Mucha gente tiene una idea equivocada al usar la versión web de ChatGPT por primera vez: creen que al subir un PDF o escribir una frase, la IA "chasquea los dedos" y genera 5 imágenes con un estilo uniforme. Pero, en cuanto pasan a la API y ajustan el parámetro n a 5, lo que obtienen son 5 variantes aleatorias, casi idénticas, como si estuvieran jugando a una máquina tragaperras. ¿Por qué hay tanta diferencia con el mismo modelo?
Este artículo no pretende dar una respuesta única, sino desglosar este problema que nos encontramos constantemente en el soporte técnico. Vamos a aclarar las dos rutas técnicas completamente distintas detrás de la generación de imágenes en grupo con GPT, explicaremos por qué el parámetro n no sirve para crear "grupos de imágenes" reales y qué soluciones prácticas existen si quieres implementar consistencia entre múltiples imágenes usando la API.
I. Dos rutas técnicas para la generación de imágenes en grupo con GPT
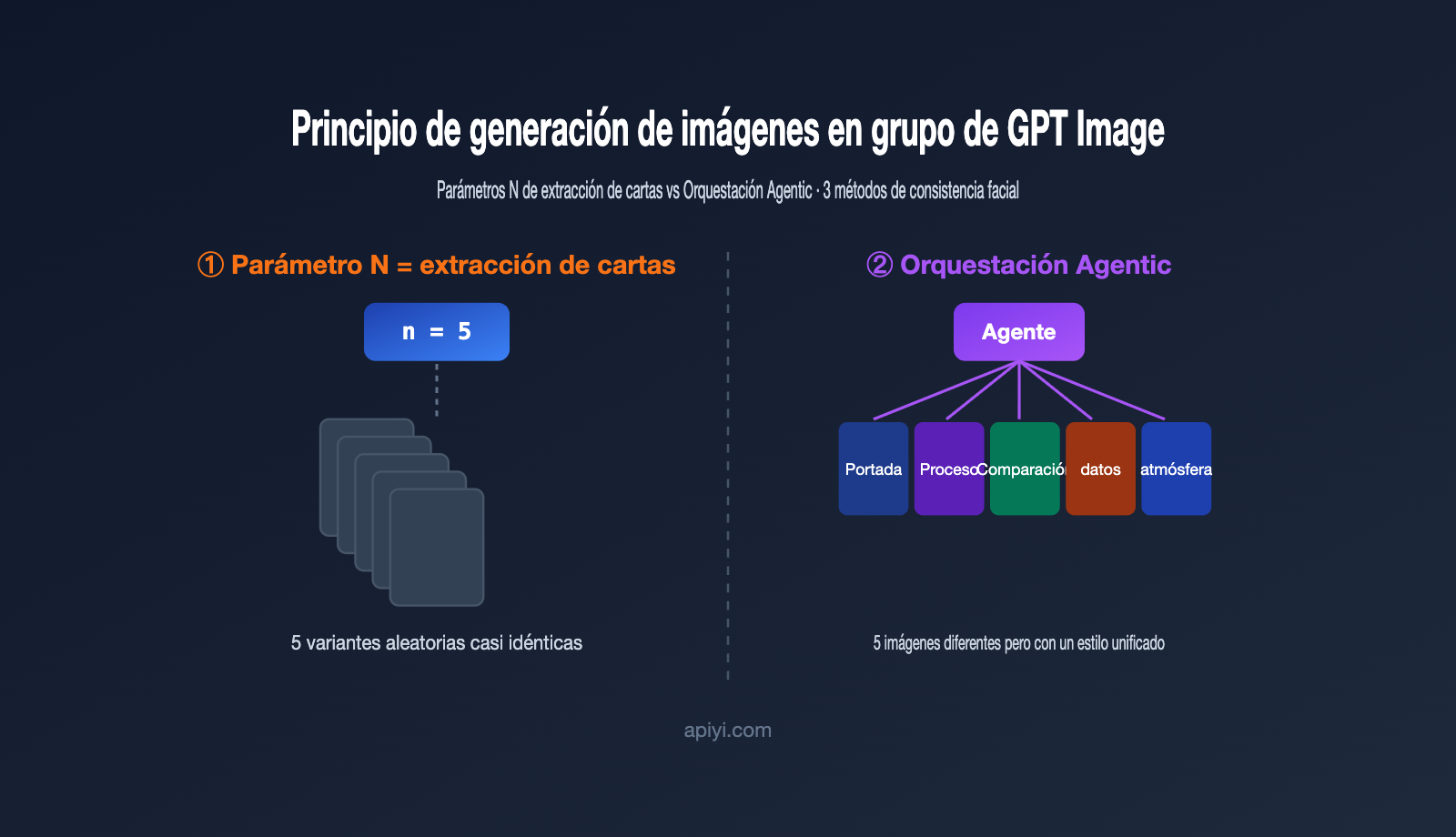
Para entender esto, primero debemos aceptar una premisa que suele pasarse por alto: "generar varias imágenes a la vez" y "generar un grupo de imágenes con relación lógica" son cosas distintas. Lo primero es solo un procesamiento por lotes, mientras que lo segundo es lo que realmente entendemos por "grupo".
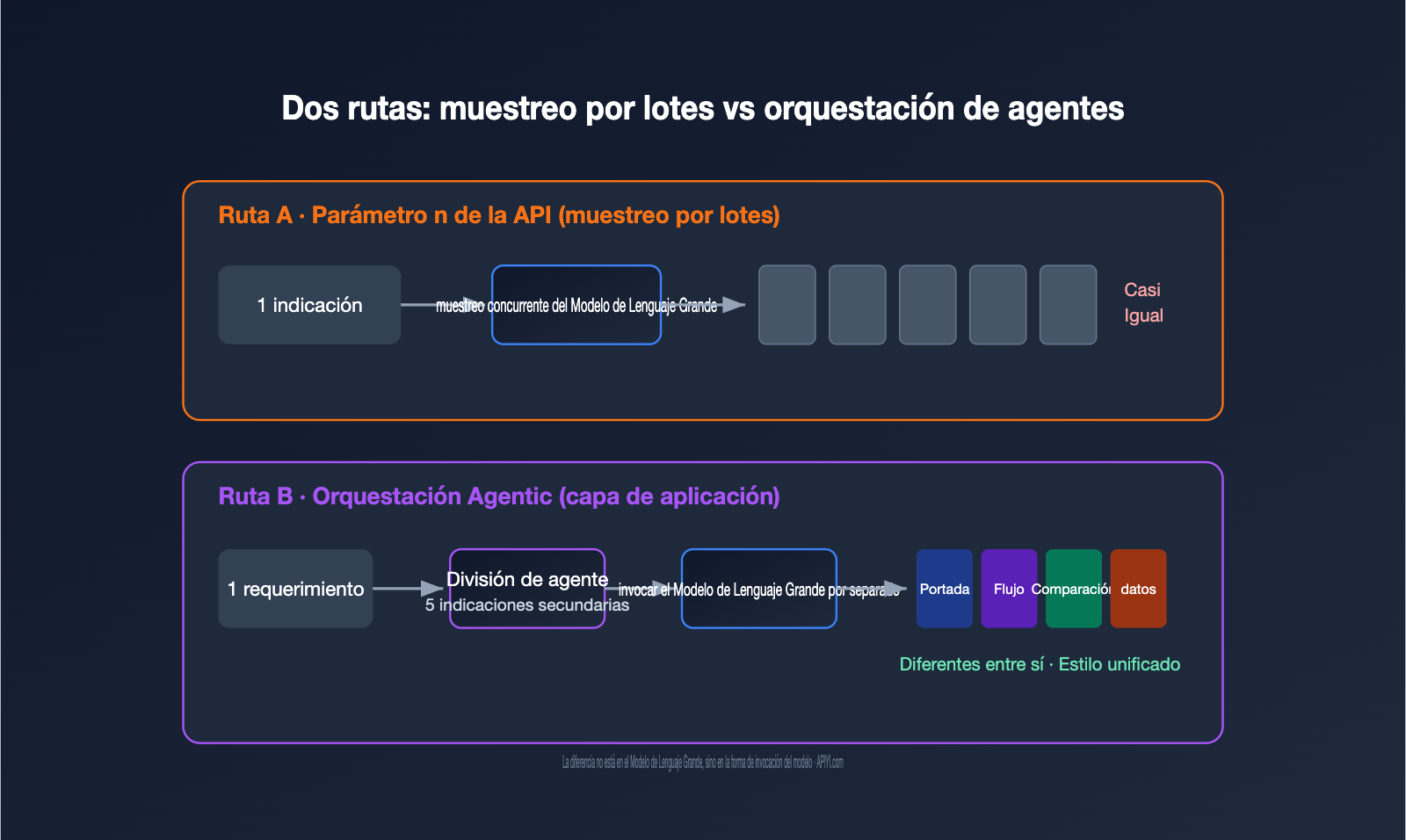
La generación de imágenes con GPT se implementa mediante dos rutas. La primera es el muestreo por lotes a nivel de modelo, es decir, el parámetro n en la API: con la misma indicación y la misma entrada, el modelo genera múltiples resultados en paralelo. La segunda es la orquestación mediante agentes (Agentic) a nivel de aplicación, donde un agente entiende la necesidad, la divide en varias subtareas, invoca la capacidad de generación por separado y finalmente las ensambla.
La siguiente tabla detalla las diferencias clave entre ambas rutas:
| Dimensión | Parámetro n de la API (muestreo por lotes) |
Orquestación Agentic (nivel de aplicación) |
|---|---|---|
| Esencia | Muestreo aleatorio repetido con la misma indicación | Generación independiente tras dividir la necesidad |
| Contenido por imagen | Casi idéntico, solo variaciones aleatorias | Diferente, pero con un tema relacionado |
| ¿Entiende el "grupo"? | No, es puramente concurrente | Sí, tiene una lógica de planificación |
| Coste | Precio por imagen × N | Suma de costes por cada invocación |
| Fuente de consistencia | Indicación y semilla aleatoria | Imagen de referencia + restricciones de indicación |
| Escenario típico | Seleccionar una imagen satisfactoria | Ilustraciones en serie, diapositivas, libros ilustrados |
En resumen, el parámetro n sirve para "dame varias opciones", mientras que un grupo de imágenes requiere "dame una serie de contenidos bajo un mismo tema". Por eso, al intentar replicar la experiencia de la web directamente mediante la API, siempre parece que falta algo. Si quieres probar el rendimiento real de ambas rutas, puedes usar tu clave API en APIYI (apiyi.com) para realizar pruebas sin tener que cambiar de plataforma.
二、为什么 API 的 n 参数做不出真正的组图
很多开发者的第一反应是:既然要 5 张图,那把 n 设成 5 不就行了?实际跑一遍就会发现,出来的 5 张图往往是「同一个东西的 5 个微小变体」,而不是「一组互相配合的图」。
原因在于 n 参数的工作机制。它并不会改变你的提示词,而是用同一个提示词再跑几遍,靠模型生成过程中的随机采样制造差异。OpenAI 开发者社区里有一句很贴切的描述:这些图来自「同一输入下随机采样产生的变化」(random sampling variations)。换句话说,这就是抽卡——同样的卡池,抽 5 次,卡面相似、稀有度随机。
这带来两个直接后果。其一,你无法在一次调用里表达「第一张画封面、第二张画流程、第三张画对比」这种结构化需求,因为提示词只有一个。其二,费用是线性叠加的:n=5 就是按 5 张图计费,而不是打包优惠。
下表用一个具体场景说明这个差异,假设你想为一篇文章生成 5 张不同用途的配图。
| 需求 | 用 n=5 的结果 | 你真正想要的 |
|---|---|---|
| 封面图 | 5 张都是封面候选 | 1 张封面 |
| 流程图 | 拿不到 | 1 张流程图 |
| 对比图 | 拿不到 | 1 张对比图 |
| 数据图 | 拿不到 | 1 张数据图 |
| 配图 | 拿不到 | 1 张氛围图 |
结论很清楚:n 参数适合「我要一张好图,多给几个候选让我挑」,不适合「我要一套内容不同的组图」。理解了这一点,就不会再纠结于「为什么 API 出不来网页版那种效果」——因为你用错了工具。想低成本验证 n 参数的抽卡特性,APIYI (apiyi.com) 支持按调用量计费,跑几组对比实验花不了多少钱。
三、网页版组图背后的 Agentic 编排原理
那 ChatGPT 网页版凭什么能「一个 PDF 出 5 张图」?答案就是上面提到的第二条路径——Agentic 编排,而这恰好是 2026 年 4 月发布的 GPT Image 2 / ChatGPT Images 2.0 带来的关键升级。
按照 OpenAI 的官方定位,GPT Image 2 是首个把「推理能力」内置进图像模型的版本:它在动笔之前会先研究、规划、推理图像结构(proactively researches, plans, and reasons),这套机制在网页端被称为 Thinking 模式。所以当你丢进去一份 PDF,模型不是简单地「读图」,而是先理解文档讲了什么、需要几张图、每张图分别承担什么角色,再逐张生成。
把这个过程翻译成工程语言,大致是四步:
- 理解与拆解: Agent 解析输入(文本、PDF、参考图),判断需要几张图、每张图的主题。
- 生成子提示词:为每张图各写一条独立的提示词,例如「整体架构图」「关键流程图」「数据对比图」。
- 逐张调用生图:对每条子提示词分别调用底层生图能力,本质上是多次 API 调用。
- 一致性约束:在每条提示词里注入统一的风格描述,并把前面生成的图作为参考图传给后面,保证整组视觉统一。
学术界也在用类似思路。多智能体框架(如视频生成里的 ViMax、文生图里的 Maestro)会把一个大需求拆成多个细粒度的视觉子问题,并行生成、择优选取,再把前一帧或前一张图作为后续生成的参考,以此维持角色和场景的连贯。GPT Image 2 的过人之处,是把这套原本要工程师手搭的编排,收进了模型自身的推理回路里。
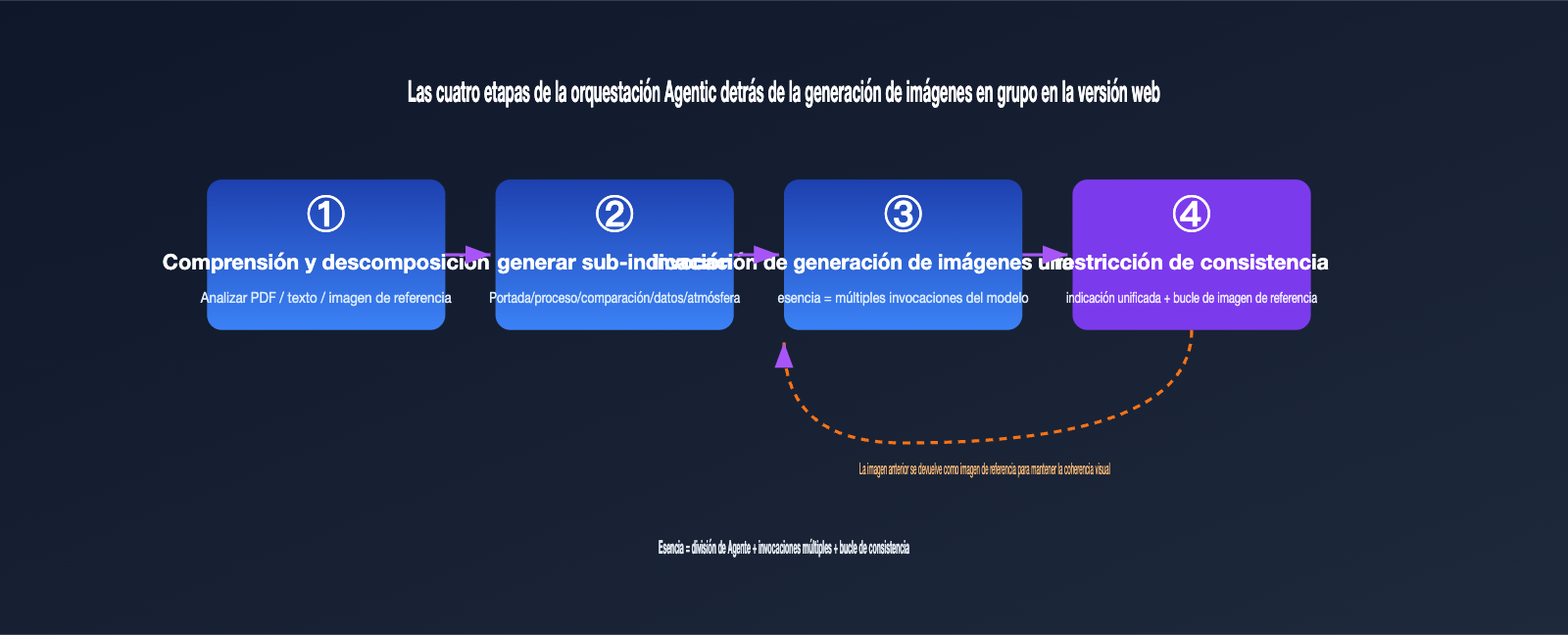
这里也藏着真正的难点:多次独立调用天然会漂移。每一张图都是一次新的随机采样,角色长相、配色、画风都可能跑偏。这就是我们和客户聊到的那个核心问题——「如何保持视觉一致性」,它比「如何出多张图」难得多。下一节就专门讲怎么对付它。
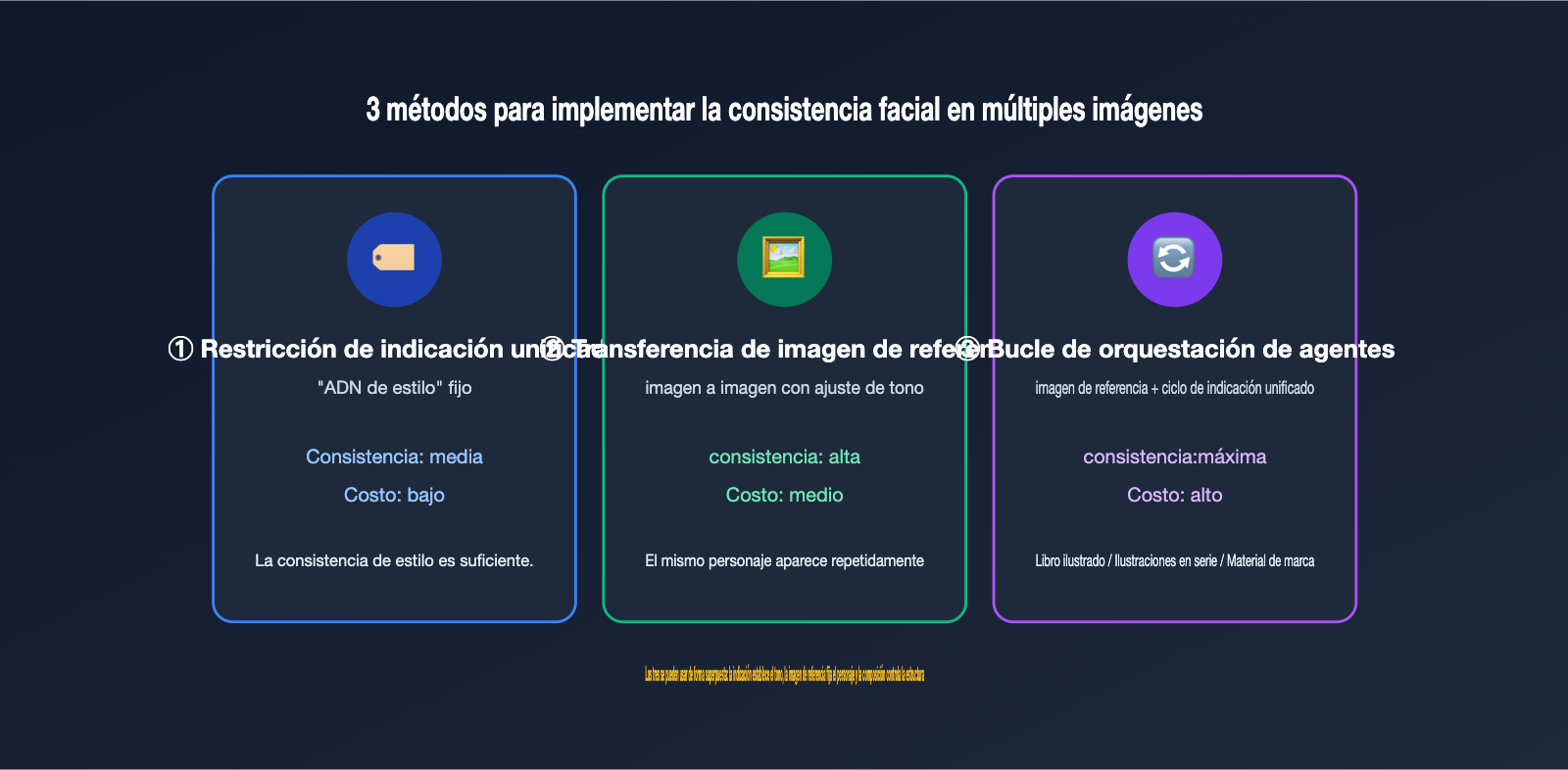
IV. Reproducción de series de imágenes con API: 3 métodos para lograr consistencia en múltiples imágenes
Si no quieres depender de la versión web y prefieres implementar la generación de series de imágenes con GPT Image en tu propio producto, tendrás que construir tu propia lógica de orquestación. El núcleo del asunto es utilizar técnicas de ingeniería para recuperar esa "consistencia visual". Basándonos en la práctica, hemos resumido tres métodos que van de lo más sencillo a lo más avanzado y que pueden combinarse entre sí.
Método 1: Restricción mediante indicaciones unificadas (Tabla de descripción de personajes). La forma más económica es escribir un "ADN de estilo" fijo para toda la serie y adjuntarlo tal cual en cada llamada. Por ejemplo: "estilo de ilustración plana, colores principales azul oscuro y ámbar, personaje: ingeniera con cabello corto". En la comunidad, esta descripción fija se llama character bible (biblia de personajes); cuanto más específica sea la descripción, mayor será la consistencia entre imágenes.
Método 2: Transferencia de imagen de referencia (imagen a imagen). Toma la primera imagen con la que estés satisfecho y pásala como imagen de referencia en cada llamada posterior. GPT Image 2 puede recibir múltiples imágenes de referencia en escenarios de edición/referencia (la documentación oficial indica hasta 16 imágenes, aunque esto depende de las pruebas en la plataforma). Esto convierte a la "definición de estilo mediante imagen" en el pilar de la consistencia. Suele ser más estable que la descripción puramente textual, especialmente para detalles como los rasgos faciales del personaje.
Método 3: Orquestación de agentes + bucle de imagen de referencia. Combina los dos métodos anteriores en un ciclo: primero generas una imagen base, y luego cada imagen subsiguiente se genera utilizando la imagen base + la indicación unificada; si es necesario, puedes incluir también la imagen anterior como referencia. Esto es exactamente lo que hace el modo Thinking de la versión web, solo que tú lo escribes explícitamente en el código.
A continuación, se muestra un ejemplo simplificado de orquestación que ilustra la lógica básica de "generar primero la imagen base y luego generar la serie utilizando imágenes de referencia".
from openai import OpenAI
# base_url apunta a APIYI, gestionando de forma unificada las claves API de múltiples modelos
client = OpenAI(base_url="https://api.apiyi.com/v1", api_key="YOUR_KEY")
STYLE = "estilo de ilustración plana, colores principales azul oscuro y ámbar, personaje: ingeniera con cabello corto" # Tabla de descripción de personajes
shots = ["Portada: personaje frente a un centro de datos", "Proceso: personaje dibujando arquitectura en una pizarra", "Resumen: personaje levantando el pulgar"]
# 1. Generar primero la imagen base para fijar el estilo de toda la serie
base = client.images.generate(model="gpt-image-2", prompt=f"{shots[0]},{STYLE}")
# 2. Cada imagen posterior lleva la restricción de estilo unificada (en avanzado, se puede añadir la base como imagen de referencia en la interfaz de edición)
for shot in shots[1:]:
img = client.images.generate(model="gpt-image-2", prompt=f"{shot},{STYLE}")
# save(img) ...
Para ayudarte a decidir rápidamente, la siguiente tabla compara las características y escenarios de uso de estos tres métodos.
| Método | Intensidad de consistencia | Coste de implementación | Escenario de uso |
|---|---|---|---|
| Restricción de indicación unificada | Media | Bajo | Estilo unificado, sin requisitos estrictos de personaje |
| Transferencia de imagen de referencia | Alta | Medio | Mismo personaje/producto apareciendo repetidamente |
| Bucle de orquestación de agentes | Máxima | Alto | Libros ilustrados, series de ilustraciones, materiales de marca |
Los tres métodos pueden combinarse: usa la indicación para establecer el tono, la imagen de referencia para fijar al personaje y la orquestación para controlar la estructura. Recomendamos empezar con "indicación unificada + imagen de referencia" y, una vez que funcione, pasar a la orquestación completa. En APIYI (apiyi.com), modelos como gpt-image-2 y gpt-image-1.5 comparten el mismo base_url y clave API, lo que facilita cambiar de modelo para realizar pruebas de comparación de consistencia sin modificar el código.
V. Costes y selección de modelos para la generación de series de imágenes con GPT Image
Generar una serie implica múltiples llamadas, por lo que el coste se multiplica; elegir el modelo correcto es fundamental. Actualmente, la serie GPT Image cuenta con varios niveles en entornos de producción, cada uno con un enfoque distinto.
| Modelo | Posicionamiento | ¿Soporta orquestación de inferencia? | Escenario de serie ideal |
|---|---|---|---|
| gpt-image-2 | Insignia, inferencia integrada | Sí (Thinking) | Materiales de alta calidad, carteles con texto |
| gpt-image-1.5 | Insignia de generación anterior | Parcial | Equilibrio entre calidad y coste para producción masiva |
| gpt-image-1 | Clásico y estable | No | Ilustraciones convencionales de estilo simple |
| gpt-image-1-mini | Ligero y de bajo coste | No | Producción a gran escala, sin requisitos altos de calidad |
Debes ser consciente de los gastos: la generación de series se factura "por número de imágenes". Tomando como ejemplo 1024×1024, el precio por imagen varía desde unos pocos milis de dólar hasta más de dos (consulta las tarifas en tiempo real de la plataforma). Una serie de 5 imágenes cuesta lo que cuestan 5 imágenes. Si planeas producir miles, el coste será considerable, por lo que es necesario hacer estimaciones previas.
Nuestra recomendación: usa el modelo mini o niveles de menor calidad durante la fase de borrador para verificar rápidamente la composición y la consistencia, y utiliza gpt-image-2 para la versión final de alta calidad. Esta combinación de "prueba y error de bajo coste + acabado de alta calidad" permite mantener la factura bajo control mientras garantizas el resultado. APIYI (apiyi.com) ofrece un panel de control de uso unificado donde puedes ver claramente cuánto has gastado en la generación de series y qué modelos has utilizado, ideal para equipos que necesitan controlar sus costes.
VI. Preguntas frecuentes (FAQ)
Q1: ¿Puede la API generar un conjunto de imágenes diferentes de una sola vez?
No, el parámetro n no sirve para esto. n solo realiza un muestreo aleatorio (como sacar una carta al azar) con la misma indicación, por lo que el contenido es casi idéntico. La verdadera generación de conjuntos de imágenes requiere una orquestación a nivel de aplicación: dividir la solicitud, realizar múltiples invocaciones y aplicar restricciones de consistencia.
Q2: ¿Qué tecnología oculta utiliza la versión web de ChatGPT para generar conjuntos de imágenes?
No es ninguna tecnología oculta, es que GPT Image 2 tiene integrado el razonamiento de agentes (Agentic). Antes de generar, planifica "cuántas imágenes se necesitan y qué debe mostrar cada una" y luego las genera una por una. En esencia, sigue siendo una serie de invocaciones múltiples, solo que el proceso de planificación es transparente para el usuario.
Q3: ¿Cuál es el método más efectivo para lograr la consistencia entre varias imágenes?
En la práctica, pasar una imagen de referencia es lo más estable: utiliza la primera imagen que te satisfaga como referencia para cada invocación posterior; la fidelidad del personaje y la combinación de colores es notablemente superior a la descripción puramente textual. Si además añades una descripción de estilo fija, el resultado es aún mejor. Puedes probar directamente la interfaz de imagen de referencia de gpt-image-2 en APIYI (apiyi.com).
Q4: ¿Es muy costoso generar conjuntos de imágenes?
Depende del número de imágenes, la resolución y el nivel de calidad, ya que se factura por imagen. Se recomienda usar modelos ligeros para los borradores y modelos insignia para la versión final, además de monitorear el gasto a través del panel de uso de la plataforma.
Q5: ¿Qué modelo es más rentable para generar conjuntos de imágenes?
Si buscas calidad y renderizado de texto, elige gpt-image-2; para equilibrar el costo, elige gpt-image-1.5; para grandes volúmenes con requisitos bajos, puedes usar gpt-image-1-mini. Al compartir un conjunto de interfaces, cambiar de modelo no tiene prácticamente ningún costo.
VII. Conclusión
Volviendo a la pregunta inicial: con el mismo modelo, la API parece una lotería mientras que la versión web puede generar conjuntos de imágenes; la diferencia no está en el modelo, sino en el método de invocación. El parámetro n es un muestreo por lotes a nivel de modelo que resuelve el problema de "dar varias opciones"; la verdadera generación de conjuntos de imágenes con GPT Image es una orquestación de agentes a nivel de aplicación, lograda mediante la división de necesidades, múltiples invocaciones y restricciones de consistencia.
Dentro de esto, la consistencia entre imágenes sigue siendo el eslabón más difícil. Afortunadamente, contamos con tres herramientas útiles: una tabla de descripción de personajes unificada para establecer el tono, la transferencia de imágenes de referencia para fijar los personajes y un bucle de orquestación de agentes para controlar la estructura. La combinación de los tres permite acercarse bastante a la experiencia de la versión web. El valor de GPT Image 2 reside precisamente en haber integrado esta capacidad de orquestación en el ciclo de razonamiento del modelo, permitiendo que cualquier usuario pueda disfrutar de ella.
Este tema no tiene necesariamente una respuesta estándar; es más bien un intercambio de experiencias, y espero que te ayude a evitar algunos rodeos. Si quieres poner a prueba cada uno de los métodos mencionados, APIYI (apiyi.com) ofrece una interfaz unificada y un panel de uso para modelos como gpt-image-2 y gpt-image-1.5, siendo un punto de partida conveniente para experimentar con conjuntos de imágenes y comparar costos. Para más detalles sobre la integración, puedes consultar el centro de ayuda en help.apiyi.com.
Este artículo es un contenido de debate preparado por el equipo técnico de APIYI basado en la práctica de soporte al cliente. Por favor, toma las especificaciones y precios de los modelos como referencia según la información oficial y de la plataforma en tiempo real.