Gemini 3.1 Pro Preview 新增了 medium 思考等级,这是与前代 Gemini 3 Pro 最大的区别之一。现在你可以在 low、medium、high 三个等级间精确控制模型的推理深度,而 high 模式更是激活了 Deep Think Mini 能力。
核心价值: 读完本文,你将掌握 thinkingLevel 参数的完整配置方法,学会在质量、速度和成本之间找到最优平衡。

Gemini 3.1 Pro 思考等级完整支持矩阵
先看全局: 不同 Gemini 模型支持的思考等级不同。
| 思考等级 | Gemini 3.1 Pro | Gemini 3 Pro | Gemini 3 Flash | 说明 |
|---|---|---|---|---|
| minimal | ❌ 不支持 | ❌ 不支持 | ✅ 支持 | 接近关闭思考,仅 Flash 支持 |
| low | ✅ 支持 | ✅ 支持 | ✅ 支持 | 快速响应,最低成本 |
| medium | ✅ 新增支持 | ❌ 不支持 | ✅ 支持 | 平衡推理,3.1 Pro 的核心升级 |
| high | ✅ 支持 (默认) | ✅ 支持 (默认) | ✅ 支持 (默认) | 最深推理,激活 Deep Think Mini |
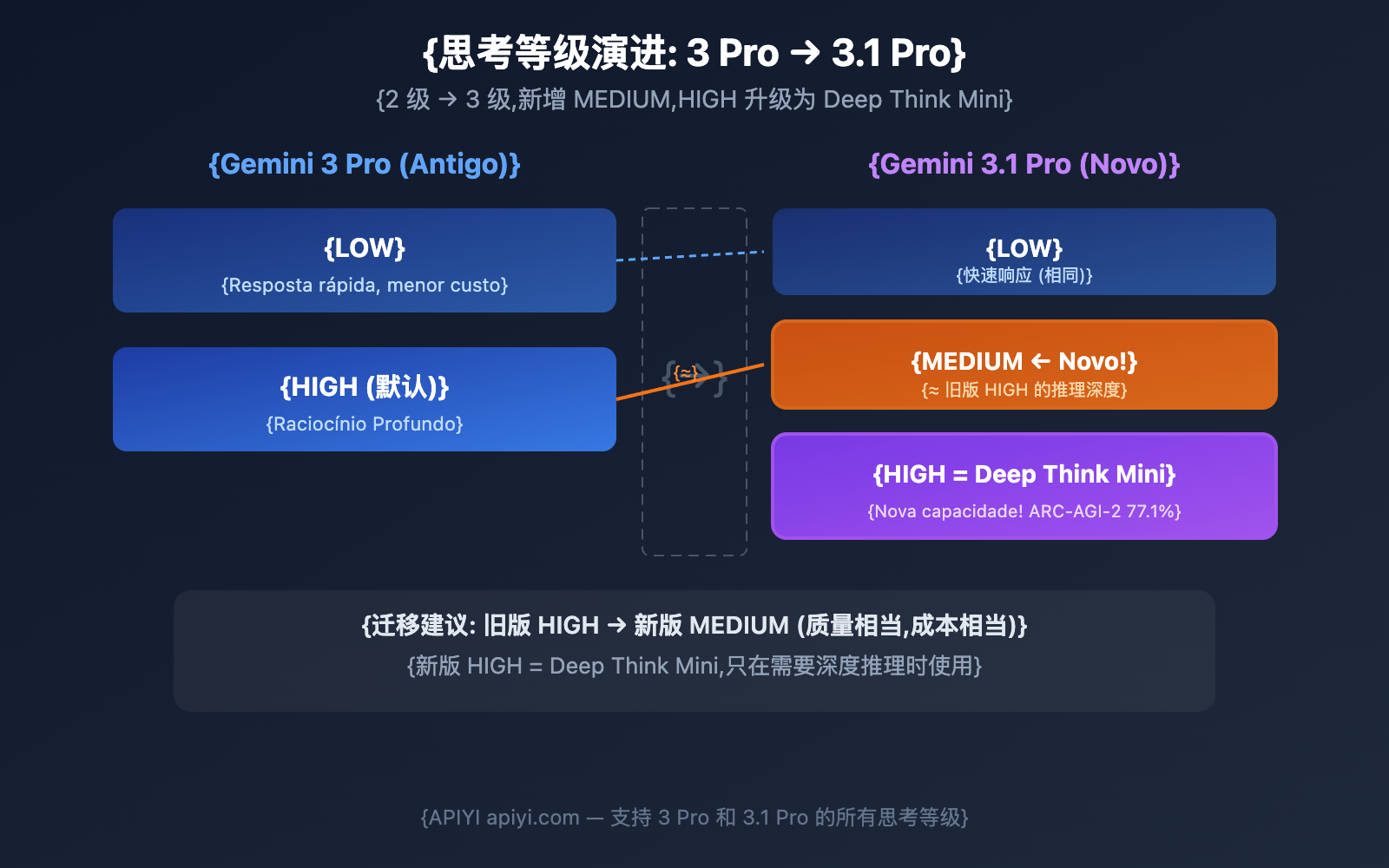
关键变化: 3 Pro → 3.1 Pro 的思考等级升级
| 对比 | Gemini 3 Pro | Gemini 3.1 Pro |
|---|---|---|
| 可用等级 | low, high (仅 2 级) | low, medium, high (3 级) |
| 默认等级 | high | high |
| high 模式含义 | 深度推理 | Deep Think Mini (更强) |
| 能否关闭思考 | 不能 | 不能 |
核心理解: Gemini 3 Pro 的 high 推理深度 ≈ Gemini 3.1 Pro 的 medium。而 3.1 Pro 的 high 是全新的 Deep Think Mini,推理深度远超上代。
🎯 迁移建议: 如果你之前用 Gemini 3 Pro 的 high 模式,切换到 3.1 Pro 后建议先用 medium (保持类似的质量和成本),只在需要深度推理时开启 high。APIYI apiyi.com 同时支持所有 Gemini 模型和思考等级。
Como configurar os níveis de pensamento do Gemini 3.1 Pro via API
Chamada via APIYI (Formato compatível com OpenAI)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unificada da APIYI
)
# Modo LOW: Resposta rápida
response_low = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "Traduza este texto em inglês para o português: Hello World"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 1024}
}
)
# Modo MEDIUM: Raciocínio equilibrado (Novo!)
response_med = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "Revise este código em busca de riscos de vazamento de memória"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 8192}
}
)
# Modo HIGH: Deep Think Mini
response_high = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "Prove: Para todo número inteiro positivo n, n^3-n é divisível por 6"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 32768}
}
)
Chamada nativa via Google SDK
from google import genai
from google.genai import types
client = genai.Client()
# Usando o parâmetro thinkingLevel
response = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents="Seu comando",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level="MEDIUM" # "LOW" / "MEDIUM" / "HIGH"
)
),
)
# Verificar o consumo de tokens de pensamento
print(f"Tokens de pensamento: {response.usage_metadata.thoughts_token_count}")
print(f"Tokens de saída: {response.usage_metadata.candidates_token_count}")
Chamada via REST API
POST https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent
{
"contents": [{"parts": [{"text": "Seu comando"}]}],
"generationConfig": {
"thinkingConfig": {
"thinkingLevel": "MEDIUM"
}
}
}
⚠️ Lembrete importante:
thinkingLevelethinkingBudgetnão podem ser usados simultaneamente, caso contrário, retornará um erro 400. Para modelos Gemini 3+, recomenda-se o uso dethinkingLevel; para modelos Gemini 2.5, usethinkingBudget.
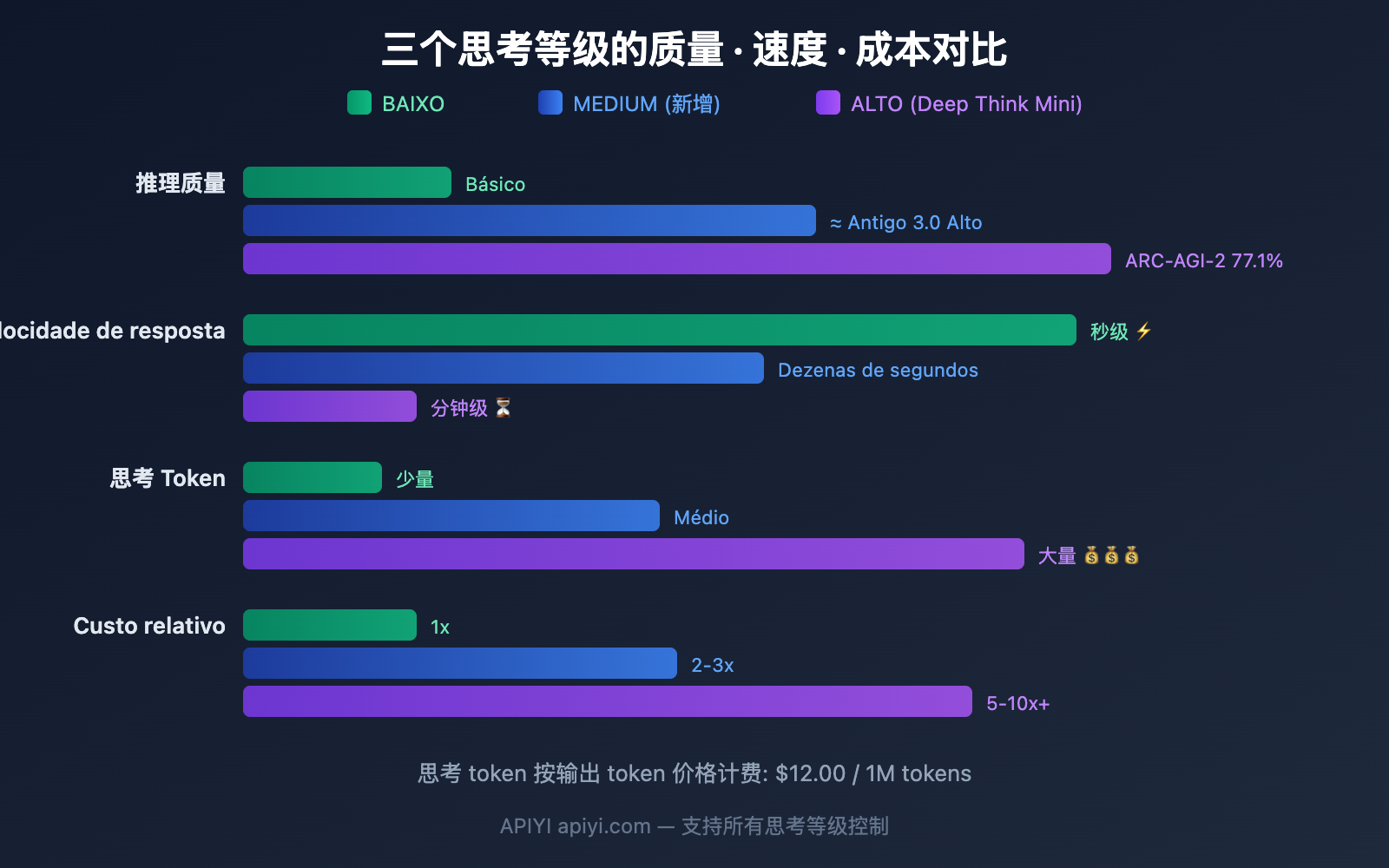
Comparação detalhada dos 3 níveis de pensamento do Gemini 3.1 Pro
LOW: O mais rápido e barato
| Dimensão | Detalhes |
|---|---|
| Profundidade de raciocínio | Mínimo de tokens de pensamento, ainda assim superior a modelos sem raciocínio |
| Velocidade de resposta | Segundos (o mais rápido) |
| Custo | Mínimo (poucos tokens de pensamento → poucos tokens de saída → custo baixo) |
| Cenários de uso | Autocompletar, classificação, extração de dados estruturados, traduções simples, resumos |
| Não indicado para | Raciocínio complexo, provas matemáticas, depuração em várias etapas |
MEDIUM: A escolha equilibrada (Novo)
| Dimensão | Detalhes |
|---|---|
| Profundidade de raciocínio | Tokens de pensamento médios, ≈ nível "high" do antigo 3.0 Pro |
| Velocidade de resposta | Latência média |
| Custo | Médio |
| Cenários de uso | Revisão de código, análise de documentos, programação diária, chamadas de API padrão, perguntas e respostas |
| Não indicado para | Matemática nível IMO, raciocínio de múltiplas etapas extremamente complexo |
HIGH: Deep Think Mini (Padrão)
| Dimensão | Detalhes |
|---|---|
| Profundidade de raciocínio | Raciocínio maximizado, ativa as capacidades do Deep Think Mini |
| Velocidade de resposta | Pode levar vários minutos (questões da IMO ~8 minutos) |
| Custo | Máximo (grande volume de tokens de pensamento cobrados ao preço de saída) |
| Cenários de uso | Depuração complexa, design de algoritmos, provas matemáticas, tarefas de pesquisa, fluxos de trabalho de agentes |
| Capacidade especial | Assinaturas de pensamento (thought signatures) mantêm a continuidade do raciocínio entre chamadas de API |
Regras de Tarifação de Tokens de Pensamento do Gemini 3.1 Pro
Entender a cobrança é fundamental para escolher o nível de pensamento (thinking level) ideal para o seu projeto.
Princípios Centrais de Tarifação
| Item de Cobrança | Descrição |
|---|---|
| Os tokens de pensamento são cobrados? | Sim, são tarifados pelo mesmo preço dos tokens de saída (output tokens). |
| Preço do token de saída | $12.00 / 1M de tokens (incluindo tokens de pensamento). |
| Base de cálculo | Cobrado pela cadeia de raciocínio interna completa, não apenas pelo resumo final. |
| Resumo do pensamento | A API retorna apenas um resumo do pensamento, mas a cobrança incide sobre o total de tokens gerados internamente. |
Explicação oficial do Google:
"Modelos de pensamento geram pensamentos completos para melhorar a qualidade da resposta final e, em seguida, emitem resumos para fornecer insights sobre o processo de pensamento. O preço é baseado nos tokens de pensamento completos que o modelo precisa gerar para criar um resumo, apesar de apenas o resumo ser retornado pela API."
Estimativa de Custo para os Três Níveis
| Nível | Tokens de Pensamento Estimados | Para 1.000 chamadas | Tendência de Custo Mensal |
|---|---|---|---|
| LOW | ~500-2K / vez | $6-24 | Mínimo |
| MEDIUM | ~2K-8K / vez | $24-96 | Médio |
| HIGH | ~8K-32K+ / vez | $96-384+ | Mais alto, aumenta em tarefas complexas |
💰 Otimização de Custos: Nem toda requisição precisa do nível HIGH. Definir 80% das tarefas diárias como LOW ou MEDIUM e apenas 20% das tarefas complexas como HIGH pode reduzir seus gastos com API em 50-70%. Você pode configurar isso de forma flexível através da plataforma APIYI (apiyi.com).
Guia de Correspondência: Tipos de Tarefa vs. Nível de Pensamento do Gemini 3.1 Pro
Recomendações por Cenário Detalhado
| Tipo de Tarefa | Nível Recomendado | Motivo | Expectativa de Latência |
|---|---|---|---|
| Tradução simples | LOW | Não requer raciocínio complexo | < 5 segundos |
| Classificação de texto | LOW | Tarefa de correspondência de padrões | < 5 segundos |
| Extração de resumo | LOW | Compressão de informação, não raciocínio | < 10 segundos |
| Autocompletar | LOW | Sensível à latência | < 3 segundos |
| Revisão de código | MEDIUM | Requer análise moderada | 10-30 segundos |
| Q&A de documentos | MEDIUM | Compreensão + Resposta | 10-30 segundos |
| Codificação rotineira | MEDIUM | Geração de código comum | 15-40 segundos |
| Análise de Bug | MEDIUM | Raciocínio de complexidade média | 20-40 segundos |
| Depuração complexa | HIGH | Cadeia de raciocínio de múltiplas etapas | 1-5 minutos |
| Prova matemática | HIGH | Deep Think Mini | 3-8 minutos |
| Design de algoritmos | HIGH | Raciocínio profundo | 2-5 minutos |
| Análise de pesquisa | HIGH | Análise profunda multidimensional | 2-5 minutos |
| Workflow de Agentes | HIGH | Mantém a continuidade da assinatura de pensamento | Depende da tarefa |
Seleção Dinâmica de Nível: Código de Exemplo (Best Practice)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unificada APIYI
)
# Configuração de pensamento baseada no tipo de tarefa
THINKING_CONFIG = {
"simple": {"type": "enabled", "budget_tokens": 1024}, # LOW
"medium": {"type": "enabled", "budget_tokens": 8192}, # MEDIUM
"complex": {"type": "enabled", "budget_tokens": 32768}, # HIGH
}
def smart_think(prompt, complexity="medium"):
"""Define o nível de pensamento automaticamente com base na complexidade da tarefa"""
return client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking": THINKING_CONFIG[complexity]}
)
# Tradução simples → LOW
resp1 = smart_think("Traduza: Good morning", "simple")
# Revisão de código → MEDIUM
resp2 = smart_think("Revise a segurança deste código: ...", "medium")
# Prova matemática → HIGH (Deep Think Mini)
resp3 = smart_think("Prove um caso especial da Hipótese de Riemann", "complex")
Gemini 3.1 Pro vs 3 Pro: Comparativo da Evolução dos Níveis de Pensamento
O que torna o Deep Think Mini tão forte?
O Deep Think Mini, ativado pelo modo HIGH do Gemini 3.1 Pro, é o grande destaque desta atualização.
O que é o Deep Think Mini
O Deep Think Mini não é um modelo independente, mas sim um modo de raciocínio especial do Gemini 3.1 Pro sob o nível de pensamento HIGH. O Google o descreve como uma "versão mini do Gemini Deep Think" — o Deep Think é o modelo de raciocínio pesado dedicado do Google (com pontuação de 84,6% no ARC-AGI-2).
Desempenho real do Deep Think Mini
| Item de Teste | Deep Think Mini (3.1 Pro HIGH) | Gemini 3 Pro HIGH | Aumento |
|---|---|---|---|
| ARC-AGI-2 | 77.1% | 31.1% | +148% |
| Problemas de Matemática IMO | Resolvido em ~8 min | Não resolvido | De impossível para possível |
| Tarefas de planejamento complexas | Aumento de 40-60% no benchmark | Comparado ao Gemini 2.5 Pro | Aumento significativo |
Assinaturas de Pensamento (Thought Signatures)
O Deep Think Mini introduz uma tecnologia exclusiva: assinaturas de pensamento (thought signatures). Trata-se de uma representação criptografada e inviolável dos estados intermediários de raciocínio.
Em fluxos de trabalho de Agentes, o raciocínio do modelo geralmente abrange várias chamadas de API. As assinaturas de pensamento podem passar o contexto de raciocínio da chamada anterior para a próxima, mantendo a continuidade do raciocínio. Isso é crucial para tarefas de Agentes em múltiplas etapas.
Quais tarefas valem o uso do Deep Think Mini?
| Vale usar HIGH (Deep Think Mini) | Não vale usar HIGH |
|---|---|
| Raciocínio de nível de competição matemática | Operações aritméticas simples |
| Depuração de bugs complexos em vários arquivos | Correção de erros de sintaxe |
| Design e otimização de algoritmos | Geração de código CRUD |
| Análise de metodologia de artigos acadêmicos | Resumo de artigos |
| Tarefas longas de Agentes multi-etapas | Perguntas e respostas de turno único |
| Análise profunda de vulnerabilidades de segurança | Conversão de formato |
💡 Sugestão prática: O poder do Deep Think Mini tem um preço — a latência e o custo são elevados. Recomenda-se usar o HIGH apenas em tarefas que realmente exijam "pensamento profundo"; para tarefas do dia a dia, o MEDIUM é suficiente. Através do APIYI (apiyi.com), você pode alternar de forma flexível em cada requisição.
thinkingLevel vs thinkingBudget: Não confunda
A Google possui dois parâmetros para controlar o "pensamento" (raciocínio), aplicáveis a diferentes séries de modelos:
| Parâmetro | Modelos compatíveis | Tipo de valor | Descrição |
|---|---|---|---|
| thinkingLevel | Gemini 3+ (3 Flash, 3 Pro, 3.1 Pro) | Enumeração: MINIMAL/LOW/MEDIUM/HIGH | Recomendado para a série Gemini 3 |
| thinkingBudget | Gemini 2.5 (Pro, Flash, Flash Lite) | Inteiro: 0-32768 | Aplicável à série 2.5 |
⚠️ Os dois parâmetros não podem ser usados simultaneamente! Enviar ambos na mesma requisição retornará um erro 400.
| Cenário | Forma correta | Forma incorreta |
|---|---|---|
| Chamar o Gemini 3.1 Pro | Use thinkingLevel: "MEDIUM" |
Use thinkingBudget: 8192 |
| Chamar o Gemini 2.5 Pro | Use thinkingBudget: 8192 |
Use thinkingLevel: "MEDIUM" |
| Passar ambos os parâmetros | — | Erro 400 ❌ |
🎯 Dica para memorizar: Série Gemini 3 → thinkingLevel (níveis em texto/string), Série Gemini 2.5 → thinkingBudget (número de tokens em formato numérico). O APIYI (apiyi.com) suporta ambos os formatos de parâmetros.
Perguntas Frequentes
Q1: Qual é o nível padrão se eu não configurar o thinkingLevel?
O padrão é HIGH. Isso significa que, se você não definir ativamente, cada chamada usará toda a capacidade de raciocínio do Deep Think Mini, consumindo o máximo de tokens de pensamento. Recomenda-se ajustar o nível conforme a necessidade real da tarefa para economizar custos. Através do APIYI (apiyi.com), você pode controlar isso de forma flexível em cada requisição.
Q2: Como os tokens de pensamento são cobrados? É caro?
Os tokens de pensamento são cobrados pelo mesmo preço dos tokens de saída (output tokens), cerca de US$ 12,00 por 1 milhão de tokens. No modo HIGH, uma requisição complexa pode consumir mais de 30 mil tokens de pensamento, custando aproximadamente US$ 0,36. Já no modo LOW, a mesma requisição pode consumir apenas 1.000 tokens, custando cerca de US$ 0,012. A diferença pode chegar a 30 vezes.
Q3: O nível MEDIUM do 3.1 Pro é o mesmo que o HIGH do 3.0 Pro?
Basicamente, sim. A descrição da Google é que o MEDIUM do 3.1 Pro oferece um "pensamento equilibrado, adequado para a maioria das tarefas", o que coincide com o posicionamento do HIGH no 3.0 Pro. Se você estiver migrando do 3.0 Pro para o 3.1 Pro, mudar de HIGH para MEDIUM deve manter uma qualidade e custo semelhantes. No APIYI (apiyi.com), você pode chamar as duas versões simultaneamente para comparar os resultados.
Q4: É possível desativar a função de pensamento?
No Gemini 3.1 Pro, não é possível desativar o pensamento completamente. O nível mais baixo é o LOW, que ainda realiza um raciocínio básico. Se você precisar de uma resposta totalmente sem pensamento, considere usar o modo MINIMAL do Gemini 3 Flash.
Mitos comuns sobre os níveis de pensamento do Gemini 3.1 Pro
| Mito | Fato |
|---|---|
| "O nível HIGH tem a melhor qualidade de resposta, devo usá-lo sempre" | A qualidade do HIGH em tarefas simples é próxima à do MEDIUM, mas o custo é 5 a 10 vezes maior |
| "O nível LOW tem uma capacidade de raciocínio ruim" | O LOW ainda é superior a modelos que não pensam, apenas utiliza menos tokens de pensamento |
| "O MEDIUM é um recurso novo e pode ser instável" | A profundidade de raciocínio do MEDIUM é ≈ ao HIGH da versão anterior 3.0 Pro, e já foi amplamente validado |
| "Os tokens de pensamento não são cobrados" | São cobrados! São faturados pelo mesmo preço dos tokens de saída ($12/MTok) |
| "Posso desativar o pensamento no 3.1 Pro" | Não, o mínimo que você pode configurar é LOW, que ainda mantém um raciocínio básico |
"Posso usar thinkingLevel e thinkingBudget juntos" |
Não! Usá-los simultaneamente retornará um erro 400 |
| "Configurar um nível alto aumenta a latência, mas o resultado vem de uma vez" | O modo HIGH pode levar vários minutos para começar a responder, não é apenas um pequeno atraso |
Resumo: Guia rápido de escolha dos níveis de pensamento do Gemini 3.1 Pro
| Nível | Em uma frase | Cenários de uso | Custo relativo |
|---|---|---|---|
| LOW | O mais rápido e barato | Tradução, classificação, resumo, preenchimento | 1x |
| MEDIUM | Escolha equilibrada (Novo) | Programação, revisão, análise, Q&A | 2-3x |
| HIGH | Deep Think Mini | Matemática, depuração, pesquisa, Agentes | 5-10x+ |
Principais recomendações:
- Use MEDIUM para o desenvolvimento diário — Boa qualidade, custo razoável, equivalente ao antigo HIGH.
- Use LOW para tarefas simples — Economize mais de 70% nos custos de tokens de pensamento.
- Use HIGH para raciocínio profundo — A capacidade do Deep Think Mini é única, mas fique atento ao custo.
- O padrão é HIGH — Se não configurar, usará o modo mais caro; lembre-se de ajustar manualmente.
Recomendamos usar a plataforma APIYI (apiyi.com) para alternar dinamicamente entre os níveis de pensamento conforme o tipo de tarefa, alcançando o melhor equilíbrio entre qualidade e custo.
Referências
-
Documentação do Google AI: Guia de configuração de pensamento do Gemini
- Link:
ai.google.dev/gemini-api/docs/thinking - Descrição: Documentação completa do parâmetro
thinkingLevel.
- Link:
-
Documentação do Google AI: Página do modelo Gemini 3.1 Pro
- Link:
ai.google.dev/gemini-api/docs/models/gemini-3.1-pro-preview - Descrição: Matriz de suporte de níveis de pensamento e observações importantes.
- Link:
-
Página de preços da API do Gemini: Explicação sobre a cobrança de tokens de pensamento
- Link:
ai.google.dev/gemini-api/docs/pricing - Descrição: Os tokens de pensamento são cobrados com base no preço dos tokens de saída.
- Link:
-
VentureBeat: Experiência profunda com o Deep Think Mini
- Link:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Descrição: Dados de testes reais mostrando a resolução de um problema da IMO em 8 minutos.
- Link:
-
Blog oficial do Google: Anúncio de lançamento do Gemini 3.1 Pro
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Descrição: Apresentação oficial do sistema de pensamento de três níveis e do Deep Think Mini.
- Link:
📝 Autor: Equipe APIYI | Para troca de conhecimentos técnicos, visite APIYI em apiyi.com
📅 Data de atualização: 20 de fevereiro de 2026
🏷️ Palavras-chave: Níveis de pensamento do Gemini 3.1 Pro, thinkingLevel, Deep Think Mini, LOW MEDIUM HIGH, chamada de API, controle de raciocínio