Viele Nutzer, die zum ersten Mal die Webversion von ChatGPT verwenden, unterliegen einem Trugschluss: Sie laden ein PDF hoch oder geben einen Satz ein, und „zack“ – das Modell spuckt fünf Bilder in einem einheitlichen Stil aus. Sobald man jedoch zur API wechselt und den Parameter n auf 5 stellt, erhält man fünf kaum unterscheidbare, zufällige Varianten, die eher einem Glücksspiel gleichen. Warum gibt es bei demselben Modell so große Unterschiede?
Dieser Artikel liefert keine Standardantwort, sondern beleuchtet das Problem, das uns im Kundensupport immer wieder begegnet. Wir erklären die zwei grundlegend verschiedenen technischen Ansätze hinter der GPT-Bilderzeugung, warum der n-Parameter keine echte „Bilderserie“ erzeugen kann und welche praktischen Möglichkeiten es gibt, wenn Sie Konsistenz bei mehreren Bildern über die API selbst umsetzen möchten.
I. Zwei technische Pfade für die GPT-Bilderzeugung
Um dies zu verstehen, muss man sich zunächst ein oft übersehenes Prinzip vor Augen führen: „Mehrere Bilder gleichzeitig generieren“ und „eine logisch zusammenhängende Bilderserie erstellen“ sind zwei verschiedene Dinge. Ersteres ist lediglich eine Mengen-Skalierung, Letzteres ist das, was man gemeinhin unter einer „Bilderserie“ versteht.
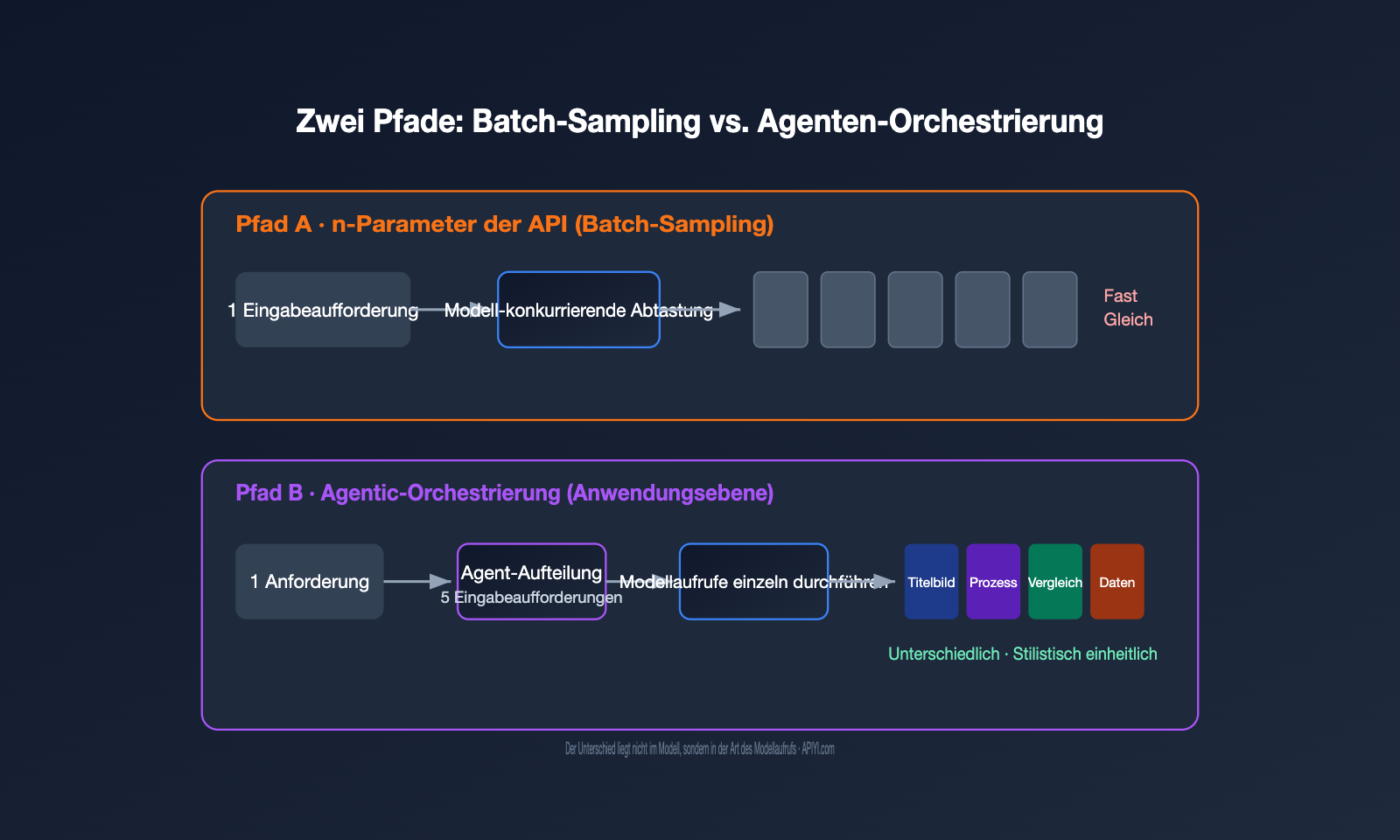
Die GPT-Bilderzeugung lässt sich technisch auf zwei Pfade zurückführen. Der erste ist das Batch-Sampling auf Modellebene, also der n-Parameter in der API: Bei gleicher Eingabeaufforderung und gleichem Input lässt das Modell parallel mehrere Ergebnisse sampeln. Der zweite Pfad ist die Agentic-Orchestrierung auf Anwendungsebene, bei der ein Agent (intelligenter Agent) den Bedarf zunächst versteht, ihn in mehrere Teilaufgaben zerlegt, diese einzeln zur Bilderzeugung anstößt und die Ergebnisse schließlich zu einer Serie zusammenfügt.
Die folgende Tabelle verdeutlicht die Kernunterschiede beider Ansätze, auf die wir in den nächsten Abschnitten näher eingehen werden.
| Dimension | API-Parameter n (Batch-Sampling) |
Agentic-Orchestrierung (Anwendungsebene) |
|---|---|---|
| Wesen | Wiederholtes Zufallssampling derselben Eingabeaufforderung | Aufteilung des Bedarfs in mehrere unabhängige Generierungen |
| Bildinhalt | Fast identisch, nur zufällige Abweichungen | Unterschiedlich, aber thematisch verknüpft |
| Verständnis von „Serie“ | Nicht vorhanden, rein parallel | Vorhanden, mit Planungslogik |
| Kosten | Preis pro Bild × N | Summe der Kosten für mehrere Aufrufe |
| Konsistenzquelle | Eingabeaufforderung + Zufalls-Seed | Referenzbild + einheitliche Vorgaben |
| Typische Szenarien | Auswahl eines passenden Bildes | Serienillustrationen, PPT-Grafiken, Bilderbücher |
Kurz gesagt: Der n-Parameter dient dazu, „mir ein paar Alternativen zu geben“, während eine Bilderserie erfordert, „mir eine Reihe von Inhalten zu einem Thema zu liefern“. Genau deshalb fühlt sich die direkte API-Nutzung oft unzureichend an, wenn man die Erfahrung der Webversion nachbilden möchte. Wenn Sie beide Ansätze in der Praxis vergleichen möchten, können Sie dies mit demselben API-Schlüssel auf APIYI (apiyi.com) tun und sich so das Hin- und Herwechseln zwischen verschiedenen Plattformen sparen.
二、 Warum der n-Parameter der API keine echten Bilderserien erzeugen kann
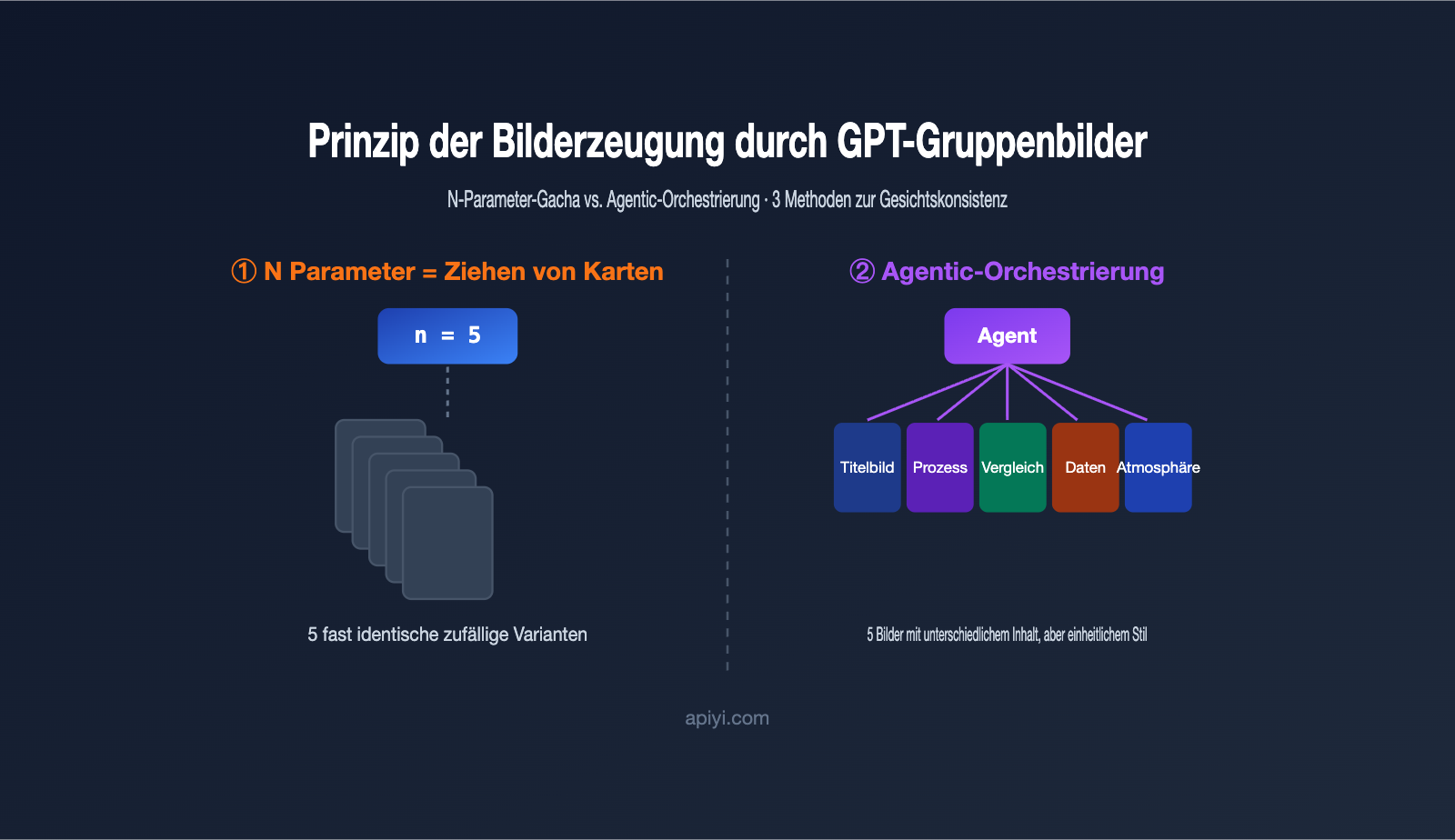
Die erste Reaktion vieler Entwickler ist: Wenn ich 5 Bilder brauche, setze ich einfach n auf 5, oder? Wer das in der Praxis testet, wird schnell feststellen, dass die 5 Bilder meist nur „fünf minimale Variationen desselben Motivs“ sind und keine „aufeinander abgestimmte Bilderserie“.
Der Grund liegt im Arbeitsmechanismus des n-Parameters. Er ändert nicht deine Eingabeaufforderung, sondern führt dieselbe Eingabeaufforderung einfach mehrmals aus, wobei er sich auf zufällige Stichproben während des Generierungsprozesses verlässt, um Unterschiede zu erzeugen. In der OpenAI-Entwickler-Community gibt es eine treffende Beschreibung dafür: Diese Bilder sind „zufällige Stichprobenvariationen bei gleicher Eingabe“ (random sampling variations). Anders gesagt: Es ist wie beim „Gacha-Spiel“ – derselbe Pool, 5 Versuche, ähnliche Karten, zufällige Seltenheit.
Das hat zwei direkte Konsequenzen. Erstens kannst du in einem einzigen Aufruf keine strukturierten Anforderungen wie „Bild 1: Cover, Bild 2: Prozess, Bild 3: Vergleich“ ausdrücken, da es nur eine einzige Eingabeaufforderung gibt. Zweitens summieren sich die Kosten linear: n=5 wird für 5 Bilder berechnet, es gibt keinen Mengenrabatt.
Die folgende Tabelle verdeutlicht diesen Unterschied anhand eines konkreten Szenarios, in dem du 5 Bilder für unterschiedliche Zwecke in einem Artikel generieren möchtest.
| Anforderung | Ergebnis mit n=5 | Was du eigentlich willst |
|---|---|---|
| Cover-Bild | 5 Cover-Kandidaten | 1 Cover-Bild |
| Prozess-Grafik | Nicht möglich | 1 Prozess-Grafik |
| Vergleichs-Grafik | Nicht möglich | 1 Vergleichs-Grafik |
| Daten-Grafik | Nicht möglich | 1 Daten-Grafik |
| Stimmungsbild | Nicht möglich | 1 Stimmungsbild |
Das Fazit ist klar: Der n-Parameter eignet sich, wenn du „ein gutes Bild willst und mehrere Kandidaten zur Auswahl brauchst“, aber nicht, wenn du „eine Serie mit unterschiedlichen Inhalten“ suchst. Wenn man das einmal verstanden hat, fragt man sich nicht mehr, „warum die API nicht die Ergebnisse der Web-Version liefert“ – man hat schlicht das falsche Werkzeug verwendet. Um die Gacha-Eigenschaften des n-Parameters kostengünstig zu testen, bietet APIYI (apiyi.com) eine nutzungsbasierte Abrechnung an; ein paar Vergleichsexperimente kosten dort kaum etwas.
三、 Das Prinzip der Agentic-Orchestrierung hinter der Web-Version
Wie schafft es dann die ChatGPT-Web-Version, „aus einem PDF 5 Bilder zu generieren“? Die Antwort ist der oben genannte zweite Weg – Agentic-Orchestrierung. Genau das ist die entscheidende Neuerung, die mit GPT Image 2 / ChatGPT Images 2.0 im April 2026 eingeführt wurde.
Laut der offiziellen Positionierung von OpenAI ist GPT Image 2 die erste Version, die „Schlussfolgerungsfähigkeiten“ (Reasoning) direkt in das Bildmodell integriert hat: Bevor das Modell zeichnet, analysiert, plant und durchdenkt es die Bildstruktur (proactively researches, plans, and reasons). Dieser Mechanismus wird in der Web-Version als „Thinking“-Modus bezeichnet. Wenn du also ein PDF hochlädst, „liest“ das Modell nicht einfach nur das Bild, sondern versteht zuerst, worum es im Dokument geht, wie viele Bilder benötigt werden, welche Rolle jedes Bild spielt und generiert sie dann nacheinander.
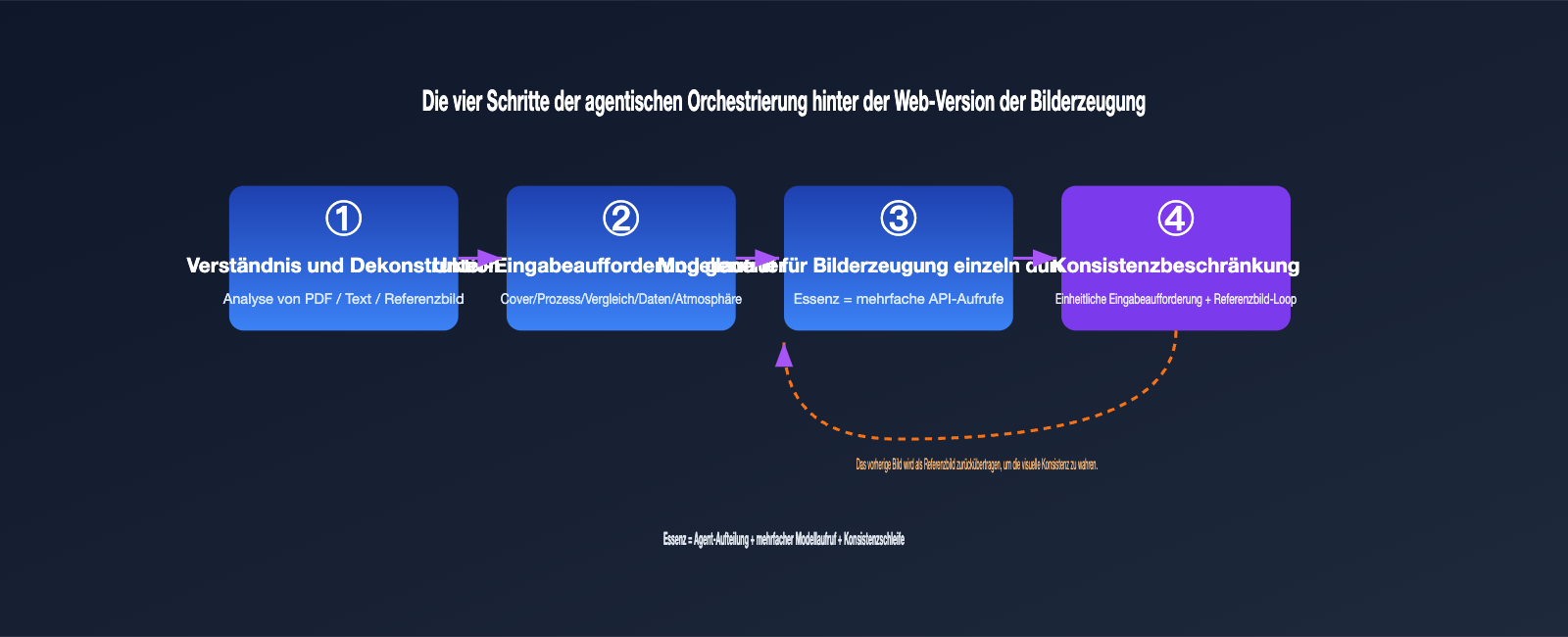
Übersetzt in die Ingenieurssprache lässt sich dieser Prozess in vier Schritte unterteilen:
- Verständnis & Zerlegung: Der Agent analysiert die Eingabe (Text, PDF, Referenzbild) und bestimmt, wie viele Bilder benötigt werden und was das Thema jedes Bildes ist.
- Generierung von Unter-Eingabeaufforderungen: Für jedes Bild wird eine eigene, unabhängige Eingabeaufforderung geschrieben, z. B. „Gesamtarchitektur“, „Schlüsselprozess“, „Datenvergleich“.
- Sequenzieller Modellaufruf: Für jede Unter-Eingabeaufforderung wird die zugrunde liegende Bilderzeugungs-Funktion aufgerufen – im Grunde handelt es sich um mehrere API-Aufrufe.
- Konsistenz-Einschränkung: In jede Eingabeaufforderung wird eine einheitliche Stilbeschreibung injiziert, und die zuvor generierten Bilder werden als Referenzbild an die nachfolgenden übergeben, um eine visuelle Einheitlichkeit der gesamten Serie zu gewährleisten.
Auch in der Wissenschaft wird ein ähnlicher Ansatz verfolgt. Multi-Agenten-Frameworks (wie ViMax bei der Videogenerierung oder Maestro bei der Text-zu-Bild-Generierung) zerlegen eine große Anforderung in mehrere fein abgestimmte visuelle Teilprobleme, generieren diese parallel oder sequenziell, wählen die besten aus und nutzen das vorherige Bild als Referenz für die nächste Generierung, um die Konsistenz von Charakteren und Szenen zu wahren. Die Stärke von GPT Image 2 liegt darin, dass diese Orchestrierung, die früher von Ingenieuren manuell aufgebaut werden musste, direkt in den Schlussfolgerungskreislauf des Modells integriert wurde.
Hier liegt auch die eigentliche Schwierigkeit: Mehrfache, unabhängige Aufrufe führen naturgemäß zu Abweichungen. Jedes Bild ist eine neue zufällige Stichprobe, bei der Gesichtszüge, Farbgebung und Zeichenstil abweichen können. Das ist genau das Kernproblem, das wir mit Kunden besprechen – „Wie bewahrt man visuelle Konsistenz?“, was deutlich schwieriger ist als „Wie generiere ich mehrere Bilder?“. Im nächsten Abschnitt gehen wir gezielt darauf ein, wie man dieses Problem in den Griff bekommt.
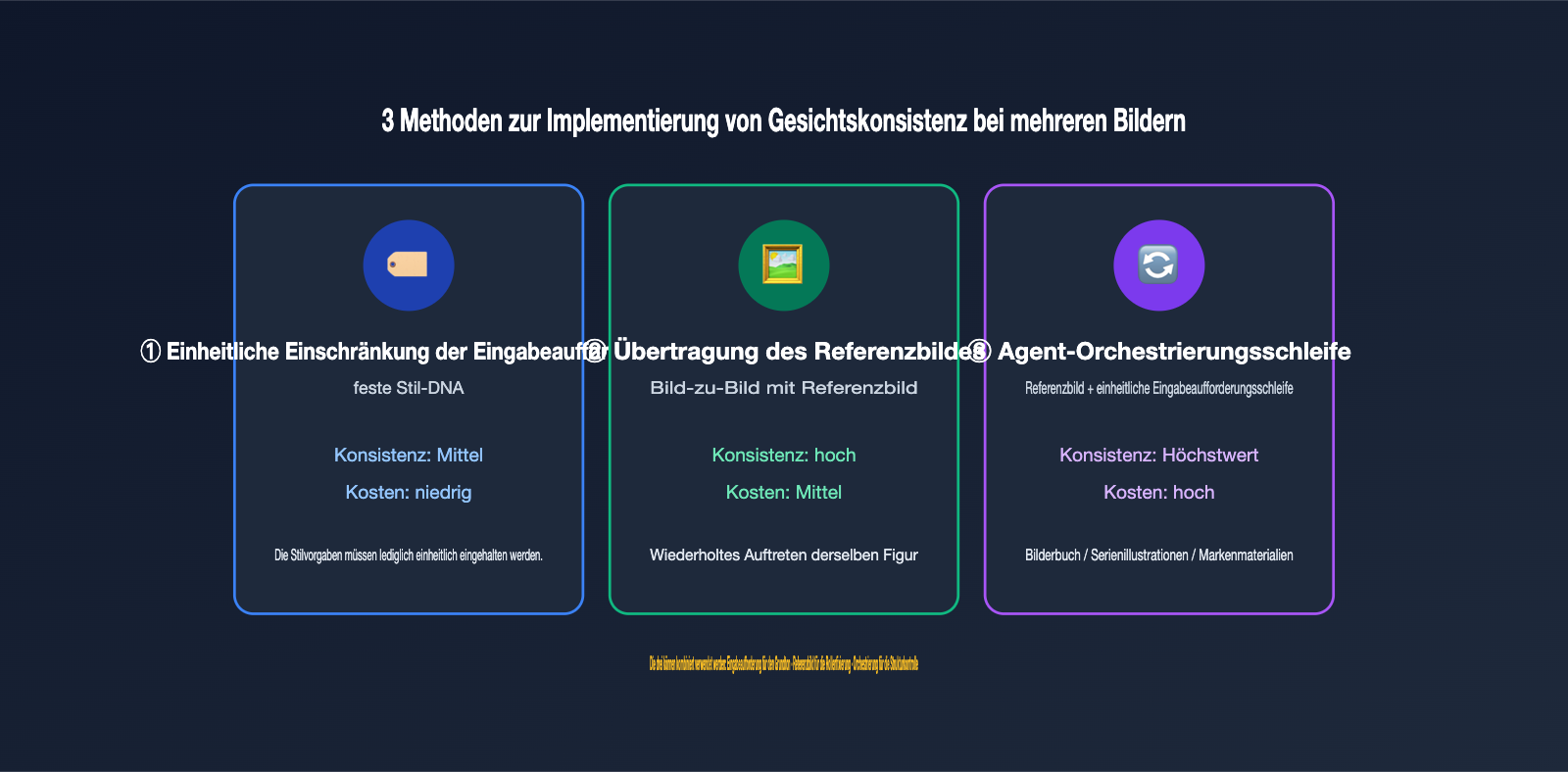
IV. Bilder-Sets mit der API erstellen: 3 Methoden für visuelle Konsistenz
Wenn Sie nicht auf die Webversion angewiesen sein möchten, sondern die GPT Image-Bilderzeugung direkt in Ihr eigenes Produkt integrieren wollen, müssen Sie die entsprechende Orchestrierungslogik selbst aufbauen. Der Kernpunkt besteht darin, die „visuelle Konsistenz“ durch technische Maßnahmen zu gewährleisten. Basierend auf unseren Erfahrungen haben wir drei Methoden zusammengestellt, die von einfach bis komplex reichen und sich kombinieren lassen.
Methode 1: Einheitliche Einschränkung durch Eingabeaufforderung (Charakter-Datenblatt). Der kostengünstigste Ansatz besteht darin, einen festen „Stil-DNA“-Block für das gesamte Set zu definieren und diesen bei jedem Aufruf unverändert in die Eingabeaufforderung einzufügen. Zum Beispiel: „Flacher Illustrationsstil, Hauptfarben Dunkelblau und Bernstein, Person ist eine kurzhaarige Ingenieurin“. In der Community wird diese feste Beschreibung als „Character Bible“ bezeichnet – je detaillierter die Beschreibung, desto höher die Konsistenz über verschiedene Bilder hinweg.
Methode 2: Übertragung von Referenzbildern (Bild-zu-Bild). Verwenden Sie das erste Bild, mit dem Sie zufrieden sind, als Referenzbild für jeden nachfolgenden Aufruf. GPT Image 2 kann in Bearbeitungs- oder Referenzszenarien mehrere Referenzbilder empfangen (die offizielle Dokumentation gibt bis zu 16 Bilder an, die genaue Anzahl hängt von der Plattform ab). Dies macht die „Stilvorgabe durch Bilder“ zum wichtigsten Mittel für die Konsistenz von Bild-Sets. Die Ergebnisse sind meist stabiler als bei reinen Textbeschreibungen, insbesondere bei Details wie dem Gesichtsausdruck.
Methode 3: Agenten-Orchestrierung + Referenzbild-Schleife. Kombinieren Sie die ersten beiden Methoden in einem Kreislauf: Erzeugen Sie zuerst ein Basisbild und lassen Sie jedes nachfolgende Bild mit dem Basisbild und der einheitlichen Eingabeaufforderung generieren. Bei Bedarf kann auch das jeweils vorherige Bild als Referenz dienen. Genau das macht der Thinking-Modus der Webversion – Sie schreiben diesen Prozess lediglich explizit in Ihren Code.
Hier ist ein vereinfachtes Beispiel für die Orchestrierung, das die Grundlogik „Zuerst Basisbild erstellen, dann Serie mit Referenzbildern generieren“ demonstriert:
from openai import OpenAI
# base_url verweist auf APIYI, zentrale Verwaltung für Modell-Schlüssel
client = OpenAI(base_url="https://api.apiyi.com/v1", api_key="YOUR_KEY")
STYLE = "Flacher Illustrationsstil, Hauptfarben Dunkelblau und Bernstein, Person ist eine kurzhaarige Ingenieurin" # Charakter-Datenblatt
shots = ["Cover: Person steht vor dem Rechenzentrum", "Prozess: Person zeichnet Architektur am Whiteboard", "Zusammenfassung: Person zeigt Daumen hoch"]
# 1. Erst Basisbild generieren, um den Stil für das Set festzulegen
base = client.images.generate(model="gpt-image-2", prompt=f"{shots[0]},{STYLE}")
# 2. Nachfolgende Bilder mit einheitlicher Stilvorgabe (fortgeschritten: base als Referenzbild in edits-Schnittstelle übergeben)
for shot in shots[1:]:
img = client.images.generate(model="gpt-image-2", prompt=f"{shot},{STYLE}")
# save(img) ...
Die folgende Tabelle vergleicht die Merkmale und Einsatzszenarien der drei Methoden:
| Methode | Konsistenzgrad | Implementierungskosten | Einsatzszenario |
|---|---|---|---|
| Einheitliche Eingabeaufforderung | Mittel | Niedrig | Stil muss konsistent sein, Charakter nicht strikt |
| Referenzbild-Übertragung | Hoch | Mittel | Wiederkehrende Charaktere/Produkte |
| Agenten-Orchestrierung | Höchster | Hoch | Bilderbücher, Serienillustrationen, Markenmaterial |
Die Methoden lassen sich kombinieren: Nutzen Sie die Eingabeaufforderung für den Grundton, Referenzbilder für den Charakter und die Orchestrierung für die Struktur. Wir empfehlen, mit „Einheitliche Eingabeaufforderung + Referenzbild“ zu starten und erst nach erfolgreichem Test die vollständige Orchestrierung zu implementieren. Bei APIYI (apiyi.com) nutzen Modelle wie gpt-image-2 und gpt-image-1.5 dieselbe base_url und denselben Schlüssel, was den Modellwechsel für Konsistenz-Vergleiche ohne Codeänderungen erleichtert.
V. Kosten und Modellauswahl für die GPT Image-Bilderzeugung
Bild-Sets bedeuten mehrere Aufrufe, wodurch die Kosten steigen – die Wahl des richtigen Modells ist daher entscheidend. Derzeit gibt es in der GPT Image-Serie verschiedene Stufen für den produktiven Einsatz:
| Modell | Positionierung | Unterstützt Inferenz-Orchestrierung | Geeignete Szenarien |
|---|---|---|---|
| gpt-image-2 | Flaggschiff, integrierte Inferenz | Ja (Thinking) | Hochwertige Serien, Poster mit Text |
| gpt-image-1.5 | Vorgänger-Flaggschiff | Teilweise | Ausgewogenes Verhältnis von Qualität und Kosten |
| gpt-image-1 | Klassisch, stabil | Nein | Einfache Illustrationen |
| gpt-image-1-mini | Leicht, kostengünstig | Nein | Massenproduktion, geringere Qualitätsanforderungen |
Beachten Sie bei den Kosten: Bild-Sets werden pro Bild abgerechnet. Bei 1024×1024 variieren die Preise je nach Qualitätsstufe (aktuelle Preise entnehmen Sie bitte den offiziellen Angaben). Ein Set aus 5 Bildern kostet also den Preis von 5 Einzelbildern. Bei einer Produktion von tausenden Bildern summieren sich die Kosten schnell, eine vorherige Kalkulation ist daher ratsam.
Unsere Empfehlung: Nutzen Sie in der Entwurfsphase „mini“ oder niedrigere Qualitätsstufen, um Komposition und Konsistenz schnell zu prüfen, und verwenden Sie erst für die finale Version „gpt-image-2“. Diese Kombination aus kostengünstigem Ausprobieren und hochwertiger Fertigstellung schont Ihr Budget. APIYI (apiyi.com) bietet ein einheitliches Dashboard zur Überwachung der Nutzung, sodass Sie genau sehen, welches Modell wie viele Kosten verursacht hat – ideal für Teams, die ihre Ausgaben kontrollieren müssen.
VI. Häufig gestellte Fragen (FAQ)
F1: Kann die API tatsächlich eine Reihe unterschiedlicher Bilder auf einmal generieren?
Nein, der Parameter n reicht dafür nicht aus. n führt lediglich eine zufällige Stichprobe (ähnlich wie beim Ziehen von Karten) für dieselbe Eingabeaufforderung durch, wobei der Inhalt nahezu identisch bleibt. Echte Bilderserien erfordern eine Orchestrierung auf Anwendungsebene: Anforderungen aufteilen, mehrere Modellaufrufe tätigen und anschließend Konsistenzvorgaben anwenden.
F2: Welche „Black Magic“ nutzt die Webversion von ChatGPT, um Bilderserien zu erstellen?
Das ist keine „Black Magic“, sondern GPT Image 2, das Agentic-Reasoning direkt integriert hat. Vor der Erzeugung plant das Modell: „Wie viele Bilder werden benötigt und was soll auf jedem Bild zu sehen sein?“. Danach erfolgt die schrittweise Generierung. Im Grunde sind es immer noch mehrere Modellaufrufe, nur der Planungsprozess bleibt für den Benutzer transparent.
F3: Was ist die effektivste Methode für die Gesichtskonsistenz bei mehreren Bildern?
In der Praxis ist die Verwendung eines Referenzbildes am stabilsten: Übergeben Sie das erste gelungene Bild als Referenz an jeden nachfolgenden Modellaufruf. Die Wiedergabetreue von Charakteren und Farbschemata ist dabei deutlich höher als bei reinen Textbeschreibungen. Kombiniert mit einer festen Stilbeschreibung erzielen Sie noch bessere Ergebnisse. Sie können die Referenzbild-Schnittstelle von gpt-image-2 direkt auf APIYI (apiyi.com) testen.
F4: Ist die Generierung von Bilderserien sehr teuer?
Das hängt von der Anzahl der Bilder, der Auflösung und der Qualitätsstufe ab, da die Kosten pro Bild anfallen. Es empfiehlt sich, für Entwürfe leichtere Modelle zu verwenden und für die finale Version Flaggschiff-Modelle einzusetzen. Überwachen Sie Ihre Ausgaben zudem über das Nutzungs-Dashboard der Plattform.
F5: Welches Modell ist für Bilderserien am kosteneffizientesten?
Für höchste Qualität und Textdarstellung wählen Sie gpt-image-2; für ein ausgewogenes Kosten-Nutzen-Verhältnis ist gpt-image-1.5 ideal; für große Mengen mit geringeren Anforderungen eignet sich gpt-image-1-mini. Da alle Modelle dieselbe Schnittstelle nutzen, ist der Wechsel zwischen den Modellen nahezu kostenlos.
VII. Fazit
Kommen wir zurück zur ursprünglichen Frage: Warum liefert die API bei demselben Modell nur „Zufallstreffer“, während die Webversion ganze Bilderserien erstellt? Der Unterschied liegt nicht im Modell, sondern in der Art des Modellaufrufs. Der n-Parameter ist eine Batch-Stichprobe auf Modellebene, um „mehrere Kandidaten“ zu erhalten. Echte GPT Image-Bilderserien sind eine Agentic-Orchestrierung auf Anwendungsebene, die durch das Aufteilen von Anforderungen, mehrfache Modellaufrufe und Konsistenzvorgaben erreicht wird.
Dabei bleibt die Gesichtskonsistenz über mehrere Bilder hinweg die größte Herausforderung. Glücklicherweise haben wir drei hilfreiche Werkzeuge: eine einheitliche Charakterbeschreibung für den Grundton, die Weitergabe von Referenzbildern zur Fixierung der Charaktere und eine Agent-Orchestrierung zur Strukturkontrolle. Die Kombination dieser drei Ansätze bringt Sie der Erfahrung der Webversion sehr nahe. Der Wert von GPT Image 2 liegt genau darin, diese Orchestrierungsfähigkeiten in den Inferenz-Loop des Modells zu integrieren, sodass auch normale Benutzer davon profitieren können.
Dieses Thema hat vielleicht keine Standardlösung, aber ich hoffe, diese Erfahrungswerte helfen Ihnen, einige Umwege zu vermeiden. Wenn Sie die hier beschriebenen Methoden selbst ausprobieren möchten, bietet APIYI (apiyi.com) eine einheitliche Schnittstelle für Modelle wie gpt-image-2 und gpt-image-1.5 sowie ein Nutzungs-Dashboard – ein idealer Ausgangspunkt für Experimente und Kostenvergleiche. Weitere Details zur Anbindung finden Sie im Hilfecenter unter help.apiyi.com.
Dieser Artikel wurde vom technischen Team von APIYI auf Basis von Erfahrungen aus dem Kundensupport zusammengestellt. Bitte beachten Sie, dass sich Modellspezifikationen und Preise gemäß den offiziellen Angaben und Echtzeit-Informationen der Plattform ändern können.