Gemini 3 Pro Image 인터페이스를 호출해 이미지를 생성할 때, 응답으로 받은 첫 번째 이미지를 그대로 사용자에게 보여주면 문제가 생길 수 있습니다. 구도가 이상하거나, 디테일이 뭉개지거나, 심지어 화면 일부가 잘린 결과물이 나오는 경우죠. 이는 모델의 성능이 떨어진 것이 아니라, 잘못된 이미지를 선택했기 때문일 가능성이 큽니다. 응답에 포함된 첫 번째 이미지는 모델의 '사고 초안'일 확률이 높으며, 진짜 완성본은 응답의 마지막 이미지일 가능성이 높습니다.
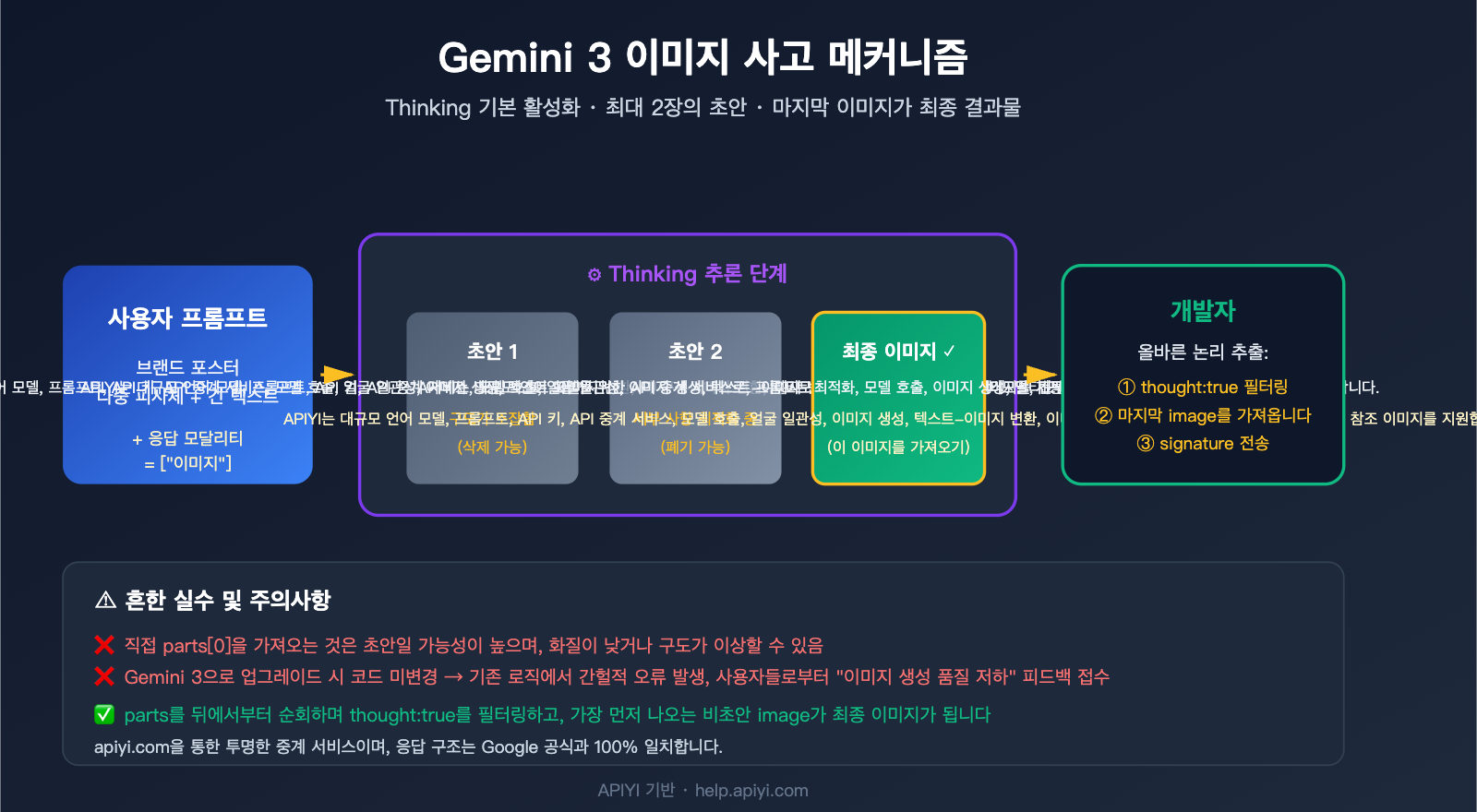
이 글은 Google AI 공식 문서를 바탕으로 Gemini 3의 이미지 사고(Thinking) 메커니즘과 응답 구조를 상세히 분석합니다. 왜 한 번의 호출로 2~3개의 이미지가 반환되는지, part.thought 필드와 thought_signature 서명을 사용해 최종 결과물을 정확히 식별하는 방법을 설명하고, Python, Node.js, cURL 환경에서 활용할 수 있는 올바른 추출 코드를 제공합니다. 모든 예시는 APIYI(apiyi.com)의 투명한 중계 서비스를 기준으로 하며, 중계 계층은 Gemini의 원본 응답 구조를 그대로 유지하므로 개발자는 공식 규격에 따라 처리하기만 하면 됩니다.
Gemini 3 이미지 사고 메커니즘의 핵심 원리
코드를 작성하기 전에, 왜 한 번의 호출로 여러 이미지가 반환되는지에 대한 근본적인 문제를 짚고 넘어갑시다.
Gemini 3 이미지 사고 기능을 끌 수 없는 이유
Google은 gemini-3-pro-image-preview(상품명: Nano Banana Pro)에 Gemini 텍스트 모델과 동일한 계통의 "Thinking" 메커니즘을 도입했습니다. 모델은 최종 이미지를 출력하기 전에 최대 2장의 임시 이미지를 사용해 구도, 배치, 텍스트 렌더링을 테스트합니다. 인간 디자이너가 최종 결과물을 내놓기 전 초안을 그리는 것과 같은 이치입니다.
공식 문서에 명시된 3가지 핵심 사실은 다음과 같습니다:
| 사실 | 설명 |
|---|---|
| 기본 활성화 (종료 불가) | Thinking 기능은 API 계층에서 강제로 활성화되며, 끄는 파라미터가 없습니다 |
| 최대 2장의 임시 이미지 | 모델은 최대 2장의 사고 초안을 생성할 수 있으며, 항상 생성되는 것은 아닙니다 |
| 마지막 이미지가 최종 결과물 | Thinking 단계의 마지막 이미지가 최종 렌더링 결과로 간주됩니다 |
| 사고 토큰 과금 | 사고 내용을 반환하도록 요청하지 않아도, 사고 토큰은 소모되며 과금됩니다 |
다시 말해, 당신이 받는 응답에는 자연스럽게 여러 이미지가 포함되어 있습니다. 이는 버그가 아닌 설계입니다. 핵심은 "이 기능을 어떻게 끌 것인가"가 아니라 "어떻게 최종 이미지만 정확히 가져올 것인가"입니다.
🎯 아키텍처 이해: Gemini 3 이미지 사고 메커니즘은 Gemini 3 Pro 텍스트 모델의 추론 체인과 동일한 기본 Thinking 엔진을 사용합니다. 이것이 Nano Banana Pro가 긴 텍스트 렌더링이나 다중 객체 일관성 측면에서 구버전인 Nano Banana보다 월등한 이유입니다. APIYI(apiyi.com)를 통해 호출할 때 모든 Thinking 동작은 Google과의 직결 환경과 동일하게 유지되며, 중계 계층에서 어떠한 사고 데이터도 제거하지 않습니다.
개발자들이 자주 겪는 실수 사례
사용자 커뮤니티에서 가장 흔히 발생하는 시행착오 유형은 다음과 같습니다:
API 호출 → 응답 수신 → 응답 내 parts 배열 확인 → parts[0]의 image를 바로 선택 → 사용자에게 보여줌
이 의사 코드는 구버전인 Nano Banana(Gemini 2.5 Flash Image) 시절에는 잘 작동했습니다. 당시에는 기본적으로 한 장의 이미지만 반환했기 때문이죠. 하지만 Gemini 3 Pro Image로 업그레이드한 후 동일한 코드를 사용하면 "사고 초안"을 최종 결과물로 오인하게 됩니다. 그 결과 사용자는 프롬프트 설명과 맞지 않거나 구도가 이상한 '반제품' 이미지를 보게 되는 것입니다.
이 문제는 다음과 같은 이유로 발견하기가 매우 까다롭습니다:
- 매번 발생하는 것이 아님: 간단한 프롬프트는 모델이 Thinking을 유발하지 않아 단일 이미지만 반환할 수 있습니다.
- 오류가 발생하지 않음: 응답 구조 자체가 정상적이므로
parts[0]를 가져올 때 예외가 발생하지 않습니다. - 품질은 떨어지지만 이미지는 존재함: 사용자는 모델 성능 문제라고 생각하지만, 실제로는 이미지를 잘못 선택한 것입니다.
Gemini 3 이미지 사고(Thinking) 응답 구조 상세 분석
API 호출 시 어떤 데이터가 반환되는지 정확히 파악하는 것은 개발의 첫걸음입니다.
응답 전체 parts 배열 구조
Gemini 3 Pro Image의 사고 기능(Thinking)이 활성화되면 response.candidates[0].content.parts는 다음과 같은 형태를 띱니다:

candidates[0].content.parts = [
{ text: "구도를 고려해야 해...", thought: true },
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, # 초안 1
{ inline_data: { mime_type: "image/png", data: "..." }, thought: true }, # 초안 2
{ inline_data: { mime_type: "image/png", data: "..." }, thought_signature: "..." } # 최종 이미지
]
이 배열에 대한 오해는 대부분의 버그를 유발합니다. 다음 3가지 규칙을 기억하면 올바른 코드를 작성할 수 있습니다.
최종 이미지를 식별하는 3가지 공식 신호
구글이 제시한 최종 이미지 식별 신호를 우선순위에 따라 활용하세요.
| 우선순위 | 식별 신호 | 설명 | 신뢰도 |
|---|---|---|---|
| ★★★ | part.thought === false(또는 필드 누락) |
사고 과정이 아님을 명확히 표시 | 매우 높음 |
| ★★ | thought_signature 필드 존재 |
최종 이미지에만 서명 포함 | 높음 |
| ★ | 배열 내 마지막 inline_data |
공식 문서상 "마지막 이미지가 최종본" | 보조 수단 |
가장 안전한 방법은 조합하여 사용하는 것입니다. 먼저 thought 필드를 확인하고, 없으면 thought_signature를 사용하며, 그래도 안 될 경우 마지막 inline_data를 선택하는 방식입니다.
Gemini 3.1 Flash Image의 thinking_level 차이
모델별로 사고 방식이 다르다는 점을 유의해야 합니다.
| 모델 | Thinking 기본값 | thinking_level 설정 |
활용 사례 |
|---|---|---|---|
gemini-3-pro-image-preview |
강제 활성화 | ❌ 불가 | 고충실도, 전문 작업 |
gemini-3-flash-image |
기본 minimal | ✅ minimal / high | 실시간 인터랙션, 대량 생성 |
gemini-2.5-flash-image |
미지원 | – | 기존 버전 호환 |
Gemini 3.1 Flash는 thinking_level을 수동으로 조절하여 정교한 구도(high)나 빠른 응답(minimal)을 선택할 수 있습니다. 이러한 유연성은 Pro 모델에는 없습니다.
🎯 모델 선택 제안: C-서비스를 운영한다면
gemini-3-flash-image+thinking_level=minimal(속도/비용 효율적)을 기본으로 사용하고, 사용자가 "고품질 모드" 선택 시gemini-3-pro-image-preview로 전환하는 것을 추천합니다. APIYI 플랫폼에서는 같은 API 키와 base_url로 모델을 원활하게 교체할 수 있습니다.
Gemini 3 이미지 사고 응답 처리 코드 예시
이론을 익혔으니 이제 실전 코드입니다. 모든 예제는 APIYI API 중계 서비스를 기준으로 작성되었습니다. 구글 AI 스튜디오를 직접 연결하던 기존 코드에서 base_url을 APIYI 주소로, api_key를 APIYI 키로 변경하기만 하면 동일하게 작동합니다.
Python 공식 SDK 예시
from google import genai
client = genai.Client(
api_key="sk-your-apiyi-key",
http_options={"base_url": "https://vip.apiyi.com/v1beta"}
)
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="사이버펑크 스타일 시바견, 네온사인 아래, 4K 고화질",
config={"response_modalities": ["IMAGE"]}
)
# ✅ 올바른 방법: 모든 사고(thought) part를 걸러내고 최종 이미지만 저장
for part in response.parts:
if getattr(part, "thought", False):
continue # 사고 과정 초안 건너뛰기
if hasattr(part, "as_image"):
image = part.as_image()
if image:
image.save("final_output.png")
break # 첫 번째로 발견된 비사고 이미지가 최종본
나쁜 예시(오류 발생의 주원인):
# ❌ 오류: 첫 번째 이미지를 가져오면 초안이 나올 수 있음
image_part = response.parts[0]
image_bytes = image_part.inline_data.data
# 미완성 이미지가 생성될 위험이 있음
Node.js / TypeScript 예시
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({
apiKey: process.env.APIYI_KEY,
httpOptions: { baseUrl: "https://vip.apiyi.com/v1beta" }
});
const response = await ai.models.generateContent({
model: "gemini-3-pro-image-preview",
contents: "사이버펑크 스타일 시바견, 네온사인 아래, 4K 고화질",
config: { responseModalities: ["IMAGE"] }
});
const parts = response.candidates?.[0]?.content?.parts ?? [];
// ✅ 뒤에서부터 탐색하여 첫 번째 비사고(non-thought) 이미지를 선택
let finalImage: string | null = null;
for (let i = parts.length - 1; i >= 0; i--) {
const p = parts[i];
if (p.thought === true) continue;
if (p.inlineData?.mimeType?.startsWith("image/")) {
finalImage = p.inlineData.data;
break;
}
}
if (finalImage) {
fs.writeFileSync("final.png", Buffer.from(finalImage, "base64"));
}
cURL + jq 명령줄 예시
쉘 스크립트에서 호출할 경우 jq 필터를 사용할 수 있습니다.
curl -sS https://vip.apiyi.com/v1beta/models/gemini-3-pro-image-preview:generateContent \
-H "x-goog-api-key: $APIYI_KEY" \
-H "content-type: application/json" \
-d '{
"contents": [{
"parts": [{"text": "사이버펑크 스타일 시바견"}]
}],
"generationConfig": {"responseModalities": ["IMAGE"]}
}' | jq -r '
.candidates[0].content.parts
| map(select(.thought != true))
| map(select(.inlineData.mimeType | startswith("image/")))
| last.inlineData.data
' | base64 -d > final.png
이 jq 표현식은 사고 과정 필터링, 이미지 mime 타입 제한, 마지막 데이터 추출이라는 3가지 규칙을 완벽히 수행합니다.
🎯 코드 리뷰 팁: Gemin 이미지 응답을 처리하는 코드라면 반드시
thought필터링 로직이 있는지 확인하세요. 팀 내에서extractFinalImage()와 같은 공통 유틸리티 함수를 만들어 사용하면 오류를 방지할 수 있습니다. APIYI를 통해 접속하면 로컬에서 테스트한 로직을 그대로 운영 환경에 적용할 수 있어 매우 편리합니다.
Gemini 3 이미지 사고 관련 고급 주제
다중 라운드 편집 시 thought_signature 필수 반환
Nano Banana Pro는 '연속 편집' 기능을 지원합니다. 예를 들어 사용자가 "배경을 해변으로 바꿔줘"라고 한 뒤, 이어서 "강아지 표정을 기쁘게 바꿔줘"라고 요청하는 식이죠. 하지만 공식적으로 다중 라운드 대화 시 이전 라운드의 thought_signature를 반드시 반환해야 한다고 명시하고 있습니다. 그렇지 않으면 모델이 이전 추론 컨텍스트를 이어받지 못해 생성 품질이 현저히 떨어지게 됩니다.
올바른 다중 라운드 작성법은 다음과 같습니다:
# 첫 번째 라운드
response1 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="공원에서 달리고 있는 시바견 한 마리"
)
# 최종 이미지의 part 객체 추출 (thought_signature 포함)
final_part = next(
p for p in response1.parts
if not getattr(p, "thought", False) and hasattr(p, "inline_data")
)
# 두 번째 라운드: 전체 final_part를 history에 추가
response2 = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=[
{"role": "user", "parts": [{"text": "공원에서 달리고 있는 시바견 한 마리"}]},
{"role": "model", "parts": [final_part]}, # thought_signature 포함
{"role": "user", "parts": [{"text": "배경을 해변 일몰로 바꿔줘"}]}
]
)
사고 과정 확인 (디버깅용)
모델이 "무슨 생각을 했는지" 확인하고 싶다면 include_thoughts를 활성화할 수 있습니다:
from google.genai import types
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents="복잡한 브랜드 홍보 포스터 프롬프트...",
config=types.GenerateContentConfig(
response_modalities=["IMAGE"],
thinking_config=types.ThinkingConfig(
include_thoughts=True
)
)
)
# 사고 과정 출력
for part in response.parts:
if getattr(part, "thought", False):
if part.text:
print(f"[사고] {part.text}")
elif hasattr(part, "as_image"):
img = part.as_image()
img.save(f"draft_{id(part)}.png") # 초안 저장
이는 "왜 생성 결과가 만족스럽지 않은지" 디버깅할 때 매우 유용합니다. 초안을 확인하면 모델이 프롬프트의 어느 부분을 오해했는지 추론할 수 있기 때문입니다.

사고(thinking) 토큰의 과금 논리
Gemini 3 Pro Image의 과금 방식은 개발자가 특별히 주의해야 합니다:
| 토큰 유형 | 단가(백만 토큰당) | 강제 발생 여부 |
|---|---|---|
| 입력 프롬프트 | $2 | ✅ 예 |
| 출력 이미지/텍스트 | $12 | ✅ 예 |
| 사고(Thinking) 추론 | 출력 토큰에 포함 | ✅ 강제(비활성화 불가) |
즉, 최종 이미지만 필요하고 사고 과정은 궁금하지 않더라도 thinking 토큰은 여전히 생성되며 과금됩니다. 절약할 수 있는 것은 "사고 내용을 반환받을지 여부"(include_thoughts 파라미터)일 뿐, "사고 과정을 실행할지 여부"는 선택할 수 없습니다.
🎯 비용 최적화 제안: 제품 이미지나 일러스트 같은 단순 작업에는
gemini-3-flash-image+thinking_level=minimal조합을 사용하세요. Pro 버전보다 비용이 훨씬 저렴합니다. 반면 다중 객체 일관성이나 고품질 텍스트 렌더링이 필요한 복잡한 작업에는 Pro 모델을 권장합니다. APIYI(apiyi.com)를 통해 호출할 때 사용량 모니터링을 활성화하여 두 모델의 비용 대비 품질을 직접 비교해본 뒤 프로덕션 설정을 결정하세요.
Gemini 3 이미지 사고 관련 오류 해결 실전
문제 1: 품질이 낮은 이미지만 계속 나오는 경우
진단 단계:
# 모든 parts의 thought 필드 출력
for i, part in enumerate(response.parts):
is_thought = getattr(part, "thought", False)
has_image = hasattr(part, "inline_data")
has_sig = hasattr(part, "thought_signature")
print(f"Part {i}: thought={is_thought}, image={has_image}, signature={has_sig}")
만약 출력 결과에 image=True인 파트가 여러 개 있다면, "이미지가 여러 장 생성된" 전형적인 경우입니다. 코드에서 인덱스가 앞선 part를 선택하고 있지는 않은지 확인해보세요.
문제 2: 응답 구조에 thought 필드가 없는 경우
가능한 원인: REST API가 반환하는 원본 JSON을 사용할 때, 카멜 표기법은 thought이지만 일부 SDK 버전에서는 필드명이 snake_case로 변환될 수 있습니다. 두 경우 모두 호환되도록 처리하세요:
def is_thought(part):
return getattr(part, "thought", None) or \
getattr(part, "is_thought", None) or \
(isinstance(part, dict) and part.get("thought", False))
문제 3: 모든 이미지 저장하기 (디버깅용)
공식에서 추천하는 전체 순회 코드입니다:
for i, part in enumerate(response.parts):
if not hasattr(part, "inline_data"):
continue
is_draft = getattr(part, "thought", False)
suffix = "draft" if is_draft else "final"
filename = f"gemini_output_{suffix}_{i}.png"
with open(filename, "wb") as f:
f.write(part.inline_data.data)
print(f"저장 완료: {filename}")
Gemini 3 이미지 사고(Thinking)의 실제 비즈니스 시나리오 적용
이론과 기본 코드를 넘어, 다양한 비즈니스 시나리오에서 고려해야 할 몇 가지 중요한 세부 사항이 있습니다.
시나리오 1: 웹 프론트엔드에서 생성된 이미지 직접 표시
프론트엔드에서 받은 base64 이미지는 data:image/png;base64,xxx 형식으로 변환하여 표시해야 합니다. 프론트엔드에서 사고(thought) 필터링을 하지 않도록 주의하세요. 백엔드에서 이미 필터링된 깔끔한 결과를 반환하도록 해야 합니다. 그렇지 않으면 프론트엔드에서 Gemini의 응답 구조를 복잡하게 처리해야 합니다.
// ❌ 비추천: 프론트엔드에서 Gemini 원본 응답을 직접 처리
const parts = await apiCall();
parts.forEach(p => {
if (!p.thought) showImage(p.inlineData.data);
});
// ✅ 추천: 백엔드에서 일괄 필터링하고, 프론트엔드는 최종 이미지만 소비
// 백엔드 API 응답 예시: { "image": "base64-string" }
const { image } = await fetch("/api/generate").then(r => r.json());
imgEl.src = `data:image/png;base64,${image}`;
시나리오 2: 이미지 생성 + OSS / CDN 저장
대량 생성 후 객체 스토리지(OSS)에 저장할 때는 해시를 사용하여 중복 저장을 방지하세요.
import hashlib, base64
def save_to_oss(bucket, base64_data):
binary = base64.b64decode(base64_data)
# 파일명 중복 방지를 위한 MD5 해시 처리
fname = f"gemini3/{hashlib.md5(binary).hexdigest()}.png"
bucket.put_object(fname, binary)
return fname
final_b64 = extract_final_image(response)
if final_b64:
url = save_to_oss(my_bucket, final_b64)
반드시 최종 이미지만 업로드하세요. 사고 과정이 담긴 초안은 OSS를 오염시키고 스토리지 비용만 낭비하게 됩니다.
시나리오 3: 스트리밍 응답의 올바른 처리
Gemini 3 이미지는 스트리밍을 지원하며, 사고 초안이 먼저 도착하고 최종 이미지가 나중에 도착합니다. 스트리밍 시나리오에서는 "받을 때마다 덮어쓰기(Overwrite while receiving)" 방식을 권장합니다.
stream = client.models.generate_content_stream(
model="gemini-3-pro-image-preview",
contents="..."
)
current_image = None
for chunk in stream:
for part in chunk.parts:
if getattr(part, "thought", False):
continue # 사고 초안은 건너뜀
if hasattr(part, "inline_data") and part.inline_data:
current_image = part.inline_data.data # 매번 덮어쓰며 마지막 이미지만 남김
# 스트림 종료 후, current_image에 최종 이미지가 담겨 있음
🎯 스트리밍 최적화: 사용자 경험을 위해 사고 초안을 프론트엔드로 보내 "로딩 중 미리보기"로 보여주고, 최종 이미지가 도착하면 교체하는 방식인 "점진적 렌더링"은 C-end 제품에서 매우 인기가 많습니다. APIYI(apiyi.com)는 Gemini의 SSE 스트리밍 프로토콜을 완벽하게 지원하므로, 프론트엔드 연동은 직접 연결할 때와 동일하게 느껴질 것입니다.
Gemini 3 이미지 사고(Thinking)와 비즈니스 지표의 연관성
품질 향상에 대한 정량적 데이터
Google의 공식 발표와 커뮤니티 테스트에 따르면, 사고(thinking) 기능을 활성화하면 이미지 품질이 눈에 띄게 향상됩니다.
| 지표 | Gemini 2.5 Flash Image | Gemini 3 Pro Image (thinking) | 향상 폭 |
|---|---|---|---|
| 긴 텍스트 렌더링 정확도 | ~70% | ~95% | +35% |
| 다중 객체 일관성 (5인) | ~60% | ~90% | +50% |
| 복잡한 구도 준수도 | ~75% | ~92% | +22% |
| 첫 이미지 가용성 | ~80% | ~95% | +18% |
반면 응답 시간은 4080% 증가하고, 토큰 비용은 2040% 상승합니다. 이 투자가 가치가 있을까요? 비즈니스 시나리오에 따라 결정하세요.
- 전문 디자인 소스, 광고 소재: 품질 향상이 비용 증가보다 훨씬 큽니다. 강력 추천합니다.
- UGC 사용자 이미지 생성, 대량 콘텐츠:
Flash + thinking_level=minimal조합으로 균형을 맞추는 것을 권장합니다. - 실시간 인터랙션, 챗봇: 응답 속도가 우선이므로 Flash 모델이 더 적합합니다.
🎯 A/B 테스트 제안: 감으로 모델을 선택하지 마세요. APIYI(apiyi.com)에서 각 모델별로 키를 생성한 뒤, 비즈니스 레이어에서 50/50으로 트래픽을 배분해 보세요. 7일 후 실제 사용자 만족도 지표(좋아요 비율, 재생성 비율, 전환율)를 비교하면 데이터가 정답을 알려줄 것입니다.
Gemini 3 이미지 사고(Thinking) FAQ
Q1: Gemini 3로 업그레이드한 후 이미지 생성 코드가 "가끔 반제품(미완성본)을 출력"하는 이유는 무엇인가요?
Gemini 3 Pro Image는 기본적으로 사고(Thinking) 기능이 켜져 있어, 응답에 1~3장의 이미지가 포함될 수 있습니다. 기존 코드는 대부분 parts[0]를 가져오도록 되어 있는데, 이것이 초안(Draft)일 가능성이 높습니다. 해결 방법: thought: true를 필터링하고, 사고 과정이 아닌 마지막 이미지를 가져오도록 코드를 수정하세요.
Q2: APIYI 플랫폼의 Gemini 3 이미지 API도 사고(Thinking) 기능이 작동하나요?
완벽히 동일합니다. APIYI(apiyi.com)는 투명한 전달(Transparent Forwarding) 아키텍처를 사용합니다. Gemini 원본 응답에 포함된 thought, thought_signature, inline_data를 수정이나 삭제 없이 그대로 전달합니다. Google AI Studio에 직접 연결하던 기존 코드를 그대로 APIYI로 향하게 해도 응답 구조가 완벽히 호환됩니다.
Q3: 특정 파라미터를 통해 최종 이미지만 반환하도록 강제할 수 있나요?
불가능합니다. 공식 문서에 "이 기능은 API에서 기본적으로 활성화되어 있으며 비활성화할 수 없음(This feature is enabled by default and cannot be disabled in the API)"이라고 명시되어 있습니다. 다만 include_thoughts: false를 설정하여 응답에 사고 텍스트가 포함되지 않게 할 수는 있지만, 이미지 초안은 여전히 존재할 수 있으므로 코드 수준의 필터링은 필수입니다.
Q4: 사고(Thinking) 기능 때문에 응답 지연이 발생하는데, 어떻게 최적화하나요?
세 가지 방향을 추천합니다:
- 단순 작업은
gemini-3-flash-image+thinking_level=minimal조합으로 교체하세요. - 요구사항이 복잡하지 않다면, 프롬프트를 더 정밀하게 작성하여 모델이 "과도하게 사고"하지 않도록 하세요.
- 스트리밍 응답을 사용하여 사용자가 사고 과정의 초안을 먼저 보게 하고, 마지막에 최종 이미지가 도착하도록 구현하세요.
Q5: 응답에서 실제로 사고(Thinking)가 발생했는지 어떻게 판단하나요?
response.usage_metadata.thoughts_token_count 필드를 확인하세요. 이 값이 0보다 크면 사고가 발생한 것입니다. 이 값은 실제 추론 비용을 계산하는 데에도 도움이 됩니다.
Q6: thought_signature를 직접 생성하거나 수정할 수 있나요?
없습니다. thought_signature는 Google 서버에서 발행하는 암호화된 인증값으로, 다중 턴 대화에서 문맥의 연속성을 검증하는 데 사용됩니다. 임의로 생성한 시그니처는 서버에서 거부됩니다. 다중 턴 편집 시 signature가 포함된 part를 통째로 다시 전달하면 됩니다.
Q7: 100장의 이미지를 일괄 생성할 때 사고(Thinking)로 인한 불확실성은 어떻게 처리하나요?
요청마다 독립적으로 응답을 처리하고 thoughts_token_count를 기록하는 것을 권장합니다. APIYI(apiyi.com) 제어판에서 호출 단위로 토큰 소비량을 확인하여, 사고 소비량이 비정상적으로 높은 요청을 선별해 재검토할 수 있습니다. 일괄 작업 시에는 Batch API(Gemini 3 Pro Image 지원)를 고려해 보세요. 비용이 절반으로 줄고 응답을 비동기적으로 처리할 수 있습니다.
Gemini 3 이미지 사고 요약 및 체크리스트
전체 내용을 돌아보면, Gemini 3의 이미지 사고는 품질 향상을 가져온 동시에 응답 구조를 완전히 바꿔놓았습니다. 한 문장으로 요약하자면 다음과 같습니다.
✅ 핵심 원칙: 절대로
parts[0]를 바로 가져오지 말고,thought: true를 필터링한 뒤, 마지막inline_data를 최종 이미지로 사용하세요.

마이그레이션 체크리스트
프로젝트를 Gemini 2.5에서 Gemini 3로 업그레이드한다면 다음 목록을 확인하세요:
- 모델 ID 교체:
gemini-2.5-flash-image→gemini-3-pro-image-preview또는gemini-3-flash-image - 응답 파싱 재작성: 모든
parts[0]접근 방식을 "thought 필터링 + 마지막 이미지 추출"로 변경 - signature 처리 추가: 다중 턴 대화 시
thought_signature가 포함된 part를 유지 - 비용 검증: 사고 토큰이 출력 토큰으로 계산되어 비용이 20~40% 상승할 수 있음을 인지
- 회귀 테스트: 20개 이상의 샘플 프롬프트를 준비하여 Gemini 2.5와 3의 결과를 비교, 예기치 않은 오류 방지
빠른 통합 템플릿
팀의 "표준 템플릿"으로 아래 코드를 사용하세요. 모든 업무 호출은 이 방식을 따릅니다:
def extract_final_image(response):
"""Gemini 3 Image 응답에서 최종 이미지를 안전하게 추출"""
parts = response.candidates[0].content.parts if response.candidates else []
# 뒤에서부터 탐색하여 첫 번째 thought가 아닌 image를 찾음
for part in reversed(parts):
if getattr(part, "thought", False):
continue
if hasattr(part, "inline_data") and part.inline_data:
mime = part.inline_data.mime_type or ""
if mime.startswith("image/"):
return part.inline_data.data # base64 bytes
return None # 최종 이미지를 찾지 못함, 재시도 필요
🎯 마지막 제언: Gemini 3의 이미지 사고 메커니즘은 양날의 검입니다. 잘 활용하면 업계 최고 수준의 이미지 생성 품질을 얻을 수 있지만, 잘못하면 "랜덤 뽑기"식의 반제품이 나올 수 있습니다. APIYI(apiyi.com)를 통해 연동한 후, 10~20개의 실제 업무 프롬프트로 회귀 테스트를 진행하여 다양한 사고 트리거 상태에서도 코드가 최종 이미지를 올바르게 추출하는지 확인하고 운영 환경에 배포하세요. 본 플랫폼은 Gemini 3 전체 모델을 지원하며, API 응답은 Google 공식 사양과 완전히 일치합니다.
작성자: APIYI 기술팀 | 더 많은 AI 이미지 생성 튜토리얼은 help.apiyi.com에서 확인하세요.