title: "Guía completa: Cómo activar el modo de razonamiento (Thinking) en Kimi K2.5 a través de APIYI"
description: "Aprende a activar el modo de razonamiento de Kimi K2.5 con el parámetro enable_thinking usando APIYI, ahorrando más del 20% respecto al precio oficial."

El modo de razonamiento (thinking) de Kimi K2.5 es una de las capacidades de inferencia más potentes disponibles actualmente, alcanzando una puntuación de 96.1% en el benchmark matemático AIME 2025. Sin embargo, muchos desarrolladores se encuentran con el mismo problema al integrarlo: el modelo no muestra el proceso de pensamiento tras realizar la llamada a la API.
Esto sucede porque, al utilizar la plataforma APIYI, es necesario incluir manualmente el parámetro "enable_thinking": true para activar este modo. En este artículo, te guiaré paso a paso para configurar correctamente el modo de razonamiento de Kimi K2.5.
🎯 Valor principal: Al terminar de leer, dominarás la invocación completa del modo thinking de Kimi K2.5 y aprenderás cómo utilizar esta capacidad de forma estable a través de APIYI, con un costo inferior al 80% del precio oficial.
Puntos clave del modo Thinking de Kimi K2.5
| Punto clave | Descripción | Valor |
|---|---|---|
| Parámetro de activación | Requiere incluir "enable_thinking": true |
Desbloquea el razonamiento profundo |
| Temperatura recomendada | Establecer en 1.0 (valor fijo) |
Garantiza la calidad del razonamiento |
| max_tokens recomendado | ≥ 16000 | Asegura la salida completa del proceso |
| Ventaja de precio | Precio de grupo 0.88, menos del 80% del oficial | Reduce drásticamente los costos |
| Estabilidad | Nivel de servicio proxy de API de Alibaba | Fiabilidad de grado empresarial |
💡 Inicio rápido: Regístrate en la plataforma APIYI en apiyi.com, recarga tu saldo y comienza a invocar Kimi K2.5. Es compatible con la interfaz de OpenAI, por lo que no necesitas modificar tu infraestructura de código actual.
¿Qué es Kimi K2.5?: El buque insignia de código abierto con 1 billón de parámetros
Kimi K2.5 fue lanzado por Moonshot AI el 27 de enero de 2026 y es actualmente uno de los Modelos de Lenguaje Grande multimodales con mayor capacidad de razonamiento en la comunidad de código abierto.
Especificaciones de la arquitectura central de Kimi K2.5
| Especificación | Valor | Descripción |
|---|---|---|
| Parámetros totales | 1 billón (1T) | Arquitectura de mezcla de expertos (MoE) |
| Parámetros activos | 32 mil millones (32B) | Utilizados realmente durante la inferencia |
| Ventana de contexto | 256K tokens | Capacidad de procesamiento de documentos extralargos |
| Número de expertos | 384 capas de expertos | Arquitectura dual MLA + MoE |
| Datos de entrenamiento | ~15 billones de tokens | Mezcla de texto + imagen |
| Estado de código abierto | Totalmente abierto | Descargable en HuggingFace |
Kimi K2.5 utiliza Atención Latente Multi-cabeza (MLA) y una estructura MoE de 384 expertos. Al mantener 1 billón de parámetros totales y activar solo 32 mil millones durante la inferencia, logra el equilibrio óptimo entre rendimiento y coste.
Cuatro modos de ejecución de Kimi K2.5
K2.5 Instant → Respuesta ultrarrápida, sin proceso de pensamiento, ideal para tareas simples
K2.5 Thinking → Razonamiento profundo, genera reasoning_content, ideal para problemas complejos
K2.5 Agent → Ejecución autónoma de tareas, capacidad de invocación de herramientas
K2.5 Agent Swarm → Colaboración multi-agente, hasta 100 sub-agentes en paralelo
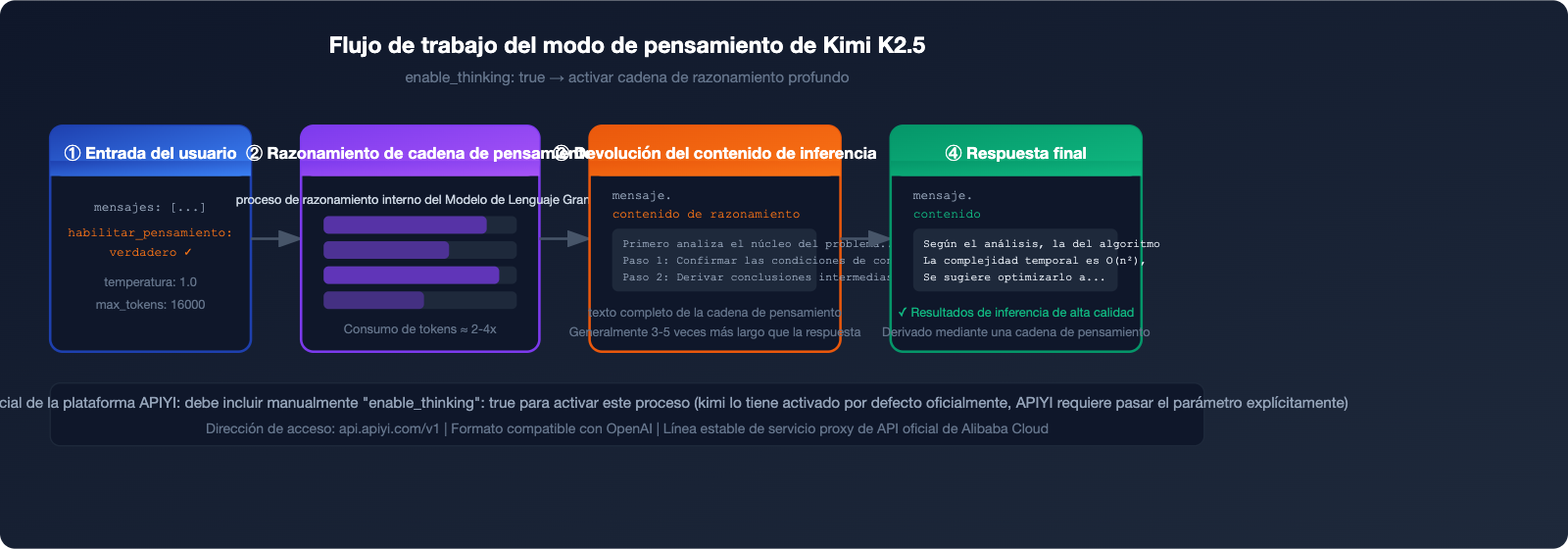
La plataforma APIYI admite actualmente el modo K2.5 Thinking, que se activa mediante el parámetro enable_thinking: true, permitiendo obtener la cadena de razonamiento completa.
💡 Recomendación de uso: Se recomienda acceder a kimi-k2.5 a través de APIYI (apiyi.com), utilizando el servicio proxy de API estable de Alibaba Cloud, sin preocuparse por interrupciones del servicio.
Benchmarks de rendimiento de Kimi K2.5: Datos de pruebas del modo de razonamiento
Tras activar el modo de razonamiento (thinking mode), el rendimiento de inferencia de Kimi K2.5 ha mejorado drásticamente. A continuación, presentamos los datos clave de las pruebas de rendimiento:
Resultados de los principales benchmarks
| Benchmark | Resultado de Kimi K2.5 | Notas comparativas |
|---|---|---|
| AIME 2025 (razonamiento matemático) | 96.1% | Cerca de la puntuación perfecta, capacidad matemática de primer nivel |
| SWE-Bench Verified (código) | 76.8% | Nivel líder entre los modelos de código abierto |
| HLE-Full w/ tools (agentes) | 4.7 puntos por encima | Primer puesto en tareas de invocación de herramientas |
| BrowseComp (navegación web) | 60.6% / 78.4%* | *En modo Agent Swarm |
| Índice de Inteligencia Integral | 47 puntos | El promedio de la industria es de 27 puntos |
Nota: Los datos anteriores provienen del Artificial Analysis Intelligence Index, resultados de evaluación de enero de 2026.
En comparación con el modo estándar, el modo de razonamiento (thinking mode) ofrece una mejora significativa del 30-50% en tareas complejas de matemáticas, razonamiento de múltiples pasos y generación de código. El coste es que el consumo de tokens es aproximadamente 2-4 veces mayor que en el modo estándar, por lo que controlar adecuadamente max_tokens es clave para reducir costes.
3 pasos para activar el modo de razonamiento de Kimi K2.5 en APIYI
Paso 1: Registrarse y obtener una clave API
Visite el sitio web oficial de APIYI en apiyi.com para registrar una cuenta y completar los siguientes pasos:
- Registre una cuenta y complete la verificación por correo electrónico.
- Acceda a "Consola" (Control Panel) → "Gestión de claves API".
- Cree una nueva clave API, cópiela y guárdela.
🎯 Ventaja de precio: Obtenga 10 USD de saldo extra al recargar 100 USD. El precio por grupo es de 0.88 (tokens de entrada), lo que hace que el coste real de uso sea inferior al 80% del precio oficial de Kimi. APIYI ofrece una línea estable al nivel de la transición oficial de Alibaba Cloud, con fiabilidad de nivel empresarial.
Paso 2: Configurar los parámetros de la solicitud
La clave para activar el modo de razonamiento de Kimi K2.5 reside en la configuración de estos tres parámetros:
{
"model": "kimi-k2.5",
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}
⚠️ Nota importante: La lógica de parámetros de la plataforma APIYI difiere de la API oficial de Kimi:
- Kimi oficial: El razonamiento está activado por defecto, requiere pasar parámetros para desactivarlo.
- Plataforma APIYI: Debe pasar manualmente
"enable_thinking": truepara activarlo.
Paso 3: Enviar la solicitud y analizar el contenido de razonamiento
A continuación, se muestra un ejemplo completo de invocación, incluyendo la activación del modo de razonamiento y el análisis de la respuesta.
Ejemplo de curl (la forma más rápida de verificar)
curl --location 'https://api.apiyi.com/v1/chat/completions' \
--header "Authorization: Bearer sk-TU_CLAVE_API" \
--header 'Content-Type: application/json' \
--data '{
"model": "kimi-k2.5",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Explica paso a paso: ¿Por qué 0.1 + 0.2 no es igual a 0.3 en informática?"
}
],
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}'
Ejemplo en Python (recomendado para entornos de producción)
from openai import OpenAI
client = OpenAI(
api_key="sk-TU_CLAVE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Analiza la complejidad temporal de este código y da sugerencias de optimización:\n\ndef find_duplicates(arr):\n result = []\n for i in range(len(arr)):\n for j in range(i+1, len(arr)):\n if arr[i] == arr[j] and arr[i] not in result:\n result.append(arr[i])\n return result"
}
],
extra_body={
"enable_thinking": True
},
temperature=1.0,
max_tokens=16000
)
# Analizar el contenido de razonamiento (si existe)
message = response.choices[0].message
# Imprimir el proceso de razonamiento (campo reasoning_content)
if hasattr(message, 'reasoning_content') and message.reasoning_content:
print("=== Proceso de razonamiento ===")
print(message.reasoning_content)
print()
# Imprimir la respuesta final
print("=== Respuesta final ===")
print(message.content)
Desplegar ejemplo completo en JavaScript / Node.js
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'sk-TU_CLAVE_API',
baseURL: 'https://api.apiyi.com/v1',
});
async function callKimiThinking(userMessage) {
const response = await client.chat.completions.create({
model: 'kimi-k2.5',
messages: [
{
role: 'system',
content: 'You are a helpful assistant.',
},
{
role: 'user',
content: userMessage,
},
],
// Pasar el parámetro enable_thinking a través de extra_body
// @ts-ignore
enable_thinking: true,
temperature: 1.0,
max_tokens: 16000,
});
const message = response.choices[0].message;
// Extraer el proceso de razonamiento
const reasoningContent = message.reasoning_content;
if (reasoningContent) {
console.log('=== Proceso de razonamiento ===');
console.log(reasoningContent);
console.log();
}
// Extraer la respuesta final
console.log('=== Respuesta final ===');
console.log(message.content);
return {
thinking: reasoningContent,
answer: message.content,
};
}
// Ejemplo de uso
callKimiThinking('Demuestra paso a paso: que existen infinitos números primos (demostración de Euclides)');
💡 Consejo de integración: En el código anterior, simplemente reemplace
base_urlporhttps://api.apiyi.com/v1. El resto de los parámetros son totalmente compatibles con el SDK de OpenAI, por lo que no requiere aprendizaje adicional. APIYI (apiyi.com) permite llamar a todos los modelos principales con una sola clave.
Detalles de los parámetros clave: Configuración correcta para evitar errores
Tabla de configuración de parámetros
| Parámetro | Valor recomendado | Descripción | Ejemplo incorrecto |
|---|---|---|---|
model |
"kimi-k2.5" |
Identificador del modelo | No usar kimi-k2 o kimi-k2.5-thinking |
enable_thinking |
true |
Activa el modo de razonamiento (exclusivo de APIYI) | Si falta, no se mostrará el contenido de razonamiento |
temperature |
1.0 |
Valor fijo recomendado oficialmente | Valores como 0.7 pueden causar inestabilidad |
max_tokens |
≥ 16000 |
Asegura una salida completa | Un valor muy bajo truncará el razonamiento |
stream |
false (prueba inicial) |
Compatible con streaming y no streaming | El streaming requiere manejo adicional del campo reasoning |
Explicación de la estructura de respuesta de la API
{
"choices": [
{
"message": {
"role": "assistant",
"content": "Contenido de la respuesta final...",
"reasoning_content": "Proceso de pensamiento del modelo, incluye razonamiento paso a paso..."
}
}
],
"usage": {
"prompt_tokens": 150,
"completion_tokens": 3200,
"total_tokens": 3350
}
}
El campo reasoning_content contiene la cadena de pensamiento completa; suele ser de 3 a 5 veces más largo que el campo content y es el dato fundamental para comprender el proceso de toma de decisiones del modelo.
🎯 Consejo de control de costos: En el modo de razonamiento (thinking), el consumo de tokens es aproximadamente de 2 a 4 veces mayor que en el modo normal. Recomendamos realizar la conexión a través de APIYI (apiyi.com), donde los precios por grupo de 0.88 pueden reducir significativamente los costos de inferencia. Además, al recargar 100 USD, recibirás 10 USD adicionales de crédito.
title: "APIYI vs. Sitio oficial: Comparativa de precios y estabilidad"
description: "Análisis comparativo entre APIYI y la API oficial de Kimi, centrado en costos, estabilidad y casos de uso óptimos para el modo Thinking."
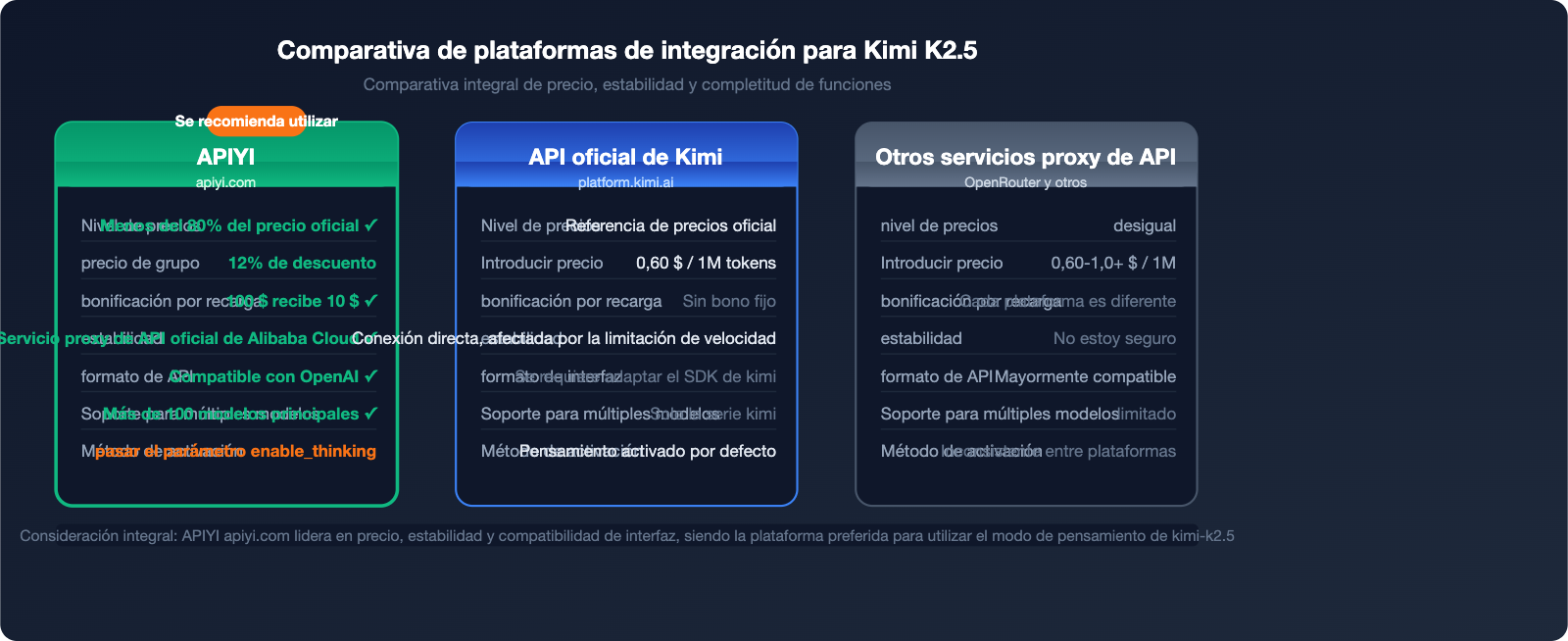
APIYI vs. Sitio oficial: Comparativa de precios y estabilidad
Resumen comparativo de plataformas
| Dimensión de comparación | APIYI (apiyi.com) | API oficial de Kimi | Otros servicios proxy de API |
|---|---|---|---|
| Nivel de precios | 20% menos que el oficial (precio de grupo 0.88) | Precio oficial | Variable |
| Estabilidad | Nivel de retransmisión oficial de Alibaba Cloud | Conexión directa, sujeta a límites de velocidad | Incierta |
| Descuentos por recarga | Recarga $100 obtén $10 extra | Sin bonificaciones fijas | Variado |
| Compatibilidad de interfaz | Formato OpenAI, 100% compatible | Requiere adaptar el SDK de Kimi | Mayoría compatible |
| Soporte multimodelo | Más de 100 modelos principales | Solo serie Kimi | Limitado |
| Soporte empresarial | Atención al cliente dedicada + Facturación | Soporte estándar | Limitado |
Ejemplo de cálculo de ventaja de precio en APIYI
Tomemos como ejemplo 1000 invocaciones mensuales del modelo kimi-k2.5 en modo thinking (promedio de 3000 tokens de entrada + 5000 tokens de salida por cada una):
Costo de tokens de entrada:
Precio oficial aprox. $0.60/1M → 1000 veces × 3000 tokens = 3M tokens → $1.80
Precio de grupo APIYI 0.88 → aprox. $1.58
Costo de tokens de salida (incluyendo razonamiento):
Precio oficial aprox. $2.50/1M → 1000 veces × 5000 tokens = 5M tokens → $12.50
Precio de grupo APIYI 0.88 → aprox. $11.00
Ahorro mensual: aprox. $1.72 + la bonificación por recarga cubre un 10% adicional de costos
💡 Descuento real: El ahorro de "más del 20%" en APIYI proviene de la combinación de dos factores: el descuento por precio de grupo (0.88) y la bonificación por recarga (recarga 100 obtén 10, es decir, un 10% de presupuesto adicional). El costo integral real es aproximadamente el 79-80% del precio oficial.
Mejores escenarios de uso para el modo Thinking de Kimi K2.5
Escenarios recomendados para activar el modo Thinking
1. Razonamiento matemático complejo
# Adecuado para el modo thinking
prompt = "Por favor, demuestra el último teorema de Fermat para el caso n=3 y proporciona los pasos detallados"
2. Depuración y optimización de código
# Adecuado para el modo thinking
prompt = """
El siguiente código tiene un error de concurrencia oculto, por favor encuéntralo y arréglalo:
[Pegar código multihilo complejo]
"""
3. Análisis lógico de múltiples pasos
# Adecuado para el modo thinking
prompt = "Analiza las lagunas lógicas de este plan de negocios y ordénalas por prioridad"
4. Deducción de problemas científicos
# Adecuado para el modo thinking
prompt = "Deduce la fórmula de los niveles de energía del átomo de hidrógeno a partir de los principios básicos de la mecánica cuántica"
Escenarios donde no es necesario activar el modo Thinking
# En los siguientes escenarios, usar el modo normal (sin pasar enable_thinking) puede ahorrar entre un 50% y un 70% en costos de tokens
# Preguntas y respuestas simples
"¿Qué tiempo hace hoy?" # No requiere razonamiento
# Traducción de textos
"Por favor, traduce el siguiente contenido al inglés:..." # No requiere razonamiento
# Salida formateada
"Formatea los siguientes datos JSON para su visualización" # No requiere razonamiento
# Escritura creativa
"Escribe un poema sobre la primavera" # No requiere razonamiento profundo
🎯 Sugerencia de uso: Se recomienda cambiar de modo dinámicamente según la complejidad de la tarea. Al conectarse a través de APIYI (apiyi.com), puede utilizar la misma clave API para invocar de forma flexible tanto el modelo kimi-k2.5 (modo thinking) como otros modelos ligeros, combinándolos según sus necesidades.
Salida en streaming: manejo de respuestas en tiempo real con el modo Thinking
Al utilizar la salida en streaming en el modo Thinking, es necesario gestionar de forma específica los fragmentos incrementales de reasoning_content:
from openai import OpenAI
client = OpenAI(
api_key="sk-tu_clave_API",
base_url="https://api.apiyi.com/v1"
)
# Ejemplo de invocación en streaming
stream = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "user", "content": "Por favor, analiza la complejidad temporal en el peor de los casos del algoritmo de ordenamiento rápido (quicksort)"}
],
extra_body={"enable_thinking": True},
temperature=1.0,
max_tokens=16000,
stream=True
)
thinking_buffer = []
answer_buffer = []
is_thinking = True
for chunk in stream:
delta = chunk.choices[0].delta
# Procesar el flujo de contenido de razonamiento
if hasattr(delta, 'reasoning_content') and delta.reasoning_content:
thinking_buffer.append(delta.reasoning_content)
print(delta.reasoning_content, end='', flush=True)
# Procesar el flujo de la respuesta final
elif delta.content:
if is_thinking:
print("\n\n=== Respuesta final ===\n")
is_thinking = False
answer_buffer.append(delta.content)
print(delta.content, end='', flush=True)
print() # Salto de línea
💡 Puntos clave del procesamiento en streaming:
reasoning_contentycontentson campos independientes durante el streaming; generalmente, primero se emite elreasoning_contentcompleto y luego elcontent. Es necesario escuchar los datos incrementales de ambos campos por separado.
Preguntas frecuentes (FAQ)
P1: ¿No aparece el campo reasoning_content tras la invocación? ¿El modo de pensamiento no se activó?
R: Por favor, verifica los siguientes tres puntos:
- Si se ha pasado correctamente el parámetro
"enable_thinking": true. - Si
max_tokensestá configurado en 16000 o más. - Si al realizar la invocación con el SDK de Python se ha pasado el parámetro a través de
extra_body={"enable_thinking": True}.
Se recomienda realizar una prueba directa con curl para confirmar que el formato de los parámetros es correcto antes de integrarlo en el código. El servicio de atención al cliente de APIYI en apiyi.com puede ofrecerte soporte técnico.
P2: El consumo de tokens es muy alto en el modo Thinking, ¿cómo puedo controlar los costos?
R: Puedes optimizarlo desde los siguientes ángulos:
- Desactivar el modo Thinking para tareas sencillas (no pasar el parámetro
enable_thinking). - Reducir adecuadamente
max_tokens(mínimo 8000, aunque esto podría truncar razonamientos complejos). - Segmentar las tareas: utiliza kimi-k2.5 thinking para razonamientos complejos y modelos ligeros como gpt-4o-mini para tareas simples.
- Reducir los costos base mediante los precios por grupo de APIYI en apiyi.com (0.88).
P3: ¿Es obligatorio configurar temperature en 1.0?
R: Oficialmente se recomienda encarecidamente configurarlo en 1.0, ya que es el parámetro de temperatura óptimo para el modo Thinking de kimi-k2.5. Una configuración demasiado baja (por ejemplo, 0.7) hará que el modelo sea demasiado conservador durante el razonamiento, reduciendo la calidad; una configuración demasiado alta (por ejemplo, 1.5) podría generar cadenas de razonamiento incoherentes. Usar 1.0 directamente es la opción más segura.
P4: ¿Es el kimi-k2.5 de APIYI exactamente igual al oficial?
R: Sí. APIYI utiliza el enlace de transferencia oficial de Alibaba Cloud; los pesos y capacidades del modelo son exactamente iguales a los del kimi oficial. La única diferencia radica en la forma de pasar los parámetros: el oficial activa el modo Thinking por defecto, mientras que en APIYI se debe pasar manualmente enable_thinking: true. Esta es una diferencia estándar en las plataformas de servicio proxy de API y no afecta la calidad de la salida del modelo.
Resumen: Puntos clave del modo de razonamiento de Kimi K2.5
| Punto clave | Descripción |
|---|---|
| Parámetros de activación | Es obligatorio incluir "enable_thinking": true |
| Configuración de temperatura | Usar siempre temperature: 1.0 |
| Presupuesto de tokens | max_tokens ≥ 16000 |
| Campos de respuesta | El contenido de razonamiento aparece en reasoning_content, la respuesta en content |
| Dirección de acceso | https://api.apiyi.com/v1 (compatible con OpenAI) |
| Descuentos | Menos del 80% del precio oficial, recarga $100 y recibe $10 extra |
Kimi K2.5 destaca en benchmarks clave como el razonamiento matemático AIME (96.1%) y la generación de código (SWE-Bench 76.8%). Su modo de razonamiento es especialmente adecuado para gestionar tareas complejas que requieren múltiples pasos de inferencia.
🎯 Pruébalo ahora: Visita el sitio web de APIYI en apiyi.com, registra tu cuenta para obtener una clave API y podrás completar la integración del modo de razonamiento de kimi-k2.5 en menos de 5 minutos. Al recargar 100 dólares obtendrás 10 dólares de regalo, lo que, sumado a los descuentos por grupo, sitúa el coste total por debajo del 80% del precio oficial de Kimi.
Artículo redactado por el equipo técnico de APIYI | Fuente de datos: Documentación oficial de Moonshot AI e informe de evaluación de Artificial Analysis (enero de 2026)
Si necesitas asistencia técnica, visita el centro de ayuda de APIYI: help.apiyi.com