저자 주: Kimi K2.5 기술 논문의 핵심 내용을 심층 분석하여, 1T 파라미터 MoE 아키텍처, 384개 전문가 구성, MLA 주의 집중(Attention) 메커니즘을 자세히 설명하고 로컬 배포를 위한 하드웨어 요구 사항과 API 연동 방안을 비교해 드립니다.
Kimi K2.5의 기술적 세부 사항이 궁금하신가요? 본 포스팅은 Kimi K2.5 공식 기술 논문을 바탕으로 조 단위 파라미터 MoE 아키텍처, 학습 방법 및 벤치마크 테스트 결과를 체계적으로 분석하고, 로컬 배포에 필요한 하드웨어 사양을 상세히 안내해 드립니다.
핵심 가치: 이 글을 읽고 나면 Kimi K2.5의 핵심 기술 파라미터와 아키텍처 설계 원리를 파악하고, 자신의 하드웨어 조건에 맞는 최적의 배포 방안을 선택할 수 있게 됩니다.
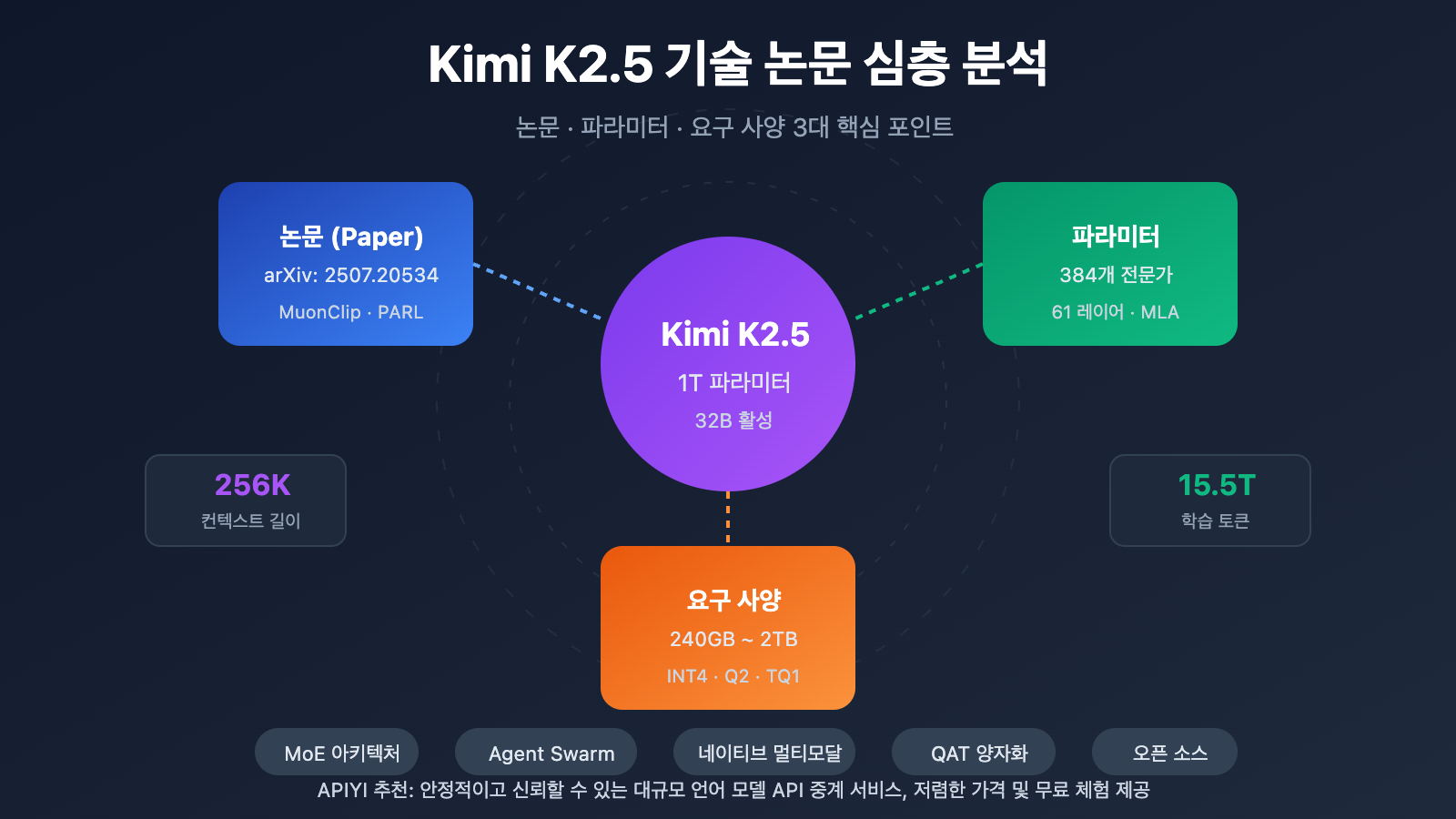
Kimi K2.5 기술 논문 핵심 요점
| 요점 | 기술 세부 사항 | 혁신 가치 |
|---|---|---|
| 조 단위 파라미터 MoE | 총 파라미터 1T, 활성 파라미터 32B | 추론 시 단 3.2%만 활성화되어 효율성 극대화 |
| 384개 전문가 시스템 | 토큰당 8개 전문가 + 1개 공유 전문가 선택 | DeepSeek-V3보다 50% 더 많은 전문가 구성 |
| MLA 주의 집중 | Multi-head Latent Attention | KV 캐시를 줄여 256K 컨텍스트 지원 |
| MuonClip 최적화 도구 | 토큰 효율적 학습, Loss Spike 제로 | 15.5T 토큰 학습 중 손실 급증 현상 없음 |
| 네이티브 멀티모달 | MoonViT 400M 비전 인코더 | 15T 비전-텍스트 혼합 학습 |
Kimi K2.5 논문 배경
Kimi K2.5 기술 논문은 Moonshot AI(웨즈안몐) 팀이 발표하였으며, arXiv 번호는 2507.20534입니다. 이 논문은 Kimi K2에서 K2.5로의 기술적 진화 과정을 상세히 설명하고 있으며, 주요 기여 포인트는 다음과 같습니다.
- 초희소(Ultra-sparse) MoE 아키텍처: DeepSeek-V3의 256개보다 50% 더 많은 384개 전문가를 구성했습니다.
- MuonClip 학습 최적화: 대규모 학습 시 발생하는 Loss Spike(손실 급증) 문제를 해결했습니다.
- Agent Swarm 패러다임: PARL(Parallel-Agent Reinforcement Learning) 학습 방법론을 도입했습니다.
- 네이티브 멀티모달 융합: 사전 학습 단계부터 비전-언어 능력을 통합했습니다.
논문에서는 고품질의 인간 데이터가 점차 희귀해짐에 따라 토큰 효율성이 대규모 모델 확장의 핵심 계수가 되고 있으며, 이것이 Muon 최적화 도구와 합성 데이터 생성 기술의 적용을 이끌었다고 분석합니다.
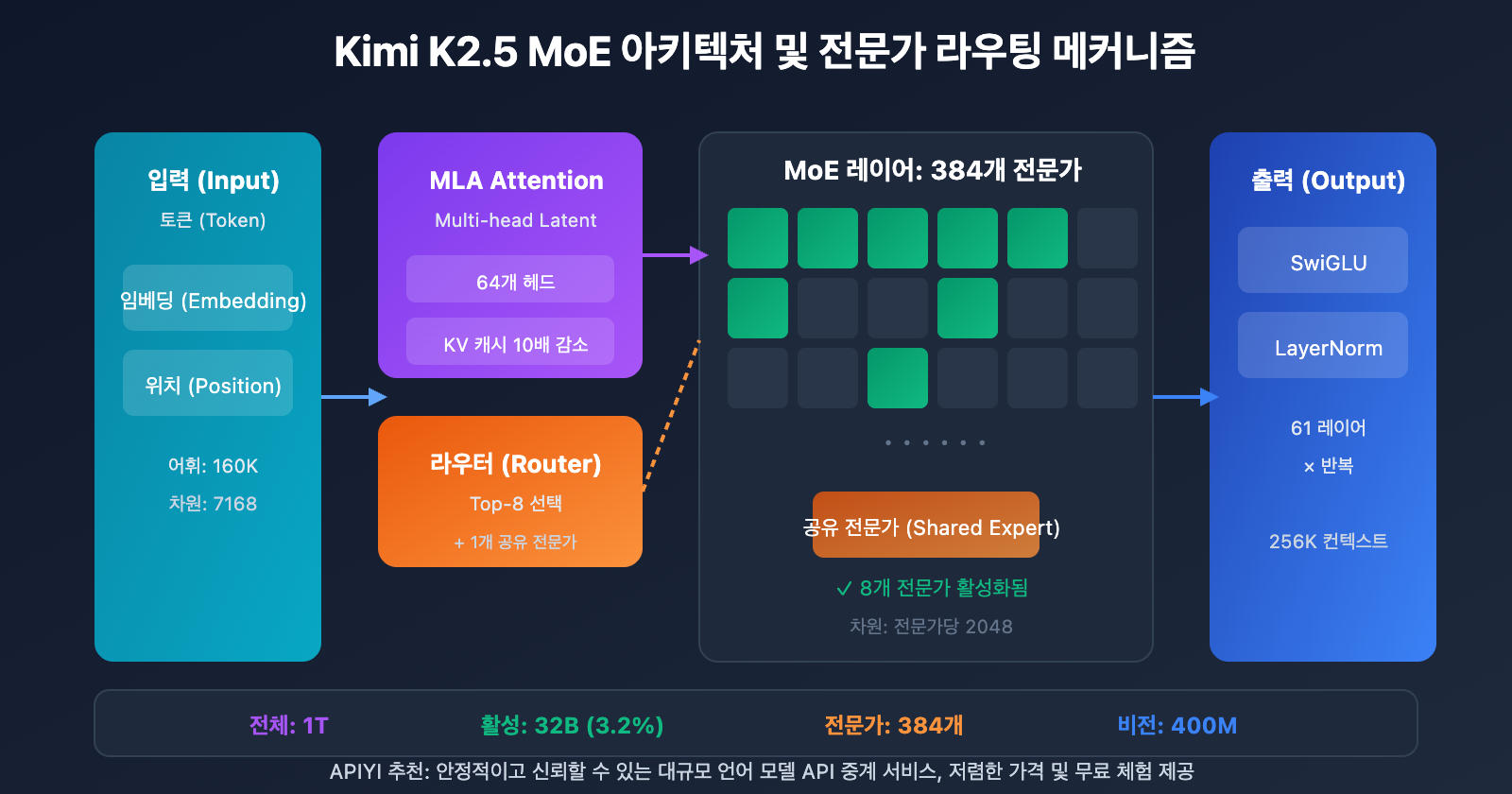
Kimi K2.5 Parameters 전체 사양
핵심 아키텍처 파라미터
| 파라미터 카테고리 | 파라미터명 | 수치 | 설명 |
|---|---|---|---|
| 규모 | 총 파라미터 수 | 1T (1.04조 개) | 전체 모델 크기 |
| 규모 | 활성화 파라미터 | 32B | 단회 추론 시 실제 사용량 |
| 구조 | 레이어 수 | 61개 | Dense 레이어 1개 포함 |
| 구조 | 숨겨진 차원(Hidden Dimension) | 7168 | 모델 백본 차원 |
| MoE | 전문가 수 | 384 | DeepSeek-V3보다 128개 더 많음 |
| MoE | 활성화 전문가 | 8 + 1 공유 | Top-8 라우팅 선택 |
| MoE | 전문가 숨겨진 차원 | 2048 | 각 전문가의 FFN 차원 |
| 어텐션 | 어텐션 헤드 수 | 64 | DeepSeek-V3의 절반 수준 |
| 어텐션 | 메커니즘 유형 | MLA | Multi-head Latent Attention |
| 기타 | 어휘집(Vocabulary) 크기 | 160K | 다국어 지원 |
| 기타 | 컨텍스트 길이 | 256K | 초장문 문서 처리 가능 |
| 기타 | 활성화 함수 | SwiGLU | 효율적인 비선형 변환 |
Kimi K2.5 Parameters 설계 분석
왜 384개의 전문가를 선택했을까요?
논문의 스케일링 법칙(Scaling Law) 분석에 따르면, 희소성(Sparsity)을 지속적으로 높이면 성능이 크게 향상되는 것으로 나타났습니다. 팀은 전문가 수를 DeepSeek-V3의 256개에서 384개로 늘려 모델의 표현 능력을 한층 끌어올렸어요.
왜 어텐션 헤드를 줄였을까요?
추론 시 발생하는 계산 비용을 낮추기 위해 어텐션 헤드 수를 128개에서 64개로 줄였습니다. MLA 메커니즘과 결합된 이 설계는 성능을 유지하면서도 KV 캐시(KV Cache)의 메모리 점유율을 획기적으로 낮춰줍니다.
MLA 어텐션 메커니즘의 장점:
전통적인 MHA: KV Cache = 2 × L × H × D × B
MLA: KV Cache = 2 × L × C × B (C << H × D)
L = 레이어 수, H = 헤드 수, D = 차원, B = 배치(Batch), C = 압축 차원
MLA는 잠재 공간 압축을 통해 KV 캐시를 약 10배 정도 줄여주기 때문에 256K에 달하는 방대한 컨텍스트 처리가 가능해진 것이죠.
비전 인코더 파라미터
| 컴포넌트 | 파라미터 | 수치 |
|---|---|---|
| 이름 | MoonViT | 자체 개발 비전 인코더 |
| 파라미터 수 | – | 400M |
| 특징 | 시공간 풀링 | 비디오 이해 지원 |
| 통합 방식 | 네이티브 융합 | 프리트레이닝 단계에서 통합 |
Kimi K2.5 Requirements 배포 하드웨어 요구사항
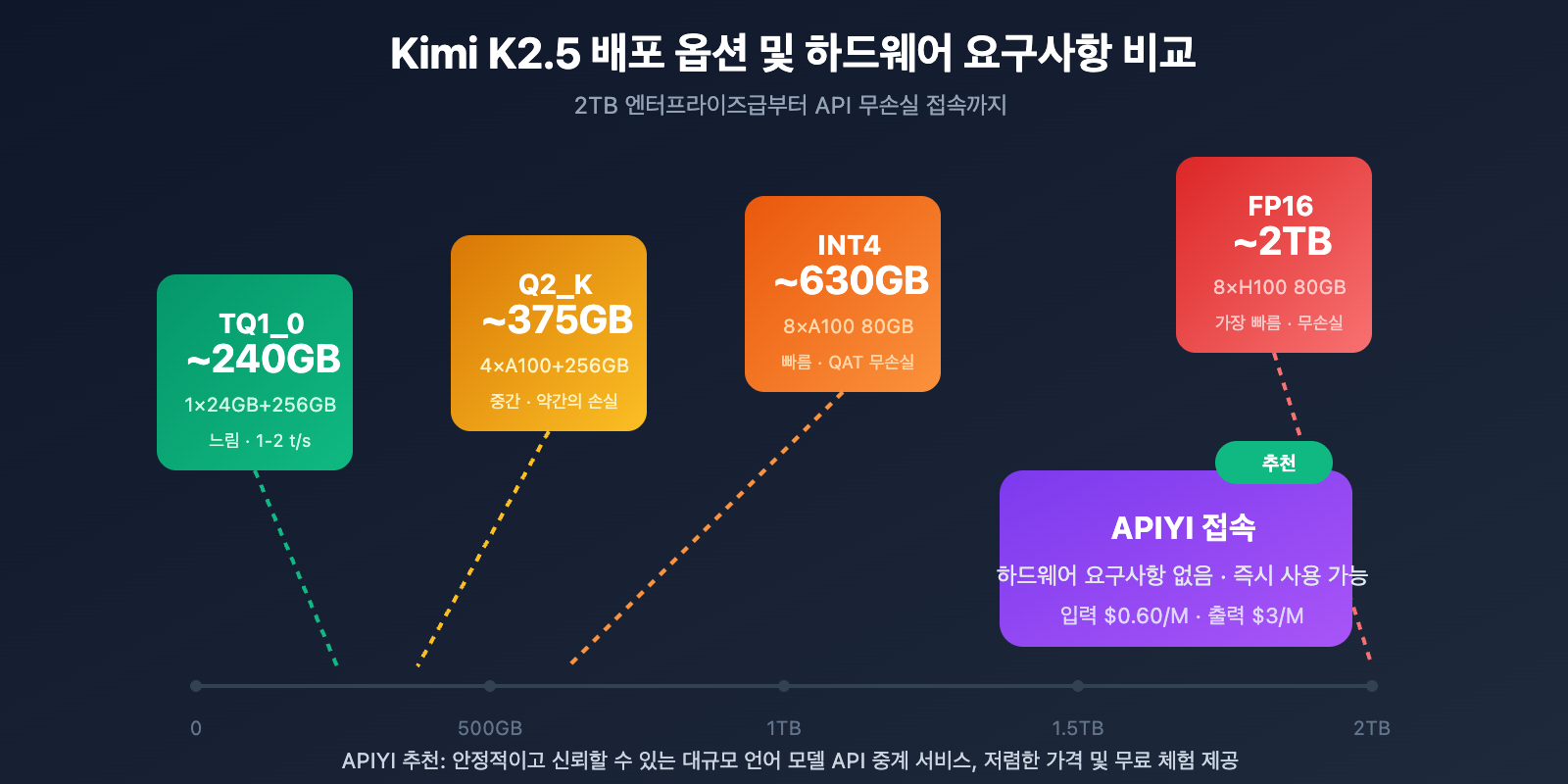
로컬 배포 하드웨어 요구사항
| 양자화 정밀도 | 스토리지 요구사항 | 최소 하드웨어 | 추론 속도 | 정밀도 손실 |
|---|---|---|---|---|
| FP16 | ~2TB | 8×H100 80GB | 가장 빠름 | 없음 |
| INT4 (QAT) | ~630GB | 8×A100 80GB | 빠름 | 거의 무손실 |
| Q2_K_XL | ~375GB | 4×A100 + 256GB RAM | 중간 | 경미함 |
| TQ1_0 (1.58-bit) | ~240GB | 1×24GB GPU + 256GB RAM | 느림 (1-2 t/s) | 눈에 띔 |
Kimi K2.5 Requirements 상세 설명
엔터프라이즈급 배포 (추천)
하드웨어 구성: 2× NVIDIA H100 80GB 또는 8× A100 80GB
스토리지 요구사항: 630GB+ (INT4 양자화)
예상 성능: 50-100 tokens/s
적용 시나리오: 프로덕션 환경, 대규모 동시 접속 서비스
극한 압축 배포
하드웨어 구성: 1× RTX 4090 24GB + 256GB 시스템 메모리
스토리지 요구사항: 240GB (1.58-bit 양자화)
예상 성능: 1-2 tokens/s
적용 시나리오: 연구 테스트, 기능 검증
주의사항: MoE 레이어가 시스템 메모리(RAM)로 완전히 오프로드되어 속도가 느립니다.
왜 이렇게 많은 메모리가 필요할까요?
MoE 아키텍처는 매 추론 시 32B의 파라미터만 활성화하지만, 입력값에 따라 전문가에게 동적으로 라우팅하기 위해 전체 1T 파라미터를 메모리에 유지해야 합니다. 이는 MoE 모델의 고유한 특성 때문이에요.
더 실용적인 솔루션: API 접속
대부분의 개발자에게 Kimi K2.5를 로컬에 배포하는 것은 하드웨어 장벽이 매우 높습니다. 따라서 API를 통한 접속이 훨씬 실용적인 선택입니다.
| 솔루션 | 비용 | 장점 |
|---|---|---|
| APIYI (추천) | 입력 $0.60/M, 출력 $3/M | 통합 인터페이스, 다양한 모델 전환, 무료 크레딧 제공 |
| 공식 API | 위와 동일 | 모든 기능 지원, 가장 빠른 업데이트 |
| 로컬 1-bit | 하드웨어 비용 + 전기세 | 데이터 로컬 보관 가능 |
배포 제안: 엄격한 데이터 로컬화 요구사항이 있는 경우가 아니라면, 고가의 하드웨어 투자 대신 **APIYI(apiyi.com)**를 통해 Kimi K2.5를 이용하는 것을 권장합니다.
Kimi K2.5 논문 벤치마크 결과
핵심 역량 평가
| 벤치마크 | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | 설명 |
|---|---|---|---|---|
| AIME 2025 | 96.1% | – | – | 수학 경진 대회 (avg@32) |
| HMMT 2025 | 95.4% | 93.3% | – | 수학 경진 대회 (avg@32) |
| GPQA-Diamond | 87.6% | – | – | 과학적 추론 (avg@8) |
| SWE-Bench Verified | 76.8% | – | 80.9% | 코드 수정 |
| SWE-Bench Multi | 73.0% | – | – | 다국어 코드 |
| HLE-Full | 50.2% | – | – | 종합 추론 (도구 사용 시) |
| BrowseComp | 60.2% | 54.9% | 24.1% | 웹 페이지 상호작용 |
| MMMU-Pro | 78.5% | – | – | 멀티모달 이해 |
| MathVision | 84.2% | – | – | 시각적 수학 |
학습 데이터 및 방법론
| 단계 | 데이터 양 | 방법 |
|---|---|---|
| K2 Base 사전 학습 | 15.5T 토큰 | MuonClip 옵티마이저, Loss Spike 제로 |
| K2.5 추가 사전 학습 | 15T 비전-텍스트 혼합 | 네이티브 멀티모달 융합 |
| 에이전트(Agent) 학습 | – | PARL (병렬 에이전트 강화 학습) |
| 양자화 학습 | – | QAT (양자화 인식 학습) |
논문에서는 MuonClip 옵티마이저 덕분에 15.5T 토큰에 달하는 전체 사전 학습 과정에서 Loss Spike가 전혀 발생하지 않았다는 점을 특별히 강조하고 있습니다. 이는 조 단위 파라미터 규모의 모델 학습에서 거둔 매우 중요한 기술적 돌파구입니다.
Kimi K2.5 빠른 연결 예시
초간단 호출 코드
APIYI 플랫폼을 이용하면 단 10줄의 코드로 Kimi K2.5를 호출할 수 있습니다.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY", # apiyi.com에서 발급
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "MoE 아키텍처의 작동 원리를 설명해 줘"}]
)
print(response.choices[0].message.content)
Thinking 모드 호출 코드 확인하기
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Thinking 모드 - 심층 추론
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "system", "content": "당신은 Kimi입니다. 문제를 자세히 분석해 주세요."},
{"role": "user", "content": "루트 2가 무리수임을 증명해 줘"}
],
temperature=1.0, # Thinking 모드 권장 설정
top_p=0.95,
max_tokens=8192
)
# 추론 과정과 최종 답변 가져오기
reasoning = getattr(response.choices[0].message, "reasoning_content", None)
answer = response.choices[0].message.content
if reasoning:
print(f"추론 과정:\n{reasoning}\n")
print(f"최종 답변:\n{answer}")
팁: APIYI(apiyi.com)에서 무료 테스트 크레딧을 받아 Kimi K2.5의 Thinking 모드가 선사하는 강력한 심층 추론 능력을 직접 경험해 보세요.
자주 묻는 질문
Q1: Kimi K2.5 paper 기술 논문은 어디에서 확인할 수 있나요?
Kimi K2 시리즈의 공식 기술 논문은 arXiv에 게시되어 있으며, 번호는 2507.20534입니다. arxiv.org/abs/2507.20534를 통해 접속할 수 있습니다. Kimi K2.5의 기술 보고서는 공식 블로그인 kimi.com/blog/kimi-k2-5.html에서 확인하실 수 있어요.
Q2: Kimi K2.5 로컬 배포를 위한 최소 사양(requirements)은 무엇인가요?
극한의 압축 솔루션을 사용할 경우, 최소 24GB VRAM GPU 1장 + 256GB 시스템 메모리 + 240GB 저장 공간이 필요합니다. 하지만 이 사양에서는 추론 속도가 1-2 tokens/s 수준에 그칩니다. 권장 사양은 2×H100 또는 8×A100이며, INT4 양자화를 적용하면 실제 서비스 가능한 수준의 성능을 낼 수 있습니다.
Q3: Kimi K2.5의 성능을 빠르게 검증하려면 어떻게 해야 하나요?
로컬 배포를 할 필요 없이, API를 통해 빠르게 테스트해 볼 수 있어요:
- APIYI(apiyi.com)에 접속하여 계정을 등록합니다.
- API Key와 무료 크레딧을 받습니다.
- 본문에 소개된 코드 예제를 사용하고, 모델명에
kimi-k2.5를 입력합니다. - Thinking 모드의 심층 추론 능력을 직접 경험해 보세요.
요약
Kimi K2.5 기술 논문의 핵심 포인트는 다음과 같습니다:
- Kimi K2.5 Paper 핵심 혁신: 384개 전문가 MoE 아키텍처 + MLA 어텐션 + MuonClip 옵티마이저를 통해 조 단위 파라미터의 무손실 피크 트레이닝(Peak Training)을 실현했습니다.
- Kimi K2.5 Parameters 주요 파라미터: 총 1T 파라미터, 활성 파라미터 32B, 61개 레이어, 256K 컨텍스트를 지원하며, 매 추론 시 단 3.2%의 파라미터만 활성화됩니다.
- Kimi K2.5 Requirements 배포 요구 사양: 로컬 배포 문턱이 상당히 높기 때문에(최소 240GB 이상), API 연동이 훨씬 실용적인 선택입니다.
Kimi K2.5는 현재 APIYI(apiyi.com)에 출시되어 있습니다. API를 통해 모델 성능을 빠르게 검증하고, 여러분의 비즈니스 시나리오에 적합한지 평가해 보시길 추천드려요.
참고 자료
⚠️ 링크 형식 안내: 모든 외부 링크는
자료명: domain.com형식을 사용했습니다. 복사는 간편하지만 클릭으로 바로 이동되지는 않는데, 이는 SEO 가치 손실을 방지하기 위한 조치입니다.
-
Kimi K2 arXiv 논문: 아키텍처와 훈련 방법을 상세히 다룬 공식 기술 보고서
- 링크:
arxiv.org/abs/2507.20534 - 설명: 전체 기술 세부 정보와 실험 데이터를 확인할 수 있습니다.
- 링크:
-
Kimi K2.5 기술 블로그: 공식 발표된 K2.5 기술 보고서
- 링크:
kimi.com/blog/kimi-k2-5.html - 설명: 에이전트 스웜(Agent Swarm)과 멀티모달 능력을 이해하는 데 도움이 됩니다.
- 링크:
-
HuggingFace 모델 카드: 모델 가중치 및 사용 설명서
- 링크:
huggingface.co/moonshotai/Kimi-K2.5 - 설명: 모델 가중치를 다운로드하고 배포 가이드를 확인할 수 있습니다.
- 링크:
-
Unsloth 로컬 배포 가이드: 양자화 배포 상세 튜토리얼
- 링크:
unsloth.ai/docs/models/kimi-k2.5 - 설명: 다양한 양자화 정밀도에 따른 하드웨어 요구 사항을 안내합니다.
- 링크:
작성자: 기술 팀
기술 교류: 댓글 창에서 Kimi K2.5의 기술적 세부 사항에 대해 자유롭게 의견을 나누어 주세요. 더 많은 대규모 언어 모델 분석은 APIYI apiyi.com 기술 커뮤니티를 방문해 확인하실 수 있습니다.