作者注:深度解析 Nano Banana Pro (gemini-3-pro-image-preview) 多輪對話出圖 API 的字段結構、contents 數組構造、thoughtSignature 機制與代碼實戰。
很多開發者第一次接入 Nano Banana Pro 都會遇到同一個困惑:在 gemini.google.com 網頁端可以連續追問「把背景換成黃昏」「再加一隻貓」,模型完美記得上一張圖;但調用官方 API 時,模型卻像斷片一樣什麼都不記得。原因是 Gemini API 本身是無狀態的,多輪上下文必須由調用方手動構造。本文將徹底講清 Nano Banana Pro 多輪對話出圖 API 的底層字段、Python SDK 與 REST 兩套實現,以及關鍵的 thoughtSignature 機制,幫你 3 步搭建出像網頁版一樣流暢的上下文出圖體驗。
核心價值: 讀完本文,你將掌握 contents 數組的正確構造方式、能在自己的應用裏實現「基於上一張圖繼續編輯」的多輪工作流,並避免「圖片忘記」「token 浪費」「signature 丟失」三大典型坑。

Nano Banana Pro 多輪對話出圖 核心要點
| 要點 | 說明 | 價值 |
|---|---|---|
| API 無狀態 | gemini-3-pro-image-preview 接口本身不記得任何歷史 | 多輪上下文需調用方主動維護 |
| contents 數組 | user/model 角色交替,每次請求攜帶完整歷史 | 一次請求即可讓模型「看到」過往對話 |
| 圖片回傳 | 之前生成的圖片需以 inline_data 形式塞回 contents | 模型據此進行持續編輯而非重新生成 |
| thoughtSignature | 加密的思考簽名,跨輪保留推理上下文 | 關鍵編輯指令不會被遺忘 |
| SDK 自動化 | 官方 Python SDK 的 chat 對象自動管理歷史 |
從 REST 直接遷移可省 80% 代碼 |
多輪對話出圖 與 網頁版 Agent 的本質區別
gemini.google.com 是 Google 官方搭建的 Agent 應用,它在前端幫你維護了一份完整的「對話狀態」(包含每輪的文本、生成的圖片、思考簽名),每次你輸入新消息時,這個 Agent 會把所有歷史一次性打包發送給底層模型。這就是爲什麼網頁端體驗如此流暢——所有「記憶」工作都被 Agent 包攬了。
而當你直接調用 generateContent API 時,你拿到的是「赤裸」的模型調用接口。每次 HTTP 請求都是一次獨立的推理,模型對你之前的對話毫無概念。要復現網頁版的多輪體驗,本質上就是在你的代碼裏自己實現一個 Agent——把歷史 user 消息、model 響應(含圖片和簽名)按規範填入 contents,再發起請求。
Nano Banana Pro 多輪對話出圖 字段結構詳解
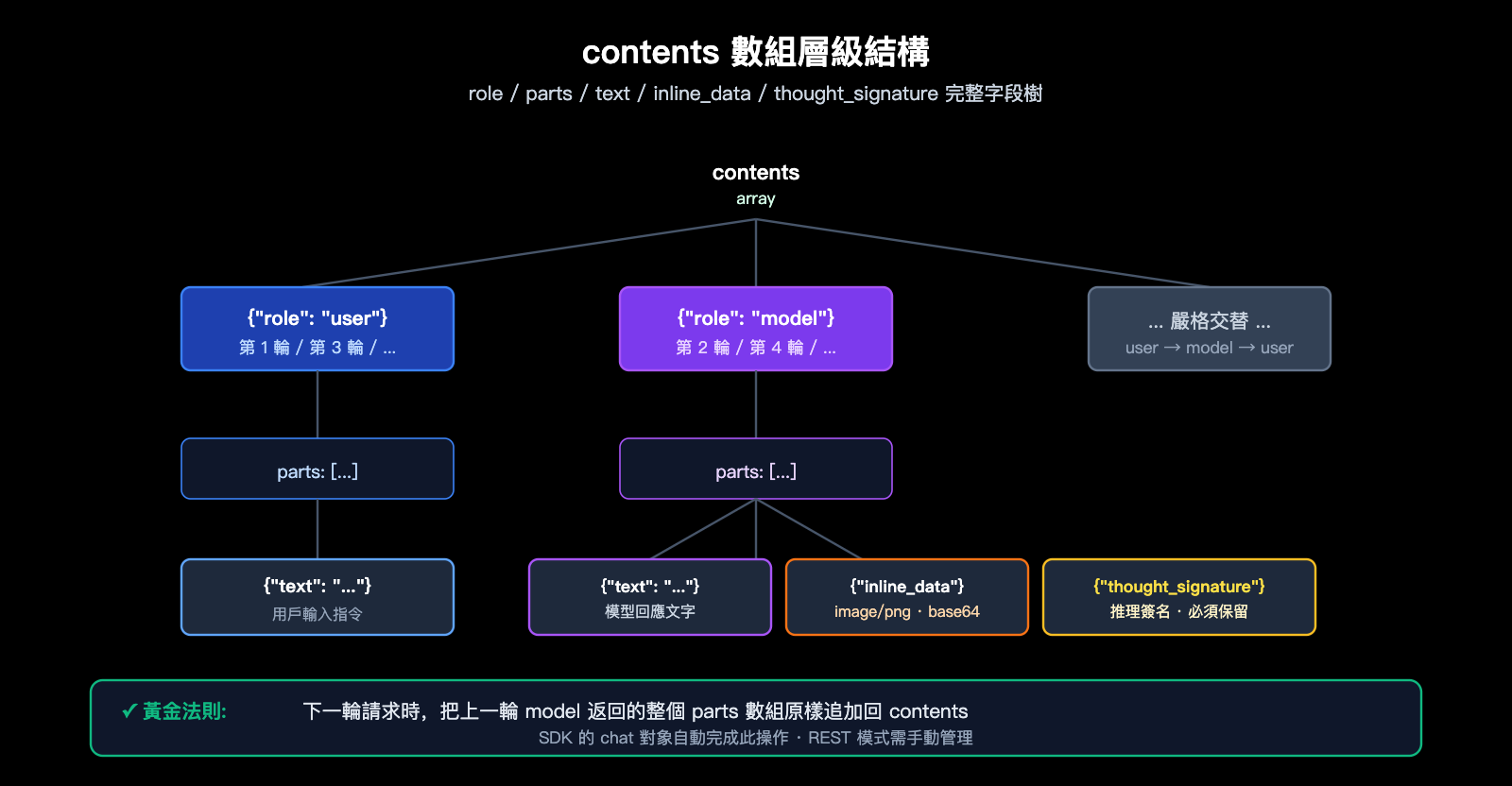
contents 數組的核心規範
contents 是 Gemini API 表達對話歷史的標準字段,它是一個 JSON 數組,每個元素代表一輪發言:
| 字段 | 類型 | 說明 |
|---|---|---|
role |
string | "user" 或 "model",必須嚴格交替 |
parts |
array | 該輪發言的內容片段,可以混合文本/圖片/簽名 |
parts[].text |
string | 文本內容,如指令或對話 |
parts[].inline_data.mime_type |
string | 圖片格式,通常爲 "image/png" |
parts[].inline_data.data |
string | 圖片的 base64 編碼數據 |
parts[].thought_signature |
string | 模型生成的加密簽名(僅在 model role 中出現) |
一個完整的兩輪對話請求體長這樣:
{
"contents": [
{"role": "user", "parts": [{"text": "生成一隻在沙灘奔跑的金毛犬"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<第一輪生成圖base64>"}},
{"thought_signature": "<加密簽名>"}
]},
{"role": "user", "parts": [{"text": "把場景改成黃昏時分"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {"aspectRatio": "16:9", "imageSize": "2K"}
}
}
圖片回傳的兩種方式
第二輪請求裏,模型必須能「看到」第一輪生成的圖片。Nano Banana Pro 支持兩種回傳姿勢:
# 方式一:inline_data 內嵌 base64(適合小圖,簡單直接)
{
"inline_data": {
"mime_type": "image/png",
"data": base64.b64encode(image_bytes).decode()
}
}
# 方式二:file_data 引用 Files API 上傳後的資源(適合大圖或複用)
{
"file_data": {
"mime_type": "image/png",
"file_uri": "files/abc123xyz"
}
}
關鍵提示:
inline_data是直接調用最常用的方式,適合一次性場景;file_data引用模式適合需要在多輪中複用同一張大圖的場景,可顯著降低請求體大小和上傳開銷。
Nano Banana Pro 多輪對話出圖 快速上手
極簡示例(Python SDK 自動管理)
如果你使用官方 Python SDK,最簡潔的寫法只需要 10 行:
from google import genai
client = genai.Client(api_key="YOUR_API_KEY")
chat = client.chats.create(model="gemini-3-pro-image-preview")
# 第一輪:生成初始圖
r1 = chat.send_message("生成一隻在沙灘奔跑的金毛犬")
# 第二輪:基於第一張圖繼續編輯(chat 對象自動攜帶歷史)
r2 = chat.send_message("把場景改成黃昏時分,加一隻飛翔的海鷗")
# 第三輪:繼續追加修改
r3 = chat.send_message("再把狗的顏色換成深棕色")
chat 對象內部維護了完整的 contents 列表(包括每輪的 thoughtSignature),開發者無需關心字段細節。每次 send_message 都會自動把歷史打包發送。
查看 OpenAI 兼容接口完整調用示例
如果你使用 API易 apiyi.com 這類 OpenAI 兼容平臺調用 Nano Banana Pro,可以直接複用 OpenAI SDK:
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 維護一個本地的 messages 列表(即 contents 概念)
messages = [
{"role": "user", "content": "生成一隻在沙灘奔跑的金毛犬"}
]
# 第一輪
response1 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
img1_url = response1.choices[0].message.content # 提取圖片URL或base64
# 把模型響應加入歷史
messages.append({"role": "assistant", "content": img1_url})
# 第二輪:追加新指令
messages.append({"role": "user", "content": "把場景改成黃昏時分"})
response2 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
# 第三輪繼續追加...
messages.append({"role": "assistant", "content": response2.choices[0].message.content})
messages.append({"role": "user", "content": "再加一隻飛翔的海鷗"})
response3 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
關鍵點:在 OpenAI 兼容模式下,messages 數組等同於原生 contents,role 字段從 "model" 改爲 "assistant",平臺層會自動轉換。
建議: 對於多輪編輯場景,推薦使用 SDK 的
chat對象或維護本地 messages 列表,避免每次手動拼接 contents。可在 API易 apiyi.com 註冊免費額度,先用 SDK 跑通再考慮 REST 優化。
Nano Banana Pro 多輪對話出圖 REST 手動構造
不依賴 SDK 的純 REST 實現
某些場景(例如服務端中轉、ComfyUI 節點、低代碼平臺)無法使用官方 SDK,需要直接構造 REST 請求。以下是完整的 curl 調用:
# 第一輪:純文本指令生成圖
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "生成一隻在沙灘奔跑的金毛犬"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
# 響應中會有: parts[0].inline_data.data (base64圖片)
# 以及 parts[0].thought_signature
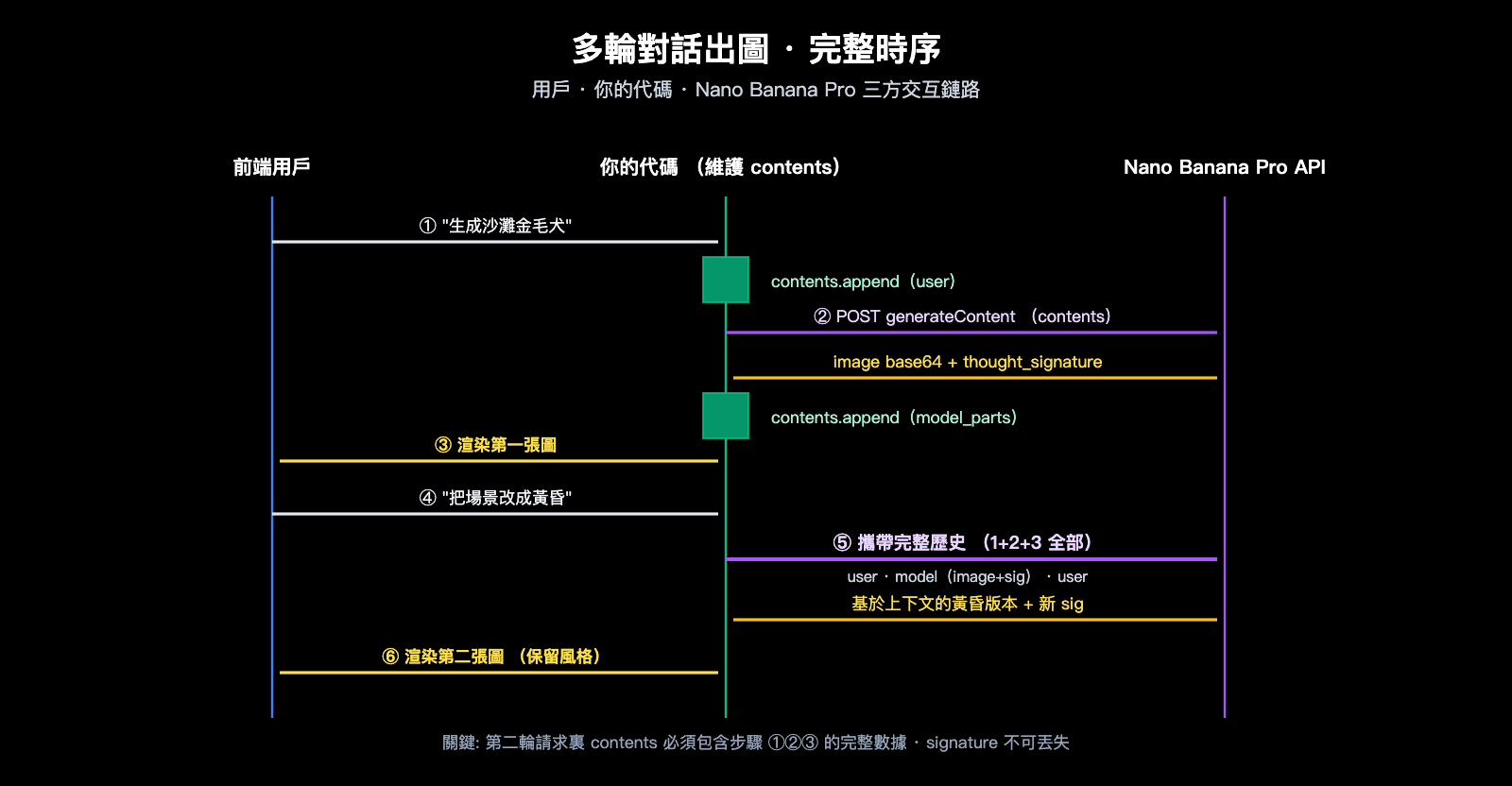
第二輪請求時,必須把第一輪的整個 model 響應(包括圖片和簽名)原樣塞回 contents:
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "生成一隻在沙灘奔跑的金毛犬"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<第一輪返回的base64>"}},
{"thought_signature": "<第一輪返回的signature>"}
]},
{"role": "user", "parts": [{"text": "把場景改成黃昏時分"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
三種調用模式對比
| 調用方式 | 歷史管理 | 適合場景 | 學習成本 |
|---|---|---|---|
官方 Python SDK (chat 對象) |
自動 | 後端服務、Notebook 實驗 | ⭐ 最低 |
| OpenAI 兼容接口 (messages 數組) | 半自動 | 已有 OpenAI 項目遷移 | ⭐⭐ 較低 |
| 原生 REST (contents 數組) | 完全手動 | ComfyUI、低代碼、跨語言 | ⭐⭐⭐ 中等 |

數據說明: 上圖展示了 Agent 自動管理 vs API 手動管理的核心差異,可通過 API易 apiyi.com 平臺直接對比兩種調用方式的實際表現差異。
Nano Banana Pro 多輪對話出圖 thoughtSignature 機制
什麼是 thoughtSignature
thoughtSignature 是 Gemini 3 系列引入的「加密思考簽名」。它是模型對自己內部推理狀態的一個緊湊編碼,肉眼不可讀,但模型在下一輪可以用它快速恢復上下文。具體作用:
- 保留細節決策: 例如第一輪裏模型「決定」用淺色調,第二輪通過簽名繼承這個風格
- 提升一致性: 角色、場景、構圖在多輪編輯中保持穩定
- 節省 token: 避免在 prompt 裏反覆重申「保持原風格」
何時必須攜帶 signature
| 場景 | 是否必須攜帶 signature |
|---|---|
| 單輪獨立請求(一次性出圖) | ❌ 不需要 |
| 多輪編輯(基於上一張圖修改) | ✅ 必須 |
| 跨會話恢復歷史 | ✅ 必須(需自行持久化) |
| 僅文本對話(無圖片) | ✅ 必須,用於推理連續性 |
實戰:手動管理 signature 的代碼模式
import requests
import base64
import json
API_BASE = "https://vip.apiyi.com/v1beta"
MODEL = "gemini-3-pro-image-preview"
HEADERS = {
"x-goog-api-key": "YOUR_API_KEY",
"Content-Type": "application/json"
}
class NanoBananaChat:
"""手動維護 contents + signature 的極簡 chat 客戶端"""
def __init__(self):
self.contents = []
def send(self, text: str, attach_image_b64: str = None) -> dict:
# 構造本輪 user message
user_parts = [{"text": text}]
if attach_image_b64:
user_parts.append({
"inline_data": {"mime_type": "image/png", "data": attach_image_b64}
})
self.contents.append({"role": "user", "parts": user_parts})
# 發起請求
resp = requests.post(
f"{API_BASE}/models/{MODEL}:generateContent",
headers=HEADERS,
json={
"contents": self.contents,
"generationConfig": {"responseModalities": ["TEXT", "IMAGE"]}
}
).json()
# 把 model 響應(含 signature)原樣追加回 contents
model_parts = resp["candidates"][0]["content"]["parts"]
self.contents.append({"role": "model", "parts": model_parts})
return model_parts
# 使用示例
chat = NanoBananaChat()
parts1 = chat.send("生成一隻在沙灘奔跑的金毛犬")
parts2 = chat.send("把場景改成黃昏時分") # 自動攜帶歷史和signature
parts3 = chat.send("再加一隻飛翔的海鷗")
優化建議: 通過 API易 apiyi.com 接入時,平臺層會原樣透傳 thought_signature 字段,開發者只需保證「把整個 model parts 數組追加回 contents」即可,無需關心簽名的具體內容。
Nano Banana Pro 多輪對話出圖 實戰場景
場景 1:漸進式品牌圖設計
營銷團隊常見需求:基於一張產品概念圖,逐步調整文案、配色、排版。多輪對話出圖 API 的優勢在於每次只需描述「增量變化」,不必從頭描述整張圖:
chat = client.chats.create(model="gemini-3-pro-image-preview")
chat.send_message("設計一張深藍漸變背景的咖啡品牌海報,左側放產品圖")
chat.send_message("把標題文案改成「Awaken Your Morning」")
chat.send_message("右下角加一個二維碼佔位")
chat.send_message("整體風格再現代一點,去掉裝飾花邊")
場景 2:基於參考圖的多輪編輯
Nano Banana Pro 支持單次最多 14 張參考圖。結合多輪對話,可以構建強大的圖像融合工作流:
# 上傳一張人像 + 一張服裝參考圖
chat.send_message([
"把第一張圖的人物穿上第二張圖裏的服裝",
{"inline_data": {"mime_type": "image/png", "data": person_b64}},
{"inline_data": {"mime_type": "image/png", "data": outfit_b64}}
])
# 後續微調
chat.send_message("把領口改成 V 字領")
chat.send_message("背景換成簡潔的灰色")
場景 3:跨會話恢復歷史
如果用戶在前端關閉頁面後重新打開,希望繼續上次對話,需要把 contents 數組持久化到數據庫:
import json
# 保存
with open(f"sessions/{user_id}.json", "w") as f:
json.dump(chat.get_history(), f)
# 恢復
with open(f"sessions/{user_id}.json") as f:
history = json.load(f)
restored_chat = client.chats.create(
model="gemini-3-pro-image-preview",
history=history
)
restored_chat.send_message("繼續上次的,把背景再亮一點")
上下文窗口限制
| 資源 | 限制 |
|---|---|
| 輸入上下文 | 64K tokens |
| 輸出上下文 | 32K tokens |
| 單請求最大參考圖數量 | 14 張 |
| 推薦歷史輪數 | 不超過 8-10 輪 |
| 單圖最大分辨率 | 2K (默認 1K) |
場景建議: 當對話超過 8-10 輪時,建議主動「截斷」前面的歷史或用 LLM 摘要替代,否則 token 會快速逼近 64K 上限。生產環境務必加入 token 計數器,提前在客戶端做截斷決策。
常見問題
Q1: 我直接調 API 沒有上下文,要怎麼實現網頁版那種連續對話?
API 是無狀態的,必須由你的代碼維護一份本地的 contents 數組(或 SDK 裏的 chat 對象)。每次請求把完整歷史(包括用戶文本、模型生成的圖片、thought_signature)一起發回去,模型纔會「記得」之前的對話。最簡單的方式是用官方 Python SDK 的 client.chats.create(),由 SDK 自動管理。
Q2: 上一輪生成的圖片,下一輪要傳什麼字段?
要把圖片以 inline_data 的形式(base64 編碼 + mime_type)放入「上一輪 model 角色」的 parts 數組中。同時務必把模型返回的 thought_signature 也一併帶回。如果使用 API易 apiyi.com 等 OpenAI 兼容接口,平臺會自動處理這些字段映射,開發者只需維護標準的 messages 列表。
Q3: thoughtSignature 必須傳嗎?不傳會怎樣?
強烈建議傳。不傳的話,模型在多輪編輯時可能「忘記」上一輪的關鍵決策(如風格、配色、構圖),導致每次都像在重新生成。官方文檔明確指出多輪場景下 signature 必須保留。SDK 會自動處理,REST 模式下需要手動把 model parts 完整追加回 contents。
Q4: 歷史太長了怎麼辦?token 超 64K 會報錯嗎?
會的,超過 64K 輸入 token 會被拒絕。常見優化策略:
- 截斷: 只保留最近 4-6 輪歷史
- 圖片下采樣: 歷史圖片傳 1K 而不是 2K 分辨率
- 摘要替代: 用 LLM 把前幾輪壓縮成一段文字描述
- 分段會話: 當對話主題切換時主動開新會話
Q5: 如何快速測試 Nano Banana Pro 多輪出圖效果?
推薦使用 API易 apiyi.com 這類支持 Gemini 模型的聚合平臺快速驗證:
- 註冊賬號獲取 API Key 和免費額度
- 選擇
gemini-3-pro-image-preview模型 - 用本文的 Python SDK 示例代碼連續發起 3-5 輪編輯
- 對比每輪輸出的連貫性,判斷是否符合業務需求
總結
Nano Banana Pro 多輪對話出圖 API 的核心要點:
- 無狀態本質: API 不記憶任何歷史,必須由調用方維護
contents數組 - 角色交替: user 與 model 嚴格交替,每輪 parts 可混合 text/image/signature
- 圖片回傳: 上一輪生成的圖必須以
inline_data形式塞回,否則模型「看不到」 - 簽名機制: thought_signature 是多輪一致性的關鍵,REST 模式下必須手動攜帶
- SDK 簡化: 官方 Python SDK 的
chat對象可自動管理上述所有細節
對於希望快速實現網頁版體驗的開發者,最佳路徑是使用官方 SDK 的 chat 對象或 OpenAI 兼容接口的 messages 模式,避免手動構造 REST 帶來的複雜度。
推薦通過 API易 apiyi.com 接入 Nano Banana Pro 多輪對話出圖能力,平臺支持原生 Gemini 字段與 OpenAI 兼容雙模式調用,提供免費測試額度,便於快速驗證多輪編輯效果並平滑遷移現有項目。
📚 參考資料
-
Gemini API 圖像生成官方文檔: 多輪對話出圖的權威說明
- 鏈接:
ai.google.dev/gemini-api/docs/image-generation - 說明: 包含 contents 字段規範、Python SDK 與 REST 完整示例
- 鏈接:
-
Gemini 3 Pro Image Preview 模型卡: 模型能力與限制說明
- 鏈接:
ai.google.dev/gemini-api/docs/models/gemini-3-pro-image-preview - 說明: 上下文窗口、分辨率、參考圖數量等關鍵參數
- 鏈接:
-
Google AI Developers Forum – Multi-turn Nano Banana: 社區實戰示例
- 鏈接:
discuss.ai.google.dev/t/multi-turn-nano-banana-example - 說明: 真實開發者討論的多輪對話最佳實踐
- 鏈接:
-
Vertex AI Gemini 3 Pro Image 文檔: 企業級部署參考
- 鏈接:
docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/3-pro-image - 說明: 包含 thought_signature 與 file_data 引用的高級用法
- 鏈接:
-
API易 Nano Banana Pro 接入文檔: 國內開發者快速上手
- 鏈接:
help.apiyi.com - 說明: 包含 OpenAI 兼容接口、原生 Gemini 接口雙模式示例
- 鏈接:
作者: APIYI 技術團隊
技術交流: 歡迎在評論區分享你在多輪對話出圖中遇到的實戰問題,更多 Nano Banana Pro 配置技巧可訪問 API易 docs.apiyi.com 文檔中心