Uma descoberta interessante~ Recentemente, muitos desenvolvedores ao testarem o modelo M2.7 da MiniMax, lançado em março de 2026, esbarraram em um problema contraintuitivo: este modelo emblemático, conhecido como o "rei do código e dos fluxos de trabalho de agentes", simplesmente não suporta entrada de imagens. Considerando que, hoje em dia, capacidades multimodais são padrão no Claude 4, GPT-5 e Gemini 3, é realmente surpreendente que um Modelo de Linguagem Grande de 230B parâmetros não consiga processar imagens. Este artigo, baseado na documentação oficial da MiniMax, nos modelos NIM da NVIDIA e nas especificações públicas do OpenRouter, além das observações da APIYI (apiyi.com) em implementações reais, analisa profundamente a lógica de produto por trás do posicionamento "apenas texto" do M2.7.
I. É verdade que o MiniMax M2.7 não suporta entrada de imagens?
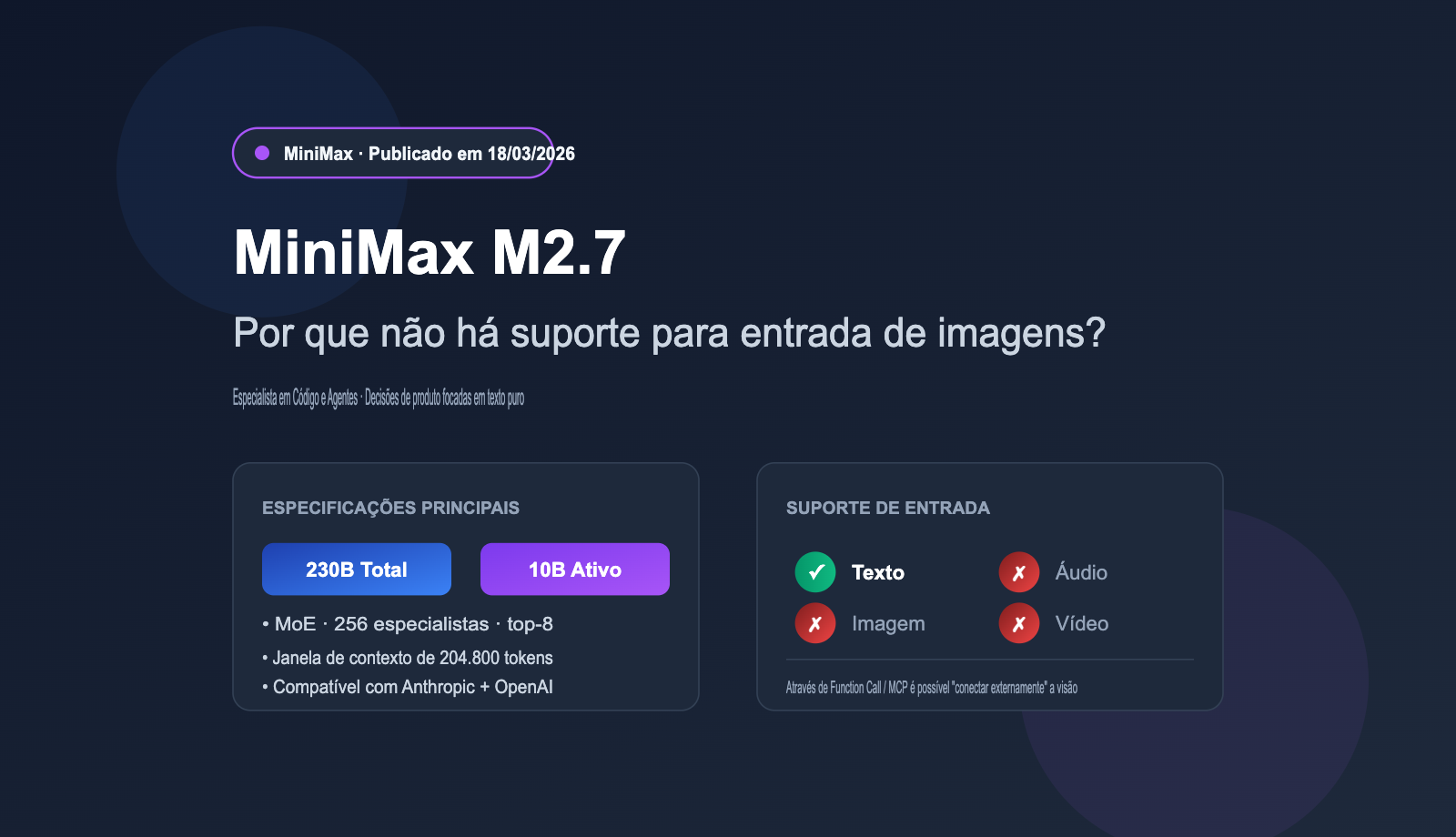
Respondendo diretamente à pergunta: é verdade. De acordo com as especificações públicas da plataforma oficial da MiniMax e dos modelos NIM da NVIDIA, o M2.7 (incluindo a versão M2.7-highspeed) suporta atualmente apenas entrada de texto, sendo incapaz de processar diretamente imagens, áudio ou vídeo. Isso é consistente com o posicionamento de texto puro da geração anterior, o M2.5, mas contrasta fortemente com a tendência de "multimodalidade nativa" do Claude 4 Opus, GPT-5 e da série Gemini 3, lançados no mesmo período.
1.1 Visão geral das especificações principais do MiniMax M2.7
O M2.7 teve sua interface aberta oficialmente em 18 de março de 2026, utilizando uma arquitetura MoE (Mistura de Especialistas), com 230B de parâmetros totais e 10B de parâmetros ativos, focando em "alto desempenho + baixo custo".
| Especificação | Parâmetro |
|---|---|
| Data de lançamento | 18/03/2026 |
| Tipo de arquitetura | MoE Transformer (256 especialistas, 8 ativos por token) |
| Parâmetros totais / ativos | 230B / 10B |
| Janela de contexto | 204.800 tokens |
| Saída máxima | 131.072 tokens |
| Preço de entrada | $0,279 / M tokens |
| Preço de saída | $1,20 / M tokens |
| Suporte multimodal | ❌ Apenas texto |
| Compatibilidade de API | Anthropic API + OpenAI API |
1.2 Em quais cenários você pode "cair em uma armadilha"?
Se sua aplicação envolve perguntas e respostas sobre capturas de tela, análise de PDFs com imagens, compreensão de fotos de produtos, detecção visual de automação de interface (UI) ou recuperação de imagens em RAG multimodal, a chamada direta ao M2.7 falhará ou retornará resultados sem sentido. Sugerimos realizar uma verificação do tipo de modelo na camada de roteamento (como LiteLLM, One API ou gateways de proxy de API unificados como o da APIYI apiyi.com), direcionando solicitações baseadas em imagem para as séries Claude, GPT-5 ou Gemini 3 para processamento.
二、Por que o MiniMax M2.7 escolheu a rota de "texto puro"
A orientação de texto puro do M2.7 não é uma falta de capacidade técnica, mas sim uma decisão de produto muito clara. A MiniMax já havia lançado anteriormente a série de modelos abab com capacidades multimodais e tinha total competência para adicionar módulos visuais à série M. No entanto, eles optaram por investir todo o poder computacional de treinamento do M2.7 nas frentes de "código + Agent", visando obter um desempenho extremo nessas duas direções.
2.1 Código e Agent são o campo de batalha central do M2.7
De acordo com o README oficial e o blog técnico da NVIDIA, o M2.7 foi otimizado especificamente para "edição de múltiplos arquivos, ciclos de código-execução-correção, correções orientadas a testes e chamadas de ferramentas de longa cadeia em Shell/navegador/busca/executores de código". Em tarefas de codificação reais, como SWE-bench, Aider Polyglot e Terminal Bench, o desempenho do M2.7 aproxima-se do Claude 4 Sonnet, mas com apenas 10B de parâmetros ativos, custando apenas cerca de 1/8 do valor de inferência do último.
2.2 O equilíbrio entre a rota de texto puro e a rota multimodal
Concentrar os recursos de treinamento em uma única direção traz ganhos e perdas determinísticos. A tabela abaixo resume os pontos de equilíbrio fundamentais entre as duas rotas:
| Dimensão | Rota de texto puro (M2.7 / DeepSeek-R1) | Rota multimodal (Claude/GPT/Gemini) |
|---|---|---|
| Custo de treinamento | Concentrado, alta eficiência | Disperso, alto custo de dados |
| Preço por token | Mais baixo ($0.28-2 / M) | Mais alto ($3-15 / M) |
| Profundidade de raciocínio em texto/código | Geralmente mais forte | Ligeiramente mais fraco, mas suficiente |
| Compreensão de imagem/vídeo | Não suportado | Suporte nativo |
| Amplitude de cenários | Mais focado | Mais generalista |
| Complexidade de integração de engenharia | Baixa | Baixa a média |
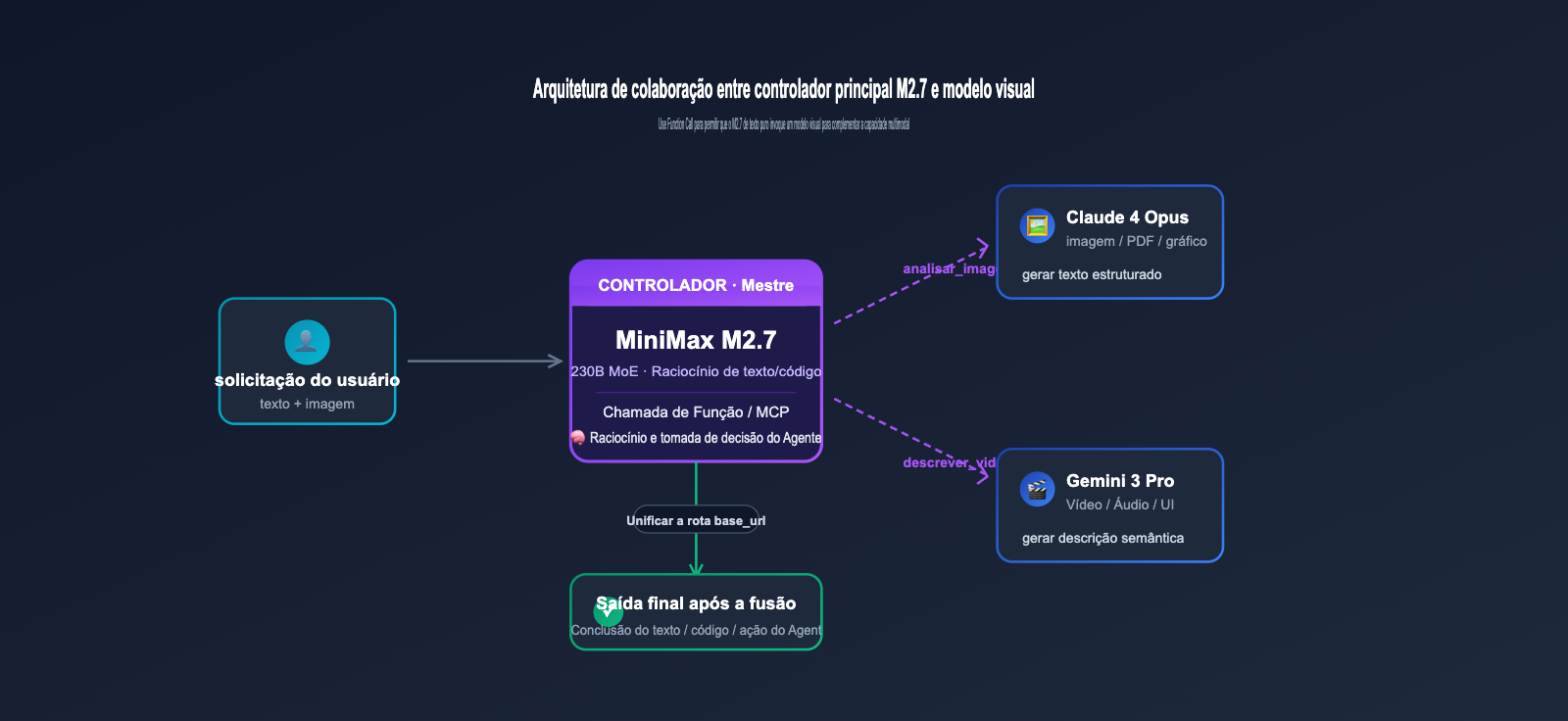
2.3 "Complementando" a capacidade multimodal através de chamadas de ferramentas
Embora o M2.7 não reconheça imagens por si só, ele suporta nativamente MCP (Model Context Protocol) e Function Calling. Isso significa que os desenvolvedores podem permitir que o M2.7 "terceirize" tarefas de compreensão de imagem para modelos visuais especializados (como o Claude 4 Opus ou Gemini 3 Vision), ficando responsável apenas pelo agendamento e pelo raciocínio final. Essa arquitetura de "controle central + colaboração visual" é muito comum em sistemas de Agent.
三、A API multimodal é realmente o padrão da indústria em 2026?
Intuitivamente, "multimodal = padrão" tornou-se quase um consenso na indústria em 2026. Mas, ao observar profundamente o campo dos modelos dominantes, percebe-se que esse julgamento precisa ser entendido em camadas.
3.1 Os principais modelos proprietários suportam quase todos a multimodalidade
A série Claude 4 da Anthropic, a série GPT-5 da OpenAI e o Gemini 3 Pro/Ultra do Google já adotaram a imagem como capacidade básica de entrada. O Gemini 3 saltou de 11,4% para 72,7% no teste ScreenSpot-Pro em relação à geração anterior, podendo "entender" capturas de tela e operar a interface do usuário diretamente; o Claude 4 também reforçou suas capacidades de reconhecimento de gráficos e análise de PDF.
3.2 O campo de código aberto/custo-benefício apresenta uma divisão clara
O campo de código aberto apresenta uma divisão clara: de um lado, modelos "multimodais de pilha completa" como Llama 3.2 Vision, Qwen3-VL e InternVL; do outro, modelos "especializados em texto/raciocínio" como DeepSeek-R1 e MiniMax M2.7, que obtêm vantagens de custo-benefício através do foco. Esses dois tipos de modelos não representam apenas uma divisão de "nível superior ou inferior", mas sim escolhas diferenciadas voltadas para diferentes formas de aplicação.
3.3 Comparação das capacidades multimodais dos principais modelos
A tabela abaixo resume as diferenças nas capacidades multimodais dos principais modelos de linguagem grande em maio de 2026, permitindo identificar rapidamente o posicionamento do M2.7 no mercado:
| Modelo | Entrada de imagem | Entrada de vídeo | Entrada de áudio | Posicionamento principal |
|---|---|---|---|---|
| MiniMax M2.7 | ❌ | ❌ | ❌ | Raciocínio de código/Agent |
| Claude 4 Opus | ✅ | ❌ | ❌ | Geral + textos longos + código |
| GPT-5 | ✅ | ✅ | ✅ | Multimodal geral |
| Gemini 3 Pro | ✅ | ✅ | ✅ | Multimodal + compreensão de UI |
| DeepSeek-R1 | ❌ | ❌ | ❌ | Raciocínio matemático |
| Qwen3-VL | ✅ | ✅ | ❌ | Multimodal de código aberto |
Como se pode observar, o "padrão multimodal" concentra-se principalmente no campo dos modelos proprietários. No campo de código aberto e de custo-benefício, a especialização em texto continua sendo uma rota de diferenciação eficaz.

IV. Sem visão nativa, como fazer o MiniMax M2.7 processar imagens
Embora o M2.7 não processe imagens nativamente, através de chamadas de ferramentas e roteamento, é perfeitamente possível construir uma arquitetura híbrida de "M2.7 como controlador + modelo visual colaborativo". Isso permite aproveitar o baixo custo do M2.7 sem sacrificar a experiência multimodal.
4.1 Arquitetura de chamada híbrida recomendada
A prática mais comum é utilizar um gateway unificado (como o roteamento de múltiplos modelos oferecido pela APIYI em apiyi.com) para distribuir as solicitações de acordo com o tipo de conteúdo. As solicitações de texto/código seguem para o M2.7, enquanto as solicitações de imagem são enviadas para o Claude 4 ou Gemini 3, retornando o texto gerado pelo modelo visual para que o M2.7 realize o raciocínio e a tomada de decisão final. Essa arquitetura é transparente para o front-end e não exige alterações na forma como o SDK é chamado no lado do negócio.
4.2 Integração de modelos visuais via Function Calling
Se a sua aplicação utiliza Function Calling, você pode registrar uma ferramenta analyze_image para o M2.7, que internamente chama a interface visual do Claude/GPT/Gemini e retorna o resultado da análise em formato JSON. O M2.7 determinará automaticamente quando chamar essa ferramenta com base na solicitação do usuário, sem a necessidade de uma verificação explícita na camada de comando. Esse modelo é ideal para frameworks de agentes (como LangGraph, CrewAI ou OpenAI Agents SDK).
🎯 Sugestão de integração: Recomendamos utilizar um
base_urlda APIYI (apiyi.com) para acessar simultaneamente o M2.7 e modelos multimodais (como Claude 4 Opus, Gemini 3 Pro). Isso evita a manutenção de SDKs e chaves API separadas para cada fornecedor, reduzindo drasticamente a complexidade de engenharia da arquitetura híbrida e facilitando o monitoramento unificado do consumo de tokens e custos.
4.3 Parâmetros de inferência recomendados
A MiniMax recomenda oficialmente o uso de parâmetros de amostragem relativamente altos para o M2.7: temperature=1.0, top_p=0.95, top_k=40. Isso difere da recomendação de baixa temperatura da maioria dos modelos. Testes práticos mostram que, em cenários de codificação e agentes, esse conjunto de parâmetros produz código de maior qualidade e mais criativo. Se o seu modelo de comando anterior utilizava temperature=0 por padrão, você pode obter resultados rígidos ou repetitivos no M2.7, sendo necessário realizar um novo ajuste fino.
V. Decisão de seleção: MiniMax M2.7 vs. Modelos Multimodais
Quando escolher o M2.7 e quando optar por um modelo multimodal de ponta? O ponto principal é verificar se sua aplicação é "focada em texto/código" ou "focada em multimodal", em vez de apenas comparar qual tem mais parâmetros.
5.1 Cenários focados em texto/código: prefira o M2.7
Se mais de 90% das solicitações do seu produto são baseadas em texto (geração de código, perguntas e respostas sobre documentos, orquestração de agentes, resumo de textos longos), o M2.7 é uma das opções com melhor custo-benefício atualmente. Os 230B de parâmetros totais oferecem um limite de capacidade próximo ao do Claude 4 Sonnet, mas o preço por token é apenas uma fração, o que é extremamente vantajoso para backends SaaS de alta concorrência.
5.2 Cenários multimodais de alta frequência: prefira Claude / Gemini
Se o seu cenário principal envolve compreensão de imagem (OCR, automação de UI, reconhecimento de produtos, assistência em imagens médicas), análise de vídeo ou processamento de áudio, escolher diretamente o Claude 4 Opus, GPT-5 ou Gemini 3 Pro será mais simples e confiável do que uma arquitetura híbrida de "M2.7 + modelo visual", reduzindo a latência e a taxa de falhas causadas por invocações entre modelos.
5.3 Sugestões de seleção por cenário
| Cenário de aplicação | Modelo prioritário | Alternativa |
|---|---|---|
| Geração / Refatoração de código | MiniMax M2.7 | Claude 4 Sonnet |
| Chamada de ferramentas por Agente | MiniMax M2.7 | GPT-5 |
| P&R de documentos longos (até 200K) | MiniMax M2.7 | Claude 4 Opus |
| OCR de imagem / P&R de capturas de tela | Gemini 3 Pro | Claude 4 Opus |
| Análise de vídeo | Gemini 3 Pro | GPT-5 |
| RAG multimodal | Claude 4 Opus | Gemini 3 Pro |
| Tarefas mistas (texto + poucas imagens) | Combinação M2.7 + modelo visual | Modelo único Claude 4 Opus |
🎯 Dica de seleção: A escolha do modelo não é sobre "quem é mais forte", mas sobre "quem melhor atende à distribuição das suas solicitações". Recomendamos realizar testes A/B com tráfego real na plataforma APIYI (apiyi.com), comparando o custo e a qualidade de diferentes modelos na mesma tarefa antes de definir a combinação principal.
VI. Perguntas frequentes sobre o MiniMax M2.7
6.1 O M2.7 realmente não consegue processar imagens?
Exatamente. Se você enviar arquivos de imagem (base64 ou URL) diretamente nas mensagens, a interface rejeitará ou retornará um erro. A única forma viável é usar primeiro outro modelo visual para converter a imagem em uma descrição de texto e, em seguida, passar essa descrição para o M2.7 realizar o raciocínio.
6.2 Qual a diferença entre o M2.7 e o M2.7-highspeed?
Ambos entregam os mesmos resultados, a diferença está apenas na velocidade de resposta. O M2.7-highspeed é ideal para cenários sensíveis à latência (como preenchimento de código em tempo real em IDEs), enquanto a versão padrão do M2.7 é ideal para tarefas assíncronas em lote. Ambas as versões podem ser alternadas pelo nome do modelo no painel da APIYI (apiyi.com), com total compatibilidade de parâmetros de interface.
6.3 O M2.7 é um modelo open source? Posso fazer deploy local?
Sim, o M2.7 é um modelo de pesos abertos e pode ser baixado no HuggingFace para auto-hospedagem. No entanto, são necessárias pelo menos 8 GPUs A100/H100 para suportar a janela de contexto de 200K. O custo de deploy local é muito superior ao da invocação via API; a menos que você tenha requisitos rigorosos de conformidade de dados, não recomendamos a auto-hospedagem.
6.4 O M2.7 é compatível com os SDKs oficiais da Anthropic / OpenAI?
Totalmente compatível. Você pode usar diretamente os SDKs oficiais anthropic ou openai, bastando apontar a base_url para o gateway do serviço proxy de API (como o endpoint de acesso unificado da APIYI.com) e alterar o nome do modelo. Não é necessário reescrever nenhuma lógica de negócio. Esta é a forma mais simples de implementar uma arquitetura híbrida.
6.5 Equipes com muitas demandas multimodais não deveriam considerar o M2.7?
Não necessariamente. Mesmo em aplicações multimodais, o raciocínio e a orquestração de texto ainda representam um grande volume de solicitações. Sugerimos deixar a parte multimodal para o Claude/Gemini e delegar a orquestração de texto e a tomada de decisão para o M2.7, o que pode reduzir significativamente o custo total de inferência. Se precisar de uma solução híbrida personalizada, entre em contato com a equipe comercial da APIYI.com para obter sugestões de arquitetura.
VII. Conclusão: O multimodal é a tendência, mas a "especialização" continua sendo uma rota eficaz
O fato de o MiniMax M2.7 não suportar entrada de imagens é tanto uma realidade quanto uma estratégia de produto deliberada. Em 2026, momento em que o multimodal se tornou o padrão para modelos topo de linha de código fechado, a MiniMax optou por concentrar todos os seus recursos de treinamento nas duas áreas mais diferenciadas: código e agentes. Isso resultou em uma capacidade de codificação próxima à do Claude 4 Sonnet, com um custo de inferência muito inferior.
Para os desenvolvedores, isso significa que a seleção de modelos não é mais uma comparação simples de "quem é mais versátil", mas sim "quem melhor se adapta à distribuição das suas requisições". Em cenários dominados por texto/código, o M2.7 continua sendo uma das opções com melhor custo-benefício atualmente; já em cenários de alta frequência multimodal, a tarefa deve ser delegada a especialistas como o Claude 4 Opus, GPT-5 ou Gemini 3. Combinar ambos através de um gateway unificado geralmente permite obter o melhor equilíbrio entre custo e desempenho.
Se você precisa integrar o M2.7 e os principais modelos multimodais sob o mesmo base_url, acesse a documentação oficial da APIYI em apiyi.com para conferir a lista completa de modelos e exemplos de integração.
Autor: Equipe APIYI — Fornecendo continuamente serviços estáveis e eficientes de serviço proxy de API e roteamento multimodelo para desenvolvedores de IA em todo o mundo. Para mais detalhes, visite apiyi.com