多くの人が初めてChatGPTのWeb版を使うときに、ある錯覚を抱きます:PDFを1つ入力するか、あるいは一言指示するだけで、それが「パッ」と5枚のスタイル統一された挿絵を吐き出してくれるというものです。しかし、いざAPIに切り替えてnを5に設定すると、得られるのは5枚の大同小異で、ガチャを引いたようなランダムなバリエーションです。同じモデルなのに、なぜこんなに差が出るのでしょうか?
この記事では標準的な答えを提供するのではなく、私たちがカスタマーサポートで繰り返し遭遇したこの問題を分解してお話しします。GPT Imageの組図生成の背後にある2つの全く異なる技術パスを明確にし、なぜnパラメータでは真の「組図」が作れないのかを説明します。さらに、APIを使って自分で多画像の一貫性を実現したい場合に、実際に使える方法についてもご紹介します。

一、GPT Image 組図生成の2つの技術パス
このことを理解するには、まず見落とされがちな前提を認める必要があります:「一度に複数の画像を生成する」ことと、「論理的な関係性を持つ一組の画像を生成する」ことは別物だということです。前者は単なる数量上のバッチ処理であり、後者が皆さんが口にする真の「組図」です。
GPT Imageのエンジニアリング実装には、2つのパスが対応しています。1つ目はモデルレイヤーでのバッチサンプリング、つまりAPIのnパラメータです:同じプロンプト、同じ入力に対して、モデルが並列に複数の結果をサンプリングします。2つ目はアプリケーションレイヤーでのAgenticオーケストレーションで、1つのエージェント(インテリジェントエージェント)がまず要求を理解し、それをいくつかのサブタスクに分解し、それぞれ画像生成能力を呼び出して、最後に一組にまとめます。
以下の表では、まず2つのパスの核心的な違いを明確にし、後の節で各項目を詳しく説明していきます。
| 次元 | APIのnパラメータ(バッチサンプリング) | Agenticオーケストレーション(アプリケーションレイヤー) |
|---|---|---|
| 本質 | 同一プロンプトのランダムサンプリング繰り返し | 要求を分解して複数回独立生成 |
| 各画像の内容 | ほぼ同じ、ランダムな差異のみ | それぞれ異なるが、テーマに関連 |
| 「組」を理解するか | 理解しない、純粋な並行処理 | 理解する、計画的な論理あり |
| 費用 | 単価 × N | 複数回呼び出し費用の累計 |
| 一貫性の源 | プロンプトとランダムシード | 参照画像 + 統一されたプロンプト制約 |
| 典型的なシナリオ | 満足のいく1枚を選ぶための大量候補 | シリーズイラスト、PPT挿絵、絵本 |
簡単に言えば、nパラメータは「もっと候補をいくつかください」という問題を解決し、組図が必要とするのは「一つのテーマに沿って一連の内容をください」ということです。これが、直接APIを呼び出してWeb版の体験を再現しようとすると、何か物足りなさを感じる理由でもあります。もしこの2つのパスの実際の挙動を同時に検証したい場合は、APIYI apiyi.comで同一のキーを使ってそれぞれテストすることができ、複数プラットフォームを行き来するコストを省けます。

二、APIのnパラメータで真の組図が作れない理由
多くの開発者が最初に考えるのは、「5枚の画像が必要なら、nを5に設定すればいいのでは?」ということでしょう。しかし、実際に実行してみると、生成される5枚の画像は「同じものの5つのわずかなバリエーション」であり、「互いに連携した一組の画像」にはなりません。
その理由は、nパラメータの動作メカニズムにあります。このパラメータはプロンプトを変更するのではなく、同じプロンプトで何度か生成を実行し、モデルの生成プロセスにおけるランダムサンプリングによって差異を生み出します。OpenAIの開発者コミュニティには、これを的確に表現した言葉があります:これらの画像は「同一入力下でのランダムサンプリングによる変化」から生まれる、と。言い換えれば、これはガチャと同じです——同じガチャプールから5回引く、カードの絵柄は似ていて、レア度はランダムです。
これにより、2つの直接的な問題が生じます。第一に、「1枚目は表紙、2枚目はフローチャート、3枚目は比較図」といった構造化された要求を、1回の呼び出しで表現することはできません。プロンプトは1つしかないからです。第二に、コストは線形に加算されます:n=5は5枚分の料金がかかり、パッケージ割引はありません。
以下の表は、ある記事のために用途の異なる5枚の挿絵を生成したいという具体的なシナリオで、この違いを説明します。
| 要求 | n=5を使用した結果 | 本当に欲しいもの |
|---|---|---|
| 表紙画像 | 5枚とも表紙の候補 | 1枚の表紙 |
| フローチャート | 取得不可 | 1枚のフローチャート |
| 比較図 | 取得不可 | 1枚の比較図 |
| データ可視化図 | 取得不可 | 1枚のデータ可視化図 |
| 挿絵 | 取得不可 | 1枚の雰囲気を出す画像 |
結論は明らかです:nパラメータは「良い画像が1枚欲しい、複数の候補から選びたい」という用途には適していますが、「内容の異なる一組の画像が欲しい」という用途には向きません。この点を理解すれば、「なぜAPIではウェブ版のような効果が出ないのか」と悩むことはなくなります——間違ったツールを使っているからです。nパラメータの「ガチャ」特性を低コストで検証したい場合は、APIYI (apiyi.com) が呼び出し量ベースの課金をサポートしているので、いくつかの比較実験を実行しても費用はかかりません。
三、ウェブ版組図の裏にあるAgentic編成の原理
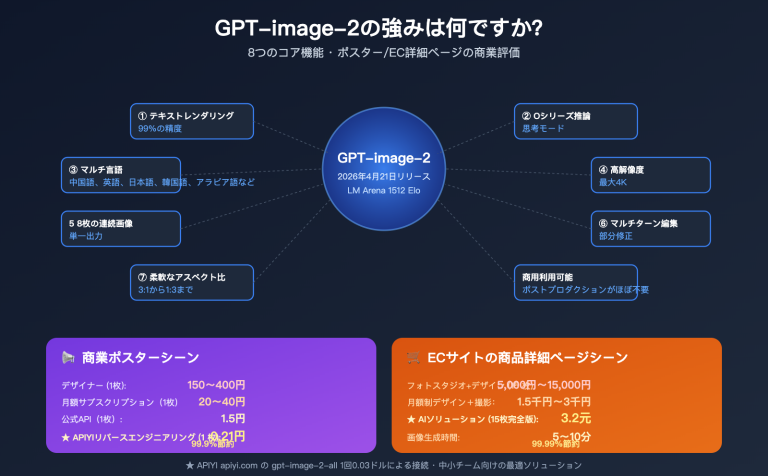
では、ChatGPTウェブ版はなぜ「1つのPDFから5枚の画像を生成」できるのでしょうか?その答えは、先述した2つ目の道筋——Agentic編成にあり、これはまさに2026年4月にリリースされたGPT Image 2 / ChatGPT Images 2.0がもたらした重要なアップグレードです。
OpenAIの公式な位置づけによれば、GPT Image 2は「推論能力」を画像モデルに組み込んだ初めてのバージョンです:筆を動かす前に、画像の構造を調査、計画、推論(proactively researches, plans, and reasons)します。この仕組みはウェブ版では「Thinkingモード」と呼ばれています。したがって、PDFを投入すると、モデルは単純に「画像を読み取る」のではなく、まずドキュメントの内容、必要な画像の枚数、各画像が担うべき役割を理解し、その後、一枚ずつ生成していきます。
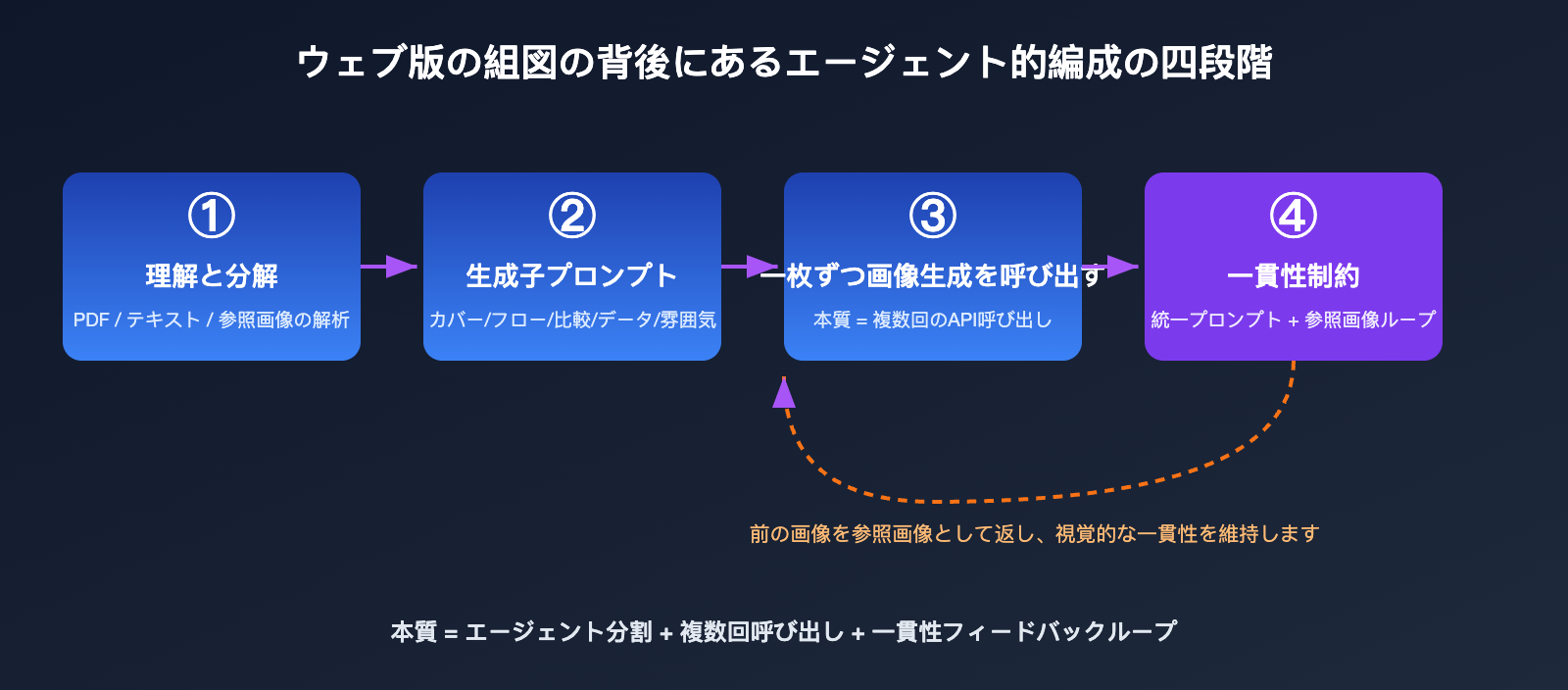
このプロセスをエンジニアリングの言葉に翻訳すると、おおよそ以下の4ステップになります:
- 理解と分解: Agentが入力(テキスト、PDF、参照画像)を解析し、必要な画像枚数と各画像の主題を判断します。
- サブプロンプトの生成: 各画像に対して独立したプロンプトを作成します(例:「全体アーキテクチャ図」「主要フローチャート」「データ比較図」)。
- 逐次呼び出しによる画像生成: 各サブプロンプトに対して、基盤となる画像生成能力を個別に呼び出します。本質的には複数回のAPI呼び出しです。
- 一貫性の制約: 各プロンプトに統一されたスタイルの記述を注入し、先に生成された画像を後の生成の参照画像として渡すことで、一組全体の視覚的一貫性を保証します。
学界でも同様の考え方が用いられています。マルチエージェントフレームワーク(ビデオ生成におけるViMax、テキストから画像生成におけるMaestroなど)は、大きな要求を複数の細粒度の視覚的サブ問題に分解し、並列生成して最良のものを選択し、前のフレームや画像を後続生成の参照として用いることで、キャラクターやシーンの一貫性を維持します。GPT Image 2の優れた点は、この本来エンジニアが手組みで構築する必要があった編成を、モデル自身の推論回路に組み込んだことです。
ここにこそ、真の難しさが潜んでいます:複数回の独立した呼び出しは、本質的に「ドリフト(ずれ)」を生み出します。各画像はそれぞれ新しいランダムサンプリングであり、キャラクターの顔立ち、配色、画風が意図しない方向にずれてしまう可能性があります。これが、私たちがお客様と話す中で出てくる核心的な問題——「視覚的一貫性をどう保つか」であり、これは「どうやって複数枚の画像を出すか」よりもはるかに難しい課題です。次のセクションでは、この問題にどう対処するかを具体的に説明します。
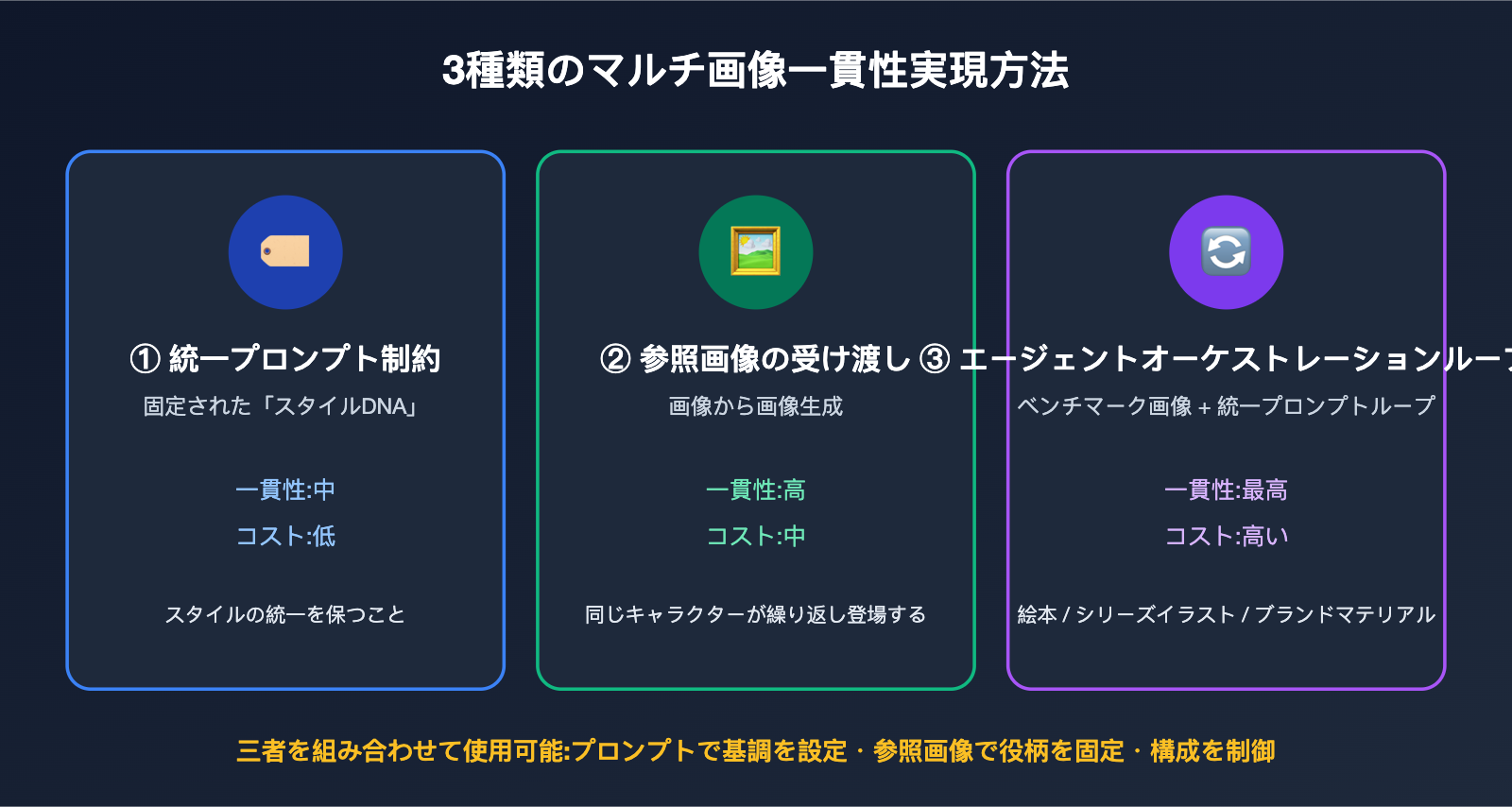
四、APIでシリーズ画像を再現する:3つの多画像一貫性実現方法
もしWeb版に依存せず、自社のプロダクトで GPT Image のシリーズ画像生成 を実装したい場合、そのオーケストレーションロジックを自前で構築する必要があり、その核心は「視覚的一貫性」を工学的な手段で補完することです。実践を踏まえ、私たちは、段階的で、組み合わせて使用できる3つの方法をまとめました。
方法1:統一プロンプト制約(キャラクター記述表)。 最も低コストな方法は、一連の画像全体に対して固定の「スタイルDNA」を記述し、毎回の呼び出し時にプロンプトにそのまま添付することです。例えば、「統一されたフラットイラストスタイル、メインカラーはネイビーブルーと琥珀色、人物はショートヘアの女性エンジニア」などです。コミュニティではこのような固定記述を「キャラクター・バイブル(役割聖書)」と呼び、記述が具体的であればあるほど、画像間の一貫性は高まります。
方法2:参照画像の受け渡し(画像から画像生成)。 既に生成されて満足のいく最初の画像を、参照画像として以降の各呼び出しに渡します。GPT Image 2は編集/参照シーンにおいて複数の参照画像を受け取ることができます(公式ドキュメントでは最大16枚と記載されていますが、実際にはプラットフォームでの実測値に準拠します)。これにより、「画像で基調を決定する」ことがシリーズ画像の一貫性を確保する主要な手段となります。特にキャラクターの顔立ちなどの詳細において、純粋なテキスト記述よりも安定した効果が得られることが一般的です。
方法3:エージェント・オーケストレーション + 参照画像ループ。 前の2つの方法を1つのループに組み合わせます:まず最初の画像をベースライン画像として生成し、以降の各画像はベースライン画像と統一プロンプトを組み合わせて生成します。必要に応じて、前回生成した画像も参照画像として一緒に渡します。これは、Web版の「Thinking」モードが行っていることであり、あなたはそれをコード内に明示的に記述するだけです。
以下は、「まずベースライン画像を生成し、その後参照画像を伴ってシリーズ画像を生成する」という骨組みのロジックを示す、簡潔なオーケストレーションの例です。
from openai import OpenAI
# base_url は APIYI を指し、複数モデルのキーを一元管理します。
client = OpenAI(base_url="https://api.apiyi.com/v1", api_key="YOUR_KEY")
STYLE = "フラットイラストスタイル, メインカラーはネイビーブルーと琥珀色, 人物はショートヘアの女性エンジニア" # キャラクター記述表
shots = ["表紙:人物がデータセンターの前に立つ", "プロセス:人物がホワイトボードにアーキテクチャを描く", "まとめ:人物が親指を立てる"]
# 1. まずベースライン画像を生成し、シリーズ全体のスタイルを確定します。
base = client.images.generate(model="gpt-image-2", prompt=f"{shots[0]},{STYLE}")
# 2. 以降の各画像は統一スタイル制約を伴って生成します(発展形として、ベースライン画像を edits インターフェースへの参照画像として追加することも可能です)。
for shot in shots[1:]:
img = client.images.generate(model="gpt-image-2", prompt=f"{shot},{STYLE}")
# save(img) ...
選択を手助けするために、以下の表で3つの方法の特徴と適用シーンを比較します。
| 方法 | 一貫性の強度 | 実装コスト | 適用シーン |
|---|---|---|---|
| 統一プロンプト制約 | 中 | 低 | スタイル統一のみで良く、キャラクターが厳密でない場合 |
| 参照画像の受け渡し | 高 | 中 | 同一キャラクター/製品が繰り返し登場する場合 |
| エージェント・オーケストレーションループ | 最高 | 高 | 絵本、シリーズイラスト、ブランドマテリアル |
3つの方法は組み合わせることができます:プロンプトで基調を定め、参照画像でキャラクターを固定し、オーケストレーションで構造を制御します。まずは「統一プロンプト + 参照画像」から始め、動作確認後に完全なオーケストレーションを導入することをお勧めします。APIYI apiyi.com では、gpt-image-2、gpt-image-1.5 などのモデルが同じ base_url と APIキー を共有しているため、コードを変更することなくモデルを切り替えて一貫性の比較テストを行うことが容易です。
五、GPT Image シリーズ画像生成のコストとモデル選択
シリーズ画像は複数回の呼び出しを意味するため、コストが増幅されます。したがって、適切なモデルを選択することが重要です。現在、GPT Image シリーズで本番環境でよく使用されるモデルにはいくつかのグレードがあり、それぞれ異なる重点があります。
| モデル | 位置付け | 推論オーケストレーション対応 | 適したシリーズ画像シーン |
|---|---|---|---|
| gpt-image-2 | フラグシップ、推論機能内蔵 | 対応(Thinkingモード) | 高品質なシリーズマテリアル、テキスト入りポスター |
| gpt-image-1.5 | 前世代フラグシップ | 部分的対応 | 品質とコストのバランスが取れたバッチ画像生成 |
| gpt-image-1 | クラシックで安定 | 非対応 | スタイルがシンプルな通常の挿絵 |
| gpt-image-1-mini | 軽量・低価格 | 非対応 | 大量バッチ、品質要求が高くない場合 |
コストについては明確に認識する必要があります:シリーズ画像は「枚数に応じて累積」課金されます。1024×1024 を例にとると、異なる品質グレードでの単価はおおよそ数ミリドルから2ミリドル強まで様々です(詳細は公式およびプラットフォームのリアルタイム価格に準拠します)。5枚1組の画像セットであれば5枚分の費用がかかります。何千枚ものバッチ生産を行う場合、コストは相当なものになる可能性があるため、事前の見積もりが重要です。
私たちの推奨は:下書き段階では mini または低品質グレードを使用して構図と一貫性を素早く検証し、最終段階で gpt-image-2 を使用して高品質の最終画像を生成するという方法です。この「低コスト試行錯誤 + 高品質最終決定」の組み合わせは、効果を保証しながら請求額を抑えることができます。APIYI apiyi.com は統一された使用量ダッシュボードを提供しており、シリーズ画像生成にいくらかかったのか、どのモデルが使用されたのかが一目でわかるため、コスト管理が必要なチームに適しています。
六、よくある質問 FAQ
Q1: APIで本当に異なる画像を一度に生成することはできますか?
できません。n パラメータだけでは不可能です。n は同じプロンプトからのランダムサンプリング(ガチャ)であり、内容はほぼ同じです。真の「組写真」を生成するには、アプリケーション層でのオーケストレーションが必要です。つまり、要件を分割し、複数回呼び出し、一貫性の制約をかけることです。
Q2:ウェブ版ChatGPTで組写真を生成するのは、どんなブラックボックス技術を使っているのですか?
ブラックボックス技術ではなく、GPT Image 2がエージェンシック推論を内蔵しているからです。生成前に「何枚の画像が必要か、それぞれ何を描くか」を計画し、その後一枚ずつ生成します。本質的には複数回の呼び出しですが、計画プロセスがユーザーに透明化されているだけです。
Q3:複数画像の一貫性を保つ最も効果的な方法は何ですか?
実践的には、参照画像の受け渡しが最も安定しています。最初に気に入った画像を参照画像として、以降のすべての呼び出しに渡すことで、キャラクターや配色の再現度は、純粋なテキスト記述よりも明らかに高まります。これに固定のスタイル記述表を重ねると、さらに効果的です。APIYI apiyi.com の gpt-image-2 の参照画像インターフェースで直接検証できます。
Q4:組写真生成は高くつきますか?
枚数、解像度、品質レベルによって異なります。枚数に応じて累積するためです。下書きには軽量モデル、完成稿にはフラッグシップモデルを使用し、プラットフォームの使用量ダッシュボードでコストを監視することをお勧めします。
Q5:組写真生成に最もコストパフォーマンスの良いモデルはどれですか?
品質と文字レンダリングを追求するなら gpt-image-2。コストバランスを重視するなら gpt-image-1.5。大量で低要求の場合は gpt-image-1-mini が使えます。同じインターフェースを共有しているため、モデルの切り替えはほぼコストゼロです。
七、まとめ
最初の疑問に戻りましょう:同じモデルでも、APIはガチャのようで、ウェブ版は組写真を生成できる。この違いはモデル自体ではなく、呼び出し方にあります。n パラメータはモデル層でのバッチサンプリングであり、「候補を数枚多く出す」ことを解決します。真の GPT Image 組写真生成は、アプリケーション層でのエージェンシック・オーケストレーションであり、要件の分割、複数回の呼び出し、一貫性の制約によって組み立てられます。
この中で、複数画像の一貫性は常に最も難しい部分です。幸いなことに、私たちには3つの便利なツールがあります:統一されたキャラクター記述表で基調を定め、参照画像の受け渡しでキャラクターを固定し、エージェントのオーケストレーション・ループで構造を制御します。これらを組み合わせることで、ウェブ版の体験にほぼ近づけることができます。GPT Image 2 の価値は、まさにこのオーケストレーション能力をモデルの推論ループに組み込み、一般ユーザーもそれを享受できるようにした点にあります。
このトピックには必ずしも正解があるわけではなく、むしろ経験の共有です——皆さんが少しでも遠回りをせずに済むことを願っています。本文で紹介した各方法を実際に試してみたい場合は、APIYI apiyi.com が gpt-image-2、gpt-image-1.5 などのモデルの統一インターフェースと使用量ダッシュボードを提供しており、組写真の実験やコスト比較の便利な出発点となります。詳細な接続方法については、ヘルプセンター help.apiyi.com をご参照ください。
本記事は、APIYI技術チームがカスタマーサポートの実践に基づいてまとめた考察的な内容です。モデルの仕様や価格は、公式およびプラットフォームの最新情報をご確認ください。