作者注:详细介绍阿里巴巴通义最新开源的 Z-Image 图像生成模型,包括快速上手、三种部署方式、提示词技巧和最佳实践,帮助新手快速掌握这个 8 步出图的强大 AI 工具。
在 AI 图像生成领域,2025 年 11 月阿里巴巴通义实验室推出的 Z-Image 开源模型引起了轰动。这个仅有 60 亿参数的模型,在发布首日就获得了 50 万下载量,登顶 Hugging Face 趋势榜双榜第一。Z-Image 的核心突破在于:仅需 8 步推理即可生成高质量图像,在消费级 16GB 显卡上实现亚秒级生成,且原生支持中英文双语文本渲染。本文将为您详细介绍 Z-Image 新手入门的完整路径,帮助您快速掌握这个强大的开源图像生成工具。
核心价值:通过本文,您将掌握 Z-Image 的三种部署方式(Python/ComfyUI/WebUI),学会编写高质量提示词,了解硬件配置要求和性能优化技巧,零基础也能在 30 分钟内开始生成专业级图像。

Z-Image 核心特性与技术突破
什么是 Z-Image?
Z-Image (造相) 是阿里巴巴通义实验室 (Tongyi MAI) 于 2025 年 11 月发布的开源 AI 图像生成模型。该模型采用创新的 S3-DiT (Scalable Single-Stream Diffusion Transformer) 架构,将文本、视觉语义 token 和图像 VAE token 在序列级别统一处理,相比传统双流架构实现了更高的参数效率。
模型系列:
- Z-Image-Turbo: 快速推理版本,8 步生成,适合实时应用
- Z-Image-Base: 基础版本,适合通用开发和模型微调
- Z-Image-Edit: 图像编辑专用版,支持自然语言编辑指令
开源协议:
Z-Image 采用 Apache 2.0 开源协议,这意味着您可以自由使用、修改和商业化,无需支付授权费用。这一点对于个人开发者和中小企业尤为重要。
六大核心突破
1. 极速推理:8 步生成高质量图像
传统的扩散模型通常需要 20-50 步推理才能生成高质量图像,而 Z-Image-Turbo 通过模型蒸馏技术,将推理步数压缩至 8 步,在保持图像质量的同时,生成速度提升了 2.5-6 倍。
实测性能数据:
- H800 GPU: 亚秒级生成 (< 1 秒)
- RTX 4090: 3-4 秒生成 1024×1024 图像
- RTX 4080 (16GB): 6-7 秒生成 1024×1024 图像
- RTX 3060 (12GB): 10-15 秒生成 1024×1024 图像
2. 消费级友好:最低 8GB 显存即可运行
与动辄需要 24GB 甚至 48GB 显存的商业模型不同,Z-Image 针对消费级硬件进行了深度优化:
| 显存配置 | 推荐 GPU | 运行模式 | 生成速度 | 适用场景 |
|---|---|---|---|---|
| 8GB | RTX 3060 12GB | FP8 量化 | 15-20 秒 | 学习测试 |
| 12-16GB | RTX 4060 Ti / 4070 | BF16 标准 | 8-12 秒 | 个人创作 |
| 16-24GB | RTX 4080 / 4090 | BF16 完整 | 3-7 秒 | 专业设计 |
| 40GB+ | A100 / H800 | BF16 批量 | < 1 秒 | 企业生产 |
3. 双语文本渲染:原生支持中英文
Z-Image 的核心竞争力之一是原生的双语文本渲染能力。多数国际模型(如 DALL-E 3、Midjourney)在中文文本渲染上表现不佳,经常出现字形错误、排版混乱等问题。Z-Image 通过专门的训练数据集和架构优化,实现了:
- ✅ 中文字符准确渲染(包括繁体字)
- ✅ 中英文混合排版
- ✅ 多种字体风格(楷体、宋体、黑体等)
- ✅ 复杂文本场景(海报、广告、品牌 Logo)
应用价值:
对于面向中文市场的设计师和内容创作者,这一特性意味着可以直接生成带有中文文字的海报、广告和品牌素材,无需后期 PS 添加文字,大幅提升工作效率。
4. 参数效率:6B 参数达到 SOTA 性能
Z-Image 仅使用 60 亿参数,就达到了与百亿级模型相当甚至更优的生成质量。这得益于创新的单流 DiT 架构设计:
技术优势:
- 内存占用低: 加载模型仅需 12-16GB 系统内存
- 推理速度快: 参数量小,计算开销低
- 微调成本低: 适合 LoRA 等轻量级微调方法
- 部署灵活: 可在边缘设备和云端灵活部署
5. 开源生态:完整的社区支持
Z-Image 发布仅一周,社区就涌现了大量教程、工作流和应用案例:
- HuggingFace: 官方模型仓库,50+ 万下载量
- GitHub: 开源代码和文档,2000+ Stars
- ComfyUI: 原生支持,无需安装第三方节点
- Replicate: 云端 API 服务,一键调用
🎯 技术建议: 对于希望快速测试 Z-Image 能力的开发者,我们建议通过 API易 apiyi.com 平台访问托管的 Z-Image API 服务。该平台提供国内直连访问,无需自行部署硬件环境,支持按需付费,适合快速验证技术方案和进行原型开发。
6. 商业友好:Apache 2.0 许可证
Apache 2.0 是业界最宽松的开源许可证之一,允许:
- ✅ 商业使用和闭源修改
- ✅ 修改代码和二次分发
- ✅ 申请专利保护
- ✅ 无需支付授权费用
商业价值:
相比 Midjourney ($10-60/月订阅) 和 DALL-E 3 ($0.04-0.08/图),Z-Image 的免费开源模式为企业节省了大量成本,特别适合图像生成需求量大的电商、营销和创意行业。
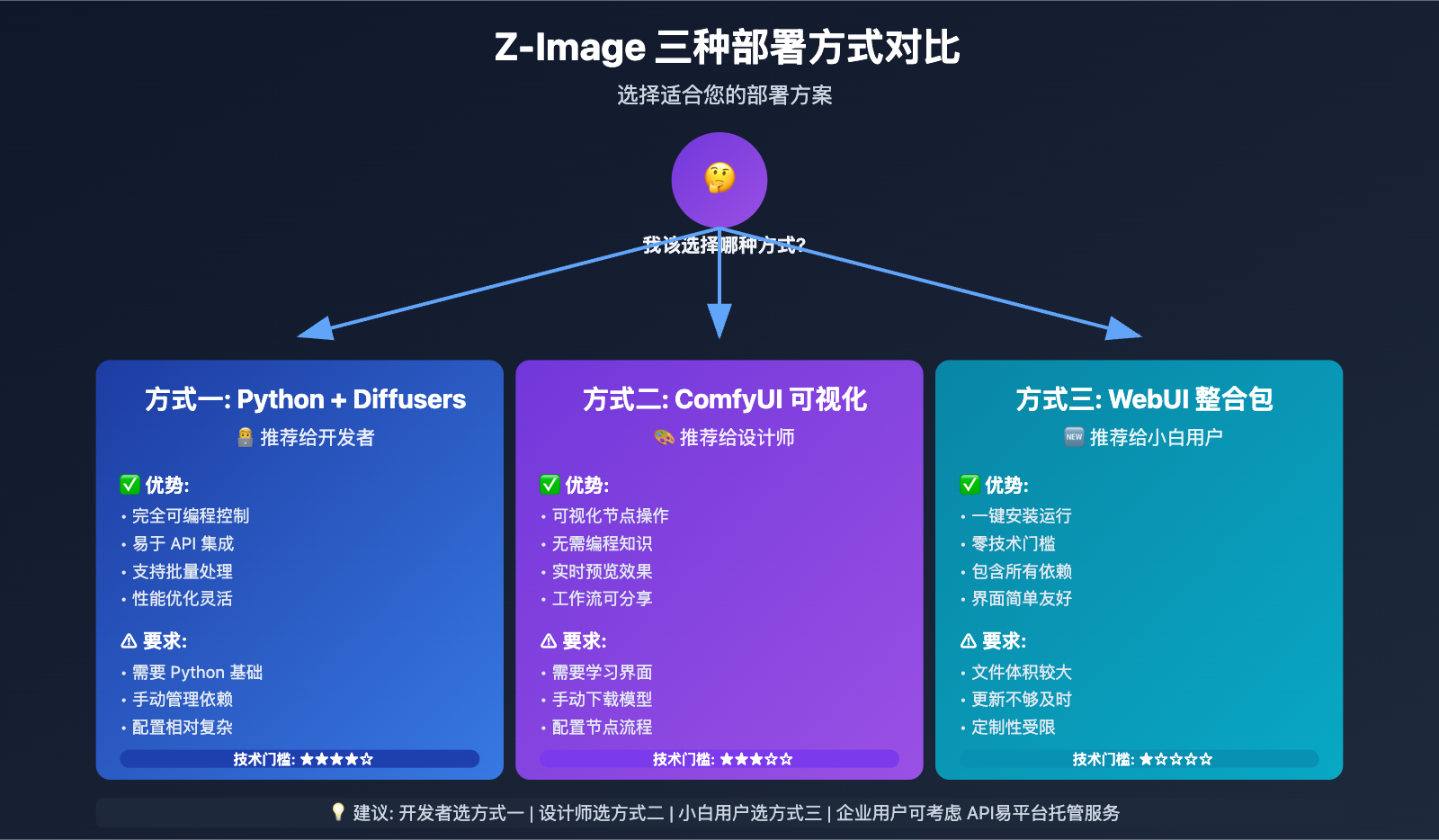
Z-Image 快速上手:三种部署方式
方式一:Python + Diffusers 部署 (推荐开发者)
这是最灵活、最可控的部署方式,适合需要 API 集成和批量处理的开发者。
步骤 1:环境准备
# 创建 Python 虚拟环境 (推荐)
python3 -m venv z-image-env
source z-image-env/bin/activate # Linux/Mac
# 或 z-image-env\Scripts\activate # Windows
# 安装依赖
pip install torch torchvision
pip install git+https://github.com/huggingface/diffusers
pip install transformers accelerate
硬件要求检查:
import torch
print(f"PyTorch 版本: {torch.__version__}")
print(f"CUDA 可用: {torch.cuda.is_available()}")
print(f"CUDA 版本: {torch.version.cuda}")
print(f"显卡型号: {torch.cuda.get_device_name(0)}")
print(f"显存大小: {torch.cuda.get_device_properties(0).total_memory / 1024**3:.2f} GB")
步骤 2:加载模型和生成图像
import torch
from diffusers import ZImagePipeline
# 加载 Z-Image-Turbo 模型
pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.bfloat16, # 使用 BF16 精度
low_cpu_mem_usage=False,
)
pipe.to("cuda") # 移至 GPU
# 生成图像
prompt = "一只橙色的猫咪坐在窗台上,阳光洒在毛发上,温暖的氛围,高质量摄影"
image = pipe(
prompt=prompt,
height=1024,
width=1024,
num_inference_steps=9, # 实际执行 8 次前向传播
guidance_scale=0.0, # Turbo 模型使用 0.0
generator=torch.Generator("cuda").manual_seed(42),
).images[0]
# 保存图像
image.save("cat_on_windowsill.png")
print("✅ 图像生成完成!")
步骤 3:批量生成优化
# 批量生成多张图像
prompts = [
"一只猫在阳光下打盹,暖色调",
"一只狗在草地上奔跑,动感捕捉",
"一只鸟站在树枝上,清晨薄雾",
]
images = []
for i, prompt in enumerate(prompts):
print(f"正在生成第 {i+1}/{len(prompts)} 张图像...")
image = pipe(
prompt=prompt,
height=1024,
width=1024,
num_inference_steps=9,
guidance_scale=0.0,
).images[0]
image.save(f"batch_output_{i+1}.png")
images.append(image)
print(f"✅ 批量生成完成!共生成 {len(images)} 张图像")
性能优化技巧:
- 使用
torch.bfloat16代替float32,速度提升 30-50% - 设置
low_cpu_mem_usage=False加快模型加载 - 批量生成时复用 Pipeline 对象,避免重复加载
💡 实践建议: 对于需要大规模批量生成的企业用户,推荐使用 API易 apiyi.com 平台的 Z-Image API 服务。平台提供了高并发支持和自动负载均衡,可以实现每分钟生成数百张图像,相比本地部署节省了硬件投入和运维成本。
方式二:ComfyUI 可视化部署 (推荐设计师)
ComfyUI 是目前最流行的 AI 图像生成可视化工具,Z-Image 已原生支持,无需安装第三方节点。
步骤 1:下载和安装 ComfyUI
# 克隆 ComfyUI 仓库
git clone https://github.com/comfyanonymous/ComfyUI
cd ComfyUI
# 安装依赖
pip install -r requirements.txt
# 启动 ComfyUI
python main.py
访问 http://127.0.0.1:8188 打开 ComfyUI 界面。
步骤 2:下载 Z-Image 模型文件
需要下载两个文件:
- 文本编码器:
qwen_3_4b.safetensors(约 6.8GB) - 扩散模型:
z_image_turbo_bf16.safetensors(约 12GB)
文件存放位置:
ComfyUI/
├── models/
│ ├── text_encoders/
│ │ └── qwen_3_4b.safetensors
│ └── diffusion_models/
│ └── z_image_turbo_bf16.safetensors
下载链接:
- HuggingFace: https://huggingface.co/Tongyi-MAI/Z-Image-Turbo
- ModelScope (国内镜像): https://modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo
步骤 3:导入工作流
ComfyUI 支持导入预设工作流 JSON 文件。Z-Image 官方提供了优化的工作流模板:
基础工作流配置:
- 提示词节点: 输入中英文提示词
- Z-Image 加载节点: 加载 Turbo 模型
- 采样器节点: 设置 9 步推理
- VAE 解码节点: 将 latent 转为图像
- 保存节点: 导出 PNG 图像
推荐参数设置:
- 分辨率: 1024×1024 (最佳性能)
- 采样步数: 9 步
- CFG Scale: 0.0 (Turbo 模型固定)
- 采样器: Euler
- 调度器: Simple
步骤 4:生成和导出
在提示词框输入描述文字,点击 "Queue Prompt" 即可开始生成。生成的图像会保存在 ComfyUI/output/ 目录。
工作流优势:
- ✅ 可视化操作,无需编程
- ✅ 支持实时预览和参数调整
- ✅ 可保存和分享工作流配置
- ✅ 社区有大量预设工作流
方式三:WebUI 一键整合包 (推荐小白用户)
对于完全没有编程基础的用户,可以使用社区打包的 WebUI 一键整合包。
步骤 1:下载整合包
整合包通常包含:
- ✅ Python 运行环境
- ✅ Z-Image 模型文件
- ✅ WebUI 界面
- ✅ 所有必需依赖
下载渠道:
- GitHub Releases (国际用户)
- 百度网盘/123 云盘 (国内用户)
- Bilibili UP 主分享链接
步骤 2:解压和运行
# 解压整合包到任意目录 (路径不要包含中文)
unzip Z-Image-WebUI-Pack.zip
# 进入目录
cd Z-Image-WebUI-Pack
# 运行启动脚本
./run.bat # Windows
# 或 ./run.sh # Linux/Mac
步骤 3:使用 WebUI 界面
启动后会自动打开浏览器访问 http://localhost:7860。
界面功能:
- 提示词输入框: 输入图像描述
- 参数设置: 分辨率、采样步数等
- 生成按钮: 一键生成图像
- 历史记录: 查看之前生成的图像
- 批量生成: 一次生成多张变体
推荐配置:
- 图像尺寸: 1024×1024
- 采样步数: 9
- 批量数量: 1-4 张
- 随机种子: -1 (随机)
🚀 快速开始: 如果您不想处理本地部署的复杂性,可以直接访问 AI 图片大师 imagen.apiyi.com 在线工具。该工具基于 Z-Image 和其他主流模型构建,提供免费的在线生成服务,无需注册即可体验,适合快速测试和轻度使用。

Z-Image 提示词工程:从入门到精通
提示词基本结构
一个高质量的 Z-Image 提示词通常包含以下要素:
[主体描述] + [环境背景] + [光线氛围] + [风格特征] + [质量修饰]
示例对比:
❌ 差的提示词 (太简单):
一只猫
✅ 好的提示词 (具体详细):
一只橙色短毛猫,蓝色眼睛,坐在木质窗台上,
阳光透过窗户洒在猫咪身上,背景是模糊的绿色植物,
温馨的家居氛围,高质量摄影,浅景深,柔和光线
效果差异:
- 简单提示词: 生成结果随机性强,质量不稳定
- 详细提示词: 生成结果更符合预期,质量更高
中英文提示词对比
Z-Image 原生支持中英文,两种语言各有优势:
中文提示词
优势:
- ✅ 自然流畅,更符合中文表达习惯
- ✅ 文化元素理解更准确(如"水墨画"、"工笔画")
- ✅ 生成中文文字更准确
示例:
一张中国风新年海报,
顶部正中央写着大号金色楷体"新年快乐"四个字,
底部写着小号红色"福"字,
红色背景,金色祥云装饰,对称构图,
传统中国美学,喜庆氛围
英文提示词
优势:
- ✅ 风格术语更丰富(如 "photorealistic", "hyperdetailed")
- ✅ 特效描述更准确(如 "bokeh", "ray tracing")
- ✅ 与国际社区提示词兼容
示例:
A Chinese New Year poster,
large golden calligraphy "新年快乐" (Happy New Year) at the top center,
small red "福" (Fortune) character at the bottom,
red background, golden cloud decorations, symmetrical composition,
traditional Chinese aesthetics, festive atmosphere,
high quality, 4K resolution
双语文本渲染技巧
Z-Image 的核心优势之一是双语文本渲染,掌握以下技巧可以获得更好的效果:
技巧 1:明确文本内容和位置
✅ 推荐写法:
一张海报,
顶部居中显示"限时特惠"四个大字(红色,粗体),
中间显示产品图片,
底部显示"仅需 ¥99"(黄色,醒目)
❌ 不推荐:
一张促销海报,有标题和价格
技巧 2:指定字体风格
楷体风格的"新年快乐"
宋体风格的"福"字
现代简约字体的"SALE"
书法字体的古诗词
技巧 3:中英文混合排版
一张双语菜单,
左侧写中文"红烧肉"(黑色宋体),
右侧写英文"Braised Pork"(灰色无衬线字体),
价格"¥38"用橙色标注
风格化提示词模板
1. 写实摄影风格
[主体描述],
专业摄影,高清晰度,浅景深,
自然光线,电影级色彩分级,
8K 超高清,佳能 EOS R5 拍摄
2. 插画艺术风格
[主体描述],
扁平插画风格,鲜艳色彩,
简洁线条,现代设计感,
矢量图形,Adobe Illustrator 风格
3. 中国传统风格
[主体描述],
水墨画风格,淡雅色彩,
留白构图,国画意境,
宣纸质感,传统中国美学
4. 赛博朋克风格
[主体描述],
赛博朋克风格,霓虹灯光,
未来科技感,高饱和度色彩,
数字艺术,Blade Runner 氛围
10 个高质量提示词模板
模板 1 – 产品摄影:
一瓶香水放在大理石台面上,
柔和的侧光照射,
背景是模糊的白色纱帘,
简约奢华风格,商业摄影,
高端产品展示,4K 超清
模板 2 – 食物摄影:
一碗热气腾腾的拉面,
金黄色的面条,红色的叉烧肉,
碧绿的葱花,白色的温泉蛋,
俯拍视角,浅景深,
美食摄影,食欲满满,4K 画质
模板 3 – 建筑摄影:
现代极简主义建筑,
白色混凝土外墙,大面积玻璃幕墙,
蓝天白云背景,黄金时刻光线,
对称构图,建筑摄影,
专业级画质,8K 超高清
模板 4 – 人物肖像:
一位年轻女性,
长发飘逸,柔和的微笑,
自然光从侧面照射,
温暖色调,浅景深背景虚化,
人像摄影,电影级色彩,高清晰度
模板 5 – 概念艺术:
未来城市景观,
高耸的摩天大楼,飞行汽车穿梭,
霓虹灯招牌,赛博朋克风格,
夜晚场景,蓝紫色调,
科幻艺术,数字绘画,超高清
模板 6 – 自然风光:
雪山倒映在湖面上,
清晨的薄雾,柔和的粉色天空,
前景是野花点缀的草地,
风光摄影,宁静氛围,
专业相机拍摄,8K 超高清
模板 7 – 中文海报设计:
一张促销海报,
顶部大字"年终大促"(红色加粗),
中间展示商品图片,
底部"全场5折起"(黄色醒目字体),
红金配色,现代设计感,4K 分辨率
模板 8 – 产品场景图:
一台银色笔记本电脑放在木质桌面上,
旁边放着咖啡杯和笔记本,
背景是明亮的落地窗,
自然光线,居家办公氛围,
商业摄影,高质量渲染
模板 9 – 游戏场景:
魔幻森林场景,
巨大的发光蘑菇,蜿蜒的藤蔓,
神秘的蓝色雾气,
奇幻插画风格,游戏概念艺术,
高细节渲染,4K 游戏画质
模板 10 – 抽象艺术:
抽象几何图形,
渐变色彩流动,蓝色到紫色,
光滑的表面反射,
现代艺术风格,极简主义,
高分辨率,数字艺术
负面提示词使用
虽然 Z-Image-Turbo 不支持 negative prompt 参数,但可以在正面提示词中使用排除性描述:
一张清晰的产品照片,
简洁构图,无杂乱背景,
无文字水印,无 logo,
专业摄影,高质量
Z-Image 常见问题解答
性能相关
Q1: 我的显卡只有 8GB 显存,能运行 Z-Image 吗?
A: 可以!Z-Image-Turbo 通过 FP8 量化可以在 8GB 显存上运行。虽然速度会慢一些 (15-20 秒/张),但完全可用。推荐使用 FP8 量化版本模型,并将分辨率设置为 1024×1024。
Q2: 为什么我的生成速度比官方宣称的慢?
A: 影响生成速度的因素包括:
- 显卡型号和显存大小
- 图像分辨率设置 (2048×2048 比 1024×1024 慢 4 倍)
- 使用的数据类型 (BF16 最快,FP32 最慢)
- 系统内存和 CPU 性能
- 是否使用了模型编译优化
Q3: 生成的图像质量不理想怎么办?
A: 尝试以下优化方法:
- 增加提示词的详细程度和具体性
- 尝试不同的随机种子 (生成多个版本)
- 调整分辨率 (1024×1024 通常效果最好)
- 检查是否使用了正确的模型版本 (Turbo vs Base)
模型相关
Q4: Z-Image 支持 LoRA 微调吗?
A: 根据 GitHub Issue #6,Z-Image 团队正在开发 LoRA 微调支持。目前可以使用全参数微调,但成本较高。建议关注官方 GitHub 仓库获取最新进展。
Q5: Z-Image-Turbo 和 Z-Image-Base 有什么区别?
A:
- Turbo: 8 步快速生成,速度优先,适合实时应用
- Base: 更多步数,质量优先,适合精细创作
大多数情况下推荐使用 Turbo,除非对图像质量有极高要求。
Q6: 可以使用 Z-Image 做图像编辑吗?
A: 可以!使用 Z-Image-Edit 模型版本,支持自然语言描述的图像编辑。例如:"将背景改为蓝色"、"添加一朵花"等。
商业使用相关
Q7: 我可以用 Z-Image 生成的图像进行商业用途吗?
A: 可以!Z-Image 使用 Apache 2.0 许可证,允许商业使用。但建议:
- 遵守当地法律法规
- 不生成侵犯他人权益的内容
- 注意敏感内容审核
- 生成的图像版权归属请咨询法律顾问
Q8: Z-Image 生成的图像会有水印吗?
A: 不会。Z-Image 生成的图像是纯净的,不包含任何水印或署名。
Q9: 如何批量生成大量图像?
A: 推荐方案:
- 本地部署: 使用 Python 脚本批量调用
- 云端 API: 使用 API易 等平台的 API 服务
- 分布式部署: 多台机器并行生成
💰 成本优化: 对于大规模批量生成需求(每月 > 1000 张),我们建议使用 API易 apiyi.com 平台的 Z-Image API 服务。平台提供灵活的包月套餐和按需付费选项,相比自建硬件可节省 60% 以上的成本,同时提供高并发支持和 7×24 技术支持。
技术问题
Q10: 遇到 "CUDA out of memory" 错误怎么办?
A: 解决方法:
- 降低图像分辨率 (从 2048 降到 1024)
- 使用 FP8 或 FP16 量化模型
- 减少批量生成数量
- 清理显存:
torch.cuda.empty_cache() - 关闭其他占用显存的程序
Q11: 为什么生成的中文文字有时不准确?
A: 可能原因和解决方案:
- 提示词不够明确 → 详细描述文字内容和位置
- 字体过于复杂 → 使用常见字体(楷体、宋体)
- 文字过多 → 限制在 10 个字以内
- 随机性影响 → 多生成几次,选择最好的
Q12: Z-Image 支持哪些图像分辨率?
A: Z-Image 理论上支持任意分辨率,但推荐使用:
- 1024×1024: 最佳性能和质量平衡
- 1024×768 / 768×1024: 适合横版/竖版图像
- 2048×2048: 高质量输出,但速度慢 4 倍
不推荐使用奇怪的分辨率(如 1080×1920),可能导致质量下降。
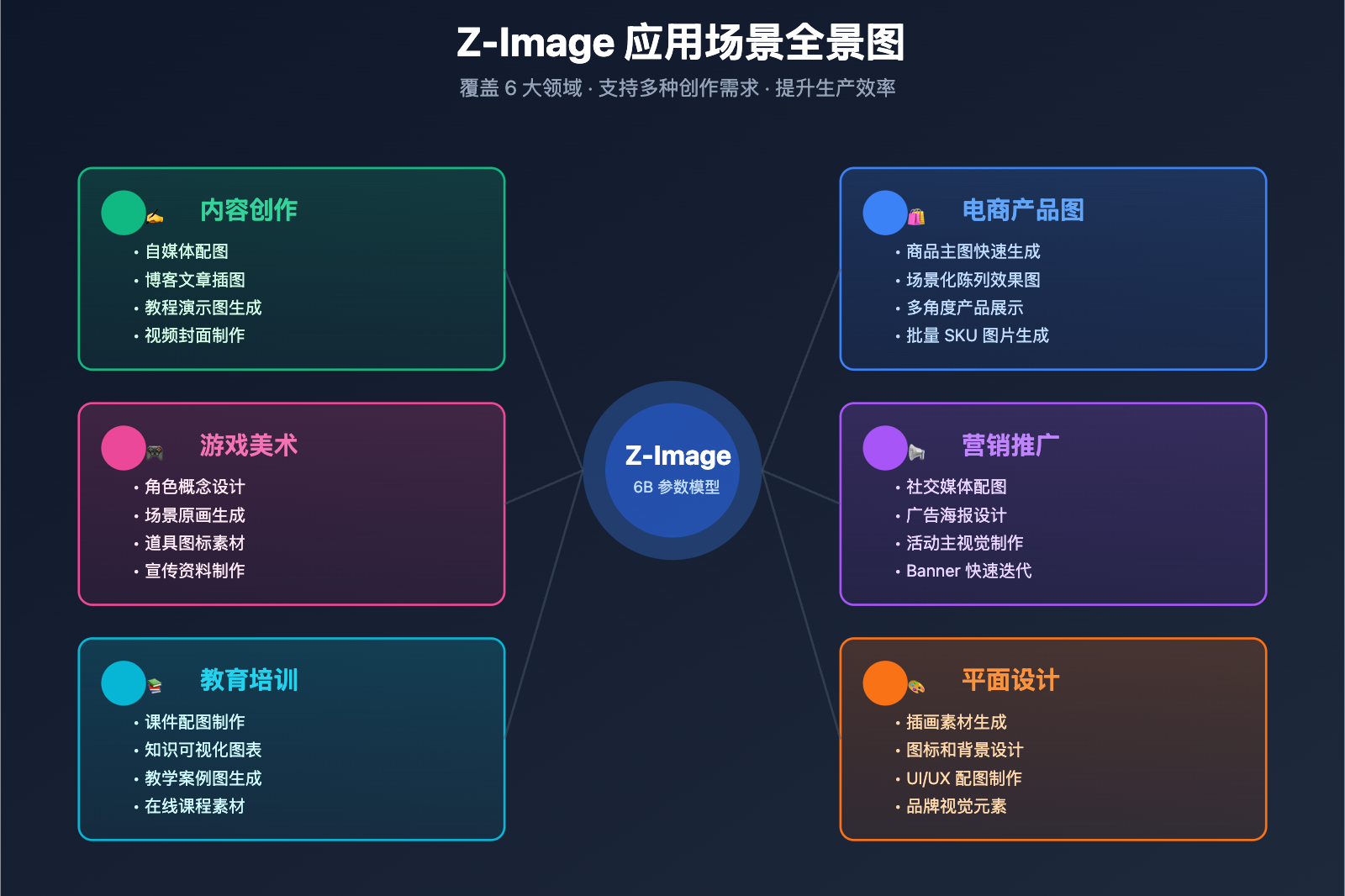
Z-Image 最佳实践与优化建议
硬件配置推荐
个人用户配置
入门级 (¥3000-5000):
- GPU: RTX 3060 12GB / RX 6600 XT 8GB
- CPU: Intel i5-12400 / AMD Ryzen 5 5600X
- 内存: 16GB DDR4
- 存储: 512GB NVMe SSD
- 适用场景: 学习测试,轻度创作
主流级 (¥8000-12000):
- GPU: RTX 4070 Ti 16GB / RTX 4080 16GB
- CPU: Intel i7-13700 / AMD Ryzen 7 7700X
- 内存: 32GB DDR5
- 存储: 1TB NVMe SSD
- 适用场景: 专业设计,日常创作
专业级 (¥20000-30000):
- GPU: RTX 4090 24GB
- CPU: Intel i9-13900K / AMD Ryzen 9 7950X
- 内存: 64GB DDR5
- 存储: 2TB NVMe SSD
- 适用场景: 批量生产,商业应用
企业级配置
云端部署 (按需付费):
- GPU: NVIDIA A100 40GB / H100 80GB
- 托管平台: AWS / Google Cloud / 阿里云
- 按小时/按次数计费
- 适用场景: 弹性负载,大规模并发
性能优化技巧
1. 使用模型编译
# 使用 Torch Compile 加速推理
import torch
from diffusers import ZImagePipeline
pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.bfloat16,
)
pipe.to("cuda")
# 编译模型 (首次运行较慢,后续加速显著)
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
# 之后的生成速度会提升 20-30%
2. 缓存优化
# 避免重复加载模型
class ZImageGenerator:
def __init__(self):
self.pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.bfloat16,
)
self.pipe.to("cuda")
def generate(self, prompt, **kwargs):
return self.pipe(prompt=prompt, **kwargs).images[0]
# 创建全局实例
generator = ZImageGenerator()
# 多次调用无需重新加载
image1 = generator.generate("一只猫")
image2 = generator.generate("一只狗")
3. 批量处理优化
# 使用多线程/多进程加速批量生成
from concurrent.futures import ThreadPoolExecutor
def generate_single(prompt):
return pipe(prompt=prompt, num_inference_steps=9).images[0]
prompts = ["提示词1", "提示词2", "提示词3", "提示词4"]
with ThreadPoolExecutor(max_workers=4) as executor:
images = list(executor.map(generate_single, prompts))
提示词优化工作流
步骤 1:基础提示词生成
使用 AI 辅助工具生成基础提示词:
用户需求: "我需要一张电商产品图"
↓
AI 生成基础提示词: "一台笔记本电脑放在桌面上,专业摄影"
步骤 2:细化和丰富
添加细节描述:
一台银色笔记本电脑放在木质桌面上,
屏幕显示着代码编辑器,
旁边放着咖啡杯和绿植,
柔和的自然光从左侧照射,
简约现代风格,商业摄影,4K 超清
步骤 3:测试和迭代
生成图像后,根据结果调整提示词:
- 图像过暗 → 添加"明亮光线"、"高亮度"
- 背景杂乱 → 添加"简洁背景"、"白色背景"
- 风格不对 → 调整风格描述词
步骤 4:保存优秀提示词
建立提示词库:
# 产品摄影模板
[产品名称] + 木质桌面 + 自然光 + 简约风格 + 商业摄影
# 人像摄影模板
[人物描述] + 柔和光线 + 浅景深 + 温暖色调 + 人像摄影
# 建筑摄影模板
[建筑描述] + 蓝天白云 + 对称构图 + 黄金时刻 + 建筑摄影
Z-Image 应用场景与案例
场景 1:电商产品图生成
需求: 为商品快速生成多样化的场景展示图
解决方案:
# 产品基础信息
product = "白色运动鞋"
# 生成多个场景
scenes = [
f"{product}放在木质地板上,自然光照射,简约风格",
f"一双{product},草地背景,户外运动场景",
f"{product}特写,工作室灯光,产品摄影",
f"穿着{product}的脚步,城市街道,街拍风格",
]
for i, prompt in enumerate(scenes):
image = pipe(prompt=prompt, num_inference_steps=9).images[0]
image.save(f"product_scene_{i+1}.png")
效果: 10 分钟生成 20+ 个场景图,成本仅为传统摄影的 1/100。
场景 2:社交媒体内容创作
需求: 为公众号/小红书快速生成配图
解决方案:
提示词模板:
"[主题内容],
扁平插画风格,鲜艳色彩,
简洁构图,现代设计感,
适合社交媒体,横版 16:9"
示例:
"健康饮食主题插画,
新鲜蔬菜水果,绿色健康,
扁平插画风格,清新配色,
适合小红书配图,横版 16:9"
场景 3:品牌视觉设计
需求: 为品牌快速生成视觉方案
解决方案:
Logo 设计提示词:
"[品牌名称] Logo 设计,
极简风格,几何图形,
蓝色渐变,现代科技感,
白色背景,矢量图形风格"
海报设计提示词:
"[活动名称]宣传海报,
顶部大字'[标题]'(粗体白色),
中间展示关键视觉元素,
底部'[时间地点]',
品牌色调,现代设计,4K 分辨率"
场景 4:游戏资产快速原型
需求: 为游戏设计快速生成场景概念图
解决方案:
"魔幻森林游戏场景,
巨大发光蘑菇,神秘雾气,
蜿蜒小径,奇幻光效,
游戏概念艺术,高细节,4K"
优势: 快速迭代设计方向,节省概念设计时间 70%。
Z-Image 未来发展与生态
技术路线图
根据 Z-Image 官方 GitHub 和社区讨论,未来计划包括:
近期更新 (1-3 个月):
- ✅ LoRA 微调支持
- ✅ Image-to-Image 功能增强
- ✅ ControlNet 集成
- ✅ 更多宽高比支持
中期目标 (3-6 个月):
- 🔄 5 步推理优化 (Turbo v2)
- 🔄 视频生成扩展
- 🔄 3D 资产生成
- 🔄 移动端优化版本
长期愿景 (6-12 个月):
- 💡 实时生成 (< 0.5 秒)
- 💡 多模态融合 (文本+音频+视频)
- 💡 个性化风格学习
- 💡 云端 API 服务
社区生态
开源项目
- ComfyUI 节点: 官方支持,无需第三方插件
- Stable Diffusion WebUI: 社区插件开发中
- Replicate API: 云端一键部署
- HuggingFace Spaces: 在线体验 Demo
商业服务
- API易平台: 国内首家支持 Z-Image API
- 魔搭社区: 阿里云托管版本
- Colab 笔记本: 免费体验环境
学习资源
- 官方文档: GitHub Wiki
- 视频教程: Bilibili UP 主分享
- 提示词库: 社区共建提示词数据库
- Discord 社区: 国际开发者交流
🌟 生态建设: API易 apiyi.com 作为国内首家支持 Z-Image 的 API 平台,提供了完整的开发文档、SDK 和技术支持。平台还计划推出 Z-Image 专题竞赛和奖励计划,鼓励开发者基于 Z-Image 构建创新应用,共同推动开源 AI 图像生成生态发展。
总结与行动建议
核心要点回顾
- Z-Image 是阿里巴巴通义开源的 6B 图像生成模型,仅需 8 步推理即可生成高质量图像
- 三种部署方式可选: Python/ComfyUI/WebUI,适合不同技术水平用户
- 原生双语文本渲染: 中英文海报、广告设计的最佳选择
- 消费级硬件友好: 最低 8GB 显存即可运行,16GB 体验最佳
- Apache 2.0 开源协议: 免费商用,无需授权费用
- 活跃的社区支持: 丰富的教程、工作流和应用案例
立即开始的 3 个步骤
步骤 1: 选择部署方式 (5 分钟)
- 开发者 → Python + Diffusers
- 设计师 → ComfyUI
- 小白用户 → WebUI 整合包
步骤 2: 熟悉提示词编写 (15 分钟)
- 阅读本文提示词模板
- 尝试生成 5-10 张测试图像
- 总结自己的提示词规律
步骤 3: 应用到实际项目 (30 分钟)
- 根据业务需求调整提示词
- 批量生成所需图像
- 优化生成参数和工作流
进阶学习路径
阶段 1: 基础掌握 (1 周)
- 熟练使用基础功能
- 掌握提示词编写技巧
- 了解参数调整方法
阶段 2: 深度应用 (2-4 周)
- 尝试 ComfyUI 高级工作流
- 探索图像编辑功能
- 优化生成效率和质量
阶段 3: 专业定制 (1-3 个月)
- 学习 LoRA 微调(即将支持)
- 开发自动化生成工具
- 构建企业级应用方案
获取支持
技术问题:
- GitHub Issues: https://github.com/Tongyi-MAI/Z-Image/issues
- HuggingFace 讨论区: https://huggingface.co/Tongyi-MAI/Z-Image-Turbo/discussions
商业咨询:
- API易平台: api.apiyi.com (国内首家 Z-Image API 服务)
- 帮助中心: help.apiyi.com
社区交流:
- Bilibili: 搜索"Z-Image 教程"
- 知乎: "Z-Image 使用经验"话题
通过本文的完整指南,您已经掌握了 Z-Image 从入门到精通的所有关键知识。无论是个人创作还是商业应用,Z-Image 都提供了一个强大、高效且经济实惠的 AI 图像生成解决方案。
💡 最后建议: 开源模型的最大价值在于自由度和可控性。如果您的团队希望快速上手而不想处理部署复杂性,可以从 API易 apiyi.com 平台的托管 Z-Image API 服务开始,先验证业务价值,再决定是否自建部署。平台提供按需付费和免费试用额度,适合快速 MVP 开发和技术验证。
祝您使用 Z-Image 创作出精彩的 AI 艺术作品! 🎨✨