作者注:详解如何通过 API易 平台调用 kimi-k2.5 并开启 enable_thinking 参数,享受低于官网八折的稳定价格,附 curl、Python、JavaScript 完整示例代码
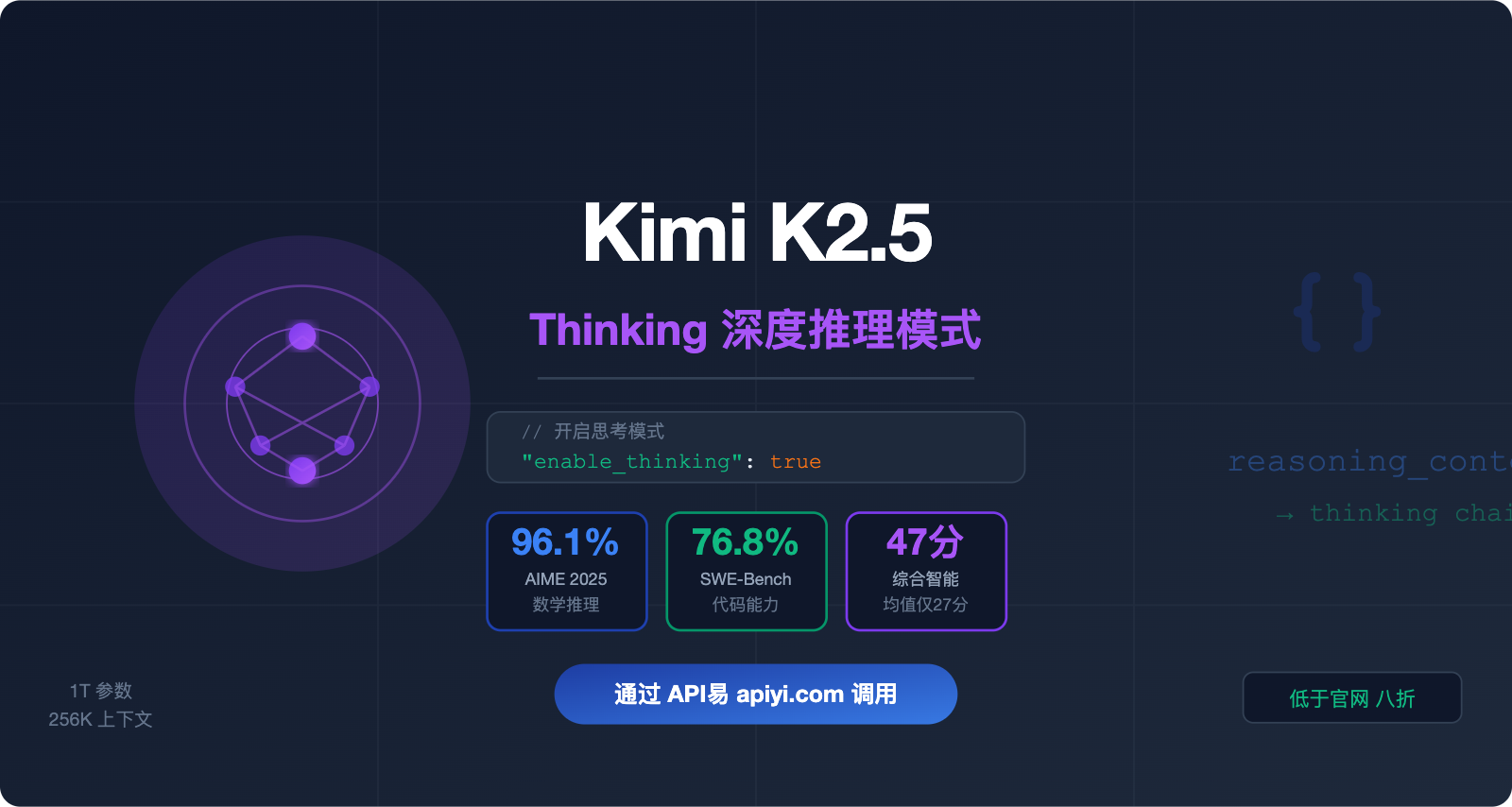
Kimi K2.5 的 thinking 思考模式是目前开源模型中推理能力最强的功能之一,AIME 2025 数学基准得分高达 96.1%。但很多开发者在接入时遇到同一个问题:调用 API 后模型没有输出思考过程。
这是因为 API易 平台需要手动传入 "enable_thinking": true 参数才能激活思考模式。本文将从零开始,带你完成 Kimi K2.5 思考模式的完整接入配置。
🎯 核心价值: 读完本文,你将掌握 kimi-k2.5 thinking 模式的完整调用方式,并了解如何通过 API易 以低于官网八折的价格稳定使用这一能力。
Kimi K2.5 Thinking 模式核心要点
| 要点 | 说明 | 价值 |
|---|---|---|
| 激活参数 | 需传入 "enable_thinking": true |
解锁深度推理能力 |
| 推荐 temperature | 设置为 1.0(固定值) |
保证思考质量稳定 |
| 推荐 max_tokens | ≥ 16000 | 确保思考内容完整输出 |
| 价格优势 | 分组价 0.88,低于官网八折 | 大幅降低推理成本 |
| 稳定性 | 阿里云官转水平 | 企业级可靠性保障 |
💡 快速开始: 注册 API易 账号 apiyi.com,充值即可调用 kimi-k2.5,支持 OpenAI 兼容接口,无需改动现有代码框架。
Kimi K2.5 是什么:1 万亿参数的开源推理旗舰
Kimi K2.5 由 Moonshot AI 于 2026 年 1 月 27 日发布,是目前开源社区中推理能力最强的多模态大模型之一。
Kimi K2.5 核心架构规格
| 规格 | 数值 | 说明 |
|---|---|---|
| 总参数量 | 1 万亿(1T) | MoE 混合专家架构 |
| 激活参数量 | 320 亿(32B) | 推理时实际使用 |
| 上下文窗口 | 256K tokens | 超长文档处理能力 |
| 专家数量 | 384 个专家层 | MLA + MoE 双架构 |
| 训练数据 | ~15 万亿 token | 文本 + 图像混合 |
| 开源状态 | 完全开源 | HuggingFace 可下载 |
Kimi K2.5 采用 多头潜在注意力(MLA) 和 384 专家 MoE 结构,在保持 1 万亿总参数的前提下,推理时仅激活 320 亿参数,实现了性能与成本的最优平衡。
Kimi K2.5 的四种运行模式
K2.5 Instant → 极速响应,无思考过程,适合简单任务
K2.5 Thinking → 深度推理,输出 reasoning_content,适合复杂问题
K2.5 Agent → 自主任务执行,工具调用能力
K2.5 Agent Swarm → 多智能体协作,最多 100 个子智能体并行
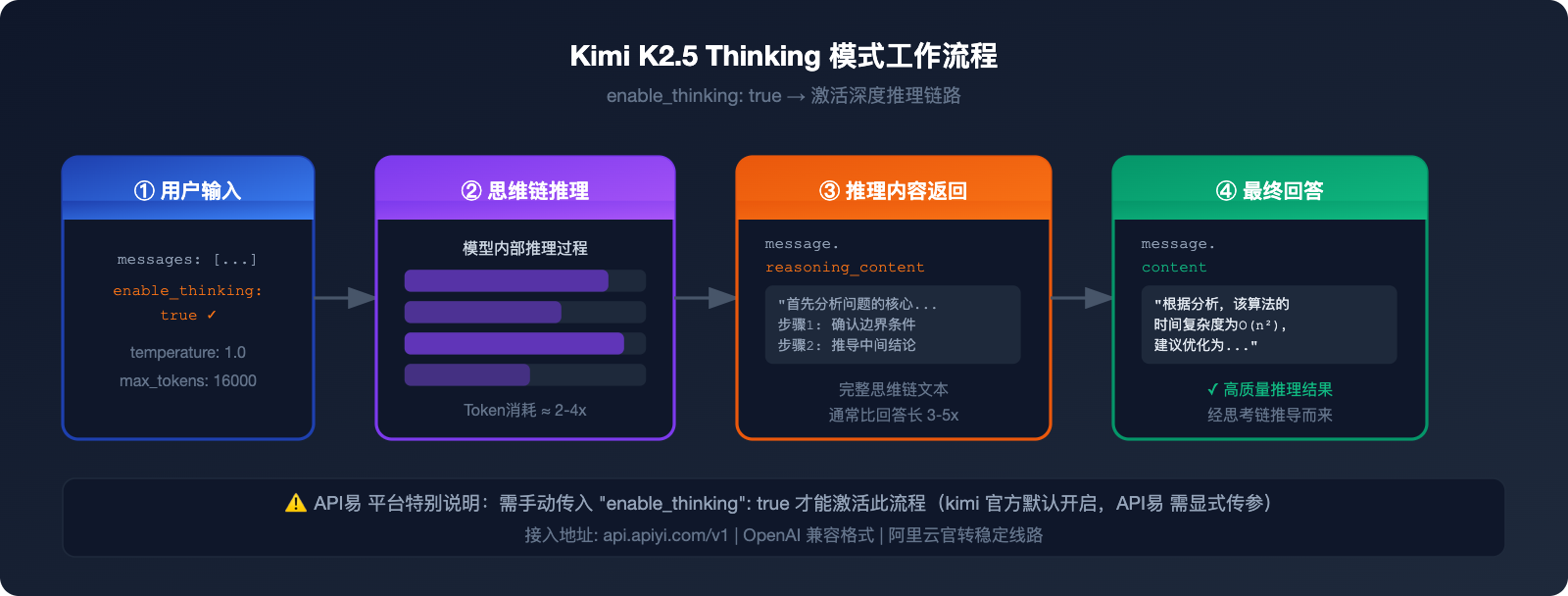
API易 平台当前支持 K2.5 Thinking 模式,通过 enable_thinking: true 参数激活,输出完整推理链。
💡 使用建议: 推荐通过 API易 apiyi.com 接入 kimi-k2.5,稳定的阿里云官转链路,无需担心服务中断。
Kimi K2.5 性能基准:思考模式实测数据
在开启 thinking 模式后,kimi-k2.5 的推理性能大幅提升,以下是关键基准测试数据:
主要基准测试成绩
| 基准测试 | Kimi K2.5 成绩 | 对比说明 |
|---|---|---|
| AIME 2025(数学推理) | 96.1% | 接近满分水平,数学能力顶尖 |
| SWE-Bench Verified(代码) | 76.8% | 开源模型中领先水平 |
| HLE-Full w/ tools(智能体) | 领先 4.7 分 | 工具调用任务第一名 |
| BrowseComp(网页浏览) | 60.6% / 78.4%* | *Agent Swarm 模式下 |
| 综合智能指数 | 47 分 | 行业平均为 27 分 |
注: 以上数据来自 Artificial Analysis Intelligence Index,2026 年 1 月评测结果。
思考模式(Thinking mode)相比标准模式,在复杂数学、多步推理、代码生成等任务上有 30-50% 的显著提升。代价是 token 消耗约为标准模式的 2-4 倍,因此合理控制 max_tokens 是降本关键。
3 步在 API易 开启 Kimi K2.5 Thinking 模式
第 1 步:注册并获取 API Key
访问 API易 官网 apiyi.com 注册账号,完成以下操作:
- 注册账号并完成邮箱验证
- 进入「控制台」→「API Key 管理」
- 创建新的 API Key,复制保存
🎯 价格优势: 充值 100 美金立享 10 美金赠金,分组价格 0.88(输入 token),实际使用成本低于 kimi 官网八折水平。API易 提供阿里云官转水平的稳定线路,企业级可靠性。
第 2 步:配置请求参数
开启 kimi-k2.5 思考模式的关键在于以下三个参数配置:
{
"model": "kimi-k2.5",
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}
⚠️ 重要说明:API易 平台与 kimi 官方 API 的参数逻辑不同:
- kimi 官方:thinking 默认开启,需要主动传参关闭
- API易 平台:需要手动传入
"enable_thinking": true才能激活
第 3 步:发送请求并解析思考内容
以下是完整的调用示例,包含 thinking 模式激活和响应解析。
curl 示例(最快验证方式)
curl --location 'https://api.apiyi.com/v1/chat/completions' \
--header "Authorization: Bearer sk-你的API_KEY" \
--header 'Content-Type: application/json' \
--data '{
"model": "kimi-k2.5",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "请用步骤化的方式解释:为什么 0.1 + 0.2 在计算机中不等于 0.3?"
}
],
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}'
Python 示例(推荐生产环境使用)
from openai import OpenAI
client = OpenAI(
api_key="sk-你的API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "请分析这段代码的时间复杂度并给出优化建议:\n\ndef find_duplicates(arr):\n result = []\n for i in range(len(arr)):\n for j in range(i+1, len(arr)):\n if arr[i] == arr[j] and arr[i] not in result:\n result.append(arr[i])\n return result"
}
],
extra_body={
"enable_thinking": True
},
temperature=1.0,
max_tokens=16000
)
# 解析思考内容(如果存在)
message = response.choices[0].message
# 输出思考过程(reasoning_content 字段)
if hasattr(message, 'reasoning_content') and message.reasoning_content:
print("=== 思考过程 ===")
print(message.reasoning_content)
print()
# 输出最终回答
print("=== 最终回答 ===")
print(message.content)
展开 JavaScript / Node.js 完整示例
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'sk-你的API_KEY',
baseURL: 'https://api.apiyi.com/v1',
});
async function callKimiThinking(userMessage) {
const response = await client.chat.completions.create({
model: 'kimi-k2.5',
messages: [
{
role: 'system',
content: 'You are a helpful assistant.',
},
{
role: 'user',
content: userMessage,
},
],
// 通过 extra_body 传入 enable_thinking 参数
// @ts-ignore
enable_thinking: true,
temperature: 1.0,
max_tokens: 16000,
});
const message = response.choices[0].message;
// 提取思考过程
const reasoningContent = message.reasoning_content;
if (reasoningContent) {
console.log('=== Thinking Process ===');
console.log(reasoningContent);
console.log();
}
// 提取最终回答
console.log('=== Final Answer ===');
console.log(message.content);
return {
thinking: reasoningContent,
answer: message.content,
};
}
// 使用示例
callKimiThinking('请分步骤证明:质数有无穷多个(欧几里得证明)');
💡 接入提示: 上述代码将
base_url替换为https://api.apiyi.com/v1,其余参数与 OpenAI SDK 完全兼容,无需额外学习成本。API易 apiyi.com 支持一个 Key 调用所有主流模型。
关键参数详解:正确配置避免踩坑
参数配置对照表
| 参数 | 推荐值 | 说明 | 错误示例 |
|---|---|---|---|
model |
"kimi-k2.5" |
模型标识符 | 不要写 kimi-k2 或 kimi-k2.5-thinking |
enable_thinking |
true |
激活思考模式(API易专用) | 缺少此参数将不输出推理内容 |
temperature |
1.0 |
官方推荐固定值 | 设置 0.7 等值会导致质量不稳定 |
max_tokens |
≥ 16000 |
确保完整输出 | 设置过小会截断思考内容 |
stream |
false(初始测试) |
流式/非流式均支持 | 流式需额外处理 reasoning 字段 |
API响应结构说明
{
"choices": [
{
"message": {
"role": "assistant",
"content": "最终回答内容...",
"reasoning_content": "模型的思考过程,包含分步推理..."
}
}
],
"usage": {
"prompt_tokens": 150,
"completion_tokens": 3200,
"total_tokens": 3350
}
}
reasoning_content 字段包含完整的思维链内容,通常比 content 字段长 3-5 倍,是理解模型决策过程的核心数据。
🎯 成本控制建议: thinking 模式下 token 消耗约为普通模式的 2-4 倍。我们建议通过 API易 apiyi.com 接入,分组价格 0.88 可大幅降低推理成本,充值 100 美金还可获赠 10 美金额度。

API易 vs 官网:价格与稳定性对比
平台对比总览
| 对比维度 | API易 (apiyi.com) | Kimi 官方 API | 其他中转平台 |
|---|---|---|---|
| 价格水平 | 低于官网八折(0.88 分组价) | 官方定价 | 参差不齐 |
| 稳定性 | 阿里云官转水平 | 直连,受限速影响 | 不确定 |
| 充值优惠 | 充值 $100 送 $10 | 无固定赠送 | 各异 |
| 接口兼容性 | OpenAI 格式,100% 兼容 | 需适配 kimi SDK | 多数兼容 |
| 多模型支持 | 100+ 主流模型 | 仅 kimi 系列 | 有限 |
| 企业支持 | 专属客服 + 发票 | 标准支持 | 有限 |
API易 价格优势计算示例
以每月调用 1000 次 kimi-k2.5 thinking 模式(每次平均 3000 token 输入 + 5000 token 输出)为例:
输入 token 成本:
官网价格约 $0.60/1M → 1000次 × 3000 token = 3M token → $1.80
API易 分组价 0.88 折 → 约 $1.58
输出 token 成本(含 reasoning):
官网价格约 $2.50/1M → 1000次 × 5000 token = 5M token → $12.50
API易 分组价 0.88 折 → 约 $11.00
月度节省: 约 $1.72 + 充值赠金额外覆盖约 10% 成本
💡 实际优惠: API易 的「低于八折」来自两部分叠加——分组价格折扣(0.88)+ 充值赠金(充 100 送 10,即额外 10% 预算)。实际综合成本约为官网的 79-80%。
Kimi K2.5 Thinking 模式最佳使用场景
推荐开启 Thinking 的场景
1. 复杂数学推理
# 适合 thinking 模式
prompt = "请证明费马大定理对于 n=3 的情况,并给出详细步骤"
2. 代码调试与优化
# 适合 thinking 模式
prompt = """
以下代码有一个隐藏的并发 bug,请找出并修复:
[粘贴复杂的多线程代码]
"""
3. 多步骤逻辑分析
# 适合 thinking 模式
prompt = "分析这份商业计划书的逻辑漏洞,并按优先级排列"
4. 科学问题推导
# 适合 thinking 模式
prompt = "从量子力学基本原理推导氢原子的能级公式"
无需开启 Thinking 的场景
# 以下场景使用普通模式(不传 enable_thinking),可节省 50-70% token 成本
# 简单问答
"今天天气怎么样?" # 无需推理
# 文本翻译
"请将以下内容翻译成英文:..." # 无需推理
# 格式化输出
"将以下 JSON 数据格式化显示" # 无需推理
# 创意写作
"写一首关于春天的诗" # 无需深度推理
🎯 使用建议: 建议根据任务复杂度动态切换模式。通过 API易 apiyi.com 接入,可以用同一个 API Key 灵活调用 kimi-k2.5(thinking 模式)和其他轻量模型,按需混合使用。
流式输出:处理 Thinking 模式的实时响应
在 thinking 模式下使用流式输出(streaming)时,需要特别处理 reasoning_content 的增量片段:
from openai import OpenAI
client = OpenAI(
api_key="sk-你的API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 流式调用示例
stream = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "user", "content": "请分析快速排序算法的最坏情况时间复杂度"}
],
extra_body={"enable_thinking": True},
temperature=1.0,
max_tokens=16000,
stream=True
)
thinking_buffer = []
answer_buffer = []
is_thinking = True
for chunk in stream:
delta = chunk.choices[0].delta
# 处理思考内容流
if hasattr(delta, 'reasoning_content') and delta.reasoning_content:
thinking_buffer.append(delta.reasoning_content)
print(delta.reasoning_content, end='', flush=True)
# 处理最终回答流
elif delta.content:
if is_thinking:
print("\n\n=== 最终回答 ===\n")
is_thinking = False
answer_buffer.append(delta.content)
print(delta.content, end='', flush=True)
print() # 换行
💡 流式处理要点:
reasoning_content和content在流式中是独立的字段,通常先完整输出 reasoning_content,再输出 content。需要分别监听两个字段的增量数据。
常见问题 FAQ
Q1:调用后没有 reasoning_content 字段,思考模式没有生效?
A:请检查以下三点:
- 是否正确传入了
"enable_thinking": true参数 max_tokens是否设置为 16000 或以上- Python SDK 调用时是否通过
extra_body={"enable_thinking": True}传参
建议先用 curl 直接测试,确认参数格式正确后再集成到代码中。API易 客服 apiyi.com 可提供技术支持。
Q2:thinking 模式下 token 消耗过高,如何控制成本?
A:可以从以下角度优化:
- 对简单任务关闭 thinking 模式(不传 enable_thinking 参数)
- 适当降低 max_tokens(最低 8000,但可能截断复杂推理)
- 在任务层面分流:复杂推理用 kimi-k2.5 thinking,简单任务用 gpt-4o-mini 等轻量模型
- 通过 API易 apiyi.com 的分组价格(0.88)降低基础成本
Q3:temperature 必须设置为 1.0 吗?
A:官方强烈推荐设置为 1.0,这是 kimi-k2.5 thinking 模式的最佳温度参数。设置过低(如 0.7)会导致模型在推理时过于保守,质量下降;设置过高(如 1.5)则可能产生不连贯的推理链。直接使用 1.0 是最稳妥的选择。
Q4:API易 的 kimi-k2.5 是否与官方完全一致?
A:是的。API易 采用阿里云官转链路,模型权重和能力与 kimi 官方完全一致,区别仅在于参数传递方式:官方默认开启 thinking,API易 需要手动传 enable_thinking: true。这是中转平台的标准差异,不影响模型输出质量。
总结:Kimi K2.5 Thinking 模式核心要点回顾
| 关键点 | 说明 |
|---|---|
| 激活参数 | 必须传入 "enable_thinking": true |
| 温度设置 | 固定使用 temperature: 1.0 |
| token 预算 | max_tokens ≥ 16000 |
| 响应字段 | 思考内容在 reasoning_content,回答在 content |
| 接入地址 | https://api.apiyi.com/v1(OpenAI 兼容) |
| 价格优惠 | 低于官网八折,充值 $100 送 $10 |
Kimi K2.5 在 AIME 数学推理(96.1%)、代码生成(SWE-Bench 76.8%)等核心基准上表现突出,思考模式特别适合处理需要多步推理的复杂任务。
🎯 立即体验: 访问 API易 官网 apiyi.com,注册账号获取 API Key,5 分钟内即可完成 kimi-k2.5 thinking 模式的接入。充值 100 美金享受 10 美金赠金,叠加分组折扣后综合成本低于 kimi 官网八折水平。
文章由 API易 技术团队撰写 | 数据来源:Moonshot AI 官方文档及 Artificial Analysis 评测报告(2026年1月)
如需技术支持,请访问 API易 帮助中心:help.apiyi.com