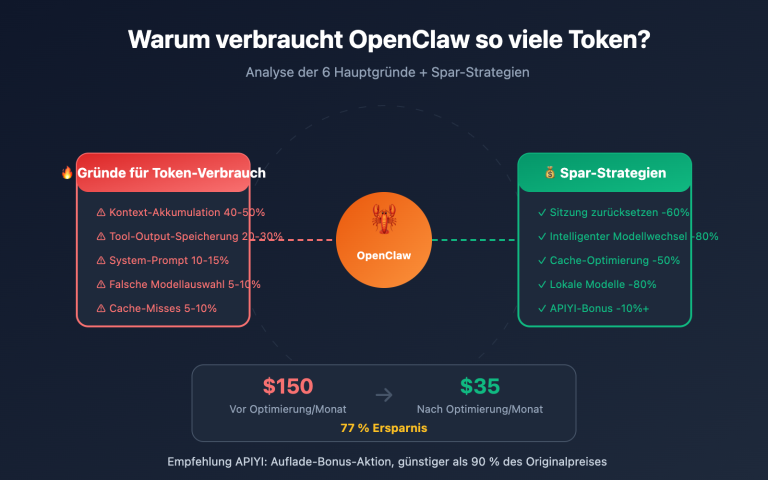
Das Wissen von Modellen hat ein Ablaufdatum, während reale geschäftliche Probleme oft Daten von "heute" erfordern. Claude hat 2025 offiziell das native web_search-Tool eingeführt und 2026 auf die Version web_search_20260209 mit Unterstützung für dynamische Filterung aktualisiert. Damit wurde die Websuche via Claude API von einer "selbst gebastelten Lösung" zu einer "Ein-Zeilen-Parameter"-Konfiguration.
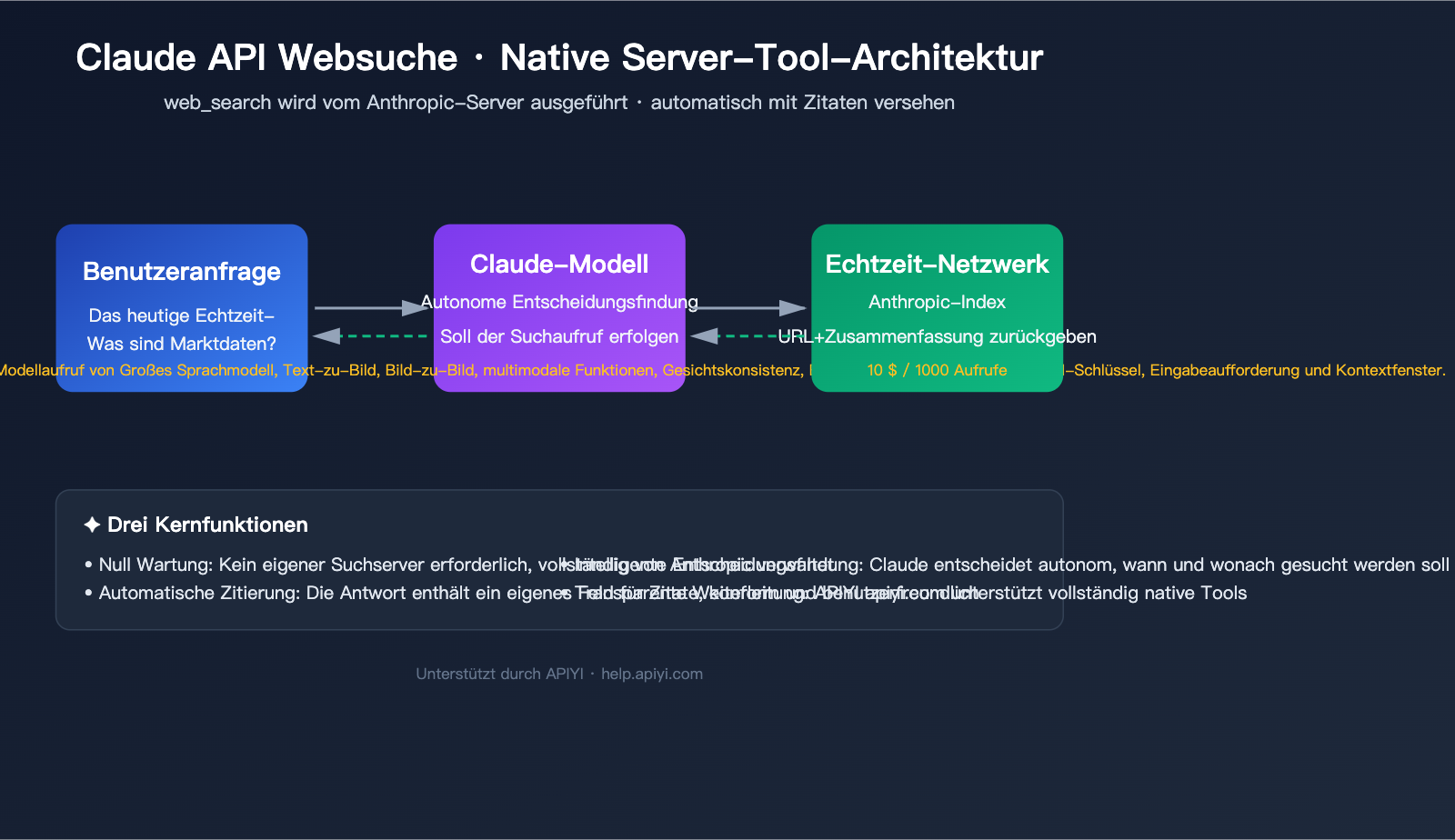
Dieser Artikel bietet einen systematischen Überblick über die neuesten Implementierungsmöglichkeiten für die Claude API-Websuche im Jahr 2026. Wir konzentrieren uns auf die Parameter, die Abrechnung, die Einschränkungen und Code-Vorlagen der offiziellen nativen web_search / web_fetch-Tools und vergleichen diese mit Drittanbieter-MCPs und selbst gehosteten RAG-Lösungen. Am Ende finden Sie ein Beispiel für eine transparente Weiterleitung über APIYI (apiyi.com) – Sie müssen lediglich base_url und api_key austauschen, um den gesamten Prozess in einer inländischen Umgebung auszuführen.
Kernpunkte der Claude API-Websuche
Bevor wir mit dem Programmieren beginnen, sollten wir die Konzepte klären. Die Claude API-Websuche ist im Wesentlichen ein von Anthropic bereitgestelltes Server-Tool – das bedeutet, die Suche wird von Anthropic in der Cloud ausgeführt. Sie müssen weder eine Google/Bing-API einbinden noch Web-Crawler selbst bereitstellen.
Übersicht der drei gängigen Implementierungslösungen
| Lösung | Integrationsaufwand | Kosten | Echtzeitfähigkeit | Quellen & Compliance |
|---|---|---|---|---|
Offizielles web_search |
★☆☆ (ein tool-Feld) | $10 / 1000 Anfragen + Token | Hoch (Anthropic Echtzeit-Index) | Automatische Zitate |
| Drittanbieter MCP (z.B. Brave/Tavily) | ★★☆ (MCP-Server erforderlich) | Abrechnung über Drittanbieter-Suche | Mittel-Hoch | Selbst zu verwalten |
| Selbstbau (Google CSE + Tool-Aufruf) | ★★★ (eigenes Tool + Parsing) | Google API-Kontingent | Mittel | Vollständig eigenverantwortlich |
🎯 Empfehlung zur Lösungswahl: Wenn Ihr Hauptanliegen darin besteht, "Claude in die Lage zu versetzen, aktuelle Ereignisse zu beantworten und Echtzeitdaten zu ergänzen", ist die offizielle
web_searchdie derzeit beste Lösung – wartungsfrei, regelkonform bei Zitaten und verfügbar für Hauptmodelle wie Sonnet 4.6 / Opus 4.7. Wir empfehlen die Anbindung über den API-Proxy-Dienst von APIYI (apiyi.com), um ohne VPN auf die volle Funktionalität der offiziellen Anthropic-Schnittstellen zuzugreifen.
Modellmatrix für die Claude API-Websuche
Nicht alle Claude-Modelle unterstützen web_search. Die neue Version web_search_20260209 stellt klare Anforderungen an die Modelle:
| Modell | Basisversion web_search_20250305 |
Dynamische Filterung web_search_20260209 |
|---|---|---|
| Claude Opus 4.7 | ✅ | ✅ |
| Claude Opus 4.6 | ✅ | ✅ |
| Claude Sonnet 4.6 | ✅ | ✅ |
| Claude Sonnet 4.5 | ✅ | ❌ |
| Claude Haiku 4.5 | ✅ | ❌ |
Die dynamische Filterung (Dynamic Filtering) ist das Kern-Upgrade der Version 2026: Claude führt mit einem Code-Ausführungstool eine Filterung der Suchergebnisse durch, bevor diese in das Kontextfenster gelangen, und behält nur relevante Fragmente bei. Bei der Suche in langen Dokumenten oder technischen Literaturübersichten kann dies den Token-Verbrauch erheblich senken.
Ausführliche Erklärung der nativen Web-Suchtools der Claude API
Anthropic stellt zwei komplementäre native Tools bereit. Das Verständnis ihrer Grenzen ist die Voraussetzung dafür, die Web-Suche der Claude API optimal zu nutzen.
Arbeitsteilung zwischen web_search und web_fetch
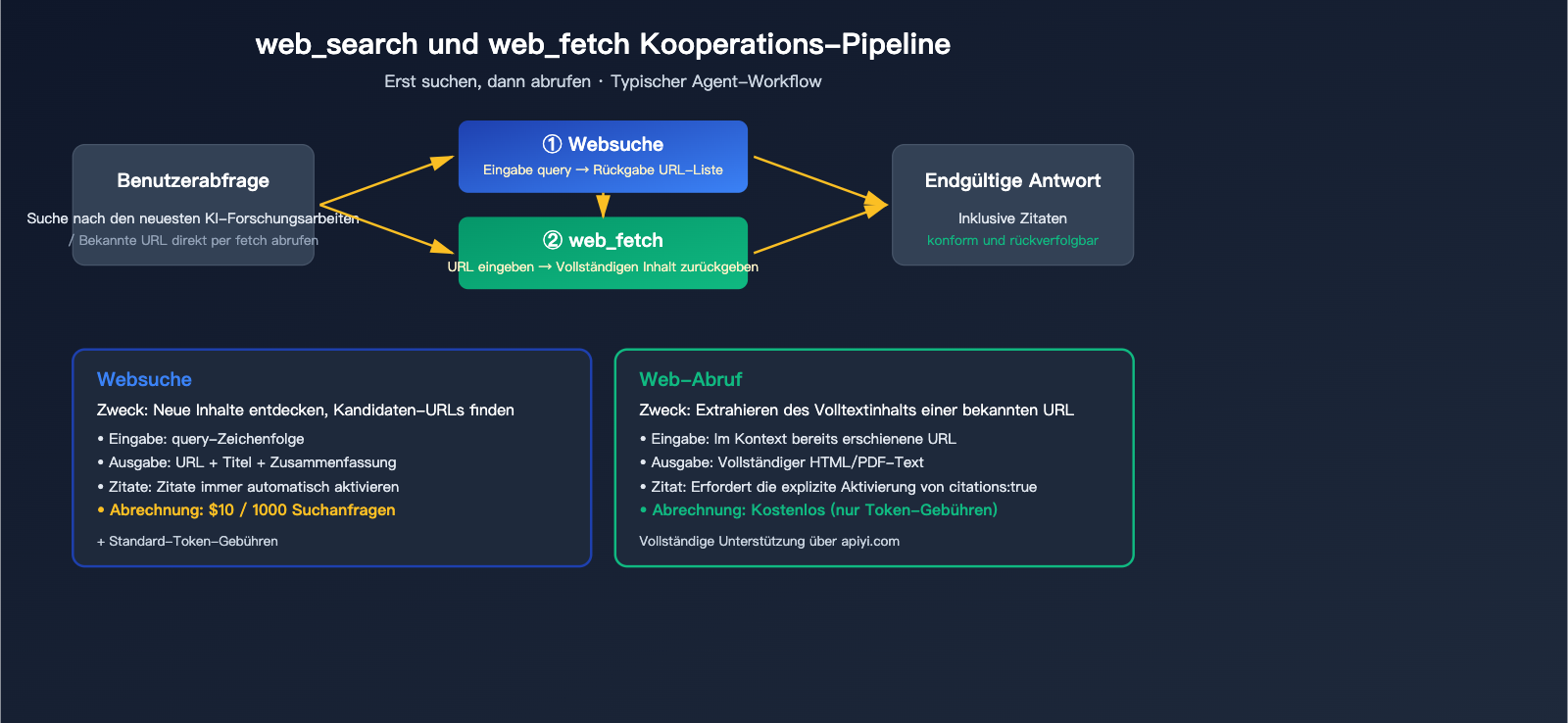
| Tool | Zweck | Eingabe | Ausgabe | Abrechnung |
|---|---|---|---|---|
web_search |
Neue Inhalte entdecken | Query-String | URL + Titel + Zusammenfassung | $10 / 1000 Aufrufe |
web_fetch |
Volltext bekannter URLs extrahieren | URL-String | Vollständiger HTML/PDF-Text | Kostenlos (nur nach Token) |
🎯 Architektur-Tipp: Der typische Agent-Workflow lautet: „Erst suchen, dann abrufen“ –
web_searchfindet Kandidatenseiten,web_fetchlädt den Volltext der relevantesten Seiten. Wenn der Nutzer bereits eine URL angegeben hat (z. B. „Analysiere diesen Artikel auf example.com“), verwenden Sie direktweb_fetch, um Suchkontingente zu sparen. Bei APIYI (apiyi.com) werden beide Tools transparent unterstützt, ohne dass eine zusätzliche Konfiguration erforderlich ist.
Vollständige Parameterdefinition für das web_search-Tool
Die folgende Tabelle zeigt die offiziellen JSON-Parameter, die je nach Bedarf kombiniert werden können:
| Parameter | Typ | Erforderlich | Standard | Beschreibung |
|---|---|---|---|---|
type |
string | ✅ | – | Festgelegt auf web_search_20250305 oder web_search_20260209 |
name |
string | ✅ | – | Festgelegt auf web_search |
max_uses |
integer | ❌ | Unbegrenzt | Maximale Anzahl der Suchvorgänge pro Anfrage |
allowed_domains |
string[] | ❌ | – | Nur Ergebnisse dieser Domains zulassen (exklusiv zu blocked) |
blocked_domains |
string[] | ❌ | – | Ergebnisse dieser Domains blockieren |
user_location |
object | ❌ | – | Ungefährer Standort des Nutzers für lokalisierte Suche |
Feldstruktur von user_location:
{
"type": "approximate",
"city": "Shanghai",
"region": "Shanghai",
"country": "CN",
"timezone": "Asia/Shanghai"
}
Fehlerbehandlung bei der Claude API Web-Suche
Wenn eine Suche fehlschlägt, gibt die Anthropic API weiterhin HTTP 200 zurück; die Fehlermeldung ist im web_search_tool_result des Antwortkörpers eingebettet. Achten Sie darauf, diese Fehlercodes in Ihrem Client-Code zu identifizieren:
| Fehlercode | Bedeutung | Empfehlung |
|---|---|---|
too_many_requests |
Ratenbegrenzung erreicht | Backoff-Retry, Parallelität reduzieren |
max_uses_exceeded |
max_uses-Limit überschritten |
Limit erhöhen oder Anfrage aufteilen |
query_too_long |
Suchanfrage zu lang | Query kürzen oder umschreiben |
invalid_input |
Parameterformat fehlerhaft | JSON-Struktur prüfen |
unavailable |
Interner Anthropic-Fehler | Nach kurzer Zeit erneut versuchen |
⚠️ Abrechnungshinweis: Fehlerhafte
web_search-Anfragen werden nicht berechnet. Wenn jedoch nach einer erfolgreichen Suche ein Fehler auftritt, wird der vorherige erfolgreiche Aufruf mit $10 / 1000 Aufrufen berechnet. Es wird empfohlen, die detaillierte Abrechnung im APIYI (apiyi.com) Dashboard zu prüfen, um ungewöhnliche Kosten zu identifizieren.
Schnelleinstieg in die Claude API Web-Suche
Im Folgenden finden Sie den kürzesten Weg, um die gesamte Kette zu implementieren. Alle Beispiele nutzen die transparente Weiterleitung von APIYI (apiyi.com) – Sie müssen keine Geschäftslogik ändern, sondern lediglich die base_url auf den Proxy-Knoten richten und den ANTHROPIC_API_KEY durch den APIYI-Schlüssel ersetzen.
Minimales cURL-Beispiel
Die kleinste ausführbare Anfrage für die Claude API Web-Suche:
curl https://vip.apiyi.com/v1/messages \
-H "x-api-key: $APIYI_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "Fasse auf Deutsch zusammen, welche neuen Modelle OpenAI im April 2026 veröffentlicht hat"}
],
"tools": [{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5
}]
}'
Die Antwortstruktur enthält drei Inhaltsblöcke: Claudes Entscheidungstext, server_tool_use (die tatsächlich ausgeführte Query), web_search_tool_result (URL-Liste) sowie die endgültige Antwort mit citations.
Vollständiges Python SDK Beispiel (inkl. web_fetch)
import anthropic
client = anthropic.Anthropic(
base_url="https://vip.apiyi.com",
api_key="sk-your-apiyi-key",
)
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[{
"role": "user",
"content": "Suche nach Papern zur Evaluierung von KI-Agenten aus dem letzten Monat und erstelle eine detaillierte Zusammenfassung des relevantesten Artikels"
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search"
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 3,
"citations": {"enabled": True}
}
]
)
for block in response.content:
if block.type == "text":
print(block.text)
elif block.type == "server_tool_use":
print(f"[Tool-Aufruf] {block.name}: {block.input}")
🎯 Code-Tipp: Die oben gezeigte Kombination aus
web_search_20260209undweb_fetch_20260209mit dynamischer Filterung senkt bei Claude Opus 4.7 den Token-Verbrauch bei langen Dokumenten erheblich. Für einfache Echtzeit-Fragen reicht das Modellclaude-sonnet-4-6mit dem Basis-Toolweb_search_20250305aus, was kostengünstiger ist. Alle Aufrufe über APIYI (apiyi.com) bieten die gleiche Stabilität wie das Original.
TypeScript / Node.js Beispiel
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic({
baseURL: "https://vip.apiyi.com",
apiKey: process.env.APIYI_API_KEY,
});
const response = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 2048,
messages: [
{ role: "user", content: "Wie ist das Wetter heute in Shanghai?" }
],
tools: [{
type: "web_search_20250305",
name: "web_search",
max_uses: 3,
user_location: {
type: "approximate",
city: "Shanghai",
region: "Shanghai",
country: "CN",
timezone: "Asia/Shanghai"
}
}]
});
console.log(response.content);
Verarbeitung von Streaming-Antworten
Wenn stream: true aktiviert ist, wird der Suchvorgang über SSE-Ereignisse in Echtzeit übertragen. Während der Suche tritt eine kurze „Pause“ auf – dies liegt daran, dass Claude darauf wartet, dass der Anthropic-Server die Suche abschließt:
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=2048,
messages=[{"role": "user", "content": "Frage die neuesten Preise für Claude 4.7 ab"}],
tools=[{"type": "web_search_20250305", "name": "web_search", "max_uses": 2}]
) as stream:
for event in stream:
if event.type == "content_block_start":
block = event.content_block
if block.type == "server_tool_use":
print(f"\n[Suche läuft] Query-Ergebnisse werden gestreamt...")
elif block.type == "web_search_tool_result":
print(f"[Suche abgeschlossen] {len(block.content)} Ergebnisse gefunden")
elif event.type == "content_block_delta":
if hasattr(event.delta, "text"):
print(event.delta.text, end="", flush=True)
Vergleich und Auswahl von Lösungen für die Claude API-Websuche
Nachdem wir die offiziellen Schnittstellen kennengelernt haben, kommen wir nun zur Entscheidungsfindung. Für die Claude API-Websuche gibt es praktisch drei Wege, die jeweils für unterschiedliche Szenarien geeignet sind.

Lösung A: Offizielles natives web_search (Empfehlung)
Vorteile:
- Kein Wartungsaufwand: Kein eigener Server erforderlich, vollständig von Anthropic verwaltet.
- Automatische Quellenangaben: Jede Antwort enthält automatisch
citations, was die Konformität erleichtert. - Modell-Integration: Claude entscheidet eigenständig, wann und was gesucht werden muss.
- Transparente Abrechnung: $10 / 1000 Anfragen, direkt über die Anthropic-Rechnung.
Nachteile:
- Unterstützt nur von Anthropic indexierte Quellen (kein Austausch der Suchmaschine möglich).
- Teilweise Einschränkungen bei Modellversionen (Haiku/ältere Sonnet-Versionen unterstützen nur die Basisversion).
Einsatzszenario: 90 % der allgemeinen dialogbasierten Agenten, Frage-Antwort-Assistenten und Rechercheaufgaben.
Lösung B: Drittanbieter-MCP-Dienste (Brave/Tavily/Serper etc.)
Über das Model Context Protocol starten Sie einen lokalen oder entfernten MCP-Server, um Claude Suchfunktionen hinzuzufügen:
# Beispiel für Tavily MCP, erfordert vorher: npm install -g @tavily/mcp-server
claude mcp add tavily-search npx -- @tavily/mcp-server
Vorteile:
- Such-Backend frei wählbar (Brave für Datenschutz, Tavily für LLM-Optimierung).
- Anpassbar: Ergebnisse können nachbearbeitet oder mit Metadaten versehen werden.
- Native Unterstützung durch Clients wie Claude Code oder Cursor.
Nachteile:
- Zusätzliche Wartung des MCP-Server-Prozesses erforderlich.
- Suchergebnisse generieren nicht automatisch
citationsgemäß Anthropic-Standard. - Verwaltung der Kontingente und Abrechnung der Drittanbieter-Such-APIs erforderlich.
Einsatzszenario: Sie besitzen bereits Unternehmenskonten bei Brave/Tavily oder haben spezifische Anforderungen an das Such-Backend.
Lösung C: Selbst implementierter Tool-Aufruf (Google CSE + Custom Tool)
Der klassische Ansatz: Sie definieren ein tool, rufen in Ihrem Backend die Google Custom Search oder Bing API auf und speisen die Ergebnisse zurück in die messages:
tools = [{
"name": "google_search",
"description": "Google durchsuchen und die besten N Ergebnisse zurückgeben",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"}
},
"required": ["query"]
}
}]
Vorteile: Volle Kontrolle, Anbindung an interne Unternehmenssuche oder private Wissensdatenbanken möglich.
Nachteile: Sie tragen die volle Verantwortung für das Design der Eingabeaufforderung, die Sortierung der Ergebnisse, die Generierung von Quellenangaben und Fehlerbehandlung. Zudem ruft Claude das Tool nicht "automatisch" auf – es muss explizit über die System-Eingabeaufforderung gesteuert werden.
Einsatzszenario: Unternehmensszenarien mit strengen Compliance-Anforderungen, hohem Anpassungsbedarf oder privater Datenquellen.
Entscheidungsbaum für die drei Lösungen
| Ihr Bedarf | Empfohlene Lösung |
|---|---|
| Schnell starten, Standardfunktionen ausreichend | Lösung A natives web_search |
| Such-Backend muss ersetzt werden (Datenschutz/Compliance) | Lösung B Drittanbieter-MCP |
| Anbindung privater Datenquellen zwingend erforderlich | Lösung C Eigenes Tool + RAG |
| Zugriff auf Anthropic aus China instabil | Lösung A + APIYI API-Proxy-Dienst |
🎯 Hinweis für Entwickler in China: Die offizielle Anthropic API ist dort oft instabil und erfordert eine ausländische Telefonnummer für die Registrierung. Wir empfehlen die Nutzung über den transparenten API-Proxy-Dienst von APIYI (apiyi.com) – er leitet alle Server-Tools von Anthropic vollständig durch (einschließlich
web_search/web_fetch/code_execution). Ihr Code benötigt keine Änderungen; ändern Sie einfach diebase_urlaufhttps://vip.apiyi.comund verwenden Sie Ihren APIYI-Schlüssel.
Fortgeschrittene Nutzung der Claude API für die Websuche
Domain-Whitelist: „Vertikale Suche“ umsetzen
Möchten Sie, dass Claude nur innerhalb bestimmter Domains sucht? Verwenden Sie dazu allowed_domains:
tools=[{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"allowed_domains": [
"docs.python.org",
"pypi.org",
"github.com"
]
}]
Beachten Sie dabei folgende Einschränkungen:
allowed_domainsundblocked_domainsdürfen nicht gleichzeitig verwendet werden.- Subdomains werden exakt abgeglichen:
docs.example.comschließtapi.example.comnicht mit ein. - Domain-Beschränkungen auf Anfrageebene müssen mit der Konfiguration auf Organisationsebene kompatibel sein und dürfen den vom Administrator festgelegten Bereich nicht erweitern.
Aktivierung von web_fetch-Zitaten
Während web_search standardmäßig Zitate (Citations) aktiviert hat, muss dies bei web_fetch explizit eingeschaltet werden:
{
"type": "web_fetch_20250910",
"name": "web_fetch",
"max_uses": 5,
"citations": {"enabled": True},
"max_content_tokens": 50000
}
max_content_tokens dient dazu, sehr große Dokumente zu kürzen, damit das Kontextfenster nicht durch einen einzigen Abruf gesprengt wird. Hier einige Richtwerte:
| Inhaltstyp | Größe | Ca. Token |
|---|---|---|
| Normale Webseite | 10 KB | ~2.500 |
| Umfangreiches Dokument | 100 KB | ~25.000 |
| Forschungs-PDF | 500 KB | ~125.000 |
encrypted_content in Multi-Turn-Dialogen
Jedes Ergebnis, das web_search zurückgibt, enthält ein Feld namens encrypted_content. Wenn Sie möchten, dass Claude in einem Multi-Turn-Dialog weiterhin auf frühere Suchergebnisse verweist, müssen Sie dieses Feld unverändert zurücksenden – andernfalls geht der Referenzkontext für nachfolgende Runden verloren.
messages.append({
"role": "assistant",
"content": previous_response.content # Vollständig beibehalten, inklusive encrypted_content
})
messages.append({
"role": "user",
"content": "Analysiere den zweiten Artikel, den du gerade gefunden hast, im Detail."
})
🎯 Technischer Hinweis: Wenn Sie Agent-Frameworks (wie LangChain oder LlamaIndex) verwenden, stellen Sie sicher, dass das Framework alle Inhaltsblöcke der Claude-Antwort vollständig durchreicht. Viele Frameworks "bereinigen" Felder wie
server_tool_use, was dazu führt, dass Zitate nicht mehr funktionieren. Wir empfehlen, direkt auf Basis des Anthropic SDK zu entwickeln und über APIYI (apiyi.com) aufzurufen, um ein Verhalten zu gewährleisten, das exakt dem offiziellen Standard entspricht.
Praxisbeispiele für die Claude API Websuche
Nach der Theorie schauen wir uns nun Best-Practice-Kombinationen für die Claude API Websuche in realen Geschäftsszenarien an.
Szenario 1: Echtzeit-Nachrichtenassistent
Ein Nutzer fragt nach der aktuellen Marktlage – hier sind Echtzeitdaten gefragt. Strategie:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system="Du bist ein Finanzassistent. Bei Echtzeit-Kursen oder Nachrichten musst du zwingend web_search verwenden. Antworten müssen zitiert werden.",
messages=[{"role": "user", "content": "Wie steht der Shanghai Composite Index heute zum Handelsschluss? Wie ist die Entwicklung?"}],
tools=[{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 3,
"allowed_domains": ["sina.com.cn", "eastmoney.com", "163.com"],
"user_location": {
"type": "approximate",
"country": "CN",
"timezone": "Asia/Shanghai"
}
}]
)
Wichtig: Nutzen Sie allowed_domains, um autoritative Finanzseiten festzulegen, und user_location, damit Claude bevorzugt chinesischsprachige Ergebnisse liefert.
Szenario 2: RAG-Optimierung für technische Dokumentation
Claude soll bei technischen Fragen bevorzugt in der offiziellen Dokumentation suchen:
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=4096,
messages=[{
"role": "user",
"content": "Wie implementiere ich WebSocket-Heartbeats in FastAPI? Gib mir ein vollständiges Beispiel."
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search",
"max_uses": 5,
"allowed_domains": [
"fastapi.tiangolo.com",
"docs.python.org",
"github.com",
"stackoverflow.com"
]
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 3,
"citations": {"enabled": True}
}
]
)
Wichtig: Nutzen Sie den dynamischen Filter von web_search_20260209, um irrelevantes HTML auszuschließen, und ziehen Sie dann mit web_fetch den vollständigen Text der relevanten offiziellen Dokumentation.
Szenario 3: Assistent für akademische Forschung
Für Szenarien, die strikte Zitate und Analysen langer Kontexte erfordern, empfehlen wir Opus 4.7 in Kombination mit beiden Tools:
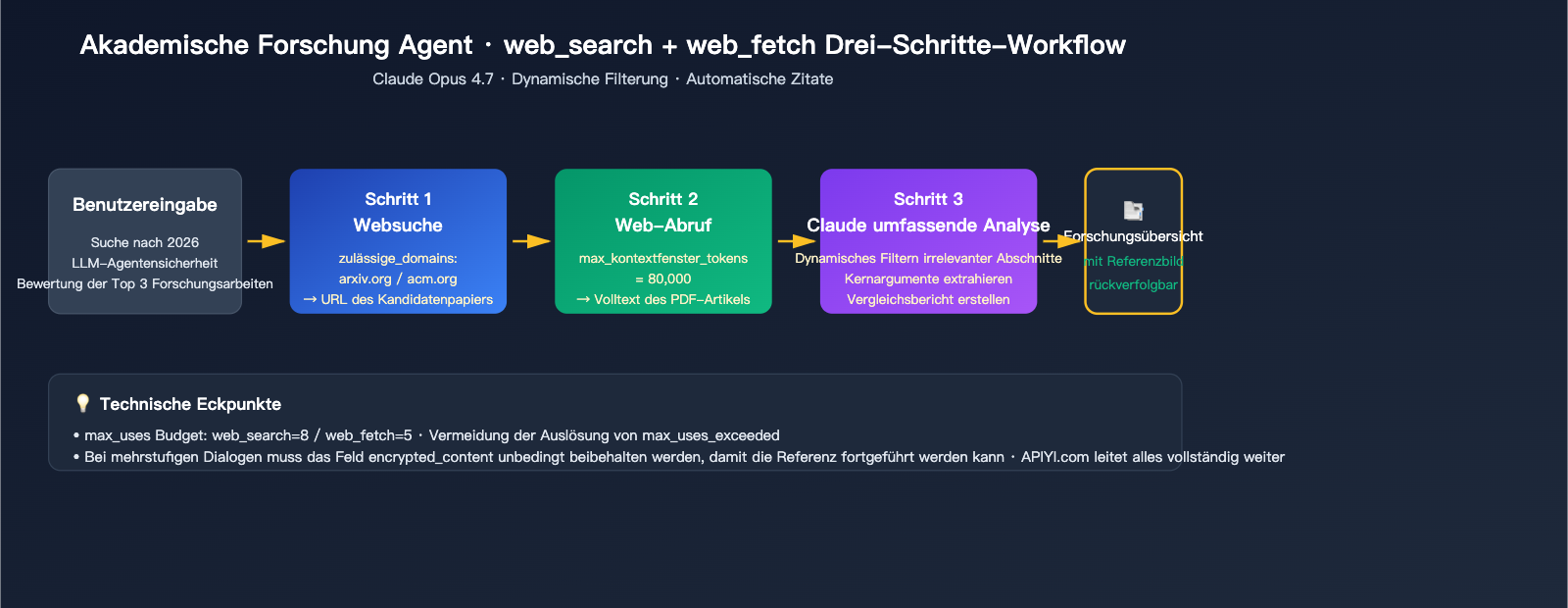
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=8192,
messages=[{
"role": "user",
"content": "Suche nach Forschungsarbeiten aus 2026 zur Sicherheitsbewertung von LLM-Agenten und vergleiche die Top 3."
}],
tools=[
{
"type": "web_search_20260209",
"name": "web_search",
"max_uses": 8,
"allowed_domains": ["arxiv.org", "openreview.net", "acm.org"]
},
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 5,
"citations": {"enabled": True},
"max_content_tokens": 80000
}
]
)
🎯 Empfehlung: Unterschiedliche Geschäftsbereiche haben verschiedene Anforderungen an Suchqualität, Compliance bei Zitaten und Kosten. Wir empfehlen, bei APIYI (apiyi.com) für jedes Szenario einen eigenen API-Schlüssel zu erstellen. So lassen sich Abrechnungsdaten nach Anwendungsfall trennen und die tatsächliche Anzahl der Suchvorgänge sowie der Token-Verbrauch präzise überwachen, anstatt alle Aufrufe zu vermischen.
Engineering Best Practices for Claude API Web Search
Es ist nicht schwer, eine Demo zum Laufen zu bringen, aber um die Claude API Web-Suche wirklich produktiv zu nutzen, müssen einige Hürden überwunden werden.
Praxis 1: Kosten senken und Effizienz steigern durch Prompt Caching
Obwohl die Definition des Server-Tools kurz ist, verursacht sie zusammen mit dem System-Prompt einen nicht zu unterschätzenden Fixkostenaufwand. Aktivieren Sie daher das Prompt Caching:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[{
"type": "text",
"text": "Du bist ein professioneller Forschungsassistent...(500 Wörter System-Prompt hier gekürzt)",
"cache_control": {"type": "ephemeral"}
}],
messages=[...],
tools=[
{
"type": "web_search_20250305",
"name": "web_search",
"max_uses": 5,
"cache_control": {"type": "ephemeral"}
}
]
)
Praxistest: Bei wiederholten Anfragen innerhalb von 5 Minuten können die Token-Kosten für den System- und Tool-Teil um 90 % gesenkt werden.
Praxis 2: Streaming-Antworten zur Vermeidung von Timeouts
Eine einzelne web_search-Ausführung kann 5–15 Sekunden dauern. Wenn Ihre nachgelagerten Systeme (Gateways, Clients) ein 30-Sekunden-Timeout haben, sollten Sie unbedingt stream=True aktivieren, um die Verbindung durch Streaming-Heartbeats aktiv zu halten.
Praxis 3: Konsistenz über mehrere Runden bei encrypted_content
In mehrstufigen Dialogen kann Claude auf Ergebnisse früherer Suchanfragen verweisen. Sie müssen in jeder Anfrage das vollständige Content-Array aller vorherigen Assistant-Nachrichten beibehalten; beschränken Sie sich nicht nur auf den Textteil:
# ❌ Falsche Vorgehensweise
messages.append({"role": "assistant", "content": response.content[-1].text})
# ✅ Richtige Vorgehensweise
messages.append({"role": "assistant", "content": response.content})
Praxis 4: Ratenbegrenzung und Wiederholungsstrategien
Die Ratenbegrenzung für web_search ist unabhängig von der normalen Nachrichten-Schnittstelle. Es empfiehlt sich, auf SDK-Ebene eine Wiederholungslogik mit exponentiellem Backoff zu implementieren:
| Fehlercode | Wiederholungsstrategie | Maximale Versuche |
|---|---|---|
too_many_requests |
Exponentieller Backoff (2s/4s/8s) | 3 |
unavailable |
Feste Verzögerung (5s) | 2 |
max_uses_exceeded |
Keine Wiederholung, max_uses erhöhen | – |
query_too_long |
Keine Wiederholung, Abfrage kürzen | – |
🎯 Empfehlung für die Produktion: Protokollieren Sie alle Fehlerantworten von
web_searchin Ihrem Monitoring-System und analysieren Sie regelmäßig den Anteil vontoo_many_requests– dies ist der Schlüsselindikator, um zu bewerten, ob die aktuelle Kapazität ausreicht. Bei der Nutzung über die APIYI-Plattform (apiyi.com) können Sie Erfolgsraten und durchschnittliche Antwortzeiten direkt im Dashboard einsehen, was den Betrieb erheblich erleichtert.
FAQ zur Claude API Web-Suche
F1: Unterstützt der API-Proxy-Dienst von APIYI die native web_search? Muss der Code geändert werden?
Ja, und zwar ohne Code-Änderungen. APIYI (apiyi.com) nutzt eine transparente Proxy-Architektur, die alle offiziellen Server-Tools von Anthropic vollständig durchleitet. Sie müssen lediglich die base_url auf https://vip.apiyi.com ändern und den API-Schlüssel durch den von APIYI ersetzen. Ihr bestehender Code für die offizielle API läuft ohne eine Zeile Änderung weiter – einschließlich web_search / web_fetch / code_execution und aller anderen nativen Tools.
F2: Wie wird web_search abgerechnet? Sind $10/1000 Anfragen teuer?
Eine Suche = $0,01, unabhängig von der Anzahl der zurückgegebenen Ergebnisse. Fehlgeschlagene Suchanfragen werden nicht berechnet. Im Vergleich: Tavily $0,005/Suche, Brave $0,006/Suche, Google CSE $0,005/Abfrage (nach Überschreiten des Kontingents). Die native web_search ist etwas teurer, spart aber die technischen Kosten für den Betrieb von MCP-Servern und die Einhaltung von Zitierrichtlinien, was für kleine und mittlere Teams oft wirtschaftlicher ist.
F3: Warum erhalte ich den Fehler max_uses_exceeded?
Claude kann während eines Dialogs web_search mehrfach aufrufen (es entscheidet autonom, wie oft gesucht wird). Wenn Sie "max_uses": 1 eingestellt haben, die Frage aber 3 Suchvorgänge erfordert, wird dieser Fehler ausgelöst. Wir empfehlen, für komplexe Fragen ein Budget von 5–10 Versuchen einzuplanen, für einfache Fragen reichen 1–2 aus.
F4: Kann web_search chinesische Webseiten durchsuchen?
Ja. web_search basiert auf dem Echtzeit-Index von Anthropic und deckt chinesische Inhalte gut ab (einschließlich WeChat-Accounts, Zhihu, CSDN usw.). Wenn Sie die Suche auf chinesische Seiten beschränken möchten, können Sie dies über die Whitelist allowed_domains steuern.
F5: Die Token-Nutzung bei der Recherche langer Texte mit web_search ist hoch. Wie kann ich optimieren?
Drei Optimierungsansätze:
- Verwenden Sie die dynamische Filterversion
web_search_20260209(erfordert Claude Opus/Sonnet 4.6+), um irrelevante Abschnitte automatisch zu entfernen. - Nutzen Sie den Parameter
max_content_tokensvonweb_fetch, um das Abrufen pro Seite zu begrenzen. - Aktivieren Sie Prompt Caching, um Tool-Definitionen und System-Prompts zwischenzuspeichern und die Kosten für wiederholte Anfragen zu senken.
F6: Können Drittanbieter-MCP-Suchlösungen und die native web_search kombiniert werden?
Ja. Claude unterstützt die gleichzeitige Definition mehrerer Tools. Achten Sie jedoch darauf, dass die Tool-Beschreibungen klar zwischen ihnen unterscheiden – beschreiben Sie z. B. das MCP-Tool tavily_search als "Suche nach wissenschaftlichen Arbeiten" und das native web_search als "Suche nach allgemeinen Webseiten". Claude wählt dann basierend auf der Beschreibung. Um Mehrdeutigkeiten zu vermeiden, empfehlen wir jedoch, pro Szenario nur ein Such-Tool zu verwenden.
F7: Was tun, wenn der Aufruf der Claude API Web-Suche aus China fehlschlägt?
Die Hauptgründe sind: Instabile direkte Verbindungen zur Anthropic API und die Tatsache, dass die Anthropic-Backend-Infrastruktur bei der Ausführung von web_search IP-Adressen aus Festlandchina blockieren könnte. Die direkteste Lösung ist die Nutzung des API-Proxy-Dienstes von APIYI (apiyi.com) – alle web_search-Anfragen werden über APIYI-Übersee-Knoten an Anthropic weitergeleitet und die Antwort zurückgegeben, was die Stabilität auf das Niveau einer direkten Verbindung aus dem Ausland hebt.
Zusammenfassung und Empfehlungen zur Claude API-Websuche
Rückblickend ist die Claude API-Websuche im Jahr 2026 so ausgereift, dass sie „out-of-the-box“ einsatzbereit ist. Unsere Entscheidungshilfe in einem Satz:
✅ Für 80 % der Projekte reicht die offizielle native
web_searchvöllig aus – einfache Konfiguration, regelkonforme Quellenangaben und direkte Wartung durch Anthropic. Nur für die restlichen 20 % mit spezifischen Anpassungsanforderungen sollten Sie Drittanbieter-MCPs oder eigene Tools in Betracht ziehen.
Checkliste für die Implementierung
Wenn Sie die Claude API-Websuche heute in Ihr Projekt integrieren möchten:
- Modellwahl: Nutzen Sie
claude-sonnet-4-6für allgemeine Szenarien (gutes Preis-Leistungs-Verhältnis) undclaude-opus-4-7für komplexe Recherchen. - Tool-Version: Bevorzugen Sie
web_search_20260209(dynamische Filterung); für ältere Modelle greifen Sie aufweb_search_20250305zurück. - max_uses festlegen: 1–3 Aufrufe für einfache Fragen, 5–10 für komplexe Analysen.
- Kombination mit web_fetch: Wenn eine Volltextanalyse erforderlich ist, kombinieren Sie dies mit
web_fetch, um relevante Seiteninhalte zu extrahieren. - Zugriff konfigurieren: Nutzen Sie den API-Proxy-Dienst von APIYI (apiyi.com) für eine transparente Weiterleitung – ohne VPN und ohne Code-Anpassungen.
🎯 Abschließende Empfehlung: Bei der Claude API-Websuche geht es nicht darum, „ob“ es funktioniert, sondern darum, wie man die Qualität der Suchergebnisse, die Token-Kosten und die Antwortlatenz optimal ausbalanciert. Wir empfehlen, zunächst einige reale Geschäftsszenarien über die Plattform APIYI (apiyi.com) zu testen, die tatsächliche Anzahl der Suchvorgänge und den Token-Verbrauch pro Dialog zu analysieren und erst dann über fortgeschrittene Optimierungen wie Prompt Caching oder dynamische Filterung zu entscheiden. Die Plattform unterstützt die gesamte Claude-Modellreihe sowie native Server-Tools, was eine schnelle Iteration ermöglicht.
Autor: APIYI Technik-Team | Weitere Praxis-Tutorials zur Claude API finden Sie unter help.apiyi.com