Anmerkung des Autors: Erfahren Sie, wie Sie über die APIYI-Plattform auf das Modell kimi-k2.5 zugreifen, den Parameter enable_thinking aktivieren und von stabilen Preisen profitieren, die 20 % unter den offiziellen liegen. Inklusive vollständiger Code-Beispiele für cURL, Python und JavaScript.

Der Thinking-Modus (Denkmodus) von Kimi K2.5 gehört derzeit zu den leistungsfähigsten Funktionen für logisches Schließen bei Open-Source-Modellen und erreicht einen beeindruckenden Wert von 96,1 % im AIME 2025 Mathematik-Benchmark. Viele Entwickler stehen jedoch bei der Implementierung vor demselben Problem: Nach dem API-Aufruf zeigt das Modell keinen Denkprozess an.
Dies liegt daran, dass auf der APIYI-Plattform der Parameter "enable_thinking": true manuell übergeben werden muss, um den Denkmodus zu aktivieren. In diesem Artikel führen wir Sie Schritt für Schritt durch die vollständige Konfiguration für den Kimi K2.5 Thinking-Modus.
🎯 Kernvorteil: Nach der Lektüre dieses Artikels beherrschen Sie den vollständigen Aufruf des kimi-k2.5 Thinking-Modus und wissen, wie Sie diese Funktion über APIYI zu einem stabilen Preis nutzen können, der 20 % unter dem offiziellen liegt.
Wichtige Punkte zum Kimi K2.5 Thinking-Modus
| Punkt | Beschreibung | Nutzen |
|---|---|---|
| Aktivierungsparameter | Erfordert "enable_thinking": true |
Schaltet tiefgreifende Schlussfolgerungsfähigkeiten frei |
| Empfohlene Temperatur | Auf 1.0 setzen (fest) |
Garantiert stabile Qualität der Überlegungen |
| Empfohlene max_tokens | ≥ 16000 | Stellt die vollständige Ausgabe der Überlegungen sicher |
| Preisvorteil | Gruppenpreis 0,88, günstiger als 80 % der offiziellen Website | Massive Senkung der Kosten für Modellaufrufe |
| Stabilität | Niveau eines offiziellen Alibaba Cloud-Proxys | Zuverlässigkeit auf Unternehmensniveau |
💡 Schnellstart: Registrieren Sie sich bei APIYI unter apiyi.com, laden Sie Ihr Guthaben auf und nutzen Sie kimi-k2.5. Unterstützt OpenAI-kompatible Schnittstellen, keine Änderungen an bestehenden Code-Frameworks erforderlich.
Was ist Kimi K2.5: Das Open-Source-Flaggschiff mit 1 Billion Parametern
Kimi K2.5 wurde am 27. Januar 2026 von Moonshot AI veröffentlicht und ist eines der leistungsfähigsten multimodalen Großmodelle in der Open-Source-Community.
Kimi K2.5 Kernarchitektur-Spezifikationen
| Spezifikation | Wert | Beschreibung |
|---|---|---|
| Gesamtparameter | 1 Billion (1T) | MoE-Misch-Experten-Architektur |
| Aktivierte Parameter | 32 Milliarden (32B) | Tatsächliche Nutzung während des Modellaufrufs |
| Kontextfenster | 256K Token | Verarbeitung extrem langer Dokumente |
| Anzahl der Experten | 384 Experten-Schichten | MLA + MoE Dual-Architektur |
| Trainingsdaten | ~15 Billionen Token | Text + Bild-Mix |
| Open-Source-Status | Vollständig Open Source | Auf HuggingFace verfügbar |
Kimi K2.5 verwendet Multi-Head Latent Attention (MLA) und eine 384-Experten-MoE-Struktur. Bei einer Gesamtzahl von 1 Billion Parametern werden während des Modellaufrufs nur 32 Milliarden Parameter aktiviert, was ein optimales Gleichgewicht zwischen Leistung und Kosten ermöglicht.
Die vier Betriebsmodi von Kimi K2.5
K2.5 Instant → Blitzschnelle Antwort, kein Denkprozess, für einfache Aufgaben
K2.5 Thinking → Tiefgreifende Schlussfolgerung, Ausgabe von reasoning_content, für komplexe Probleme
K2.5 Agent → Autonome Aufgabenausführung, Werkzeugaufruf-Fähigkeiten
K2.5 Agent Swarm → Multi-Agenten-Zusammenarbeit, bis zu 100 Sub-Agenten parallel
Die APIYI-Plattform unterstützt derzeit den K2.5 Thinking-Modus, der über den Parameter enable_thinking: true aktiviert wird und die vollständige Schlussfolgerungskette ausgibt.
💡 Nutzungsempfehlung: Wir empfehlen den Zugriff auf kimi-k2.5 über APIYI (apiyi.com). Dank der stabilen, offiziellen Alibaba Cloud-Proxy-Anbindung müssen Sie keine Dienstunterbrechungen befürchten.
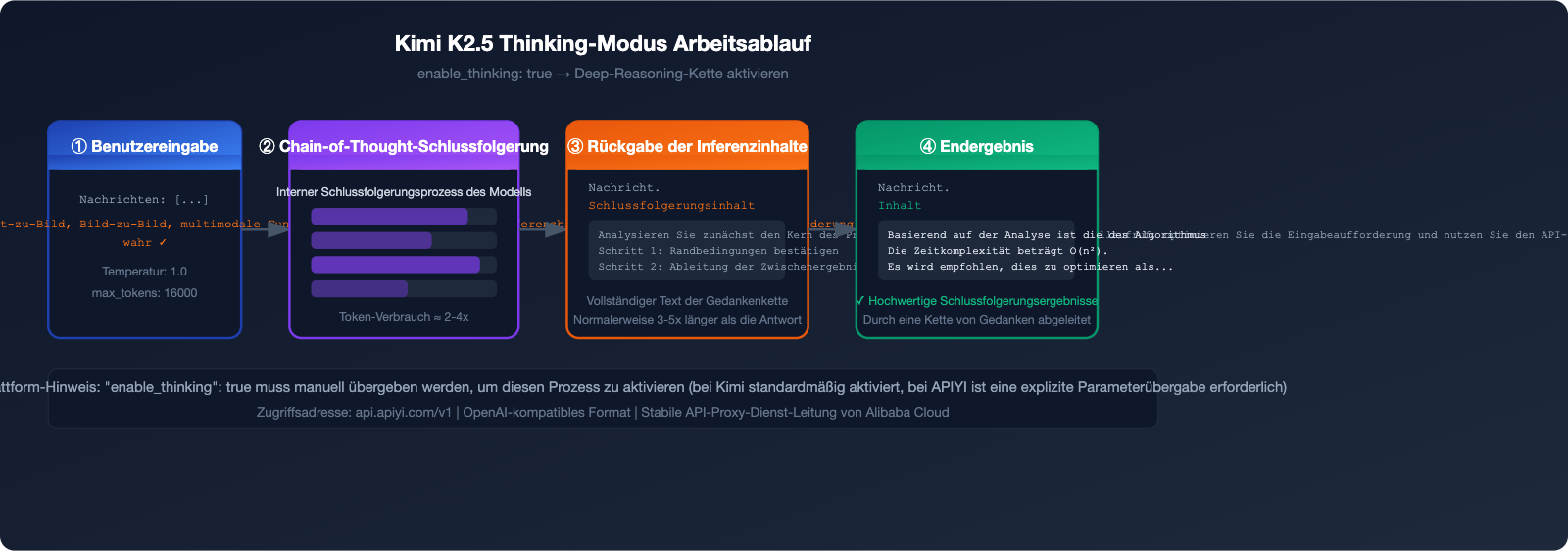
Kimi K2.5 Performance-Benchmark: Testergebnisse des Denkmodus
Nach der Aktivierung des Thinking-Modus hat sich die Schlussfolgerungsleistung von Kimi K2.5 massiv verbessert. Hier sind die wichtigsten Benchmark-Daten:
Wichtigste Benchmark-Ergebnisse
| Benchmark | Kimi K2.5 Ergebnis | Vergleichshinweis |
|---|---|---|
| AIME 2025 (Mathematische Schlussfolgerung) | 96,1 % | Nahezu volle Punktzahl, Spitzenleistung in Mathe |
| SWE-Bench Verified (Code) | 76,8 % | Führend unter den Open-Source-Modellen |
| HLE-Full w/ tools (Agenten) | + 4,7 Punkte | Platz 1 bei Tool-Aufruf-Aufgaben |
| BrowseComp (Web-Browsing) | 60,6 % / 78,4 %* | *Im Agent Swarm-Modus |
| Gesamtintelligenz-Index | 47 Punkte | Branchendurchschnitt liegt bei 27 Punkten |
Hinweis: Die oben genannten Daten stammen aus dem Artificial Analysis Intelligence Index, Testergebnisse vom Januar 2026.
Der Thinking-Modus bietet im Vergleich zum Standardmodus eine signifikante Steigerung von 30–50 % bei komplexer Mathematik, mehrstufigen Schlussfolgerungen und der Code-Generierung. Der Preis dafür ist ein Token-Verbrauch, der etwa 2–4 Mal höher ist als im Standardmodus. Daher ist eine sinnvolle Kontrolle der max_tokens der Schlüssel zur Kostenoptimierung.
In 3 Schritten den Kimi K2.5 Thinking-Modus bei APIYI aktivieren
Schritt 1: Registrieren und API-Schlüssel abrufen
Besuchen Sie die APIYI-Website apiyi.com, registrieren Sie ein Konto und führen Sie folgende Schritte aus:
- Konto registrieren und E-Mail-Verifizierung abschließen.
- Gehen Sie zu „Konsole“ → „API-Schlüssel-Verwaltung“.
- Erstellen Sie einen neuen API-Schlüssel und speichern Sie ihn sicher.
🎯 Preisvorteil: Erhalten Sie 10 USD Bonus bei einer Aufladung von 100 USD. Der Gruppenpreis liegt bei 0,88 (Eingabe-Token), was die tatsächlichen Nutzungskosten auf unter 80 % des Niveaus der offiziellen Kimi-Website senkt. APIYI bietet eine stabile Leitung auf dem Niveau offizieller Alibaba-Cloud-Proxys mit Zuverlässigkeit auf Unternehmensebene.
Schritt 2: Anforderungsparameter konfigurieren
Der Schlüssel zur Aktivierung des Kimi-K2.5-Denkmodus liegt in der Konfiguration der folgenden drei Parameter:
{
"model": "kimi-k2.5",
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}
⚠️ Wichtiger Hinweis: Die Parameterlogik der APIYI-Plattform unterscheidet sich von der offiziellen Kimi-API:
- Offizielles Kimi: Thinking ist standardmäßig aktiviert und muss aktiv per Parameter deaktiviert werden.
- APIYI-Plattform: Sie müssen manuell
"enable_thinking": trueübergeben, um es zu aktivieren.
Schritt 3: Anfrage senden und Denkprozess analysieren
Hier ist ein vollständiges Beispiel für den Modellaufruf, einschließlich der Aktivierung des Thinking-Modus und der Analyse der Antwort.
curl-Beispiel (schnellste Verifizierungsmethode)
curl --location 'https://api.apiyi.com/v1/chat/completions' \
--header "Authorization: Bearer sk-DEIN_API_SCHLUESSEL" \
--header 'Content-Type: application/json' \
--data '{
"model": "kimi-k2.5",
"messages": [
{
"role": "system",
"content": "Du bist ein hilfreicher Assistent."
},
{
"role": "user",
"content": "Erkläre schrittweise: Warum ist 0.1 + 0.2 im Computer nicht gleich 0.3?"
}
],
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}'
Python-Beispiel (Empfohlen für die Produktionsumgebung)
from openai import OpenAI
client = OpenAI(
api_key="sk-DEIN_API_SCHLUESSEL",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{
"role": "system",
"content": "Du bist ein hilfreicher Assistent."
},
{
"role": "user",
"content": "Analysiere die Zeitkomplexität dieses Codes und gib Optimierungsvorschläge:\n\ndef find_duplicates(arr):\n result = []\n for i in range(len(arr)):\n for j in range(i+1, len(arr)):\n if arr[i] == arr[j] and arr[i] not in result:\n result.append(arr[i])\n return result"
}
],
extra_body={
"enable_thinking": True
},
temperature=1.0,
max_tokens=16000
)
# Denkprozess analysieren (falls vorhanden)
message = response.choices[0].message
# Denkprozess ausgeben (Feld reasoning_content)
if hasattr(message, 'reasoning_content') and message.reasoning_content:
print("=== Denkprozess ===")
print(message.reasoning_content)
print()
# Endgültige Antwort ausgeben
print("=== Endgültige Antwort ===")
print(message.content)
JavaScript / Node.js vollständiges Beispiel ausklappen
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'sk-DEIN_API_SCHLUESSEL',
baseURL: 'https://api.apiyi.com/v1',
});
async function callKimiThinking(userMessage) {
const response = await client.chat.completions.create({
model: 'kimi-k2.5',
messages: [
{
role: 'system',
content: 'Du bist ein hilfreicher Assistent.',
},
{
role: 'user',
content: userMessage,
},
],
// Parameter enable_thinking über extra_body übergeben
// @ts-ignore
enable_thinking: true,
temperature: 1.0,
max_tokens: 16000,
});
const message = response.choices[0].message;
// Denkprozess extrahieren
const reasoningContent = message.reasoning_content;
if (reasoningContent) {
console.log('=== Denkprozess ===');
console.log(reasoningContent);
console.log();
}
// Endgültige Antwort extrahieren
console.log('=== Endgültige Antwort ===');
console.log(message.content);
return {
thinking: reasoningContent,
answer: message.content,
};
}
// Anwendungsbeispiel
callKimiThinking('Beweise schrittweise: Es gibt unendlich viele Primzahlen (Euklidischer Beweis)');
💡 Hinweis zur Integration: Ersetzen Sie im obigen Code die
base_urldurchhttps://api.apiyi.com/v1. Alle anderen Parameter sind vollständig mit dem OpenAI SDK kompatibel, es ist kein zusätzlicher Lernaufwand erforderlich. APIYI (apiyi.com) unterstützt den Aufruf aller gängigen Modelle mit einem einzigen Schlüssel.
Wichtige Parameter im Detail: Konfiguration für optimale Ergebnisse
Parameter-Konfigurationstabelle
| Parameter | Empfohlener Wert | Erläuterung | Fehlerbeispiel |
|---|---|---|---|
model |
"kimi-k2.5" |
Modell-Identifikator | Nicht kimi-k2 oder kimi-k2.5-thinking verwenden |
enable_thinking |
true |
Aktiviert den Denkmodus (exklusiv für APIYI) | Ohne diesen Parameter erfolgt keine Ausgabe des Denkprozesses |
temperature |
1.0 |
Offiziell empfohlener Festwert | Werte wie 0.7 führen zu instabiler Qualität |
max_tokens |
≥ 16000 |
Stellt eine vollständige Ausgabe sicher | Zu niedrige Werte schneiden den Denkprozess ab |
stream |
false (Initialtest) |
Unterstützt Streaming/Nicht-Streaming | Streaming erfordert zusätzliche Verarbeitung des reasoning-Feldes |
Erläuterung der API-Antwortstruktur
{
"choices": [
{
"message": {
"role": "assistant",
"content": "Endgültige Antwort...",
"reasoning_content": "Denkprozess des Modells, inklusive schrittweiser Herleitung..."
}
}
],
"usage": {
"prompt_tokens": 150,
"completion_tokens": 3200,
"total_tokens": 3350
}
}
Das Feld reasoning_content enthält die vollständige Gedankenkette. Es ist meist 3- bis 5-mal länger als das Feld content und stellt die zentrale Datenquelle dar, um die Entscheidungsfindung des Modells nachzuvollziehen.
🎯 Tipp zur Kostenkontrolle: Im Thinking-Modus ist der Token-Verbrauch etwa 2- bis 4-mal höher als im Standardmodus. Wir empfehlen die Anbindung über den API-Proxy-Dienst APIYI (apiyi.com). Gruppenpreise von 0,88 senken die Kosten für Modellaufrufe erheblich; bei einer Aufladung von 100 USD erhalten Sie zudem 10 USD Guthaben geschenkt.

APIYI vs. offizielle Website: Preis- und Stabilitätsvergleich
Plattform-Vergleich im Überblick
| Vergleichsdimension | APIYI (apiyi.com) | Kimi Offizielle API | Andere API-Proxy-Dienste |
|---|---|---|---|
| Preisniveau | 20 % unter Listenpreis (0,88 Gruppenpreis) | Offizielle Preisgestaltung | Sehr unterschiedlich |
| Stabilität | Auf dem Niveau von Alibaba Cloud | Direktverbindung, ratenbegrenzt | Ungewiss |
| Aufladebonus | $100 aufladen, $10 geschenkt | Kein fester Bonus | Variabel |
| API-Kompatibilität | OpenAI-Format, 100 % kompatibel | Erfordert Kimi-SDK | Meist kompatibel |
| Modellunterstützung | 100+ gängige Modelle | Nur Kimi-Serie | Begrenzt |
| Unternehmenssupport | Dedizierter Support + Rechnung | Standard-Support | Begrenzt |
Beispielrechnung zum Preisvorteil von APIYI
Am Beispiel von 1.000 Modellaufrufen pro Monat für den Kimi-k2.5 Thinking-Modus (durchschnittlich 3.000 Token Input + 5.000 Token Output pro Aufruf):
Kosten für Input-Token:
Offizieller Preis ca. $0,60/1M → 1000 Aufrufe × 3000 Token = 3M Token → $1,80
APIYI Gruppenpreis 0,88 → ca. $1,58
Kosten für Output-Token (inkl. Reasoning):
Offizieller Preis ca. $2,50/1M → 1000 Aufrufe × 5000 Token = 5M Token → $12,50
APIYI Gruppenpreis 0,88 → ca. $11,00
Monatliche Ersparnis: ca. $1,72 + zusätzliche Abdeckung von ca. 10 % der Kosten durch Aufladebonus
💡 Tatsächlicher Vorteil: Der Rabatt von „unter 20 %“ bei APIYI setzt sich aus zwei Faktoren zusammen: dem Gruppenpreis-Rabatt (0,88) und dem Aufladebonus (bei $100 Aufladung gibt es $10 dazu, also 10 % zusätzliches Budget). Die effektiven Gesamtkosten liegen bei etwa 79–80 % des offiziellen Preises.
Optimale Einsatzszenarien für den Kimi K2.5 Thinking-Modus
Szenarien, in denen Thinking empfohlen wird
1. Komplexe mathematische Schlussfolgerungen
# Geeignet für den Thinking-Modus
prompt = "Beweise den Großen Fermatschen Satz für den Fall n=3 und gib die detaillierten Schritte an"
2. Code-Debugging und Optimierung
# Geeignet für den Thinking-Modus
prompt = """
Der folgende Code enthält einen versteckten Nebenläufigkeits-Bug. Bitte finde und behebe ihn:
[Komplexen Multithreading-Code einfügen]
"""
3. Mehrstufige logische Analyse
# Geeignet für den Thinking-Modus
prompt = "Analysiere die logischen Schwachstellen in diesem Businessplan und ordne sie nach Priorität"
4. Herleitung wissenschaftlicher Fragestellungen
# Geeignet für den Thinking-Modus
prompt = "Leite die Energieformel für das Wasserstoffatom aus den Grundprinzipien der Quantenmechanik her"
Szenarien, in denen Thinking nicht erforderlich ist
# In den folgenden Szenarien den normalen Modus verwenden (ohne enable_thinking),
# um 50–70 % der Token-Kosten zu sparen.
# Einfache Fragen
"Wie ist das Wetter heute?" # Keine Schlussfolgerung nötig
# Textübersetzung
"Bitte übersetze den folgenden Inhalt ins Deutsche:..." # Keine Schlussfolgerung nötig
# Formatierte Ausgabe
"Formatiere die folgenden JSON-Daten" # Keine Schlussfolgerung nötig
# Kreatives Schreiben
"Schreibe ein Gedicht über den Frühling" # Keine tiefgreifende Schlussfolgerung nötig
🎯 Empfehlung: Es ist ratsam, den Modus je nach Komplexität der Aufgabe dynamisch zu wechseln. Durch die Anbindung über APIYI (apiyi.com) können Sie denselben API-Schlüssel nutzen, um flexibel zwischen dem Kimi-k2.5 (Thinking-Modus) und anderen leichtgewichtigen Modellen zu wählen und diese je nach Bedarf kombiniert einzusetzen.
Streaming-Ausgabe: Echtzeit-Antworten im Thinking-Modus verarbeiten
Bei der Verwendung von Streaming im Thinking-Modus müssen die inkrementellen Fragmente des reasoning_content speziell behandelt werden:
from openai import OpenAI
client = OpenAI(
api_key="sk-DEIN_API_SCHLUESSEL",
base_url="https://api.apiyi.com/v1"
)
# Beispiel für einen Streaming-Modellaufruf
stream = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "user", "content": "Bitte analysiere die Worst-Case-Zeitkomplexität des Quicksort-Algorithmus"}
],
extra_body={"enable_thinking": True},
temperature=1.0,
max_tokens=16000,
stream=True
)
thinking_buffer = []
answer_buffer = []
is_thinking = True
for chunk in stream:
delta = chunk.choices[0].delta
# Verarbeitung des Denkprozess-Streams
if hasattr(delta, 'reasoning_content') and delta.reasoning_content:
thinking_buffer.append(delta.reasoning_content)
print(delta.reasoning_content, end='', flush=True)
# Verarbeitung des finalen Antwort-Streams
elif delta.content:
if is_thinking:
print("\n\n=== Finale Antwort ===\n")
is_thinking = False
answer_buffer.append(delta.content)
print(delta.content, end='', flush=True)
print() # Zeilenumbruch
💡 Wichtige Hinweise zum Streaming:
reasoning_contentundcontentsind im Streaming-Modus eigenständige Felder. Normalerweise wird zuerst der vollständigereasoning_contentund anschließend dercontentausgegeben. Sie müssen die inkrementellen Daten beider Felder separat überwachen.
Häufig gestellte Fragen (FAQ)
F1: Nach dem Aufruf fehlt das Feld reasoning_content, der Denkmodus scheint nicht aktiv zu sein?
A: Bitte prüfe die folgenden drei Punkte:
- Wurde der Parameter
"enable_thinking": truekorrekt übergeben? - Ist
max_tokensauf 16000 oder höher eingestellt? - Wird beim Aufruf über das Python SDK der Parameter
extra_body={"enable_thinking": True}korrekt verwendet?
Es empfiehlt sich, den Aufruf zunächst per curl zu testen, um sicherzustellen, dass das Parameterformat korrekt ist, bevor die Integration in den Code erfolgt. Der APIYI-Kundensupport unter apiyi.com bietet hierzu technische Unterstützung.
F2: Der Token-Verbrauch im Thinking-Modus ist zu hoch. Wie lassen sich die Kosten kontrollieren?
A: Optimierungsmöglichkeiten:
- Deaktiviere den Thinking-Modus für einfache Aufgaben (Parameter
enable_thinkingweglassen). - Reduziere
max_tokensmoderat (Minimum 8000, wobei dies bei komplexen Schlussfolgerungen zu Kürzungen führen kann). - Aufgabenbasierte Verteilung: Nutze
kimi-k2.5 thinkingfür komplexe Schlussfolgerungen und leichtere Modelle wiegpt-4o-minifür einfache Aufgaben. - Nutze die Gruppenpreise (0,88) von APIYI (apiyi.com), um die Basiskosten zu senken.
F3: Muss temperature zwingend auf 1.0 gesetzt werden?
A: Es wird offiziell dringend empfohlen, den Wert auf 1.0 zu setzen, da dies der optimale Temperaturparameter für den kimi-k2.5 Thinking-Modus ist. Ein zu niedriger Wert (z. B. 0,7) führt dazu, dass das Modell bei der Schlussfolgerung zu konservativ agiert, was die Qualität mindert; ein zu hoher Wert (z. B. 1,5) kann zu inkohärenten Schlussfolgerungsketten führen. 1.0 ist die sicherste Wahl.
F4: Ist das kimi-k2.5 von APIYI identisch mit dem offiziellen Modell?
A: Ja. APIYI nutzt die offizielle Schnittstelle von Alibaba Cloud; die Modellgewichte und Fähigkeiten sind identisch mit dem offiziellen Kimi-Modell. Der einzige Unterschied liegt in der Parameterübergabe: Während das offizielle Modell den Thinking-Modus standardmäßig aktiviert hat, muss er bei APIYI manuell über enable_thinking: true aktiviert werden. Dies ist eine Standardabweichung bei API-Proxy-Diensten und hat keinen Einfluss auf die Qualität der Modellausgabe.
Zusammenfassung: Die wichtigsten Punkte zum Kimi K2.5 Thinking-Modus
| Schlüsselpunkt | Beschreibung |
|---|---|
| Aktivierungsparameter | "enable_thinking": true muss übergeben werden |
| Temperatureinstellung | Fest auf temperature: 1.0 setzen |
| Token-Budget | max_tokens ≥ 16000 |
| Antwortfelder | Denkprozess in reasoning_content, Antwort in content |
| API-Endpunkt | https://api.apiyi.com/v1 (OpenAI-kompatibel) |
| Preisvorteil | Über 20 % günstiger als beim Originalanbieter, $10 Bonus bei $100 Aufladung |
Kimi K2.5 überzeugt bei zentralen Benchmarks wie mathematischem Schlussfolgern (AIME 96,1 %) und Codegenerierung (SWE-Bench 76,8 %). Der Thinking-Modus eignet sich besonders gut für komplexe Aufgaben, die eine mehrstufige logische Herleitung erfordern.
🎯 Jetzt ausprobieren: Besuchen Sie die APIYI-Website unter apiyi.com, registrieren Sie sich für einen API-Schlüssel und integrieren Sie den Kimi-K2.5-Thinking-Modus in unter 5 Minuten. Bei einer Aufladung von 100 USD erhalten Sie 10 USD Bonus; in Kombination mit unseren Gruppenrabatten liegen die Gesamtkosten deutlich unter dem Preisniveau der offiziellen Kimi-Website.
Artikel verfasst vom APIYI-Technikteam | Datenquelle: Offizielle Dokumentation von Moonshot AI und Bewertungsbericht von Artificial Analysis (Januar 2026)
Für technischen Support besuchen Sie bitte das APIYI-Hilfezentrum: help.apiyi.com