O conhecimento dos modelos tem uma data de corte, mas os problemas de negócios reais geralmente exigem dados "atuais". A Anthropic lançou oficialmente a ferramenta nativa
web_searchpara o Claude em 2025, e em 2026 a atualizou para a versãoweb_search_20260209com suporte a filtragem dinâmica, transformando a pesquisa na web via API do Claude de um "trabalho manual complexo" para apenas "um parâmetro de linha única".
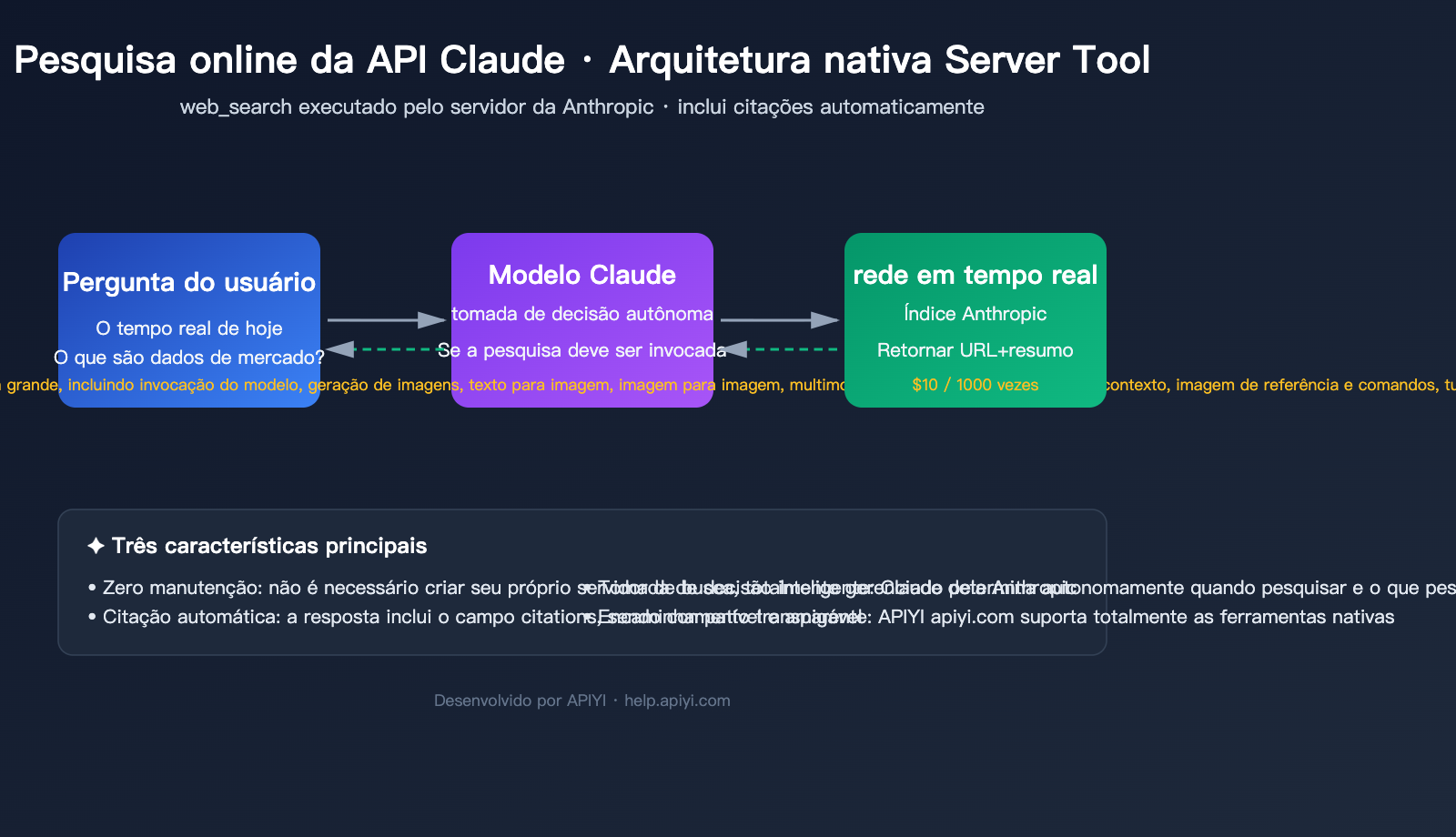
Este artigo organiza sistematicamente as soluções mais recentes para a pesquisa na web via API do Claude em 2026, focando nos parâmetros, cobrança, limitações e modelos de código das ferramentas oficiais web_search / web_fetch, além de comparar as abordagens de MCP de terceiros e RAG auto-hospedado. Ao final, apresentamos um exemplo de integração via serviço proxy de API da APIYI (apiyi.com), onde basta substituir a base_url e a chave API para executar todo o fluxo em ambiente local.
Pontos principais da pesquisa na web via API do Claude
Antes de colocar a mão na massa, vamos alinhar os conceitos. A pesquisa na web via API do Claude é, essencialmente, uma ferramenta de servidor (Server Tool) fornecida oficialmente pela Anthropic — isso significa que a pesquisa é executada na nuvem pela Anthropic; você não precisa conectar sua própria API do Google/Bing, nem implantar web scrapers.
Visão geral das três principais soluções
| Solução | Complexidade de Integração | Custo | Tempo Real | Citações e Conformidade |
|---|---|---|---|---|
web_search nativa oficial |
★☆☆ (um campo tool) | $10 / 1000 chamadas + token | Forte (índice em tempo real da Anthropic) | Citações automáticas |
| MCP de terceiros (ex: Brave/Tavily) | ★★☆ (requer servidor MCP) | Cobrança da API de busca de terceiros | Médio-Forte | Requer tratamento próprio |
| Auto-hospedado (Google CSE + invocação de ferramenta) | ★★★ (ferramenta personalizada + parsing) | Cota da API do Google | Médio | Totalmente autogerenciado |
🎯 Sugestão de escolha: Se o seu objetivo principal é "fazer com que o Claude responda sobre eventos recentes e complemente dados em tempo real", a
web_searchnativa oficial é a melhor escolha atual — zero manutenção, conformidade com citações e suporte a modelos principais como Sonnet 4.6 / Opus 4.7. Recomendamos a conexão direta via serviço proxy de API da APIYI (apiyi.com), permitindo acessar todos os recursos da interface oficial da Anthropic sem necessidade de VPN.
Matriz de modelos com suporte à pesquisa na web via API do Claude
Nem todos os modelos Claude suportam web_search. A nova versão web_search_20260209 possui requisitos claros para os modelos:
| Modelo | Versão básica web_search_20250305 |
Versão com filtragem dinâmica web_search_20260209 |
|---|---|---|
| Claude Opus 4.7 | ✅ | ✅ |
| Claude Opus 4.6 | ✅ | ✅ |
| Claude Sonnet 4.6 | ✅ | ✅ |
| Claude Sonnet 4.5 | ✅ | ❌ |
| Claude Haiku 4.5 | ✅ | ❌ |
A filtragem dinâmica (Dynamic Filtering) é a atualização principal da versão de 2026: o Claude filtrará os resultados da pesquisa usando uma ferramenta de execução de código antes de inseri-los na janela de contexto, mantendo apenas os trechos relevantes. Para recuperação de documentos longos e revisão de literatura técnica, isso pode reduzir significativamente o consumo de tokens.
Detalhando as ferramentas nativas oficiais de busca na web da Claude API
A Anthropic oferece duas ferramentas nativas complementares. Entender os limites de cada uma é o pré-requisito para utilizar bem a busca na web da Claude API.
A divisão de tarefas entre web_search e web_fetch
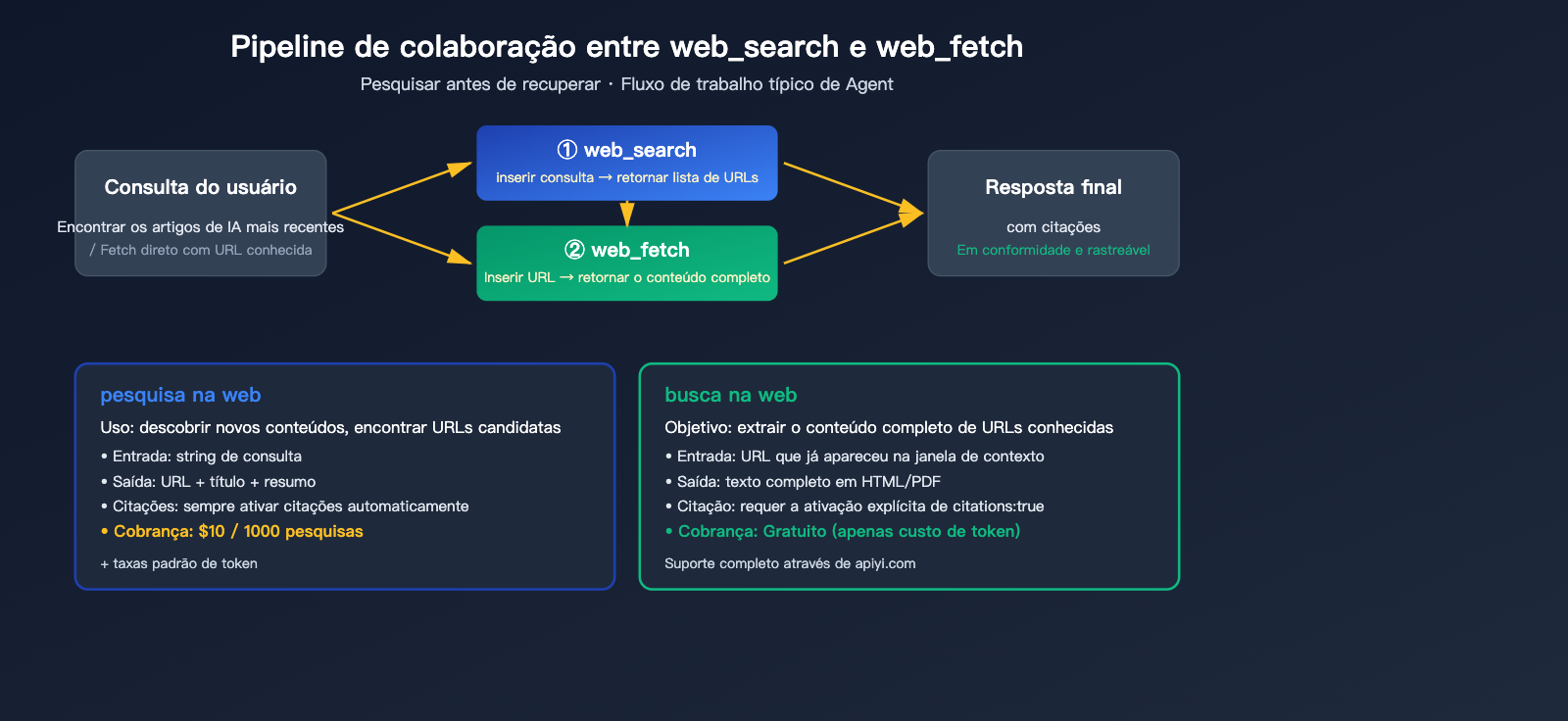
| Ferramenta | Uso | Entrada | Saída | Cobrança |
|---|---|---|---|---|
web_search |
Descobrir novos conteúdos | String de consulta | URL + Título + Resumo | $10 / 1000 chamadas |
web_fetch |
Extrair texto completo de URL conhecida | String de URL | HTML/PDF completo | Gratuito (apenas tokens) |
🎯 Dica de arquitetura: O fluxo de trabalho típico do agente é "primeiro busca, depois extrai" — o
web_searchencontra as páginas candidatas e oweb_fetchextrai o texto completo das mais relevantes. Se o usuário já forneceu uma URL (ex: "analise este artigo em example.com/artigo"), use diretamente oweb_fetch, sem consumir a cota de busca. Na APIYI (apiyi.com), ambas as ferramentas são suportadas de forma transparente, sem necessidade de configuração extra.
Definição completa dos parâmetros da ferramenta web_search
A tabela abaixo mostra a especificação oficial dos parâmetros JSON. Use-os conforme a necessidade:
| Parâmetro | Tipo | Obrigatório | Padrão | Descrição |
|---|---|---|---|---|
type |
string | ✅ | – | Fixo como web_search_20250305 ou web_search_20260209 |
name |
string | ✅ | – | Fixo como web_search |
max_uses |
integer | ❌ | Sem limite | Máximo de buscas permitidas por requisição |
allowed_domains |
string[] | ❌ | – | Apenas resultados destes domínios (excludente com blocked) |
blocked_domains |
string[] | ❌ | – | Proíbe resultados destes domínios |
user_location |
object | ❌ | – | Localização aproximada do usuário para busca local |
Estrutura do campo user_location:
{
"type": "approximate",
"city": "Shanghai",
"region": "Shanghai",
"country": "CN",
"timezone": "Asia/Shanghai"
}
Tratamento de erros na busca da Claude API
Quando a busca falha, a API da Anthropic ainda retorna HTTP 200, com a informação de erro embutida no corpo da resposta web_search_tool_result. Certifique-se de identificar estes códigos de erro no seu código cliente:
| Código de erro | Significado | Sugestão de tratamento |
|---|---|---|
too_many_requests |
Limite de taxa atingido | Tente novamente com backoff, reduza a concorrência |
max_uses_exceeded |
Excedeu o limite max_uses |
Aumente o limite ou divida a requisição |
query_too_long |
String de consulta muito longa | Trunque ou reescreva a consulta |
invalid_input |
Formato de parâmetro inválido | Verifique a estrutura JSON |
unavailable |
Erro interno da Anthropic | Tente novamente após um curto intervalo |
⚠️ Dica de cobrança: Requisições
web_searchcom erro não são cobradas. No entanto, se você já disparou uma busca bem-sucedida e depois ocorreu uma falha, a chamada bem-sucedida anterior ainda será cobrada a $10 / 1000 chamadas. Recomendamos verificar o detalhamento de consumo no painel da APIYI (apiyi.com) para identificar gastos anormais.
Primeiros passos com a busca na web da Claude API
A seguir, veja como rodar o fluxo completo com o mínimo de código. Todos os exemplos utilizam a interface de encaminhamento transparente da APIYI (apiyi.com) — você não precisa alterar nenhuma lógica de negócio, basta apontar a base_url para o nó de proxy e substituir a ANTHROPIC_API_KEY pela chave da APIYI.
Exemplo minimalista em cURL
Requisição mínima para a busca na web da Claude API:
curl https://vip.apiyi.com/v1/messages \
-H "x-api-key: $APIYI_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "Resuma em português quais são os modelos mais recentes lançados pela OpenAI em abril de 2026"}
],
"tools": [{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5
}]
}'
A estrutura de retorno conterá três blocos: o texto de decisão da Claude, server_tool_use (a consulta executada), web_search_tool_result (lista de URLs) e, finalmente, o texto da resposta com as citations.
Exemplo completo com SDK Python (incluindo uso conjunto com web_fetch)
import anthropic
client = anthropic.Anthropic(
base_url="https://vip.apiyi.com",
api_key="sk-sua-chave-apiyi",
)
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[{
"role": "user",
"content": "Encontre artigos sobre avaliação de AI Agents do último mês e faça um resumo detalhado do mais relevante"
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search"
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 3,
"citations": {"enabled": True}
}
]
)
for block in response.content:
if block.type == "text":
print(block.text)
elif block.type == "server_tool_use":
print(f"[Chamada de ferramenta] {block.name}: {block.input}")
🎯 Dica de código: Usamos aqui a combinação de filtragem dinâmica
web_search_20260209+web_fetch_20260209, que, com o Claude Opus 4.7, reduz significativamente o consumo de tokens em cenários de documentos longos. Se quiser apenas perguntas e respostas simples em tempo real, troque o modelo paraclaude-sonnet-4-6e use a versão básicaweb_search_20250305para reduzir custos. Todas as chamadas via APIYI (apiyi.com) mantêm a mesma estabilidade da oficial.
Exemplo em TypeScript / Node.js
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({
baseURL: "https://vip.apiyi.com",
apiKey: process.env.APIYI_API_KEY,
});
const response = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 2048,
messages: [
{ role: "user", content: "Como está o clima em Xangai hoje?" }
],
tools: [{
type: "web_search_20250305",
name: "web_search",
max_uses: 3,
user_location: {
type: "approximate",
city: "Shanghai",
region: "Shanghai",
country: "CN",
timezone: "Asia/Shanghai"
}
}]
});
console.log(response.content);
Processamento de resposta em streaming
Ao ativar stream: true, o processo de busca será enviado via eventos SSE em tempo real. Haverá uma "pausa" durante a execução da busca — isso ocorre porque a Claude está aguardando o servidor da Anthropic concluir a pesquisa:
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=2048,
messages=[{"role": "user", "content": "Consulte o preço mais recente do Claude 4.7"}],
tools=[{"type": "web_search_20250305", "name": "web_search", "max_uses": 2}]
) as stream:
for event in stream:
if event.type == "content_block_start":
block = event.content_block
if block.type == "server_tool_use":
print(f"\n[Buscando] a consulta começará a retornar via streaming...")
elif block.type == "web_search_tool_result":
print(f"[Busca concluída] {len(block.content)} resultados encontrados")
elif event.type == "content_block_delta":
if hasattr(event.delta, "text"):
print(event.delta.text, end="", flush=True)
Comparativo e Seleção de Soluções para Pesquisa na Web com a API do Claude
Após entendermos a interface oficial, vamos à tomada de decisão. Existem, na prática, três caminhos para realizar a pesquisa na web com a API do Claude, cada um adequado a diferentes cenários.

Solução A: web_search nativo oficial (Recomendado)
Vantagens:
- Sem manutenção: Não precisa de servidor próprio, tudo é gerenciado pela Anthropic.
- Citações automáticas: Cada resposta inclui
citationsautomaticamente, garantindo conformidade. - Integração total: O Claude decide autonomamente quando e o que pesquisar.
- Cobrança transparente: $10 por 1.000 requisições, unificado na fatura da Anthropic.
Desvantagens:
- Suporta apenas as fontes indexadas pela Anthropic (não é possível trocar o buscador).
- Algumas versões de modelo são limitadas (Haiku/Sonnet antigo suportam apenas a versão básica).
Cenários de uso: 90% dos agentes de conversação, assistentes de perguntas e respostas e tarefas de pesquisa.
Solução B: Serviço MCP de terceiros (Brave/Tavily/Serper, etc.)
Através do Model Context Protocol, você inicia um servidor MCP local ou remoto para injetar capacidades de busca no Claude:
# Exemplo com Tavily MCP, primeiro execute npm install -g @tavily/mcp-server
claude mcp add tavily-search npx -- @tavily/mcp-server
Vantagens:
- Liberdade para trocar o buscador (Brave focado em privacidade, Tavily focado em LLMs).
- Customizável: Você pode limpar os resultados ou adicionar metadados.
- Suporte nativo em clientes como Claude Code e Cursor.
Desvantagens:
- Requer manutenção extra do processo do servidor MCP.
- Os resultados da busca não geram automaticamente
citationsno padrão da Anthropic. - Você precisa gerenciar o consumo e a cobrança da API de busca de terceiros.
Cenários de uso: Se você já possui contas corporativas no Brave/Tavily ou tem necessidades específicas de customização do buscador.
Solução C: Ferramenta própria (Google CSE + Ferramenta Customizada)
A abordagem mais tradicional: você define uma tool, chama a API do Google Custom Search ou Bing no seu código backend e insere os resultados de volta nas messages:
tools = [{
"name": "google_search",
"description": "Pesquisar no Google e retornar os N principais resultados",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"}
},
"required": ["query"]
}
}]
Vantagens: Controle total, permitindo integração com buscas em intranets corporativas ou bases de conhecimento privadas.
Desvantagens: Você assume todo o trabalho de design de comando, ordenação de resultados, geração de citações e tratamento de erros. Além disso, o Claude não chamará a ferramenta "automaticamente" — é necessário guiá-lo explicitamente no system prompt.
Cenários de uso: Cenários corporativos com requisitos rigorosos de conformidade, customização ou necessidade de fontes de dados privadas.
Árvore de decisão das três soluções
| Sua necessidade | Solução recomendada |
|---|---|
| Quer implementar rápido, sem exigências específicas | Solução A web_search nativo |
| Precisa trocar o buscador (privacidade/conformidade) | Solução B MCP de terceiros |
| Precisa integrar fontes de dados privadas | Solução C Ferramenta própria + RAG |
| Acesso instável à Anthropic no Brasil | Solução A + serviço proxy de API APIYI |
🎯 Dica para desenvolvedores: A API oficial da Anthropic pode apresentar instabilidade em algumas regiões e exige registro com número de telefone internacional. Recomendamos o acesso via serviço proxy de API da APIYI (apiyi.com) — ele transmite integralmente todas as Server Tools da Anthropic (incluindo
web_search/web_fetch/code_execution). Seu código não precisa de nenhuma alteração, basta mudar abase_urlparahttps://vip.apiyi.come usar sua chave API da APIYI.
Usos avançados da pesquisa online na API do Claude
Lista de permissões de domínio: fazendo "pesquisa vertical"
Precisa que o Claude pesquise apenas em domínios específicos? Use allowed_domains:
tools=[{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"allowed_domains": [
"docs.python.org",
"pypi.org",
"github.com"
]
}]
Observe alguns limites:
allowed_domainseblocked_domainsnão podem ser usados simultaneamente.- Subdomínios são correspondências exatas:
docs.example.comnão incluiráapi.example.com. - As restrições de domínio no nível da solicitação devem ser compatíveis com as configurações da organização; não é possível ampliar o escopo definido pelos administradores da organização.
Habilitando citações com web_fetch
O web_search tem citações ativadas por padrão, mas o web_fetch precisa ser ativado explicitamente:
{
"type": "web_fetch_20250910",
"name": "web_fetch",
"max_uses": 5,
"citations": {"enabled": True},
"max_content_tokens": 50000
}
O max_content_tokens é usado para truncar documentos muito grandes, evitando que uma única busca estoure a janela de contexto. Valores de referência:
| Tipo de conteúdo | Tamanho | Aprox. tokens |
|---|---|---|
| Página web comum | 10 KB | ~2.500 |
| Documento grande | 100 KB | ~25.000 |
| PDF de pesquisa acadêmica | 500 KB | ~125.000 |
encrypted_content em conversas de múltiplos turnos
Cada resultado retornado pelo web_search traz um campo encrypted_content. Em conversas de múltiplos turnos, se você quiser que o Claude continue citando os resultados de pesquisa anteriores, deve reenviar este campo exatamente como está — caso contrário, os turnos subsequentes perderão o contexto das citações.
messages.append({
"role": "assistant",
"content": previous_response.content # Mantenha completo, incluindo encrypted_content
})
messages.append({
"role": "user",
"content": "Analise detalhadamente o segundo artigo encontrado anteriormente"
})
🎯 Dica de engenharia: Ao integrar com frameworks de agentes (como LangChain ou LlamaIndex), certifique-se de que o framework transmita todos os blocos de conteúdo da resposta do Claude — muitos frameworks "limpam" campos como
server_tool_use, fazendo com que as citações parem de funcionar. Recomendamos construir diretamente com o SDK da Anthropic e utilizar o serviço proxy de API APIYI (apiyi.com), garantindo um comportamento idêntico ao oficial.
Casos de uso práticos da pesquisa online na API do Claude
Agora que cobrimos a teoria, vejamos algumas combinações de melhores práticas para a pesquisa online na API do Claude em cenários reais de negócios.
Cenário 1: Assistente de notícias em tempo real
Se um usuário pergunta "Como está o mercado hoje?", dados em tempo real são essenciais. Estratégia de configuração:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system="Você é um assistente financeiro. Ao tratar de cotações ou notícias em tempo real, use sempre o web_search. As respostas devem conter citações.",
messages=[{"role": "user", "content": "Qual foi o fechamento do índice hoje? Como foi a variação?"}],
tools=[{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 3,
"allowed_domains": ["sina.com.cn", "eastmoney.com", "163.com"],
"user_location": {
"type": "approximate",
"country": "CN",
"timezone": "Asia/Shanghai"
}
}]
)
Dica: Use allowed_domains para restringir a sites financeiros autorizados e user_location para que o Claude priorize resultados em chinês.
Cenário 2: RAG aprimorado para documentação técnica
Ao responder perguntas técnicas, faça com que o Claude priorize a busca na documentação oficial:
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[{
"role": "user",
"content": "Como implementar o keep-alive de WebSocket no FastAPI? Me dê um exemplo completo"
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search",
"max_uses": 5,
"allowed_domains": [
"fastapi.tiangolo.com",
"docs.python.org",
"github.com",
"stackoverflow.com"
]
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 3,
"citations": {"enabled": True}
}
]
)
Dica: Use o filtro dinâmico do web_search_20260209 para remover HTML irrelevante e, em seguida, use o web_fetch para extrair o texto completo da documentação oficial mais relevante.
Cenário 3: Assistente de pesquisa acadêmica
Para cenários que exigem citações rigorosas e análise de contexto longo, recomendamos o Opus 4.7 com ferramentas duplas:
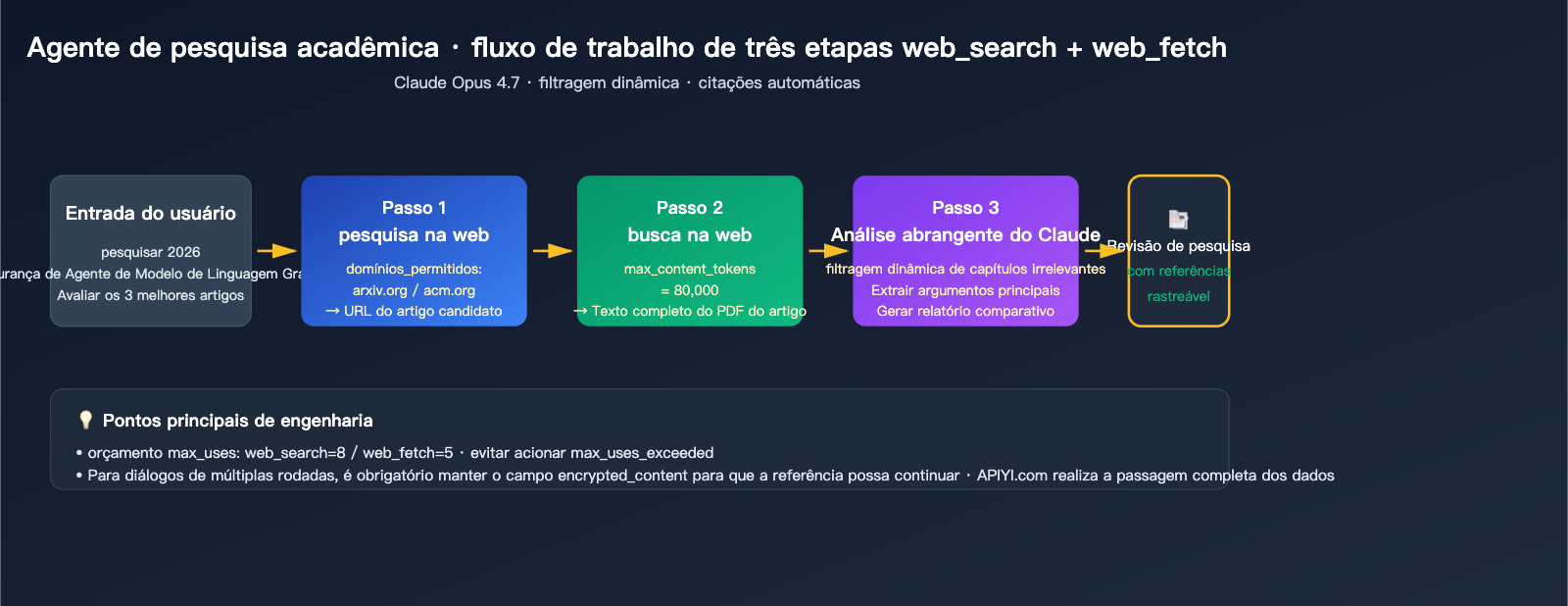
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=8192,
messages=[{
"role": "user",
"content": "Encontre artigos de 2026 sobre avaliação de segurança de agentes de IA, selecione os 3 principais e faça uma análise comparativa"
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search",
"max_uses": 8,
"allowed_domains": ["arxiv.org", "openreview.net", "acm.org"]
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 5,
"citations": {"enabled": True},
"max_content_tokens": 80000
}
]
)
🎯 Sugestão por cenário: Diferentes negócios possuem pesos distintos para qualidade de busca, conformidade de citações e custos. Recomendamos criar chaves API separadas para cada cenário de negócio no APIYI (apiyi.com), facilitando a divisão de dados de faturamento e o monitoramento do uso real de pesquisas e consumo de tokens, em vez de misturar todas as invocações.
Melhores práticas de engenharia para pesquisa na web com a API do Claude
Fazer um demo funcionar não é difícil, mas levar a pesquisa na web da API do Claude para um ambiente de produção exige superar alguns desafios.
Prática 1: Redução de custos e aumento de eficiência com prompt caching
Embora a definição da Server Tool seja curta, ela gera um custo fixo considerável quando combinada com o system prompt. Ative o prompt caching:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[{
"type": "text",
"text": "Você é um assistente de pesquisa profissional...(500 palavras de system prompt omitidas aqui)",
"cache_control": {"type": "ephemeral"}
}],
messages=[...],
tools=[
{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"cache_control": {"type": "ephemeral"}
}
]
)
Teste prático: para solicitações repetidas dentro de 5 minutos, o custo de tokens da parte de system + tools pode ser reduzido em até 90%.
Prática 2: Resposta em streaming para evitar timeouts
Uma única execução de web_search pode levar de 5 a 15 segundos. Se o seu downstream (gateway, cliente) tiver um limite de timeout de 30 segundos, certifique-se de ativar stream=True para manter a conexão ativa através de um heartbeat de streaming.
Prática 3: Consistência de múltiplas rodadas com encrypted_content
Em conversas de várias rodadas, o Claude pode citar resultados de pesquisas anteriores. Você deve manter o array de conteúdo completo de todas as mensagens anteriores do assistente em cada solicitação, não apenas a parte de texto:
# ❌ Prática incorreta
messages.append({"role": "assistant", "content": response.content[-1].text})
# ✅ Prática correta
messages.append({"role": "assistant", "content": response.content})
Prática 4: Limites de taxa e estratégia de retentativa
O limite de taxa do web_search é independente da interface de mensagens comum. Recomenda-se encapsular uma lógica de retentativa com backoff exponencial no nível do SDK:
| Código de erro | Estratégia de retentativa | Máximo de tentativas |
|---|---|---|
too_many_requests |
Backoff exponencial (2s/4s/8s) | 3 |
unavailable |
Atraso fixo (5s) | 2 |
max_uses_exceeded |
Não tentar novamente, aumente max_uses | – |
query_too_long |
Não tentar novamente, corte a query | – |
🎯 Dica para produção: Registre todas as respostas de erro do
web_searchem seu sistema de monitoramento de logs e analise periodicamente a proporção detoo_many_requests— este é o indicador principal para avaliar se a concorrência atual precisa de escalonamento. Ao utilizar a plataforma APIYI (apiyi.com), você pode verificar diretamente no painel a taxa de sucesso das solicitações, tempo médio de resposta e outros indicadores essenciais para a operação.
FAQ: Perguntas frequentes sobre a pesquisa na web da API do Claude
Q1: O serviço proxy de API da APIYI suporta o web_search nativo? Preciso alterar o código?
Sim, e não é necessário alterar o código. A APIYI (apiyi.com) utiliza uma arquitetura de encaminhamento transparente, transmitindo integralmente todas as Server Tools oficiais da Anthropic. Você só precisa alterar a base_url para https://vip.apiyi.com, substituir a chave API pela da APIYI, e o código que chamava a API oficial funcionará sem alterações — incluindo web_search / web_fetch / code_execution e todas as outras ferramentas nativas.
Q2: Como funciona a cobrança do web_search? US$ 10/1000 pesquisas é caro?
Cada pesquisa = US$ 0,01, independentemente de quantos resultados forem retornados. Pesquisas que falham não são cobradas. Comparação: Tavily US$ 0,005/pesquisa, Brave US$ 0,006/pesquisa, Google CSE US$ 0,005/consulta (após exceder a cota gratuita). O web_search nativo é um pouco mais caro, mas elimina os custos de engenharia com a manutenção de servidores MCP e conformidade de citações, o que geralmente é mais vantajoso para pequenas e médias equipes.
Q3: Por que minha solicitação retorna o erro max_uses_exceeded?
O Claude pode chamar o web_search várias vezes em uma única conversa (ele decide autonomamente quantas vezes pesquisar). Se você definiu "max_uses": 1 e a pergunta exige 3 pesquisas para ser respondida, esse erro será acionado. Recomendamos reservar um orçamento de 5 a 10 usos para perguntas complexas e 1 a 2 para perguntas simples.
Q4: O web_search consegue pesquisar páginas em chinês?
Sim. O web_search utiliza o índice em tempo real da Anthropic, que possui uma excelente cobertura de conteúdo em chinês (incluindo contas oficiais do WeChat, Zhihu, CSDN, etc.). Se você quiser limitar a pesquisa apenas a sites em chinês, pode usar a lista de permissões allowed_domains.
Q5: O consumo de tokens é alto ao usar o web_search para pesquisas longas, como otimizar?
Três direções de otimização:
- Use a versão de filtragem dinâmica
web_search_20260209(requer Claude Opus/Sonnet 4.6+), que descarta automaticamente fragmentos irrelevantes. - Utilize o parâmetro
max_content_tokensdoweb_fetchpara limitar o limite de extração por página. - Ative o prompt caching para armazenar a definição da ferramenta e o system prompt, reduzindo o custo de solicitações repetidas.
Q6: É possível misturar soluções de pesquisa MCP de terceiros com o web_search nativo?
Sim. O Claude suporta a definição de várias ferramentas simultaneamente, mas é importante escrever descrições claras para as ferramentas — por exemplo, descreva o tavily_search do MCP como "pesquisar artigos acadêmicos" e o web_search nativo como "pesquisar páginas da web gerais"; o Claude escolherá autonomamente com base na descrição. No entanto, para reduzir ambiguidades, recomendamos usar uma única ferramenta de pesquisa por cenário.
Q7: O que fazer se a chamada da API do Claude para pesquisa na web falhar na China?
Existem dois motivos principais: instabilidade de rede ao conectar diretamente à API da Anthropic e o fato de que, durante a execução do web_search, o backend da Anthropic pode bloquear IPs da China continental. A solução mais direta é usar o serviço proxy de API da APIYI (apiyi.com) — todas as solicitações de web_search são encaminhadas através dos nós da APIYI no exterior para a Anthropic, e a resposta é retornada, mantendo a mesma estabilidade de uma conexão direta do exterior.
Resumo e Recomendações sobre a Solução de Busca na Web via Claude API
Revisando o conteúdo, a busca na web via Claude API atingiu um nível de maturidade "pronto para uso" em 2026. Uma decisão rápida:
✅ Para 80% dos projetos, o
web_searchnativo oficial é suficiente — configuração simples, referências em conformidade e manutenção pela Anthropic. Para os 20% restantes com necessidades de personalização rigorosas, considere MCPs de terceiros ou ferramentas próprias.
Lista de Ações para Implementação
Se você pretende integrar a busca na web via Claude API ao seu projeto hoje mesmo:
- Escolha o modelo: Use o
claude-sonnet-4-6para cenários gerais (melhor custo-benefício) e oclaude-opus-4-7para pesquisas complexas. - Escolha a versão da ferramenta: Priorize o
web_search_20260209(filtragem dinâmica); para modelos antigos, utilize oweb_search_20250305. - Defina
max_uses: 1 a 3 vezes para perguntas e respostas simples, 5 a 10 vezes para pesquisas complexas. - Combine com
web_fetch: Quando precisar de análise de texto completo, utilize em conjunto com oweb_fetchpara extrair páginas candidatas. - Configure o acesso: No Brasil ou em regiões com restrições, utilize o serviço proxy de API da APIYI (apiyi.com) para encaminhamento transparente, sem necessidade de VPN e sem alterar o código.
🎯 Dica final: O segredo da busca na web via Claude API não é apenas "se funciona", mas sim "como equilibrar a qualidade dos resultados da busca, o custo de tokens e a latência de resposta". Recomendamos rodar alguns exemplos reais de negócio na plataforma APIYI (apiyi.com), contabilizar o número real de buscas e o consumo de tokens por conversa antes de decidir se deve implementar otimizações avançadas, como prompt caching ou filtragem dinâmica. A plataforma oferece suporte a toda a linha de modelos Claude + Server Tool nativo, facilitando a iteração rápida.
Autor: Equipe Técnica da APIYI | Para mais tutoriais práticos sobre a Claude API, acesse help.apiyi.com





