Beaucoup d'utilisateurs qui découvrent la version web de ChatGPT ont une illusion tenace : ils pensent qu'en téléversant un PDF ou en écrivant une simple phrase, l'IA va « hop », générer instantanément 5 images au style parfaitement cohérent. Pourtant, dès qu'ils passent par l'API et règlent le paramètre n sur 5, ils obtiennent 5 variantes aléatoires qui se ressemblent comme deux gouttes d'eau, un peu comme un tirage au sort. Pourquoi une telle différence avec un même modèle ?
Cet article ne cherche pas à donner une réponse toute faite, mais plutôt à décortiquer ce problème que nous rencontrons régulièrement dans le support client. Nous allons clarifier les deux approches techniques radicalement différentes derrière la génération d'images par GPT, expliquer pourquoi le paramètre n ne permet pas de créer de véritables « séries » d'images, et vous donner des pistes concrètes pour implémenter vous-même une cohérence visuelle via l'API.
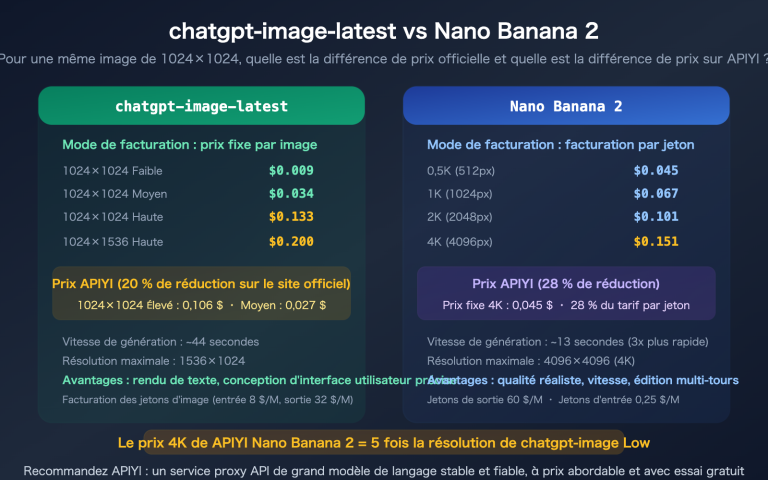
I. Les deux voies techniques de la génération d'images avec GPT
Pour comprendre ce phénomène, il faut d'abord admettre un prérequis souvent ignoré : « générer plusieurs images à la fois » et « générer une série d'images liées par une logique » sont deux choses différentes. La première n'est qu'une question de volume, la seconde est ce que l'on appelle réellement une « série ».
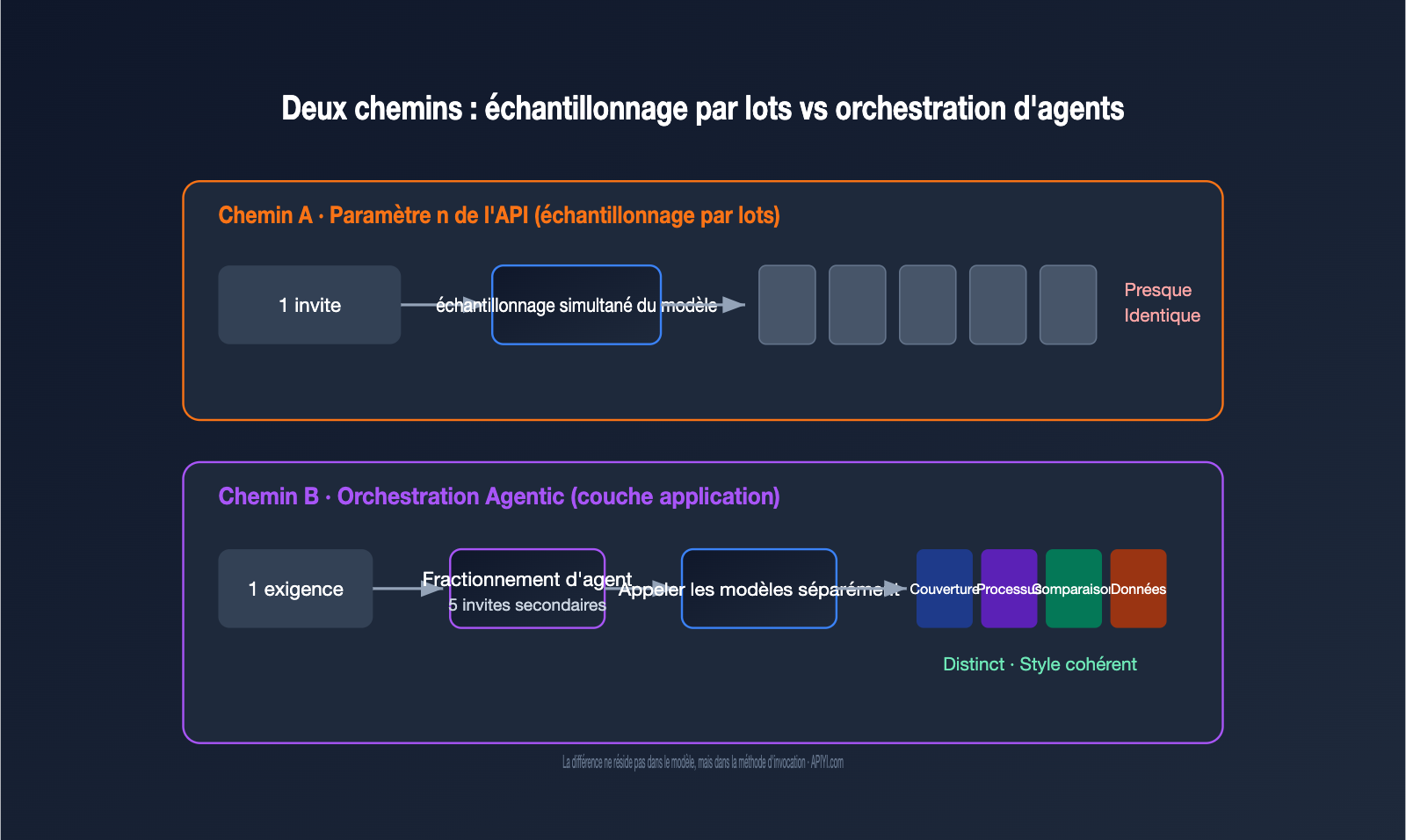
Au niveau de l'implémentation, GPT Image suit deux chemins. Le premier est l'échantillonnage par lots au niveau du modèle, c'est-à-dire le paramètre n de l'API : avec une même invite et une même entrée, on demande au modèle de générer plusieurs résultats en parallèle. Le second est l'orchestration par agent (Agentic) au niveau de l'application : un agent comprend le besoin, le divise en plusieurs sous-tâches, appelle la fonction de génération d'images pour chacune, puis les assemble.
Le tableau ci-dessous résume les différences fondamentales entre ces deux approches.
| Dimension | Paramètre n de l'API (échantillonnage) | Orchestration par agent (application) |
|---|---|---|
| Nature | Échantillonnage aléatoire répété | Générations indépendantes après segmentation |
| Contenu | Quasi identique, variations aléatoires | Différent, mais thématiquement lié |
| Logique de « série » | Aucune, purement concurrent | Oui, planification logique |
| Coût | Prix par image × N | Coût cumulé des appels |
| Cohérence | Invite + graine aléatoire | Image de référence + contraintes d'invite |
| Cas d'usage | Sélectionner la meilleure image | Illustrations, supports PPT, livres |
En résumé, le paramètre n sert à obtenir « plusieurs options », tandis qu'une série nécessite « une suite de contenus sur un même thème ». C'est pourquoi, en appelant directement l'API, on a souvent l'impression qu'il manque quelque chose par rapport à la version web. Si vous souhaitez tester ces deux approches, vous pouvez utiliser vos clés API sur APIYI (apiyi.com) pour comparer les résultats sans avoir à jongler entre plusieurs plateformes.
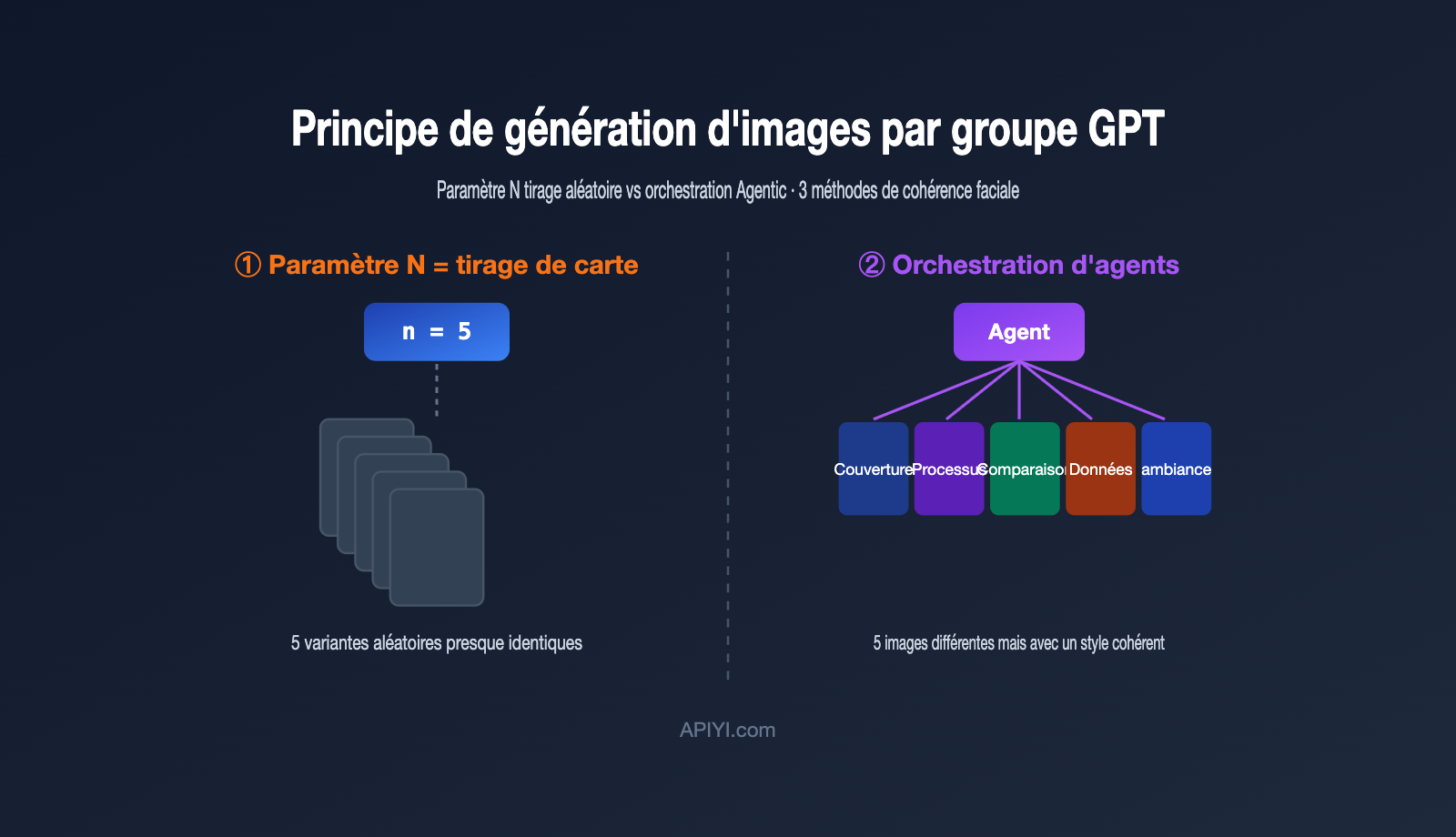
二、为什么 API 的 n 参数做不出真正的组图
很多开发者的第一反应是:既然要 5 张图,那把 n 设成 5 不就行了?实际跑一遍就会发现,出来的 5 张图往往是「同一个东西的 5 个微小变体」,而不是「一组互相配合的图」。
原因在于 n 参数的工作机制。它并不会改变你的提示词,而是用同一个提示词再跑几遍,靠模型生成过程中的随机采样制造差异。OpenAI 开发者社区里有一句很贴切的描述:这些图来自「同一输入下随机采样产生的变化」(random sampling variations)。换句话说,这就是抽卡——同样的卡池,抽 5 次,卡面相似、稀有度随机。
这带来两个直接后果。其一,你无法在一次调用里表达「第一张画封面、第二张画流程、第三张画对比」这种结构化需求,因为提示词只有一个。其二,费用是线性叠加的:n=5 就是按 5 张图计费,而不是打包优惠。
下表用一个具体场景说明这个差异,假设你想为一篇文章生成 5 张不同用途的配图。
| 需求 | 用 n=5 的结果 | 你真正想要的 |
|---|---|---|
| 封面图 | 5 张都是封面候选 | 1 张封面 |
| 流程图 | 拿不到 | 1 张流程图 |
| 对比图 | 拿不到 | 1 张对比图 |
| 数据图 | 拿不到 | 1 张数据图 |
| 配图 | 拿不到 | 1 张氛围图 |
结论很清楚:n 参数适合「我要一张好图,多给几个候选让我挑」,不适合「我要一套内容不同的组图」。理解了这一点,就不会再纠结于「为什么 API 出不来网页版那种效果」——因为你用错了工具。想低成本验证 n 参数的抽卡特性,APIYI (apiyi.com) 支持按调用量计费,跑几组对比实验花不了多少钱。
三、网页版组图背后的 Agentic 编排原理
那 ChatGPT 网页版凭什么能「一个 PDF 出 5 张图」?答案就是上面提到的第二条路径——Agentic 编排,而这恰好是 2026 年 4 月发布的 GPT Image 2 / ChatGPT Images 2.0 带来的关键升级。
按照 OpenAI 的官方定位,GPT Image 2 是首个把「推理能力」内置进图像模型的版本:它在动笔之前会先研究、规划、推理图像结构(proactively researches, plans, and reasons),这套机制在网页端被称为 Thinking 模式。所以当你丢进去一份 PDF,模型不是简单地「读图」,而是先理解文档讲了什么、需要几张图、每张图分别承担什么角色,再逐张生成。
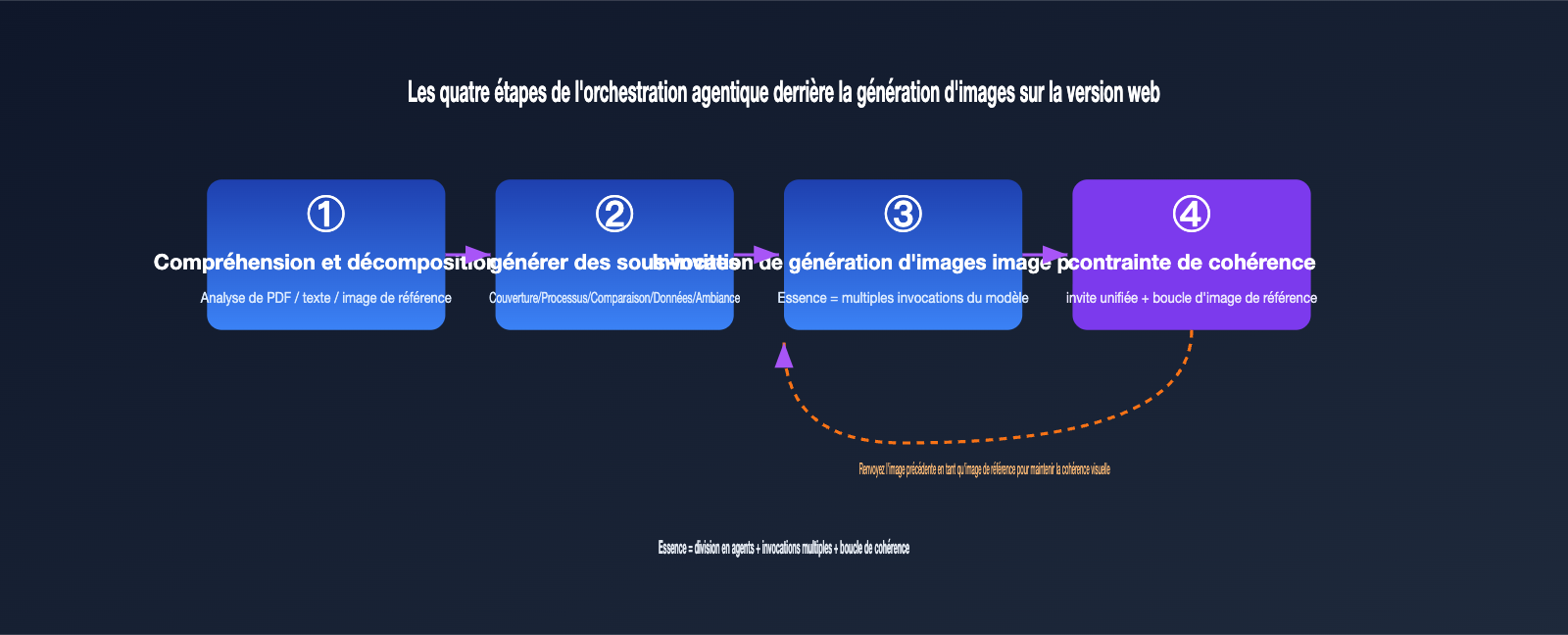
把这个过程翻译成工程语言,大致是四步:
- 理解与拆解: Agent 解析输入(文本、PDF、参考图),判断需要几张图、每张图的主题。
- 生成子提示词:为每张图各写一条独立的提示词,例如「整体架构图」「关键流程图」「数据对比图」。
- 逐张调用生图:对每条子提示词分别调用底层生图能力,本质上是多次 API 调用。
- 一致性约束:在每条提示词里注入统一的风格描述,并把前面生成的图作为参考图传给后面,保证整组视觉统一。
学术界也在用类似思路。多智能体框架(如视频生成里的 ViMax、文生图里的 Maestro)会把一个大需求拆成多个细粒度的视觉子问题,并行生成、择优选取,再把前一帧或前一张图作为后续生成的参考,以此维持角色和场景的连贯。GPT Image 2 的过人之处,是把这套原本要工程师手搭的编排,收进了模型自身的推理回路里。
这里也藏着真正的难点:多次独立调用天然会漂移。每一张图都是一次新的随机采样,角色长相、配色、画风都可能跑偏。这就是我们和客户聊到的那个核心问题——「如何保持视觉一致性」,它比「如何出多张图」难得多。下一节就专门讲怎么对付它。
IV. Créer des séries d'images avec l'API : 3 méthodes pour assurer la cohérence visuelle
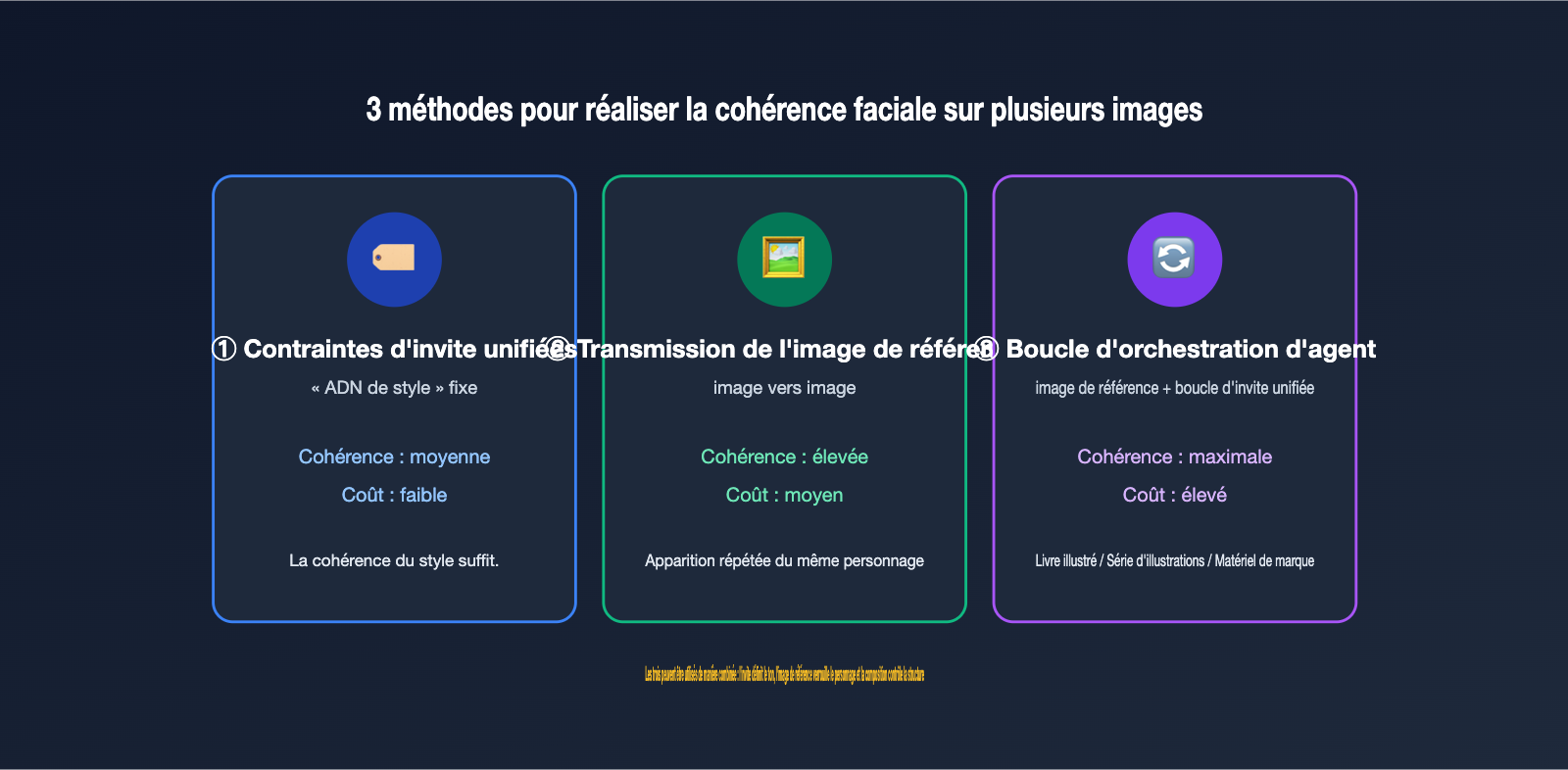
Si vous préférez ne pas dépendre de l'interface web et souhaitez intégrer la génération de séries d'images GPT Image directement dans votre produit, vous devrez concevoir votre propre logique d'orchestration. L'essentiel est d'utiliser des méthodes d'ingénierie pour compenser la « cohérence visuelle ». Sur la base de notre expérience, nous avons résumé trois méthodes, de la plus simple à la plus avancée, qui peuvent être combinées.
Méthode 1 : Contrainte par invite unifiée (Tableau de description des personnages). L'approche la plus économique consiste à rédiger une « ADN de style » fixe pour toute la série et à l'ajouter systématiquement à chaque invite. Par exemple : « Style illustration plate, couleurs dominantes bleu marine et ambre, personnage : ingénieure aux cheveux courts ». Dans la communauté, cette description fixe est appelée character bible (bible des personnages) ; plus la description est précise, plus la cohérence entre les images sera élevée.
Méthode 2 : Transmission d'image de référence (image vers image). Utilisez la première image générée, si elle vous satisfait, comme image de référence pour chaque appel ultérieur. GPT Image 2 peut accepter plusieurs images de référence dans des scénarios d'édition ou de référence (la documentation officielle indique jusqu'à 16 images, à vérifier selon la plateforme). Cela fait de la « définition du style par l'image » l'outil principal pour la cohérence d'une série. Le résultat est généralement plus stable qu'avec une description textuelle seule, surtout pour des détails comme les traits du visage.
Méthode 3 : Orchestration par Agent + Boucle de référence. Combinez les deux premières méthodes dans une boucle : générez d'abord une image de base, puis utilisez cette base + l'invite unifiée pour générer les suivantes, en incluant éventuellement l'image précédente comme référence si nécessaire. C'est exactement ce que fait le mode Thinking de l'interface web, mais vous l'écrivez explicitement dans votre code.
Voici un exemple simplifié d'orchestration illustrant la logique de base : « générer d'abord une image de référence, puis générer la série en s'appuyant sur cette référence ».
from openai import OpenAI
# base_url pointe vers APIYI, gestion unifiée des clés pour plusieurs modèles
client = OpenAI(base_url="https://api.apiyi.com/v1", api_key="VOTRE_CLE")
STYLE = "Style illustration plate, couleurs dominantes bleu marine et ambre, personnage : ingénieure aux cheveux courts" # Tableau de description
shots = ["Couverture : personnage devant un centre de données", "Processus : personnage dessinant une architecture sur un tableau blanc", "Résumé : personnage faisant un pouce levé"]
# 1. Générer d'abord l'image de base pour verrouiller le style de la série
base = client.images.generate(model="gpt-image-2", prompt=f"{shots[0]},{STYLE}")
# 2. Chaque image suivante conserve la contrainte de style unifiée (pour aller plus loin, on peut ajouter 'base' comme image de référence dans l'interface d'édition)
for shot in shots[1:]:
img = client.images.generate(model="gpt-image-2", prompt=f"{shot},{STYLE}")
# save(img) ...
Pour vous aider à choisir rapidement, le tableau ci-dessous compare les caractéristiques et les scénarios d'utilisation de ces trois méthodes.
| Méthode | Force de cohérence | Coût de mise en œuvre | Scénario d'utilisation |
|---|---|---|---|
| Contrainte par invite unifiée | Moyenne | Faible | Style uniforme suffisant, personnage non strict |
| Transmission d'image de référence | Élevée | Moyen | Personnage/produit récurrent |
| Orchestration par Agent | Très élevée | Élevé | Livres illustrés, séries d'illustrations, supports de marque |
Ces trois méthodes peuvent être cumulées : utilisez l'invite pour définir le ton, l'image de référence pour verrouiller le personnage, et l'orchestration pour contrôler la structure. Nous vous conseillons de commencer par « Invite unifiée + Image de référence » avant de passer à une orchestration complète. Sur APIYI (apiyi.com), les modèles gpt-image-2, gpt-image-1.5, etc., partagent la même base_url et la même clé API, ce qui facilite les tests de cohérence en changeant de modèle sans modifier votre code.
V. Coûts et choix du modèle pour la génération de séries d'images
La génération de séries implique des appels multiples, ce qui multiplie les coûts. Il est donc crucial de choisir le bon modèle. Voici les options courantes pour la production avec la gamme GPT Image :
| Modèle | Positionnement | Supporte l'orchestration | Scénario idéal |
|---|---|---|---|
| gpt-image-2 | Flagship, raisonnement intégré | Oui (Thinking) | Matériel de haute qualité, affiches avec texte |
| gpt-image-1.5 | Flagship génération précédente | Partiel | Équilibre qualité/coût pour la production en masse |
| gpt-image-1 | Classique et stable | Non | Illustrations standards au style simple |
| gpt-image-1-mini | Léger et économique | Non | Gros volumes, exigences de qualité modérées |
Soyez conscient d'une chose : la génération de séries est facturée « au nombre d'images ». Pour du 1024×1024, le prix unitaire varie selon la qualité (vérifiez les tarifs officiels en temps réel). Une série de 5 images coûte le prix de 5 images. Si vous prévoyez de produire des milliers d'images, le coût sera significatif ; une estimation préalable est donc indispensable.
Notre conseil : utilisez le modèle mini ou une qualité inférieure lors de la phase de brouillon pour valider rapidement la composition et la cohérence, puis utilisez gpt-image-2 pour la version finale. Cette combinaison « essai à faible coût + finalisation haute qualité » permet de maîtriser votre facture tout en garantissant le résultat. APIYI (apiyi.com) propose un tableau de bord de consommation unifié, idéal pour les équipes qui doivent surveiller leurs coûts.
VI. FAQ – Questions fréquentes
Q1 : Est-il possible de générer un groupe d'images différentes en une seule fois via l'API ?
Non, le paramètre n ne suffit pas. Il ne sert qu'à effectuer un échantillonnage aléatoire (comme un tirage au sort) pour une même invite, ce qui donne des résultats quasi identiques. Pour obtenir un véritable groupe d'images, vous devez passer par une orchestration au niveau de l'application : diviser la demande, effectuer plusieurs invocations, puis appliquer des contraintes de cohérence.
Q2 : Quelle est la « magie » derrière la génération de groupes d'images sur la version web de ChatGPT ?
Ce n'est pas de la magie, mais l'intégration du raisonnement agentique (Agentic) dans GPT Image 2. Avant de générer, le modèle planifie le nombre d'images nécessaires et le contenu de chacune, puis les génère une par une. Il s'agit toujours, par essence, d'invocations multiples, mais le processus de planification est transparent pour l'utilisateur.
Q3 : Quelle est la méthode la plus efficace pour garantir la cohérence entre plusieurs images ?
En pratique, l'utilisation d'une image de référence est la solution la plus stable : transmettez la première image satisfaisante comme référence à chaque invocation suivante. La fidélité des personnages et de la palette de couleurs est nettement supérieure à une simple description textuelle. Ajoutez-y une description de style fixe pour de meilleurs résultats. Vous pouvez tester cela directement via l'interface d'image de référence de gpt-image-2 sur APIYI (apiyi.com).
Q4 : La génération de groupes d'images est-elle coûteuse ?
Cela dépend du nombre d'images, de la résolution et du niveau de qualité, car la facturation se cumule par image. Nous vous conseillons d'utiliser des modèles légers pour les brouillons et des modèles phares pour les versions finales, tout en surveillant vos dépenses via le tableau de bord de consommation de la plateforme.
Q5 : Quel modèle est le plus rentable pour générer des groupes d'images ?
Pour la qualité et le rendu de texte, choisissez gpt-image-2 ; pour un bon équilibre des coûts, optez pour gpt-image-1.5 ; pour de gros volumes avec des exigences moindres, gpt-image-1-mini est idéal. Comme ils partagent la même interface, le changement de modèle est quasi instantané.
VII. Conclusion
Revenons à la question initiale : avec un même modèle, pourquoi l'API semble-t-elle limitée au tirage aléatoire alors que la version web produit des groupes cohérents ? La différence ne réside pas dans le modèle, mais dans la méthode d'invocation. Le paramètre n est un échantillonnage par lots au niveau du modèle, utile pour obtenir plusieurs candidats ; la véritable génération de groupes d'images GPT Image est une orchestration agentique au niveau de l'application, obtenue par la décomposition des besoins, des invocations multiples et des contraintes de cohérence.
La cohérence entre les images reste le défi majeur. Heureusement, nous disposons de trois outils efficaces : une description de personnage unifiée pour définir le ton, l'utilisation d'une image de référence pour verrouiller le personnage, et une boucle d'orchestration par agent pour contrôler la structure. La combinaison de ces trois éléments permet de se rapprocher de l'expérience offerte par la version web. La valeur ajoutée de GPT Image 2 réside précisément dans l'intégration de cette capacité d'orchestration au cœur du cycle d'inférence du modèle.
Ce sujet n'a pas de réponse unique, il s'agit plutôt d'un partage d'expérience — en espérant que cela vous évitera quelques détours. Si vous souhaitez tester les méthodes présentées, APIYI (apiyi.com) propose une interface unifiée et un tableau de bord de suivi pour les modèles gpt-image-2, gpt-image-1.5, etc. C'est un point de départ pratique pour vos expérimentations et vos analyses de coûts. Pour plus de détails sur l'intégration, consultez le centre d'aide sur help.apiyi.com.
Cet article est une synthèse technique préparée par l'équipe d'APIYI sur la base de nos pratiques de support client. Veuillez vous référer aux informations officielles et à celles de la plateforme pour les spécifications des modèles et les tarifs en vigueur.