Nota do autor: Leitura aprofundada do conteúdo principal do paper técnico do Kimi K2.5, detalhando a arquitetura MoE de 1T de parâmetros, configuração de 384 especialistas, mecanismo de atenção MLA, além de fornecer os requisitos de hardware para implantação local e comparação de soluções de acesso via API.
Quer entender os detalhes técnicos do Kimi K2.5? Este artigo baseia-se no paper técnico oficial do Kimi K2.5 para interpretar sistematicamente sua arquitetura MoE de trilhões de parâmetros, métodos de treinamento e resultados de benchmark, detalhando também os requisitos de hardware para implantação local.
Valor central: Ao terminar de ler este artigo, você dominará os principais parâmetros técnicos do Kimi K2.5, os princípios de design da arquitetura e terá a capacidade de escolher a melhor solução de implantação de acordo com suas condições de hardware.
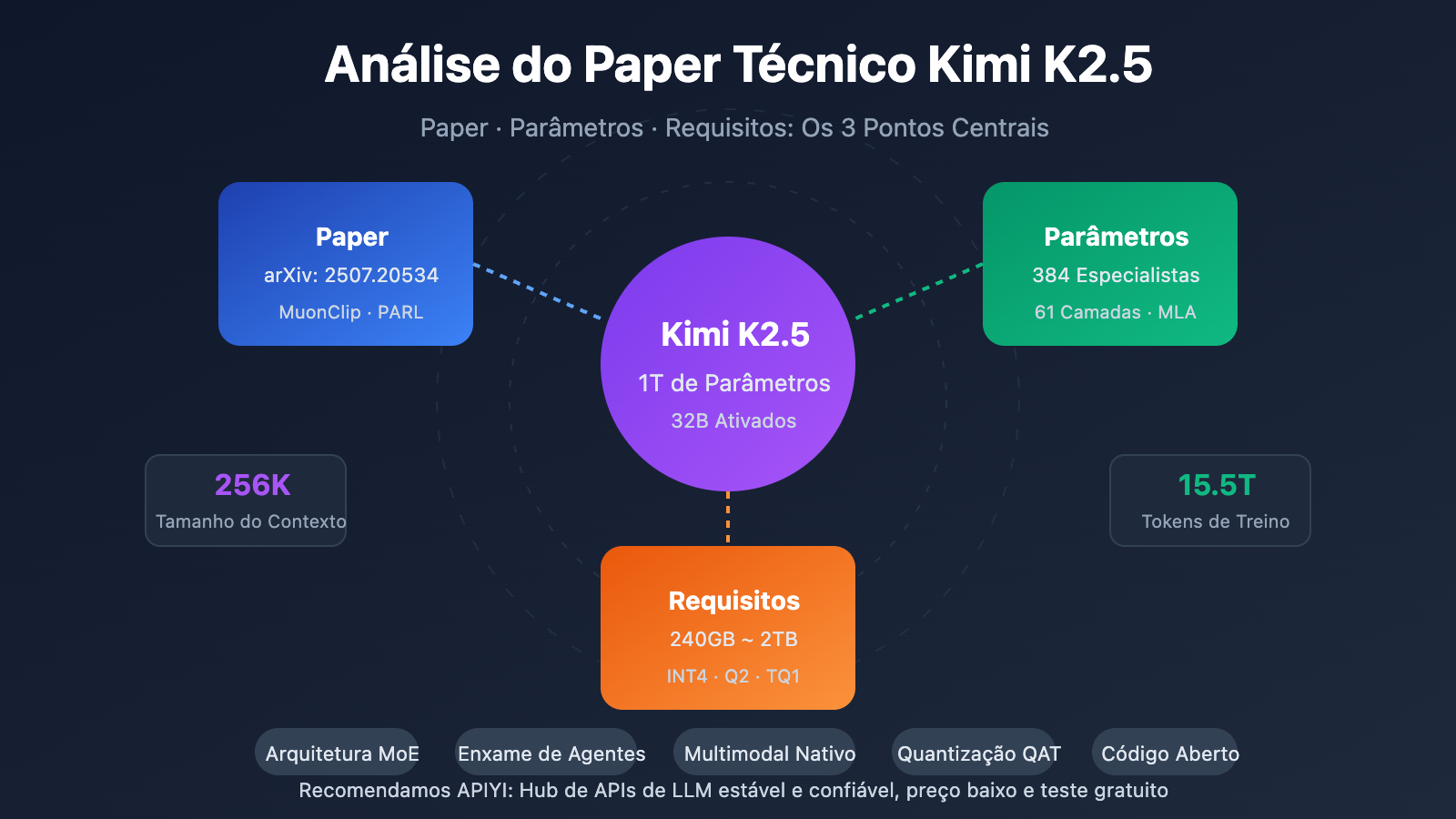
Pontos Centrais do Paper Técnico Kimi K2.5
| Destaque | Detalhes Técnicos | Valor de Inovação |
|---|---|---|
| MoE de Trilhões de Parâmetros | 1T de parâmetros totais, 32B ativados | Apenas 3,2% de ativação na inferência, extrema eficiência |
| Sistema de 384 Especialistas | 8 especialistas selecionados por Token + 1 compartilhado | 50% mais especialistas que o DeepSeek-V3 |
| Atenção MLA | Multi-head Latent Attention | Reduz KV Cache, suporta contexto de 256K |
| Otimizador MuonClip | Treinamento eficiente de tokens, sem Loss Spike | 15.5T Tokens treinados sem picos de perda |
| Multimodal Nativo | Codificador visual MoonViT 400M | 15T de treinamento híbrido visão-texto |
Contexto do Paper Kimi K2.5
O paper técnico do Kimi K2.5 foi publicado pela equipe da Moonshot AI (Yuezhi Anmian), com o registro arXiv 2507.20534. O artigo detalha a evolução técnica do Kimi K2 para o K2.5, com as principais contribuições incluindo:
- Arquitetura MoE Ultra-esparsa: Configuração de 384 especialistas, 50% a mais que os 256 especialistas do DeepSeek-V3.
- Otimização de Treino MuonClip: Resolve o problema de picos de perda (Loss Spike) em treinamentos de larga escala.
- Paradigma Agent Swarm: Método de treinamento PARL (Parallel-Agent Reinforcement Learning).
- Fusão Multimodal Nativa: Integra capacidades de visão e linguagem desde a fase de pré-treinamento.
O paper aponta que, com a crescente escassez de dados humanos de alta qualidade, a eficiência de tokens está se tornando o fator crítico para a expansão de modelos de linguagem grandes, o que impulsionou a aplicação do otimizador Muon e da geração de dados sintéticos.
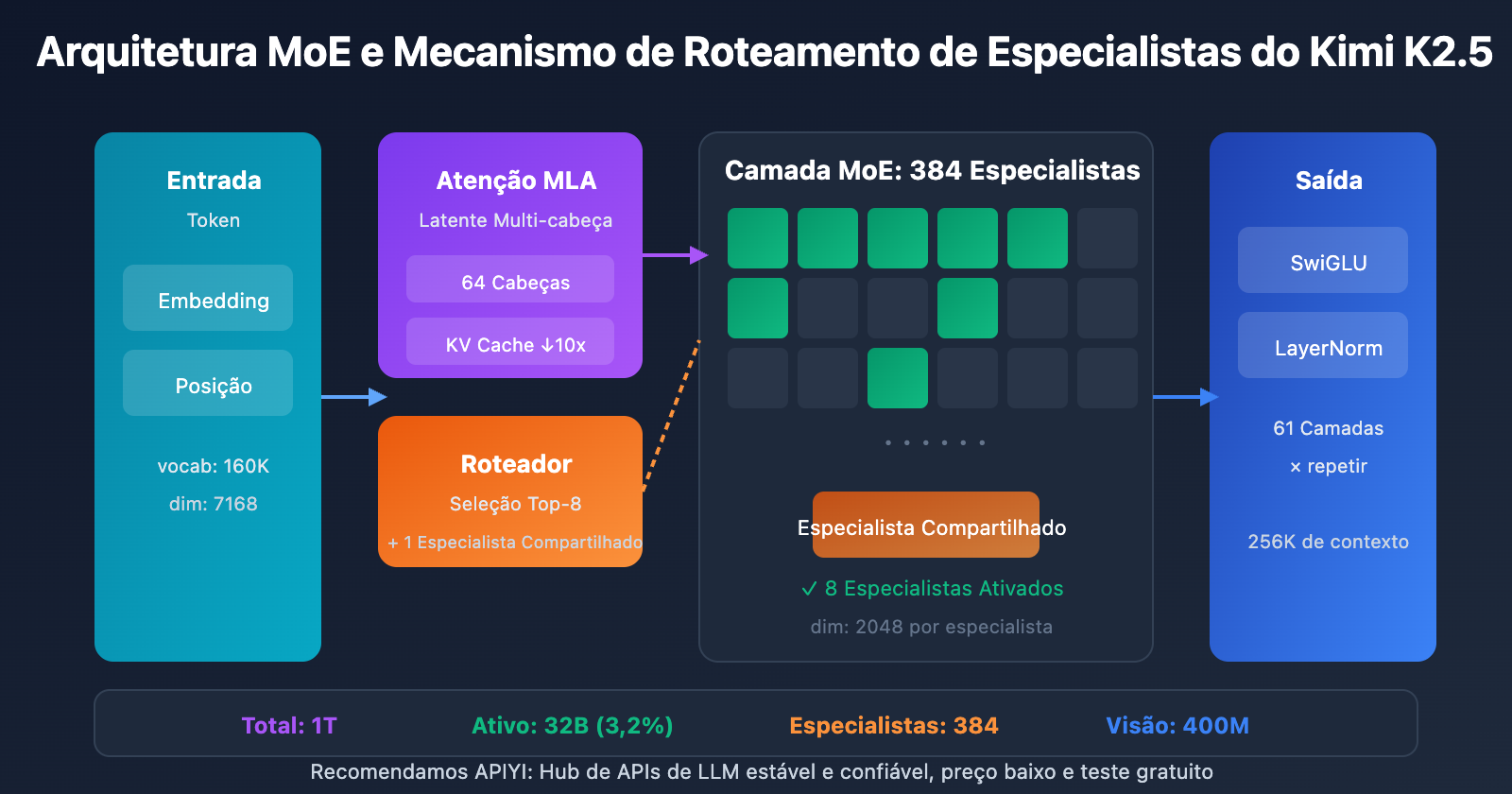
Kimi K2.5: Especificações Completas de Parâmetros
Parâmetros da Arquitetura Principal
| Categoria | Nome do Parâmetro | Valor | Descrição |
|---|---|---|---|
| Escala | Total de Parâmetros | 1T (1,04 trilhão) | Tamanho total do modelo |
| Escala | Parâmetros Ativos | 32B | Usados de fato em uma única inferência |
| Estrutura | Camadas | 61 camadas | Incluindo 1 camada Densa |
| Estrutura | Dimensão Oculta | 7168 | Dimensão do backbone do modelo |
| MoE | Número de Especialistas | 384 | 128 a mais que o DeepSeek-V3 |
| MoE | Especialistas Ativados | 8 + 1 compartilhado | Seleção de roteamento Top-8 |
| MoE | Dimensão Oculta do Especialista | 2048 | Dimensão FFN de cada especialista |
| Atenção | Cabeças de Atenção | 64 | Metade das do DeepSeek-V3 |
| Atenção | Tipo de Mecanismo | MLA | Multi-head Latent Attention |
| Outros | Tamanho do Vocabulário | 160K | Suporte multilíngue |
| Outros | Comprimento do Contexto | 256K | Processamento de documentos ultra-longos |
| Outros | Função de Ativação | SwiGLU | Transformação não linear eficiente |
Interpretação do Design do Kimi K2.5
Por que escolher 384 especialistas?
A análise da Scaling Law no artigo científico demonstra que aumentar continuamente a esparsidade traz melhorias significativas de desempenho. A equipe aumentou o número de especialistas de 256 (no DeepSeek-V3) para 384, elevando a capacidade de representação do modelo.
Por que reduzir as cabeças de atenção?
Para diminuir o custo computacional durante a inferência, o número de cabeças de atenção foi reduzido de 128 para 64. Combinado com o mecanismo MLA, este design mantém o desempenho enquanto reduz drasticamente o uso de memória do KV Cache.
Vantagens do mecanismo de atenção MLA:
MHA Tradicional: KV Cache = 2 × L × H × D × B
MLA: KV Cache = 2 × L × C × B (C << H × D)
L = camadas, H = cabeças, D = dimensão, B = Batch, C = dimensão de compressão
O MLA, através da compressão no espaço latente, reduz o KV Cache em cerca de 10 vezes, tornando possível o contexto de 256K.
Parâmetros do Codificador Visual (Vision Encoder)
| Componente | Parâmetro | Valor |
|---|---|---|
| Nome | MoonViT | Codificador visual proprietário |
| Parâmetros | – | 400M |
| Recursos | Pooling Espaço-Temporal | Suporte para compreensão de vídeo |
| Integração | Fusão Nativa | Integrado na fase de pré-treinamento |
Requisitos de Hardware para o Kimi K2.5
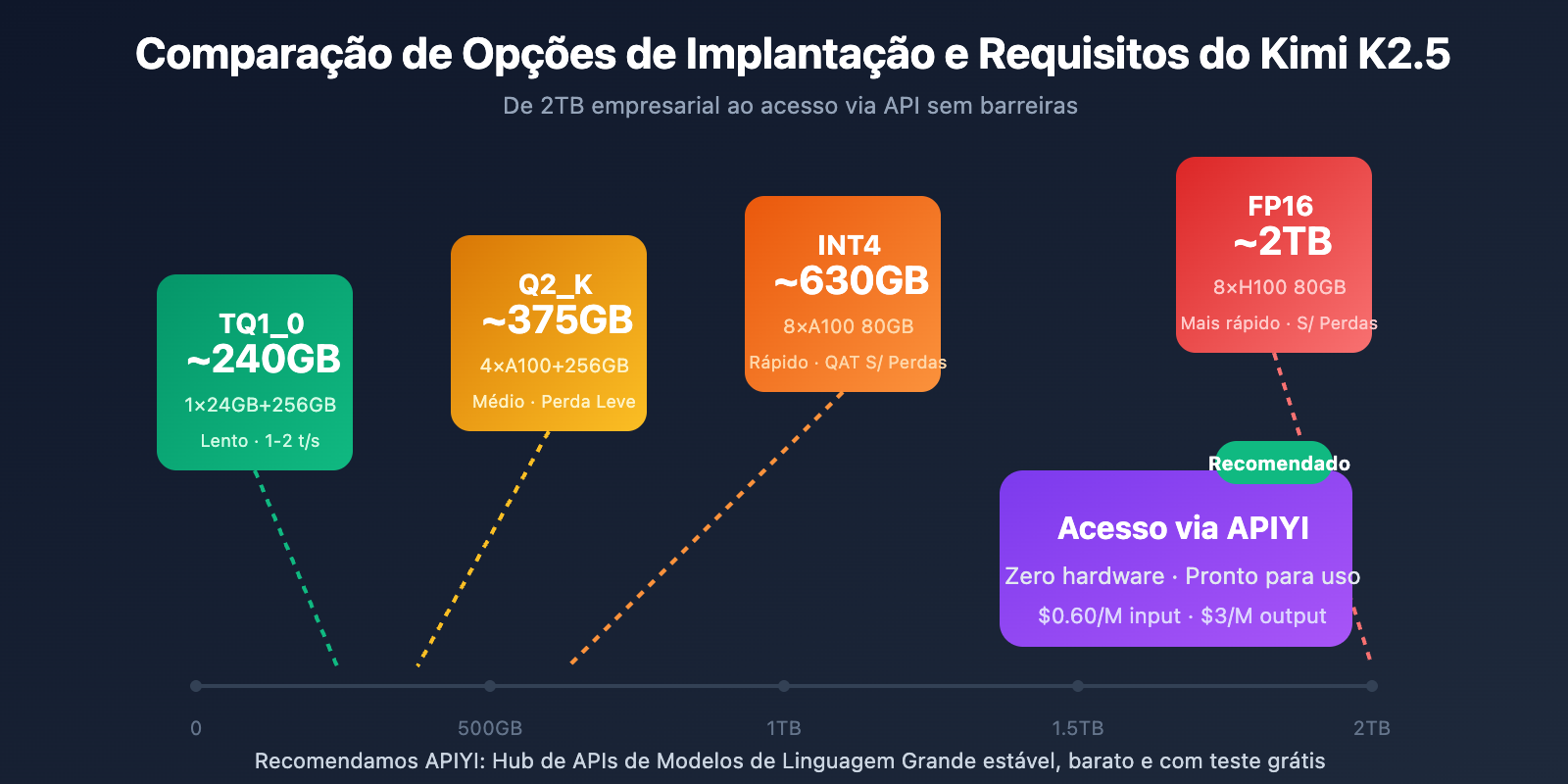
Requisitos de Hardware para Implantação Local
| Precisão de Quantização | Armazenamento | Hardware Mínimo | Velocidade de Inferência | Perda de Precisão |
|---|---|---|---|---|
| FP16 | ~2TB | 8×H100 80GB | Mais rápido | Nenhuma |
| INT4 (QAT) | ~630GB | 8×A100 80GB | Rápido | Quase nenhuma |
| Q2_K_XL | ~375GB | 4×A100 + 256GB RAM | Média | Leve |
| TQ1_0 (1.58-bit) | ~240GB | 1×24GB GPU + 256GB RAM | Lenta (1-2 t/s) | Significativa |
Detalhes dos Requisitos do Kimi K2.5
Implantação de Nível Empresarial (Recomendado)
Configuração de Hardware: 2× NVIDIA H100 80GB ou 8× A100 80GB
Armazenamento: 630GB+ (Quantização INT4)
Desempenho Esperado: 50-100 tokens/s
Cenário de Uso: Ambientes de produção, serviços de alta concorrência
Implantação com Compressão Extrema
Configuração de Hardware: 1× RTX 4090 24GB + 256GB de memória do sistema
Armazenamento: 240GB (Quantização 1.58-bit)
Desempenho Esperado: 1-2 tokens/s
Cenário de Uso: Testes de pesquisa, verificação de funcionalidades
Observação: A camada MoE é totalmente descarregada na RAM, o que torna a velocidade lenta.
Por que tanta memória é necessária?
Embora a arquitetura MoE ative apenas 32B parâmetros por inferência, o modelo precisa manter todos os 1T parâmetros na memória para rotear dinamicamente a entrada para os especialistas corretos. Esta é uma característica intrínseca dos modelos MoE.
Solução Mais Prática: Acesso via API
Para a maioria dos desenvolvedores, a barreira de hardware para implantação local do Kimi K2.5 é muito alta. O acesso via API é a escolha mais viável:
| Opção | Custo | Vantagens |
|---|---|---|
| APIYI (Recomendado) | $0.60/M entrada, $3/M saída | Interface unificada, troca entre vários modelos, créditos grátis |
| API Oficial | O mesmo | Funcionalidades completas, atualizações em tempo real |
| Local 1-bit | Hardware + Eletricidade | Localização de dados |
Sugestão de implantação: A menos que você tenha requisitos rígidos de soberania de dados local, recomendamos o uso do APIYI (apiyi.com) para acessar o Kimi K2.5, evitando investimentos pesados em hardware.
Resultados de Benchmarking do Paper do Kimi K2.5
Avaliação de Capacidades Essenciais
| Benchmark | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | Descrição |
|---|---|---|---|---|
| AIME 2025 | 96.1% | – | – | Competição de matemática (avg@32) |
| HMMT 2025 | 95.4% | 93.3% | – | Competição de matemática (avg@32) |
| GPQA-Diamond | 87.6% | – | – | Raciocínio científico (avg@8) |
| SWE-Bench Verified | 76.8% | – | 80.9% | Correção de código |
| SWE-Bench Multi | 73.0% | – | – | Código multilíngue |
| HLE-Full | 50.2% | – | – | Raciocínio abrangente (com ferramentas) |
| BrowseComp | 60.2% | 54.9% | 24.1% | Interação web |
| MMMU-Pro | 78.5% | – | – | Compreensão multimodal |
| MathVision | 84.2% | – | – | Matemática visual |
Dados e Métodos de Treinamento
| Etapa | Volume de Dados | Método |
|---|---|---|
| Pré-treinamento Base do K2 | 15.5T tokens | Otimizador MuonClip, zero Loss Spike |
| Pré-treinamento Contínuo do K2.5 | 15T (mix visão-texto) | Fusão multimodal nativa |
| Treinamento de Agente | – | PARL (Aprendizado por Reforço de Agente Paralelo) |
| Treinamento de Quantização | – | QAT (Treinamento Ciente de Quantização) |
O artigo destaca especialmente que o otimizador MuonClip permitiu que todo o processo de pré-treinamento de 15,5 trilhões de tokens ocorresse completamente sem nenhum Loss Spike (pico de perda), o que representa um avanço importante em treinamentos na escala de trilhões de parâmetros.
Exemplo de Acesso Rápido ao Kimi K2.5
Código de chamada minimalista
Através da plataforma APIYI, você pode chamar o Kimi K2.5 com apenas 10 linhas de código:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY", # Obtenha em apiyi.com
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "Explique como funciona a arquitetura MoE"}]
)
print(response.choices[0].message.content)
Ver código de chamada para o modo Thinking
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Modo Thinking - Raciocínio Profundo
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "system", "content": "Você é o Kimi, por favor analise o problema detalhadamente"},
{"role": "user", "content": "Prove que a raiz quadrada de 2 é um número irracional"}
],
temperature=1.0, # Recomendado para o modo Thinking
top_p=0.95,
max_tokens=8192
)
# Obter o processo de raciocínio e a resposta final
reasoning = getattr(response.choices[0].message, "reasoning_content", None)
answer = response.choices[0].message.content
if reasoning:
print(f"Processo de Raciocínio:\n{reasoning}\n")
print(f"Resposta Final:\n{answer}")
Dica: Obtenha créditos de teste gratuitos em apiyi.com para experimentar a capacidade de raciocínio profundo do modo Thinking do Kimi K2.5.
Perguntas Frequentes
Q1: Onde posso encontrar o artigo técnico (paper) do Kimi K2.5?
O artigo técnico oficial da série Kimi K2 foi publicado no arXiv sob o número 2507.20534 e pode ser acessado em arxiv.org/abs/2507.20534. O relatório técnico específico do Kimi K2.5 está disponível no blog oficial em kimi.com/blog/kimi-k2-5.html.
Q2: Quais são os requisitos mínimos (requirements) para o deployment local do Kimi K2.5?
Uma solução de compressão extrema exige: 1 GPU com 24GB de VRAM + 256GB de memória do sistema + 240GB de armazenamento. No entanto, nessa configuração, a velocidade de inferência é de apenas 1-2 tokens/s. A configuração recomendada é 2×H100 ou 8×A100, onde o uso de quantização INT4 permite alcançar um desempenho de nível de produção.
Q3: Como validar rapidamente as capacidades do Kimi K2.5?
Não é necessário fazer o deployment local; você pode testar rapidamente via API:
- Acesse o APIYI (apiyi.com) e crie uma conta.
- Obtenha sua API Key e os créditos gratuitos.
- Utilize os exemplos de código deste artigo, preenchendo o nome do modelo como
kimi-k2.5. - Experimente a profundidade de raciocínio do modo "Thinking".
Resumo
Principais pontos do artigo técnico do Kimi K2.5:
- Inovações do Kimi K2.5 Paper: Arquitetura MoE com 384 especialistas + Atenção MLA + otimizador MuonClip, permitindo o treinamento de trilhões de parâmetros sem picos de perda.
- Parâmetros do Kimi K2.5 (Parameters): 1T de parâmetros totais, 32B de parâmetros ativos, 61 camadas e 256K de contexto, ativando apenas 3,2% dos parâmetros em cada inferência.
- Requisitos do Kimi K2.5 (Requirements): A barreira para deployment local é alta (mínimo de 240GB+), tornando o acesso via API a escolha mais prática.
O Kimi K2.5 já está disponível no APIYI (apiyi.com). Recomendamos validar as capacidades do modelo via API para avaliar se ele atende ao seu cenário de negócio.
Referências
⚠️ Nota sobre o formato dos links: Todos os links externos utilizam o formato
Nome da Fonte: domain.com, facilitando a cópia, mas sem links clicáveis para evitar a perda de autoridade de SEO.
-
Artigo do Kimi K2 no arXiv: Relatório técnico oficial, detalhando a arquitetura e os métodos de treinamento
- Link:
arxiv.org/abs/2507.20534 - Descrição: Obtenha detalhes técnicos completos e dados experimentais
- Link:
-
Blog Técnico do Kimi K2.5: Relatório técnico oficial do K2.5 publicado oficialmente
- Link:
kimi.com/blog/kimi-k2-5.html - Descrição: Entenda o Agent Swarm e as capacidades multimodais
- Link:
-
Model Card no HuggingFace: Pesos do modelo e instruções de uso
- Link:
huggingface.co/moonshotai/Kimi-K2.5 - Descrição: Baixe os pesos do modelo e consulte o guia de implantação
- Link:
-
Guia de Implantação Local da Unsloth: Tutorial detalhado de implantação com quantização
- Link:
unsloth.ai/docs/models/kimi-k2.5 - Descrição: Conheça os requisitos de hardware para diferentes níveis de precisão de quantização
- Link:
Autor: Equipe Técnica
Troca de Conhecimento: Sinta-se à vontade para discutir os detalhes técnicos do Kimi K2.5 na seção de comentários. Para mais análises de modelos, visite a comunidade técnica APIYI apiyi.com





