Qwen3-Max로 AI 애플리케이션을 개발할 때 자주 발생하는 429 You exceeded your current quota 오류는 많은 개발자분들이 겪는 골칫거리예요. 이번 글에서는 알리바바 클라우드 Qwen3-Max의 속도 제한 메커니즘을 심층 분석하고, 할당량 부족 문제를 완벽하게 해결할 수 있는 5가지 실용적인 해결 방법을 제안해 드릴게요.
핵심 가치: 이 글을 다 읽고 나면 Qwen3-Max의 속도 제한 원리를 이해하고, 다양한 해결 방법을 습득하여 조 단위 파라미터를 가진 대규모 언어 모델을 가장 안정적으로 호출하는 방법을 선택할 수 있게 됩니다.
Qwen3-Max 속도 제한 문제 개요
전형적인 오류 메시지
애플리케이션에서 Qwen3-Max API를 빈번하게 호출하면 다음과 같은 오류를 만날 수 있어요.
{
"error": {
"message": "You exceeded your current quota, please check your plan and billing details.",
"type": "insufficient_quota",
"code": "insufficient_quota"
},
"status": 429
}
이 오류는 여러분이 알리바바 클라우드 Model Studio의 할당량 제한을 초과했음을 의미해요.
Qwen3-Max 속도 제한 문제의 영향 범위
| 영향 시나리오 | 구체적인 증상 | 심각도 |
|---|---|---|
| 에이전트(Agent) 개발 | 다회차 대화의 빈번한 중단 | 높음 |
| 배치 처리 | 작업 완료 불가 | 높음 |
| 실시간 애플리케이션 | 사용자 경험 저해 | 높음 |
| 코드 생성 | 긴 코드 출력 도중 끊김 현상 | 중간 |
| 테스트 및 디버깅 | 개발 효율성 저하 | 중간 |
Qwen3-Max 속도 제한 메커니즘 상세 분석
알리바바 클라우드 공식 쿼터 제한
알리바바 클라우드 Model Studio 공식 문서에 따르면, Qwen3-Max의 쿼터 제한은 다음과 같아요.
| 모델 버전 | RPM (분당 요청 수) | TPM (분당 토큰 수) | RPS (초당 요청 수) |
|---|---|---|---|
| qwen3-max | 600 | 1,000,000 | 10 |
| qwen3-max-2025-09-23 | 60 | 100,000 | 1 |
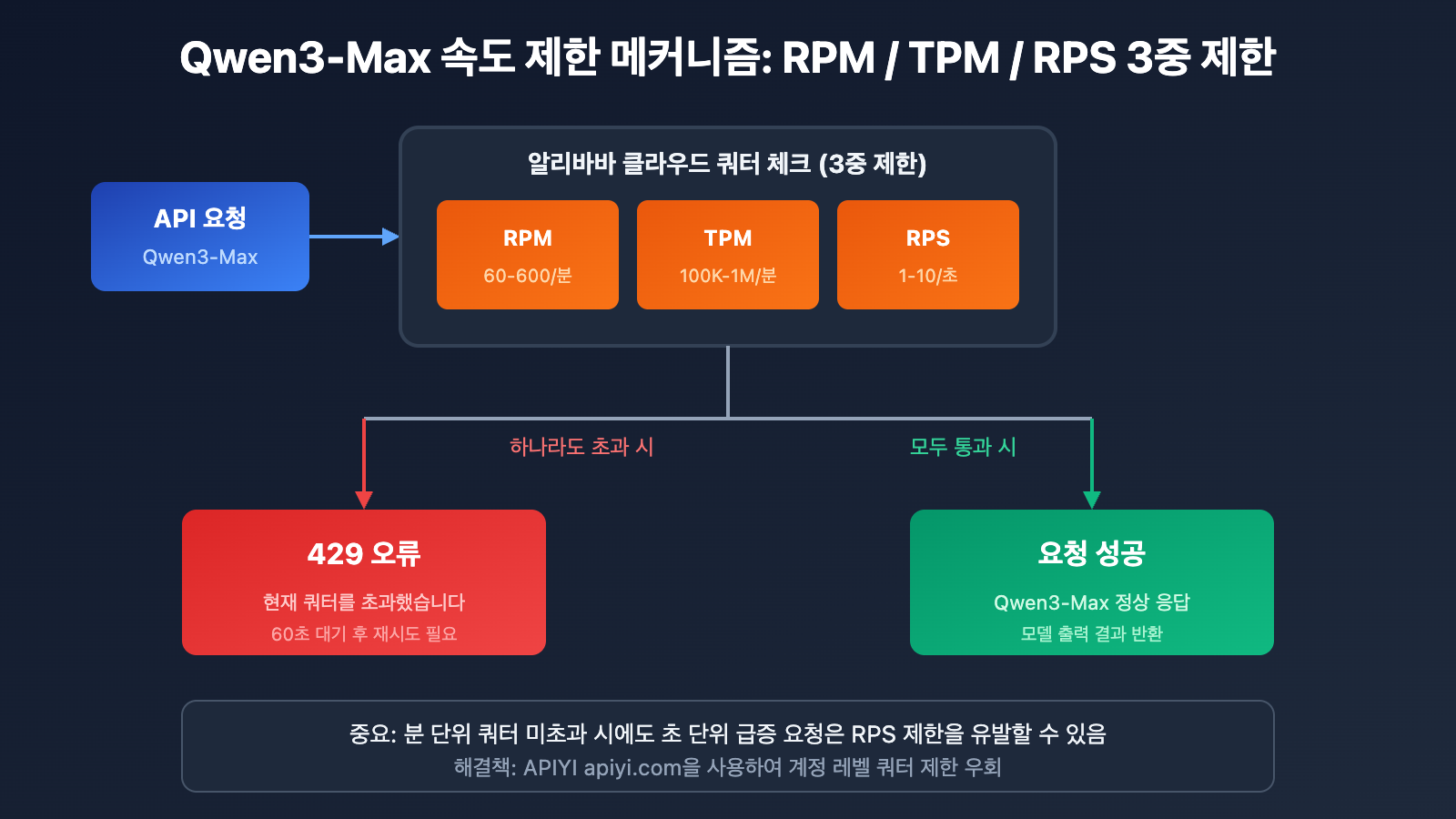
Qwen3-Max 속도 제한이 발생하는 4가지 상황
알리바바 클라우드는 Qwen3-Max에 대해 이중 제한 메커니즘을 시행하고 있어요. 다음 조건 중 하나라도 해당되면 429 오류가 반환됩니다.
| 오류 유형 | 오류 메시지 | 발생 원인 |
|---|---|---|
| 요청 빈도 초과 | Requests rate limit exceeded | RPM/RPS 제한 초과 |
| 토큰 소모 초과 | You exceeded your current quota | TPM/TPS 제한 초과 |
| 갑작스러운 트래픽 보호 | Request rate increased too quickly | 순간적인 요청 급증 |
| 무료 할당량 소진 | Free allocated quota exceeded | 체험용 쿼터 모두 사용 |
속도 제한 계산 공식
실제 제한 = min(RPM 제한, RPS × 60)
= min(TPM 제한, TPS × 60)
중요 팁: 분 단위의 전체 쿼터가 남아있더라도, 초 단위의 급격한 요청은 속도 제한을 발생시킬 수 있습니다.
Qwen3-Max 속도 제한 문제 해결을 위한 5가지 방법
솔루션 비교 요약
| 방법 | 구현 난이도 | 효과 | 비용 | 권장 상황 |
|---|---|---|---|---|
| API 중계 서비스 | 낮음 | 완벽 해결 | 절감 | 모든 상황 |
| 요청 평활화 전략 | 중간 | 완화 | 없음 | 가벼운 속도 제한 |
| 다중 계정 라운드 로빈 | 높음 | 완화 | 높음 | 기업 사용자 |
| 예비 모델 폴백 | 중간 | 보조 | 중간 | 비핵심 작업 |
| 쿼터 증설 신청 | 낮음 | 제한적 | 없음 | 장기 사용자 |
방법 1: API 중계 서비스 사용 (추천)
Qwen3-Max의 속도 제한 문제를 해결하는 가장 직관적이고 효과적인 방법이에요. API 중계 플랫폼을 통해 호출하면 알리바바 클라우드 계정 단위의 쿼터 제한을 우회할 수 있습니다.
왜 API 중계 서비스가 속도 제한을 해결해주나요?
| 비교 항목 | 알리바바 클라우드 직접 연결 | APIYI 중계 서비스 이용 |
|---|---|---|
| 쿼터 제한 | 계정 레벨 RPM/TPM 제한 | 플랫폼 레벨 통합 쿼터 공유 |
| 제한 발생 빈도 | 빈번한 429 오류 발생 | 거의 제한 없음 |
| 가격 | 공식 정가 | 기본 약 12% 할인 |
| 안정성 | 계정 쿼터에 따라 가변적 | 다중 채널을 통한 안정성 보장 |
아주 간단한 코드 예시
from openai import OpenAI
# APIYI 중계 서비스를 사용하여 속도 제한 걱정 없이 호출하세요
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "user", "content": "MoE 아키텍처의 작동 원리를 설명해줘"}
]
)
print(response.choices[0].message.content)
🎯 추천 솔루션: APIYI(apiyi.com)를 통해 Qwen3-Max를 호출하면 속도 제한 문제를 완벽히 해결할 뿐만 아니라 약 12% 할인된 가격으로 이용할 수 있습니다. APIYI는 알리바바 클라우드와의 파트너십을 통해 더 안정적인 서비스와 혜택을 제공합니다.
전체 코드 보기 (재시도 및 오류 처리 포함)
import time
from openai import OpenAI
from openai import APIError, RateLimitError
class Qwen3MaxClient:
"""APIYI를 통해 속도 제한 걱정 없이 호출하는 Qwen3-Max 클라이언트"""
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # APIYI 중계 인터페이스
)
self.model = "qwen3-max"
def chat(self, message: str, max_retries: int = 3) -> str:
"""
메시지를 보내고 응답을 받습니다.
APIYI를 사용하면 속도 제한 문제가 거의 발생하지 않습니다.
"""
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": message}],
max_tokens=4096
)
return response.choices[0].message.content
except RateLimitError as e:
# APIYI 사용 시 거의 발생하지 않지만, 예외 처리를 해둡니다.
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"요청 제한 발생, {wait_time}초 후 재시도 중...")
time.sleep(wait_time)
else:
raise e
except APIError as e:
print(f"API 오류 발생: {e}")
raise e
return ""
def batch_chat(self, messages: list[str]) -> list[str]:
"""속도 제한 걱정 없이 메시지를 대량으로 처리합니다."""
results = []
for msg in messages:
result = self.chat(msg)
results.append(result)
return results
# 사용 예시
if __name__ == "__main__":
client = Qwen3MaxClient(api_key="your-apiyi-key")
# 단일 호출
response = client.chat("Python으로 퀵 정렬 알고리즘을 짜줘")
print(response)
# 일괄 호출 - APIYI를 사용하면 속도 제한 걱정이 없습니다.
questions = [
"MoE 아키텍처가 뭐야?",
"Transformer와 RNN을 비교해줘",
"어텐션 메커니즘이 뭐야?"
]
answers = client.batch_chat(questions)
for q, a in zip(questions, answers):
print(f"Q: {q}\nA: {a}\n")
방법 2: 요청 평활화 전략
알리바바 클라우드를 직접 연결하여 사용해야 한다면, 요청 흐름을 조절하여 속도 제한을 완화할 수 있어요.
지수 백오프(Exponential Backoff) 재시도
import time
import random
def call_with_backoff(func, max_retries=5):
"""지수 백오프 재시도 전략"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if "429" in str(e) and attempt < max_retries - 1:
# 지수 백오프 + 랜덤 지터(jitter)
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"속도 제한 발생, {wait_time:.2f}초 대기 후 재시도...")
time.sleep(wait_time)
else:
raise e
요청 큐 버퍼링
import asyncio
from collections import deque
class RequestQueue:
"""Qwen3-Max 호출 빈도를 조절하는 요청 큐"""
def __init__(self, rpm_limit=60):
self.queue = deque()
self.interval = 60 / rpm_limit # 요청 간격
self.last_request = 0
async def throttled_request(self, request_func):
"""속도 제한이 적용된 요청"""
now = time.time()
wait_time = self.interval - (now - self.last_request)
if wait_time > 0:
await asyncio.sleep(wait_time)
self.last_request = time.time()
return await request_func()
참고: 요청 평활화는 속도 제한을 완화할 뿐 근본적인 해결책은 아닙니다. 고성능이 필요한 경우에는 APIYI 중계 서비스를 권장합니다.
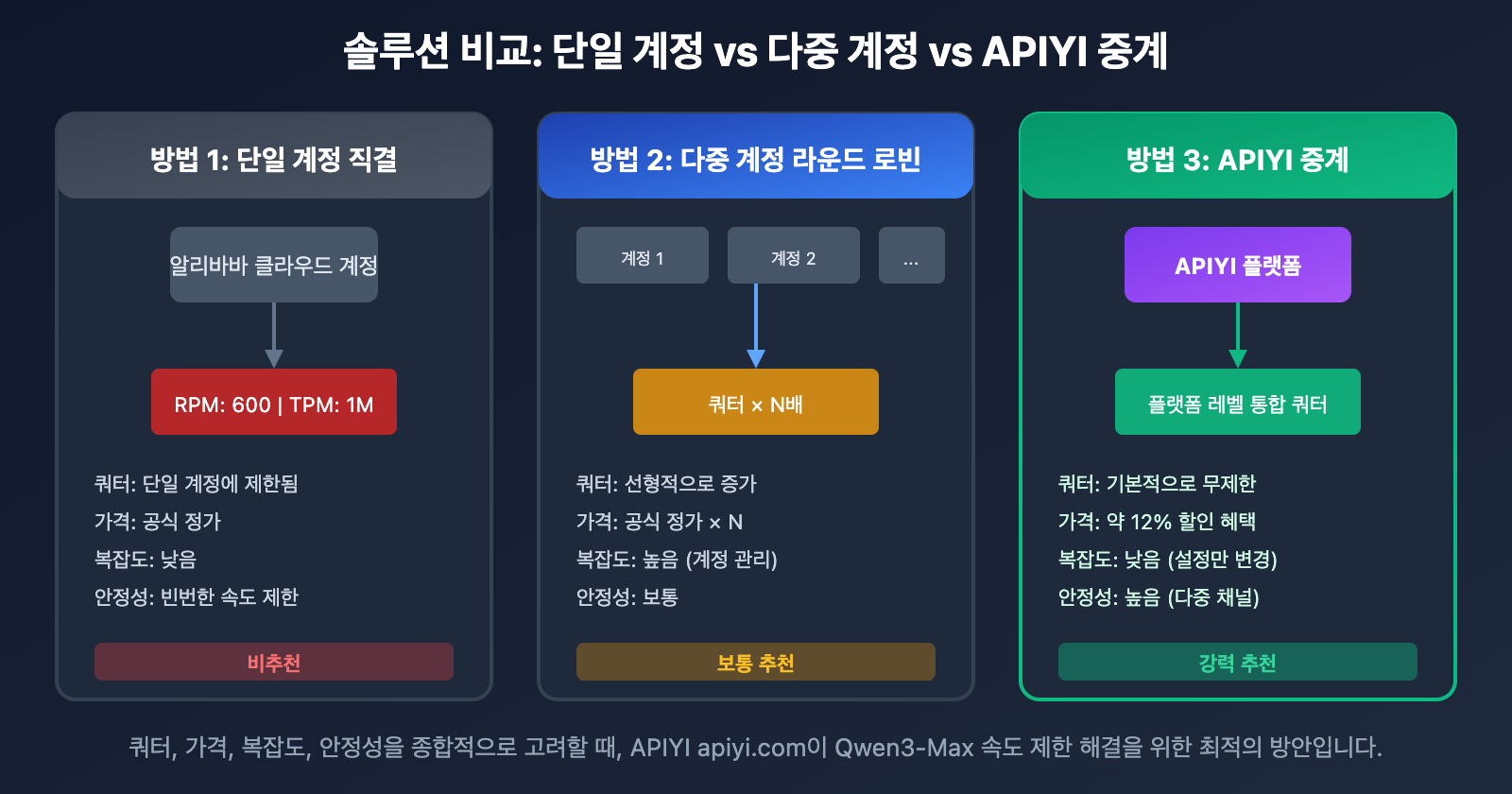
방법 3: 다중 계정 라운드 로빈
기업 사용자의 경우 여러 계정을 번갈아 가며 사용하여 전체 쿼터를 늘릴 수 있습니다.
from itertools import cycle
class MultiAccountClient:
"""다중 계정 라운드 로빈 클라이언트"""
def __init__(self, api_keys: list[str]):
self.clients = cycle([
OpenAI(api_key=key, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
for key in api_keys
])
def chat(self, message: str) -> str:
client = next(self.clients)
response = client.chat.completions.create(
model="qwen3-max",
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content
| 계정 수 | 등가 RPM | 등가 TPM | 관리 복잡도 |
|---|---|---|---|
| 1 | 600 | 1,000,000 | 낮음 |
| 3 | 1,800 | 3,000,000 | 중간 |
| 5 | 3,000 | 5,000,000 | 높음 |
| 10 | 6,000 | 10,000,000 | 매우 높음 |
💡 비교 조언: 다중 계정 관리는 복잡하고 비용이 많이 듭니다. 차라리 APIYI(apiyi.com) 중계 서비스를 사용하여 번거로운 관리 없이 플랫폼 수준의 대규모 쿼터를 이용하는 것이 훨씬 효율적입니다.
방법 4: 예비 모델 폴백(Fallback)
Qwen3-Max에 속도 제한이 걸렸을 때, 자동으로 하위 모델로 전환되도록 설정할 수 있습니다.
class FallbackClient:
"""폴백 기능을 지원하는 Qwen 클라이언트"""
MODEL_PRIORITY = [
"qwen3-max", # 1순위
"qwen-plus", # 예비 1
"qwen-turbo", # 예비 2
]
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # APIYI 사용
)
def chat(self, message: str) -> tuple[str, str]:
"""(응답 내용, 실제 사용된 모델) 반환"""
for model in self.MODEL_PRIORITY:
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content, model
except Exception as e:
if "429" in str(e):
print(f"{model} 속도 제한 발생, 폴백 시도 중...")
continue
raise e
raise Exception("모든 모델을 사용할 수 없습니다.")
방법 5: 쿼터 증설 신청
장기간 안정적으로 서비스를 이용해야 하는 사용자라면 알리바바 클라우드에 직접 쿼터 증설을 요청할 수 있습니다.
신청 단계:
- 알리바바 클라우드 콘솔 로그인
- Model Studio 쿼터 관리 페이지 접속
- 쿼터 증설 신청서 제출
- 심사 대기 (보통 영업일 기준 1~3일 소요)
신청 요건:
- 계정 실명 인증 완료
- 미납금 없음
- 구체적인 사용 사례 설명 필요
Qwen3-Max 속도 제한 문제 및 비용 비교 분석
가격 비교 분석
| 서비스 제공사 | 입력 가격 (0-32K) | 출력 가격 | 속도 제한 상황 |
|---|---|---|---|
| 알리바바 클라우드 직접 연결 | $1.20/M | $6.00/M | 엄격한 RPM/TPM 제한 |
| APIYI (12% 할인) | $1.06/M | $5.28/M | 기본적으로 속도 제한 없음 |
| 가격 차이 | 12% 절감 | 12% 절감 | – |
종합 비용 계산
월 호출량 1,000만 토큰(입력 및 출력 각 절반)을 가정할 때:
| 솔루션 | 월 비용 | 속도 제한 영향 | 종합 평가 |
|---|---|---|---|
| 알리바바 클라우드 직접 연결 | $36.00 | 잦은 중단, 재시도 필요 | 실제 비용이 더 높음 |
| APIYI 중개 서비스 | $31.68 | 중단 없이 안정적 | 가성비 최적 |
| 다중 계정 방안 | $36.00+ | 관리 비용 높음 | 추천하지 않음 |
💰 비용 최적화: APIYI(apiyi.com)는 알리바바 클라우드와 채널 파트너십을 맺고 있어, 기본적으로 12% 할인된 가격을 제공할 뿐만 아니라 속도 제한 문제를 완벽하게 해결해 줍니다. 중고빈도 사용 시나리오에서 종합적인 비용이 훨씬 저렴해요.
자주 묻는 질문(FAQ)
Q1: 왜 사용을 시작하자마자 Qwen3-Max 속도 제한이 걸리나요?
알리바바 클라우드 Model Studio는 신규 계정의 무료 할당량이 제한적이며, 특히 최신 버전인 qwen3-max-2025-09-23의 쿼터는 더 낮게 설정되어 있습니다(RPM 60, TPM 100,000). 만약 스냅샷 버전을 사용 중이라면 속도 제한이 더욱 엄격하게 적용될 수 있어요.
이런 경우 APIYI(apiyi.com)를 통해 호출하면 계정 레벨의 할당량 제한을 피할 수 있어 훨씬 쾌적합니다.
Q2: 속도 제한이 걸리면 회복까지 얼마나 걸리나요?
알리바바 클라우드의 속도 제한은 슬라이딩 윈도우(Sliding Window) 메커니즘을 따릅니다.
- RPM 제한: 약 60초 대기 후 회복
- TPM 제한: 약 60초 대기 후 회복
- 버스트 보호(Burst Protection): 더 오랜 대기 시간이 필요할 수 있음
APIYI 플랫폼을 사용하면 이러한 빈번한 대기 시간을 피할 수 있어 개발 효율을 높일 수 있습니다.
Q3: APIYI 중개 서비스의 안정성은 어떻게 보장되나요?
APIYI는 알리바바 클라우드와 공식 채널 파트너 관계이며, 플랫폼 레벨의 대규모 리소스 풀 방식을 채택하고 있어요.
- 다중 채널 로드 밸런싱
- 자동 장애 조치(Failover)
- 99.9% 가용성 보장
개인 계정의 할당량 제한과 비교했을 때, 플랫폼급 서비스가 훨씬 더 안정적이고 신뢰할 수 있답니다.
Q4: APIYI를 사용하려면 코드를 많이 수정해야 하나요?
거의 수정할 필요가 없어요. APIYI는 OpenAI SDK 형식과 완벽하게 호환되므로, 다음 두 가지만 변경하면 됩니다.
# 수정 전 (알리바바 클라우드 직접 연결)
client = OpenAI(
api_key="sk-xxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 수정 후 (APIYI 중개)
client = OpenAI(
api_key="your-apiyi-key", # APIYI에서 발급받은 키로 교체
base_url="https://api.apiyi.com/v1" # APIYI 주소로 교체
)
모델 이름과 파라미터 형식이 완전히 동일하기 때문에 다른 부분은 건드릴 필요가 없습니다.
Q5: Qwen3-Max 외에 APIYI에서 지원하는 다른 모델은 무엇인가요?
APIYI 플랫폼은 200개 이상의 주요 AI 모델에 대한 통합 호출을 지원합니다.
- Qwen 전 시리즈: qwen3-max, qwen-plus, qwen-turbo, qwen-vl 등
- Claude 시리즈: claude-3-opus, claude-3-sonnet, claude-3-haiku
- GPT 시리즈: gpt-4o, gpt-4-turbo, gpt-3.5-turbo
- 기타: gemini, deepseek, moonshot 등
모든 모델이 통합 인터페이스를 사용하므로, API Key 하나로 이 모든 모델을 호출할 수 있어 매우 편리해요.
Qwen3-Max 속도 제한(Rate Limit) 문제 해결 방법 요약
솔루션 선택 의사결정 나무
Qwen3-Max 429 오류 발생 시
│
├─ 근본적인 해결이 필요한 경우 → APIYI 중계 서비스 사용 (추천)
│
├─ 가벼운 속도 제한 → 요청 평활화(Smoothing) + 지수 백오프(Exponential Backoff)
│
├─ 기업용 대규모 호출 → 다중 계정 라운드 로빈 또는 APIYI 기업용 버전
│
└─ 비핵심 작업 → 백업 모델로 다운그레이드
핵심 요점 복습
| 핵심 요점 | 설명 |
|---|---|
| 속도 제한 원인 | 알리바바 클라우드 RPM/TPM/RPS 3중 제한 |
| 최적의 솔루션 | APIYI 중계 서비스로 근본적 해결 |
| 비용 장점 | 0.88할(약 12% 할인), 직결보다 저렴함 |
| 마이그레이션 비용 | base_url과 api_key 수정만으로 간단히 교체 가능 |
APIYI(apiyi.com)를 통해 Qwen3-Max 속도 제한 문제를 빠르게 해결하고, 안정적인 서비스와 합리적인 가격 혜택을 누려보세요.
참고 자료
-
알리바바 클라우드 Rate Limits 문서: 공식 속도 제한 설명
- 링크:
alibabacloud.com/help/en/model-studio/rate-limit
- 링크:
-
알리바바 클라우드 Error Codes 문서: 오류 코드 상세 설명
- 링크:
alibabacloud.com/help/en/model-studio/error-code
- 링크:
-
Qwen3-Max 모델 문서: 공식 기술 사양
- 링크:
alibabacloud.com/help/en/model-studio/what-is-qwen-llm
- 링크:
기술 지원: Qwen3-Max 사용 중 궁금한 점이 있으시다면 언제든지 APIYI(apiyi.com)를 통해 기술 지원을 받아보세요.