作者注:分享 Claude Opus 4.7 处理 CSV 和 Excel 的实战经验,解释为什么不应直接把大表丢给 AI,而应让 AI 写脚本、建工具、做校验。
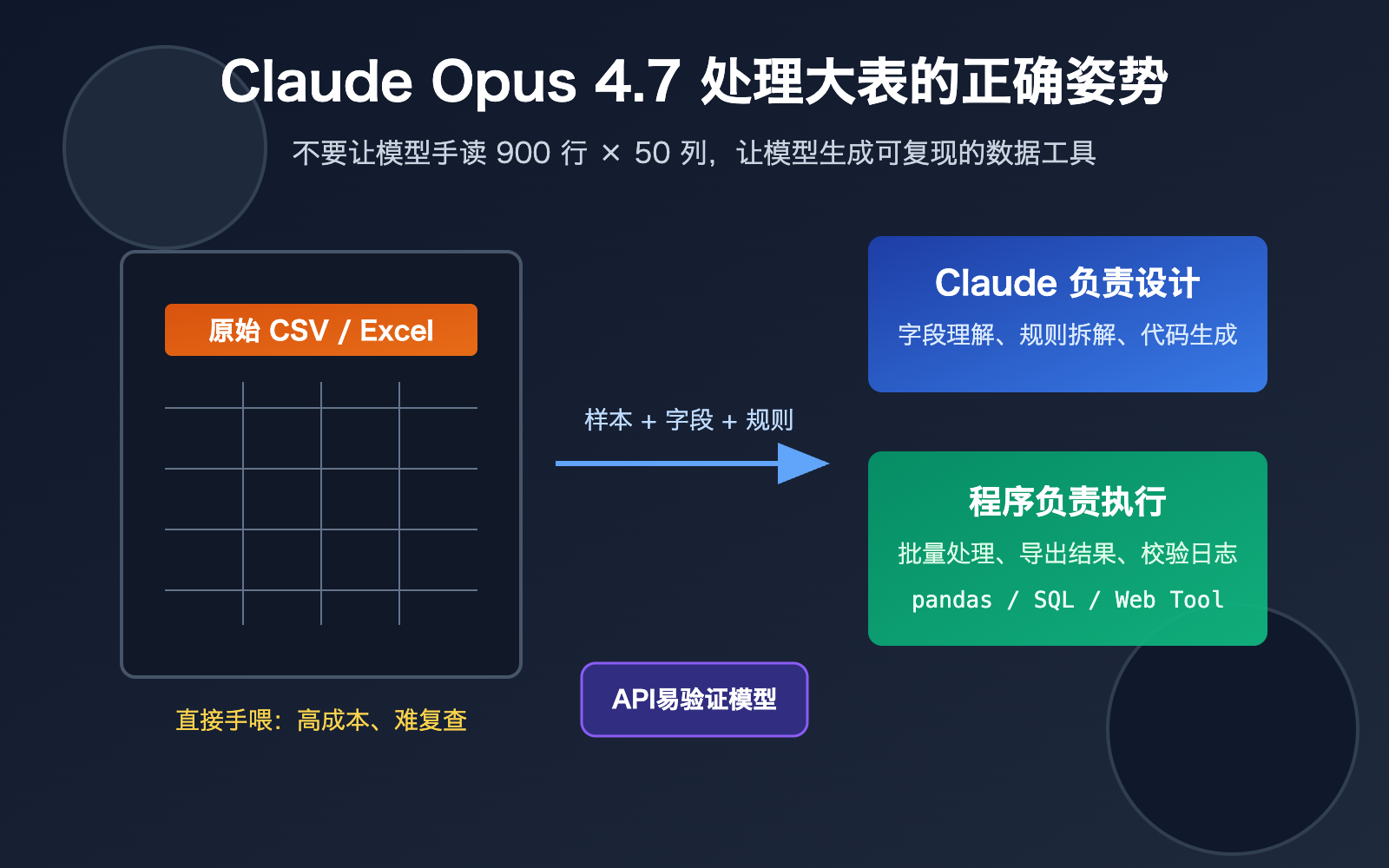
如果你拿着一个 900 多行、每行 50 列的 CSV 或 Excel 文件,直接问 Claude Opus 4.7「帮我处理一下这个表」,大概率会得到一个看似聪明、但不可复现的回答。问题不在于 Claude Opus 4.7 不够强,而在于你把它当成了人工读表员,而不是数据处理流程设计师。
更好的方法是:给 Claude Opus 4.7 一小段样本数据、完整字段说明和目标结果,让它写 Python 脚本、生成网页工具或设计可复现的数据管道,再用脚本处理完整数据。这样既能利用模型的推理和编码能力,又能让计算、筛选、聚合、校验交给确定性的程序完成。
Claude Opus 4.7 处理 CSV 的核心要点
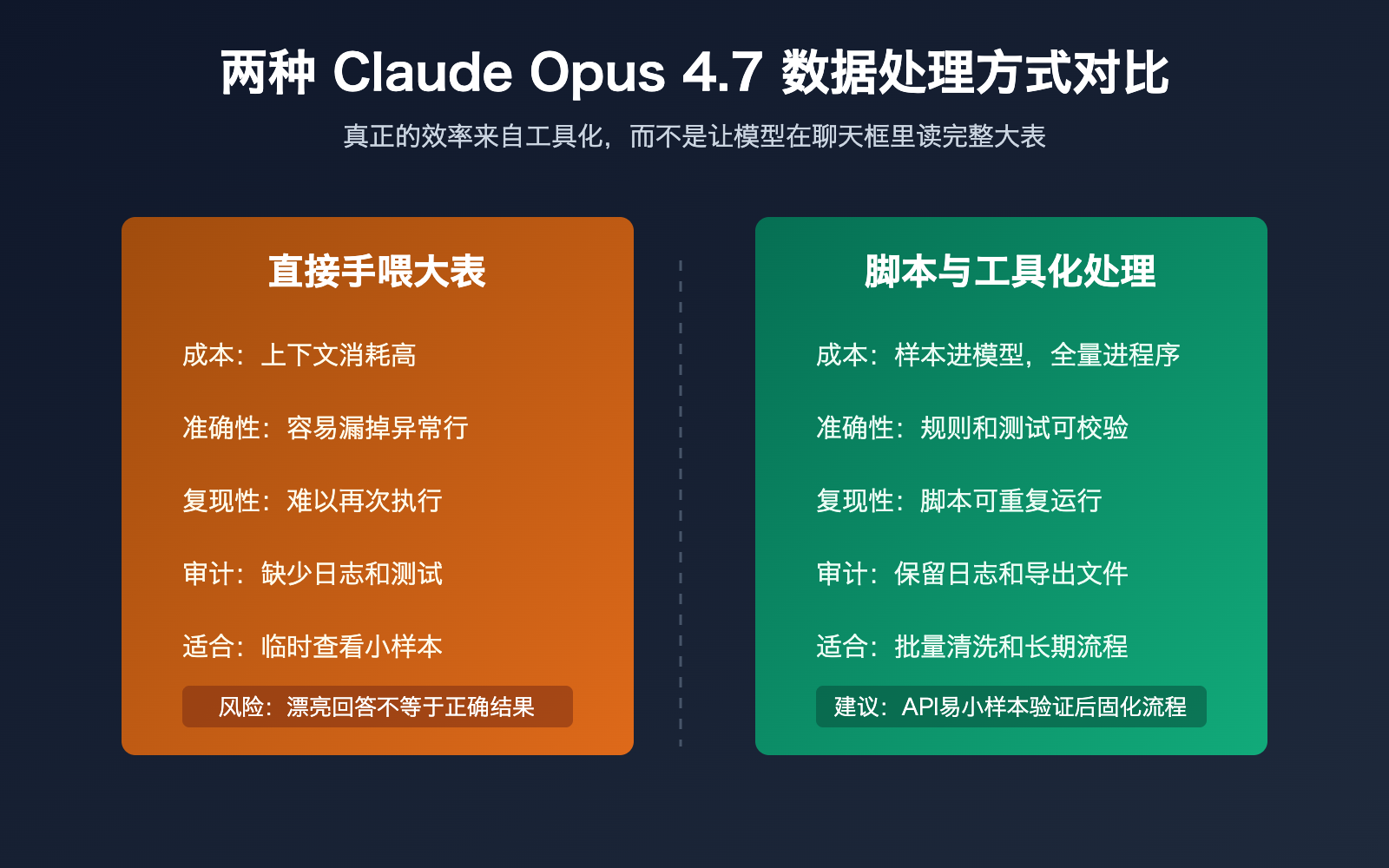
Claude Opus 4.7 已经是很强的 coding 和 agentic workflow 模型,官方也强调它适合复杂代码、企业工作流和 spreadsheet 场景。但「上下文窗口更大」并不等于「应该把整个表格塞进对话里」,尤其是当数据包含大量重复行、异常值、隐藏列、格式混乱和业务规则时,直接手喂原始数据既低效,也容易让结果难以审计。
真正高效的 Claude Opus 4.7 处理 CSV 方法,是把模型放在三个位置:理解业务目标、生成处理程序、解释输出结果。至于逐行读取、类型转换、去重、聚合、排序、导出文件,则应该交给 Python、SQL、浏览器端工具或 Claude 自带的数据分析工具链完成。
| 场景 | 直接让 AI 读表的问题 | 更推荐的 Claude Opus 4.7 做法 | 结果优势 |
|---|---|---|---|
| 900 行 × 50 列 CSV | 上下文消耗高,容易漏列漏行 | 给前 20 行样本和字段说明,让 Claude 写 pandas 脚本 | 可复现、可批量运行 |
| Excel 多 Sheet | 隐藏公式、合并单元格、格式影响理解 | 先让 Claude 写结构探测脚本,输出工作簿概览 | 先理解结构再处理 |
| 业务规则筛选 | 自然语言容易遗漏边界条件 | 让 Claude 把规则转成函数和测试用例 | 规则清晰,可验证 |
| 生成报表 | 一次性回答难以复查 | 让 Claude 生成导出脚本和校验摘要 | 输出稳定,便于交付 |
这里有一个很重要的判断:Claude Opus 4.7 可以「参与数据分析」,但不应该成为「数据本身的唯一执行环境」。如果你需要通过 API 反复验证数据处理提示词或模型选择,我们建议用 API易 apiyi.com 统一接口做小样本测试,再把稳定提示词沉淀到脚本中,避免每次都重新复制大表。
Claude Opus 4.7 处理 CSV 的分工原则
Claude Opus 4.7 最适合做高层次判断,例如字段含义推断、清洗策略设计、异常情况提示、代码生成和结果解释。它不适合在聊天框中承担确定性计算,因为聊天窗口里的表格文本会丢失部分结构信息,也不方便做重复运行和版本管理。
一个更稳的原则是「小样本给模型,大数据给程序」。你可以先提供前 20 行、随机 20 行、异常 20 行,再补充字段字典和目标输出。Claude Opus 4.7 根据这些信息生成脚本后,你再让脚本跑完整 CSV 或 Excel 文件,这样模型负责设计,程序负责执行。
Claude Opus 4.7 处理 Excel 为什么不能直接手喂大表
Excel 和 CSV 看起来都是表格,但它们的复杂度完全不同。CSV 是纯文本行列结构,Excel 还可能包含多个 Sheet、公式、格式、筛选状态、隐藏列、合并单元格、日期序列和本地化数字格式。把 Excel 直接复制成文本给 AI,通常会把这些关键信息压扁,导致模型看到的不是原始工作簿,而是被破坏后的平面文本。
官方英文资料显示,Claude 相关产品已经支持分析工具、代码执行、Data 插件以及 Excel 场景能力;这些方向都说明一个事实:表格处理应该依靠工具环境,而不是只靠语言模型在聊天窗口里「脑算」。即便 Claude Opus 4.7 支持更大的上下文,也应该把上下文用于业务规则、字段说明、样本示例和校验要求,而不是浪费在整张表的原始行列上。
| 数据特征 | 直接上传或粘贴的风险 | 推荐给 Claude Opus 4.7 的输入 | 推荐执行工具 |
|---|---|---|---|
| 列很多 | 模型难以稳定记住每列含义 | 字段字典、列类型、关键列说明 | pandas、SQL |
| 行很多 | Token 成本高,结果不可复现 | 头部样本、随机样本、异常样本 | Python 分块处理 |
| 多 Sheet | Sheet 关系容易丢失 | 工作簿结构摘要、Sheet 用途说明 | openpyxl、Excel 插件 |
| 数据脏 | 异常值会影响推断 | 缺失值统计、重复行统计、格式样例 | 数据质量脚本 |
| 规则复杂 | 自然语言解释容易跑偏 | 明确规则、反例、期望输出样例 | 单元测试、校验脚本 |
技术建议:如果你需要把 Claude Opus 4.7 接入现有数据处理系统,可以先通过 API易 apiyi.com 做接口级验证。建议先用小样本跑通提示词、模型参数和错误处理,再接入完整文件处理链路。
Claude Opus 4.7 处理 Excel 的关键误区
第一个误区是把「模型能看懂表格」理解成「模型应该直接处理大表」。在小文件、临时分析、探索性问答中,上传 CSV 或 Excel 很方便;但在批量清洗、客户名单评分、订单对账、财务分类这类任务里,你真正需要的是可重复执行的规则,而不是一次性的自然语言答案。
第二个误区是只给前 20 行样本。前 20 行通常只能展示正常结构,不能覆盖异常情况。更好的样本组合是「前 20 行 + 随机 20 行 + 异常 20 行 + 字段字典 + 目标输出 3 行」,这样 Claude Opus 4.7 才能写出更接近真实业务的处理逻辑。
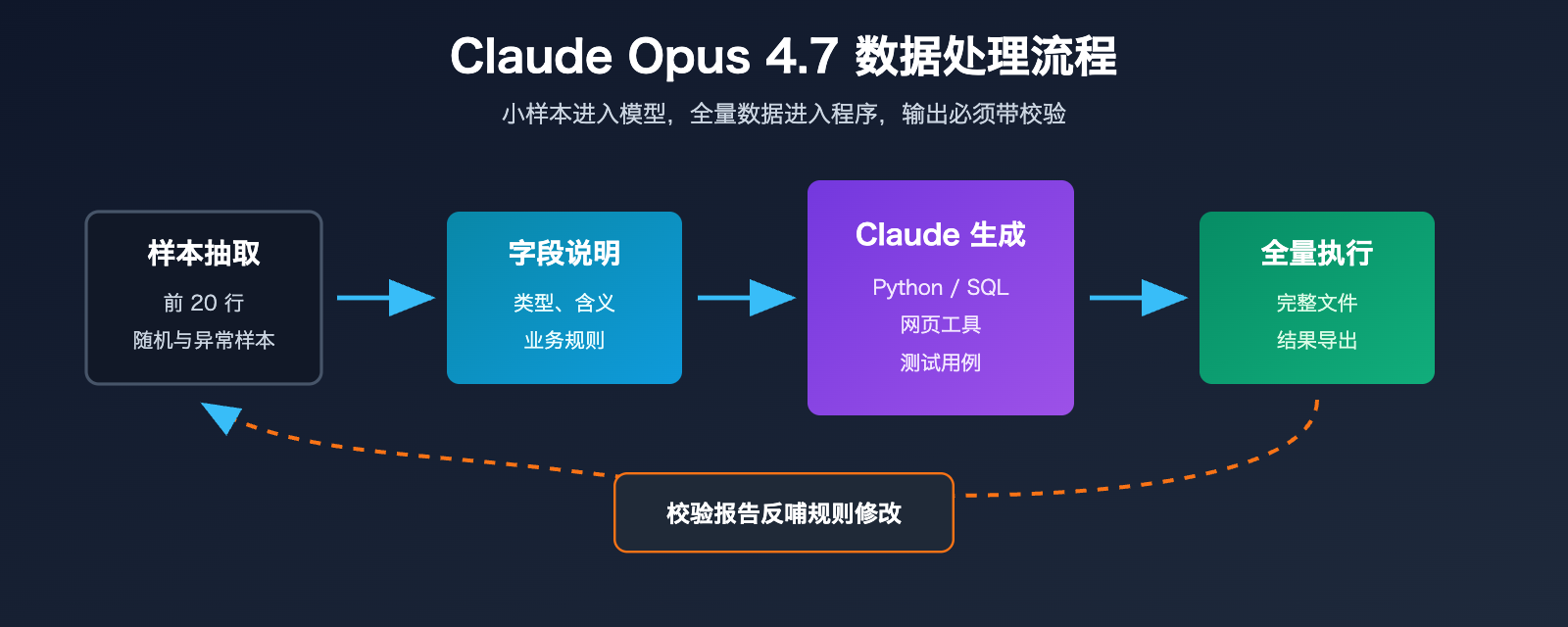
Claude Opus 4.7 处理 CSV 的 5 步工作流
下面这套流程适合大多数 CSV 和 Excel 自动化任务,尤其适合 500 行以上、字段超过 20 列、规则需要反复调整的场景。你不需要一开始就把完整文件交给模型,只要把样本、结构和目标说清楚,再要求它产出脚本、测试和输出说明。
| 步骤 | 给 Claude Opus 4.7 的材料 | 让 Claude 产出的内容 | 人类需要确认的点 |
|---|---|---|---|
| 1. 结构探测 | 文件格式、字段名、样本行 | 字段类型假设和清洗计划 | 字段含义是否正确 |
| 2. 规则定义 | 业务目标、筛选条件、反例 | 处理规则表和边界条件 | 是否覆盖业务例外 |
| 3. 脚本生成 | 样本数据、目标输出格式 | Python 或 SQL 处理脚本 | 是否能本地运行 |
| 4. 小样本验证 | 20 至 60 行样本 | 预期输出和测试断言 | 输出是否符合直觉 |
| 5. 全量执行 | 完整文件路径 | 结果文件、日志、校验报告 | 总数、金额、分组是否对齐 |
这套流程的核心价值,是把「一次问答」变成「可执行资产」。当业务规则变化时,你只需要让 Claude Opus 4.7 修改脚本和测试,而不需要重新上传完整数据、重新解释上下文、重新赌一次模型是否记住了所有细节。
Claude Opus 4.7 处理 CSV 的提示词模板
你可以直接复用下面的提示词结构。注意不要只贴 CSV 内容,还要明确字段含义、处理目标、异常样本和验收标准。模型越清楚「怎样算正确」,生成的脚本越稳定。
我有一个 CSV/Excel 数据处理任务,请不要直接给结论。
目标:
把客户表按行业、职位、公司规模打分,输出 top leads。
数据样本:
1. 前 20 行:...
2. 随机 20 行:...
3. 异常 20 行:...
字段说明:
- company_name:公司名
- title:联系人职位
- employee_count:员工数,可能为空
- industry:行业,可能存在同义词
请你完成:
1. 先解释字段和潜在数据质量问题
2. 写一个 Python 脚本读取 input.csv
3. 输出 cleaned.csv 和 scored.csv
4. 加入基础校验:行数、空值、重复值、分数分布
5. 不要假设未知字段含义,遇到不确定规则先标注 TODO
如果你要把这套流程做成 API 服务,可以把提示词模板、字段字典和样本数据作为固定输入,通过 API易 apiyi.com 调用 Claude Opus 4.7 或其他可用模型进行对比测试。这样可以快速判断不同模型在代码生成、规则解释和异常处理上的差异。
Claude Opus 4.7 处理 CSV 的 Python 示例
下面是一个极简版本,它体现了正确思路:Claude Opus 4.7 写脚本,脚本读完整文件,输出结果和校验摘要。真实项目里可以继续增加日志、异常处理、单元测试和配置文件。
import pandas as pd
INPUT = "input.csv"
OUTPUT = "scored.csv"
df = pd.read_csv(INPUT)
required = ["company_name", "title", "employee_count", "industry"]
missing = [col for col in required if col not in df.columns]
if missing:
raise ValueError(f"Missing columns: {missing}")
df["employee_count"] = pd.to_numeric(df["employee_count"], errors="coerce").fillna(0)
df["score"] = 0
df.loc[df["title"].str.contains("cto|chief|founder", case=False, na=False), "score"] += 40
df.loc[df["employee_count"].between(50, 500), "score"] += 30
df.loc[df["industry"].str.contains("ai|software|saas", case=False, na=False), "score"] += 30
print({"rows": len(df), "duplicates": int(df.duplicated().sum())})
df.sort_values("score", ascending=False).to_csv(OUTPUT, index=False)
如果你还需要模型解释输出结果,可以在脚本生成 summary.json 后,再把摘要交给 Claude Opus 4.7。对于多轮自动化任务,建议通过 API易 apiyi.com 统一管理模型调用、失败重试和日志留存,让数据处理链路更容易维护。
Claude Opus 4.7 处理 Excel 的工具选择
不同任务应该选择不同工具。临时探索可以用 Claude 的分析能力或 Data 插件,生产流程更适合 Python 脚本、SQL 管道或网页工具。如果团队里有非技术同事,可以让 Claude Opus 4.7 生成一个本地网页工具,把上传、规则选择、结果下载做成可视化界面。
| 工具方案 | 适合任务 | 不适合任务 | 推荐用法 |
|---|---|---|---|
| Python 脚本 | 批量清洗、评分、对账、导出 | 完全不懂命令行的团队 | 让 Claude 写脚本和 README |
| 本地网页工具 | 非技术人员反复处理同类文件 | 复杂后端权限和多人协作 | 让 Claude 生成 HTML/JS 或轻量服务 |
| SQL 管道 | 数据仓库、订单、日志分析 | 临时 Excel 小表 | 让 Claude 写查询和校验 SQL |
| Claude 数据工具 | 探索分析、图表、临时报表 | 强合规或需长期自动化任务 | 先探索,再沉淀为脚本 |
| API 工作流 | 多模型对比、自动化系统集成 | 一次性手工任务 | 通过统一接口调试 |
Claude Opus 4.7 处理 Excel 的网页工具思路
当用户不懂 Python 时,「让 Claude 写网页工具」往往比「让 Claude 直接读 CSV」更实用。网页工具可以提供上传按钮、字段映射、规则配置、结果预览和下载按钮,用户每次只需要换文件,不需要反复和 AI 对话。
你可以这样要求 Claude Opus 4.7:生成一个单文件 HTML 工具,使用 Papa Parse 读取 CSV,前端完成字段映射和评分,最后导出新 CSV。对于数据量不大、规则不涉密、只在本地浏览器运行的任务,这种方式非常经济;对于更复杂的权限、审计和大文件任务,则应升级到后端服务。
落地建议:如果你要把网页工具接入模型解释、字段映射建议或异常诊断,可以通过 API易 apiyi.com 调用模型接口,让前端只负责交互,后端负责模型请求和日志记录。
Claude Opus 4.7 处理 CSV 的校验清单
数据处理最怕的不是代码报错,而是代码安静地输出了错误结果。因此,无论你让 Claude Opus 4.7 写 Python、SQL 还是网页工具,都应该要求它同步生成校验清单。这个清单不需要复杂,但必须覆盖行数、字段、空值、重复值、关键指标和抽样复查。
| 校验项 | 为什么重要 | 推荐检查方式 | 异常处理建议 |
|---|---|---|---|
| 输入输出行数 | 防止误删或重复生成 | 对比 len(input) 和 len(output) |
输出差异说明 |
| 必需字段 | 防止字段名变化导致错算 | 检查列集合 | 缺字段立即报错 |
| 空值比例 | 防止评分或分类偏差 | 每列空值统计 | 超阈值写入警告 |
| 重复记录 | 防止重复计费或重复触达 | 主键或组合键去重 | 保留重复报告 |
| 金额与数量合计 | 防止聚合逻辑错误 | 分组前后总和对比 | 不一致则终止 |
| 抽样复查 | 发现规则理解偏差 | 随机抽取 20 行人工看 | 将问题反馈给 Claude 修改规则 |
实际使用中,你可以把这张表直接作为提示词的一部分,让 Claude Opus 4.7 在生成脚本时自动加入对应检查。我们在 API易 apiyi.com 做模型调用测试时,也建议把校验输出作为固定返回要求,这样便于比较不同模型的稳定性,而不是只看某一次回答是否漂亮。
Claude Opus 4.7 处理 CSV 的反例提示
不要只说「帮我清洗这个表」。更好的说法是「请先指出你需要哪些字段信息,再写脚本;不要直接给最终结论;每一步输出日志;对无法判断的规则标注 TODO;生成 5 条单元测试样例」。这类约束会迫使模型把隐含推断显性化,也能让你更快发现它是否误解了业务。
同样,不要把前 20 行样本当成完整事实。前 20 行适合让 Claude Opus 4.7 理解结构,但不足以覆盖脏数据。你应该额外提供异常样本,例如空值、重复、日期格式混乱、金额为负、枚举值拼写不一致、中文和英文混排等情况。
Claude Opus 4.7 处理 CSV FAQ
Claude Opus 4.7 处理 CSV 时,前 20 行样本够不够?
不够,但它是一个好的起点。前 20 行适合展示字段结构和正常记录,但无法覆盖异常数据;更推荐「前 20 行 + 随机 20 行 + 异常 20 行」的组合。把样本给 Claude Opus 4.7 后,应要求它写脚本跑完整文件,而不是只基于样本给结论。
Claude Opus 4.7 处理 Excel 时,应该上传整个文件吗?
如果是临时探索,可以上传文件并使用工具分析;如果是要长期复用的业务流程,应该让 Claude Opus 4.7 先写结构探测脚本,再生成处理脚本。对于 API 自动化场景,可以通过 API易 apiyi.com 先跑小样本,确认模型能稳定理解字段和规则后再接全量流程。
Claude Opus 4.7 处理 CSV 会不会因为 1M 上下文就不需要脚本?
不会。更大的上下文可以容纳更多字段说明、样本和业务背景,但它不能替代可复现的计算程序。尤其是涉及金额、排名、分组、去重、统计口径时,脚本和校验才是结果可信的基础。
Claude Opus 4.7 处理 Excel 与传统 BI 有什么区别?
Claude Opus 4.7 更适合把模糊需求转成规则、代码和解释,传统 BI 更适合稳定报表、权限、数据建模和多人协作。两者并不冲突:可以先用 Claude 生成清洗脚本和分析逻辑,再把稳定结果接入 BI 或数据仓库。
没有编程基础,Claude Opus 4.7 处理 CSV 还值得用吗?
值得,但建议让它生成本地网页工具或详细操作说明,而不是让它直接在聊天里输出最终结果。你可以要求它把处理逻辑做成按钮、表单和下载功能,自己只负责上传文件和检查结果。需要模型接口时,可以用 API易 apiyi.com 快速测试不同模型的代码生成效果。
Claude Opus 4.7 处理敏感 Excel 文件要注意什么?
敏感数据应先脱敏或在受控环境中处理,不要把身份证、手机号、客户合同、财务明细原样发送到不确定的环境。更稳妥的做法是提供脱敏样本和字段结构,让 Claude 写脚本,然后在本地或企业环境执行完整数据处理。
Claude Opus 4.7 处理 CSV Key Takeaways
- Claude Opus 4.7 处理 CSV 的最佳姿势,不是直接读完整大表,而是根据样本和规则生成可执行脚本。
- 前 20 行样本只能帮助模型理解结构,真实任务还需要随机样本、异常样本和字段字典。
- Excel 比 CSV 更复杂,多 Sheet、公式、隐藏列和格式都可能影响处理结果,应先做结构探测。
- 对于批量任务,Python、SQL、本地网页工具比聊天窗口中的一次性回答更可复现。
- 校验清单必须和处理脚本一起生成,重点检查行数、字段、空值、重复值和关键合计。
- API 自动化场景建议先做小样本模型测试,再把稳定方案接入生产链路。
Claude Opus 4.7 处理 Excel 的总结建议
Claude Opus 4.7 很适合处理数据任务,但正确方式不是「把表格扔给 AI」,而是「让 AI 设计工具来处理表格」。当数据规模达到几百行、几十列,或者业务规则需要多次复用时,脚本、网页工具、SQL 管道和校验报告才是更经济的选择。
你可以把 Claude Opus 4.7 当成数据工程助手:让它看小样本、问清规则、写处理脚本、生成测试、解释结果。这样既保留了大模型理解业务语义的优势,也避免了直接手喂原始数据带来的低效和不可审计。
如果你正在做 Claude Opus 4.7、CSV、Excel 或数据自动化相关开发,推荐先用 API易 apiyi.com 进行模型调用和提示词验证,再把稳定流程沉淀成脚本或工具。这样成本更可控,结果也更容易被团队复查和长期维护。
资料参考:
- Anthropic Claude Opus 4.7: anthropic.com/claude/opus
- Claude Opus 4.7 使用指南: claude.com/resources/tutorials/working-with-claude-opus-4-7
- Claude Code Execution Tool: platform.claude.com/docs/en/agents-and-tools/tool-use/code-execution-tool
- Claude Data Plugin: claude.com/plugins/data