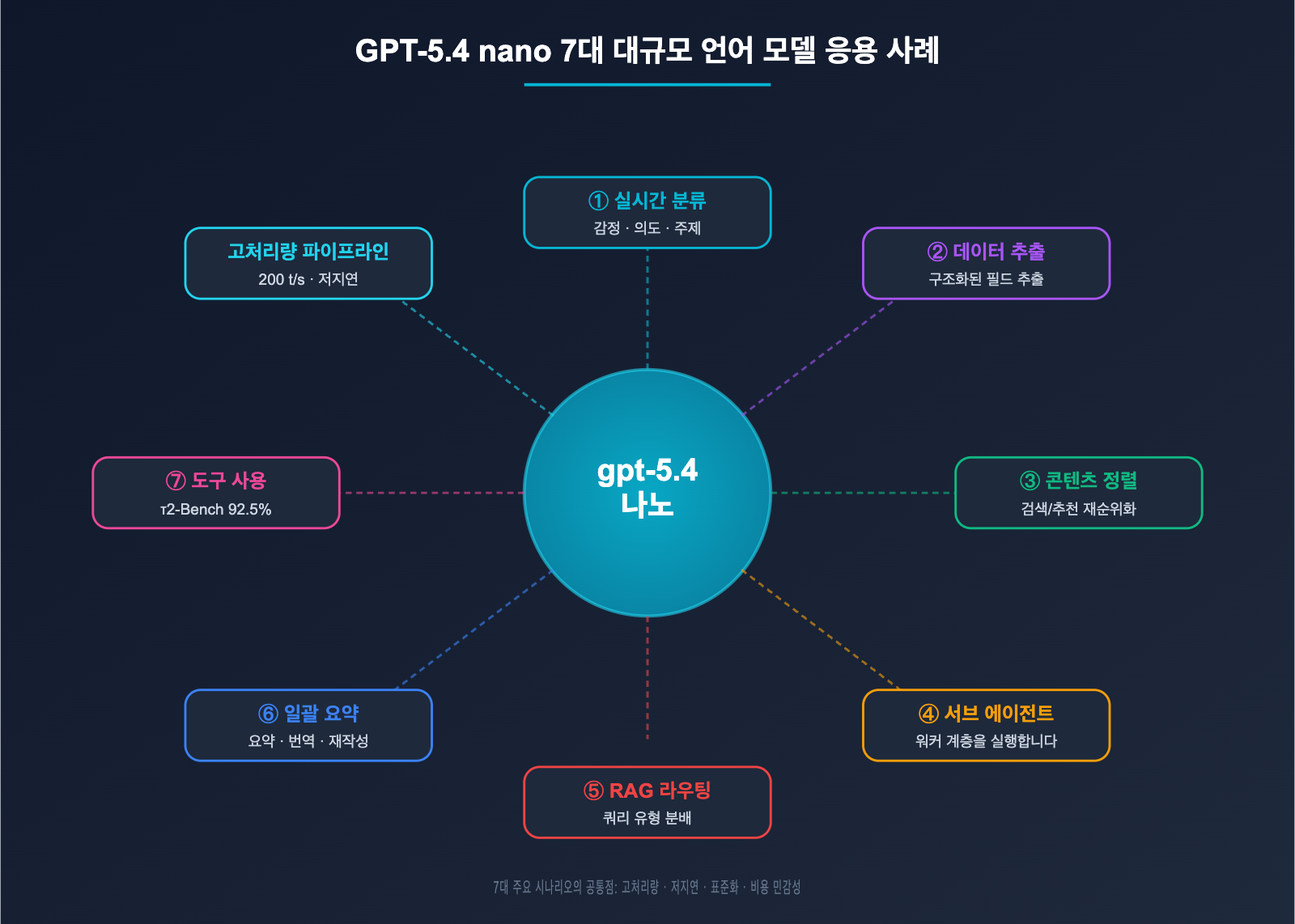
작성자 주: OpenAI의 가장 저렴한 모델인 gpt-5.4-nano는 100만 토큰당 입력 $0.20, 출력 $1.25라는 파격적인 가격을 자랑하며, τ2-Bench에서 92.5%의 성능으로 mini 모델과 대등한 수준을 보여줍니다. 이번 글에서는 nano 모델에 가장 적합한 7가지 애플리케이션 시나리오와 mini 모델로 전환해야 할 시점, 그리고 캐싱을 통해 비용을 90%까지 절감하는 최적화 전략을 상세히 다룹니다.
애플리케이션의 일일 호출 횟수가 1만 건을 넘거나, 고객 응대, 분류, RAG 라우팅과 같은 고처리량(High-throughput) 작업을 위해 모델을 고민 중이라면 OpenAI가 GPT-5.4 시리즈의 가격 하한선을 새로 쓴 점에 주목하세요. gpt-5.4-nano는 입력 비용이 5.4-mini보다 3.75배나 저렴합니다.
이 모델은 단순한 '저가형 모델'이 아닙니다. OpenAI가 공개한 벤치마크에 따르면, nano는 도구 호출(τ2-Bench)에서 92.5%를 기록하며 mini의 93.4%와 거의 차이가 없고, 일반 지식 질의응답(GPQA Diamond)에서도 82.8%로 mini보다 불과 5.2%p 낮을 뿐입니다. 즉, '높은 처리량 + 낮은 복잡도'가 요구되는 대다수 시나리오에서 nano가 진정한 최적의 선택지라는 뜻입니다.
핵심 가치: 본문에서는 7가지 구체적인 적용 사례를 통해 nano가 "충분히 강력하면서도 저렴한" 영역과, 반드시 mini를 사용해야 하는 영역을 구분하고 각 시나리오별 코드 예제와 비용 산출 방식을 제공합니다.

GPT-5.4 nano 애플리케이션 시나리오 핵심 요약
| 요점 | 설명 | 가치 |
|---|---|---|
| 극강의 저가 | 100만 토큰당 $0.20 / $1.25 | 5.4-mini 대비 3.75배 저렴 |
| 캐싱 -90% | 캐시 입력 시 100만 토큰당 $0.02 | 고빈도 컨텍스트 시나리오 사실상 무료 |
| 도구 호출 mini 수준 | τ2-Bench 92.5% vs mini 93.4% | 대부분의 도구 호출 시나리오 적합 |
| 지식 질의응답 강점 | GPQA Diamond 82.8% | 일반 FAQ, 지식 검색 충분 |
| 400K 긴 컨텍스트 | 입력 400K + 출력 128K | 긴 문서 대량 처리 부담 없음 |
| 속도 우위 | ~200 t/s, mini보다 10% 빠름 | 고처리량 파이프라인 최우선 선택 |
GPT-5.4 nano의 "충분한 임계값" 판단 기준
nano 모델이 충분한지 판단하려면 간단한 "3분류법"을 활용하세요.
녹색 구역(안심하고 nano 사용): 도구 호출, 구조화된 데이터 추출, 분류 및 라벨링, 지식 질의응답, 콘텐츠 라우팅, 대량 번역/요약 — 이러한 작업은 nano와 mini의 성능 차이가 10%p 미만이므로 가격 이점이 압도적입니다.
황색 구역(신중한 평가): 복잡한 다단계 추론, 긴 체인의 에이전트 오케스트레이션, 코드 생성 — SWE-Bench Pro 52.4%로 여전히 수행 가능하지만, nano로 AB 테스트를 먼저 실행해 보는 것을 권장합니다.
적색 구역(mini 사용 권장): Computer Use(nano의 OSWorld는 39%에 불과), 터미널 장기 작업(46.3%로 다소 약함), 파인튜닝이 필요한 맞춤형 시나리오 — 이러한 작업은 nano의 성능이 눈에 띄게 떨어지므로 mini나 표준 버전을 선택하세요.
GPT-5.4 nano 활용 사례 1: 실시간 분류
시나리오 설명
실시간 분류는 nano 모델의 가장 대표적인 활용 사례입니다. 감정 분석, 의도 인식, 주제 태깅, 콘텐츠 검토 마킹 등이 여기에 포함되죠. 이런 작업은 매번 호출할 때마다 보통 수백 토큰의 입력과 수십 토큰의 출력만 필요하므로, 지연 시간(Latency)과 비용에 매우 민감합니다.
간단한 코드 예시
import openai
import json
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def classify_intent(user_query: str) -> dict:
"""사용자 질문 의도 분류"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": "당신은 의도 분류기입니다. JSON 형식으로 반환하세요: {intent, confidence, sub_category}"},
{"role": "user", "content": user_query}
],
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
# 사용 예시
result = classify_intent("지난주 주문을 취소하고 싶어요")
# {"intent": "refund_request", "confidence": 0.95, "sub_category": "subscription_cancel"}
비용 산정
| 시나리오 규모 | 1회 호출 비용 | 일일 비용(10만 회) |
|---|---|---|
| 입문용 고객센터(입력 50 + 출력 20) | $0.000035 | $3.5 |
| 중형 SaaS(입력 200 + 출력 30) | $0.000078 | $7.8 |
| 기업용(입력 500 + 출력 50) | $0.000163 | $16.3 |
💡 최적화 제안: 분류 태그와 예시를 시스템 프롬프트에 넣고 캐싱을 활성화하면 입력 비용을 최대 90%까지 절감할 수 있습니다. APIYI(apiyi.com)를 통해 호출하면 캐싱 할인 혜택이 그대로 적용됩니다.
GPT-5.4 nano 활용 사례 2: 데이터 추출
시나리오 설명
비정형 텍스트(이력서, 계약서, 뉴스, 이메일 등)에서 구조화된 필드를 추출하는 작업입니다. 이는 nano의 강력한 장점 중 하나로, Structured Outputs(JSON Schema 강제 제약) 기능을 활용하면 99% 이상의 높은 형식 정확도를 보장할 수 있습니다.
실전 코드
from pydantic import BaseModel
from typing import Optional
class ContactInfo(BaseModel):
name: str
email: Optional[str]
phone: Optional[str]
company: Optional[str]
role: Optional[str]
def extract_contact(text: str) -> ContactInfo:
response = client.beta.chat.completions.parse(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": "연락처 정보를 추출하세요. 누락된 필드는 null을 반환합니다."},
{"role": "user", "content": text}
],
response_format=ContactInfo
)
return response.choices[0].message.parsed
nano에 적합한 추출 작업 리스트
- 이력서/CV 핵심 필드 추출
- 송장/영수증 숫자 인식
- 이메일 서명 블록 파싱
- 뉴스 개체명 인식(인명, 지명, 기관명)
- 양식 데이터 정규화
- 로그 이벤트 분류
GPT-5.4 nano 활용 사례 3: 콘텐츠 순위 재조정(Reranking)
시나리오 설명
검색 결과, 추천 목록, 메시지 큐 등을 재정렬하는 작업입니다. nano 모델의 저렴한 비용 덕분에 이제는 프로덕션 환경에서도 LLM을 활용한 리랭커(reranker) 도입이 경제적으로 가능해졌습니다.
순위 재조정 코드 예시
def rerank_documents(query: str, candidates: list[str], top_k: int = 5) -> list:
"""질의 관련성에 기반하여 후보 문서를 재정렬합니다"""
docs_text = "\n".join([f"[{i}] {doc[:300]}" for i, doc in enumerate(candidates)])
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[{
"role": "user",
"content": f"""질의 "{query}"를 기준으로 다음 문서들을 관련성 순으로 정렬하세요.
문서:
{docs_text}
JSON 형식으로 반환: {{"ranking": [문서 인덱스 리스트, 가장 관련성 높은 순서부터]}}"""
}],
response_format={"type": "json_object"}
)
ranking = json.loads(response.choices[0].message.content)["ranking"]
return [candidates[i] for i in ranking[:top_k]]
🎯 활용 제안: nano 모델을 활용한 재정렬은 기존의 BM25 + 벡터 검색 기반 리랭커보다 정확도가 높으면서도, GPT-5.4-mini 대비 비용은 27% 수준에 불과합니다. APIYI(apiyi.com)를 통해 즉시 연동 가능하며, 별도의 신청 절차 없이 Default 그룹에서 바로 사용할 수 있습니다.
GPT-5.4 nano 활용 사례 4: 서브 에이전트(Sub-agent) 실행 계층
시나리오 설명
멀티 에이전트 아키텍처에서 메인 에이전트(주로 mini 또는 표준 모델 사용)가 계획을 수립하면, 서브 에이전트(실행 워커)는 구체적인 도구 호출, 데이터 조회, 상태 업데이트를 담당합니다. nano 모델은 τ2-Bench에서 92.5%의 점수를 기록하며 워커 역할을 완벽하게 수행합니다.
멀티 에이전트 협업 예시
def execute_subtask(task: dict, available_tools: list) -> dict:
"""서브 에이전트로서 단일 하위 작업을 수행하는 nano"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": f"당신은 실행 워커입니다. 사용 가능한 도구: {available_tools}"},
{"role": "user", "content": f"작업 수행: {task['description']}"}
],
tools=task.get("tools", []),
tool_choice="auto"
)
return {
"task_id": task["id"],
"result": response.choices[0].message.content,
"tool_calls": response.choices[0].message.tool_calls
}
# 메인 에이전트는 mini, 서브 에이전트는 nano를 사용하여 비용을 60% 이상 절감하세요.
GPT-5.4 nano 활용 사례 5: RAG 라우팅 계층
시나리오 설명
RAG 시스템에서 nano를 '라우팅 계층'으로 활용해 쿼리 유형(기술 질문 / 사전 상담 / 제품 피드백 / 일상 대화)을 판단하고 적절한 처리기로 분배합니다. 이러한 설계 덕분에 비용이 높은 mini 또는 표준 모델은 꼭 필요한 경우에만 호출할 수 있습니다.
RAG 라우팅 예시
def route_query(query: str) -> str:
"""nano가 쿼리를 어떤 RAG 처리기로 보낼지 판단합니다"""
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[
{"role": "system", "content": """쿼리 유형에 따라 라우팅 태그를 반환하세요:
- "technical_docs": 기술 문서 조회
- "product_faq": 제품 FAQ
- "code_help": 코드 도움
- "small_talk": 일상 대화(RAG 불필요)
- "complex_reasoning": 복잡한 추론(mini/표준 모델로 전달)"""},
{"role": "user", "content": query}
],
max_tokens=20
)
return response.choices[0].message.content.strip()
route = route_query(user_input)
if route == "complex_reasoning":
final_model = "gpt-5.4-mini" # mini 모델로 업그레이드
else:
final_model = "gpt-5.4-nano" # nano 모델 유지
💰 비용 최적화: 'nano 라우팅 + mini/표준 모델 처리' 아키텍처를 사용하면 전체 호출 비용을 보통 60~80%까지 절감할 수 있습니다. APIYI(apiyi.com)를 통하면 동일한 API 키 환경에서
model파라미터만 수정하여 두 모델을 유연하게 전환할 수 있습니다.
GPT-5.4 nano 활용 사례 6: 고처리량 요약 및 번역
시나리오 설명
뉴스 요약, 문서 번역, 댓글 수정 등 대량의 작업을 처리할 때 유용합니다. 400K 컨텍스트 윈도우를 지원하므로 nano 하나로 긴 글을 한 번에 처리할 수 있으며, 건당 비용은 거의 무시할 수 있는 수준입니다.
Batch API 예시
# 배치 작업 준비
batch_requests = []
for doc_id, content in documents.items():
batch_requests.append({
"custom_id": f"summary-{doc_id}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
"model": "gpt-5.4-nano",
"messages": [
{"role": "system", "content": "다음 내용을 100자 내외로 요약하세요"},
{"role": "user", "content": content}
],
"max_tokens": 200
}
})
# Batch API 제출(동일 가격, 온라인 할당량 미차감)
batch = client.batches.create(
input_file_id=file_id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
GPT-5.4 nano 애플리케이션 시나리오 7: Tool Use 도구 호출
시나리오 설명
τ2-Bench 테스트에서 nano 모델은 92.5%의 점수를 기록하며, mini 모델의 93.4% 성능을 거의 따라잡았습니다. "날씨 확인, 주문 조회, 문서 검색"과 같은 표준화된 도구 호출(Function Calling) 시나리오에서 nano는 충분히 제 역할을 해낼 수 있습니다.
도구 호출(Function Calling) 예시
tools = [{
"type": "function",
"function": {
"name": "get_order_status",
"description": "주문 상태 조회",
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string"}
},
"required": ["order_id"]
}
}
}]
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[{"role": "user", "content": "내 주문 #12345 어떻게 됐어?"}],
tools=tools,
tool_choice="auto"
)
# nano가 get_order_status 호출이 필요함을 정확히 식별하고, order_id="12345"를 추출합니다.
GPT-5.4 nano 가격 상세
공식 가격 구조
| 과금 유형 | 가격(1M 토큰당) | 설명 |
|---|---|---|
| 입력 | $0.20 | 표준 가격 |
| 캐시된 입력 | $0.02 | 90% 할인 |
| 출력 | $1.25 | 추론 토큰 포함 |
| Batch API | $0.20 / $1.25 | 동일 가격, 온라인 할당량 미차감 |
| 지역 데이터 상주 | +10% | 데이터 규정 준수 시나리오 |
nano vs mini 가격 비교
| 항목 | gpt-5.4-nano | gpt-5.4-mini | 배수 |
|---|---|---|---|
| 입력 | $0.20 | $0.75 | nano가 3.75배 저렴 |
| 캐시된 입력 | $0.02 | $0.075 | nano가 3.75배 저렴 |
| 출력 | $1.25 | $4.50 | nano가 3.6배 저렴 |
| 응답 속도 | ~200 t/s | ~180 t/s | nano가 약 10% 빠름 |
| 컨텍스트 | 400K | 400K | 동일 |
| 최대 출력 | 128K | 128K | 동일 |
💰 비용 최적화: 하루 수백만 건의 요청이 발생하는 고처리량 시나리오에서는 nano와 mini의 가격 차이가 매달 수천 달러의 절감 효과로 이어집니다. APIYI(apiyi.com)를 통해 접속하시면 100달러 충전 시 10% 추가 증정 혜택을 받을 수 있으며, 이는 공식 홈페이지 대비 15% 할인된 효과로, 종합적인 비용을 최대 25%까지 절감할 수 있습니다.
GPT-5.4 nano vs mini 벤치마크 전면 비교

| 평가 항목 | gpt-5.4-nano | gpt-5.4-mini | 차이 | nano로 충분한가? |
|---|---|---|---|---|
| SWE-Bench Pro | 52.4% | 54.4% | -2.0pp | ✅ 거의 동일 |
| Terminal-Bench 2.0 | 46.3% | 60.0% | -13.7pp | ⚠️ 긴 작업은 mini 권장 |
| Toolathlon | 35.5% | 42.9% | -7.4pp | ✅ 일반 작업은 충분 |
| GPQA Diamond | 82.8% | 88.0% | -5.2pp | ✅ 지식 질의응답 가능 |
| OSWorld-Verified | 39.0% | 72.1% | -33.1pp | ❌ Computer Use는 mini 필수 |
| τ2-Bench(Tool Use) | 92.5% | 93.4% | -0.9pp | ✅ 거의 대등 |
| MCP Atlas | 56.1% | 57.7% | -1.6pp | ✅ 거의 동일 |
| 응답 속도 | ~200 t/s | ~180 t/s | +10% | ✅ nano가 오히려 빠름 |
모델 선택 가이드
nano 사용을 추천하는 경우:
- "그린존" 작업(분류, 추출, 정렬, 라우팅, 도구 사용, 일괄 처리)
- 일일 호출량 1만 건 이상으로 비용 효율성이 중요한 경우
- 1초 미만의 빠른 응답 속도가 필요한 경우
- 서브 에이전트 실행 계층(메인 에이전트는 mini, 워커는 nano 사용)
mini로 업그레이드해야 하는 경우:
- Computer Use가 포함된 작업(OSWorld에서 큰 격차 발생)
- 터미널 긴 작업(10단계 이상의 조작)
- 복잡한 다단계 추론이나 심층적인 코드 디버깅이 필요한 경우
- 비용보다 작업 품질이 우선인 경우
📊 선택 팁: "고처리량 + 낮은 복잡도"를 요구하는 80%의 작업 환경에서는 nano의 가성비가 압도적입니다. APIYI(apiyi.com)를 통해 모델 파라미터만 변경하여 실제 작업에서 두 모델의 성능을 직접 비교해 보세요.
GPT-5.4 nano의 APIYI 연동 가이드
Default 그룹에서 바로 사용 가능
APIYI 플랫폼은 GPT-5.4 nano와 5.4-mini 모델에 대해 동일한 개방 정책을 적용하고 있습니다:
- ✅ Default 기본 그룹: 전체 개방, 신규 회원 가입 즉시 호출 가능
- ✅ SVIP 고급 그룹: 전체 개방, 제한 없음
- ✅ 캐시 할인 동기화: $0.02/1M 캐시 가격 완벽 적용
- ✅ Batch API 동기화: 대량 작업(Batch)도 동일한 가격 혜택 적용
APIYI vs 공식 홈페이지 비용 비교
| 항목 | OpenAI 공식 홈페이지 | APIYI (apiyi.com) |
|---|---|---|
| 기본 가격 | $0.20 / $1.25 per 1M | $0.20 / $1.25 per 1M (동일) |
| 캐시 할인 | $0.02 / 1M (90%) | $0.02 / 1M (완벽 동기화) |
| 충전 혜택 | 없음 | $100 충전 시 $10 추가 증정 (10%) |
| 실제 비용 | 100% 표준가 | 약 90% 표준가 (약 15% 할인) |
| 국내 접속 | VPN 필요 | 직결 가능, VPN 불필요 |
| 결제 방식 | 해외 신용카드 | 위챗페이, 알리페이 등 지원 |
| SDK 호환 | OpenAI 네이티브 | OpenAI SDK 완벽 호환 |
| 최소 충전 | $5 | $1부터 충전 가능 |
💰 비용 최적화: 월간 호출량이 백만 단위 이상인 애플리케이션의 경우, APIYI(apiyi.com)를 통해 nano 모델을 연동하면 공식 홈페이지 대비 15% 할인에 캐시 최적화까지 더해져, 직접 호출 대비 종합 비용을 25~35%까지 절감할 수 있습니다.
자주 묻는 질문 (FAQ)
Q1: gpt-5.4-nano란 무엇인가요? gpt-5.4-mini와 어떤 차이가 있나요?
GPT-5.4-nano는 OpenAI GPT-5.4 시리즈 중 가장 저렴하고 빠른 경량 모델($0.20/$1.25 per 1M tokens)로, 응답 속도는 약 200 t/s입니다. 5.4-mini와의 핵심 차이점은 1) 가격이 3.6~3.75배 저렴함, 2) Computer Use(OSWorld 39% vs 72.1%) 및 터미널 장기 작업(46.3% vs 60%) 성능이 다소 낮음, 3) 기타 작업(분류, 추출, 도구 사용, 질의응답)에서의 성능 차이는 보통 10%p 미만입니다.
Q2: nano는 어떤 애플리케이션에 적합하고, 어떤 경우에 mini를 써야 하나요?
nano 추천(그린 존):
- 실시간 분류(감정, 의도, 주제)
- 구조화된 데이터 추출
- 콘텐츠 정렬 및 재정렬
- 서브 에이전트 실행 계층
- RAG 라우팅 계층
- 고처리량 요약/번역
- 표준화된 도구 호출(τ2-Bench 92.5%)
mini 필수(레드 존):
- Computer Use 데스크톱 자동화(OSWorld 성능 차이 33%p)
- 터미널 장기 작업(10단계 이상)
- 복잡한 다단계 추론
- 파인튜닝이 필요한 맞춤형 시나리오
Q3: nano가 Computer Use에 권장되지 않는 이유는 무엇인가요?
OSWorld-Verified 평가에서 nano는 39.0%를 기록하여 mini의 72.1%보다 현저히 낮습니다. 이는 nano가 다단계 데스크톱 작업(브라우저 열기→검색→클릭→양식 작성)에서 실패율이 높아 안정적인 작업 수행이 어렵다는 것을 의미합니다. Computer Use가 필요한 작업이라면 mini나 5.4 표준 버전을 선택하세요.
Q4: nano의 캐시 할인 $0.02/1M은 어떻게 활성화하나요?
OpenAI의 캐시 메커니즘은 자동으로 트리거되며 별도의 파라미터가 필요 없습니다. 프롬프트 접두사(보통 시스템 프롬프트 + 공유 컨텍스트)가 최근 5~10분 내의 요청과 일치하면 자동으로 캐시가 적중되어 90% 할인이 적용됩니다.
최적화 팁:
- 시스템 프롬프트를 메시지 배열의 가장 앞에 배치하세요.
- 공유 컨텍스트(분류 태그, 스키마 정의)를 그 뒤에 배치하세요.
- 사용자 실제 질문은 마지막에 배치하세요.
- 호출 빈도를 유지하세요(5분 이상 경과 시 만료).
APIYI(apiyi.com)를 통해 호출하면 캐시 할인 정책이 공식 홈페이지와 동일하게 동기화됩니다.
Q5: nano로 대량 작업을 처리하는 가장 좋은 방법은 무엇인가요?
세 가지 핵심 전략:
- Batch API 사용:
/v1/batches인터페이스를 통해 대량 작업을 제출하세요. 24시간 이내 완료되며, 가격은 동일하지만 온라인 RPM 할당량을 소모하지 않습니다. - 시스템 프롬프트 공유: 모든 작업에 동일한 지침을 사용하여 캐시 적중률을 높이세요.
- 적절한 max_tokens 설정: nano의 출력은 저렴하지만 누적되면 비용이 발생하므로, 작업에 맞춰 50~500 사이의 합리적인 상한선을 설정하세요.
APIYI(apiyi.com)를 통해 Batch 작업을 제출하면 충전 10% 혜택을 포함해 공식 홈페이지 대비 약 85% 수준의 비용으로 이용 가능합니다.
Q6: APIYI를 통해 GPT-5.4 nano를 호출하는 방법은?
APIYI는 OpenAI SDK와 완벽 호환되므로 세 단계만 거치면 됩니다:
- APIYI(apiyi.com)에 접속하여 계정 생성(별도 신청 없이 Default 그룹 바로 사용 가능)
- API 키 발급
- 코드 내
base_url을https://vip.apiyi.com/v1으로,model을gpt-5.4-nano로 설정
client = openai.OpenAI(
api_key="YOUR_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-nano",
messages=[...]
)
100달러 충전 시 10% 추가 증정 혜택이 있어 공식 홈페이지 대비 약 15% 저렴하며, 캐시 할인도 동일하게 적용됩니다.
Q7: nano가 mini보다 경제적인 경우는 언제인가요? 계산법은?
판단 공식:
nano가 유리한 조건 = (작업 품질 저하 허용도) × (호출량) × (가격 차이)
> (mini 업그레이드로 얻는 품질 향상 가치)
실제 사례:
- 일일 호출량 > 10K: 하루 $30 이상 절감 (월 $1000)
- 일일 호출량 > 100K: 하루 $300 이상 절감 (월 $9000)
- 일일 호출량 > 1M: 하루 $3000 이상 절감 (월 $90000)
그린 존 작업(분류, 추출, 도구 사용)의 경우 nano의 품질 손실은 보통 5% 미만이지만, 비용은 73% 절감(계산 비용 3.6배 차이)됩니다. 종합적인 ROI 측면에서 nano가 거의 항상 유리합니다.
Q8: GPT-5.4 nano의 알려진 제한 사항은 무엇인가요?
주요 제한 사항:
- Computer Use 미지원: OSWorld 39%로 데스크톱 자동화 수행이 어려움
- 파인튜닝 미지원: 사용자 정의 데이터셋으로 미세 조정 불가
- 오디오/비디오 입력 미지원: 텍스트 및 이미지 입력만 가능
- 터미널 장기 작업 취약: Terminal-Bench 46.3%로 10단계 이상의 작업 시 실패 가능성 높음
- 복잡한 추론 능력 제한: GPQA 82.8%로 mini와 비슷하나, FrontierMath 등 극도로 어려운 작업에서는 성능 저하
대안: 위 제한 사항에 해당할 경우 gpt-5.4-mini 또는 5.4 표준 버전으로 전환하세요.
GPT-5.4 nano 활용 사례 핵심 요약 (Key Takeaways)
- 가격 경쟁력: 1M 토큰당 $0.20/$1.25로, 5.4-mini 대비 3.6~3.75배 저렴합니다.
- 캐싱 90% 할인: 입력 비용이 1M 토큰당 최저 $0.02까지 낮아져, 고빈도 컨텍스트 활용 시 사실상 무료에 가깝습니다.
- 7대 주요 활용 분야: 분류, 데이터 추출, 정렬, 서브 에이전트(Sub-agent), 라우팅, 배치 처리, 도구 사용(Tool Use).
- τ2-Bench 92.5%: 도구 호출 성능이 mini 모델과 거의 대등하며, 90% 이상의 Function Calling 작업에 충분합니다.
- GPQA 82.8%: 뛰어난 일반 지식 질의응답 능력을 갖춰 FAQ 및 콘텐츠 검토에 적합합니다.
- 속도 200 t/s: mini보다 10% 더 빨라 고처리량 파이프라인에 최적입니다.
- 주의 사항: Computer Use나 터미널 장기 작업 시에는 반드시 mini 모델로 전환해야 합니다.
요약
GPT-5.4 nano 활용 사례의 핵심 포인트는 다음과 같습니다:
- 활용 전략: nano는 실시간 분류, 데이터 추출, 서브 에이전트 워커, RAG 라우팅, 배치 처리 등 고처리량 및 저복잡도 작업에 최적화된 모델입니다.
- 성능 범위: τ2-Bench, GPQA, SWE-Bench Pro 등에서 mini 모델과 대등한 성능을 보여주지만, Computer Use나 터미널 장기 작업 능력은 상대적으로 약합니다.
- 연동 방법: APIYI(apiyi.com)의 Default 그룹을 통해 즉시 호출 가능하며, 캐싱 할인 혜택이 동일하게 적용됩니다. 현재 100 충전 시 10 추가 증정 이벤트를 진행 중입니다.
GPT-5.4 nano는 단순히 '모든 것을 적당히 하는' 저가형 모델이 아니라, OpenAI가 고처리량 및 저복잡도 시나리오를 위해 정교하게 최적화한 경량형 모델입니다. 본문에서 언급한 7대 주요 분야에 해당한다면, nano가 mini보다 훨씬 경제적인 선택이 될 것입니다. 다만, Computer Use나 터미널 장기 작업이 필요하다면 mini 모델을 사용하는 것이 올바른 선택입니다.
APIYI(apiyi.com) 플랫폼을 통해 GPT-5.4 nano를 빠르게 연동해 보세요. Default 그룹은 별도 신청 없이 즉시 사용 가능하며, 캐싱 할인 자동 적용, 충전 금액 10% 추가 증정, 그리고 국내에서의 안정적인 연결을 보장합니다.
추가 읽을거리
GPT-5.4 nano API에 관심이 있으시다면 다음 콘텐츠도 함께 확인해 보세요:
- 📘 GPT-5.4 mini API 업그레이드 가이드 – 이전 단계인 mini 모델의 성능과 활용 사례를 알아보세요.
- 📊 OpenAI 캐싱 메커니즘 심층 분석: 90% 할인 혜택을 누리는 베스트 프랙티스 – 캐싱 최적화 엔지니어링 기술을 마스터하세요.
- 🚀 GPT-5.4 nano 기반 RAG 라우팅 레이어 실전 구축 – "nano 라우팅 + mini 처리" 혼합 아키텍처를 탐구해 보세요.
📚 참고 자료
-
OpenAI 공식 GPT-5.4 nano 문서: 모델 사양, 가격 정책, 호출 예제
- 링크:
developers.openai.com/api/docs/models/gpt-5.4-nano - 설명: 가장 최신의 공신력 있는 공식 기술 파라미터를 확인하세요.
- 링크:
-
AI Cost Check 벤치마크 분석: nano vs mini 전 영역 평가
- 링크:
aicostcheck.com/blog/gpt-5-4-mini-nano-pricing-benchmarks - 설명: 제3자 평가를 통해 모델 간 성능 차이를 가로 비교해 보세요.
- 링크:
-
APIYI GPT-5.4 nano 연동 문서: 국내 호출 솔루션, 그룹 설정, 충전 혜택
- 링크:
docs.apiyi.com - 설명: 국내 개발자를 위한 실전 연동 가이드입니다.
- 링크:
-
OpenAI 가격 페이지: 전체 가격표 및 캐싱 메커니즘 설명
- 링크:
developers.openai.com/api/docs/pricing - 설명: 모든 모델의 최신 과금 기준을 확인할 수 있습니다.
- 링크:
작성자: APIYI 기술팀
기술 교류: 댓글로 GPT-5.4 nano 활용 경험을 자유롭게 공유해 주세요. 더 많은 모델 연동 자료는 APIYI 문서 센터(docs.apiyi.com)에서 확인하실 수 있습니다.