Voici la traduction technique du contenu, adaptée pour vos lecteurs francophones.
Note de l'auteur : Découvrez comment invoquer le modèle Kimi-K2.5 via la plateforme APIYI en activant le paramètre enable_thinking. Profitez d'une tarification stable, inférieure de 20 % aux tarifs officiels. Exemples complets en curl, Python et JavaScript inclus.

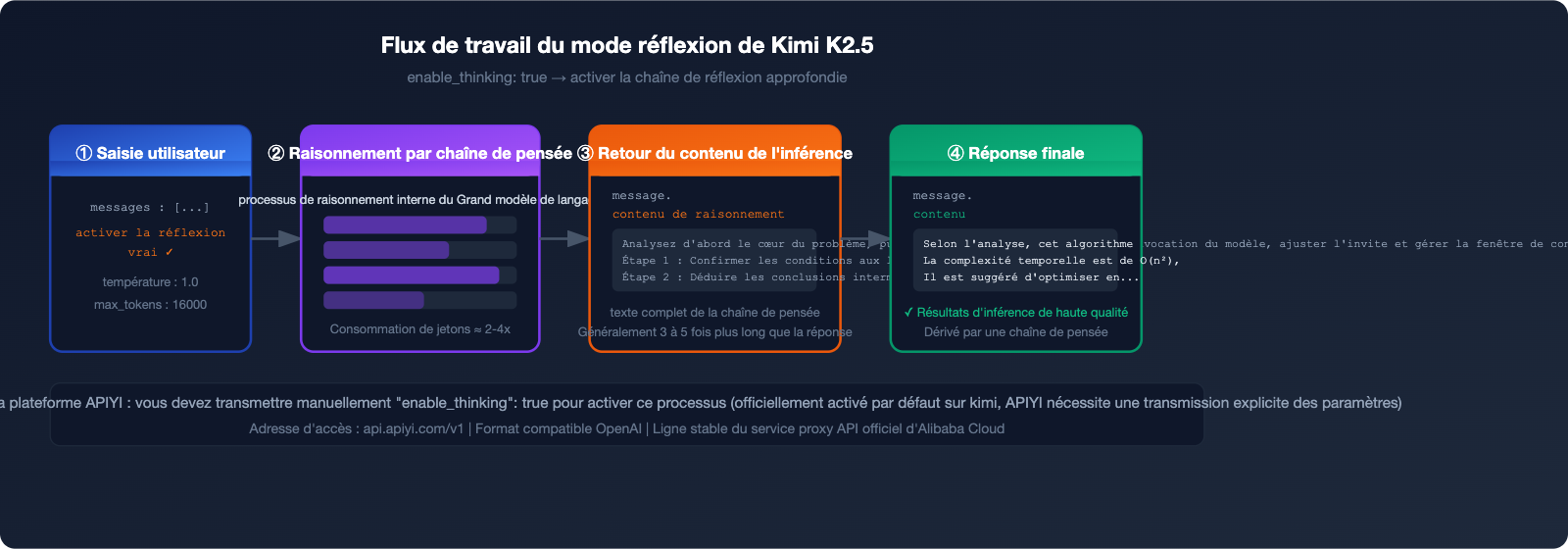
Le mode de réflexion (thinking) de Kimi K2.5 est l'une des fonctionnalités de raisonnement les plus puissantes parmi les modèles actuels, atteignant un score impressionnant de 96,1 % au benchmark mathématique AIME 2025. Cependant, de nombreux développeurs rencontrent le même problème lors de l'intégration : le modèle n'affiche pas son processus de réflexion après l'appel API.
Cela est dû au fait que la plateforme APIYI nécessite l'ajout manuel du paramètre "enable_thinking": true pour activer ce mode. Cet article vous guide pas à pas dans la configuration complète pour exploiter le mode réflexion de Kimi K2.5.
🎯 Valeur ajoutée : En lisant cet article, vous maîtriserez l'invocation complète du mode thinking de Kimi K2.5 et apprendrez comment utiliser cette capacité de manière stable via APIYI, à un tarif inférieur de 20 % aux prix officiels.
Points clés du mode Thinking de Kimi K2.5
| Point | Description | Valeur |
|---|---|---|
| Paramètre d'activation | Ajouter "enable_thinking": true |
Débloque le raisonnement profond |
| Température recommandée | Fixée à 1.0 |
Garantit la stabilité de la qualité de réflexion |
| Max_tokens recommandés | ≥ 16000 | Assure l'affichage complet du processus de réflexion |
| Avantage tarifaire | Prix de groupe à 0,88, moins cher que les 80 % officiels | Réduction significative des coûts d'inférence |
| Stabilité | Niveau de service proxy officiel d'Alibaba Cloud | Fiabilité de qualité entreprise |
💡 Démarrage rapide : Créez un compte sur APIYI (apiyi.com), rechargez votre solde et commencez à invoquer Kimi K2.5. Compatible avec l'interface OpenAI, aucune modification de votre infrastructure de code actuelle n'est nécessaire.
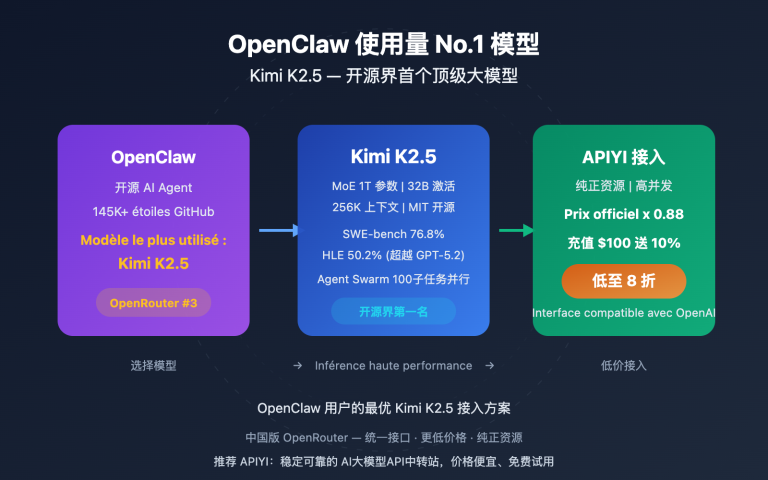
Qu'est-ce que Kimi K2.5 : Le fleuron de l'inférence open source avec 1 000 milliards de paramètres
Publié par Moonshot AI le 27 janvier 2026, Kimi K2.5 s'impose comme l'un des grands modèles de langage multimodaux les plus performants en matière de raisonnement au sein de la communauté open source.
Spécifications de l'architecture de Kimi K2.5
| Spécification | Valeur | Description |
|---|---|---|
| Paramètres totaux | 1 000 milliards (1T) | Architecture MoE (Mélange d'experts) |
| Paramètres activés | 32 milliards (32B) | Utilisés réellement lors de l'inférence |
| Fenêtre de contexte | 256K tokens | Capacité de traitement de documents ultra-longs |
| Nombre d'experts | 384 couches d'experts | Double architecture MLA + MoE |
| Données d'entraînement | ~15 000 milliards de tokens | Mélange de texte et d'images |
| Statut open source | Entièrement open source | Téléchargeable sur HuggingFace |
Kimi K2.5 utilise l'attention latente multi-têtes (MLA) et une structure MoE à 384 experts. En maintenant un total de 1 000 milliards de paramètres tout en n'en activant que 32 milliards lors de l'inférence, il atteint un équilibre optimal entre performance et coût.
Les quatre modes d'exécution de Kimi K2.5
K2.5 Instant → Réponse ultra-rapide, sans processus de réflexion, idéal pour les tâches simples
K2.5 Thinking → Raisonnement approfondi, génère du reasoning_content, idéal pour les problèmes complexes
K2.5 Agent → Exécution autonome de tâches, capacité d'appel d'outils
K2.5 Agent Swarm → Collaboration multi-agents, jusqu'à 100 sous-agents en parallèle
La plateforme APIYI prend actuellement en charge le mode K2.5 Thinking, activable via le paramètre enable_thinking: true, permettant d'obtenir la chaîne de raisonnement complète.
💡 Conseil d'utilisation : Nous recommandons d'accéder à kimi-k2.5 via APIYI (apiyi.com), qui propose une liaison stable avec le service officiel d'Alibaba Cloud, sans risque d'interruption de service.
Benchmarks de performance de Kimi K2.5 : données réelles du mode réflexion
Avec l'activation du mode réflexion (thinking), les performances de raisonnement de Kimi K2.5 ont fait un bond spectaculaire. Voici les données clés issues des benchmarks :
Résultats des principaux benchmarks
| Benchmark | Score Kimi K2.5 | Notes comparatives |
|---|---|---|
| AIME 2025 (Raisonnement mathématique) | 96,1 % | Proche du score parfait, capacités mathématiques de pointe |
| SWE-Bench Verified (Code) | 76,8 % | Niveau leader parmi les modèles open source |
| HLE-Full w/ tools (Agents) | +4,7 points | Première place sur les tâches d'invocation d'outils |
| BrowseComp (Navigation web) | 60,6 % / 78,4 %* | *En mode Agent Swarm |
| Indice d'intelligence globale | 47 points | Moyenne de l'industrie : 27 points |
Note : Les données ci-dessus proviennent de l'Artificial Analysis Intelligence Index, résultats de janvier 2026.
Comparé au mode standard, le mode réflexion (Thinking mode) offre une amélioration significative de 30 à 50 % sur les tâches complexes de mathématiques, de raisonnement multi-étapes et de génération de code. Le coût est une consommation de jetons (tokens) environ 2 à 4 fois supérieure au mode standard ; il est donc crucial de bien contrôler max_tokens pour optimiser les coûts.
3 étapes pour activer le mode réflexion de Kimi K2.5 sur APIYI
Étape 1 : S'inscrire et obtenir une clé API
Rendez-vous sur le site officiel d'APIYI, apiyi.com, pour créer votre compte et effectuer les opérations suivantes :
- Créez un compte et validez votre adresse e-mail.
- Accédez à la « Console » → « Gestion des clés API ».
- Créez une nouvelle clé API et conservez-la précieusement.
🎯 Avantage tarifaire : Recevez 10 $ de crédit offert pour tout rechargement de 100 $. Avec un prix de groupe à 0,88 (jetons en entrée), le coût réel est inférieur de 20 % aux tarifs officiels de Kimi. APIYI propose des lignes stables au niveau des services officiels d'Alibaba Cloud, garantissant une fiabilité de niveau entreprise.
Étape 2 : Configurer les paramètres de requête
L'activation du mode réflexion pour kimi-k2.5 repose sur la configuration de ces trois paramètres :
{
"model": "kimi-k2.5",
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}
⚠️ Note importante : La logique des paramètres sur la plateforme APIYI diffère de l'API officielle de Kimi :
- Kimi officiel : la réflexion est activée par défaut, il faut transmettre un paramètre pour la désactiver.
- Plateforme APIYI : vous devez transmettre manuellement
"enable_thinking": truepour l'activer.
Étape 3 : Envoyer la requête et analyser le contenu de réflexion
Voici un exemple complet d'invocation, incluant l'activation du mode réflexion et l'analyse de la réponse.
Exemple curl (la méthode la plus rapide pour tester)
curl --location 'https://api.apiyi.com/v1/chat/completions' \
--header "Authorization: Bearer sk-VOTRE_CLE_API" \
--header 'Content-Type: application/json' \
--data '{
"model": "kimi-k2.5",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Expliquez étape par étape : pourquoi 0.1 + 0.2 n'est-il pas égal à 0.3 en informatique ?"
}
],
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}'
Exemple Python (recommandé pour la production)
from openai import OpenAI
client = OpenAI(
api_key="sk-VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Analysez la complexité temporelle de ce code et proposez des optimisations :\n\ndef find_duplicates(arr):\n result = []\n for i in range(len(arr)):\n for j in range(i+1, len(arr)):\n if arr[i] == arr[j] and arr[i] not in result:\n result.append(arr[i])\n return result"
}
],
extra_body={
"enable_thinking": True
},
temperature=1.0,
max_tokens=16000
)
# Analyser le contenu de réflexion (s'il existe)
message = response.choices[0].message
# Afficher le processus de réflexion (champ reasoning_content)
if hasattr(message, 'reasoning_content') and message.reasoning_content:
print("=== Processus de réflexion ===")
print(message.reasoning_content)
print()
# Afficher la réponse finale
print("=== Réponse finale ===")
print(message.content)
Déplier l’exemple complet en JavaScript / Node.js
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'sk-VOTRE_CLE_API',
baseURL: 'https://api.apiyi.com/v1',
});
async function callKimiThinking(userMessage) {
const response = await client.chat.completions.create({
model: 'kimi-k2.5',
messages: [
{
role: 'system',
content: 'You are a helpful assistant.',
},
{
role: 'user',
content: userMessage,
},
],
// Transmettre le paramètre enable_thinking via extra_body
// @ts-ignore
enable_thinking: true,
temperature: 1.0,
max_tokens: 16000,
});
const message = response.choices[0].message;
// Extraire le processus de réflexion
const reasoningContent = message.reasoning_content;
if (reasoningContent) {
console.log('=== Processus de réflexion ===');
console.log(reasoningContent);
console.log();
}
// Extraire la réponse finale
console.log('=== Réponse finale ===');
console.log(message.content);
return {
thinking: reasoningContent,
answer: message.content,
};
}
// Exemple d'utilisation
callKimiThinking('Démontrez étape par étape : pourquoi existe-t-il une infinité de nombres premiers (preuve d\'Euclide) ?');
💡 Conseil d'intégration : Remplacez simplement
base_urlparhttps://api.apiyi.com/v1dans le code ci-dessus. Les autres paramètres sont entièrement compatibles avec le SDK OpenAI, sans coût d'apprentissage supplémentaire. APIYI (apiyi.com) permet d'appeler tous les modèles principaux avec une seule clé.
Explication des paramètres clés : configurez correctement pour éviter les pièges
Tableau de configuration des paramètres
| Paramètre | Valeur recommandée | Description | Exemple d'erreur |
|---|---|---|---|
model |
"kimi-k2.5" |
Identifiant du modèle | Ne pas utiliser kimi-k2 ou kimi-k2.5-thinking |
enable_thinking |
true |
Active le mode réflexion (exclusivité APIYI) | Sans ce paramètre, le contenu de raisonnement ne sera pas généré |
temperature |
1.0 |
Valeur fixe recommandée officiellement | Une valeur comme 0.7 peut rendre la qualité instable |
max_tokens |
≥ 16000 |
Garantit une sortie complète | Une valeur trop faible tronquera le processus de réflexion |
stream |
false (test initial) |
Supporte le mode flux ou non | Le mode flux nécessite un traitement spécifique du champ reasoning |
Explication de la structure de réponse API
{
"choices": [
{
"message": {
"role": "assistant",
"content": "Contenu de la réponse finale...",
"reasoning_content": "Processus de réflexion du modèle, incluant le raisonnement étape par étape..."
}
}
],
"usage": {
"prompt_tokens": 150,
"completion_tokens": 3200,
"total_tokens": 3350
}
}
Le champ reasoning_content contient l'intégralité de la chaîne de pensée. Il est généralement 3 à 5 fois plus long que le champ content et constitue la donnée essentielle pour comprendre le processus décisionnel du modèle.
🎯 Conseil pour le contrôle des coûts : En mode réflexion (thinking), la consommation de jetons est environ 2 à 4 fois supérieure au mode standard. Nous vous recommandons de passer par le service proxy API APIYI (apiyi.com) : le prix de groupe à 0,88 permet de réduire considérablement les coûts d'inférence, et tout rechargement de 100 $ vous offre 10 $ de crédit supplémentaire.

APIYI vs Site officiel : Comparaison des prix et de la stabilité
Vue d'ensemble de la comparaison des plateformes
| Dimension de comparaison | APIYI (apiyi.com) | API officielle Kimi | Autres services proxy API |
|---|---|---|---|
| Niveau de prix | 20% moins cher que le site officiel (tarif groupe 0,88) | Tarification officielle | Variable |
| Stabilité | Niveau de transfert officiel Alibaba Cloud | Connexion directe, sujette aux limites de débit | Incertaine |
| Offres de recharge | 100 $ rechargés = 10 $ offerts | Aucune offre fixe | Variable |
| Compatibilité API | Format OpenAI, 100% compatible | Nécessite le SDK Kimi | Majoritairement compatible |
| Support multi-modèles | 100+ modèles populaires | Uniquement la série Kimi | Limité |
| Support entreprise | Service client dédié + factures | Support standard | Limité |
Exemple de calcul de l'avantage tarifaire d'APIYI
Prenons l'exemple d'une utilisation mensuelle de 1 000 appels au mode kimi-k2.5 thinking (moyenne de 3 000 tokens en entrée + 5 000 tokens en sortie par appel) :
Coût des tokens en entrée :
Prix officiel env. 0,60 $/1M → 1000 appels × 3000 tokens = 3M tokens → 1,80 $
Tarif groupe APIYI (0,88) → env. 1,58 $
Coût des tokens en sortie (incluant le raisonnement) :
Prix officiel env. 2,50 $/1M → 1000 appels × 5000 tokens = 5M tokens → 12,50 $
Tarif groupe APIYI (0,88) → env. 11,00 $
Économies mensuelles : env. 1,72 $ + bonus de recharge couvrant environ 10 % de coût supplémentaire
💡 Économie réelle : La réduction de "plus de 20%" chez APIYI provient de deux facteurs cumulés : la remise sur le tarif de groupe (0,88) et le bonus de recharge (100 $ rechargés = 10 $ offerts, soit 10 % de budget supplémentaire). Le coût global réel représente environ 79 à 80 % du prix officiel.
Meilleurs cas d'usage pour le mode Kimi K2.5 Thinking
Scénarios recommandés pour activer le mode Thinking
1. Raisonnement mathématique complexe
# Adapté au mode thinking
prompt = "Veuillez démontrer le dernier théorème de Fermat pour le cas n=3, en détaillant chaque étape"
2. Débogage et optimisation de code
# Adapté au mode thinking
prompt = """
Le code suivant contient un bug de concurrence caché, veuillez l'identifier et le corriger :
[Coller ici le code multi-thread complexe]
"""
3. Analyse logique en plusieurs étapes
# Adapté au mode thinking
prompt = "Analysez les failles logiques de ce business plan et classez-les par ordre de priorité"
4. Déduction scientifique
# Adapté au mode thinking
prompt = "Dérivez la formule des niveaux d'énergie de l'atome d'hydrogène à partir des principes fondamentaux de la mécanique quantique"
Scénarios où le mode Thinking n'est pas nécessaire
# Pour les cas suivants, utilisez le mode normal (ne pas activer enable_thinking)
# pour économiser 50 à 70 % sur les coûts de tokens
# Questions-réponses simples
"Quel temps fait-il aujourd'hui ?" # Pas besoin de raisonnement
# Traduction de texte
"Traduisez le contenu suivant en anglais : ..." # Pas besoin de raisonnement
# Formatage de sortie
"Formatez les données JSON suivantes pour un affichage lisible" # Pas besoin de raisonnement
# Rédaction créative
"Écrivez un poème sur le printemps" # Pas besoin de raisonnement approfondi
🎯 Conseil d'utilisation : Nous vous recommandons de basculer dynamiquement entre les modes en fonction de la complexité de la tâche. En passant par APIYI (apiyi.com), vous pouvez utiliser la même clé API pour invoquer de manière flexible le modèle kimi-k2.5 (mode thinking) ainsi que d'autres modèles plus légers, en les combinant selon vos besoins.
Streaming : gérer les réponses en temps réel en mode Thinking
Lorsque vous utilisez le streaming en mode Thinking, vous devez traiter spécifiquement les fragments incrémentaux de reasoning_content :
from openai import OpenAI
client = OpenAI(
api_key="sk-votre_CLE_API",
base_url="https://api.apiyi.com/v1"
)
# Exemple d'invocation en streaming
stream = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "user", "content": "Veuillez analyser la complexité temporelle dans le pire des cas de l'algorithme de tri rapide (quicksort)"}
],
extra_body={"enable_thinking": True},
temperature=1.0,
max_tokens=16000,
stream=True
)
thinking_buffer = []
answer_buffer = []
is_thinking = True
for chunk in stream:
delta = chunk.choices[0].delta
# Traitement du flux de réflexion
if hasattr(delta, 'reasoning_content') and delta.reasoning_content:
thinking_buffer.append(delta.reasoning_content)
print(delta.reasoning_content, end='', flush=True)
# Traitement du flux de réponse finale
elif delta.content:
if is_thinking:
print("\n\n=== Réponse finale ===\n")
is_thinking = False
answer_buffer.append(delta.content)
print(delta.content, end='', flush=True)
print() # Saut de ligne
💡 Points clés du streaming :
reasoning_contentetcontentsont des champs indépendants lors du streaming. Généralement, lereasoning_contentest transmis intégralement avant lecontent. Il est nécessaire d'écouter les données incrémentales de ces deux champs séparément.
FAQ – Questions fréquentes
Q1 : Je ne vois pas de champ reasoning_content après l'invocation, le mode Thinking n'est pas activé ?
R : Veuillez vérifier les trois points suivants :
- Avez-vous correctement transmis le paramètre
"enable_thinking": true? max_tokensest-il réglé sur 16 000 ou plus ?- Lors de l'utilisation du SDK Python, avez-vous bien passé le paramètre via
extra_body={"enable_thinking": True}?
Nous vous conseillons de tester d'abord avec curl pour confirmer que le format des paramètres est correct avant de l'intégrer dans votre code. Le service client d'APIYI sur apiyi.com peut vous fournir une assistance technique.
Q2 : La consommation de jetons est trop élevée en mode Thinking, comment contrôler les coûts ?
R : Vous pouvez optimiser selon les axes suivants :
- Désactivez le mode Thinking pour les tâches simples (ne pas transmettre le paramètre
enable_thinking). - Réduisez légèrement
max_tokens(minimum 8 000, attention toutefois aux risques de troncature sur les raisonnements complexes). - Segmentez vos tâches : utilisez kimi-k2.5 thinking pour les raisonnements complexes et des modèles légers comme gpt-4o-mini pour les tâches simples.
- Réduisez les coûts de base grâce aux tarifs de groupe proposés par APIYI (0,88) sur apiyi.com.
Q3 : La température doit-elle obligatoirement être réglée sur 1.0 ?
R : Il est fortement recommandé par l'éditeur de la régler sur 1.0 ; c'est la température optimale pour le mode Thinking de kimi-k2.5. Une valeur trop basse (ex: 0,7) rendra le modèle trop conservateur lors du raisonnement, dégradant la qualité. Une valeur trop élevée (ex: 1,5) peut entraîner des chaînes de raisonnement incohérentes. Utiliser 1.0 est le choix le plus sûr.
Q4 : Le modèle kimi-k2.5 d'APIYI est-il identique à la version officielle ?
R : Oui. APIYI utilise les liens de transfert officiels d'Alibaba Cloud. Les poids et les capacités du modèle sont strictement identiques à ceux de Kimi. La seule différence réside dans la manière de transmettre les paramètres : le mode Thinking est activé par défaut chez l'éditeur, alors qu'il doit être activé manuellement avec enable_thinking: true via APIYI. Il s'agit d'une différence standard pour un service proxy API, qui n'affecte en rien la qualité de sortie du modèle.
Résumé : Points clés du mode Thinking de Kimi K2.5
| Point clé | Description |
|---|---|
| Paramètres d'activation | Doit inclure "enable_thinking": true |
| Réglage de la température | Utiliser impérativement temperature: 1.0 |
| Budget de jetons | max_tokens ≥ 16000 |
| Champs de réponse | Le raisonnement se trouve dans reasoning_content, la réponse dans content |
| URL d'accès | https://api.apiyi.com/v1 (compatible OpenAI) |
| Offre tarifaire | 20 % moins cher que le site officiel, +10 $ offerts pour 100 $ rechargés |
Kimi K2.5 affiche des performances remarquables sur les benchmarks clés comme le raisonnement mathématique AIME (96,1 %) et la génération de code (SWE-Bench 76,8 %). Le mode de réflexion est particulièrement adapté aux tâches complexes nécessitant un raisonnement en plusieurs étapes.
🎯 Testez dès maintenant : Rendez-vous sur le site officiel d'APIYI, apiyi.com, créez votre compte pour obtenir une clé API et intégrez le mode thinking de kimi-k2.5 en moins de 5 minutes. Profitez de 10 $ offerts pour tout rechargement de 100 $ ; cumulé aux remises par groupe, le coût global est inférieur à 80 % du tarif officiel de Kimi.
Article rédigé par l'équipe technique d'APIYI | Sources des données : Documentation officielle de Moonshot AI et rapport d'évaluation d'Artificial Analysis (janvier 2026)
Pour toute assistance technique, veuillez consulter le centre d'aide d'APIYI : help.apiyi.com