2026년 4월 24일, DeepSeek은 Hugging Face를 통해 V4-Pro와 V4-Flash 두 가지 프리뷰 모델을 동시에 공개했습니다. 전자는 최첨단 성능을 지향하는 1.6T 파라미터 MoE 모델이며, 후자는 "Pro 모델 성능의 90% 수준을 유지하면서 가격은 1/12"인 가성비 끝판왕 모델입니다.
만약 딱 하나의 모델만 주목해야 한다면, 단연 deepseek-v4-flash입니다. 이유는 간단합니다.
- 284B / 13B MoE 아키텍처 + Hybrid Attention 적용, 1M 컨텍스트 윈도우 기준 추론 FLOPs가 V3.2 대비 27% 수준
- 1M 토큰 컨텍스트 / 384K 토큰 최대 출력, 긴 글도 청크(chunk)로 나눌 필요 없이 한 번에 처리
- 입력 $0.14, 출력 $0.28 (백만 토큰당), Pro 모델 대비 한 자릿수 저렴한 가격
- SWE-bench Verified 79.0%, Artificial Analysis Intelligence Index 45–47 기록, 대부분의 실무 환경에서 충분한 성능
- OpenAI ChatCompletions 및 Anthropic API 이중 프로토콜 호환, Claude Code / OpenClaw / OpenCode 등 기존 도구에 즉시 적용 가능
더 중요한 사실: 기존 deepseek-chat 및 deepseek-reasoner 모델은 2026년 7월 24일부로 서비스가 종료됩니다. 모든 온라인 비즈니스는 이 날짜 전까지 마이그레이션을 완료해야 합니다. 90일 카운트다운이 시작되었습니다.
다행인 점은 deepseek-v4-flash가 이미 APIYI(apiyi.com)에 상주해 있다는 것입니다. 별도의 DeepSeek 계정을 만들거나 SDK를 수정할 필요 없이, model 필드만 바꾸고 base_url을 api.apiyi.com으로 설정하기만 하면 바로 사용할 수 있습니다.
본 글은 3+5 구성으로 준비했습니다: V4-Flash 핵심 업그레이드 3분 요약 + 기존 모델에서 5분 만에 끝내는 마이그레이션 가이드.
1. deepseek-v4-flash의 5가지 핵심 업그레이드
1.1 핵심 사양 한눈에 보기
전체적인 사양을 먼저 확인해 보세요.
| 항목 | deepseek-v4-flash |
|---|---|
| 출시일 | 2026-04-24 (프리뷰) |
| 오픈소스 저장소 | huggingface.co/deepseek-ai/DeepSeek-V4-Flash |
| 총 파라미터 | 284B (Mixture of Experts) |
| 활성 파라미터 | 13B |
| 컨텍스트 윈도우 | 1M 토큰 |
| 최대 출력 | 384K 토큰 |
| 어텐션 아키텍처 | Hybrid Attention (CSA + HCA) |
| 추론 모드 | Thinking / Non-Thinking 이중 모드 |
| Function Calling | ✅ 지원 |
| JSON 모드 | ✅ 지원 |
| Chat Prefix Completion | Beta 지원 |
| API 프로토콜 | OpenAI ChatCompletions + Anthropic 이중 호환 |
| 입력 가격 | $0.14 / M 토큰 |
| 출력 가격 | $0.28 / M 토큰 |
이제 5가지 주요 업그레이드를 하나씩 살펴보겠습니다.
1.2 업그레이드 1: 1M 컨텍스트 + 384K 출력 (네이티브 초장문)
deepseek-v4-flash는 1M 토큰 입력과 384K 토큰 출력을 기본 지원합니다. 이는 V4 시리즈 전체의 공통 사양으로, Flash 모델이라고 해서 가격을 낮추기 위해 컨텍스트를 줄이지 않았습니다.
1M 토큰은 어느 정도일까요?
| 콘텐츠 유형 | 대략적인 토큰 수 |
|---|---|
| 10만 자 분량의 중문 원고 | ≈ 150K 토큰 |
| 200페이지 분량의 PDF 기술 문서 | ≈ 300K 토큰 |
| 중형 코드 저장소 (~50개 파일) | ≈ 500K–800K 토큰 |
| 소설 《홍루몽》 전체 | ≈ 1M 토큰 |
GPT-5.4(400K), Claude Opus 4.6(1M + 1M 컨텍스트 패키지), Gemini 3.1-Pro(2M)와 비교했을 때, V4-Flash의 1M은 업계 표준 사양이며 가격은 앞선 모델들보다 5~20배 저렴합니다.
1.3 업그레이드 2: 284B/13B MoE + Hybrid Attention
V4-Flash는 DeepSeek이 2026년에 도입한 두 가지 핵심 아키텍처 혁신을 사용합니다.
- MoE: 총 파라미터 284B, 토큰당 13B만 활성화. 13B 밀집 모델과 유사한 속도에 200B+ 밀집 모델 수준의 지식 범위를 가집니다.
- Hybrid Attention (CSA 압축 희소 어텐션 + HCA 고도 압축 어텐션): 긴 컨텍스트 처리를 위해 특별히 설계되었습니다.
효율성 실측 데이터 (DeepSeek 공식 자료):
| 지표 | V3.2 | V4-Flash | 개선율 |
|---|---|---|---|
| 1M 컨텍스트 단일 토큰 추론 FLOPs | 100% | 27% | -73% |
| 1M 컨텍스트 KV 캐시 점유율 | 100% | 10% | -90% |
이 수치들이 바로 Flash 모델이 $0.14라는 가격을 실현할 수 있는 이유입니다. 단순한 보조금이 아니라 기반 연산 비용 자체가 획기적으로 낮아졌기 때문입니다.
1.4 업그레이드 3: Thinking / Non-Thinking 이중 모드
V4-Flash 모델 ID 하나로 두 가지 모드를 전환할 수 있습니다.
- Non-Thinking (기본값): 빠르고 가벼워 일상 대화, 질의응답, 분류, 요약에 적합합니다.
- Thinking: OpenAI o 시리즈처럼 내부 추론 과정을 거친 후 최종 답변을 제시합니다. 복잡한 추론, 다단계 도구 호출, 코드 디버깅에 적합합니다.
요청 파라미터를 통해 모드를 전환하며, 개발 측면에서의 수정은 최소화됩니다. APIYI api.apiyi.com에서 호출할 때도 DeepSeek 공식 파라미터와 완전히 동일하게 사용할 수 있습니다.
1.5 업그레이드 4: 백만 토큰당 $0.14 / $0.28
이번 발표에서 가장 놀라운 수치입니다.
| 모델 | 입력 ($/M) | 출력 ($/M) | V4-Flash 대비 |
|---|---|---|---|
| deepseek-v4-flash | 0.14 | 0.28 | 1배 (기준) |
| deepseek-v4-pro | 1.74 | 3.48 | 12배 |
| GPT-5.4 (참고) | 2.50 | 10.00 | 17배–35배 |
| Claude Sonnet 4.6 (참고) | 3.00 | 15.00 | 21배–53배 |
"입력 500 토큰 + 출력 500 토큰" 요청 시 비용 비교:
- V4-Flash: $0.000 21 ≈ ¥0.0015
- GPT-5.4: $0.006 25 ≈ ¥0.045
- Claude Sonnet 4.6: $0.009 ≈ ¥0.065
Flash 모델이 30~40배 저렴합니다. 월간 호출량이 수억 토큰에 달하는 서비스라면, 이는 곧 수익률과 직결됩니다.
1.6 업그레이드 5: OpenAI + Anthropic 이중 프로토콜 호환
V4-Flash는 API 계층에서 두 가지 프로토콜을 모두 구현했습니다.
POST /v1/chat/completions→ OpenAI 형식POST /v1/messages→ Anthropic 형식
즉, 다음과 같은 이점이 있습니다.
| 클라이언트 | 마이그레이션 비용 |
|---|---|
| OpenAI Python/Node SDK | 수정 없음, base_url과 model만 변경 |
| Anthropic Python/Node SDK | 수정 없음, base_url과 model만 변경 |
| Claude Code | Anthropic 엔드포인트로 변경만 하면 끝 |
| OpenClaw / OpenCode | 네이티브 지원 |
| LangChain / LlamaIndex | base_url 변경만으로 충분 |
이는 DeepSeek이 이번 버전에서 내린 매우 현명한 결정입니다. 새로운 프로토콜을 강요하지 않고, 기존 생태계가 비용 없이 즉시 연결되도록 했습니다.
1.7 벤치마크 실측 비교표
| 벤치마크 | V4-Flash | V4-Pro | 차이 |
|---|---|---|---|
| SWE-bench Verified (코드 수정) | 79.0% | 82.1% | -3.1 |
| Terminal-Bench 2.0 (다단계 도구 사용) | 56.9% | 67.9% | -11.0 |
| SimpleQA-Verified (사실 관계 검증) | 34.1% | 57.9% | -23.8 |
| Artificial Analysis Intelligence Index | 45 / 47 | 58 | -11 ~ -13 |
해석: Flash는 단일 단계 코드 작업(SWE-bench)에서는 Pro와 거의 대등한 성능을 보이지만, 다단계 도구 체인이 필요한 작업(Terminal-Bench)이나 사실 관계 기억(SimpleQA)에서는 격차가 뚜렷합니다. 이 격차가 바로 "Flash를 쓸지, Pro를 쓸지"를 결정하는 핵심 기준이 됩니다.
2. deepseek-v4-flash vs V4-Pro 시나리오별 선택 가이드
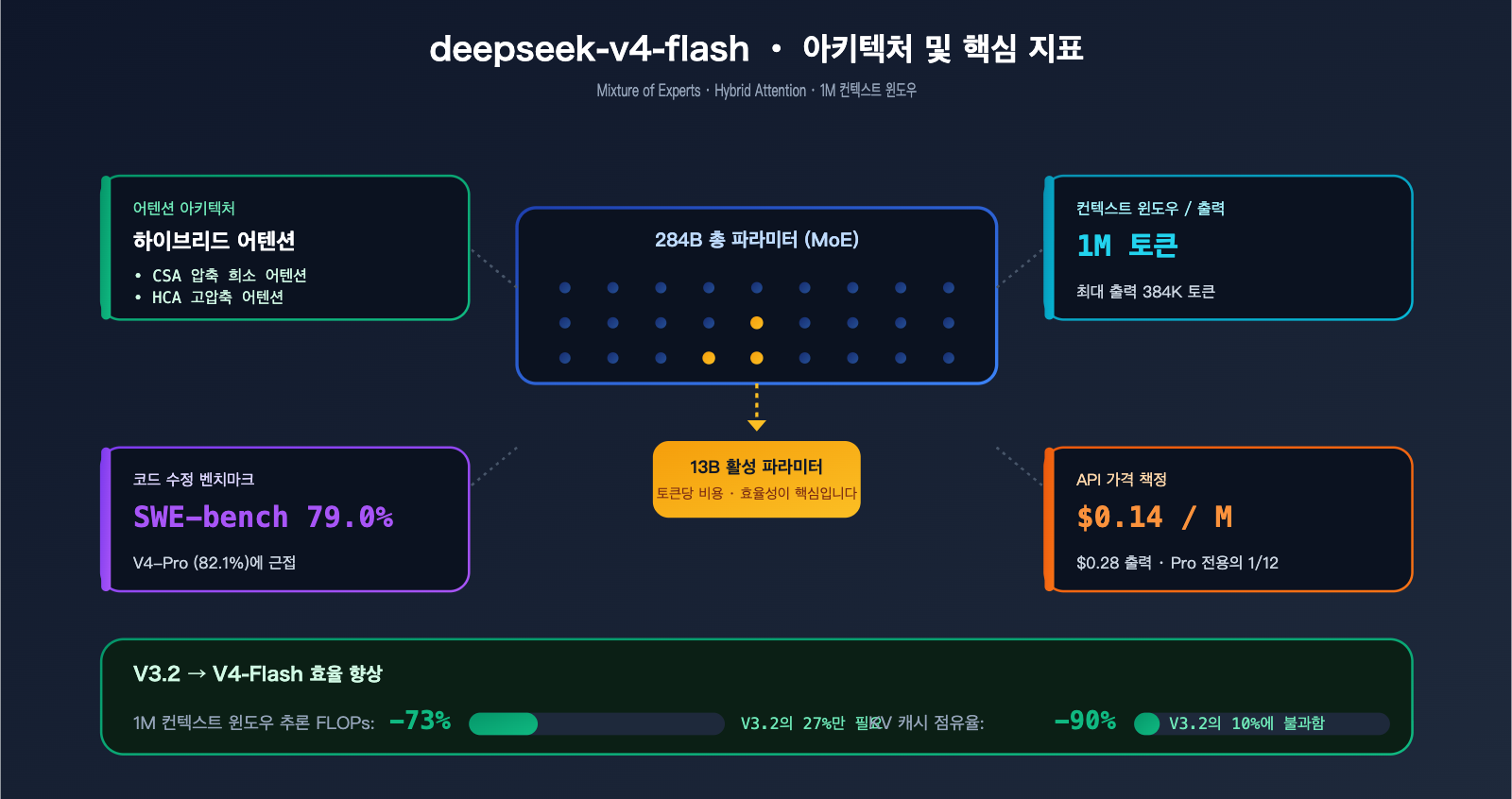
2.1 한눈에 보는 의사결정 매트릭스
| 시나리오 | 추천 모델 | 이유 |
|---|---|---|
| 일상 대화, 잡담, 질의응답 | Flash | 성능 충분, 가격은 1/12 |
| 고객 상담 봇, FAQ 시스템 | Flash | 높은 처리량, 낮은 지연 시간 |
| 코드 완성, 단일 파일 수정 | Flash | SWE-bench 79%, Pro와 근접 |
| 긴 문서 요약, 책 읽기 | Flash | 1M 컨텍스트 윈도우 지원 |
| 다단계 도구 체인 Agent | Pro | Terminal-Bench 11점 차이 |
| 심층 연구, 다회차 검증 | Pro | SimpleQA 24점 차이 |
| 고가치 비즈니스 보고서 생성 | Pro | Intelligence Index 11+ 포인트 높음 |
| 연구 / 탐색형 실험 | Flash | 12배 저렴, 빠른 반복 가능 |
일반 원칙: 기본적으로 Flash를 사용하고, 병목 현상이 발생하면 Pro로 업그레이드하세요. 이는 기술 선정 시 "간단한 솔루션으로 시작하고, 필요할 때 확장한다"는 원칙과 같습니다.
2.2 가성비 계산: 어느 규모부터 Flash가 더 경제적일까?
매일 1억 토큰(입력 6천만 + 출력 4천만)을 호출한다고 가정할 때:
| 모델 | 일일 비용 | 월 비용 | 연 비용 |
|---|---|---|---|
| V4-Flash | $19.6 | $588 | $7,056 |
| V4-Pro | $243.6 | $7,308 | $87,696 |
| GPT-5.4 (참고) | $550 | $16,500 | $198,000 |
Flash를 사용하면 Pro 대비 연간 $80K 이상 절약할 수 있습니다. 이 금액이면 개발자 반 명을 더 고용할 수 있는 수준이죠.
2.3 하이브리드 라우팅: 프로덕션 환경의 베스트 프랙티스
대부분의 서비스에서는 둘 중 하나만 선택하기보다, 요청 유형에 따라 동적으로 라우팅하는 것이 최적입니다.
def route_model(request_type: str) -> str:
# 채팅, FAQ, 요약, 분류 등은 Flash로 처리
if request_type in ("chat", "faq", "summarize", "classify"):
return "deepseek-v4-flash"
# 심층 연구, 다단계 에이전트 작업은 Pro로 처리
if request_type in ("deep_research", "multi_step_agent"):
return "deepseek-v4-pro"
return "deepseek-v4-flash" # 기본값은 Flash
🎯 도입 제안: APIYI(apiyi.com) 플랫폼에서 V4-Flash와 V4-Pro 모델 호출 권한을 모두 확보하는 것을 추천합니다. 두 모델은 하나의 API 키를 공유하므로
model필드만 변경하면 즉시 전환이 가능합니다. 대량 작업은vip.apiyi.com고성능 라인을, 복잡한 Pro 작업은 메인 사이트인api.apiyi.com을 활용하세요. 동일한 설정 내에서 비즈니스 로직에 따라 AB 트래픽 분배도 가능합니다.
3. 5분 만에 APIYI(apiyi.com)에서 deepseek-v4-flash 호출하기
3.1 Step 1: 환경 준비 및 API 키 발급
| 항목 | 요구 사항 |
|---|---|
| Python 또는 Node.js | Python 3.8+ / Node.js 18+ |
| 클라이언트 SDK | OpenAI Python openai >= 1.0 또는 공식 Node SDK |
| 네트워크 | api.apiyi.com 접근 가능 |
| 키 | APIYI apiyi.com 콘솔에서 생성, sk-로 시작 |
API 키 발급 방법:
apiyi.com에 접속하여 로그인 후 콘솔로 이동합니다.- 왼쪽 메뉴 → API Keys → 새 키 생성을 클릭합니다.
- 초기 테스트를 위해 '사용 한도'를 50~100위안 정도로 설정하는 것을 권장합니다.
sk-로 시작하는 키 문자열을 복사합니다.
3.2 Step 2: 라인 선택(base_url)
APIYI는 동일한 키로 사용 가능한 세 가지 라인을 제공합니다.
| base_url | 용도 | 추천 상황 |
|---|---|---|
https://api.apiyi.com/v1 |
메인 | 기본 설정, 일상적인 호출 |
https://vip.apiyi.com/v1 |
고성능 | 대량 이미지 생성/추론, 야간 작업 |
https://b.apiyi.com/v1 |
백업 | 메인 서버 불안정 시 자동 전환 |
일상적인 개발 시에는 메인 서버를 사용하고, 운영 환경에서 429 제한이나 5xx 오류가 발생할 경우 VIP/백업 서버로 전환하세요.
3.3 Step 3: Python 최소 호출 예제 (Non-Thinking)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "당신은 간결하게 답변하는 어시스턴트입니다."},
{"role": "user", "content": "DeepSeek V4-Flash의 핵심 업그레이드 3가지를 요약해줘."},
],
max_tokens=512,
)
print(resp.choices[0].message.content)
변경할 점은 딱 두 곳입니다:
base_url을api.apiyi.com으로 설정model을deepseek-v4-flash로 변경
나머지 OpenAI SDK 코드는 그대로 유지하면 됩니다.
3.4 Step 4: Thinking 추론 모드 활성화
심층 추론이 필요할 때는 요청 시 reasoning 파라미터를 추가하세요:
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "user", "content": "증명: n개의 점이 주어졌을 때, 모든 점 쌍을 덮기 위해 필요한 최소 직선의 개수는?"},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=8192,
)
# 응답에 reasoning_content 필드가 포함됩니다.
print("사고 과정:", resp.choices[0].message.reasoning_content)
print("최종 답변:", resp.choices[0].message.content)
Thinking 모드는 문제 복잡도에 따라 시간이 2~5배 정도 더 걸릴 수 있지만, 코드나 수학 문제의 정확도가 눈에 띄게 향상됩니다.
3.5 Step 5: Node.js 최소 호출 예제
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_API_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const resp = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [
{ role: "user", content: "2026년 AI에 관한 하이쿠를 써줘" },
],
max_tokens: 256,
});
console.log(resp.choices[0].message.content);
3.6 Step 6: Function Calling 예제
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "도시의 현재 날씨를 가져옵니다",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
},
}]
resp = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "오늘 상하이 날씨 어때?"}],
tools=tools,
)
print(resp.choices[0].message.tool_calls)
V4-Flash는 단일 도구 호출 시 매우 안정적입니다. 다단계 복잡 도구 체인(5단계 이상)을 사용할 경우 V4-Pro로 업그레이드하는 것을 권장합니다.
3.7 Step 7: Anthropic 프로토콜 호출
Anthropic SDK 기반으로 개발된 프로젝트(예: Claude Code 통합)도 그대로 사용할 수 있습니다:
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com",
)
resp = client.messages.create(
model="deepseek-v4-flash",
max_tokens=1024,
messages=[{"role": "user", "content": "안녕"}],
)
print(resp.content[0].text)
🎯 이중 프로토콜 팁: 동일한 deepseek-v4-flash 모델이라도 OpenAI 프로토콜은
api.apiyi.com/v1을, Anthropic 프로토콜은api.apiyi.com(/v1제외)을 사용합니다. 전환 시 base_url만 변경하세요. 자세한 내용은 APIYI 공식 문서docs.apiyi.com의 DeepSeek 섹션을 참고하세요.
4. 기존 모델에서 deepseek-v4-flash로 마이그레이션하기

4.1 마이그레이션이 필수인 이유: 90일 카운트다운
DeepSeek 공식 발표에 따르면:
기존 모델
deepseek-chat및deepseek-reasoner는 2026년 7월 24일부로 서비스가 종료됩니다.
모델을deepseek-v4-pro또는deepseek-v4-flash로 업데이트해 주세요.
2026년 7월 24일 이후에는 기존 모델 ID를 사용하는 요청은 오류를 반환합니다. 발표일(2026년 4월 24일)로부터 총 90일의 유예 기간이 주어집니다.
4.2 마이그레이션 결정표
현재 사용 중인 모델에 맞춰 새 모델을 선택하세요:
| 기존 모델 ID | 새 모델 ID | 마이그레이션 난이도 |
|---|---|---|
deepseek-chat |
deepseek-v4-flash (Non-Thinking 모드) |
⭐ 필드 1개 수정 |
deepseek-reasoner |
deepseek-v4-flash + Thinking 모드 |
⭐⭐ 모델 변경 + reasoning 파라미터 추가 |
deepseek-reasoner (고가치 시나리오) |
deepseek-v4-pro + Thinking 모드 |
⭐⭐ 모델 변경 + reasoning 파라미터 추가 |
deepseek-v3.x |
deepseek-v4-flash |
⭐ 모델 변경 |
deepseek-coder 등 전용 모델 |
deepseek-v4-flash |
⭐ 모델 변경 (범용 능력으로 대체 가능) |
4.3 코드 Diff: 거의 수정할 것이 없음
변경 전:
resp = client.chat.completions.create(
model="deepseek-chat", # ← 기존 모델
messages=[...],
)
변경 후:
resp = client.chat.completions.create(
model="deepseek-v4-flash", # ← 이 줄만 수정
messages=[...],
)
deepseek-reasoner에서 마이그레이션하는 경우:
resp = client.chat.completions.create(
- model="deepseek-reasoner",
+ model="deepseek-v4-flash",
messages=[...],
+ extra_body={"reasoning": {"enabled": True}},
)
4.4 마이그레이션 체크리스트
마이그레이션 전 다음 항목을 확인하세요:
- 코드 내
model=하드코딩 위치 모두 파악 -
deepseek-reasoner호출을 V4-Pro로 업그레이드할지 평가 - 회귀 테스트 프롬프트 세트 준비 (핵심 비즈니스를 포괄하는 20~50개)
- APIYI
apiyi.com콘솔에서 기존 요청의 일일 한도를 일시적으로 낮춰 마이그레이션을 강제 유도 - 신규/기존 모델 AB 테스트 1주일 진행, 출력 품질 비교
- 토큰 소모량 추이 모니터링, 비용 급증 여부 확인
- 내부 문서 및 운영 매뉴얼(Runbook) 업데이트
4.5 단계적 배포 제안
3단계 배포:
| 단계 | 트래픽 | 기간 | 목표 |
|---|---|---|---|
| 1단계 | 5% | 1주차 | 프로토콜 및 기본 출력 검증 |
| 2단계 | 30% | 2~3주차 | 주요 지표 비교 (품질 + 비용) |
| 3단계 | 100% | 4주차 | 전체 마이그레이션, 기존 키는 긴급 롤백용으로 보관 |
💡 긴급 롤백: APIYI apiyi.com의 기존 모델 라우팅은 2026년 7월 24일까지 호환성을 유지합니다. 마이그레이션 중 심각한 문제가 발생하면
model을 다시deepseek-chat/deepseek-reasoner로 변경하여 즉시 복구할 수 있습니다. 하지만 7월 말까지 미루지 마세요.
五、deepseek-v4-flash 자주 묻는 질문(FAQ)
Q1:Flash와 Pro 중 무엇을 선택해야 할까요?
한 문장 요약: 기본은 Flash, 성능 한계에 부딪히면 Pro로 업그레이드하세요. 구체적인 상황은 다음과 같습니다:
- 단일 대화, FAQ, 분류, 요약, 코드 완성 → Flash
- 다단계 에이전트 워크플로우(5단계 이상의 도구 호출) → Pro
- 심층 연구형 작업 → Pro
- 확실하지 않다면, 먼저 Flash로 실행해 보고 결과가 부족할 때 Pro로 전환하세요.
Q2:1M 컨텍스트 윈도우를 정말 다 쓸 수 있나요?
네, 가능합니다. 하지만 다음 사항을 주의하세요:
- 앞부분 100K–300K: 모델의 집중력이 가장 높고 결과가 가장 좋습니다.
- 300K–800K: 결과가 여전히 안정적입니다.
- 800K–1M: 정보 회수율이 떨어질 수 있으므로, 핵심 정보는 앞이나 뒤에 배치하는 것이 좋습니다.
- 비용 알림: 1M 토큰 입력 ≈ $0.14로, 저렴하지만 무료는 아닙니다.
긴 문서를 다룰 때는 "앞부분에 질문 배치 + 중간에 자료 배치 + 뒷부분에 질문 재강조" 구조를 추천합니다.
Q3:Thinking 모드는 어떻게 활성화하나요?
OpenAI 프로토콜 환경에서는 extra_body.reasoning.enabled=true를 통해 활성화할 수 있습니다. effort 매개변수는 low / medium / high를 선택할 수 있으며, 기본값은 medium입니다. APIYI api.apiyi.com에서도 공식과 동일한 매개변수를 사용합니다.
Q4:Flash에서 Function Calling은 안정적인가요?
단일 호출은 매우 안정적입니다(95% 이상의 성공률). 다단계 도구 체인(5단계 이상)의 경우 Pro 사용을 권장합니다. Terminal-Bench 2.0에서 나타나는 11점 차이가 바로 여기서 발생합니다.
Q5:적절한 동시성(Concurrency)은 어느 정도인가요?
개인 개발자라면 10–20 동시성은 문제없습니다. 프로덕션 환경에서는 다음을 권장합니다:
- 기본:
api.apiyi.com을 통해 50 동시성 사용 - 일괄/야간 작업:
vip.apiyi.com으로 전환하여 200+ 동시성까지 가능 - 긴급 대응:
b.apiyi.com으로 임시 폴백(fallback)
구체적인 상한선은 docs.apiyi.com에서 최신 할당량 설명을 확인하세요.
Q6:마이그레이션 리스크는 어떻게 평가하나요?
3단계 방법을 추천합니다:
- 출력 품질: 업무용 프롬프트 20–50개를 사용하여 AB 테스트를 진행하고, 사람이 직접 평가하거나 평가용 모델을 사용하세요.
- 비용 곡선: 일일 토큰 소모량을 관찰하세요. Flash의 출력 토큰은 보통 약간 더 많을 수 있습니다(Thinking 모드에서 더 두드러짐).
- 지연 시간: Flash의 TTFT(첫 토큰 생성 시간)는 V3.5와 비슷하지만, Thinking 모드는 2–5배 더 느릴 수 있습니다.
품질 저하가 10%를 넘으면 Pro로 업그레이드하고, 그렇지 않다면 안심하고 마이그레이션하세요.
Q7:Anthropic 프로토콜 호환은 어떻게 사용하나요?
base_url에 /v1을 붙이지 않고, 바로 POST /v1/messages를 호출하세요. Anthropic SDK의 model 필드에 deepseek-v4-flash를 입력하면 됩니다. 이는 이미 Claude SDK를 사용하는 프로젝트에 매우 간편한 마이그레이션 방법입니다.
Q8:컨텍스트 캐싱 혜택이 있나요?
V4-Flash는 자동 컨텍스트 캐싱(context caching)을 지원하므로, 접두사가 중복되는 요청은 실제 과금액이 더 낮아집니다. 긴 시스템 프롬프트를 사용하는 경우 30–50%의 비용을 절감할 수 있습니다. 이 혜택은 APIYI apiyi.com 플랫폼에서 기본적으로 활성화되어 있으며, 별도의 매개변수가 필요 없습니다.
六、deepseek-v4-flash 도입 요약
이번 DeepSeek V4 출시와 관련하여 개발자가 알아야 할 핵심 사실 두 가지입니다:
- 저렴해짐: V4-Flash는 Pro 성능에 근접하면서도 가격은 1/12 수준인 $0.14/M(입력)으로 업계 최저가를 기록했습니다.
- 마이그레이션 필요: 2026-07-24에 구형 모델이 공식 종료되며, 출시일부터 90일간의 유예 기간이 카운트다운됩니다.
다행인 점은 deepseek-v4-flash가 이미 APIYI apiyi.com에 출시되었다는 것입니다. 해외 계정을 직접 만들거나, SDK를 수정하거나, 결제 수단을 고민할 필요가 없습니다. 다음 3단계로 끝낼 수 있습니다:
- ✅
apiyi.com콘솔에서 키 발급 - ✅
base_url을api.apiyi.com/v1으로 설정(예비:vip.apiyi.com/b.apiyi.com) - ✅
model을deepseek-v4-flash로 설정하고 나머지 코드는 그대로 유지
🎯 행동 제안: 오늘 바로 deepseek-v4-flash AB 테스트를 시작하는 것을 강력히 권장합니다. APIYI apiyi.com에서 전용 키를 발급받아 업무용 프롬프트 20–50개를 실행해 보고, 기존 모델의 출력 품질과 비용을 비교해 보세요. 눈에 띄는 품질 저하가 없다면 이번 주 내로 트래픽의 5%를 전환하고, 4주 안에 전체 마이그레이션을 완료하세요. 7월까지 미루는 것보다 훨씬 여유롭습니다. 더 자세한 마이그레이션 사례와 벤치마크 스크립트는
docs.apiyi.com의 DeepSeek V4 칼럼을 참고하세요.
deepseek-v4-flash의 가치는 단순히 "또 하나의 저렴한 모델"이 아니라, "소수의 거대 기업만 누리던 성능을 누구나 사용할 수 있는 가격대로 낮췄다"는 점에 있습니다. 1M 컨텍스트로 책 한 권을 읽고, Thinking 모드로 복잡한 추론을 수행하며, Function Calling으로 모든 도구를 연결하는 이 모든 능력을 매우 저렴한 비용으로 사용할 수 있습니다. 이는 새로운 제품 기회를 열어줄 것이며, 먼저 마이그레이션을 마치는 사람이 시장을 선점할 것입니다.
작성자: APIYI 기술팀
관련 리소스:
- DeepSeek 공식 공지: api-docs.deepseek.com/news/news260424
- Hugging Face 오픈소스 저장소: huggingface.co/deepseek-ai/DeepSeek-V4-Flash
- APIYI 공식 홈페이지: apiyi.com
- APIYI 문서: docs.apiyi.com
- APIYI 메인 사이트: api.apiyi.com (예비: vip.apiyi.com / b.apiyi.com)