title: "Guia Completo: Como ativar o modo de pensamento (Thinking) do Kimi K2.5 via APIYI"
description: "Aprenda a ativar o modo de pensamento do Kimi K2.5 usando a APIYI com economia de 20% em relação ao preço oficial. Inclui exemplos em cURL, Python e JS."

Nota do autor: Detalhes sobre como invocar o Kimi K2.5 através da plataforma APIYI e ativar o parâmetro enable_thinking, aproveitando preços estáveis com 20% de desconto em relação ao site oficial. Inclui exemplos completos em curl, Python e JavaScript.
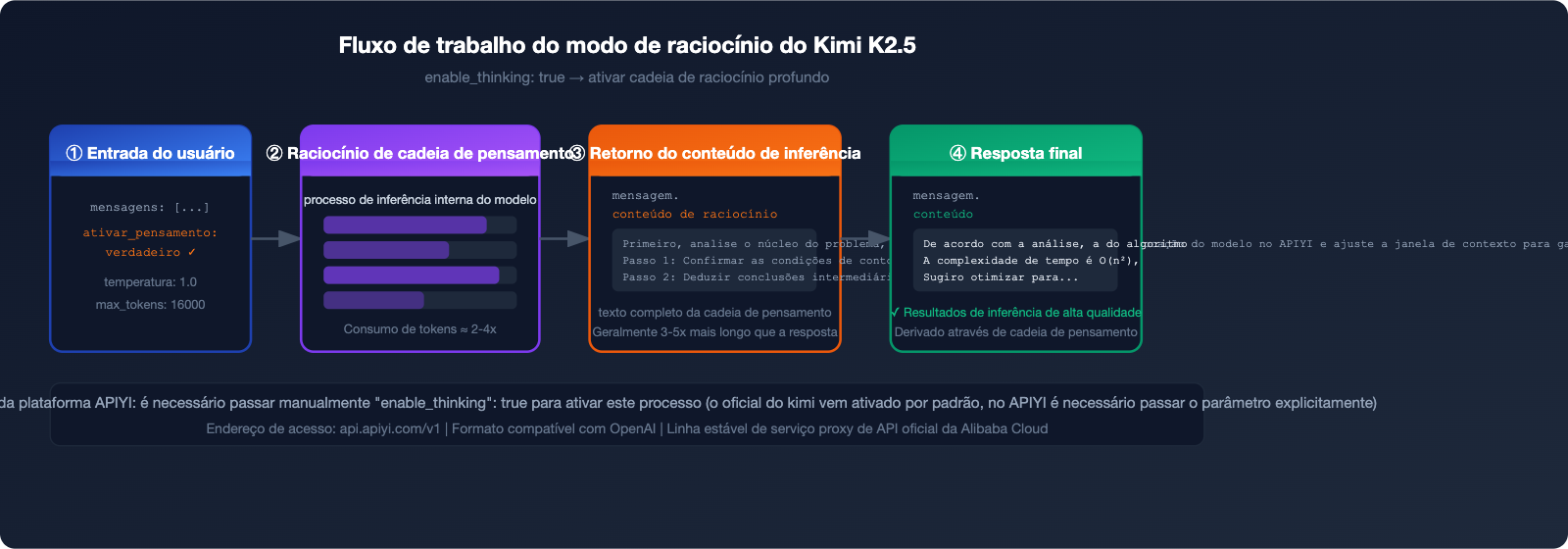
O modo de pensamento (thinking) do Kimi K2.5 é um dos recursos de raciocínio mais poderosos entre os modelos atuais, atingindo uma pontuação de 96,1% no benchmark matemático AIME 2025. No entanto, muitos desenvolvedores encontram o mesmo problema ao integrar: o modelo não exibe o processo de pensamento após a chamada da API.
Isso acontece porque, na plataforma APIYI, é necessário passar manualmente o parâmetro "enable_thinking": true para ativar o modo de raciocínio. Este artigo guiará você, passo a passo, na configuração completa para o modo de pensamento do Kimi K2.5.
🎯 Valor central: Ao terminar este artigo, você dominará a forma completa de invocar o modo thinking do Kimi K2.5 e entenderá como utilizar essa capacidade de forma estável através da APIYI, pagando menos de 80% do preço oficial.
Pontos principais do modo Thinking do Kimi K2.5
| Ponto | Descrição | Valor |
|---|---|---|
| Parâmetro de ativação | Necessário passar "enable_thinking": true |
Desbloqueia o raciocínio profundo |
| Temperatura recomendada | Definir como 1.0 (valor fixo) |
Garante a estabilidade da qualidade do raciocínio |
| max_tokens recomendado | ≥ 16000 | Garante a saída completa do conteúdo de raciocínio |
| Vantagem de preço | Preço de grupo 0.88, abaixo de 80% do oficial | Redução drástica nos custos de inferência |
| Estabilidade | Nível de proxy oficial da Alibaba Cloud | Confiabilidade de nível empresarial |
💡 Início rápido: Registre uma conta na APIYI em apiyi.com, faça um depósito e comece a invocar o Kimi K2.5. Suporta interface compatível com OpenAI, sem necessidade de alterar sua estrutura de código atual.
title: "O que é o Kimi K2.5: O novo gigante de raciocínio com 1 trilhão de parâmetros"
description: "Conheça o Kimi K2.5, o modelo de linguagem grande de código aberto da Moonshot AI com 1 trilhão de parâmetros e capacidades avançadas de raciocínio."
O que é o Kimi K2.5: O novo gigante de raciocínio com 1 trilhão de parâmetros
O Kimi K2.5 foi lançado pela Moonshot AI em 27 de janeiro de 2026 e é, atualmente, um dos Modelos de Linguagem Grande multimodais com a maior capacidade de raciocínio na comunidade de código aberto.
Especificações da arquitetura central do Kimi K2.5
| Especificação | Valor | Descrição |
|---|---|---|
| Total de parâmetros | 1 trilhão (1T) | Arquitetura de especialistas mistos (MoE) |
| Parâmetros ativos | 32 bilhões (32B) | Utilizados durante a inferência |
| Janela de contexto | 256K tokens | Processamento de documentos ultralongos |
| Número de especialistas | 384 camadas de especialistas | Arquitetura dupla MLA + MoE |
| Dados de treinamento | ~15 trilhões de tokens | Mistura de texto + imagem |
| Status de código aberto | Totalmente aberto | Disponível para download no HuggingFace |
O Kimi K2.5 utiliza Atenção Latente de Múltiplas Cabeças (MLA) e uma estrutura MoE de 384 especialistas. Ao manter 1 trilhão de parâmetros totais, ele ativa apenas 32 bilhões durante a inferência, alcançando o equilíbrio ideal entre desempenho e custo.
Os quatro modos de operação do Kimi K2.5
K2.5 Instant → Resposta ultrarrápida, sem processo de pensamento, ideal para tarefas simples
K2.5 Thinking → Raciocínio profundo, gera reasoning_content, ideal para problemas complexos
K2.5 Agent → Execução autônoma de tarefas, capacidade de chamada de ferramentas
K2.5 Agent Swarm → Colaboração multiagente, até 100 subagentes em paralelo
A plataforma APIYI suporta atualmente o modo K2.5 Thinking, que pode ser ativado através do parâmetro enable_thinking: true, permitindo a saída da cadeia de raciocínio completa.
💡 Dica de uso: Recomendamos acessar o kimi-k2.5 através da APIYI (apiyi.com). Oferecemos uma rota estável via proxy oficial do Alibaba Cloud, sem preocupações com interrupções de serviço.
Benchmarks de desempenho do Kimi K2.5: Dados reais do modo de raciocínio
Após ativar o modo de raciocínio (thinking mode), o desempenho de inferência do Kimi K2.5 aumentou drasticamente. Confira abaixo os principais dados de benchmark:
Principais resultados de benchmark
| Benchmark | Resultado do Kimi K2.5 | Observações |
|---|---|---|
| AIME 2025 (raciocínio matemático) | 96,1% | Nível próximo à pontuação máxima, capacidade matemática de elite |
| SWE-Bench Verified (código) | 76,8% | Nível de liderança entre modelos de código aberto |
| HLE-Full w/ tools (agentes) | +4,7 pontos | Primeiro lugar em tarefas de invocação de ferramentas |
| BrowseComp (navegação web) | 60,6% / 78,4%* | *No modo Agent Swarm |
| Índice de Inteligência Abrangente | 47 pontos | Média da indústria é de 27 pontos |
Nota: Os dados acima provêm do Artificial Analysis Intelligence Index, resultados da avaliação de janeiro de 2026.
O modo de raciocínio (thinking mode), em comparação com o modo padrão, apresenta uma melhoria significativa de 30-50% em tarefas complexas de matemática, raciocínio de várias etapas e geração de código. O custo é que o consumo de tokens é cerca de 2 a 4 vezes maior que no modo padrão, portanto, controlar adequadamente o max_tokens é fundamental para reduzir custos.
3 passos para ativar o modo de raciocínio do Kimi K2.5 na APIYI
Passo 1: Registre-se e obtenha sua chave API
Acesse o site oficial da APIYI em apiyi.com, crie sua conta e siga estas etapas:
- Registre-se e conclua a verificação de e-mail.
- Acesse "Console" → "Gerenciamento de chave API".
- Crie uma nova chave API e salve-a.
🎯 Vantagem de preço: Recarregue 100 dólares e ganhe 10 dólares de bônus. O preço do grupo é 0,88 (token de entrada), com um custo real de uso inferior a 80% do valor praticado no site oficial do Kimi. A APIYI oferece uma linha estável de nível empresarial, equivalente à qualidade da Alibaba Cloud.
Passo 2: Configure os parâmetros da requisição
A chave para ativar o modo de raciocínio do Kimi K2.5 está na configuração destes três parâmetros:
{
"model": "kimi-k2.5",
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}
⚠️ Observação importante: A lógica de parâmetros da plataforma APIYI difere da API oficial do Kimi:
- Kimi oficial: O raciocínio é ativado por padrão, sendo necessário passar parâmetros para desativá-lo.
- Plataforma APIYI: É necessário passar manualmente
"enable_thinking": truepara ativar a função.
Passo 3: Envie a requisição e analise o conteúdo do raciocínio
Abaixo está um exemplo completo de invocação, incluindo a ativação do modo de raciocínio e a análise da resposta.
Exemplo em curl (forma mais rápida de validar)
curl --location 'https://api.apiyi.com/v1/chat/completions' \
--header "Authorization: Bearer sk-SUA_CHAVE_API" \
--header 'Content-Type: application/json' \
--data '{
"model": "kimi-k2.5",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Explique de forma passo a passo: por que 0.1 + 0.2 não é igual a 0.3 na computação?"
}
],
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}'
Exemplo em Python (recomendado para ambientes de produção)
from openai import OpenAI
client = OpenAI(
api_key="sk-SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Analise a complexidade de tempo deste código e dê sugestões de otimização:\n\ndef find_duplicates(arr):\n result = []\n for i in range(len(arr)):\n for j in range(i+1, len(arr)):\n if arr[i] == arr[j] and arr[i] not in result:\n result.append(arr[i])\n return result"
}
],
extra_body={
"enable_thinking": True
},
temperature=1.0,
max_tokens=16000
)
# Analisar o conteúdo do raciocínio (se existir)
message = response.choices[0].message
# Exibir o processo de raciocínio (campo reasoning_content)
if hasattr(message, 'reasoning_content') and message.reasoning_content:
print("=== Processo de Raciocínio ===")
print(message.reasoning_content)
print()
# Exibir a resposta final
print("=== Resposta Final ===")
print(message.content)
Expandir exemplo completo em JavaScript / Node.js
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'sk-SUA_CHAVE_API',
baseURL: 'https://api.apiyi.com/v1',
});
async function callKimiThinking(userMessage) {
const response = await client.chat.completions.create({
model: 'kimi-k2.5',
messages: [
{
role: 'system',
content: 'You are a helpful assistant.',
},
{
role: 'user',
content: userMessage,
},
],
// Passar o parâmetro enable_thinking via extra_body
// @ts-ignore
enable_thinking: true,
temperature: 1.0,
max_tokens: 16000,
});
const message = response.choices[0].message;
// Extrair o processo de raciocínio
const reasoningContent = message.reasoning_content;
if (reasoningContent) {
console.log('=== Processo de Raciocínio ===');
console.log(reasoningContent);
console.log();
}
// Extrair a resposta final
console.log('=== Resposta Final ===');
console.log(message.content);
return {
thinking: reasoningContent,
answer: message.content,
};
}
// Exemplo de uso
callKimiThinking('Prove passo a passo: existem infinitos números primos (prova de Euclides)');
💡 Dica de integração: No código acima, substitua a
base_urlporhttps://api.apiyi.com/v1. Os demais parâmetros são totalmente compatíveis com o SDK da OpenAI, sem necessidade de aprendizado extra. A APIYI (apiyi.com) permite que você utilize todos os principais modelos com uma única chave.
Detalhamento dos parâmetros principais: configure corretamente para evitar problemas
Tabela de configuração de parâmetros
| Parâmetro | Valor recomendado | Explicação | Exemplo incorreto |
|---|---|---|---|
model |
"kimi-k2.5" |
Identificador do modelo | Não use kimi-k2 ou kimi-k2.5-thinking |
enable_thinking |
true |
Ativa o modo de raciocínio (exclusivo da APIYI) | Sem este parâmetro, o conteúdo de raciocínio não será exibido |
temperature |
1.0 |
Valor fixo recomendado oficialmente | Definir 0.7 ou outros valores pode tornar a qualidade instável |
max_tokens |
≥ 16000 |
Garante a saída completa | Valores muito baixos truncarão o conteúdo de raciocínio |
stream |
false (teste inicial) |
Suporta tanto streaming quanto não-streaming | O streaming requer tratamento adicional do campo reasoning |
Explicação da estrutura da resposta da API
{
"choices": [
{
"message": {
"role": "assistant",
"content": "Conteúdo da resposta final...",
"reasoning_content": "Processo de pensamento do modelo, incluindo raciocínio passo a passo..."
}
}
],
"usage": {
"prompt_tokens": 150,
"completion_tokens": 3200,
"total_tokens": 3350
}
}
O campo reasoning_content contém a cadeia de pensamento completa, sendo geralmente 3 a 5 vezes maior que o campo content. É o dado fundamental para entender o processo de tomada de decisão do modelo.
🎯 Dica de controle de custos: No modo de raciocínio (thinking), o consumo de tokens é cerca de 2 a 4 vezes maior que no modo normal. Recomendamos o acesso via APIYI (apiyi.com), onde o preço por grupo de 0,88 pode reduzir significativamente os custos de inferência, além de oferecer um bônus de 10 dólares em recargas de 100 dólares.

APIYI vs. Oficial: Comparativo de Preço e Estabilidade
Visão geral da comparação de plataformas
| Dimensão de comparação | APIYI (apiyi.com) | API Oficial do Kimi | Outros serviços proxy de API |
|---|---|---|---|
| Nível de preço | Abaixo de 80% do oficial (preço de grupo 0.88) | Preço oficial | Variável |
| Estabilidade | Nível de proxy oficial da Alibaba Cloud | Conexão direta, sujeita a limites de taxa | Incerta |
| Descontos de recarga | Recarregue $100 ganhe $10 | Sem bônus fixo | Variado |
| Compatibilidade de interface | Formato OpenAI, 100% compatível | Requer adaptação ao SDK do Kimi | Maioria compatível |
| Suporte a modelos | 100+ modelos convencionais | Apenas série Kimi | Limitado |
| Suporte empresarial | Atendimento exclusivo + nota fiscal | Suporte padrão | Limitado |
Exemplo de cálculo da vantagem de preço da APIYI
Tomando como exemplo 1000 invocações do modelo kimi-k2.5 thinking por mês (média de 3000 tokens de entrada + 5000 tokens de saída por vez):
Custo de tokens de entrada:
Preço oficial aprox. $0.60/1M → 1000 vezes × 3000 tokens = 3M tokens → $1.80
Preço de grupo APIYI 0.88 → aprox. $1.58
Custo de tokens de saída (incluindo reasoning):
Preço oficial aprox. $2.50/1M → 1000 vezes × 5000 tokens = 5M tokens → $12.50
Preço de grupo APIYI 0.88 → aprox. $11.00
Economia mensal: aprox. $1.72 + bônus de recarga cobrindo cerca de 10% do custo adicional
💡 Desconto real: O "abaixo de 80%" da APIYI vem da combinação de duas partes: desconto no preço de grupo (0.88) + bônus de recarga (recarregue 100 ganhe 10, ou seja, 10% a mais de orçamento). O custo total real é de cerca de 79-80% do preço oficial.
Melhores cenários de uso para o modo Thinking do Kimi K2.5
Cenários recomendados para ativar o Thinking
1. Raciocínio matemático complexo
# Adequado para o modo thinking
comando = "Por favor, prove o Último Teorema de Fermat para o caso n=3 e forneça os passos detalhados"
2. Depuração e otimização de código
# Adequado para o modo thinking
comando = """
O código abaixo tem um bug de concorrência oculto, por favor encontre e corrija:
[Cole o código multithread complexo aqui]
"""
3. Análise lógica de múltiplas etapas
# Adequado para o modo thinking
comando = "Analise as falhas lógicas deste plano de negócios e ordene por prioridade"
4. Dedução de problemas científicos
# Adequado para o modo thinking
comando = "Deduzir a fórmula do nível de energia do átomo de hidrogênio a partir dos princípios básicos da mecânica quântica"
Cenários onde não é necessário ativar o Thinking
# Os cenários abaixo usam o modo normal (sem passar enable_thinking), economizando 50-70% do custo em tokens
# Perguntas e respostas simples
"Como está o tempo hoje?" # Sem necessidade de raciocínio
# Tradução de texto
"Por favor, traduza o seguinte conteúdo para o inglês:..." # Sem necessidade de raciocínio
# Formatação de saída
"Formate os dados JSON abaixo" # Sem necessidade de raciocínio
# Escrita criativa
"Escreva um poema sobre a primavera" # Sem necessidade de raciocínio profundo
🎯 Sugestão de uso: Recomendamos alternar o modo dinamicamente de acordo com a complexidade da tarefa. Ao acessar via APIYI (apiyi.com), você pode usar a mesma chave API para invocar de forma flexível o kimi-k2.5 (modo thinking) e outros modelos mais leves, misturando conforme a necessidade.
Saída em streaming: lidando com respostas em tempo real no modo Thinking
Ao utilizar a saída em streaming no modo thinking, é necessário tratar especificamente os fragmentos incrementais de reasoning_content:
from openai import OpenAI
client = OpenAI(
api_key="sk-sua_CHAVE_API",
base_url="https://api.apiyi.com/v1"
)
# Exemplo de invocação do modelo em streaming
stream = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "user", "content": "Por favor, analise a complexidade de tempo do pior caso do algoritmo quicksort"}
],
extra_body={"enable_thinking": True},
temperature=1.0,
max_tokens=16000,
stream=True
)
thinking_buffer = []
answer_buffer = []
is_thinking = True
for chunk in stream:
delta = chunk.choices[0].delta
# Processar o fluxo de conteúdo de raciocínio
if hasattr(delta, 'reasoning_content') and delta.reasoning_content:
thinking_buffer.append(delta.reasoning_content)
print(delta.reasoning_content, end='', flush=True)
# Processar o fluxo da resposta final
elif delta.content:
if is_thinking:
print("\n\n=== Resposta Final ===\n")
is_thinking = False
answer_buffer.append(delta.content)
print(delta.content, end='', flush=True)
print() # Quebra de linha
💡 Pontos-chave do processamento em streaming:
reasoning_contentecontentsão campos independentes durante o streaming. Normalmente, oreasoning_contenté emitido primeiro na íntegra, seguido pelocontent. É necessário monitorar os dados incrementais de ambos os campos separadamente.
Perguntas Frequentes (FAQ)
P1: Não recebo o campo reasoning_content após a chamada, o modo de pensamento não foi ativado?
R: Verifique os três pontos a seguir:
- Se o parâmetro
"enable_thinking": truefoi passado corretamente. - Se o
max_tokensestá definido como 16000 ou superior. - Se, ao usar o SDK Python, você passou o parâmetro via
extra_body={"enable_thinking": True}.
Recomendamos testar primeiro via curl para confirmar se o formato do parâmetro está correto antes de integrar ao seu código. O suporte técnico da APIYI está disponível em apiyi.com.
P2: O consumo de tokens no modo thinking é muito alto, como controlar os custos?
R: Você pode otimizar a partir das seguintes perspectivas:
- Desative o modo thinking para tarefas simples (não passe o parâmetro
enable_thinking). - Reduza adequadamente o
max_tokens(mínimo de 8000, mas esteja ciente de que isso pode truncar raciocínios complexos). - Segmente as tarefas: use o kimi-k2.5 thinking para raciocínios complexos e modelos leves como o gpt-4o-mini para tarefas simples.
- Reduza os custos básicos através dos preços por grupo da APIYI (0.88) em apiyi.com.
P3: A temperatura deve ser obrigatoriamente 1.0?
R: A recomendação oficial é definir como 1.0, pois este é o parâmetro de temperatura ideal para o modo thinking do kimi-k2.5. Definir um valor muito baixo (como 0.7) fará com que o modelo seja excessivamente conservador durante o raciocínio, reduzindo a qualidade; definir um valor muito alto (como 1.5) pode gerar cadeias de raciocínio incoerentes. Usar 1.0 diretamente é a escolha mais segura.
P4: O kimi-k2.5 da APIYI é exatamente igual ao oficial?
R: Sim. A APIYI utiliza o link de transferência oficial do Alibaba Cloud; os pesos e capacidades do modelo são exatamente iguais aos do kimi oficial. A única diferença reside na forma de passar os parâmetros: o oficial ativa o thinking por padrão, enquanto na APIYI é necessário passar manualmente enable_thinking: true. Esta é uma diferença padrão de plataformas de serviço proxy de API e não afeta a qualidade da saída do modelo.
Resumo: Principais pontos do modo de raciocínio do Kimi K2.5
| Ponto-chave | Descrição |
|---|---|
| Parâmetros de ativação | É necessário passar "enable_thinking": true |
| Configuração de temperatura | Use fixo em temperature: 1.0 |
| Orçamento de tokens | max_tokens ≥ 16000 |
| Campos de resposta | O conteúdo do raciocínio está em reasoning_content, e a resposta em content |
| Endereço de acesso | https://api.apiyi.com/v1 (compatível com OpenAI) |
| Descontos | Menos de 20% de desconto em relação ao site oficial, recarregue $100 e ganhe $10 |
O Kimi K2.5 apresenta um desempenho notável em benchmarks essenciais, como o raciocínio matemático AIME (96,1%) e a geração de código (SWE-Bench 76,8%). O modo de raciocínio é especialmente adequado para lidar com tarefas complexas que exigem raciocínio em várias etapas.
🎯 Experimente agora: Acesse o site da APIYI em apiyi.com, registre uma conta para obter sua chave API e conclua a integração do modo de raciocínio do kimi-k2.5 em menos de 5 minutos. Ao recarregar 100 dólares, você ganha 10 dólares de bônus, e com os descontos de grupo, o custo total fica abaixo de 80% do valor praticado no site oficial do Kimi.
Artigo escrito pela equipe técnica da APIYI | Fonte de dados: Documentação oficial da Moonshot AI e relatório de avaliação da Artificial Analysis (janeiro de 2026)
Para suporte técnico, visite a central de ajuda da APIYI: help.apiyi.com