Ao chamar os modelos Gemini 3.0 Pro Preview ou gemini-3-flash-preview, você encontrou o erro thinking_budget and thinking_level are not supported together? Este é um problema de compatibilidade causado pela atualização de parâmetros da API do Google Gemini entre diferentes versões do modelo. Neste artigo, vamos analisar sistematicamente a causa raiz desse erro sob a perspectiva da evolução do design da API e como configurá-lo corretamente.
Valor Central: Ao terminar de ler, você dominará a configuração correta dos parâmetros do modo de pensamento para os modelos Gemini 2.5 e 3.0, evitando erros comuns de chamada de API e otimizando o desempenho de inferência e o controle de custos.

Pontos Principais da Evolução dos Parâmetros da API Gemini
| Versão do Modelo | Parâmetro Recomendado | Tipo de Parâmetro | Exemplo de Configuração | Cenário de Uso |
|---|---|---|---|---|
| Gemini 2.5 Flash/Flash-Lite | thinking_budget |
Inteiro ou -1 | thinking_budget: 0 (desativado)thinking_budget: -1 (dinâmico) |
Controle preciso do orçamento de tokens de pensamento |
| Gemini 3.0 Pro/Flash | thinking_level |
Valor enumerado | thinking_level: "minimal"/"low"/"medium"/"high" |
Configuração simplificada por níveis de cenário |
| Nota de Compatibilidade | ⚠️ Incompatíveis | – | Passar ambos os parâmetros acionará um erro 400 | Escolha um com base na versão do modelo |
Diferenças Fundamentais nos Parâmetros do Modo de Pensamento do Gemini
O principal motivo para o Google introduzir o parâmetro thinking_level no Gemini 3.0 é simplificar a experiência de configuração para o desenvolvedor. Enquanto o thinking_budget do Gemini 2.5 exigia que os desenvolvedores estimassem com precisão a quantidade de tokens de pensamento, o thinking_level do Gemini 3.0 abstrai essa complexidade em 4 níveis semânticos, reduzindo a barreira de entrada para configuração.
Essa mudança de design reflete o equilíbrio que o Google busca na evolução da API: sacrificar um pouco da capacidade de controle refinado em troca de melhor usabilidade e consistência entre modelos. Para a maioria dos cenários de aplicação, a abstração do thinking_level é suficiente; o thinking_budget só é necessário quando houver necessidade de otimização extrema de custos ou controle específico de orçamento de tokens.
💡 Dica Técnica: No desenvolvimento real, recomendamos realizar testes de chamada de interface através da plataforma APIYI (apiyi.com). Esta plataforma oferece uma interface de API unificada e suporta modelos como Gemini 2.5 Flash, Gemini 3.0 Pro e Gemini 3.0 Flash, o que ajuda a validar rapidamente os efeitos reais e as diferenças de custo de diferentes configurações de modo de pensamento.
Causa Raiz do Erro: Estratégia de Compatibilidade de Parâmetros
Análise da Mensagem de Erro da API
{
"status_code": 400,
"error": {
"message": "Unable to submit request because thinking_budget and thinking_level are not supported together.",
"type": "upstream_error",
"code": 400
}
}
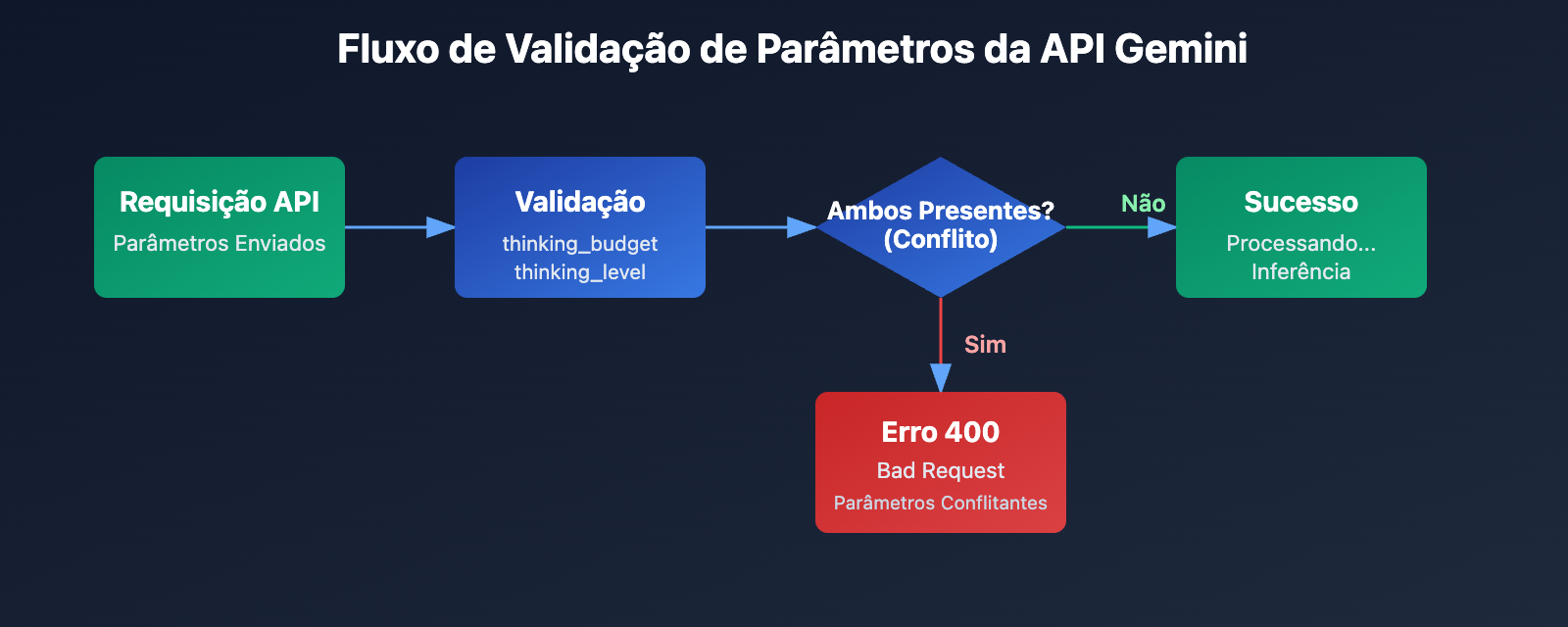
A informação central deste erro é que thinking_budget e thinking_level não podem existir simultaneamente. Ao introduzir novos parâmetros no Gemini 3.0, o Google não removeu completamente os antigos, mas adotou uma estratégia de exclusão mútua:
- Modelo Gemini 2.5: Aceita apenas
thinking_budgete ignora othinking_level. - Modelo Gemini 3.0: Prioriza o uso de
thinking_level, mas aceita othinking_budgetpara manter a retrocompatibilidade. No entanto, não permite o envio de ambos ao mesmo tempo. - Condição de Erro: Quando a requisição da API contém os parâmetros
thinking_budgetethinking_levelsimultaneamente.
Por que esse erro acontece?
Desenvolvedores geralmente encontram esse erro em um destes três cenários:
| Cenário | Causa | Características Típicas do Código |
|---|---|---|
| Cenário 1: Preenchimento Automático do SDK | Alguns frameworks de IA (como LiteLLM ou AG2) preenchem parâmetros automaticamente com base no nome do modelo, enviando os dois sem querer. | Uso de SDKs encapsulados sem verificar o corpo real da requisição. |
| Cenário 2: Configuração Hardcoded | O código possui o thinking_budget fixo e, ao mudar para o Gemini 3.0, o desenvolvedor esqueceu de atualizar ou remover o parâmetro antigo. |
Atribuição de ambos os parâmetros em arquivos de configuração ou direto no código. |
| Cenário 3: Erro no Alias do Modelo | Uso de codinomes como gemini-flash-preview que apontam para o Gemini 3.0, mas configurados com parâmetros do 2.5. |
Nomes de modelos contendo preview ou latest sem a atualização correspondente nos parâmetros. |
🎯 Dica de Especialista: Ao alternar versões do Gemini, recomendo testar a compatibilidade dos parâmetros na plataforma APIYI (apiyi.com). Lá você pode alternar rapidamente entre os modelos Gemini 2.5 e 3.0 para comparar a qualidade das respostas e a latência de cada configuração de pensamento, evitando conflitos em produção.
3 Soluções: Escolhendo o Parâmetro Certo para Cada Versão
Solução 1: Configuração para Gemini 2.5 (Usando thinking_budget)
Modelos Aplicáveis: gemini-2.5-flash, gemini-2.5-pro, etc.
Explicação dos Parâmetros:
thinking_budget: 0– Desativa completamente o modo de pensamento (menor latência e custo).thinking_budget: -1– Modo de pensamento dinâmico; o modelo ajusta conforme a complexidade.thinking_budget: <inteiro positivo>– Define um limite exato de tokens para o pensamento.
Exemplo Minimalista
import openai
client = openai.OpenAI(
api_key="SUA_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "Explique o princípio do emaranhamento quântico"}],
extra_body={
"thinking_budget": -1 # Modo de pensamento dinâmico
}
)
print(response.choices[0].message.content)
Ver código completo (incluindo extração de pensamento)
import openai
client = openai.OpenAI(
api_key="SUA_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "Explique o princípio do emaranhamento quântico"}],
extra_body={
"thinking_budget": -1, # Modo dinâmico
"include_thoughts": True # Ativa o retorno do resumo do pensamento
}
)
# Extrair o conteúdo do pensamento (se ativado)
for part in response.choices[0].message.content:
if hasattr(part, 'thought') and part.thought:
print(f"Processo de Pensamento: {part.text}")
# Extrair a resposta final
final_answer = response.choices[0].message.content
print(f"Resposta Final: {final_answer}")
Aviso: O modelo Gemini 2.5 será descontinuado em 3 de março de 2026. É recomendável migrar para a série Gemini 3.0 o quanto antes. Você pode usar a APIYI (apiyi.com) para comparar a qualidade antes e depois da migração.
Solução 2: Configuração para Gemini 3.0 (Usando thinking_level)
Modelos Aplicáveis: gemini-3.0-flash-preview, gemini-3.0-pro-preview
Explicação dos Parâmetros:
thinking_level: "minimal"– Pensamento mínimo, quase zero de orçamento (requer Thought Signatures).thinking_level: "low"– Pensamento de baixa intensidade, ideal para conversas simples.thinking_level: "medium"– Intensidade média, bom para tarefas de raciocínio geral (apenas no Flash 3.0).thinking_level: "high"– Intensidade máxima para problemas complexos (valor padrão).
Exemplo Minimalista
import openai
client = openai.OpenAI(
api_key="SUA_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "Analise a complexidade de tempo deste código"}],
extra_body={
"thinking_level": "medium" # Pensamento de intensidade média
}
)
print(response.choices[0].message.content)
Ver código completo (com passagem de Thought Signatures)
import openai
client = openai.OpenAI(
api_key="SUA_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Primeira rodada
response_1 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "Desenvolva um algoritmo de cache LRU"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# Extrair assinaturas de pensamento (retornadas automaticamente no 3.0)
thought_signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
thought_signatures.append(part.thought_signature)
# Segunda rodada, enviando a assinatura para manter a cadeia de raciocínio
response_2 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[
{"role": "user", "content": "Desenvolva um algoritmo de cache LRU"},
{"role": "assistant", "content": response_1.choices[0].message.content, "thought_signatures": thought_signatures},
{"role": "user", "content": "Otimize a complexidade de espaço desse algoritmo"}
],
extra_body={
"thinking_level": "high"
}
)
print(response_2.choices[0].message.content)
💰 Otimização de Custos: Para projetos com orçamento limitado, considere usar a API do Gemini 3.0 Flash via APIYI (apiyi.com), que oferece preços competitivos para desenvolvedores independentes. Usar
thinking_level: "low"ajuda a reduzir ainda mais os custos.
Solução 3: Estratégia de Adaptação Dinâmica de Parâmetros
Cenário: Quando seu código precisa suportar tanto o Gemini 2.5 quanto o 3.0 de forma transparente.
Função de Adaptação Inteligente
def get_thinking_config(model_name: str, complexity: str = "medium") -> dict:
"""
Seleciona automaticamente o parâmetro correto com base na versão do modelo.
Args:
model_name: Nome do modelo Gemini
complexity: Nível de complexidade ("minimal", "low", "medium", "high", "dynamic")
Returns:
Dicionário para ser usado no extra_body
"""
# Lista de modelos Gemini 3.0
gemini_3_models = [
"gemini-3.0-flash-preview",
"gemini-3.0-pro-preview",
"gemini-3-flash",
"gemini-3-pro"
]
# Lista de modelos Gemini 2.5
gemini_2_5_models = [
"gemini-2.5-flash-preview-04-17",
"gemini-2.5-flash-lite",
"gemini-2-flash",
"gemini-2-flash-lite"
]
# Identifica a versão do modelo
if any(m in model_name for m in gemini_3_models):
# Gemini 3.0 usa thinking_level
level_map = {
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high"
}
return {"thinking_level": level_map.get(complexity, "medium")}
elif any(m in model_name for m in gemini_2_5_models):
# Gemini 2.5 usa thinking_budget
budget_map = {
"minimal": 0,
"low": 512,
"medium": 2048,
"high": 8192,
"dynamic": -1
}
return {"thinking_budget": budget_map.get(complexity, -1)}
else:
# Modelo desconhecido, tenta o padrão do Gemini 3.0
return {"thinking_level": "medium"}
# Exemplo de uso
import openai
client = openai.OpenAI(
api_key="SUA_API_KEY",
base_url="https://api.apiyi.com/v1"
)
model = "gemini-3.0-flash-preview" # Pode ser alterado dinamicamente
thinking_config = get_thinking_config(model, complexity="high")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Sua pergunta aqui"}],
extra_body=thinking_config
)

| Nível de Pensamento | Gemini 2.5 (thinking_budget) | Gemini 3.0 (thinking_level) | Cenários Recomendados |
|---|---|---|---|
| Mínimo | 0 |
"minimal" |
Comandos simples, aplicações de alto volume |
| Baixo | 512 |
"low" |
Chatbots, perguntas e respostas leves |
| Médio | 2048 |
"medium" |
Raciocínio geral, geração de código |
| Alto | 8192 |
"high" |
Problemas complexos, análise profunda |
| Dinâmico | -1 |
"high" (Padrão) |
Adaptação automática de complexidade |
🚀 Comece agora: Para quem busca agilidade, a APIYI (apiyi.com) permite criar protótipos rapidamente. A plataforma oferece interface pronta para o Gemini API sem necessidade de configurações complexas, permitindo trocar os níveis de pensamento com um clique para comparar resultados em tempo real.
Detalhes do Mecanismo de Assinaturas de Pensamento (Thought Signatures) do Gemini 3.0
O que são as Assinaturas de Pensamento?
As Assinaturas de Pensamento (Thought Signatures) introduzidas pelo Gemini 3.0 são representações criptografadas do processo de raciocínio interno do modelo. Quando você ativa include_thoughts: true, o modelo retorna uma assinatura criptografada do processo de pensamento na resposta. Você pode passar essas assinaturas em diálogos subsequentes, permitindo que o modelo mantenha a continuidade da cadeia de raciocínio.
Principais características:
- Representação criptografada: O conteúdo da assinatura é ilegível, sendo decifrável apenas pelo próprio modelo.
- Manutenção da cadeia de raciocínio: Ao passar as assinaturas em conversas de vários turnos, o modelo pode continuar o raciocínio com base no que pensou anteriormente.
- Retorno obrigatório: O Gemini 3.0 retorna assinaturas de pensamento por padrão, mesmo que não sejam solicitadas.
Cenários de aplicação prática das Assinaturas de Pensamento
| Cenário | Precisa passar a assinatura? | Descrição |
|---|---|---|
| Pergunta única | ❌ Não | Pergunta isolada, sem necessidade de manter a cadeia de raciocínio. |
| Diálogo simples (vários turnos) | ❌ Não | O contexto é suficiente, sem dependências de raciocínio complexo. |
| Raciocínio complexo (vários turnos) | ✅ Sim | Exemplo: refatoração de código, provas matemáticas, análises de múltiplas etapas. |
| Modo de pensamento mínimo (minimal) | ✅ Obrigatório | O thinking_level: "minimal" exige a passagem da assinatura, caso contrário, retornará um erro 400. |
Exemplo de código para passar Assinaturas de Pensamento
import openai
client = openai.OpenAI(
api_key="SUA_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Rodada 1: Pedindo ao modelo para projetar um algoritmo
response_1 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[{"role": "user", "content": "Projete um algoritmo de limitação de taxa distribuído"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# Extraindo as assinaturas de pensamento
signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
signatures.append(part.thought_signature)
# Rodada 2: Continuando a otimização com base no raciocínio anterior
response_2 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[
{"role": "user", "content": "Projete um algoritmo de limitação de taxa distribuído"},
{
"role": "assistant",
"content": response_1.choices[0].message.content,
"thought_signatures": signatures # Passando as assinaturas de pensamento
},
{"role": "user", "content": "Como lidar com o problema de inconsistência de relógio distribuído?"}
],
extra_body={"thinking_level": "high"}
)
💡 Melhores Práticas: Em cenários que exigem raciocínio complexo em várias etapas (como design de sistemas, otimização de algoritmos ou revisão de código), recomendamos testar a diferença no efeito da passagem de assinaturas através da plataforma APIYI (apiyi.com). A plataforma suporta o mecanismo completo de Assinaturas de Pensamento do Gemini 3.0, facilitando a validação da qualidade do raciocínio em diferentes configurações.
Perguntas Frequentes
Q1: Por que o Gemini 2.5 Flash ainda retorna o conteúdo do pensamento após configurar thinking_budget=0?
Este é um bug conhecido. Na versão Gemini 2.5 Flash Preview 04-17, o thinking_budget=0 não é executado corretamente. O fórum oficial do Google já confirmou esse problema.
Soluções temporárias:
- Use
thinking_budget=1(valor mínimo) em vez de 0. - Atualize para o Gemini 3.0 Flash e use
thinking_level="minimal". - Filtre o conteúdo do pensamento no pós-processamento (se a API retornar o campo
thought).
Recomendamos migrar rapidamente para o modelo Gemini 3.0 Flash através da APIYI (apiyi.com). A plataforma suporta as versões mais recentes, permitindo evitar esse tipo de bug.
Q2: Como saber se estou usando o modelo Gemini 2.5 ou 3.0?
Método 1: Verificar o nome do modelo
- Gemini 2.x: O nome contém
2.5-flash,2-flash-lite. - Gemini 3.x: O nome contém
3.0-flash,3-pro,gemini-3-flash.
Método 2: Enviar uma requisição de teste
# Passar apenas o thinking_level e observar a resposta
response = client.chat.completions.create(
model="nome-do-seu-modelo",
messages=[{"role": "user", "content": "teste"}],
extra_body={"thinking_level": "low"}
)
# Se retornar erro 400 informando que não suporta thinking_level, trata-se do Gemini 2.5
Método 3: Verificar o cabeçalho (header) da resposta da API
Algumas implementações de API retornam o campo X-Model-Version no cabeçalho da resposta, permitindo identificar diretamente a versão do modelo.
Q3: Quantos tokens cada nível de thinking_level do Gemini 3.0 consome?
O Google não divulgou publicamente o orçamento exato de tokens para cada thinking_level, fornecendo apenas as seguintes diretrizes:
| thinking_level | Custo relativo | Latência relativa | Profundidade de raciocínio |
|---|---|---|---|
| minimal | Mínimo | Mínima | Quase nenhum pensamento |
| low | Baixo | Baixa | Raciocínio superficial |
| medium | Médio | Média | Raciocínio intermediário |
| high | Alto | Alta | Raciocínio profundo |
Sugestões práticas:
- Compare o consumo real de tokens de diferentes níveis através da plataforma APIYI (apiyi.com).
- Use o mesmo comando (prompt) para chamar low/medium/high e observe a diferença na tarifação.
- Escolha o nível adequado com base no cenário real do seu negócio (qualidade da resposta vs. custo).
Q4: Posso forçar o uso de thinking_budget no Gemini 3.0?
Pode, mas não é recomendado.
Para manter a compatibilidade com versões anteriores, o Gemini 3.0 ainda aceita o parâmetro thinking_budget, mas a documentação oficial afirma claramente:
"Embora o
thinking_budgetseja aceito para compatibilidade, usá-lo com o Gemini 3 Pro pode resultar em um desempenho abaixo do ideal."
Motivos:
- O mecanismo interno de raciocínio do Gemini 3.0 já foi otimizado para o
thinking_level. - Forçar o uso do
thinking_budgetpode ignorar as novas estratégias de raciocínio da versão 3.0. - Isso pode levar a uma queda na qualidade da resposta ou a um aumento na latência.
A forma correta:
- Migre para o parâmetro
thinking_level. - Consulte a função de adaptação de parâmetros mencionada no "Cenário 3" para selecionar dinamicamente o parâmetro correto.
Resumo
Pontos principais sobre os erros de thinking_budget e thinking_level na API do Gemini:
- Parâmetros mutuamente exclusivos: O Gemini 2.5 usa
thinking_budget, enquanto o Gemini 3.0 usathinking_level. Não é possível enviar ambos simultaneamente. - Identificação do modelo: Determine a versão pelo nome do modelo. A série 2.5 utiliza
thinking_budgete a série 3.0 utilizathinking_level. - Adaptação dinâmica: Utilize funções de adaptação de parâmetros para selecionar automaticamente o parâmetro correto conforme o nome do modelo, evitando "hardcoding".
- Assinatura de raciocínio: O Gemini 3.0 introduz o mecanismo de assinatura de raciocínio (thinking signature). Em diálogos complexos de várias rodadas, é necessário transmitir a assinatura para manter a integridade da cadeia de raciocínio.
- Sugestão de migração: O Gemini 2.5 será descontinuado em 3 de março de 2026. Recomendamos a migração para a série 3.0 o mais breve possível.
Recomendamos utilizar o APIYI (apiyi.com) para validar rapidamente os efeitos práticos das diferentes configurações do modo de raciocínio. A plataforma oferece suporte a toda a família de modelos Gemini, com uma interface unificada e modelos de cobrança flexíveis, sendo ideal para testes comparativos rápidos e implementações em produção.
Autor: Equipe Técnica APIYI | Para dúvidas técnicas, acesse APIYI (apiyi.com) e confira mais soluções de integração para modelos de IA.