Nota do autor: análise profunda da estrutura de campos, construção do array contents, mecanismo de thoughtSignature e implementação prática da API de geração de imagens em conversas multirrodadas do Nano Banana Pro (gemini-3-pro-image-preview).
Muitos desenvolvedores, ao integrarem o Nano Banana Pro pela primeira vez, deparam-se com a mesma dúvida: na interface web do gemini.google.com, é possível fazer perguntas sequenciais como "mude o fundo para o pôr do sol" ou "adicione um gato", e o modelo lembra perfeitamente da imagem anterior; porém, ao chamar a API oficial, o modelo parece "esquecer" tudo. O motivo é que a Gemini API é inerentemente sem estado (stateless), portanto, o contexto multirrodada deve ser construído manualmente por quem faz a chamada. Este artigo explicará detalhadamente os campos da API de geração de imagens multirrodada do Nano Banana Pro, as implementações via SDK Python e REST, e o mecanismo crucial de thoughtSignature, ajudando você a configurar uma experiência de geração de imagens com contexto fluido em 3 passos, tal como na versão web.
Valor central: ao terminar este artigo, você dominará a construção correta do array contents, será capaz de implementar fluxos de trabalho multirrodada de "edição baseada na imagem anterior" em suas próprias aplicações, e evitará os três erros típicos: "esquecimento da imagem", "desperdício de tokens" e "perda de assinatura".
Pontos principais da geração de imagens multirrodada do Nano Banana Pro
| Ponto | Descrição | Valor |
|---|---|---|
| API sem estado | A interface gemini-3-pro-image-preview não lembra histórico | O contexto multirrodada deve ser mantido pelo chamador |
| Array contents | Alternância de papéis user/model, cada requisição carrega o histórico completo | Uma única requisição permite que o modelo "veja" o diálogo passado |
| Retorno de imagem | Imagens geradas anteriormente devem ser inseridas de volta em contents como inline_data |
O modelo edita com base nelas, em vez de gerar do zero |
| thoughtSignature | Assinatura de pensamento criptografada, mantém o contexto de raciocínio entre rodadas | Instruções de edição cruciais não são esquecidas |
| Automação via SDK | O objeto chat do SDK Python oficial gerencia o histórico automaticamente |
Migrar do REST diretamente pode economizar 80% do código |
Diferença essencial entre a geração de imagens multirrodada e o Agent da versão web
O gemini.google.com é uma aplicação Agent construída oficialmente pelo Google, que mantém um "estado de diálogo" completo no front-end (incluindo textos de cada rodada, imagens geradas e assinaturas de pensamento). Cada vez que você insere uma nova mensagem, esse Agent empacota todo o histórico e envia ao modelo base de uma só vez. É por isso que a experiência na web é tão fluida: todo o trabalho de "memória" é feito pelo Agent.
Já ao chamar a API generateContent diretamente, você recebe uma interface de invocação de modelo "nua". Cada requisição HTTP é uma inferência independente, e o modelo não tem noção dos diálogos anteriores. Para reproduzir a experiência multirrodada da versão web, você precisa, essencialmente, implementar um Agent no seu próprio código — preenchendo o histórico de mensagens do usuário, as respostas do modelo (incluindo imagens e assinaturas) no contents conforme o padrão, e então disparando a requisição.
Detalhamento da estrutura de campos do Nano Banana Pro para geração de imagens em conversas de múltiplos turnos
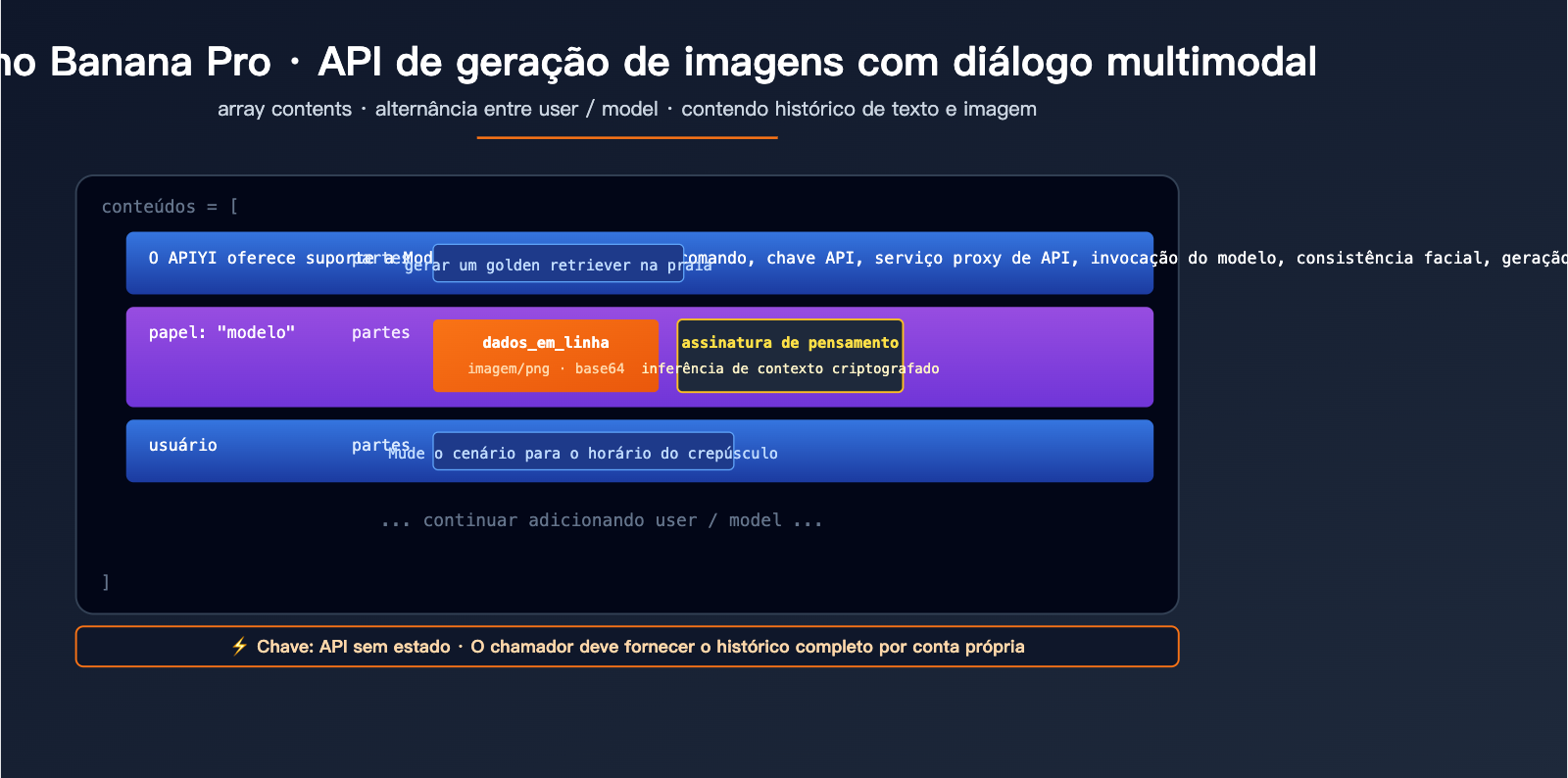
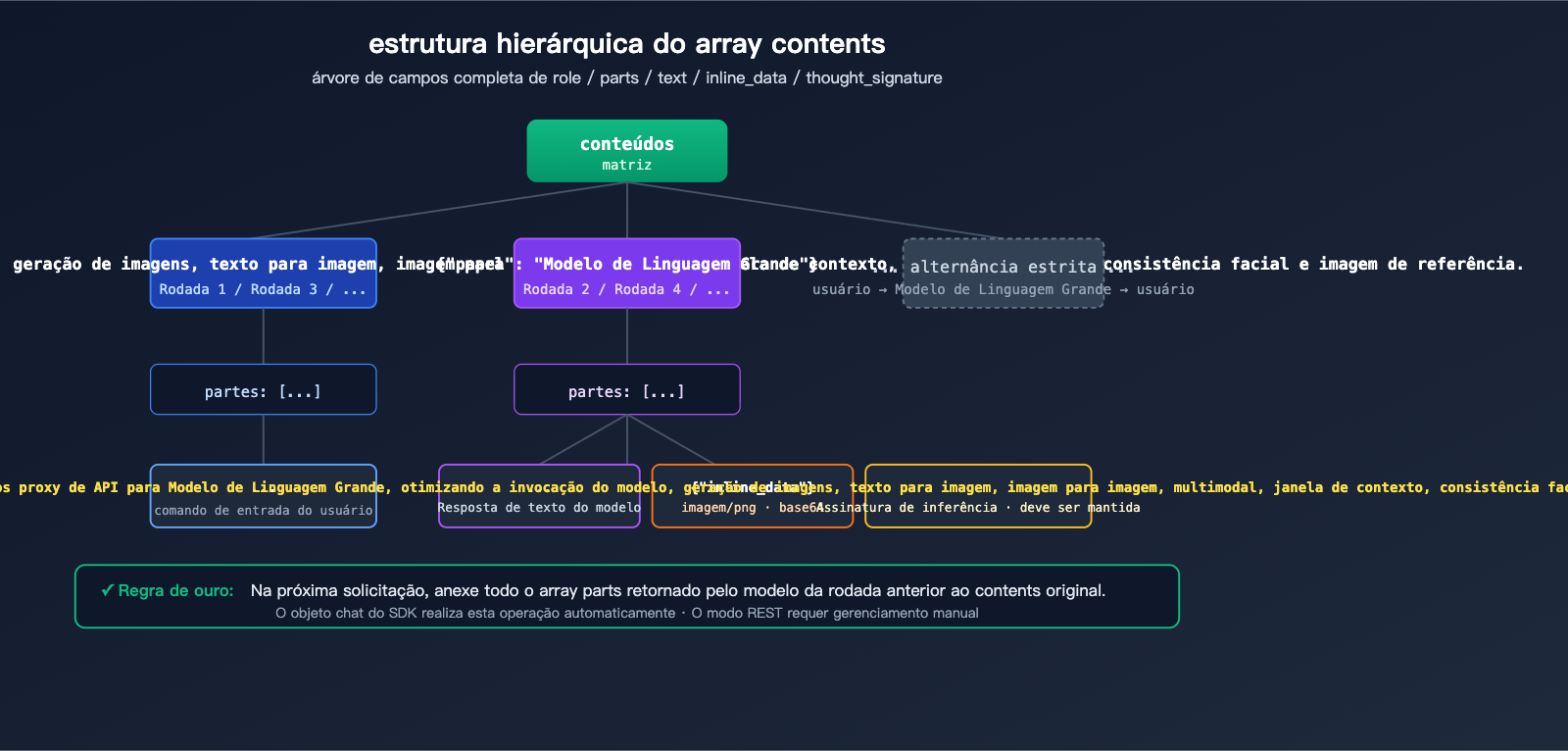
A especificação central do array contents
contents é o campo padrão da API do Gemini para representar o histórico de conversas. Ele é um array JSON onde cada elemento representa uma rodada de fala:
| Campo | Tipo | Descrição |
|---|---|---|
role |
string | "user" ou "model", deve alternar estritamente |
parts |
array | Fragmentos de conteúdo da rodada, podem misturar texto/imagem/assinatura |
parts[].text |
string | Conteúdo de texto, como comandos ou diálogos |
parts[].inline_data.mime_type |
string | Formato da imagem, geralmente "image/png" |
parts[].inline_data.data |
string | Dados da imagem codificados em base64 |
parts[].thought_signature |
string | Assinatura criptografada gerada pelo modelo (aparece apenas na role model) |
Um corpo de requisição completo de duas rodadas de conversa parece com isto:
{
"contents": [
{"role": "user", "parts": [{"text": "Gere um golden retriever correndo na praia"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<base64 da imagem gerada na primeira rodada>"}},
{"thought_signature": "<assinatura criptografada>"}
]},
{"role": "user", "parts": [{"text": "Mude o cenário para o pôr do sol"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {"aspectRatio": "16:9", "imageSize": "2K"}
}
}
Duas formas de enviar imagens de volta
Na segunda rodada da requisição, o modelo deve ser capaz de "ver" a imagem gerada na primeira rodada. O Nano Banana Pro suporta duas formas de retorno:
# Método 1: inline_data com base64 embutido (ideal para imagens pequenas, simples e direto)
{
"inline_data": {
"mime_type": "image/png",
"data": base64.b64encode(image_bytes).decode()
}
}
# Método 2: file_data referenciando recursos carregados via Files API (ideal para imagens grandes ou reutilização)
{
"file_data": {
"mime_type": "image/png",
"file_uri": "files/abc123xyz"
}
}
Dica importante:
inline_dataé a forma mais comum de chamada direta, adequada para cenários de uso único; o modo de referênciafile_dataé ideal para cenários onde você precisa reutilizar a mesma imagem grande em vários turnos, podendo reduzir significativamente o tamanho do corpo da requisição e o custo de upload.
Nano Banana Pro: Primeiros passos na geração de imagens em múltiplos turnos
Exemplo minimalista (Gerenciamento automático pelo SDK Python)
Se você usar o SDK oficial do Python, a escrita mais concisa requer apenas 10 linhas:
from google import genai
client = genai.Client(api_key="SUA_CHAVE_API")
chat = client.chats.create(model="gemini-3-pro-image-preview")
# Primeira rodada: gerar imagem inicial
r1 = chat.send_message("Gere um golden retriever correndo na praia")
# Segunda rodada: editar com base na primeira imagem (o objeto chat carrega o histórico automaticamente)
r2 = chat.send_message("Mude o cenário para o pôr do sol e adicione uma gaivota voando")
# Terceira rodada: continuar adicionando modificações
r3 = chat.send_message("Mude a cor do cachorro para marrom escuro")
O objeto chat mantém internamente a lista completa de contents (incluindo a thoughtSignature de cada rodada), então o desenvolvedor não precisa se preocupar com os detalhes dos campos. Cada send_message empacota e envia o histórico automaticamente.
Ver exemplo completo de chamada com interface compatível com OpenAI
Se você estiver usando uma plataforma compatível com OpenAI, como a APIYI (apiyi.com), para chamar o Nano Banana Pro, pode reutilizar diretamente o SDK da OpenAI:
import openai
import base64
client = openai.OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://vip.apiyi.com/v1"
)
# Mantenha uma lista local de mensagens (o conceito de contents)
messages = [
{"role": "user", "content": "Gere um golden retriever correndo na praia"}
]
# Primeira rodada
response1 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
img1_url = response1.choices[0].message.content # Extraia a URL da imagem ou base64
# Adicione a resposta do modelo ao histórico
messages.append({"role": "assistant", "content": img1_url})
# Segunda rodada: adicione o novo comando
messages.append({"role": "user", "content": "Mude o cenário para o pôr do sol"})
response2 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
# Terceira rodada e assim por diante...
messages.append({"role": "assistant", "content": response2.choices[0].message.content})
messages.append({"role": "user", "content": "Adicione uma gaivota voando"})
response3 = client.chat.completions.create(
model="gemini-3-pro-image-preview",
messages=messages
)
Ponto chave: No modo compatível com OpenAI, o array messages é equivalente ao contents nativo, e o campo role muda de "model" para "assistant"; a plataforma fará a conversão automaticamente.
Sugestão: Para cenários de edição em múltiplos turnos, recomendamos usar o objeto
chatdo SDK ou manter uma lista local de mensagens para evitar a concatenação manual decontentsa cada vez. Você pode se registrar na APIYI (apiyi.com) para obter créditos gratuitos, testar com o SDK e, só depois, considerar a otimização via REST.
Construção manual de REST para geração de imagens em conversas multi-turno no Nano Banana Pro
Implementação REST pura sem dependência de SDK
Em alguns cenários (como em serviços proxy de API, nós do ComfyUI ou plataformas low-code), não é possível utilizar o SDK oficial, sendo necessário construir as requisições REST diretamente. Abaixo está a chamada curl completa:
# Primeira rodada: Geração de imagem via comando de texto puro
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: SUA_CHAVE_API" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "Gere um golden retriever correndo na praia"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
# A resposta conterá: parts[0].inline_data.data (imagem em base64)
# E também parts[0].thought_signature
Na segunda rodada da requisição, é obrigatório inserir toda a resposta do modelo da primeira rodada (incluindo a imagem e a assinatura) de volta no campo contents:
curl -X POST \
"https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: SUA_CHAVE_API" \
-H "Content-Type: application/json" \
-d '{
"contents": [
{"role": "user", "parts": [{"text": "Gere um golden retriever correndo na praia"}]},
{"role": "model", "parts": [
{"inline_data": {"mime_type": "image/png", "data": "<base64 retornado na primeira rodada>"}},
{"thought_signature": "<assinatura retornada na primeira rodada>"}
]},
{"role": "user", "parts": [{"text": "Mude o cenário para o pôr do sol"}]}
],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"]
}
}'
Comparação entre três modos de invocação
| Modo de invocação | Gestão de histórico | Cenário ideal | Custo de aprendizado |
|---|---|---|---|
SDK Python oficial (objeto chat) |
Automático | Serviços backend, experimentos em Notebook | ⭐ Mínimo |
Interface compatível com OpenAI (array messages) |
Semiautomático | Migração de projetos OpenAI existentes | ⭐⭐ Baixo |
REST nativo (array contents) |
Manual total | ComfyUI, low-code, cross-language | ⭐⭐⭐ Médio |
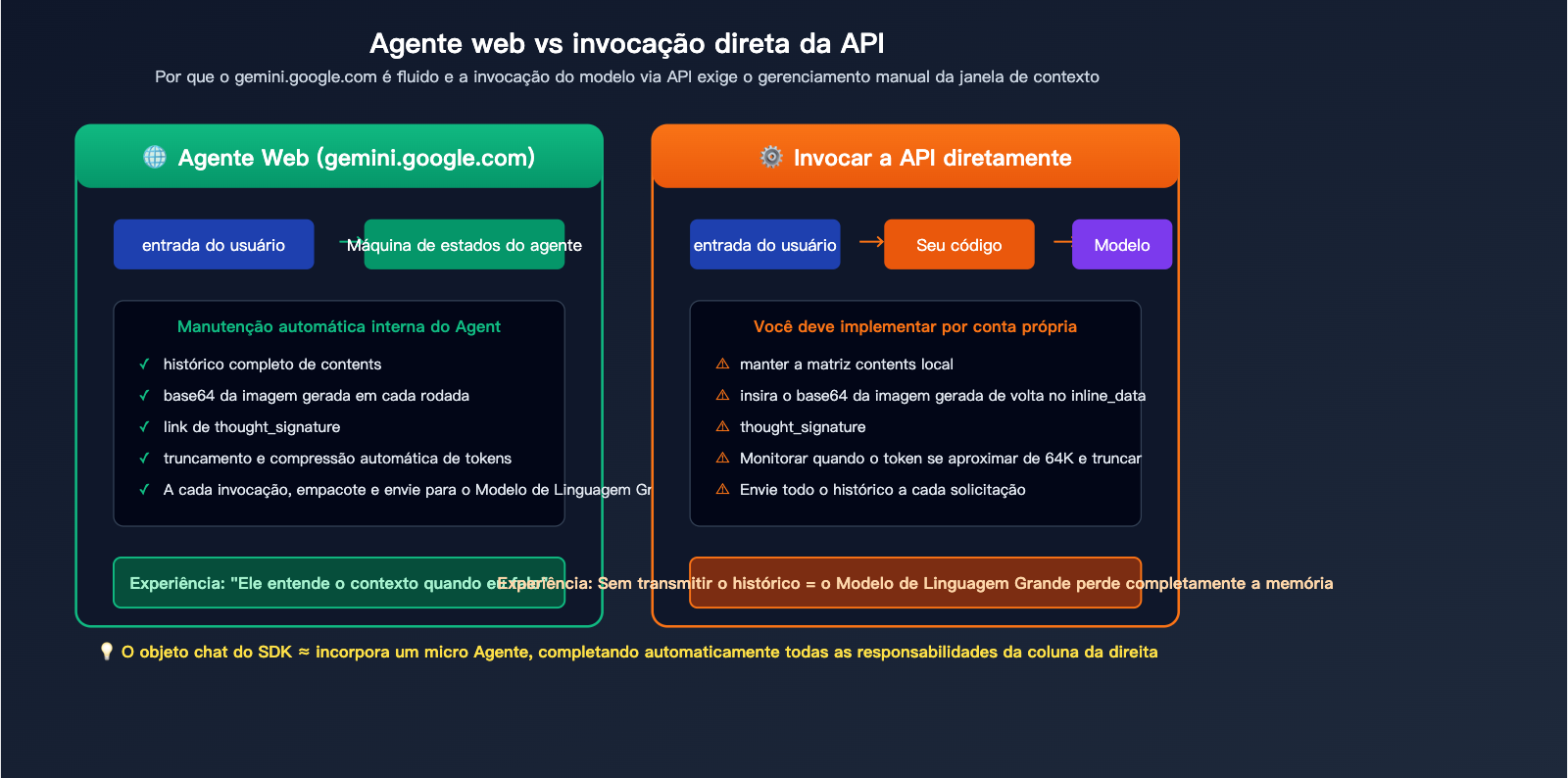
Nota sobre os dados: A imagem acima mostra as diferenças fundamentais entre a gestão automática de um Agente versus a gestão manual via API. Você pode comparar as diferenças reais de desempenho entre os dois métodos de invocação diretamente na plataforma APIYI (apiyi.com).
Mecanismo thoughtSignature para geração de imagens em conversas multirrodadas do Nano Banana Pro
O que é thoughtSignature
thoughtSignature é a "assinatura de pensamento criptografada" introduzida na série Gemini 3. Trata-se de uma codificação compacta do estado de raciocínio interno do modelo. Embora não seja legível para humanos, o modelo pode utilizá-la na rodada seguinte para restaurar rapidamente o contexto. Suas funções específicas incluem:
- Preservação de decisões detalhadas: Por exemplo, se na primeira rodada o modelo "decidir" usar tons claros, na segunda rodada ele herdará esse estilo através da assinatura.
- Melhoria da consistência: Mantém a estabilidade de personagens, cenários e composição em edições multirrodadas.
- Economia de tokens: Evita a necessidade de repetir constantemente "mantenha o estilo original" no comando.
Quando é obrigatório incluir a assinatura
| Cenário | É obrigatório incluir a assinatura? |
|---|---|
| Solicitação independente de rodada única (geração única) | ❌ Não |
| Edição multirrodada (modificação baseada na imagem anterior) | ✅ Sim |
| Recuperação de histórico entre sessões | ✅ Sim (deve ser persistido manualmente) |
| Conversa apenas de texto (sem imagens) | ✅ Sim, para continuidade do raciocínio |
Na prática: Padrão de código para gerenciamento manual da assinatura
import requests
import base64
import json
API_BASE = "https://vip.apiyi.com/v1beta"
MODEL = "gemini-3-pro-image-preview"
HEADERS = {
"x-goog-api-key": "SUA_CHAVE_API",
"Content-Type": "application/json"
}
class NanoBananaChat:
"""Cliente de chat minimalista que mantém manualmente contents + assinatura"""
def __init__(self):
self.contents = []
def send(self, text: str, attach_image_b64: str = None) -> dict:
# Constrói a mensagem do usuário desta rodada
user_parts = [{"text": text}]
if attach_image_b64:
user_parts.append({
"inline_data": {"mime_type": "image/png", "data": attach_image_b64}
})
self.contents.append({"role": "user", "parts": user_parts})
# Realiza a requisição
resp = requests.post(
f"{API_BASE}/models/{MODEL}:generateContent",
headers=HEADERS,
json={
"contents": self.contents,
"generationConfig": {"responseModalities": ["TEXT", "IMAGE"]}
}
).json()
# Adiciona a resposta do modelo (incluindo a assinatura) de volta ao contents
model_parts = resp["candidates"][0]["content"]["parts"]
self.contents.append({"role": "model", "parts": model_parts})
return model_parts
# Exemplo de uso
chat = NanoBananaChat()
parts1 = chat.send("Gere um golden retriever correndo na praia")
parts2 = chat.send("Mude o cenário para o pôr do sol") # Inclui automaticamente o histórico e a assinatura
parts3 = chat.send("Adicione uma gaivota voando")
Dica de otimização: Ao acessar via APIYI (apiyi.com), a camada da plataforma transmitirá o campo
thought_signatureexatamente como ele é. Os desenvolvedores só precisam garantir que "todo o array de partes do modelo seja adicionado de volta ao contents", sem a necessidade de se preocupar com o conteúdo específico da assinatura.
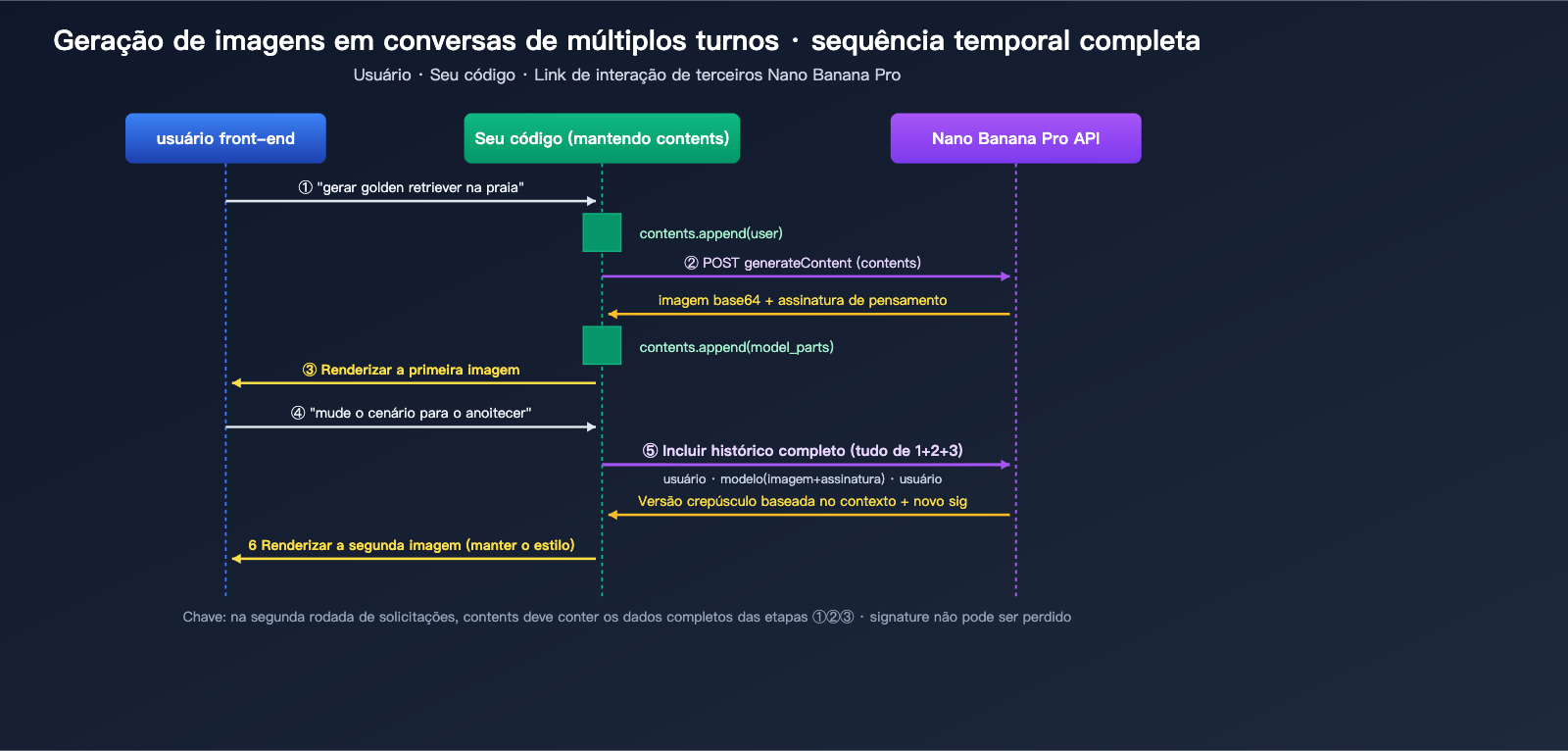
Cenários Práticos: Geração de Imagens em Múltiplas Rodadas com Nano Banana Pro
Cenário 1: Design de Marca Progressivo
Uma necessidade comum das equipes de marketing: com base em uma imagem conceitual do produto, ajustar gradualmente o texto, as cores e o layout. A vantagem da API de geração de imagens em múltiplas rodadas é que você só precisa descrever as "mudanças incrementais" a cada vez, sem precisar descrever a imagem inteira do zero:
chat = client.chats.create(model="gemini-3-pro-image-preview")
# Solicita a criação inicial
chat.send_message("Crie um pôster de marca de café com fundo degradê azul escuro, coloque a imagem do produto à esquerda")
# Ajuste incremental
chat.send_message("Mude o texto do título para 'Awaken Your Morning'")
# Adição de elemento
chat.send_message("Adicione um espaço reservado para QR code no canto inferior direito")
# Ajuste de estilo
chat.send_message("Deixe o estilo geral mais moderno e remova as bordas decorativas")
Cenário 2: Edição em Múltiplas Rodadas com Imagem de Referência
O Nano Banana Pro suporta até 14 imagens de referência por vez. Combinado com o diálogo em múltiplas rodadas, você pode construir fluxos de trabalho poderosos de fusão de imagens:
# Faz o upload de um retrato + uma imagem de referência de vestuário
chat.send_message([
"Coloque no personagem da primeira imagem as roupas da segunda imagem",
{"inline_data": {"mime_type": "image/png", "data": person_b64}},
{"inline_data": {"mime_type": "image/png", "data": outfit_b64}}
])
# Ajustes finos subsequentes
chat.send_message("Mude o decote para um decote em V")
chat.send_message("Troque o fundo por um cinza minimalista")
Cenário 3: Recuperação de Histórico entre Sessões
Se o usuário fechar a página no front-end e reabri-la, querendo continuar a conversa anterior, você precisará persistir o array contents em um banco de dados:
import json
# Salvar
with open(f"sessions/{user_id}.json", "w") as f:
json.dump(chat.get_history(), f)
# Recuperar
with open(f"sessions/{user_id}.json") as f:
history = json.load(f)
restored_chat = client.chats.create(
model="gemini-3-pro-image-preview",
history=history
)
restored_chat.send_message("Continue de onde paramos, deixe o fundo um pouco mais claro")
Limites da Janela de Contexto
| Recurso | Limite |
|---|---|
| Contexto de entrada | 64K tokens |
| Contexto de saída | 32K tokens |
| Máximo de imagens de referência por requisição | 14 imagens |
| Rodadas de histórico recomendadas | Não exceder 8-10 rodadas |
| Resolução máxima por imagem | 2K (padrão 1K) |
Sugestão de cenário: Quando a conversa ultrapassar 8-10 rodadas, recomenda-se "truncar" ativamente o histórico anterior ou substituí-lo por um resumo do Modelo de Linguagem Grande, caso contrário, os tokens atingirão rapidamente o limite de 64K. Em ambientes de produção, certifique-se de incluir um contador de tokens e tomar decisões de truncamento no cliente com antecedência.
Perguntas Frequentes
Q1: Se eu chamar a API diretamente sem contexto, como implementar a conversa contínua como na versão web?
A API é sem estado (stateless), portanto, seu código deve manter uma cópia local do array contents (ou o objeto chat do SDK). A cada requisição, envie o histórico completo (incluindo texto do usuário, imagens geradas pelo modelo e thought_signature) para que o modelo "se lembre" da conversa anterior. A maneira mais simples é usar o client.chats.create() do SDK oficial em Python, que gerencia isso automaticamente.
Q2: Que campos devo passar na próxima rodada para a imagem gerada na rodada anterior?
Você deve colocar a imagem na forma de inline_data (codificada em base64 + mime_type) dentro do array parts do "papel de modelo da rodada anterior". Além disso, certifique-se de incluir o thought_signature retornado pelo modelo. Se você estiver usando interfaces compatíveis com OpenAI, como a APIYI (apiyi.com), a plataforma tratará automaticamente o mapeamento desses campos, e o desenvolvedor só precisa manter a lista padrão de mensagens.
Q3: O thoughtSignature é obrigatório? O que acontece se eu não passar?
É altamente recomendável passá-lo. Se você não o fizer, o modelo pode "esquecer" decisões cruciais da rodada anterior (como estilo, paleta de cores, composição) durante a edição, fazendo com que cada rodada pareça uma nova geração. A documentação oficial afirma claramente que a assinatura deve ser mantida em cenários de múltiplas rodadas. O SDK lida com isso automaticamente; no modo REST, você precisará anexar manualmente as partes do modelo de volta ao contents.
Q4: O que fazer se o histórico ficar longo demais? Ocorrerá erro se exceder 64K tokens?
Sim, exceder 64K tokens de entrada resultará em erro. Estratégias de otimização comuns:
- Truncamento: Mantenha apenas as últimas 4-6 rodadas do histórico.
- Subamostragem de imagem: Transmita imagens históricas em resolução 1K em vez de 2K.
- Substituição por resumo: Use um Modelo de Linguagem Grande para comprimir as rodadas anteriores em uma descrição de texto.
- Sessões segmentadas: Inicie uma nova sessão quando o tópico da conversa mudar.
Q5: Como testar rapidamente o efeito de geração em múltiplas rodadas do Nano Banana Pro?
Recomendamos usar plataformas de agregação que suportam modelos Gemini, como a APIYI (apiyi.com), para verificação rápida:
- Registre uma conta para obter a chave API e créditos gratuitos.
- Selecione o modelo
gemini-3-pro-image-preview. - Use o código de exemplo do SDK Python deste artigo para iniciar 3-5 rodadas de edição consecutivas.
- Compare a coerência da saída de cada rodada para determinar se atende às necessidades do seu negócio.
Resumo
Pontos principais da API de geração de imagens por diálogo multirrodada do Nano Banana Pro:
- Natureza sem estado: A API não armazena histórico; o chamador deve manter o array
contents. - Alternância de papéis:
useremodeldevem alternar rigorosamente, e cada rodada departspode misturar texto, imagem e assinatura. - Retorno de imagem: A imagem gerada na rodada anterior deve ser reinserida via
inline_data, caso contrário, o modelo não conseguirá "vê-la". - Mecanismo de assinatura: A
thought_signatureé fundamental para a consistência multirrodada e deve ser incluída manualmente no modo REST. - Simplificação via SDK: O objeto
chatdo SDK oficial em Python gerencia automaticamente todos os detalhes mencionados acima.
Para desenvolvedores que desejam implementar rapidamente uma experiência web, o melhor caminho é utilizar o objeto chat do SDK oficial ou o modo de mensagens da interface compatível com OpenAI, evitando a complexidade de construir requisições REST manualmente.
Recomendamos acessar as capacidades de geração de imagens multirrodada do Nano Banana Pro via APIYI (apiyi.com). A plataforma suporta tanto o modo de campos nativos do Gemini quanto o modo compatível com OpenAI, oferecendo créditos de teste gratuitos para facilitar a validação rápida de edições multirrodada e a migração suave de projetos existentes.
📚 Referências
-
Documentação oficial de geração de imagens da API Gemini: Guia definitivo para geração de imagens em diálogos multirrodada.
- Link:
ai.google.dev/gemini-api/docs/image-generation - Descrição: Contém especificações do campo
contents, exemplos completos em Python SDK e REST.
- Link:
-
Cartão do modelo Gemini 3 Pro Image Preview: Detalhes sobre capacidades e limitações do modelo.
- Link:
ai.google.dev/gemini-api/docs/models/gemini-3-pro-image-preview - Descrição: Parâmetros críticos como janela de contexto, resolução e quantidade de imagem de referência.
- Link:
-
Fórum de Desenvolvedores Google AI – Multi-turn Nano Banana: Exemplos práticos da comunidade.
- Link:
discuss.ai.google.dev/t/multi-turn-nano-banana-example - Descrição: Melhores práticas para diálogos multirrodada discutidas por desenvolvedores reais.
- Link:
-
Documentação do Vertex AI Gemini 3 Pro Image: Referência para implantação em nível empresarial.
- Link:
docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/3-pro-image - Descrição: Inclui usos avançados de
thought_signaturee referências afile_data.
- Link:
-
Documentação de acesso ao Nano Banana Pro da APIYI: Guia de início rápido para desenvolvedores.
- Link:
help.apiyi.com - Descrição: Inclui exemplos para interface compatível com OpenAI e interface nativa do Gemini.
- Link:
Autor: Equipe Técnica APIYI
Troca técnica: Sinta-se à vontade para compartilhar nos comentários os problemas práticos que você encontrou na geração de imagens multirrodada. Para mais dicas de configuração do Nano Banana Pro, visite a central de documentação da APIYI em docs.apiyi.com.