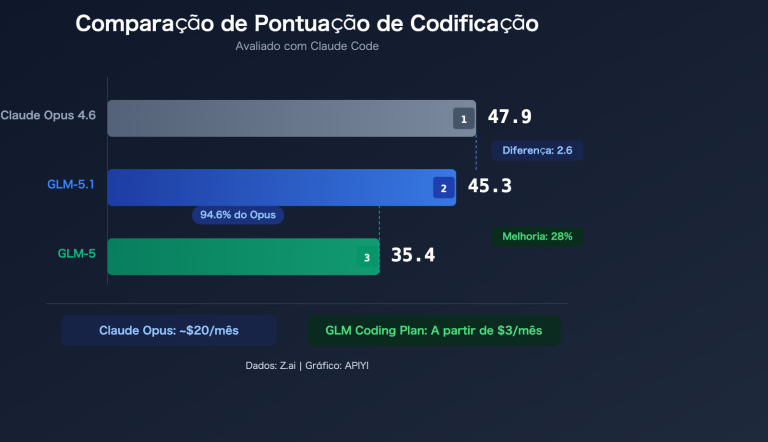
Em abril de 2026, os dois modelos de codificação mais comentados entre os desenvolvedores na China foram o GLM-5.1 e o Claude Sonnet 4.6. O primeiro acaba de ser disponibilizado como código aberto pela Z.ai (antiga Zhipu) sob a licença MIT, alcançando 58,4 pontos no SWE-Bench Pro e superando o Claude Opus 4.6, o GPT-5.4 e o Gemini 3.1 Pro, tornando-se instantaneamente o líder global em codificação open source. O segundo, descrito pela Anthropic como o "nível de flagship entre os modelos intermediários", atingiu 79,6% no SWE-bench Verified, aproximando-se dos 80,8% do Opus 4.6, mas custando apenas uma fração do preço e oferecendo, pela primeira vez, uma janela de contexto de 1M de tokens para a série Sonnet.
A pergunta que fica é: GLM-5.1 vs Claude Sonnet 4.6, quem é realmente mais forte em cenários de programação real? Não é uma pergunta que se responde com uma única frase. Os pontos fortes de cada um são bem distintos: o GLM-5.1 superou o Sonnet 4.6 no benchmark de "correção de código real de nível industrial", mas em avaliações abrangentes de terceiros, o Sonnet recupera a liderança na média geral. Este artigo detalha as diferenças reais entre ambos em 6 dimensões (benchmarks de código, conhecimento, preço, janela de contexto, tarefas de longa duração para agentes e compatibilidade de ecossistema) e oferece recomendações claras de escolha baseadas em cenários de negócio.

Visão geral dos dados principais: GLM-5.1 vs Claude Sonnet 4.6
Antes de começarmos a comparar, vamos colocar os fatos principais lado a lado em uma tabela. Todos os dados provêm de informações públicas do BenchLM, Z.ai, Anthropic e plataformas de avaliação de terceiros.
| Dimensão | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Fabricante | Z.ai (antiga Zhipu AI) | Anthropic |
| Data de lançamento | 07/04/2026 (Open Source) | Início de 2026 |
| Arquitetura | 754B MoE / 40B ativado | Não pública (nível Sonnet médio) |
| Licença Open Source | ✅ MIT | ❌ Fechado |
| Janela de contexto | 200K (203K em algumas plataformas) | 200K → 1M (beta) |
| SWE-bench Verified | 77,8% | 79,6% |
| SWE-Bench Pro | 58,4 ⭐ (Open Source #1, supera Opus 4.6) | Ligeiramente abaixo do Opus 4.6 |
| Média de codificação BenchLM | 58,4 | 66,4 |
| Média de conhecimento BenchLM | 52,3 | 73,7 |
| Pontuação total BenchLM | 79 | 80 |
| Preço de entrada ($/M) | $1,00 (direto Z.ai) | $3,00 |
| Preço de saída ($/M) | $3,20 (direto Z.ai) | $15,00 |
| Tarefas de longa duração (Agent) | ~8 horas por tarefa única | 70% de preferência dos usuários do Claude Code |
| Integração APIYI | ✅ Disponível em https://api.apiyi.com/v1 |
✅ Disponível |
| Ferramentas compatíveis | Claude Code / Cline / Cursor / OpenClaw | Mesmo acima + ecossistema nativo Anthropic |
🎯 Sugestão de decisão rápida: A diferença entre eles não é "quem é mais forte ou mais fraco", mas sim "em qual cenário cada um se destaca". Se você quiser realizar uma comparação horizontal imediata, o APIYI (apiyi.com) já disponibilizou tanto o GLM-5.1 quanto o Claude Sonnet 4.6. Basta alterar o campo
modelpara alternar entre ambos no mesmo código de negócio e, em 15 minutos, você terá um julgamento mais preciso para suas tarefas reais do que qualquer benchmark.
Diferenças fundamentais entre GLM-5.1 e Claude Sonnet 4.6: não são a mesma categoria de modelo
O primeiro fato que precisa ficar claro é: o GLM-5.1 e o Claude Sonnet 4.6, rigorosamente falando, não são modelos da "mesma categoria", pois seus objetivos de design possuem diferenças sistêmicas.
Diferenças de posicionamento dos modelos
| Dimensão | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Posicionamento do fabricante | "Open source de ponta + Codificação de Agente de longo curso" | "Flagship intermediário · Rei do custo-benefício" |
| Escala de parâmetros | Modelo de Linguagem Grande (754B MoE) | Modelo de médio porte (parâmetros não divulgados) |
| Objetivo de treinamento | Codificação + Agente + Raciocínio matemático | Geral + Codificação + Conhecimento + Segurança |
| Modelo de negócio | Open source MIT + API própria da Z.ai | Assinatura fechada + API |
| Principais concorrentes | Claude Opus 4.6 / GPT-5.4 | Claude Opus 4.5 / GPT-5 / Sonnet 4.5 |
Observe esta linha: no posicionamento interno da Z.ai, o GLM-5.1 visa, na verdade, o Claude Opus 4.6, e não o Sonnet 4.6. Isso significa que, se você comparar puramente o "limite superior da capacidade de codificação", o grupo de controle do GLM-5.1 deveria ser o Opus, não o Sonnet. No entanto, em termos de "preço + capacidade abrangente + praticidade", o Sonnet 4.6 é um adversário muito forte no mercado intermediário, portanto, comparar os dois ainda tem um valor de engenharia muito real.
Status atual em avaliações abrangentes de terceiros
De acordo com o ranking provisório publicado pelo BenchLM em abril de 2026:
- Pontuação total: Claude Sonnet 4.6 = 80, GLM-5.1 = 79 (diferença de 1 ponto, quase empatados)
- Média de codificação: Claude Sonnet 4.6 = 66.4, GLM-5.1 = 58.4 (Sonnet 4.6 lidera por 8 pontos)
- Média de conhecimento: Claude Sonnet 4.6 = 73.7, GLM-5.1 = 52.3 (Sonnet 4.6 lidera por 21.4 pontos, a maior diferença)
Mas, em outro benchmark especializado, a situação se inverte completamente:
- SWE-Bench Pro (correção de código industrial real): GLM-5.1 = 58.4 ⭐, superando o Claude Opus 4.6 com 57.3 e o GPT-5.4 com 57.7, com o Sonnet 4.6 naturalmente abaixo deles.
- SWE-bench Verified: Claude Sonnet 4.6 = 79.6%, GLM-5.1 = 77.8%, diferença de apenas 1,8 pontos percentuais.
Ao comparar esses conjuntos de números, chegamos à primeira conclusão: o GLM-5.1 não é um monstro que "supera completamente o Sonnet 4.6", mas ele realmente conquistou o primeiro lugar na "correção de código industrial de maior dificuldade", enquanto o Sonnet 4.6 mantém uma liderança equilibrada em avaliações de codificação mais amplas.
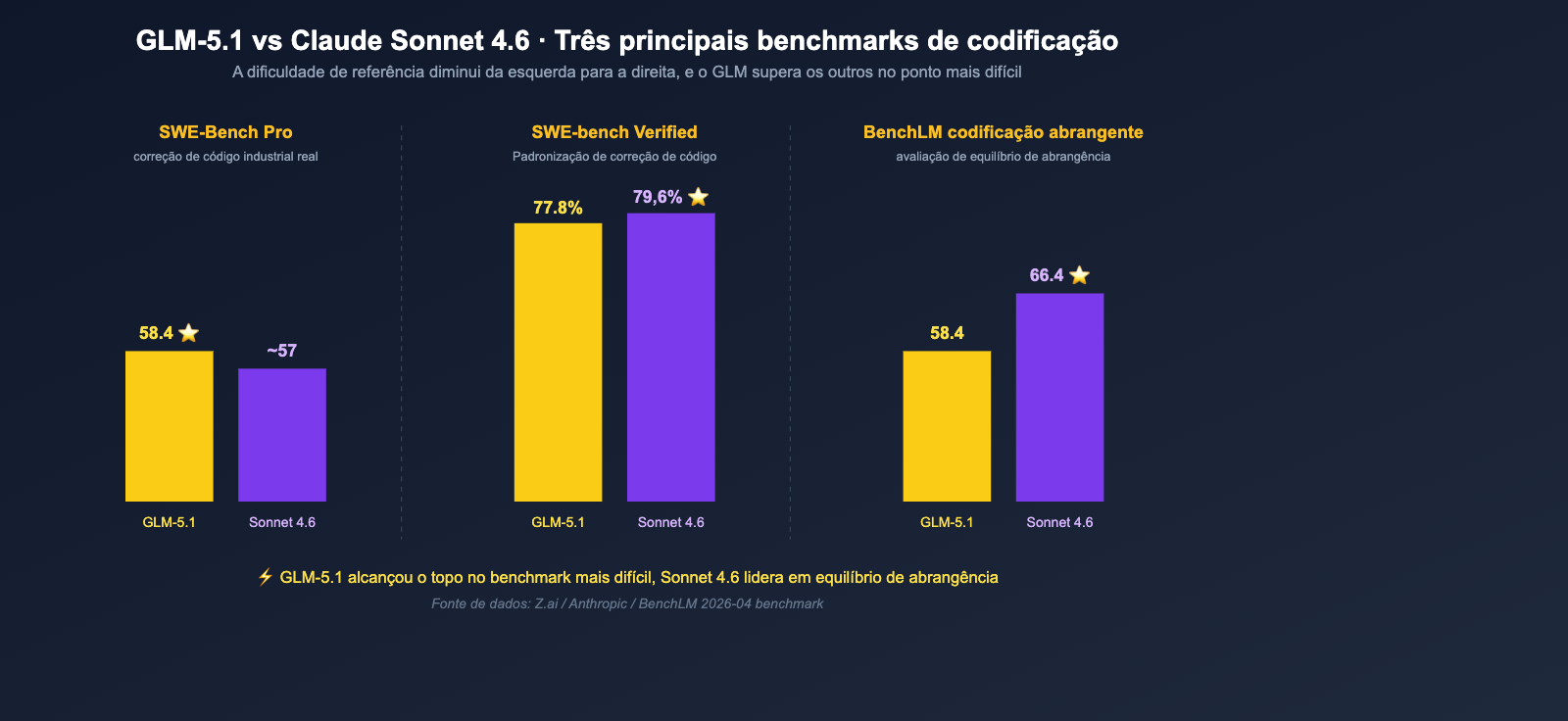
Dimensão 1: Comparação de benchmarks de código — A diferença real entre GLM-5.1 e Sonnet 4.6
A capacidade de codificação é o núcleo desta comparação e também a parte mais fácil de ser mal interpretada pelos números de referência. Consolidamos todos os benchmarks relevantes em uma tabela e, em seguida, faremos uma interpretação sob a perspectiva de um engenheiro.
Comparação completa de benchmarks relacionados a código
| Benchmark | GLM-5.1 | Claude Sonnet 4.6 | Lado líder | Diferença |
|---|---|---|---|---|
| SWE-Bench Pro | 58.4 | < 57.3 | GLM-5.1 | ~1+ ponto |
| SWE-bench Verified | 77.8% | 79.6% | Sonnet 4.6 | 1.8% |
| Média de codificação BenchLM | 58.4 | 66.4 | Sonnet 4.6 | 8 pontos |
| OSWorld (Desktop de Agente) | Não divulgado | 72.5% | Sonnet 4.6 | — |
| Taxa de preferência do usuário Claude Code | Não participou | 70% (vs Sonnet 4.5), 59% (vs Opus 4.5) | Sonnet 4.6 | — |
| Tarefas de longo curso de 8 horas | ✅ Foco oficial | Já suporta longo curso Claude Code | Quase empatado | — |
Interpretação sob a perspectiva de engenharia
Após ler esta tabela três vezes, podemos extrair algumas conclusões que até mesmo quem não é entusiasta de benchmarks industriais pode entender:
- Se o seu trabalho é "corrigir bugs reais em repositórios reais": O GLM-5.1 ocupa o primeiro lugar no SWE-Bench Pro, um benchmark muito "próximo do dia a dia do engenheiro de linha de frente". Isso significa que o GLM-5.1 é o mais adequado como motor central de um Coding Agent;
- Se o seu trabalho é "correção de código padronizada + programação geral": O SWE-bench Verified do Sonnet 4.6 é ligeiramente superior, e a média de codificação abrangente do BenchLM é claramente superior, sendo mais estável em termos de "amplitude";
- Se o seu trabalho envolve tarefas de longo curso no Claude Code / Cursor: A taxa de preferência de usuário de 70% do Sonnet 4.6 mostra que ele foi validado no "fluxo de desenvolvimento real"; a capacidade de longo curso de 8 horas do GLM-5.1 é o principal argumento de venda da Z.ai, mas você precisa testar por conta própria para confirmar os resultados;
- Se o seu trabalho inclui "problemas intensivos em conhecimento" (consultar documentação, escrever design, fazer pesquisa técnica): A diferença de 73.7 vs 52.3 do Sonnet 4.6 para o GLM-5.1 é muito óbvia.
Por que esses "benchmarks entram em conflito"
Muitos leitores perguntam: por que, sendo ambos "capacidade de codificação", um benchmark diz que o GLM-5.1 é mais forte e outro diz que o Sonnet 4.6 é mais forte? A resposta está nas diferenças de design dos benchmarks:
- SWE-Bench Pro tende a "correções de código industrial reais de altíssima dificuldade", com alto nível de exigência de qualidade de tarefa e baixa quantidade, exigindo ao máximo a capacidade de 'raciocínio de longo curso + invocação de ferramentas' do modelo — que é exatamente a direção principal do GLM-5.1;
- SWE-bench Verified é um "conjunto de tarefas de correção de código padrão verificadas por humanos", mais próximo do "nível médio de cenários de desenvolvimento diário", exigindo maior 'amplitude + estabilidade' do modelo — que é o ponto forte do Sonnet 4.6;
- A média de codificação abrangente do BenchLM faz uma média ponderada de vários benchmarks, sendo mais amigável para o flagship de médio porte que consegue lidar com "todos os tipos de tarefas".
Ao entender essa diferença, você não será mais enganado por nenhum número isolado.
🎯 Sugestão de seleção de benchmark: Não tire conclusões baseadas em apenas um benchmark. A abordagem mais pragmática é: organize as 5 a 10 tarefas de codificação reais mais comuns da sua equipe em um conjunto de benchmark interno e, em seguida, use o serviço proxy de API APIYI (apiyi.com) para invocar o GLM-5.1 e o Claude Sonnet 4.6 e executar cada um, validando inversamente com seus próprios dados qual deles é mais adequado ao estilo do seu negócio.
Dimensão 2: Conhecimento e Raciocínio — A clara vantagem do Sonnet 4.6
Se no nível de código podemos dizer que há um "empate técnico", na dimensão de Conhecimento / Raciocínio / Compreensão Geral, a vantagem do Sonnet 4.6 é muito clara.
| Dimensão | GLM-5.1 | Claude Sonnet 4.6 | Diferença |
|---|---|---|---|
| Média de Conhecimento BenchLM | 52.3 | 73.7 | 21.4 pontos |
| Compreensão de documentos longos | Forte | Mais forte (com janela de contexto de 1M) | |
| Escrita em linguagem natural | Excelente em chinês | Equilibrado em vários idiomas | |
| Raciocínio de segurança e conformidade | Médio | Claramente mais forte (ponto forte da Anthropic) |
Isso significa que, nos cenários a seguir, o Sonnet 4.6 é a escolha mais segura:
- Escrita de relatórios de pesquisa técnica / documentos de design / propostas de arquitetura;
- Resumo de documentos em vários idiomas e análise de conformidade;
- Tarefas híbridas que exigem que o modelo "entenda tanto de código quanto de negócio";
- Geração de conteúdo para clientes, que exige barreiras de segurança mais robustas.
A fraqueza relativa do GLM-5.1 na dimensão de conhecimento não significa que o "treinamento foi insuficiente", mas sim que seus dados de treinamento e objetivos estão mais voltados para Codificação + Matemática + Uso de ferramentas, sendo, portanto, menos equilibrado em "conhecimento geral" do que o Sonnet 4.6.
Dimensão 3: Comparação de preços — O trunfo do GLM-5.1
Se olharmos para apenas um item, o preço é a arma mais afiada do GLM-5.1 em comparação ao Sonnet 4.6.
Comparação direta do preço por Token
| Dimensão | GLM-5.1 (Compra direta Z.ai) | Claude Sonnet 4.6 | Vantagem de custo-benefício do GLM-5.1 |
|---|---|---|---|
| Entrada ($/M) | $1.00 | $3.00 | 3 vezes mais barato |
| Saída ($/M) | $3.20 | $15.00 | ~4.7 vezes mais barato |
| Geral (proporção 2:1) | ~$1.73 | ~$7.00 | ~4 vezes mais barato |
Observe alguns pontos:
- Os preços do GLM-5.1 em plataformas de terceiros (como o BenchLM) são ligeiramente mais altos ($1.40 entrada / $4.40 saída), pois incluem uma margem de revenda; o preço oficial de compra direta da Z.ai é $1.00 / $3.20;
- Os valores de $3 / $15 do Sonnet 4.6 são os preços oficiais da Anthropic, que já são 5 vezes mais baratos que o Opus 4.6, tornando-o o "rei do custo-benefício" no mercado intermediário;
- Mesmo assim, a vantagem do GLM-5.1 nos tokens de saída ainda é de 4 a 5 vezes, o que é extremamente significativo para cenários de geração de código onde o "volume de saída é maior que o de entrada".
Exemplo de custo real
Para tornar a diferença mais intuitiva, vamos supor uma tarefa típica de um "Agente de Codificação diário": entrada de 5K tokens, saída de 20K tokens, com 1000 invocações por dia.
| Modelo | Custo de entrada/dia | Custo de saída/dia | Total/dia | Total/mês |
|---|---|---|---|---|
| GLM-5.1 | $5 | $64 | $69 | ~$2.070 |
| Claude Sonnet 4.6 | $15 | $300 | $315 | ~$9.450 |
Diferença: O custo mensal do Sonnet 4.6 é cerca de 4.5 vezes maior que o do GLM-5.1.
Para uma SaaS de médio porte com "1000 invocações de agente por dia", apenas o custo de tokens pode gerar uma diferença de quase 7.000 dólares por mês — dinheiro suficiente para contratar meio engenheiro adicional.
🎯 Sugestão de otimização de custos: Para equipes que já utilizam o Claude Sonnet 4.6, sugerimos começar migrando 20% do tráfego para o GLM-5.1 via APIYI (apiyi.com) para realizar um teste A/B. Se o resultado for aceitável, mova toda a "geração de código de tarefas não críticas" para o GLM-5.1 e mantenha apenas as invocações críticas "voltadas ao cliente" no Sonnet 4.6 — isso reduzirá drasticamente sua fatura sem sacrificar a qualidade geral.
Dimensão 4: Janela de contexto — O contra-ataque do Sonnet 4.6
Em termos de preço, o GLM-5.1 vence com folga, mas no quesito janela de contexto, o Sonnet 4.6 retomou a iniciativa.
| Dimensão | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Contexto padrão | 200K (203K em algumas plataformas) | 200K |
| Contexto Beta | — | 1M de tokens (beta) |
| Saída máxima | 128K | Menor |
| Compressão de contexto | Não | ✅ Compressão automática de contexto antigo |
1M de tokens é a atualização emblemática do Sonnet 4.6 — isso significa que você pode inserir um repositório de código de médio porte inteiro diretamente no comando sem precisar de busca via RAG. Para tarefas como "refatoração de todo o repositório / localização de bugs entre arquivos / compreensão completa da base de código", o Sonnet 4.6 é praticamente insubstituível em abril de 2026.
Os 200K do GLM-5.1 já são suficientes para 90% dos cenários diários, mas ele realmente fica um passo atrás em cenários extremos de "contexto super longo".
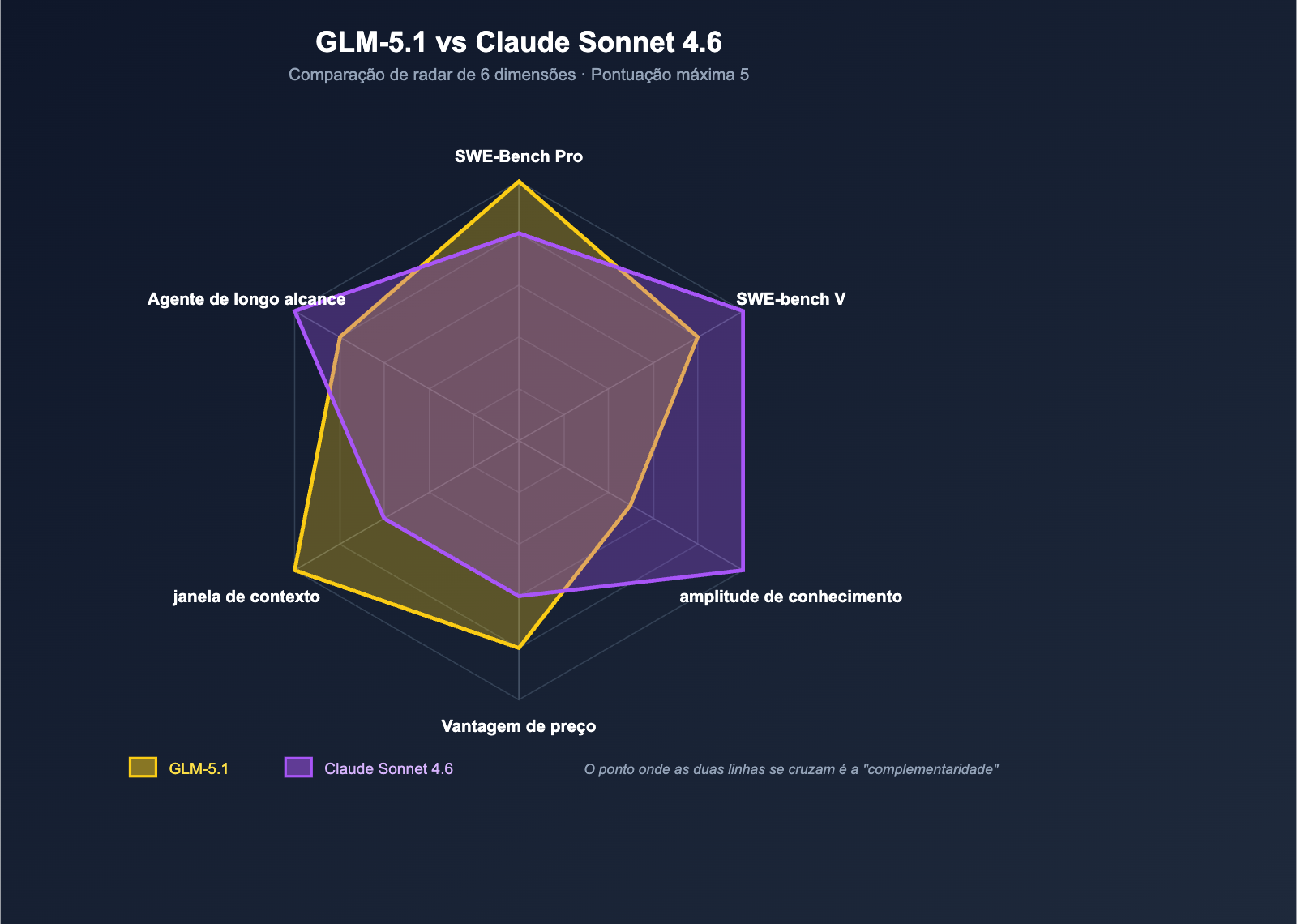
Dimensão 5: Tarefas de longa duração de Agentes — O duelo entre duas abordagens
A quinta dimensão é a capacidade de tarefas de longa duração de Agentes — esta é a área onde todos os principais modelos de codificação estão competindo em 2026.
As rotas de "longa duração" de cada um são diferentes
- GLM-5.1: O Z.ai foca em "trabalho contínuo de 8 horas por tarefa única", enfatizando o ciclo de ponta a ponta de planejamento → execução → teste → correção → otimização secundária, baseando-se na profundidade de raciocínio do próprio modelo e na estabilidade da invocação do modelo;
- Claude Sonnet 4.6: A Anthropic foca na "experiência prática do Claude Code", onde 70% dos usuários do Sonnet 4.5 preferiram o Sonnet 4.6 em testes internos, baseando-se no fluxo de trabalho de engenharia do Claude Code + 1M de contexto + compressão de contexto.
Pode-se entender da seguinte forma:
| Rota | Vantagem principal | Cenário ideal |
|---|---|---|
| GLM-5.1 | Profundidade de raciocínio + estabilidade de invocação do modelo | Agentes de automação em segundo plano / tarefas sem supervisão |
| Sonnet 4.6 | Fluxo de trabalho Claude Code + 1M de contexto | Codificação interativa para desenvolvedores / integração com IDE |
Se você está criando um cenário de "Agente executando em segundo plano para desenvolver funcionalidades" sem supervisão, a capacidade de longa duração de 8 horas do GLM-5.1 é naturalmente adequada; se você está "conversando com o modelo no IDE para escrever código", a experiência de integração do Claude Code no Sonnet 4.6 é mais madura.
Dimensão 6: Compatibilidade de Ecossistema — A vantagem da cadeia de ferramentas do Sonnet 4.6
A última dimensão é o ecossistema. O Sonnet 4.6 ainda mantém uma liderança clara aqui, mas o GLM-5.1 tem reduzido essa distância rapidamente.
| Dimensão | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Compatibilidade Claude Code | ✅(Entrada compatível com OpenAI) | ✅ Nativo |
| Cline / Cursor | ✅(Entrada compatível com OpenAI) | ✅ Nativo |
| OpenClaw | ✅ | ✅ |
| Invocação de ferramentas Anthropic | Estilo OpenAI | ✅ Nativo |
| Frameworks de Agent de terceiros | Maioria suporta compatibilidade OpenAI | Maioria suporta nativo Anthropic |
| Flexibilidade de implantação | ✅ MIT auto-hospedado / APIYI / Z.ai próprio | APIYI / Oficial Anthropic |
Vale notar que o APIYI apiyi.com suporta simultaneamente os três formatos nativos: OpenAI / Claude Native / Gemini Native, o que significa que, independentemente do estilo de SDK que você queira usar para a invocação do modelo GLM-5.1 ou Sonnet 4.6, você pode realizar tudo com a mesma chave API. Este é um detalhe extremamente prático nos testes comparativos entre ambos — você não precisa gerenciar dois conjuntos de autenticação, dois de monitoramento e duas faturas durante os testes.
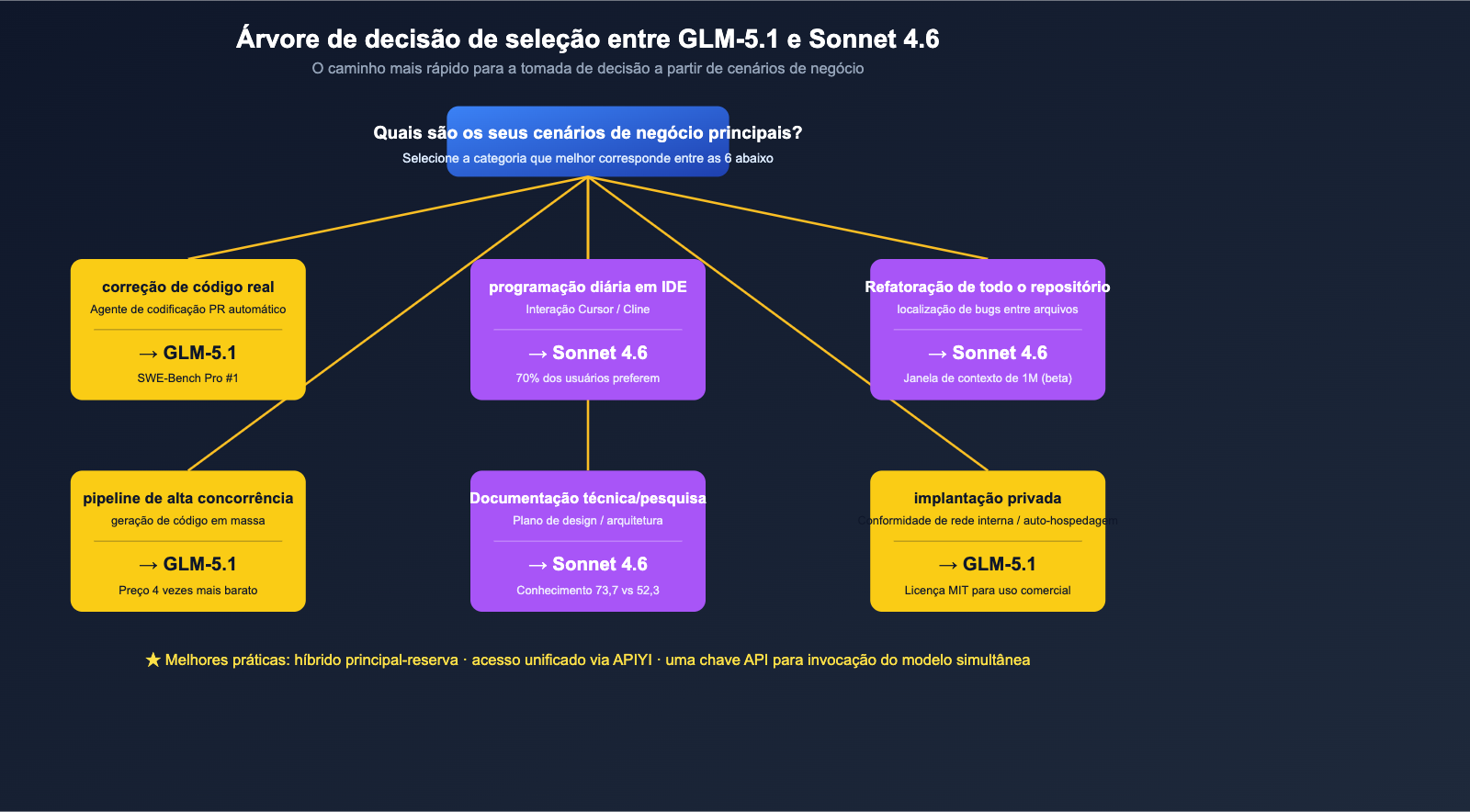
Sugestões de seleção final por cenário
Ao conectar todas as 6 dimensões, podemos oferecer recomendações muito específicas de "seleção de modelo por cenário de negócio".
Tabela de comparação de cenários
| Cenário de negócio | Modelo recomendado | Motivo principal |
|---|---|---|
| Correção de código industrial real (Agent com PR automático) | GLM-5.1 | 1º lugar mundial no SWE-Bench Pro + contexto longo de 8h |
| Codificação diária no IDE (Cursor / Cline) | Claude Sonnet 4.6 | 70% de preferência dos usuários do Claude Code, fluxo de trabalho maduro |
| Refatoração de repositório completo / localização de bug entre arquivos | Claude Sonnet 4.6 | Janela de contexto de 1M (beta) é a arma principal |
| Geração de código padronizada + invocação de alta concorrência | GLM-5.1 | 4x mais barato, ideal para produção em pipeline |
| Pesquisa técnica / documentos de design / arquitetura | Claude Sonnet 4.6 | Vantagem significativa em conhecimento (73,7 vs 52,3) |
| Raciocínio matemático / estilo de competição de algoritmos | GLM-5.1 | AIME 2026 95,3 + GPQA-Diamond 86,2 |
| Módulo de geração de código em SaaS voltado ao cliente | Sonnet 4.6(Principal) + GLM-5.1(Backup) | Sonnet como principal, GLM como garantia, reduz custos mantendo a qualidade |
| Implantação privada / conformidade de rede interna | GLM-5.1 | Licença MIT + auto-hospedagem possível |
| Interação de codificação em chinês | GLM-5.1 | Modelo nacional mais amigável a comandos em chinês |
| Raciocínio de alta dificuldade único + invocação de ferramentas de longa cadeia | Empate, requer teste próprio | Ambos funcionam, diferença abaixo de 5% |
Estratégia híbrida recomendada
Para a grande maioria das equipes de médio porte, recomendamos uma estratégia de "principal e backup" em vez de "escolher um ou outro":
- Modelo principal: Escolha um com base no seu cenário de negócio mais frequente (GLM-5.1 para correção de código, Sonnet 4.6 para integração com IDE);
- Modelo de backup: Configure o outro para validação A/B e alternância gradual (canary deployment) em negócios críticos;
- Camada de acesso unificada: Use a mesma chave API via APIYI apiyi.com para invocar ambos; o código de negócio só precisa alterar o campo
model, sem necessidade de manter duas lógicas de autenticação; - Monitoramento de custos: Separe as faturas dos dois modelos no painel do APIYI e avalie periodicamente qual modelo oferece o melhor "custo-benefício" para o seu negócio, ajustando a proporção de tráfego dinamicamente.
🎯 Dica para implementar a estratégia híbrida: No APIYI apiyi.com, você pode alternar perfeitamente entre o GLM-5.1 e o Claude Sonnet 4.6 com a mesma chave API, bastando alterar uma string no seu código. Sugerimos direcionar 70% do tráfego de "geração de código não crítico" para o GLM-5.1 e reservar 30% do tráfego de "foco no cliente + raciocínio de alta dificuldade" para o Sonnet 4.6. Assim, você aproveita a vantagem de preço do GLM-5.1 e garante a estabilidade em cenários críticos.
FAQ: GLM-5.1 vs Claude Sonnet 4.6
Q1: O GLM-5.1 realmente superou o Claude Sonnet 4.6 em codificação?
Parcialmente, mas ainda há pontos onde ele fica atrás. No SWE-Bench Pro (o benchmark mais difícil, focado em reparos de código reais da indústria), o GLM-5.1 alcançou 58,4, conquistando o primeiro lugar global e superando o Claude Opus 4.6 (57,3) e o GPT-5.4 (57,7), e consequentemente o Sonnet 4.6. No entanto, no SWE-bench Verified (reparo de código padronizado), o Sonnet 4.6 ainda lidera com 79,6% contra 77,8% do GLM-5.1, uma diferença de cerca de 1,8 pontos percentuais. Na média geral de codificação do BenchLM, o Sonnet 4.6 também lidera com 66,4 contra 58,4 do GLM-5.1. Conclusão: o GLM-5.1 superou o Sonnet 4.6 no "pico de dificuldade", mas ainda está atrás na "consistência de amplitude".
Q2: Quanto o GLM-5.1 é mais barato que o Claude Sonnet 4.6?
De acordo com os preços oficiais da Z.ai, o GLM-5.1 custa US$ 1,00 na entrada / US$ 3,20 na saída, enquanto o Claude Sonnet 4.6 custa US$ 3,00 / US$ 15,00 — a entrada é 3 vezes mais barata e a saída é cerca de 4,7 vezes mais barata. Em um cenário típico de "1.000 invocações de Coding Agent por dia + 5K de entrada / 20K de saída", a fatura mensal do Sonnet 4.6 é cerca de 4,5 vezes maior que a do GLM-5.1. Se o seu negócio tem um "volume de saída significativamente maior que o de entrada", a vantagem de custo-benefício do GLM-5.1 será ainda mais evidente.
Q3: Qual tem a maior janela de contexto, GLM-5.1 ou Sonnet 4.6?
O Claude Sonnet 4.6 é maior. O GLM-5.1 possui 200K (algumas plataformas exibem 203K), enquanto o Sonnet 4.6 oferece de 200K a 1M de tokens (beta). Uma janela de 1M significa que o Sonnet 4.6 pode ler um repositório de código de médio porte de uma só vez, o que é sua principal arma em tarefas como "refatoração de repositório completo / localização de bugs entre arquivos". Se a sua tarefa exige um contexto extremamente longo, o Sonnet 4.6 é a escolha mais segura.
Q4: Atualmente uso o Claude Sonnet 4.6 no Cursor / Cline, vale a pena mudar para o GLM-5.1?
Depende de onde dói mais. Se você se preocupa principalmente com a "fatura", o GLM-5.1 pode reduzir seus custos pela metade ou mais, valendo a pena a troca. Se você prioriza a "estabilidade da experiência diária de codificação", a taxa de preferência de 70% dos usuários do Sonnet 4.6 mostra que ele já foi amplamente validado no fluxo de trabalho do Claude Code, e os ganhos da migração podem ser menores que os riscos. A abordagem mais prudente é usar a APIYI (apiyi.com) para direcionar 20% do tráfego para o GLM-5.1 para um teste A/B, e decidir se deve aumentar a proporção após uma semana.
Q5: Ambos, GLM-5.1 e Sonnet 4.6, podem ser invocados via APIYI?
Sim, ambos já estão disponíveis. A APIYI (apiyi.com) suporta nativamente os formatos OpenAI, Claude e Gemini. Basta alterar a base_url do SDK da OpenAI para https://api.apiyi.com/v1 e alternar o model entre glm-5.1 e claude-sonnet-4-6 (ou ID similar). Isso permite rodar ambos no mesmo código, tornando a eficiência da comparação horizontal muito alta.
Q6: Como desenvolvedor independente, qual devo escolher?
Se você só puder escolher um, analise seu fluxo de trabalho: se faz Coding Agent / automação de backend / geração de código em massa → escolha o GLM-5.1; se faz programação interativa no IDE / refatoração de repositório completo / geração de conteúdo voltado ao cliente → escolha o Sonnet 4.6. Se você não quer ter que escolher, conectar ambos e usar a APIYI para gerenciamento unificado é a melhor prática para desenvolvedores em 2026 — a fatura será otimizada automaticamente conforme a seleção do modelo, sem ficar refém de um único fornecedor.
Resumo: O veredito final entre GLM-5.1 e Claude Sonnet 4.6
Combinando os 6 pilares de comparação, o veredito final entre GLM-5.1 e Claude Sonnet 4.6 pode ser resumido assim: O GLM-5.1 possui uma vantagem estrutural em "reparo de código industrial de alta dificuldade + preço + código aberto nacional + agentes de longo curso", enquanto o Claude Sonnet 4.6 mantém a liderança em "consistência de amplitude + profundidade de conhecimento + 1M de contexto + maturidade de fluxo de trabalho no IDE". Eles não são uma relação de "quem substitui quem", mas sim um par de ferramentas complementares para diferentes cenários de negócio.
Para equipes de desenvolvimento na China continental em meados de 2026, a estratégia mais inteligente não é escolher um ou outro, mas sim "mistura de principal e reserva + camada de acesso unificada": deixe o GLM-5.1 lidar com partes sensíveis a custo, automação de longo curso e conformidade de privacidade, e deixe o Sonnet 4.6 lidar com partes voltadas ao usuário, contextos complexos e escrita técnica. Ao usar um serviço proxy de API como a APIYI para colocar ambos sob a mesma chave API e ajustar a proporção de tráfego com base em dados reais de fatura, você pode reduzir drasticamente a fatura mensal sem sacrificar a qualidade.
🎯 Sugestão final: Tanto o GLM-5.1 quanto o Claude Sonnet 4.6 já estão disponíveis na APIYI (apiyi.com). Recomendamos que você crie uma chave API na apiyi.com hoje mesmo, altere a
base_urldo SDK da OpenAI parahttps://api.apiyi.com/v1, rode 5 tarefas no GLM-5.1 com o mesmo código e, em seguida, rode as mesmas 5 tarefas no Sonnet 4.6 com o mesmo comando para validar pessoalmente todas as conclusões deste artigo. Nenhuma avaliação substitui seu teste prático, mas essa validação mínima de 30 minutos lhe dará uma noção real dos dois modelos de codificação mais fortes de 2026.
Autor: Equipe APIYI | Focados na implementação de Modelos de Linguagem Grande e avaliação de cadeias de ferramentas de codificação. Para mais comparações de modelos e invocações práticas, visite APIYI (apiyi.com).