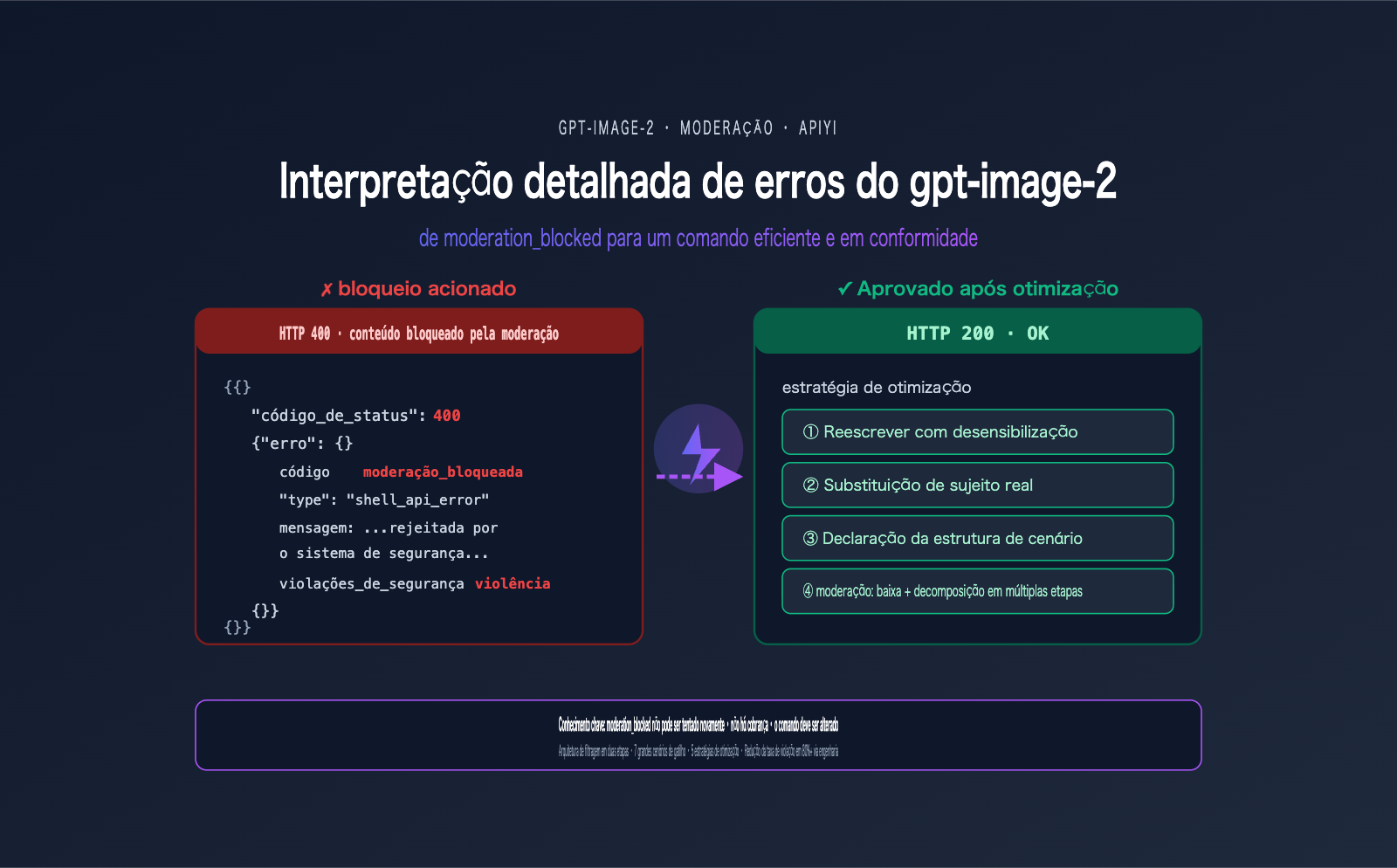
Um usuário recebeu o erro abaixo ao invocar o gpt-image-2 — este é um dos erros mais frequentes na comunidade de desenvolvedores desde o lançamento do gpt-image-2 em abril de 2026:
{
"status_code": 400,
"error": {
"message": "Your request was rejected by the safety system. ... safety_violations=[violence].",
"type": "shell_api_error",
"code": "moderation_blocked"
}
}
A primeira reação de muitos é: "Vou adicionar uma tentativa de reenvio (retry) e pronto". Mas essa é uma reação errada — o mesmo comando (prompt) continuará sendo bloqueado mesmo após 100 tentativas. A essência do erro moderation_blocked no gpt-image-2 é que a solicitação sequer chega ao modelo; ela é ativamente rejeitada pelo classificador de segurança prévio. Tentar novamente é apenas perda de tempo.
Este artigo parte deste caso real de erro para dissecar sistematicamente o mecanismo de revisão de segurança do gpt-image-2 (incluindo a arquitetura de filtragem em duas etapas), o panorama dos 7 principais cenários de gatilho, 5 estratégias de otimização de comandos e práticas de engenharia para reduzir a taxa de erro do gpt-image-2 em produção. Após a leitura, você poderá realizar uma auditoria de conformidade em seus modelos de comando e reduzir a taxa de violação em mais de 80%.
Interpretação da essência do erro moderation_blocked no gpt-image-2
Para resolver este erro, é preciso primeiro entender o que ele realmente é. Muitos desenvolvedores o tratam como "o modelo se recusou a responder", mas, na verdade, não é nada disso.
Fatos fundamentais sobre o erro moderation_blocked no gpt-image-2
| Fato | Explicação | Implicação de Engenharia |
|---|---|---|
| HTTP 400 (lado do cliente) | Erro de nível de solicitação, não falha no servidor | Retentativas são inúteis, é preciso alterar o comando |
| Solicitação não chegou ao modelo | Bloqueada pelo classificador prévio | Não há cobrança, não consome tokens |
code=moderation_blocked |
Código de erro padronizado, identificável programaticamente | Adequado para criar pipelines de reescrita automática |
safety_violations=[…] |
Lista as categorias de violação acionadas | Localiza com precisão a parte que precisa ser alterada |
| 100% de reprodução com o mesmo comando | O resultado é determinístico, não é um evento probabilístico | É obrigatório reescrever o comando para restaurar |
Mecanismo de revisão de segurança em duas etapas do gpt-image-2
Para entender o erro do gpt-image-2, é preciso primeiro observar a arquitetura de filtragem de segurança em duas etapas da OpenAI.
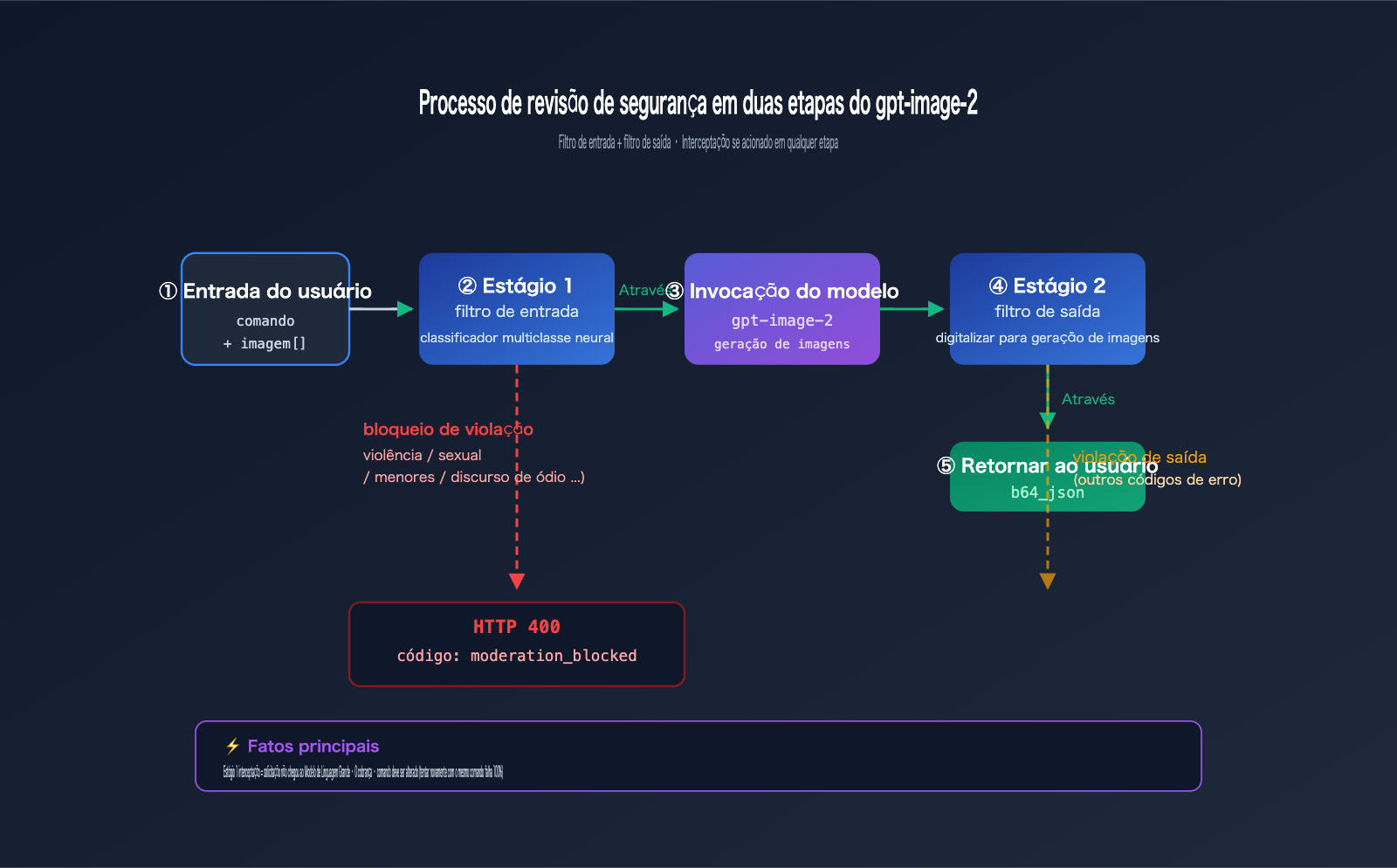
Todo o fluxo de segurança possui, na verdade, duas barreiras:
Etapa 1 · Filtro de Entrada (Input Filter):
- Analisa o texto do seu comando.
- Analisa todas as imagens de referência enviadas (se você invocar
/v1/images/edits). - Utiliza um classificador neural multiclasse.
- É aqui que o
moderation_blockedé acionado.
Etapa 2 · Filtro de Saída (Output Filter):
- Analisa as imagens que o modelo já gerou.
- Se o conteúdo gerado violar as normas, ainda pode ser bloqueado.
- Geralmente retorna um código de erro diferente (não
moderation_blocked).
O caso fornecido pelo usuário acionou a Etapa 1 (filtro de entrada), portanto, não entrou na fase de inferência do modelo. Isso também explica por que a resposta a esse tipo de erro é muito rápida (geralmente < 1 segundo) — ela não entrou em fila nem consumiu GPU.
Diferenças de Backend no erro do gpt-image-2
Um fato que é facilmente ignorado: a severidade da revisão varia entre diferentes canais de backend. Ao usar o mesmo comando, a taxa de acionamento entre a conexão direta da OpenAI e o Azure OpenAI terá diferenças significativas; o Azure é geralmente mais rigoroso. É por isso que a mensagem de erro no caso do usuário menciona "contact us at Azure support ticket" — essa solicitação foi, na verdade, roteada para o filtro do backend do Azure.
🎯 Sugestão de escolha de canal: Se você está testando o mesmo comando em diferentes canais, é normal encontrar bloqueios em alguns e aprovações em outros. Recomendamos validar através do canal de redirecionamento oficial da OpenAI via APIYI (apiyi.com). Este canal segue a estratégia de filtragem oficial da OpenAI, e a taxa de acionamento é consistente com a conexão direta da OpenAI, facilitando a criação de uma base de comparação.
Panorama das 7 principais situações que disparam erros no gpt-image-2
A OpenAI listou claramente 7 categorias de cenários de alta frequência no System Card público do ChatGPT Images 2.0. Compreender esses 7 cenários é a base para escrever comandos (prompts) que estejam em conformidade com as diretrizes.
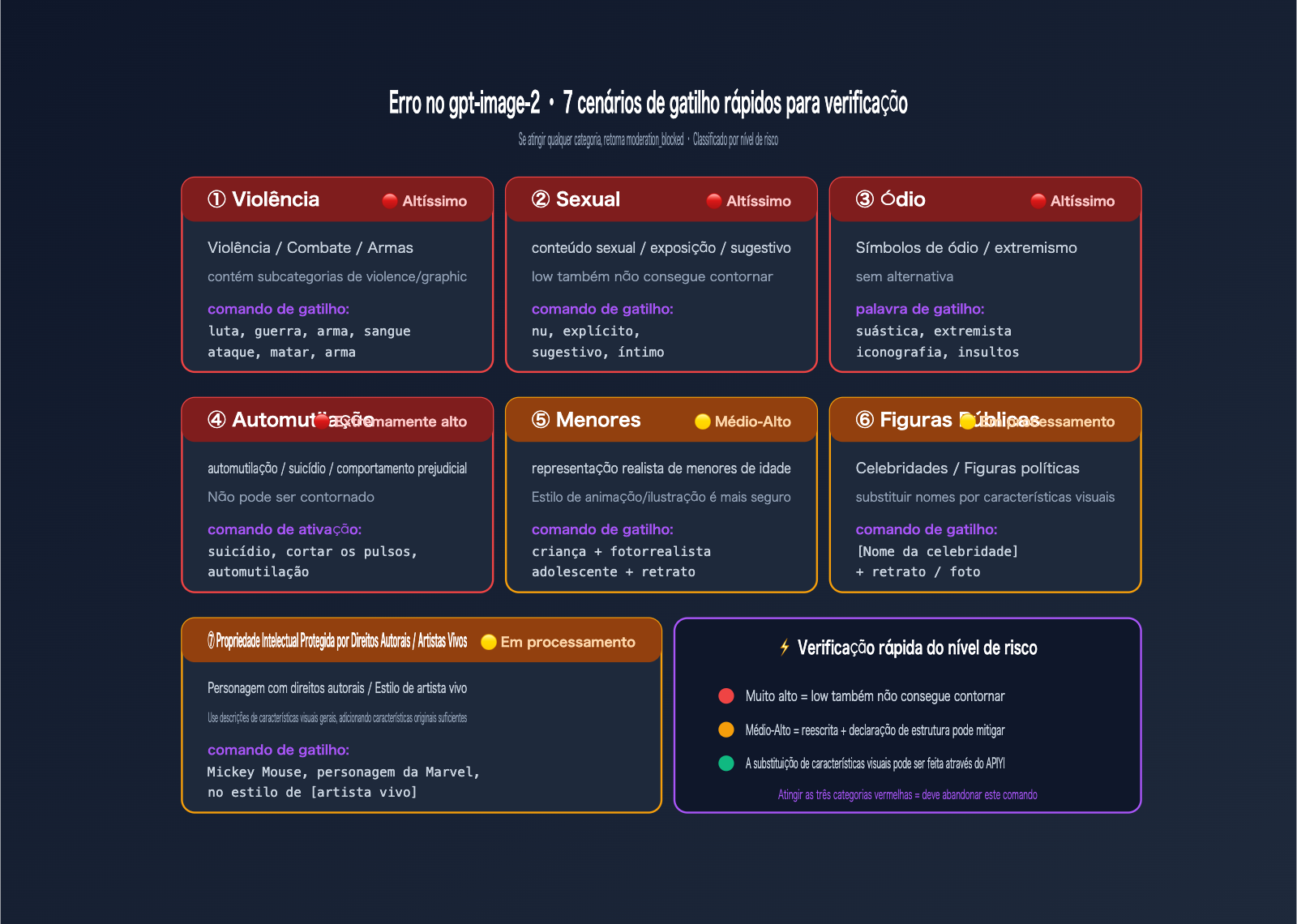
Tabela comparativa de cenários de erro do gpt-image-2
| Categoria | Exemplos de termos de alto risco | Nível de risco |
|---|---|---|
| Violência | luta, guerra, arma, sangue, tiro, soco, matar | 🔴 Alto |
| Violência/Gráfica | gore, grotesco, mutilação, decepado | 🔴 Altíssimo |
| Sexual | nudez, explícito, sugestivo, poses íntimas | 🔴 Altíssimo |
| Símbolos de Ódio | suástica, iconografia extremista específica | 🔴 Altíssimo |
| Automutilação | suicídio, cortes nos pulsos, autolesão | 🔴 Altíssimo |
| Menores | combinação de criança + fotorrealista | 🟡 Médio-Alto |
| Figuras Públicas | figuras políticas, nomes de celebridades | 🟡 Médio |
| IP com Direitos Autorais | personagens da Disney, Marvel, nomes de IP conhecidos | 🟡 Médio |
| Artistas Vivos | "no estilo de [nome do artista vivo]" | 🟡 Médio |
Decomposição das subcategorias de violência no gpt-image-2
O parâmetro safety_violations=[violence] corresponde, na verdade, a duas subcategorias que muitas pessoas da área confundem:
violence → Descrição de violência geral (ações, conflitos, presença de armas)
violence/graphic → Detalhes de violência gráfica e sangrenta
Sempre que o seu comando disparar qualquer uma dessas subcategorias, ele retornará safety_violations=[violence]. Isso significa que, mesmo que você escreva algo relativamente neutro como "um soldado com um rifle", o contexto geral do comando pode ser classificado pelo sistema como a categoria de violência.
Interpretação profunda de casos de usuário: a causa raiz do erro "violence"
Voltando ao erro real mencionado no início. O campo safety_violations=[violence] nos informa que um bloqueio por conteúdo violento foi acionado, mas qual palavra específica causou isso? Abaixo, apresento um roteiro de diagnóstico sistemático.
Lista de palavras que acionam o erro "violence" no gpt-image-2
Com base no feedback da comunidade e em testes práticos, os termos a seguir aumentam significativamente a taxa de bloqueio por violência (não se limitando apenas a estes):
| Tipo de palavra-chave | Palavras de alta violação | Alternativas seguras |
|---|---|---|
| Nomes de armas | gun, rifle, sword, knife, weapon | ceremonial prop, movie prop, decorative blade |
| Ações violentas | fight, attack, shoot, stab, punch | dynamic cinematic action, dramatic standoff |
| Contexto de guerra | war, battle, soldier, combat | heroic struggle, historical reenactment |
| Sangue/ferimentos | blood, wound, scar, gore | red splatter, dramatic shadow, weathered |
| Explosão/destruição | explosion, destruction, debris | dramatic light burst, swirling particles |
Fluxo de diagnóstico para o erro no gpt-image-2
Se o seu comando acionou um bloqueio por violência, verifique seguindo esta ordem:
- Verifique palavras de violência explícita: escaneie o comando em busca das palavras-chave listadas acima.
- Verifique a intensidade dos verbos: tente substituir verbos de ação como "fight" ou "attack" por descrições de estado.
- Verifique a imagem de referência (se for um cenário de edição): a imagem enviada contém elementos violentos?
- Verifique o contexto geral: mesmo sem uma palavra de alto risco, a descrição geral pode configurar uma cena violenta.
- Tente adicionar uma declaração de enquadramento: adicione "movie still" ou "theatrical scene" no início do comando.
O uso do ID de solicitação no erro do gpt-image-2
A informação de erro request id: 2026042723155331083492939703753 não é decorativa — ela é a prova única para localizar o log. Se você utiliza um canal oficial, pode entrar em contato com o suporte técnico da plataforma usando este ID para verificar o motivo específico do bloqueio.
💡 Dica de diagnóstico: salve todos os IDs de solicitação e os comandos originais que resultaram em
moderation_blockedpara criar uma "biblioteca de amostras de violação" interna, útil para treinar regras de reescrita automática. Recomendamos exportar os logs de solicitação através do painel da APIYI (apiyi.com) para realizar auditorias de conformidade mensais e identificar os padrões de bloqueio mais frequentes da sua equipe.
5 estratégias de otimização de comando para o erro no gpt-image-2
Abaixo, apresento 5 estratégias validadas na prática para reduzir a taxa de erro do gpt-image-2. A prioridade vai do alto para o baixo, sendo recomendado aplicá-las nesta ordem.
Estratégia 1: Reescrita de dessensibilização do comando
Esta é a estratégia mais comum e eficaz: substituir palavras de alto risco por descrições neutras visualmente equivalentes. O princípio central é manter o efeito visual, removendo a referência à violência.
# ✗ Aciona o bloqueio de violência
- "Two warriors fighting with swords, blood splatter on the ground, war scene"
# ✓ Passa após a reescrita de dessensibilização
+ "Two armored figures in dramatic standoff with ceremonial blades, red light reflections on the stone floor, cinematic composition, theatrical scene"
Mudanças:
fighting→dramatic standoffswords→ceremonial bladesblood splatter→red light reflectionswar scene→theatrical scene
Estratégia 2: Substituição do sujeito real
Evite referências diretas a figuras públicas, celebridades ou personagens protegidos por direitos autorais; use descrições de características visuais.
# ✗ Aciona bloqueio de public_figures ou copyrighted_ip
- "A portrait of [nome da celebridade] in business suit"
- "Mickey Mouse riding a bicycle in Paris"
# ✓ Descrição segura
+ "A portrait of a charismatic 30-year-old Asian businesswoman with shoulder-length black hair, wearing a tailored navy suit"
+ "A friendly anthropomorphic mouse character with round black ears and red shorts, riding a bicycle near the Eiffel Tower"
Nota: Descrições de "estilo" puras ainda podem acionar bloqueios em cenários de personagens protegidos — o filtro julga com base na similaridade visual, não apenas na correspondência de texto. Sugiro adicionar características "originais" suficientes.
Estratégia 3: Declaração de enquadramento de cena
Adicione um enquadramento artístico/criativo claro no início do comando para indicar ao classificador que se trata de uma criação, não da realidade.
- "Soldiers running across a battlefield"
+ "Movie still from a 1940s war drama: soldiers running across a foggy field, sepia tones, film grain texture"
- "Action scene with gunfire"
+ "Video game cutscene illustration: heroic action sequence with stylized energy effects, comic book style"
Palavras de enquadramento comuns:
movie still/film stilltheatrical scene/stage performancevideo game cutscene/game illustrationcomic book panel/manga stylehistorical reenactment/museum dioramaoil painting/watercolor sketch
Estratégia 4: Decomposição em múltiplas etapas
Cenários complexos e de alto risco podem ser divididos em várias etapas:
# Passo 1: Gerar "imagem de referência de estilo" (sem elementos sensíveis)
step1_prompt = "Cinematic storyboard sketch, dramatic composition, sepia tones, no text"
style_ref = client.images.generate(model="gpt-image-2", prompt=step1_prompt)
# Passo 2: Gerar a imagem final usando a descrição de estilo + conteúdo neutro
step2_prompt = "Two figures in dramatic standoff, sepia tones, cinematic storyboard style, dust particles in the air"
final_image = client.images.generate(model="gpt-image-2", prompt=step2_prompt)
Este fluxo de trabalho de "estilo primeiro, conteúdo depois" pode reduzir significativamente a sensibilidade do comando individual.
Estratégia 5: Ajuste do parâmetro de moderação
A API oferece o parâmetro moderation para controlar a sensibilidade (aplicável apenas a modelos de imagem da família OpenAI):
response = client.images.generate(
model="gpt-image-2",
prompt="A dramatic action scene from a noir film",
moderation="low", # O padrão é auto, pode ser reduzido para low
size="1024x1024",
quality="medium"
)
Lembrete importante:
moderation: "low"não desativa a moderação, apenas flexibiliza o limite.- Conteúdos de altíssimo risco (sexo, automutilação, menores de idade de forma realista, símbolos de ódio) serão bloqueados mesmo em "low".
- Se o erro
moderation_blockedpersistir após mudar para "low", significa que o conteúdo realmente ultrapassou o limite e o comando deve ser alterado. - Tenha cautela ao usar "low" em produtos voltados para o usuário final (risco de conformidade).
🚀 Dica para começar rápido: tente primeiro as estratégias 1-3 (reescrita + substituição + enquadramento), que resolvem mais de 80% dos erros de
moderation_blocked. Recomendamos usar a interface unificada da APIYI (apiyi.com) commoderation: autopara validar se o comando está realmente em conformidade antes de decidir se é necessário reduzir para "low".
Comparativo prático: antes e depois da otimização de erros no gpt-image-2
Abaixo, apresento 4 cenários reais que demonstram o efeito prático da otimização de comandos.

Caso 1 de otimização de erro no gpt-image-2: Pôster de filme
# ✗ Antes da otimização (aciona filtro de violência)
- "An action movie poster featuring a male hero firing a gun at enemies, blood splatter background"
# ✓ Depois da otimização
+ "Cinematic action movie poster: a male protagonist in dramatic pose, holding a stylized prop, dynamic motion lines, red gradient background, theatrical lighting, film grain"
Caso 2 de otimização de erro no gpt-image-2: Ilustração de personagem de jogo
# ✗ Antes da otimização (aciona filtro de violência)
- "Fantasy warrior with bloody sword, severed enemy head at his feet, gore details"
# ✓ Depois da otimização
+ "Fantasy warrior video game character art: armored figure with ornate ceremonial blade, defeated stylized monster silhouette at his feet, JRPG illustration style, painterly textures"
Caso 3 de otimização de erro no gpt-image-2: Ilustração educacional histórica
# ✗ Antes da otimização (aciona filtro de violência)
- "World War II soldiers fighting in trenches with rifles and explosions"
# ✓ Depois da otimização
+ "Historical educational illustration depicting a 1940s European trench scene: figures in period uniforms, weathered terrain with dramatic atmospheric effects, sepia documentary style, museum diorama aesthetic"
Caso 4 de otimização de erro no gpt-image-2: Imagem conceitual de publicidade comercial
# ✗ Antes da otimização (aciona filtro de figuras públicas)
- "[Nome da celebridade] holding our coffee product in his usual style"
# ✓ Depois da otimização
+ "Charismatic 35-year-old male model with confident smile, casual blazer, warmly holding a takeaway coffee cup, modern minimalist café background, professional commercial photography"
Melhores práticas de engenharia para reduzir a taxa de erros do gpt-image-2
Se o seu projeto realiza milhares de chamadas ao gpt-image-2 diariamente, a revisão manual de cada comando não é viável. Abaixo, apresento algumas abordagens de engenharia para reduzir a taxa de erros do gpt-image-2.
Fluxo de pré-validação para erros do gpt-image-2
Antes de chamar a API de imagem, realize uma pré-validação usando a Moderations API:
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1"
)
def safe_generate(prompt: str, max_rewrites: int = 3):
# Passo 1: Pré-validação
mod = client.moderations.create(input=prompt)
flagged = mod.results[0].flagged
categories = mod.results[0].categories
if flagged:
offending = [k for k, v in categories.model_dump().items() if v]
raise ValueError(f"O comando disparou a pré-validação: {offending}")
# Passo 2: Invocação do modelo
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="medium"
)
A pré-validação pode bloquear de 60% a 70% das solicitações de alto risco, evitando invocações inúteis.
Pipeline de reescrita automática para erros do gpt-image-2
Para os modelos de comando em produção, você pode construir um reescritor leve:
SENSITIVE_REPLACEMENTS = {
r"\bgun\b": "ceremonial prop",
r"\bsword\b": "ornate ceremonial blade",
r"\bblood\b": "red splatter",
r"\bfight\b": "dramatic standoff",
r"\bwar\b": "heroic struggle",
r"\battack\b": "dynamic motion",
r"\bweapon\b": "stylized prop",
r"\bkill\b": "defeat",
r"\bshoot\b": "aim",
}
import re
def desensitize(prompt: str) -> str:
out = prompt
for pattern, replacement in SENSITIVE_REPLACEMENTS.items():
out = re.sub(pattern, replacement, out, flags=re.IGNORECASE)
if not out.lower().startswith(("movie still", "video game", "theatrical")):
out = "Cinematic movie still: " + out
return out
Encapsulamento de nova tentativa inteligente para erros do gpt-image-2
Estratégia de nova tentativa específica para moderation_blocked — não tente novamente da mesma forma, você deve reescrever o comando primeiro:
from openai import BadRequestError
def generate_with_rewrite(prompt: str, max_attempts: int = 3):
current = prompt
for attempt in range(max_attempts):
try:
return client.images.generate(
model="gpt-image-2",
prompt=current,
size="1024x1024"
)
except BadRequestError as e:
if "moderation_blocked" not in str(e):
raise # Outros erros 400 não devem ser tentados novamente
print(f"[{attempt+1}/{max_attempts}] Disparo de moderação, aplicando reescrita de dessensibilização...")
current = desensitize(current)
if attempt == max_attempts - 1:
# Na última tentativa, adicionamos moderation: low
return client.images.generate(
model="gpt-image-2",
prompt=current,
moderation="low",
size="1024x1024"
)
raise RuntimeError("Todas as estratégias de reescrita falharam")
Painel de monitoramento de conformidade para erros do gpt-image-2
O ambiente de produção deve registrar indicadores-chave de cada violação:
| Indicador | Finalidade |
|---|---|
| Taxa de violação (bloqueios/total de requisições) | Saúde geral |
Distribuição por categoria de safety_violations |
Identificar tipos de violação mais frequentes |
| Top 10 comandos que disparam violações | Otimizar modelos problemáticos |
| Taxa de sucesso após reescrita | Avaliar a eficácia do reescritor |
🎯 Sugestão de implantação em produção: Recomendamos tratar a taxa de violação como um indicador SLO central. Em linhas de produção saudáveis, a taxa de violação deve ser < 2%; valores > 5% indicam problemas sistêmicos nos modelos de comando. Sugerimos usar os logs de requisição do console da APIYI (apiyi.com) para análises diárias e identificar modelos com alta incidência de violações para reescrita centralizada.
Perguntas frequentes (FAQ) sobre erros do gpt-image-2
P1: O erro moderation_blocked do gpt-image-2 gera cobrança?
Não. O classificador de segurança intercepta a solicitação antes que ela chegue ao modelo, sem consumir tokens ou tempo de GPU. Tanto a OpenAI quanto a APIYI seguem essa regra. Se você notar cobranças indevidas, entre em contato com a plataforma para verificação. Recomendamos conferir os registros de cobrança por request_id no console da APIYI (apiyi.com) para garantir que requisições bloqueadas tenham custo zero.
P2: Por que tentar novamente com o mesmo comando no gpt-image-2 não funciona?
Porque o classificador de segurança é determinístico — o resultado da classificação para a mesma entrada é estável, ao contrário dos modelos generativos que possuem aleatoriedade. Tentar 100 vezes resultará em 100 bloqueios idênticos. A única solução é modificar o comando.
P3: O moderation: low do gpt-image-2 pode desativar completamente a moderação?
Não. O low apenas reduz o limite de sensibilidade, tornando-o mais tolerante a conteúdos moderadamente sensíveis, mas conteúdos de altíssimo risco (sexo, automutilação, menores de idade, símbolos de ódio, líderes políticos, etc.) ainda serão bloqueados. Tratar o low como um "botão de desligar" é um equívoco.
P4: Por que meu comando parece inofensivo e ainda assim foi bloqueado?
Existem três possibilidades:
- Contexto geral: Palavras individuais são inofensivas, mas a combinação forma um cenário proibido.
- Polissemia: Palavras com múltiplos sentidos, como "shoot a photo", podem ser mal interpretadas como violência.
- Diferenças de backend: O backend do Azure é mais rigoroso que a conexão direta da OpenAI.
Para o segundo caso, adicionar uma declaração de cenário ("professional photography session") ajuda muito. Recomendamos usar a APIYI (apiyi.com) para armazenar esses "falsos positivos" em uma base de conhecimento interna, servindo como material para iterar seus modelos de comando.
P5: Posso ver qual palavra específica disparou o erro do gpt-image-2?
A API não retorna a palavra exata, apenas a categoria (ex: [violence]). Esta é uma escolha de design da OpenAI para evitar que o sistema seja usado para criar "guias de contorno". Para localizar a palavra, faça uma busca binária: divida o comando em duas partes e teste cada uma separadamente.
P6: Como lidar com violações em imagens de referência (cenários de edição)?
O endpoint /v1/images/edits verifica simultaneamente o texto do comando e todas as imagens de referência enviadas. Se a imagem de referência for a causa:
- Verifique se ela contém violência, insinuações sexuais ou personagens protegidos por direitos autorais.
- Pré-processe a imagem localmente (corte ou desfoque áreas sensíveis).
- Se for uma foto de pessoa real, confirme se não viola a política de figuras públicas.
P7: As categorias de violação do gpt-image-2 são iguais às da Moderations API?
São basicamente iguais, mas com diferenças. As categorias da Moderations API são mais detalhadas (11), enquanto as de geração de imagem são mais granulares (7-9). Recomendamos usar a Moderations API como ferramenta de pré-validação, mas não assuma que os resultados são idênticos — às vezes, um comando aprovado pela Moderations pode ser bloqueado pelo endpoint de imagem.
P8: Posso recorrer de um erro do gpt-image-2?
Pode, mas o efeito é limitado. O request_id na mensagem de erro pode ser usado para solicitar verificação ao suporte técnico. Experiência prática: se for um falso positivo (ex: conteúdo neutro para fins médicos/educacionais), a plataforma pode colocar em uma lista de permissões; se for uma violação real, o recurso não funcionará. Recomendamos enviar o request_id completo e a descrição do cenário de negócio via sistema de tickets da APIYI (apiyi.com) para maior eficiência.
Resumo: Do erro no gpt-image-2 ao comando eficiente e em conformidade
Ao percorrer os 7 capítulos deste artigo, você deve ter dominado o sistema completo de tratamento de erros do gpt-image-2:
- ✅ Compreender a essência ——
moderation_blockedé um erro 400 ao nível da requisição, não gera cobrança e não deve ser tentado novamente. - ✅ Dominar a arquitetura —— Verificação de segurança em duas etapas (Etapa 1: filtragem de entrada + Etapa 2: filtragem de saída).
- ✅ Conhecer os cenários de gatilho —— 7 categorias principais de violação + detalhes da subcategoria de violência.
- ✅ Diagnosticar violações —— Localização precisa através do campo
safety_violations. - ✅ 5 estratégias de otimização —— Reescrita com dessensibilização, substituição de sujeitos, declaração de enquadramento, decomposição em várias etapas e parâmetros de moderação.
- ✅ Soluções de engenharia —— Pré-validação, reescrita automática, nova tentativa inteligente e monitoramento de conformidade.
O ponto mais importante: o erro moderation_blocked no gpt-image-2 não é um bug, mas sim o limite de conformidade do produto. Em vez de reclamar do rigor, trate a "engenharia de comando em conformidade" como uma capacidade de produção — esta é, precisamente, uma das competências centrais para a implementação de produtos de IA no mercado consumidor (C-end).
Se a sua equipe está enfrentando erros frequentes de moderation_blocked, precisa estabelecer um fluxo de auditoria de conformidade de comandos para a linha de produção ou deseja usar soluções de engenharia para reduzir a taxa de violações, recomendamos solicitar uma chave de teste diretamente através da APIYI (apiyi.com) e executar o modelo de código de pré-validação + reescrita automática apresentado neste artigo. Todos os exemplos são baseados no SDK oficial + canal de trânsito da APIYI (campos 100% consistentes com a OpenAI), garantindo alta compatibilidade para reutilização direta em seus próprios projetos.
Referências
-
OpenAI ChatGPT Images 2.0 System Card: Explicação oficial sobre políticas de segurança e mecanismos de bloqueio.
- Link:
deploymentsafety.openai.com/chatgpt-images-2-0/live-blocking - Descrição: Contém a arquitetura de filtragem em duas etapas e a lista completa de categorias de violação.
- Link:
-
Documentação da API de Moderação da OpenAI: Guia oficial para ferramentas de pré-validação.
- Link:
developers.openai.com/api/docs/guides/moderation - Descrição: 11 categorias de violação e métodos de invocação da API.
- Link:
-
Políticas de Uso da OpenAI: Explicação oficial sobre as políticas de uso.
- Link:
openai.com/policies/usage-policies/ - Descrição: Usos proibidos, responsabilidades e requisitos de conformidade.
- Link:
-
Guia de Criação de Comandos para Modelos de Imagem GPT da OpenAI: Melhores práticas oficiais para comandos.
- Link:
developers.openai.com/cookbook/examples/multimodal/image-gen-models-prompting-guide - Descrição: Inclui métodos e exemplos de comandos em conformidade.
- Link:
-
Documentação de Integração do gpt-image-2 da APIYI: Guia completo de integração em chinês.
- Link:
docs.apiyi.com/api-capabilities/gpt-image-2/overview - Descrição: Contém explicações detalhadas sobre parâmetros de moderação e tratamento de códigos de erro.
- Link:
Autor: Equipe Técnica APIYI
Data de publicação: 27 de abril de 2026
Palavras-chave: erro gpt-image-2, moderation_blocked, safety_violations, moderação de conteúdo, otimização de comando, APIYI, conformidade OpenAI