Quando você precisa processar dezenas de milhares de descrições de produtos, rotulagem de dados, moderação de conteúdo ou tarefas de vetorização da noite para o dia, a invocação síncrona de APIs padrão torna-se lenta e cara. A API /v1/batches da OpenAI e o Batch Mode do Google Gemini oferecem a mesma solução: faça o upload de um arquivo JSONL, receba todos os resultados de forma assíncrona em até 24 horas e pague 50% a menos.
No entanto, na prática, as plataformas de agregação de API (intermediários) geralmente não suportam o uso direto de /v1/batches, pois seus modelos de cobrança são incompatíveis com o mecanismo de liquidação de tokens assíncronos das interfaces de processamento em lote oficiais. Isso significa que, se você deseja aproveitar o desconto de 50% e a alta capacidade de processamento concorrente para milhões de tokens, você deve usar uma conta oficial + chave API oficial. Para desenvolvedores, o caminho mais prático é fazer um pedido através de serviços profissionais de recarga de API oficial — endereço para pedidos: api-sparkle-charge.lovable.app, ou acesse o AI 代充网: ai.daishengji.com para consultar a lista de preços completa.
Este artigo baseia-se na documentação oficial em inglês da OpenAI e do Google AI, organizando sistematicamente as especificações técnicas, os mecanismos de cobrança e a prática de integração dessas duas APIs de processamento em lote, além de fornecer um guia de escolha de cenários para serviços de recarga.
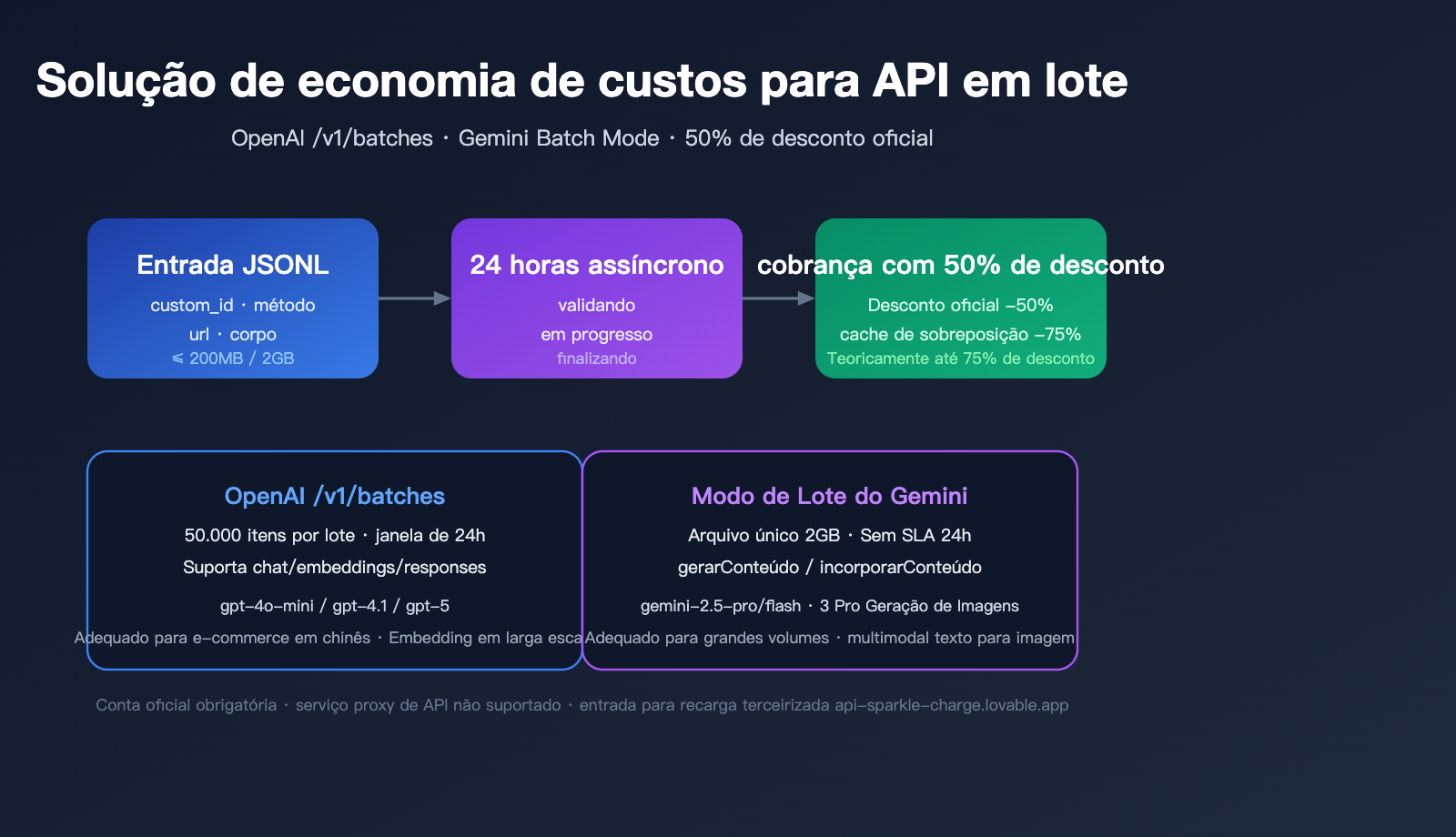
Valor central da API de processamento em lote: por que vale a pena abrir uma conta oficial
A API de processamento em lote (Batch API) é uma interface dedicada projetada pela OpenAI e pelo Google para cenários de não tempo real e alto throughput. Sua lógica de troca central é: você abre mão da determinação da resposta em tempo real em troca de uma redução de 50% no preço oficial e limites de taxa mais altos.
Diferenças essenciais entre processamento em lote e API síncrona
A tabela abaixo compara os parâmetros-chave dos dois modos de invocação:
| Dimensão | API Síncrona | API de Processamento em Lote |
|---|---|---|
| Latência de resposta | Nível de segundos | Até 24 horas |
| Preço por Token | Preço padrão | 50% de desconto (-50%) |
| Limite por solicitação | 1 item | 50 mil itens (OpenAI) / 2GB JSONL (Gemini) |
| Limite de taxa | RPM/TPM rigorosos | Cota independente mais alta |
| Tentativa de falha | Gerenciada pelo chamador | Repetição automática na camada de interface |
| Cache de comando | Janela de 5-10 minutos | Compartilhamento de sistema de comandos em lote reduz custos |
💡 Dica de integração: A API de processamento em lote deve ser usada com contas e chaves nativas oficiais; plataformas de agregação não podem realizar o repasse de tarefas assíncronas
/v1/batches. Recomendamos fazer o pedido de cota oficial diretamente pelo serviço de recarga oficial api-sparkle-charge.lovable.app para obter imediatamente o desconto de 50%, contando com a capacidade de liquidação em várias moedas do AI 代充网 ai.daishengji.com para concluir a recarga da conta em 1 minuto.
Quais cenários são mais adequados para o uso de processamento em lote
De acordo com a documentação oficial e a prática de desenvolvedores experientes, os seguintes cenários apresentam as economias mais significativas:
- Rotulagem/classificação de dados: Análise de sentimento de 100 mil comentários. Invocação síncrona custaria ~$500, processamento em lote sai por apenas ~$250.
- Geração de descrição de produtos: Expansão em massa de SKUs de e-commerce, que geralmente pode ser concluída em um lote durante a noite.
- Resumo/vetorização de documentos: Processamento de bases de conhecimento em larga escala.
- Avaliação de modelo (eval): Execução de conjuntos de testes, onde o tempo de resposta não é crítico.
- Moderação de conteúdo: Filtragem em massa de conteúdo gerado pelo usuário (UGC).
- Geração em massa de Embedding: Construção de bancos de dados vetoriais.
Especificações Técnicas da OpenAI Batch API (/v1/batches)
O endpoint /v1/batches da OpenAI é a referência do setor e opera de forma estável desde seu lançamento em 2024. Sua filosofia de design baseia-se na reutilização completa do corpo da requisição das interfaces síncronas, o que torna o custo de migração para o processamento em lote extremamente baixo para os desenvolvedores.
Restrições Principais e Cotas
| Item | Valor | Descrição |
|---|---|---|
| Janela de conclusão | 24 horas | Atualmente suporta apenas 24h |
| Limite de requisições por lote | 50.000 | Acima disso, é necessário dividir em múltiplos lotes |
| Limite de tamanho por arquivo | 200 MB | Baseado em JSONL codificado em UTF-8 |
| Endpoints suportados | /v1/chat/completions / /v1/embeddings / /v1/completions / /v1/responses |
Não inclui imagens/áudio |
| Desconto no preço | -50% | 50% de desconto em todos os modelos suportados |
| Bucket de taxa especial | Independente | Não consome o TPM (tokens por minuto) síncrono |
Exemplo de formato de arquivo JSONL
A OpenAI exige que cada linha do arquivo enviado seja um objeto JSON independente, contendo quatro campos: custom_id, method, url e body:
{"custom_id": "req-001", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "Você é um especialista em classificação de produtos"}, {"role": "user", "content": "iPhone 17 Pro 256GB"}]}}
{"custom_id": "req-002", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gpt-4o-mini", "messages": [{"role": "system", "content": "Você é um especialista em classificação de produtos"}, {"role": "user", "content": "Sony WH-1000XM6"}]}}
Quatro passos para realizar uma invocação de lote da OpenAI
Passo 1: Fazer upload do arquivo JSONL
from openai import OpenAI
client = OpenAI(api_key="sk-chave-oficial") # Chave oficial obtida via recarga
batch_file = client.files.create(
file=open("requests.jsonl", "rb"),
purpose="batch"
)
Passo 2: Criar a tarefa de processamento em lote
batch = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h",
metadata={"project": "classificacao-sku-2026q2"}
)
print(batch.id) # batch_abc123
Passo 3: Verificar o status (polling)
import time
while True:
b = client.batches.retrieve(batch.id)
print(b.status, b.request_counts)
if b.status in ("completed", "failed", "expired", "cancelled"):
break
time.sleep(60)
Passo 4: Baixar os resultados
if b.status == "completed":
result_text = client.files.content(b.output_file_id).text
with open("results.jsonl", "w") as f:
f.write(result_text)
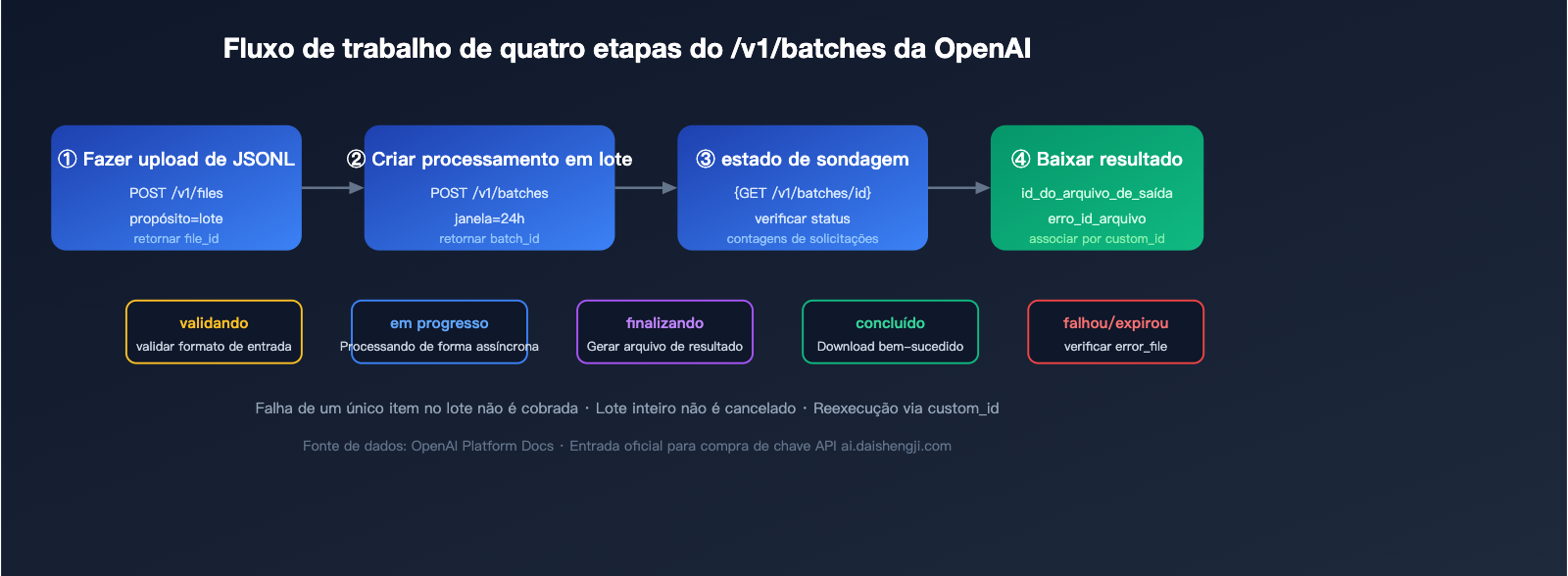
🎯 Dica sobre a chave API: O processamento em lote da OpenAI deve utilizar chaves oficiais nativas
sk-*. Chaves de serviços proxy (hub-*ousk-proxy-*) não conseguem invocar o endpoint/v1/batches. Se precisar obter cota oficial rapidamente, você pode fazer um pedido através de serviços de recarga: o api-sparkle-charge.lovable.app suporta recargas para contas oficiais da OpenAI/Anthropic/Google, com entrega entre 5 a 30 minutos. Você também pode conferir diferentes combinações de valores no site ai.daishengji.com.
Especificações Técnicas do Gemini Batch Mode
O Gemini Batch Mode, lançado pelo Google em 2025, segue uma linha de raciocínio semelhante à da OpenAI, mas é mais agressivo em dois pontos: tamanho de arquivo e adaptação de modelo.
Restrições e Cotas Principais
| Item | Valor | Descrição |
|---|---|---|
| Janela de conclusão | Até 24 horas | Sem SLA rigoroso |
| Limite de tamanho por arquivo | 2 GB | Cerca de 10 vezes o da OpenAI |
| Modelos suportados | gemini-2.5-pro / flash / flash-lite | Inclui Gemini 3 Pro Image |
| Desconto de preço | -50% | 50% de desconto em tokens de entrada + saída |
| Endpoints aplicáveis | generateContent / embedContent |
Mesmos da API síncrona |
| Versão Vertex AI | Suporta implantação regional | Cenários de conformidade corporativa |
Exemplo de formato Gemini JSONL
{"key": "req-001", "request": {"contents": [{"parts": [{"text": "Escreva um ponto de venda de 30 caracteres para o produto: iPhone 17 Pro 256GB"}]}]}}
{"key": "req-002", "request": {"contents": [{"parts": [{"text": "Escreva um ponto de venda de 30 caracteres para o produto: Sony WH-1000XM6"}]}]}}
Exemplo de invocação do Gemini Batch
from google import genai
client = genai.Client(api_key="AIza-chave-oficial")
# Upload do arquivo
uploaded = client.files.upload(file="requests.jsonl", config={"mime_type": "jsonl"})
# Criação do job de processamento em lote
batch_job = client.batches.create(
model="gemini-2.5-flash",
src=uploaded.name,
config={"display_name": "sku-cn-2026q2"}
)
# Obtenção dos resultados
final = client.batches.get(name=batch_job.name)
if final.state.name == "JOB_STATE_SUCCEEDED":
result_file = client.files.download(file=final.dest.file_name)
📌 Dica de recarga Gemini: A capacidade de processamento em lote do Gemini só está disponível em contas pagas nativas do Google AI Studio ou Vertex AI, não estando disponível dentro da cota gratuita. Se você não consegue vincular um cartão de crédito internacional na sua região, pode abrir uma cota paga rapidamente através do canal oficial de recarga Gemini em ai.daishengji.com, ou fazer um pedido de recarga exclusiva diretamente em api-sparkle-charge.lovable.app.
Decisão de comparação: API de processamento em lote da OpenAI vs. Gemini
Ao selecionar a tecnologia para um projeto real, os desenvolvedores costumam hesitar entre as duas. A tabela abaixo apresenta uma comparação em dimensões cruciais:
| Item de comparação | OpenAI Batch | Gemini Batch | Cenário recomendado |
|---|---|---|---|
| Limite por lote | 50.000 requisições | 2GB JSONL (~100 mil+) | Gemini para volumes massivos |
| Tamanho do arquivo | 200 MB | 2 GB | Gemini para volumes massivos |
| Qualidade de resposta (Chinês) | Série gpt-4o/4.1 é forte | gemini-2.5-pro é equilibrado | GPT para raciocínio em chinês |
| Suporte multimodal | Texto/Embeddings | Texto/Geração de imagens | Gemini para imagens em lote |
| Reutilização de cache | prompt caching | implicit context caching | OpenAI para prompts de sistema fixos |
| Complexidade de faturamento | Simples e clara | Requer distinção de níveis | OpenAI para auditoria financeira |
| Maturidade da documentação | Mais madura | Em iteração contínua | OpenAI para implementação rápida |

Sugestões de seleção por cenário
- Processamento em lote de SKU de e-commerce em chinês: gpt-4o-mini Batch, melhor custo-benefício
- Multimodalidade (texto e imagem): Gemini 2.5 Pro Batch, pipeline unificado
- Construção de Embedding em massa: OpenAI text-embedding-3-small Batch
- Conformidade corporativa em múltiplas regiões: Vertex AI Gemini Batch
Otimização Profunda de Reutilização e Cache de Comandos do Sistema
Os usuários costumam perguntar: "Se cada requisição em um processamento em lote (batch) contém o mesmo comando do sistema, é possível cobrar apenas uma vez?" Esta é uma dúvida frequente, mas facilmente mal compreendida.
A verdade sobre a cobrança de comandos em lotes da OpenAI
O endpoint /v1/batches da OpenAI, por si só, não remove automaticamente a duplicidade de comandos do sistema idênticos. No entanto, ao combinar com o mecanismo de Prompt Caching, quando o prefixo da mesma conversa é atingido consecutivamente dentro de um lote, os tokens de entrada em cache (Cached input tokens) recebem um desconto adicional de 50%. Somado aos 50% do processamento em lote, o custo teórico pode chegar a apenas 25% do valor original.
Condições específicas para a aplicação:
- O prefixo do corpo da requisição deve ser estritamente idêntico (incluindo papéis, definições de ferramentas e texto).
- O comprimento do prefixo deve ser ≥ 1024 tokens (512 tokens em alguns modelos).
- O limite de acerto de cache deve ser atingido dentro da mesma janela de 24 horas.
Cache de contexto implícito do Gemini
O modo de lote do Gemini suporta nativamente o Implicit Context Caching. Quando o prefixo da requisição é repetido, o sistema cria automaticamente um cache, sem a necessidade de gerenciar manualmente o cached_content. A parte atingida pelo cache é cobrada de acordo com os preços de cache do Gemini (cerca de 25% do preço original), que, somados aos 50% do Batch, pode chegar a um mínimo de 12,5%.
Cálculo de custo da combinação de processamento em lote + cache
Supondo 100.000 requisições, cada uma compartilhando 2000 tokens de comando do sistema + 500 tokens de entrada do usuário + 300 tokens de saída:
| Plano | Custo por unidade | Estimativa de custo total | Economia |
|---|---|---|---|
| Chamada síncrona (sem cache) | $0,0028 | $280 | Base |
| Síncrona + Prompt Caching | $0,0018 | $180 | -36% |
| Processamento em lote (50% off) | $0,0014 | $140 | -50% |
| Lote + Caching | $0,0009 | $90 | -68% |
⚡ Dica de economia: Quando o mesmo comando do sistema, o mesmo modelo e tarefas noturnas coincidirem, certifique-se de usar a combinação "Processamento em lote + Prompt Caching". Para habilitar essas otimizações em contas oficiais, é necessário confirmar a estratégia de cobrança. Ao fazer um pedido no serviço de recarga api-sparkle-charge.lovable.app, você pode adicionar uma observação como "preciso ativar o desconto de batch + cache", e o sistema vinculará automaticamente a melhor faixa de preço para você.
Por que os serviços proxy de API não suportam processamento em lote: análise técnica
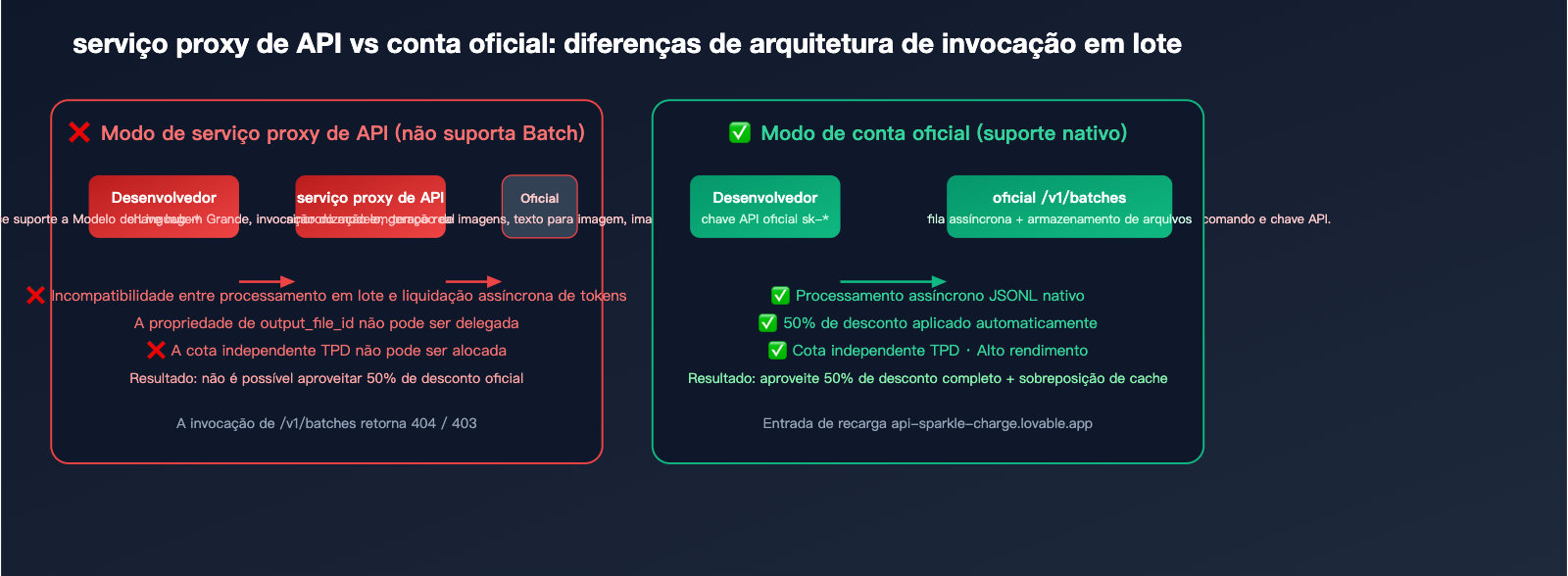
Muitos usuários não entendem por que as plataformas de API de terceiros geralmente não suportam /v1/batches. Isso precisa ser explicado a partir da arquitetura técnica:
Motivo principal 1: Incompatibilidade do modelo de cobrança
Os serviços proxy de API baseiam-se em chamadas em tempo real para cobrança com margem de lucro (custo oficial × 1.x de ágio), enquanto o processamento em lote é liquidado de uma só vez após 24 horas, exigindo que o serviço proxy assuma o risco financeiro e cambial de pagar adiantado e recuperar o valor depois.
Motivo principal 2: Link de retorno de Token não transparente
O output_file_id retornado pela interface de processamento em lote é um objeto do sistema de arquivos oficial. Se um serviço proxy quiser atuar como intermediário, ele teria que replicar todo o sistema de armazenamento e largura de banda de arquivos, sendo difícil alternar a propriedade dos links de download.
Motivo principal 3: Cota de taxa independente
A interface de processamento em lote possui uma cota de TPD (Tokens Per Day) independente, totalmente isolada do TPM/RPM síncrono. O serviço proxy não consegue prever a demanda diária de cota de cada usuário final, tornando difícil fazer uma redistribuição razoável.
Solução: Abrir uma conta oficial via recarga
A solução mais limpa é permitir que o usuário possua diretamente uma conta oficial:
- Nível técnico: Contorna todas as restrições de proxy, acessando nativamente todos os recursos do
/v1/batches. - Nível de conformidade: Faturas, conformidade e reembolsos seguem os canais oficiais.
- Nível de eficiência: Não há necessidade de fazer separação síncrona/assíncrona em cenários de processamento em lote.
- Nível de custo: O serviço de recarga cobra apenas uma taxa de serviço razoável, mantendo intacto o desconto de 50% do processamento em lote.
Esta é a proposta de valor central da api-sparkle-charge.lovable.app e da rede de recarga de IA ai.daishengji.com: ajudá-lo a obter uma conta oficial e chave API de primeira mão, permitindo que você aproveite totalmente os benefícios de economia do processamento em lote.
Prática: Classificação em lote de 100 mil perguntas de suporte ao cliente (exemplo completo)
Abaixo, apresento um exemplo prático e pronto para uso: como realizar a classificação de intenção de 100 mil perguntas históricas de suporte ao cliente.
Passo 1: Construir a entrada JSONL
import json
with open("requests.jsonl", "w") as f:
for idx, q in enumerate(questions): # questions é uma lista com 100 mil itens
payload = {
"custom_id": f"q-{idx:06d}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "Classifique a pergunta do usuário como: billing/tech/sales/other, retorne apenas a palavra da categoria"},
{"role": "user", "content": q}
],
"max_tokens": 8,
"temperature": 0
}
}
f.write(json.dumps(payload, ensure_ascii=False) + "\n")
Passo 2: Dividir pelo limite de 200MB
# Quando 100 mil linhas excederem 200MB, divida em arquivos de 40 mil linhas cada
# Se estiver usando o Gemini, não é necessário dividir, pois o limite é de 2GB
Passo 3: Enviar e monitorar
batches = []
for path in ["part1.jsonl", "part2.jsonl", "part3.jsonl"]:
fobj = client.files.create(file=open(path, "rb"), purpose="batch")
b = client.batches.create(
input_file_id=fobj.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
batches.append(b.id)
Passo 4: Consolidar resultados
results = {}
for bid in batches:
b = client.batches.retrieve(bid)
if b.status == "completed":
content = client.files.content(b.output_file_id).text
for line in content.splitlines():
item = json.loads(line)
results[item["custom_id"]] = item["response"]["body"]["choices"][0]["message"]["content"]
Estimativa de custo: 100 mil × ~600 tokens × preço Batch do gpt-4o-mini ≈ $6-9, economizando $6-9 em comparação com chamadas síncronas.
Perguntas Frequentes (FAQ)
Q1: A chave API de um serviço proxy de API pode invocar /v1/batches?
Não. As chaves retornadas por serviços proxy (geralmente começando com hub-, sk-proxy- ou prefixos personalizados) suportam apenas endpoints síncronos como /v1/chat/completions. A interface de processamento em lote depende do sistema de arquivos e da fila de tarefas assíncronas da conta oficial, exigindo obrigatoriamente uma chave sk-* nativa. Se precisar de uma chave oficial, você pode fazer um pedido via api-sparkle-charge.lovable.app ou visitar o site ai.daishengji.com para ver diferentes planos de contas oficiais.
Q2: O desconto de 50% do Gemini Batch se aplica a todos os modelos?
Atualmente, o Gemini 2.5 Pro, 2.5 Flash, 2.5 Flash-Lite e Gemini 3 Pro Image desfrutam do desconto de 50% no processamento em lote, com redução proporcional tanto nos tokens de entrada quanto de saída. Contas do nível gratuito (Free Tier) não podem usar processamento em lote; é necessário ter uma conta paga. Contas oficiais pagas obtidas via recarga estão prontas para uso imediato.
Q3: O que fazer se uma tarefa de processamento em lote falhar? O custo é reembolsado?
A política é a mesma para ambos: requisições individuais que falharem não são cobradas, e o lote inteiro não é cancelado. O output_file retornado pela OpenAI conterá entradas com falha no campo error, e o error_file_id agrega todos os erros; o Gemini fornece detalhes de erro quando o state=JOB_STATE_FAILED. Você pode reenviar as entradas com falha diretamente usando o custom_id.
Q4: O Prompt Caching é acionado no processamento em lote?
Sim. A documentação da OpenAI especifica que, quando as requisições em lote atingem os Cached Input Tokens, o desconto de 50% do Batch é aplicado sobre o valor já reduzido dos tokens em cache (resultando em 25% do preço original). Para que funcione, garanta que o prefixo das requisições dentro do lote seja estritamente consistente e atinja o comprimento mínimo de cache.
Q5: As contas oficiais de serviços de recarga são seguras? Posso recarregar por conta própria depois?
Serviços de recarga legítimos (como api-sparkle-charge.lovable.app) entregam contas oficiais com propriedade total, onde as informações de login e métodos de pagamento podem ser alterados por você. Posteriormente, é possível renovar usando seu próprio cartão de crédito internacional ou Apple Pay. O site ai.daishengji.com oferece diversos pacotes, suporta emissão de faturas e recibos para fins de conformidade corporativa.
Resumo
A API de processamento em lote (Batch API) é a alavanca de economia mais subestimada para a implementação de engenharia de IA em 2026: uma única linha completion_window="24h" e o custo total é reduzido pela metade. No entanto, ela impõe um requisito rígido ao chamador: é obrigatório o uso de contas e chaves oficiais nativas, já que plataformas de serviço proxy de API não conseguem realizar essa intermediação devido às limitações da arquitetura de cobrança.
Para equipes com tarefas offline em larga escala, o caminho mais econômico é abrir diretamente uma conta oficial e aplicar uma otimização profunda com o Prompt Caching. O serviço de recarga oficial de API é a porta de entrada mais conveniente para desenvolvedores brasileiros acessarem esse benefício: faça seu pedido em api-sparkle-charge.lovable.app e confira a tabela de preços completa em ai.daishengji.com. Pedidos realizados em 5 minutos e processados em 30 minutos, permitindo que você aproveite imediatamente o desconto de 50% do processamento em lote.
📌 Autoria: Este artigo foi preparado pela equipe técnica da APIYI (apiyi.com), com base na documentação oficial em inglês da OpenAI Platform e do Google AI for Developers. Os preços e cotas estão sujeitos às políticas oficiais de 14/04/2026. Link para recarga: api-sparkle-charge.lovable.app / ai.daishengji.com