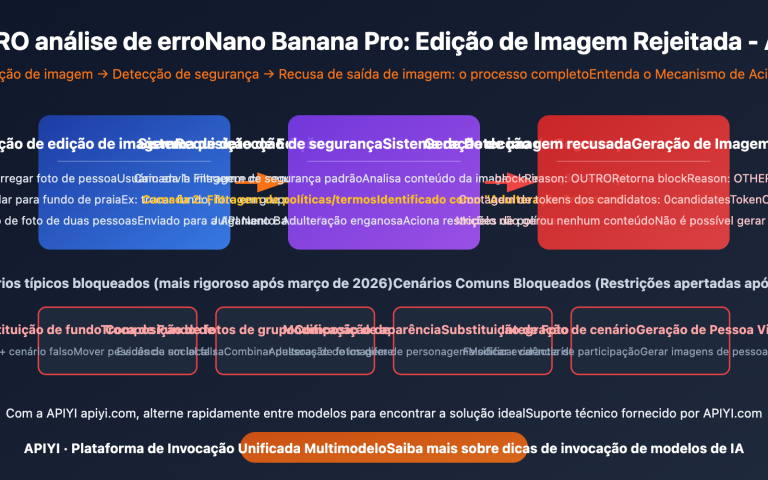
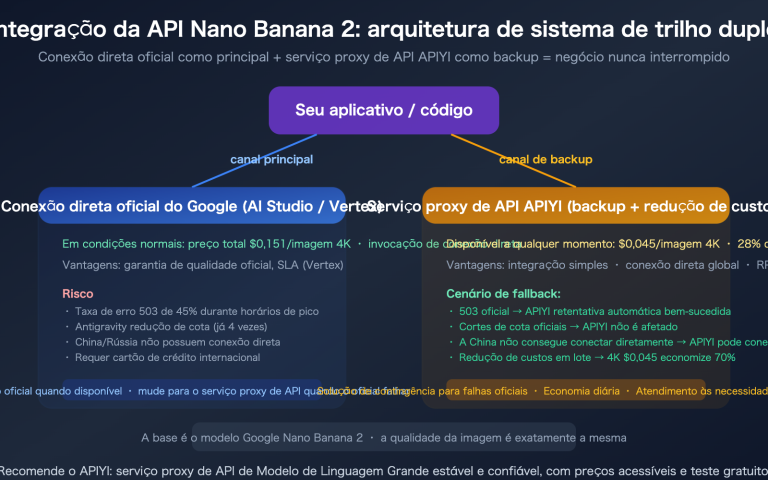
Recentemente, muitos desenvolvedores têm encontrado a seguinte mensagem de erro ao invocar a API do Gemini:
{
"error": {
"code": 503,
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"status": "UNAVAILABLE"
}
}
Traduzindo para uma linguagem mais simples: este modelo está bombando, o servidor não está aguentando, por favor, tente novamente mais tarde.
Este problema é particularmente grave nos novos modelos Gemini 3.1 Pro Preview e Gemini 3.1 Flash Image Preview (Nano Banana 2). Este artigo vai explicar a fundo a natureza desse erro, suas diferenças em relação a outros erros comuns e 5 soluções testadas e eficazes.
Valor principal: Ao ler este artigo, você entenderá a causa raiz do erro 503 de alta demanda, dominará 5 soluções práticas e não ficará mais travado no desenvolvimento por causa desse erro.
O que significa o erro Gemini API 503 High Demand?
Vamos entender esse problema com uma analogia simples:
Imagine os servidores Gemini do Google como um restaurante super famoso. Normalmente, o movimento é bom e há lugares suficientes. De repente, um dia o restaurante vira febre nas redes sociais (lançamento de um novo modelo), e a cidade inteira corre para fazer fila. A capacidade do restaurante é limitada; quando lota, lotou. Nesse momento, você chega à porta e o garçom diz: "Desculpe, está muito cheio agora, o horário de pico geralmente é temporário, por favor, volte mais tarde."
Essa é a essência de This model is currently experiencing high demand — não é um problema no seu código, nem na sua chave API, é que a capacidade de computação dos servidores do Google está esgotada.
3 Fatos Chave sobre o Erro Gemini 503
| Fato | Explicação | Impacto |
|---|---|---|
| Problema no servidor | O 503 indica que a capacidade do servidor do Google é insuficiente, não tem a ver com seu código ou configuração | Fazer upgrade para um plano pago não resolve |
| Todos os usuários são afetados | Usuários gratuitos, pagos e clientes corporativos podem encontrar o erro | Não é um problema que "mais dinheiro resolve" |
| Geralmente é temporário | Cerca de 70% dos erros 503 em horários de pico se recuperam sozinhos em 60 minutos | Requer um mecanismo de retentativa, não uma correção de código |
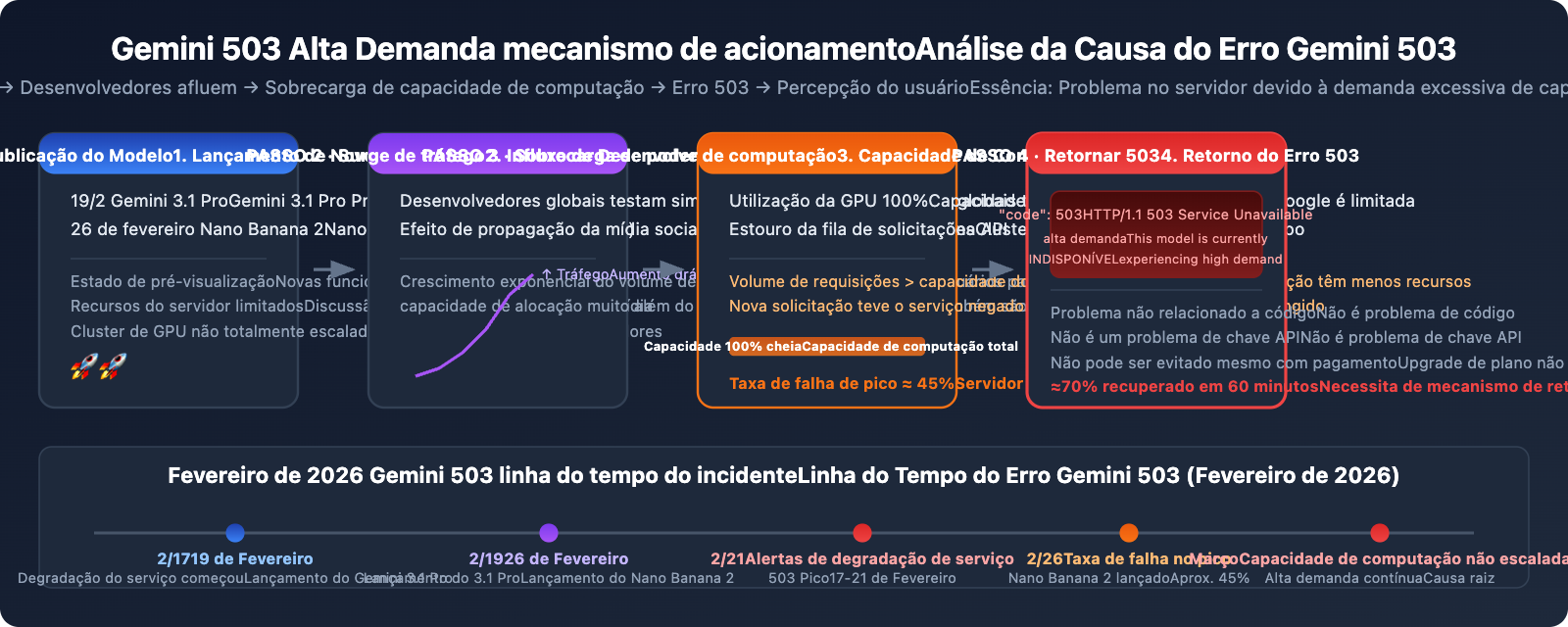
Por que o Gemini 3.1 Pro e o Nano Banana 2 são especialmente propensos ao 503
A explosão de erros 503 em fevereiro de 2026 tem uma linha do tempo clara:
- 19 de Fevereiro: Google lança o Gemini 3.1 Pro Preview, e muitos desenvolvedores correm para testar.
- 26 de Fevereiro: Lançamento do Nano Banana 2 (
gemini-3.1-flash-image-preview), aumentando drasticamente a demanda por geração de imagens. - 17-21 de Fevereiro: StatusGator registrou continuamente alertas de degradação do serviço Gemini por uma semana inteira.
- Taxa de falha no pico de cerca de 45%: Dados da comunidade mostram que a taxa de falha das requisições em horários de pico se aproximou da metade.
Causa raiz: Os novos modelos acabaram de ser lançados, e a capacidade de computação (clusters de GPU) alocada pelo Google ainda não foi escalada conforme a demanda. Os recursos do servidor para modelos em estado de Preview já são limitados, e quando desenvolvedores de todo o mundo testam simultaneamente, a demanda excede a oferta.
Diferença Essencial entre Gemini 503 High Demand e 429 Rate Limit
Muitos desenvolvedores confundem 503 e 429, mas as causas desses dois erros são completamente diferentes, e as soluções também. Errar o diagnóstico só vai fazer você perder tempo.
| Dimensão de Comparação | 503 High Demand | 429 Rate Limit |
|---|---|---|
| Mensagem de Erro | "This model is currently experiencing high demand" | "Resource has been exhausted" |
| Causa Principal | Capacidade insuficiente dos servidores do Google | Sua frequência de requisições excedeu o limite |
| Escopo do Impacto | Todos os usuários são afetados | Apenas você é afetado |
| Upgrade Resolve? | ❌ Fazer upgrade do plano pago não resolve | ✅ Fazer upgrade para o Tier 1 pode resolver |
| Tentativa e Erro? | ✅ Esperar um pouco geralmente resolve | ❌ Não diminuir a frequência causará erros contínuos |
| Características de Pico | Frequente durante o horário comercial da América do Norte (9AM-5PM PT) | Independente do horário, erro ao exceder o limite |
| Solução Fundamental | Tentar novamente + Modelo alternativo + Horários de menor pico | Diminuir a frequência de requisições ou fazer upgrade do plano |
Método de Diagnóstico Rápido
- Se vir 503 → Problema do Google, espere um pouco ou troque de modelo
- Se vir 429 → Você está requisitando muito rápido, diminua a velocidade ou faça upgrade do plano
🎯 Dica Técnica: Lidar com erros 503 e 429 simultaneamente em um ambiente de produção é uma habilidade fundamental na integração de APIs. Ao invocar os modelos da série Gemini através da plataforma APIYI apiyi.com, a plataforma oferece mecanismos integrados de retentativa inteligente e balanceamento de carga, o que pode reduzir significativamente a frequência de erros 503 percebidos pelos usuários finais.
Solução Um: Retentativa com Backoff Exponencial (o mais básico)
Já que 503 significa "tente novamente mais tarde", a resposta mais direta é a retentativa automática. Mas não dá para tentar novamente de qualquer jeito — é preciso usar uma estratégia de "backoff exponencial", dobrando o intervalo entre cada tentativa para evitar sobrecarregar ainda mais o servidor.
Código de Retentativa com Backoff Exponencial para Gemini 503
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unificada da APIYI
)
def call_gemini_with_retry(messages, model="gemini-3.1-pro-preview", max_retries=5):
"""Invocação da API Gemini com backoff exponencial"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages
)
return response
except openai.APIStatusError as e:
if e.status_code == 503:
# Backoff exponencial: 2s, 4s, 8s, 16s, 32s + jitter aleatório
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"⏳ 503 High Demand - {attempt+1}ª tentativa, esperando {wait_time:.1f}s...")
time.sleep(wait_time)
elif e.status_code == 429:
# 429 Rate Limit: esperar mais tempo
wait_time = 60 + random.uniform(0, 10)
print(f"🚫 429 Rate Limit - Esperando {wait_time:.1f}s...")
time.sleep(wait_time)
else:
raise # Lançar outras exceções diretamente
raise Exception(f"Falha após {max_retries} tentativas")
# Exemplo de uso
response = call_gemini_with_retry(
messages=[{"role": "user", "content": "Hello, Gemini!"}]
)
print(response.choices[0].message.content)
Parâmetros Essenciais da Retentativa com Backoff Exponencial
| Parâmetro | Valor Sugerido | Descrição |
|---|---|---|
| Máximo de Tentativas | 5 vezes | Mais de 5 tentativas geralmente indica que não é um problema temporário |
| Espera Inicial | 2 segundos | Muito curto pode aumentar a pressão no servidor |
| Fator de Backoff | 2x | Dobra a cada vez: 2s → 4s → 8s → 16s → 32s |
| Jitter Aleatório | 0-1 segundo | Evita que muitos clientes tentem novamente ao mesmo tempo |
| Espera Máxima | 32 segundos | Acima de 32 segundos, deve-se considerar uma solução alternativa |
💡 Dica Prática: O jitter aleatório é muito importante. Se todos os clientes tentarem novamente exatamente após 2 segundos, isso pode causar um "efeito manada" — todas as requisições inundariam o servidor novamente ao mesmo tempo, resultando em outro 503. Adicionar um jitter aleatório ajuda a dispersar as requisições de retentativa.
Solução Dois: Downgrade de Modelo / Troca Automática para Modelo de Backup
Quando o Gemini 3.1 Pro Preview retorna 503 continuamente, a solução mais prática é alternar automaticamente para um modelo de backup mais estável.
Estratégia de Downgrade de Modelo para Gemini 503
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY", # Sua chave API
base_url="https://api.apiyi.com/v1"
)
# Cadeia de downgrade de modelo: prioriza o mais forte, faz downgrade se falhar
FALLBACK_MODELS = [
"gemini-3.1-pro-preview", # Preferencial: o mais recente e poderoso
"gemini-3.0-pro", # Alternativa 1: Geração anterior Pro, mais estável
"gemini-2.5-flash-image-preview", # Alternativa 2: Versão Flash, rápida
"gemini-2.5-flash", # Fallback: O Flash mais estável
]
def call_with_fallback(messages):
"""Invocação da API com downgrade de modelo"""
for model in FALLBACK_MODELS:
try:
response = client.chat.completions.create(
model=model,
messages=messages
)
if model != FALLBACK_MODELS[0]:
print(f"⚠️ Downgrade para modelo de backup: {model}")
return response
except openai.APIStatusError as e:
if e.status_code in (503, 429):
print(f"❌ {model} retornou {e.status_code}, tentando o próximo modelo...")
continue
raise
raise Exception("Todos os modelos estão indisponíveis")
response = call_with_fallback(
messages=[{"role": "user", "content": "Analise os gargalos de desempenho deste código"}]
)
Classificação de Estabilidade dos Modelos Gemini
| Modelo | Estabilidade | Frequência de 503 | Cenários Adequados |
|---|---|---|---|
gemini-2.5-flash |
⭐⭐⭐⭐⭐ | Muito baixa | Fallback para ambientes de produção de alta disponibilidade |
gemini-3.0-pro |
⭐⭐⭐⭐ | Baixa | Cenários estáveis que exigem recursos Pro |
gemini-2.5-flash-image-preview |
⭐⭐⭐ | Média | Alternativa para geração de imagens |
gemini-3.1-pro-preview |
⭐⭐ | Alta | Exige os recursos mais recentes, mas aceita falhas ocasionais |
gemini-3.1-flash-image-preview |
⭐⭐ | Alta | Geração de imagens Nano Banana 2 |
🚀 Comece Rápido: Através da plataforma APIYI apiyi.com, você pode invocar todos os modelos da tabela acima com uma única chave API. A troca de modelo requer apenas a modificação do parâmetro
model, sem a necessidade de reconfigurar a autenticação. Implementar uma cadeia de downgrade de modelo no código é muito conveniente.
Solução Três: Invocação Fora do Horário de Pico (Solução de Custo Zero)
A alta demanda que causa o erro 503 segue padrões de horário claros. Dados da comunidade mostram:
- Horário de Pico (9AM-5PM PT): Taxa de falha de aproximadamente 45%
- Horário de Baixa (2AM-7AM PT): Taxa de falha inferior a 5%
Convertendo para o horário de Pequim (Beijing):
| Período (Horário de Pequim) | Horário do Pacífico Correspondente | Frequência de Gemini 503 | Sugestão |
|---|---|---|---|
| 1:00 AM – 10:00 AM | 9AM-6PM PT (dia anterior) | 🔴 Pico | Evitar ou usar modelo de backup |
| 10:00 AM – 3:00 PM | 6PM-11PM PT (dia anterior) | 🟡 Média | Invocar com mecanismo de retentativa |
| 3:00 PM – 11:00 PM | 11PM-7AM PT | 🟢 Baixa | Melhor janela de invocação |
| 11:00 PM – 1:00 AM | 7AM-9AM PT | 🟡 Média | Começando a aquecer |
Cenários Adequados para Invocação Fora do Horário de Pico
- Processamento em lote de dados: Tarefas que não exigem resposta em tempo real, agendadas para rodar nos horários de baixa demanda.
- Tarefas agendadas: Configurar cron jobs para execução nos horários de baixa demanda.
- Geração de conteúdo: Cenários onde artigos, geração de imagens e outros podem ser gerados antecipadamente e publicados com atraso.
Solução Quatro: Estratégia Combinada (Recomendado para Produção)
Em ambientes de produção reais, uma única solução geralmente não é suficiente. Recomenda-se combinar as 3 soluções anteriores:
Solução de Invocação da API Gemini em Nível de Produção
import openai
import time
import random
from datetime import datetime
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
FALLBACK_MODELS = [
"gemini-3.1-pro-preview",
"gemini-3.0-pro",
"gemini-2.5-flash",
]
def smart_gemini_call(messages, max_retries=3):
"""
Invocação da API Gemini em nível de produção
Estratégia: Retentativa com backoff exponencial + downgrade de modelo + classificação de erros
"""
for model in FALLBACK_MODELS:
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages,
timeout=30
)
return response, model
except openai.APIStatusError as e:
if e.status_code == 503:
if attempt < max_retries - 1:
wait = (2 ** attempt) + random.uniform(0, 1)
print(f"⏳ {model} 503 - Retentativa {attempt+1}/{max_retries}, aguardando {wait:.1f}s")
time.sleep(wait)
else:
print(f"⚠️ {model} 503 persistente, fazendo downgrade para o próximo modelo")
break # Sai da retentativa, troca de modelo
elif e.status_code == 429:
wait = 60
print(f"🚫 {model} 429 Limite de taxa - Aguardando {wait}s")
time.sleep(wait)
else:
raise
except openai.APITimeoutError:
print(f"⏰ {model} Requisição expirou, tentando o próximo modelo")
break
raise Exception("Todos os modelos e retentativas falharam, verifique a rede ou tente novamente mais tarde")
# Uso
response, used_model = smart_gemini_call(
messages=[{"role": "user", "content": "Olá"}]
)
print(f"✅ Modelo usado: {used_model}")
print(response.choices[0].message.content)
Ver encapsulamento completo de nível de produção (com logs, monitoramento, cache)
import openai
import time
import random
import hashlib
import json
import logging
from datetime import datetime
from functools import lru_cache
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("gemini_client")
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Cache de requisição simples
_cache = {}
def get_cache_key(messages, model):
"""Gera a chave de cache para a requisição"""
content = json.dumps(messages, sort_keys=True) + model
return hashlib.md5(content.encode()).hexdigest()
def gemini_call_production(
messages,
models=None,
max_retries=3,
cache_ttl=3600,
enable_cache=True
):
"""
Encapsulamento de invocação da API Gemini em nível de produção
Características:
- Retentativa com backoff exponencial (lida com 503)
- Downgrade automático de modelo
- Cache de resposta (reduz requisições duplicadas)
- Logs estruturados
"""
if models is None:
models = ["gemini-3.1-pro-preview", "gemini-3.0-pro", "gemini-2.5-flash"]
# Verifica o cache
if enable_cache:
cache_key = get_cache_key(messages, models[0])
if cache_key in _cache:
cached_time, cached_response = _cache[cache_key]
if time.time() - cached_time < cache_ttl:
logger.info("Cache hit, pulando invocação da API")
return cached_response, "cache"
errors = []
for model in models:
for attempt in range(max_retries):
try:
start_time = time.time()
response = client.chat.completions.create(
model=model,
messages=messages,
timeout=30
)
elapsed = time.time() - start_time
logger.info(f"Sucesso | model={model} | tempo={elapsed:.2f}s")
# Escreve no cache
if enable_cache:
_cache[cache_key] = (time.time(), response)
return response, model
except openai.APIStatusError as e:
errors.append(f"{model}:{e.status_code}")
if e.status_code == 503:
if attempt < max_retries - 1:
wait = (2 ** attempt) + random.uniform(0, 1)
logger.warning(f"503 | model={model} | retentativa={attempt+1} | aguardar={wait:.1f}s")
time.sleep(wait)
else:
logger.warning(f"503 persistente | model={model} | downgrade para o próximo modelo")
break
elif e.status_code == 429:
logger.warning(f"429 Limite de taxa | model={model}")
time.sleep(60)
else:
raise
except Exception as e:
logger.error(f"Exceção | model={model} | erro={e}")
break
raise Exception(f"Todas as tentativas falharam: {errors}")

Solução Cinco: Usando o Roteamento Inteligente de Plataformas de Serviço Proxy
Quando você não quer implementar a lógica complexa de retentativas e fallback mencionada acima, há uma opção mais prática: usar uma plataforma de serviço proxy de API com roteamento inteligente integrado.
Como as Plataformas de Serviço Proxy Resolvem o Problema do Gemini 503
Plataformas de serviço proxy de API profissionais geralmente possuem:
- Rotação de Múltiplas Chaves: A plataforma possui várias chaves API do Google, e alterna automaticamente quando uma chave é limitada.
- Retentativa Inteligente: A plataforma implementa retentativas com backoff exponencial, transparente para o desenvolvedor.
- Balanceamento de Carga: Distribui as requisições entre várias contas e regiões do Google.
- Detecção de Falhas: Ao detectar um aumento na frequência de erros 503 para um modelo, reduz automaticamente a proporção de requisições alocadas para esse modelo.
🎯 Sugestão Técnica: A plataforma APIYI (apiyi.com) oferece as capacidades de roteamento inteligente mencionadas para os modelos da série Gemini. Ao usar a invocação via interface compatível com OpenAI, a plataforma lida automaticamente com as retentativas de 503 e o balanceamento de carga de múltiplas chaves no backend, eliminando a necessidade de o desenvolvedor implementar lógicas de tolerância a falhas complexas.
Exemplo de Código Minimalista para a Solução com Plataforma de Serviço Proxy
import openai
# Usando a plataforma de serviço proxy APIYI, o tratamento do 503 é responsabilidade da plataforma
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Simples assim, não precisa lidar com o 503 por conta própria
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "你好"}]
)
print(response.choices[0].message.content)
Fluxo Completo de Resolução de Erros da API Gemini
Ao encontrar erros na API Gemini, siga o fluxo abaixo para identificar rapidamente o problema:
Primeiro Passo: Verificar o Código de Erro
| Código de Erro | Mensagem de Erro | Tipo | Ação Imediata |
|---|---|---|---|
| 503 | "high demand" / "overloaded" | Capacidade insuficiente do servidor | Aguardar retentativa ou trocar de modelo |
| 429 | "resource exhausted" | Limite de taxa pessoal | Reduzir frequência de requisições ou fazer upgrade do plano |
| 400 | "invalid request" | Parâmetros de requisição incorretos | Verificar formato e parâmetros da requisição |
| 401 | "unauthorized" | Falha na autenticação | Verificar chave API |
| 500 | "internal error" | Erro interno do servidor | Aguardar retentativa |
Segundo Passo: Distinguir entre 503 e 429
- Múltiplas chaves API retornam erro → 503, é um problema do servidor do Google
- Apenas sua chave retorna erro → 429, é um problema de limite pessoal
Terceiro Passo: Escolher a Solução Correspondente
- 503: Retentativa com backoff exponencial → Fallback do modelo → Invocação fora do horário de pico
- 429: Reduzir frequência de requisições → Ativar faturamento para upgrade para o Tier 1 (camada gratuita 5-15 RPM, Tier 1 é 150-300 RPM)
Perguntas Frequentes
Q1: Por que ainda encontro 503 High Demand mesmo tendo pago?
O 503 não tem absolutamente nenhuma relação com o fato de você ter pago ou não. O 503 é um problema de capacidade insuficiente dos servidores do Google, e tanto usuários gratuitos quanto clientes corporativos podem encontrá-lo. Isso é diferente do limite de taxa 429 – o 429 pode ser resolvido com a atualização do plano, mas o 503 não. Ao encontrar um 503, é recomendável usar a estratégia de repetição com backoff exponencial ou mudar para uma versão de modelo mais estável. A invocação do modelo através da plataforma APIYI apiyi.com pode usar balanceamento de carga com múltiplas chaves para reduzir a frequência percebida do 503.
Q2: Quando o 503 do Gemini 3.1 Pro Preview será resolvido?
Com base na experiência histórica, o pico de 503 após o lançamento de um novo modelo geralmente dura de 1 a 3 semanas, melhorando significativamente à medida que o Google expande gradualmente sua capacidade. O Gemini 3.0 Pro também passou por uma onda semelhante de 503 quando foi lançado e agora está muito estável. Durante o período de espera, é recomendável implementar uma estratégia de degradação do modelo, fazendo um fallback automático para gemini-3.0-pro ou gemini-2.5-flash em caso de 503.
Q3: “high demand” e “model is overloaded” são o mesmo erro?
Essencialmente, são diferentes formas de expressar o mesmo problema. Tanto "This model is currently experiencing high demand" quanto "The model is overloaded" são códigos de status 503, e ambos indicam capacidade insuficiente dos servidores do Google. O primeiro é mais comum em versões mais recentes da API, enquanto o segundo aparecia mais nas versões anteriores. A forma de lidar com eles é exatamente a mesma.
Q4: Existe alguma forma de saber antecipadamente se a API do Gemini terá 503?
Não há um aviso prévio oficial. No entanto, você pode observar alguns sinais: (1) As 1-2 semanas após o lançamento de um novo modelo pelo Google são um período de alto risco; (2) A frequência de 503 é maior durante o horário comercial da América do Norte (madrugada até a manhã, horário de Pequim); (3) Os fóruns da comunidade discuss.ai.google.dev geralmente têm feedback em tempo real. É recomendável sempre manter a lógica de repetição e degradação no código, em vez de adicioná-la apenas quando um problema é encontrado. A plataforma APIYI apiyi.com oferece monitoramento do status de disponibilidade do modelo, o que pode ajudar você a perceber antecipadamente.
Q5: Devo tratar 503 e 429 simultaneamente no meu código?
Com certeza. Em ambientes de produção, tanto 503 quanto 429 serão encontrados, e as estratégias de tratamento são diferentes, mas igualmente importantes. Para 503, use repetição com backoff exponencial + degradação do modelo; para 429, use redução da frequência de requisições + fila de limitação de taxa. O código da "Solução Quatro: Estratégia Combinada" deste artigo trata ambos os erros simultaneamente e pode ser usado diretamente em ambientes de produção.
Resumo
A essência do erro 503 This model is currently experiencing high demand é muito simples – a capacidade dos servidores do Google está temporariamente insuficiente. Especialmente para novos modelos como Gemini 3.1 Pro Preview e Nano Banana 2, é quase inevitável encontrá-lo na fase inicial de lançamento.
5 soluções, por ordem de prioridade recomendada:
- Repetição com backoff exponencial — O mais básico, todo projeto deveria ter
- Cadeia de degradação de modelos — Alterna automaticamente para um modelo mais estável em caso de 503
- Invocação fora do pico — Tarefas não em tempo real agendadas para períodos de baixa demanda
- Estratégia combinada — Recomendado para ambientes de produção: repetição + degradação + classificação de erros
- Roteamento inteligente via plataforma proxy — O mais prático, a plataforma lida com a lógica de tolerância a falhas
Independentemente da solução escolhida, o princípio central é: o 503 não é sua culpa, mas você precisa lidar com ele de forma elegante. Recomenda-se integrar rapidamente os modelos da série Gemini através da APIYI apiyi.com para aproveitar o roteamento inteligente e a capacidade de repetição integrados.
Referências
-
Google AI Developers Forum – 503 Error Discussions
- Link:
discuss.ai.google.dev - Descrição: Discussões da comunidade e respostas oficiais sobre o erro 503 da API Gemini
- Link:
-
Google Gemini API – Rate Limits Documentation
- Link:
ai.google.dev/gemini-api/docs/rate-limits - Descrição: Regras oficiais de limite de taxa e descrição das cotas para cada Tier
- Link:
-
Google Gemini API – Troubleshooting Guide
- Link:
ai.google.dev/gemini-api/docs/troubleshooting - Descrição: Guia oficial de solução de problemas
- Link:
📝 Autor: Equipe APIYI | Para intercâmbio técnico e integração de API, visite apiyi.com