Muita gente, ao usar a versão web do ChatGPT pela primeira vez, tem uma impressão equivocada: você envia um PDF ou uma frase e ele "num estalar de dedos" gera 5 imagens com um estilo consistente. Mas, ao mudar para a API e ajustar o parâmetro n para 5, o que você recebe são 5 variações aleatórias, quase idênticas, como se estivesse tirando a sorte em um jogo de cartas. Por que o mesmo modelo apresenta resultados tão diferentes?
Este artigo não pretende dar uma resposta única, mas sim dissecar esse problema que enfrentamos constantemente no suporte ao cliente. Vamos explicar as duas rotas técnicas completamente distintas por trás da geração de imagens em grupo do GPT, esclarecer por que o parâmetro n não consegue criar "grupos de imagens" de verdade e quais métodos práticos você pode usar se quiser implementar consistência entre múltiplas imagens via API.
I. Duas rotas técnicas para a geração de imagens em grupo do GPT
Para entender isso, primeiro precisamos admitir uma premissa frequentemente ignorada: "gerar várias imagens de uma vez" e "gerar um grupo de imagens com relações lógicas" são coisas diferentes. A primeira é apenas uma questão de volume, enquanto a segunda é o que realmente chamamos de "grupo de imagens".
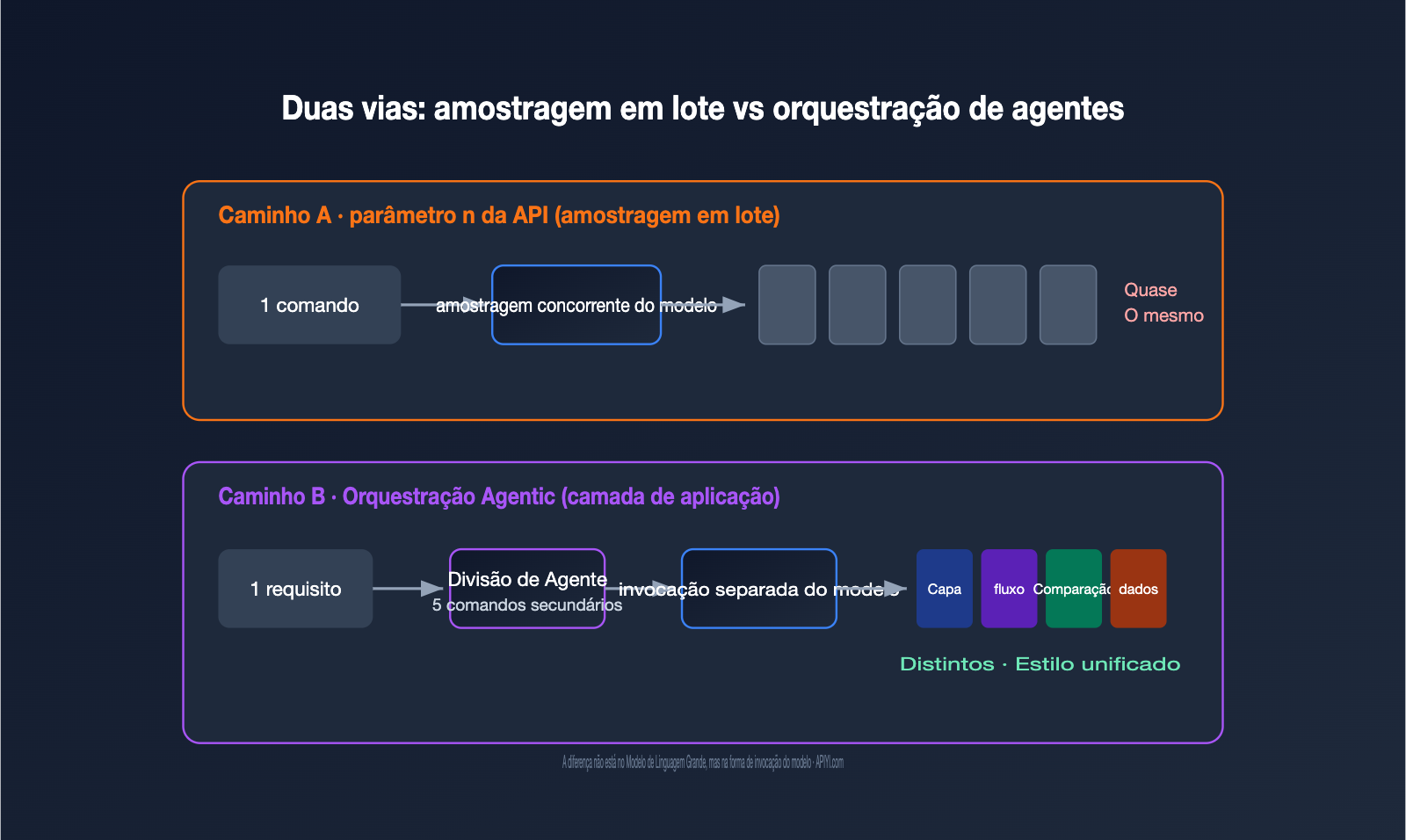
Na implementação de engenharia, o GPT Image segue dois caminhos. O primeiro é a amostragem em lote na camada do modelo, que é o parâmetro n na API: usando o mesmo comando e a mesma entrada, o modelo gera vários resultados em paralelo. O segundo é a orquestração por agentes na camada de aplicação, onde um agente entende a necessidade, divide-a em várias subtarefas, chama a capacidade de geração de imagens separadamente e, finalmente, compõe o grupo.
A tabela abaixo resume as principais diferenças entre as duas rotas, que detalharemos nas seções seguintes.
| Dimensão | Parâmetro n da API (Amostragem em lote) | Orquestração por Agentes (Camada de aplicação) |
|---|---|---|
| Essência | Amostragem aleatória repetida do mesmo comando | Geração independente múltipla após dividir a demanda |
| Conteúdo de cada imagem | Quase idêntico, apenas variações aleatórias | Diferentes entre si, mas com tema relacionado |
| Entende o "grupo"? | Não, apenas concorrência | Sim, possui lógica de planejamento |
| Custo | Preço por imagem × N | Acúmulo de custos por chamadas múltiplas |
| Fonte de consistência | Comando e semente aleatória | Imagem de referência + restrições de comando unificadas |
| Cenário típico | Selecionar uma imagem satisfatória | Ilustrações em série, imagens para PPT, livros ilustrados |
Em resumo, o parâmetro n resolve a necessidade de "me dê algumas opções", enquanto um grupo de imagens exige "me dê uma série de conteúdos seguindo um tema". É por isso que, ao tentar replicar a experiência da versão web diretamente via API, parece que falta algo. Se você quiser validar o desempenho real dessas duas rotas, pode testar com a mesma chave API no APIYI (apiyi.com), economizando o custo de alternar entre várias plataformas.
二、 Por que o parâmetro n da API não cria um conjunto de imagens real
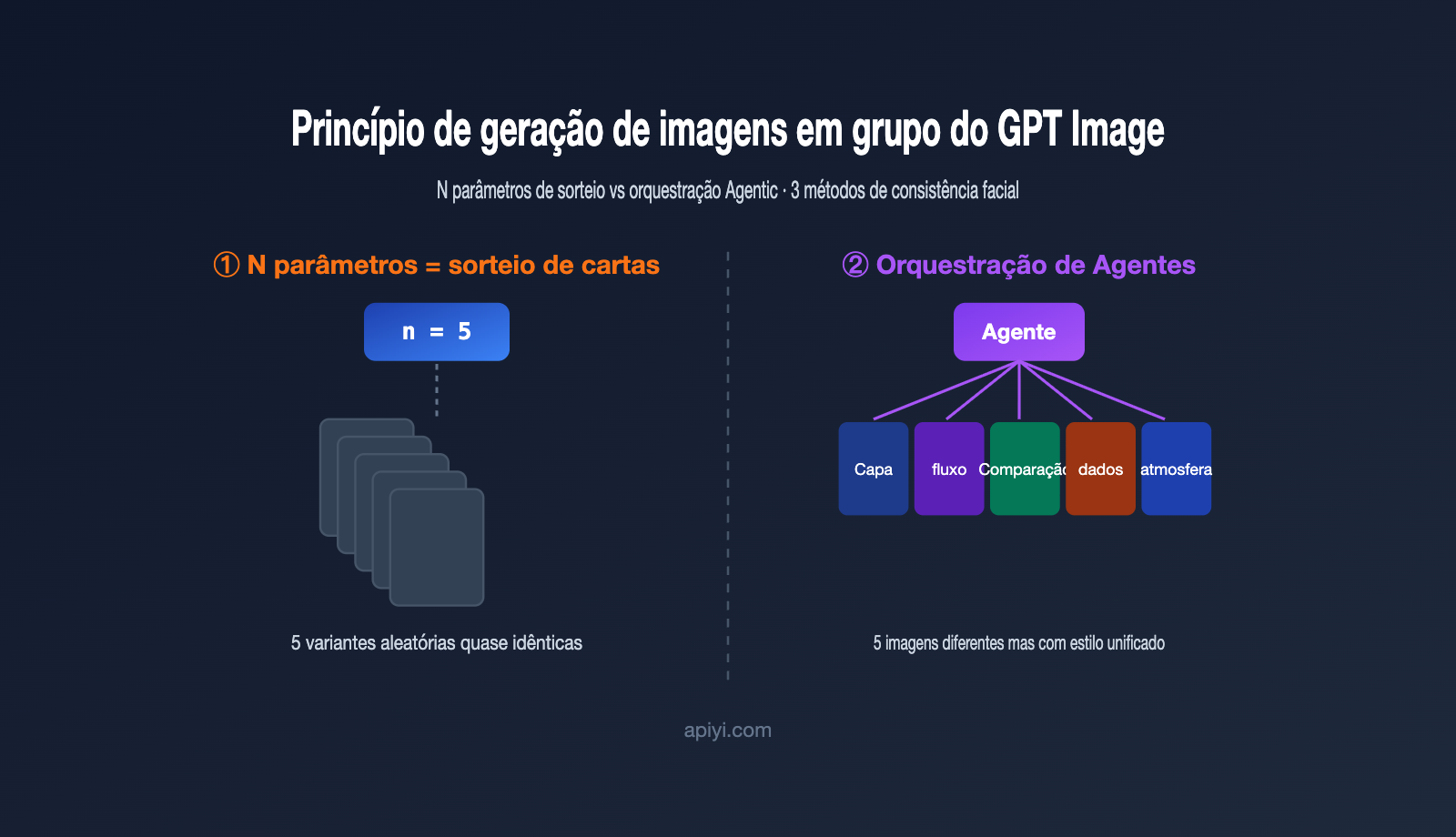
A primeira reação de muitos desenvolvedores é: se eu preciso de 5 imagens, não basta definir n como 5? Ao testar, você logo percebe que as 5 imagens geradas geralmente são "5 pequenas variações da mesma coisa", e não "um conjunto de imagens que se complementam".
O motivo está no mecanismo de funcionamento do parâmetro n. Ele não altera o seu comando; ele simplesmente executa o mesmo comando várias vezes, contando com a amostragem aleatória do processo de geração do modelo para criar diferenças. Na comunidade de desenvolvedores da OpenAI, há uma descrição muito precisa: essas imagens são "variações geradas por amostragem aleatória sob a mesma entrada" (random sampling variations). Em outras palavras, é como um sorteio — no mesmo conjunto de cartas, você sorteia 5 vezes; as cartas são parecidas, mas a raridade é aleatória.
Isso traz duas consequências diretas. Primeiro, você não consegue expressar necessidades estruturadas em uma única chamada, como "a primeira imagem é a capa, a segunda é o fluxo, a terceira é a comparação", porque existe apenas um comando. Segundo, o custo é somado linearmente: n=5 é cobrado como 5 imagens, sem qualquer desconto por pacote.
A tabela abaixo ilustra essa diferença em um cenário real, supondo que você queira gerar 5 imagens para diferentes usos em um artigo.
| Necessidade | Resultado com n=5 | O que você realmente quer |
|---|---|---|
| Imagem de capa | 5 candidatos a capa | 1 capa |
| Fluxograma | Não obtido | 1 fluxograma |
| Imagem de comparação | Não obtido | 1 imagem de comparação |
| Gráfico de dados | Não obtido | 1 gráfico de dados |
| Imagem de ambientação | Não obtido | 1 imagem de atmosfera |
A conclusão é clara: o parâmetro n é ideal para "quero uma boa imagem, me dê várias opções para escolher", mas não serve para "quero um conjunto de imagens com conteúdos diferentes". Entendendo isso, você não vai mais se perguntar "por que a API não consegue o mesmo resultado da versão web" — é porque você estava usando a ferramenta errada. Se quiser testar o comportamento de "sorteio" do parâmetro n com baixo custo, a APIYI (apiyi.com) oferece cobrança por uso, permitindo rodar vários experimentos comparativos sem gastar muito.
三、 O princípio da orquestração Agentic por trás das imagens em conjunto na versão web
Então, como a versão web do ChatGPT consegue "gerar 5 imagens a partir de um PDF"? A resposta é o segundo caminho mencionado acima — a orquestração Agentic, que é justamente a atualização chave trazida pelo GPT Image 2 / ChatGPT Images 2.0, lançado em abril de 2026.
Segundo o posicionamento oficial da OpenAI, o GPT Image 2 é a primeira versão a incorporar "capacidade de raciocínio" ao modelo de imagem: antes de começar a desenhar, ele pesquisa, planeja e raciocina sobre a estrutura da imagem (proactively researches, plans, and reasons). Esse mecanismo é chamado de modo Thinking na interface web. Portanto, quando você envia um PDF, o modelo não apenas "lê a imagem", mas primeiro entende sobre o que é o documento, quantas imagens são necessárias, qual o papel de cada uma e, então, gera uma por uma.
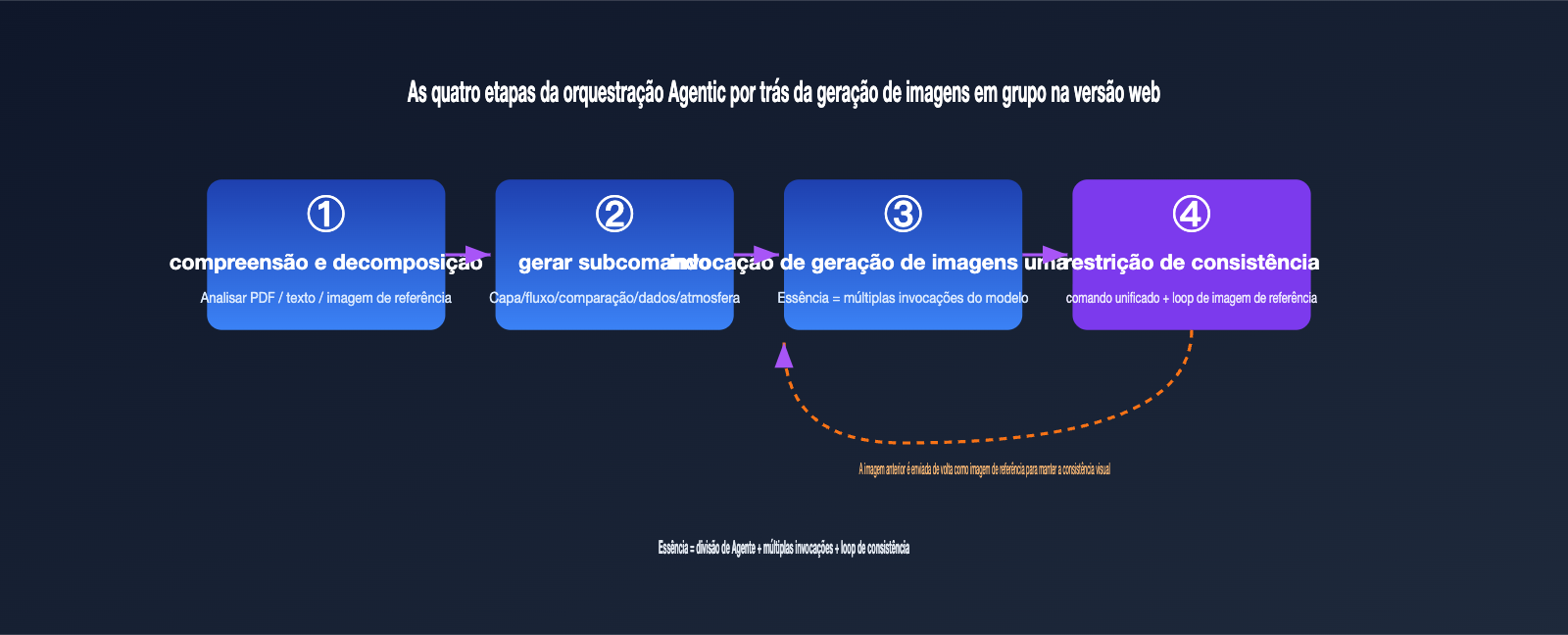
Traduzindo esse processo para a linguagem de engenharia, temos basicamente quatro etapas:
- Compreensão e decomposição: O agente analisa a entrada (texto, PDF, imagem de referência), determina quantas imagens são necessárias e o tema de cada uma.
- Geração de subcomandos: Escreve um comando independente para cada imagem, como "diagrama de arquitetura geral", "fluxograma crítico", "gráfico de comparação de dados".
- Invocação individual para geração: Chama a capacidade de geração de imagem para cada subcomando, o que, na essência, são múltiplas invocações de API.
- Restrição de consistência: Insere uma descrição de estilo unificada em cada comando e passa a imagem gerada anteriormente como imagem de referência para a próxima, garantindo a unidade visual do conjunto.
O meio acadêmico também utiliza abordagens semelhantes. Frameworks multiagentes (como o ViMax na geração de vídeo ou o Maestro na geração de texto para imagem) dividem uma grande demanda em subproblemas visuais mais granulares, gerando em paralelo, selecionando os melhores resultados e usando o quadro ou imagem anterior como referência para as próximas, mantendo assim a coerência de personagens e cenários. O diferencial do GPT Image 2 é ter incorporado essa orquestração, que antes precisava ser montada manualmente pelos engenheiros, dentro do próprio ciclo de raciocínio do modelo.
Aqui também reside o verdadeiro desafio: múltiplas invocações independentes naturalmente geram desvio. Cada imagem é uma nova amostragem aleatória, e a aparência do personagem, a paleta de cores e o estilo artístico podem acabar se perdendo. Esse é o problema central que discutimos com os clientes — "como manter a consistência visual", algo muito mais difícil do que "como gerar várias imagens". A próxima seção tratará especificamente de como lidar com isso.
四、Usando a API para replicar conjuntos de imagens: 3 métodos para implementar consistência entre múltiplas imagens
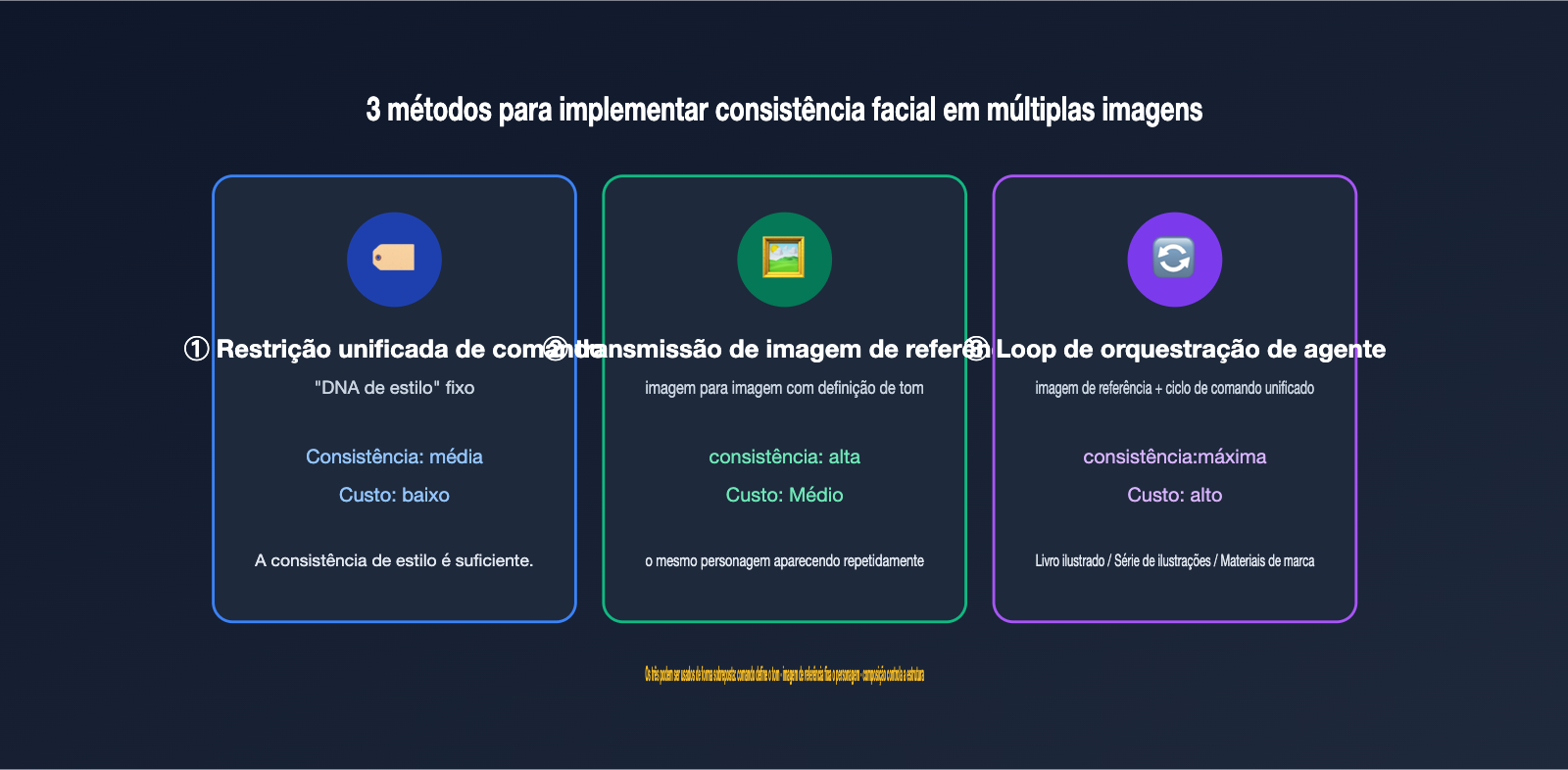
Se você não quer depender da versão web e deseja implementar a geração de conjuntos de imagens com GPT Image em seu próprio produto, precisará construir sua própria lógica de orquestração. O segredo é usar recursos de engenharia para recuperar a "consistência visual". Com base na prática, resumimos três métodos, do mais simples ao mais avançado, que podem ser combinados.
Método 1: Restrição de comando unificada (tabela de descrição de personagens). A abordagem de menor custo é escrever um "DNA de estilo" fixo para todo o conjunto de imagens e anexá-lo ao comando em cada invocação. Por exemplo: "adote um estilo de ilustração plana, cores principais azul escuro e âmbar, personagem é uma engenheira de cabelo curto". Na comunidade, essa descrição fixa é chamada de character bible (bíblia de personagens); quanto mais específica a descrição, maior a consistência entre as imagens.
Método 2: Passagem de imagem de referência (imagem para imagem). Use a primeira imagem que você gerou e que ficou satisfatória como imagem de referência para cada uma das invocações subsequentes. O GPT Image 2 pode aceitar várias imagens de referência em cenários de edição/referência (a documentação oficial indica até 16 imagens, mas verifique o limite real na plataforma). Isso torna o "definir o tom pela imagem" o principal meio de consistência. O resultado geralmente é mais estável do que apenas descrições em texto, especialmente para detalhes como as feições do personagem.
Método 3: Orquestração de Agente + Loop de imagem de referência. Combine os dois primeiros métodos em um ciclo: primeiro, gere a imagem base como referência; depois, gere cada imagem subsequente levando a imagem base + o comando unificado, e, se necessário, use a imagem anterior como referência adicional. É exatamente isso que o modo Thinking da versão web faz, só que você estará escrevendo isso explicitamente no seu código.
Abaixo está um exemplo simplificado de orquestração que demonstra a lógica básica de "gerar a imagem base primeiro e, em seguida, gerar uma série de imagens usando a imagem de referência".
from openai import OpenAI
# base_url aponta para a APIYI, gerenciando chaves de múltiplos modelos de forma unificada
client = OpenAI(base_url="https://api.apiyi.com/v1", api_key="SUA_CHAVE")
STYLE = "estilo de ilustração plana, cores principais azul escuro e âmbar, personagem é uma engenheira de cabelo curto" # Tabela de descrição de personagens
shots = ["Capa: personagem em frente ao data center", "Fluxo: personagem desenhando arquitetura no quadro branco", "Resumo: personagem fazendo sinal de positivo"]
# 1. Gere a imagem base primeiro para fixar o estilo de todo o conjunto
base = client.images.generate(model="gpt-image-2", prompt=f"{shots[0]},{STYLE}")
# 2. Cada imagem subsequente leva a restrição de estilo unificada (avançado: pode adicionar a base como imagem de referência na interface edits)
for shot in shots[1:]:
img = client.images.generate(model="gpt-image-2", prompt=f"{shot},{STYLE}")
# save(img) ...
Para ajudar na sua escolha, a tabela abaixo compara as características e cenários de aplicação dos três métodos.
| Método | Nível de consistência | Custo de implementação | Cenário de aplicação |
|---|---|---|---|
| Restrição de comando unificada | Médio | Baixo | Estilo consistente é suficiente, personagem não precisa ser rigoroso |
| Passagem de imagem de referência | Alto | Médio | Mesmo personagem/produto aparecendo repetidamente |
| Loop de orquestração de Agente | Altíssimo | Alto | Livros ilustrados, séries de ilustrações, materiais de marca |
Os três métodos podem ser combinados: use o comando para definir o tom, a imagem de referência para fixar o personagem e a orquestração para controlar a estrutura. Recomendamos começar com "comando unificado + imagem de referência" e, após validar, implementar a orquestração completa. Na APIYI apiyi.com, modelos como gpt-image-2 e gpt-image-1.5 compartilham o mesmo base_url e chave API, facilitando a alternância entre modelos para testes de consistência sem precisar alterar o código.
五、Custo e seleção de modelo para geração de conjuntos de imagens com GPT Image
Conjuntos de imagens significam múltiplas invocações, o que aumenta o custo, por isso escolher o modelo certo é fundamental. Atualmente, existem várias categorias da série GPT Image usadas em ambientes de produção, cada uma com seu foco.
| Modelo | Posicionamento | Suporta orquestração de inferência | Cenário de conjunto de imagens adequado |
|---|---|---|---|
| gpt-image-2 | Flagship, inferência integrada | Sim (Thinking) | Materiais de série de alta qualidade, pôsteres com texto |
| gpt-image-1.5 | Flagship da geração anterior | Parcial | Geração em lote com equilíbrio entre qualidade e custo |
| gpt-image-1 | Clássico e estável | Não | Imagens de acompanhamento comuns com estilo simples |
| gpt-image-1-mini | Leve e de baixo custo | Não | Grandes volumes, sem exigência alta de qualidade |
É preciso ter consciência sobre os custos: conjuntos de imagens são cobrados "por contagem de imagens". Tomando 1024×1024 como exemplo, o preço por unidade varia de alguns milésimos de dólar a mais de dois milésimos (consulte as cotações em tempo real da plataforma). Um conjunto de 5 imagens custa o valor de 5 imagens. Se você pretende produzir milhares de imagens em lote, o custo será considerável, então fazer uma estimativa antecipada é essencial.
Nossa sugestão é: use o modelo mini ou de baixa qualidade na fase de rascunho para validar rapidamente a composição e a consistência, e use o gpt-image-2 para a versão final de alta qualidade. Essa combinação de "tentativa e erro de baixo custo + finalização de alta qualidade" pode reduzir a fatura mantendo a qualidade. A APIYI apiyi.com oferece um painel de uso unificado, onde é possível ver claramente quanto foi gasto na geração de conjuntos e qual modelo foi utilizado, sendo ideal para equipes que precisam controlar custos.
VI. Perguntas Frequentes (FAQ)
Q1: A API realmente consegue gerar um conjunto de imagens diferentes de uma só vez?
Não, o parâmetro n não serve para isso. O n é apenas uma amostragem aleatória (como um "gacha") para o mesmo comando, resultando em conteúdos quase idênticos. A verdadeira geração de conjuntos de imagens deve ser feita através da orquestração na camada de aplicação: dividir a demanda, realizar múltiplas invocações e aplicar restrições de consistência.
Q2: Que tipo de "tecnologia secreta" a versão web do ChatGPT usa para gerar conjuntos de imagens?
Não é tecnologia secreta, é o GPT Image 2 que tem o raciocínio de agente integrado. Antes de gerar, ele planeja "quantas imagens são necessárias e o que cada uma deve conter" e, em seguida, gera uma por uma. Essencialmente, ainda são múltiplas invocações, mas o processo de planejamento é transparente para o usuário.
Q3: Qual é a maneira mais eficaz de garantir a consistência entre várias imagens?
Na prática, a passagem de uma imagem de referência é o método mais estável: use a primeira imagem satisfatória como referência para cada invocação subsequente; a fidelidade do personagem e da paleta de cores será significativamente maior do que com descrições apenas em texto. Adicionar um bloco fixo de descrição de estilo também melhora o resultado. Você pode testar isso diretamente na APIYI (apiyi.com) usando a interface de imagem de referência do gpt-image-2.
Q4: A geração de conjuntos de imagens é muito cara?
Depende do número de imagens, da resolução e do nível de qualidade, pois o custo é acumulado por imagem. Recomendamos usar modelos leves para rascunhos, modelos de ponta para a versão final e monitorar os gastos através do painel de uso da plataforma.
Q5: Qual modelo é o mais econômico para gerar conjuntos de imagens?
Para qualidade e renderização de texto, escolha o gpt-image-2; para equilibrar o custo, escolha o gpt-image-1.5; para grandes volumes com requisitos menores, o gpt-image-1-mini é suficiente. Ao usar uma interface unificada, a troca de modelos tem custo quase zero.
VII. Conclusão
Voltando à pergunta inicial: com o mesmo modelo, por que a API parece um sorteio e a versão web consegue gerar conjuntos de imagens? A diferença não está no modelo, mas no método de invocação. O parâmetro n é uma amostragem em lote na camada do modelo, resolvendo a necessidade de "dar algumas opções extras"; a verdadeira geração de conjuntos de imagens GPT Image é uma orquestração de agente na camada de aplicação, construída através da divisão de demandas, múltiplas invocações e restrições de consistência.
Dentre esses pontos, a consistência entre várias imagens continua sendo a parte mais difícil. Felizmente, temos três ferramentas úteis: uma tabela de descrição de personagem unificada para definir o tom, a passagem de imagem de referência para travar o personagem e o loop de orquestração de agente para controlar a estrutura. A combinação desses três elementos permite chegar bem perto da experiência da versão web. O valor do GPT Image 2 reside justamente em incorporar essa capacidade de orquestração no ciclo de inferência do modelo, permitindo que usuários comuns também possam aproveitá-la.
Este tópico pode não ter uma resposta padrão, sendo mais um compartilhamento de experiências — esperamos que isso ajude você a evitar alguns caminhos tortuosos. Se você quiser testar cada um dos métodos mencionados, a APIYI (apiyi.com) oferece uma interface unificada e um painel de uso para modelos como gpt-image-2 e gpt-image-1.5, sendo um ponto de partida conveniente para experimentos de geração de conjuntos e comparação de custos. Para mais detalhes de integração, consulte a central de ajuda em help.apiyi.com.
Este artigo é um conteúdo de discussão organizado pela equipe técnica da APIYI com base em práticas de suporte ao cliente. As especificações e preços dos modelos devem ser baseados nas informações oficiais e em tempo real da plataforma.