lite-image، وكم سيضيف من الرموز، وفي أي الحالات يستحق تقبّل هذا التأخير.

الخلاصة الأساسية حول وضع الاستدلال في gemini-3.1-flash-lite-image
لنبدأ بالخلاصة ثم ندخل في التفاصيل. تنص وثائق Google الرسمية بوضوح على أنه باستخدام gemini-3.1-flash-image وgemini-3.1-flash-lite-image، يمكن للمطوّرين التحكم في مقدار التفكير الذي يستخدمه النموذج. هذا يعني أن فئة flash-lite تتضمن أيضًا قدرات استدلال مدمجة، وليس فقط النموذج الرائد. لكن ليس كل نماذج الصور تدعم هذا المعامل؛ والجدول التالي يوضح مقارنة الدعم بين ثلاثة من أشهر نماذج الصور من Gemini.
| النموذج | هل يدعم thinkingLevel | مستويات الضبط | المستوى الافتراضي | ملاحظة |
|---|---|---|---|---|
| gemini-3.1-flash-image | ✅ مدعوم | minimal / high | minimal | مذكور بوضوح في الوثائق الرسمية |
| gemini-3.1-flash-lite-image | ✅ مدعوم | minimal / high | minimal | يستخدم نفس thinkingConfig مع flash-image |
| gemini-3-pro-image | ⚠️ المعامل غير فعّال | ثابت، غير قابل للضبط | ثابت داخليًا | تمرير high لا يُحدث خطأ، لكن لا يظهر أي فرق في الاختبار |
من المهم توضيح أن thinkingLevel لا يملك سوى مستويين فقط، وليس مثل نماذج النصوص التي تتيح ضبط ميزانية التفكير بشكل متدرج. وتشير العبارة الأصلية في الوثائق إلى أن “minimal لا يعني أن النموذج لا يفكر إطلاقًا”، أي إن النموذج، حتى في الوضع الافتراضي، ينفذ قدرًا أساسيًا من الاستدلال، لكنه لا يجري عدة جولات من التحقق من التكوين كما يفعل في وضع high.
وهذا أيضًا مؤشر مهم على مستوى الصناعة. ففي الأجيال السابقة من نماذج توليد الصور — سواء nano banana أو النسخة الأولى من flash-image — لم تكن واجهات API الرسمية تكشف عن معاملات مثل مستوى التفكير. كان النموذج إما يعتمد سياسة ثابتة لإنتاج الصورة أو يترك مهمة تعويض عيوب التكوين لهندسة الموجه. أما في جيل 3.1، فقد فتحت Google آلية “التخطيط أولًا ثم التوليد” أمام سلسلة flash، أي أنها نقلت عمليًا نمط التفكير الذي اختُبر سابقًا في نماذج النصوص إلى سيناريو توليد الصور. فهم هذا السياق يساعدك على توقع ما إذا كانت شركات أخرى ستسير على النهج نفسه في نماذج الصور الخاصة بها.
🎯 نصيحة تقنية: إذا كنت تستدعي نماذج صور Gemini عبر APIYI من خلال apiyi.com، فمن الأفضل أن تبدأ بمستوى
minimalالافتراضي لتشغيل سير العمل، ثم تقرر لاحقًا ما إذا كنت تحتاج إلى التحويل إلىhighبناءً على جودة النتائج الفعلية. توفر المنصة واجهة موحدة، ويمكنك باستخدام نفس الشيفرة التبديل بين gemini-3.1-flash-image وflash-lite-image وpro-image، ما يسهل إجراء مقارنات A/B.
شرح تفصيلي لمعامل thinkingLevel وطريقة استدعائه
thinkingLevel ليس معاملًا مستقلًا، بل يوجد داخل الكائن thinkingConfig تحت generationConfig، ويُستخدم مع includeThoughts. يحدد includeThoughts ما إذا كان سيتم إرجاع ملخص تفكير النموذج إلى جهة الاستدعاء، بينما يحدد thinkingLevel “قوة” التفكير. هذان مفتاحان منفصلان وغير مترابطين، فلا تخلط بينهما.
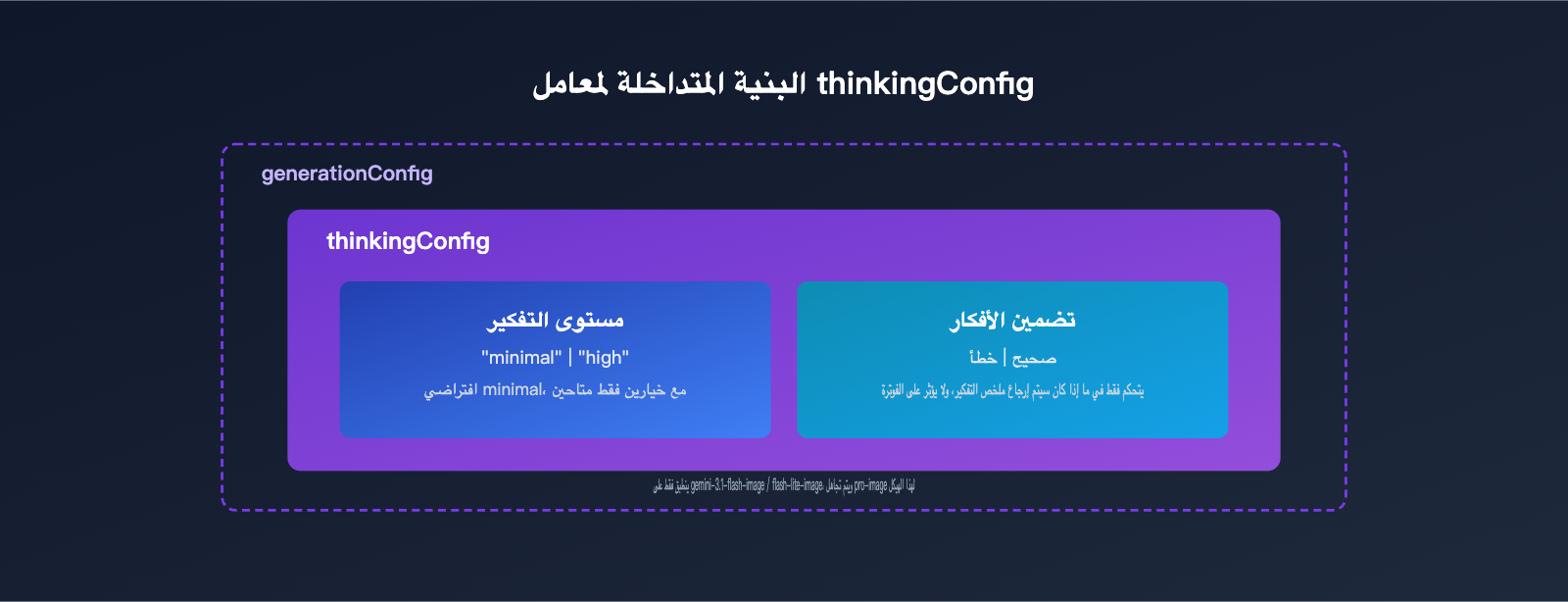
يوضح الجدول التالي نوع كل حقل داخل thinkingConfig ونطاق قيمه.
| الحقل | النوع | القيم الممكنة | القيمة الافتراضية | الوظيفة |
|---|---|---|---|---|
| thinkingLevel | سلسلة تعداد | minimal / high |
minimal |
التحكم في قوة استدلال النموذج، ويعمل فقط مع نماذج الصور من سلسلة flash |
| includeThoughts | قيمة منطقية | true / false |
false |
تحديد ما إذا كان سيتم إرجاع ملخص عملية التفكير في الاستجابة، ولا يؤثر في الفوترة |
عند الاستدعاء الفعلي، تكون بنية الكتابة في اللغات الثلاث الشائعة متطابقة تمامًا، إذ نمرر كائن thinkingConfig داخل config. على سبيل المثال، في Python:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # الاستدعاء عبر البوابة الموحدة APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-image",
messages=[{"role": "user", "content": "ارسم قطة تشرب القهوة تحت الجبال الثلجية"}],
extra_body={
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": True
}
}
)
print(response.choices[0].message.content)
عرض مثال الاستدعاء الخام عبر REST كاملًا
{
"contents": [{"parts": [{"text": "ارسم قطة تشرب القهوة تحت الجبال الثلجية"}]}],
"generationConfig": {
"responseModalities": ["IMAGE"],
"thinkingConfig": {
"thinkingLevel": "high",
"includeThoughts": true
}
}
}
صيغة JavaScript SDK المقابلة لها مطابقة في البنية، لكن يتم تحويل أسلوب REST من snake_case إلى كائن thinkingConfig بصيغة camelCase، بينما تبقى أسماء الحقول الأخرى كما هي. لا يوجد فرق جوهري في منطق الاستدعاء بين اللغات الثلاث، فقط تذكّر القاعدة التالية: thinkingConfig لا يوضع إلا تحت generationConfig.
هناك تفصيل قد يسبب خطأ شائعًا: قيمة thinkingLevel حساسة لحالة الأحرف لأنها سلسلة تعداد. في الأمثلة الرسمية ظهرت أحيانًا الصيغتان "High" و"high"، وقد تبيّن في الاختبار أن كلتيهما تعملان عبر البوابة بشكل صحيح. لكن لتجنب الاعتماد على سلوك توافق غير موثق، يُفضَّل في كود الإنتاج توحيد الاستخدام على القيم الصغيرة "high" و"minimal"، حتى لا تتأثر الاستدعاءات لاحقًا إذا شددت الجهة الأصلية التحقق من حالة الأحرف.
نصيحة: استخدم APIYI عبر apiyi.com للحصول على رصيد تجريبي مجاني، ثم اختبر من جهة البوابة ما إذا كان thinkingConfig يمرّر بشكل صحيح، فهذا أسهل من طلب مفتاح رسمي والتجربة عليه مباشرة.
بيانات اختبار APIYI الفعلية: التأثير الحقيقي لـ thinkingLevel على التوكن والزمن
حتى لو كان الوصف النظري واضحًا، يبقى الاختبار العملي أكثر إقناعًا. استخدمنا نفس الموجه، وعلى دقة 1K في تحويل النص إلى صورة، واختبرنا عبر بوابة APIYI ثلاث حالات: gemini-3.1-flash-image بوضع minimal، ثم high، ثم تمرير high قسرًا إلى gemini-3-pro-image.
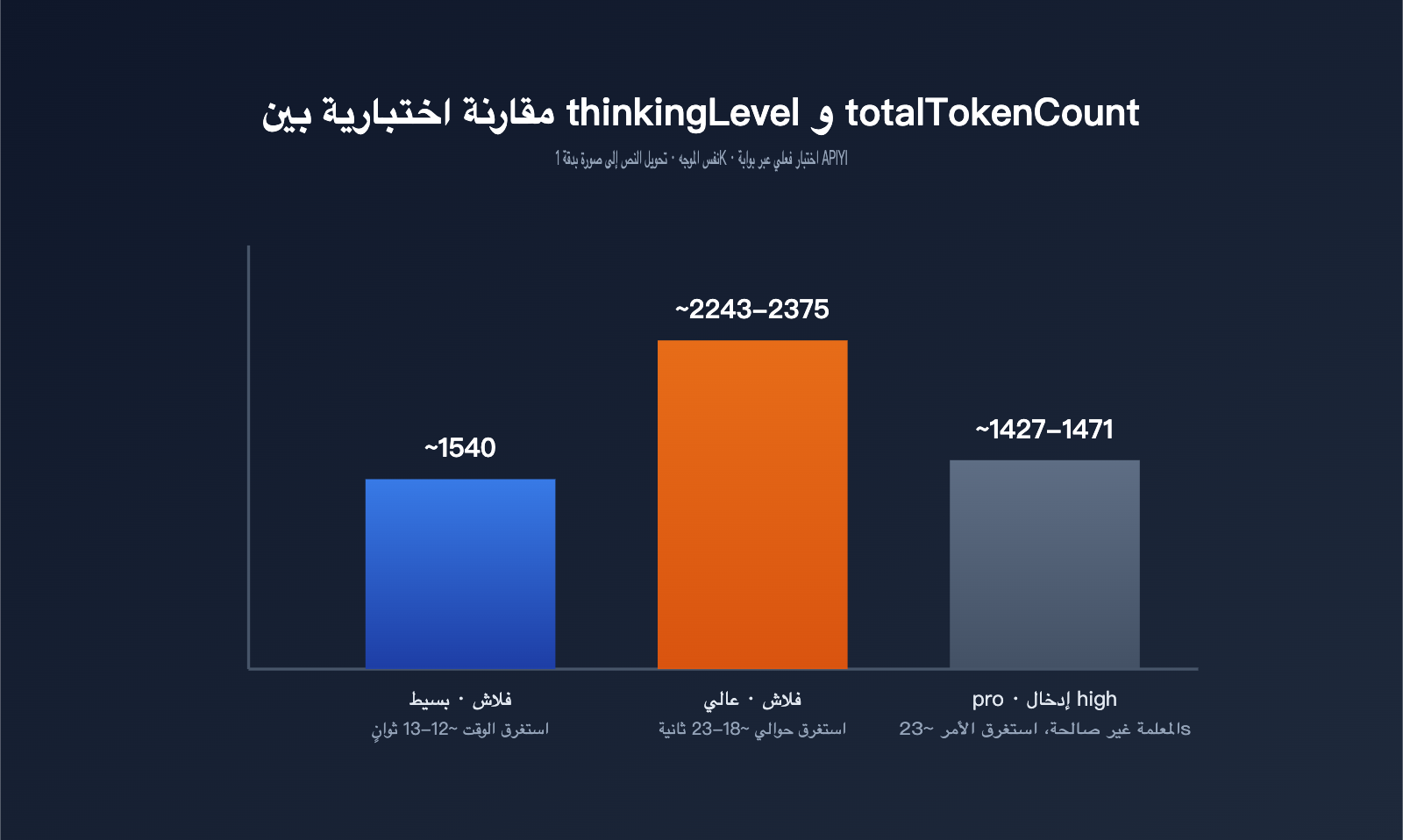
| النموذج / الإعداد | thoughtsTokenCount | توكنات الصورة | totalTokenCount | الزمن المستغرق |
|---|---|---|---|---|
| gemini-3.1-flash-image · minimal (افتراضي) | لا يوجد هذا الحقل | 1120 | حوالي 1540 | حوالي 12-13 ثانية |
| gemini-3.1-flash-image · high | 700-792 | 1120 | حوالي 2243-2375 | حوالي 18-23 ثانية |
| gemini-3-pro-image · مع تمرير high | 181-214 (مطابق تقريبًا للوضع الافتراضي) | 1120 | حوالي 1427-1471 | حوالي 23 ثانية |
تُظهر هذه البيانات ثلاث ملاحظات مهمة. أولًا، عند التحويل إلى high يرتفع thoughtsTokenCount من القيمة الافتراضية 0، حتى إن الحقل لا يظهر أصلًا في الاستجابة، إلى نطاق 700-800 تقريبًا، كما ترتفع إجمالي التوكنات بنحو 50%، ويزداد زمن الاستجابة من 12-13 ثانية إلى 18-23 ثانية. هذا يعني أن التفكير العميق يكلف وقتًا وتوكنات فعلية. ثانيًا، سواء كان الوضع minimal أو high، يبقى عدد توكنات الصورة النهائية ثابتًا عند 1120، وهذا يوضح أن thinkingLevel يؤثر فقط في “طريقة تفكير” النموذج، ولا يغيّر دقة الصورة أو طريقة احتسابها. ثالثًا، تمرير high إلى gemini-3-pro-image لا يؤدي إلى خطأ، لكن قيمة التفكير الفعلية تبقى 181-214، أي قريبة جدًا من الوضع الافتراضي، وهذا ينسجم مع ما تذكره الوثائق الرسمية من أن pro-image يملك سلوك تفكير ثابتًا ولا يدعم الضبط الخارجي.
بمعنى آخر، إذا كانت طبقة منطقك البرمجي ترسل thinkingConfig نفسه إلى نماذج flash وflash-lite وpro دفعة واحدة، فسيقوم pro-image بتجاهل هذا المعامل بهدوء من دون أن يسبب فشلًا في الطلب، لكنه لن يطبّق بالفعل مستوى التفكير الذي توقّعته.
ومن المهم الإشارة إلى أن الأرقام أعلاه ليست نتيجة استدعاء واحد، بل هي نطاقات مأخوذة بعد تكرار الطلب نفسه عدة مرات في كل إعداد. ولهذا ظهر thoughtsTokenCount في وضع high على شكل 700-792 بدلًا من قيمة ثابتة. مهام التفكير نفسها تتضمن قدرًا من العشوائية، إذ إن المسار الداخلي للاستدلال لا يكون متطابقًا كل مرة، وبالتالي يتغير استهلاك التوكن قليلًا. لكن بشكل عام تبقى النسبة والاتجاهات ثابتة وقابلة للتكرار، من دون ظهور حالات شاذة مثل أن يكون high أسرع من minimal أو أن يقفز استهلاك التوكن إلى آلاف بشكل غير طبيعي.
حول token التفكير في نموذج الصور وقواعد الفوترة
كثير من المطورين عندما يرون الحقل thoughtsTokenCount لأول مرة يقارنونه تلقائيًا بكلفة التفكير في نموذج النص، لكن آلية التفكير في نموذج الصور مختلفة فعلًا، لأنها تُحاسَب على جزأين. فهم هذه النقطة مهم جدًا للتحكم في التكلفة.
| البُعد | تفكير نموذج النص | تفكير نموذج الصور |
|---|---|---|
| شكل ناتج التفكير | سلسلة استدلال نصية خالصة | ملخص نصي + حتى صورتين مؤقتتين كمسودة تركيب |
| كمية توكنات نص التفكير | قد تصل إلى آلاف | في فئة Pro لا تتجاوز 400، وفي فئة Flash high نحو 700-800 |
| الحقل الذي يتحمل التكلفة الأساسية | thoughtsTokenCount |
تُحتسب المسودات ضمن candidatesTokenCount وتُفوّتَر كجزء صورة عادي |
| معيار فوترة كل مسودة | لا ينطبق | دقة 1K حوالي 1120 توكن، أي ما يعادل 0.0336 دولار/صورة |
تأثير includeThoughts على الفوترة |
لا تأثير، الفوترة ثابتة | لا تأثير، الفوترة ثابتة |
تشدد الوثائق الرسمية على أنه سواء كانت قيمة includeThoughts هي true أو false، فإن التوكنات الناتجة عن التفكير ستُفوّتَر كالمعتاد. وقد أكدنا ذلك أيضًا في الاختبارات الفعلية — فعند تفعيل includeThoughts لم يتغير لا شكل الاستجابة ولا إجمالي الفوترة، وإنما ظهر فقط ملخص تفكير إضافي يمكن استخدامه للتجربة والتشخيص. بمعنى آخر، includeThoughts هو مفتاح “هل أريد أن أرى؟” وليس “هل أريد أن أدفع؟”، وهذه نقطة يسهل جدًا إساءة فهمها.
الأهم من ذلك أن الجزء الأكبر من تكلفة التفكير في نموذج الصور لا يقع على الحقل thoughtsTokenCount نفسه، بل على صور التركيب المؤقتة التي يُنشئها النموذج أثناء الاستدلال. تشير الوثائق إلى أن النموذج قد يُنتج في مرحلة التفكير حتى صورتين مؤقتتين لاختبار التركيب ومدى منطقية الترتيب، وهذه المسودات تُعاد كجزء صورة عادي وتُحتسب ضمن candidatesTokenCount، وتُفوّتَر وفق السعر القياسي للصورة الخارجة. هذا يعني أن تشغيل التوليد بأسلوب استدلالي في فئة high قد يضيف بصمتك صورة أو صورتين “غير مرئيتين” من حيث التكلفة، وهذا شيء قد يُنسى عند تقدير الميزانية.
الحساب الرقمي يجعل الصورة أوضح. لنفترض أن طلب توليد صورة بدقة 1K يعمل على فئة high، وأن نص التفكير يستهلك نحو 750 توكن. إذا أنشأ النموذج أثناء الاستدلال صورتين مؤقتتين، ومعهما الصورة النهائية، فستكون هناك نظريًا ثلاث صور part. وبحساب 1120 توكن لكل صورة، أي نحو 0.0336 دولار، تصبح كلفة إخراج الصور الثلاث قرابة 0.1 دولار، ثم تُضاف إليها كلفة نص التفكير، فيمكن أن تصل الكلفة الإجمالية إلى 2-3 أضعاف فئة minimal. وأما ما إذا كانت ستظهر فعلاً صورتان مؤقتتان أم لا، فيعتمد على تقدير النموذج لنص الموجه الحالي، وليس كل استدعاء في فئة high سيُنتج بالضرورة صورتين. ولهذا تظهر في الاختبارات الفعلية أحيانًا قيمة إجمالية للتوكنات ضمن نطاق 2243-2375 بدلًا من تضاعف دقيق.
💰 تحسين التكلفة: إذا كانت فرق التوكنات يهم فريقك، فمن الأفضل أولًا مراجعة سجل الاستدعاءات في منصة APIYI apiYI.com للتحقق من
totalTokenCountالفعلي، ثم تقرر إن كان من المناسب إبقاء فئة high مفعلة دائمًا، حتى لا تتجاوز الميزانية بسبب تجاهل تكلفة المسودات.
متى تستخدم high، ومتى تكتفي بالوضع الافتراضي minimal
بناءً على الاختبارات الفعلية، هذه خلاصة عملية بسيطة تساعدك على الاختيار.

| سيناريو العمل | المستوى الموصى به | السبب |
|---|---|---|
| توليد كميات كبيرة من صور التسويق، مع عدم الحاجة إلى دقة عالية في التركيب | minimal (الافتراضي) | تأخير أقل، وتكلفة توكنات يمكن التحكم بها، وهو كافٍ للإخراج اليومي |
| تركيب معقد متعدد العناصر، أو الحاجة إلى الالتزام الدقيق بتنسيق النصوص والعلاقات المكانية | high | التفكير الإضافي يمنح دقة أعلى في التركيب، ويستحق التكلفة من أجل الجودة |
| صفحات تفاصيل المتاجر الإلكترونية والبوسترات، حيث هامش الخطأ في التفاصيل منخفض | high | يقلل عدد مرات الإعادة وإعادة التوليد، فتكون الكلفة الإجمالية أقل |
| السيناريوهات التفاعلية الفورية التي تتطلب سرعة استجابة عالية جدًا | minimal | فئة high قد تزيد التأخير 5-10 ثوانٍ، وهو غير مناسب للتجربة التفاعلية القوية |
عند استدعاء gemini-3-pro-image |
لا حاجة للتعيين | سلوك التفكير في هذا النموذج ثابت، وتمرير المعامل لن يفيد |
ببساطة، فئة high تناسب الحالات التي يكون فيها “الخروج الجاهز من أول مرة” أهم من “سرعة الإخراج”. إذا كان تطبيقك يحتاج إلى محاولات متكررة وضبط الموجه عدة مرات حتى يصل إلى تركيب مقنع، فالأفضل غالبًا أن تشغل high من البداية، وتقبل بكلفة أعلى قليلًا في الطلب الواحد مقابل نسبة نجاح أعلى من أول مرة. وعلى المجموع، قد يكون هذا أوفر.
في التطبيق العملي، الأفضل أن تجعل thinkingLevel خيارًا قابلًا للضبط بدلًا من تثبيته داخل الكود. مثلًا يمكنك توجيه الطلبات تلقائيًا بحسب نوع المهمة: المهام الدُفعية تكون افتراضيًا minimal، أما الطلبات التي تتضمن تنسيقًا دقيقًا أو علاقات مكانية متعددة العناصر فتنتقل تلقائيًا إلى high. بهذه الطريقة تحافظ على متوسط تكلفة جيد، من دون التضحية بالجودة في الحالات الحساسة. وإذا كان فريقك يدير في الوقت نفسه منطق استدعاء النماذج flash وflash-lite وpro، فمن الأفضل توحيد المعالجة في طبقة تغليف المعاملات، وألا تمرر هذا المعامل إلا للنماذج التي تدعمه، حتى لا تُرسل معاملات غير فعالة إلى pro-image وتُصعّب عملية التشخيص.
🚀 بدء سريع: يُنصح باستخدام منصة APIYI apiYI.com لبناء نموذج أولي بسرعة. يمكنك استخدام
base_urlنفسه للتبديل بين إعدادَي minimal وhigh وإجراء مقارنة مباشرة، من دون الحاجة إلى إعداد بيانات اعتماد منفصلة لكل فئة.
الأسئلة الشائعة
س1: هل أداء الاستدلال في gemini-3.1-flash-lite-image و gemini-3.1-flash-image متشابه؟
كلاهما يستخدمان نفس بنية معاملات thinkingConfig، وكلاهما يدعمان المستويين minimal وhigh. لكن flash-lite مصنّف كنسخة خفيفة، لذا يكون عمق التفكير الفعلي وتفاصيل الصورة النهائية عادةً أضعف من flash-image. ويمكن ملاحظة ذلك أيضًا من نمط التسمية: سلسلة flash-lite في نماذج النصوص كانت دائمًا موجهة إلى “أسرع، أقل تكلفة، مع دقة أقل قليلًا”، وسلسلة الصور تواصل المنطق نفسه في المفاضلة. تفعيل high يمكن أن يعوض جزئيًا نقاط ضعف النموذج الخفيف في التركيبات المعقدة، لكنه من الصعب أن يطابق أداء flash-image بالكامل. وإذا أردت مقارنة كمية واضحة، يمكنك عبر منصة APIYI apiiyi.com استدعاء النموذجين على نفس مجموعة الموجهات ومقارنة thoughtsTokenCount ونتيجة الصورة مباشرةً.
س2: هل سيظهر خطأ إذا مرّرت معامل thinkingLevel إلى gemini-3-pro-image؟
لن يظهر خطأ. أظهرت اختباراتنا العملية أن تمرير high يعيد الاستجابة بشكل طبيعي، لكن thoughtsTokenCount يبقى في نطاق 181-214، وهو تقريبًا نفسه عند عدم تمرير المعامل، ما يدل على أن سلوك التفكير الداخلي في هذا النموذج ثابت ولا يقبل الضبط من الخارج. وعند الاستدعاء الجماعي لعدة نماذج، يُنصح بالتحقق من اسم النموذج داخل كود العمل بشكل منفصل، حتى لا تظن أن المعامل قد أصبح فعّالًا بينما هو في الواقع لا يؤثر.
س3: بعد تفعيل high، هل يجب تعديل دقة الصورة أو معاملات الجودة أيضًا؟
لا حاجة لذلك. تُظهر البيانات العملية أن token الصورة يبقى ثابتًا عند 1120 في كل من minimal وhigh، ما يعني أن thinkingLevel يؤثر فقط في عملية الاستدلال الداخلية للنموذج، ولا يغيّر إعدادات دقة الصورة الناتجة. أما الدقة فتبقى مضبوطة بشكل مستقل عبر معلمات الحجم داخل imageConfig، ولا علاقة لها بمستوى التفكير. وبعبارة أخرى، thinkingLevel ومعاملات الدقة هما محوران منفصلان لا يتداخلان: أحدهما يحدد “مدى شمولية التفكير”، والآخر يحدد “حجم الرسم ودرجة تفصيله”، ويمكن دمجهما بحرية من دون تعارض أو ترابط إلزامي.
الخلاصة
يتضح أن gemini-3.1-flash-lite-image يدعم بالفعل وضع الاستدلال، وقد تأكد ذلك من خلال الوثائق الرسمية وبيانات الاختبار العملي لدى APIYI. لا يتوفر في thinkingLevel سوى الخيارين minimal وhigh، وتفعيل high يرفع token التفكير إلى أكثر من 700 ويزيد زمن التنفيذ بنحو 5-10 ثوانٍ، لكنه لا يغيّر استهلاك token النهائي للصورة. أما gemini-3-pro-image، فرغم أنه يقبل هذا المعامل من دون خطأ، فإنه لا يفعّله فعليًا. وفهم منطق الفوترة ذي المسارين — حيث يسجل النص المتفكر فيه عبر thoughtsTokenCount وتُسجل مسودة البناء عبر candidatesTokenCount — هو عنصر أساسي للتحكم في تكلفة توليد الصور. وإذا كنت تحتاج إلى التبديل السريع والاختبار بين عدة نماذج صور من Gemini، فالأفضل استخدام البوابة الموحدة لدى APIYI apiiyi.com لتجربة النماذج، بدلًا من طلب مفتاح API مستقل لكل نموذج أو إدارة كود استدعاء منفصل.
البيانات الواردة في هذا المقال من اختبارات فريق APIYI التقنية. وإذا رغبت في مناقشة المزيد من تفاصيل استدعاء نماذج صور Gemini، يمكنك التواصل مع الدعم الفني عبر APIYI apiiyi.com.
المرجع
- الوثائق الرسمية لواجهة Gemini API – توليد الصور: شرح معلمة مستويات التفكير (thinking levels)
- الرابط:
ai.google.dev/gemini-api/docs/generate-content/image-generation
- الرابط:





