Gemini 3.1 Pro Preview에 medium 추론 레벨이 추가되었습니다. 이는 이전 세대인 Gemini 3 Pro와 가장 큰 차이점 중 하나예요. 이제 low, medium, high 세 가지 단계로 모델의 추론 깊이를 정밀하게 제어할 수 있으며, 특히 high 모드에서는 Deep Think Mini 기능이 활성화됩니다.
핵심 가치: 이 글을 읽고 나면 thinkingLevel 파라미터 설정 방법을 완벽히 마스터하고, 품질, 속도, 비용 사이에서 최적의 균형을 찾는 법을 배우게 될 거예요.

Gemini 3.1 Pro 추론 레벨 전체 지원 매트릭스
먼저 전체적인 그림을 살펴볼까요? Gemini 모델마다 지원하는 추론 레벨이 다릅니다.
| 추론 레벨 | Gemini 3.1 Pro | Gemini 3 Pro | Gemini 3 Flash | 설명 |
|---|---|---|---|---|
| minimal | ❌ 지원 안 함 | ❌ 지원 안 함 | ✅ 지원 | 추론 거의 끄기, Flash만 지원 |
| low | ✅ 지원 | ✅ 지원 | ✅ 지원 | 빠른 응답, 최저 비용 |
| medium | ✅ 신규 지원 | ❌ 지원 안 함 | ✅ 지원 | 균형 잡힌 추론, 3.1 Pro의 핵심 업그레이드 |
| high | ✅ 지원 (기본) | ✅ 지원 (기본) | ✅ 지원 (기본) | 가장 깊은 추론, Deep Think Mini 활성화 |
핵심 변화: 3 Pro → 3.1 Pro 추론 레벨 업그레이드
| 비교 | Gemini 3 Pro | Gemini 3.1 Pro |
|---|---|---|
| 사용 가능 레벨 | low, high (2단계) | low, medium, high (3단계) |
| 기본 레벨 | high | high |
| high 모드의 의미 | 깊은 추론 | Deep Think Mini (더 강력함) |
| 추론 끄기 가능 여부 | 불가능 | 불가능 |
핵심 이해: Gemini 3 Pro의 high 추론 깊이는 Gemini 3.1 Pro의 medium과 비슷합니다. 반면 3.1 Pro의 high는 완전히 새로운 Deep Think Mini로, 이전 세대보다 훨씬 더 깊은 추론 성능을 보여줍니다.
🎯 마이그레이션 제안: 이전에 Gemini 3 Pro의 high 모드를 사용하셨다면, 3.1 Pro로 전환할 때 먼저 medium을 사용해 보세요(비슷한 품질과 비용 유지). 정말 깊은 추론이 필요할 때만 high를 켜는 것을 추천합니다. APIYI(apiyi.com)는 모든 Gemini 모델과 추론 레벨을 완벽하게 지원합니다.
Gemini 3.1 Pro 사고 등급(Thinking Level) API 설정 방법
APIYI를 통한 호출 (OpenAI 호환 형식)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 统一接口
)
# LOW 模式: 快速响应
response_low = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "把这段英文翻译成中文: Hello World"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 1024}
}
)
# MEDIUM 模式: 平衡推理 (新增!)
response_med = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "审查这段代码有没有内存泄漏风险"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 8192}
}
)
# HIGH 模式: Deep Think Mini
response_high = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "证明: 对所有正整数n, n^3-n能被6整除"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 32768}
}
)
Google SDK를 통한 네이티브 호출
from google import genai
from google.genai import types
client = genai.Client()
# 使用 thinkingLevel 参数
response = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents="你的提示词",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level="MEDIUM" # "LOW" / "MEDIUM" / "HIGH"
)
),
)
# 查看思考 token 消耗
print(f"思考 token: {response.usage_metadata.thoughts_token_count}")
print(f"输出 token: {response.usage_metadata.candidates_token_count}")
REST API 호출
POST https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent
{
"contents": [{"parts": [{"text": "你的提示词"}]}],
"generationConfig": {
"thinkingConfig": {
"thinkingLevel": "MEDIUM"
}
}
}
⚠️ 중요 알림:
thinkingLevel과thinkingBudget은 동시에 사용할 수 없으며, 함께 사용하면 400 오류가 반환됩니다. Gemini 3+ 모델은thinkingLevel사용을 권장하며, Gemini 2.5 모델은thinkingBudget을 사용해 주세요.
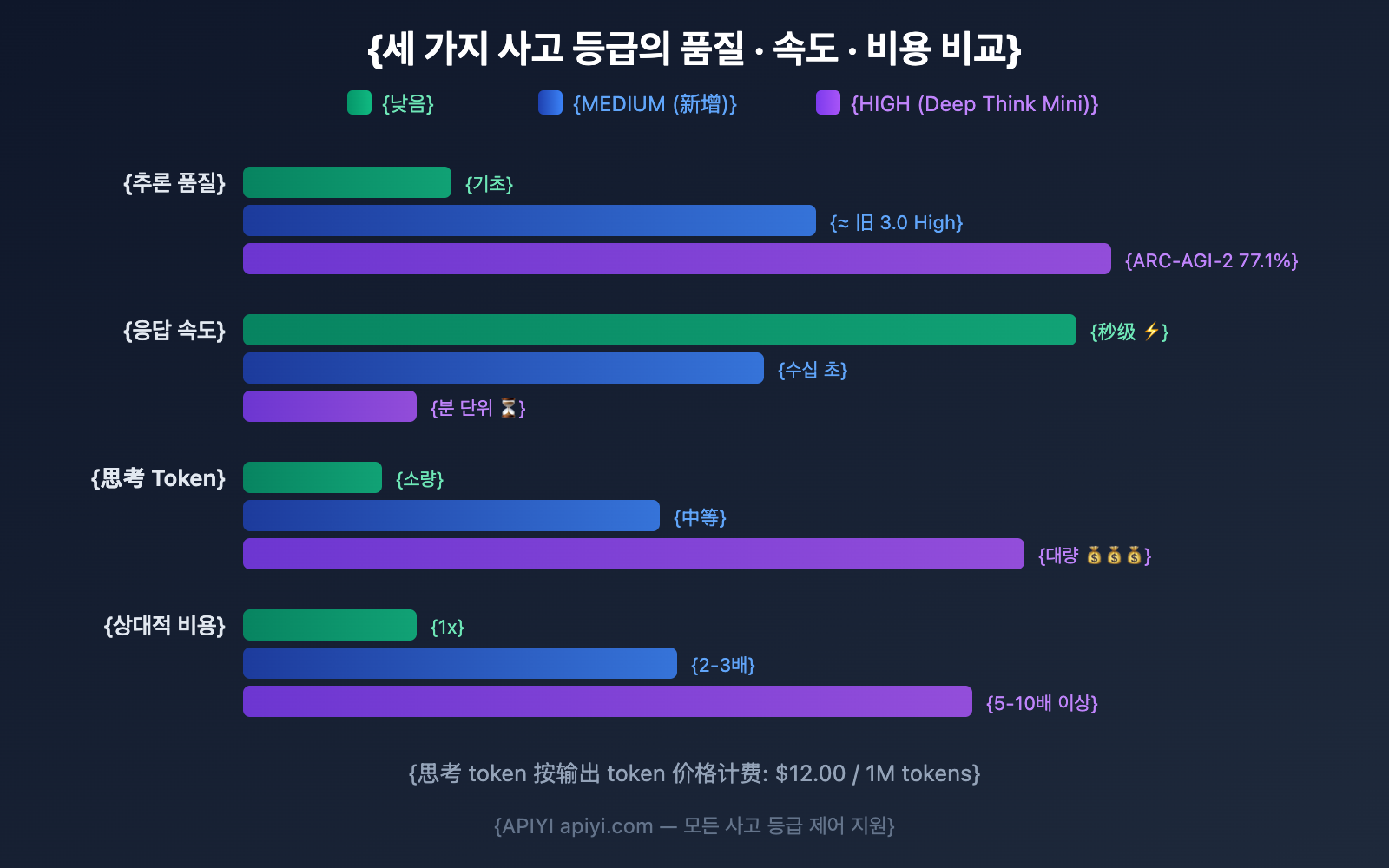
3가지 사고 등급의 Gemini 3.1 Pro 상세 비교
LOW: 가장 빠르고 저렴함
| 구분 | 상세 내용 |
|---|---|
| 추론 깊이 | 최소한의 사고 토큰을 사용하지만, 사고 기능이 없는 모델보다는 우수함 |
| 응답 속도 | 초 단위 (가장 빠름) |
| 비용 | 가장 낮음 (사고 토큰 적음 → 출력 토큰 적음 → 비용 절감) |
| 활용 사례 | 자동 완성, 분류, 구조화된 데이터 추출, 단순 번역, 요약 |
| 비권장 사례 | 복잡한 추론, 수학 증명, 다단계 디버깅 |
MEDIUM: 균형 잡힌 선택 (신규)
| 구분 | 상세 내용 |
|---|---|
| 추론 깊이 | 중간 수준의 사고 토큰 사용, 이전 버전 3.0 Pro의 High 수준과 비슷함 |
| 응답 속도 | 중간 정도의 지연 시간 |
| 비용 | 보통 |
| 활용 사례 | 코드 리뷰, 문서 분석, 일상적인 코딩, 표준 API 호출, 질의응답 |
| 비권장 사례 | IMO(국제수학올림피아드) 수준의 수학, 극도로 복잡한 다단계 추론 |
HIGH: Deep Think Mini (기본값)
| 구분 | 상세 내용 |
|---|---|
| 추론 깊이 | 추론 능력을 극대화하여 Deep Think Mini 성능 활성화 |
| 응답 속도 | 수 분 정도 소요될 수 있음 (IMO 문제의 경우 약 8분) |
| 비용 | 가장 높음 (대량의 사고 토큰이 출력 가격으로 청구됨) |
| 활용 사례 | 복잡한 디버깅, 알고리즘 설계, 수학 증명, 연구 과제, 에이전트 워크플로우 |
| 특수 기능 | 사고 서명(Thought Signatures)을 통해 여러 API 호출 간 추론 연속성 유지 |
Gemini 3.1 Pro 사고(Thinking) 토큰 과금 규칙
비용 산정 방식을 이해하는 것이 적절한 사고 등급을 선택하는 핵심입니다.
핵심 과금 원칙
| 과금 항목 | 설명 |
|---|---|
| 사고 토큰 과금 여부 | 예, 출력 토큰과 동일한 가격으로 과금됩니다. |
| 출력 토큰 가격 | $12.00 / 1M 토큰 (사고 토큰 포함) |
| 과금 기준 | 요약본뿐만 아니라 전체 내부 추론 체인을 기준으로 과금됩니다. |
| 사고 요약 | API는 사고 요약만 반환하지만, 과금은 전체 사고 토큰 수를 기준으로 이루어집니다. |
구글 공식 설명:
"Thinking 모델은 최종 답변의 품질을 높이기 위해 전체 사고 과정을 생성한 다음, 사고 과정에 대한 통찰력을 제공하기 위해 요약본을 출력합니다. API에서는 요약본만 출력되더라도, 모델이 요약본을 만들기 위해 생성해야 하는 **전체 사고 토큰(full thought tokens)**을 기준으로 가격이 책정됩니다."
세 가지 등급별 비용 추정
| 등급 | 예상 사고 토큰 | 1,000회 호출 기준 | 월간 비용 추세 |
|---|---|---|---|
| LOW | 회당 ~500-2K | $6-24 | 최저 |
| MEDIUM | 회당 ~2K-8K | $24-96 | 중간 |
| HIGH | 회당 ~8K-32K+ | $96-384+ | 높은 편, 복잡한 작업일수록 증가 |
💰 비용 최적화 팁: 모든 요청에 HIGH 등급이 필요한 것은 아닙니다. 일상적인 작업의 80%를 LOW 또는 MEDIUM으로 설정하고, 복잡한 작업 20%에만 HIGH를 사용하면 API 지출을 50-70%까지 절감할 수 있습니다. APIYI(apiyi.com) 플랫폼을 통해 유연하게 설정해 보세요.
작업 유형별 Gemini 3.1 Pro 사고 등급 매칭 가이드
상세 시나리오 추천
| 작업 유형 | 추천 등급 | 이유 | 예상 지연 시간 |
|---|---|---|---|
| 간단한 번역 | LOW | 추론이 필요 없음 | <5초 |
| 텍스트 분류 | LOW | 패턴 매칭 작업 | <5초 |
| 요약 추출 | LOW | 정보 압축이며 추론이 아님 | <10초 |
| 자동 완성 | LOW | 지연 시간에 민감함 | <3초 |
| 코드 리뷰 | MEDIUM | 적절한 분석이 필요함 | 10-30초 |
| 문서 Q&A | MEDIUM | 이해 및 답변 구성 | 10-30초 |
| 일상적인 코딩 | MEDIUM | 일반적인 코드 생성 | 15-40초 |
| 버그 분석 | MEDIUM | 중간 난이도의 추론 | 20-40초 |
| 복잡한 디버깅 | HIGH | 다단계 추론 체인 필요 | 1-5분 |
| 수학 증명 | HIGH | Deep Think Mini 활용 | 3-8분 |
| 알고리즘 설계 | HIGH | 심층적인 추론 필요 | 2-5분 |
| 연구 및 분석 | HIGH | 다차원적 심층 분석 | 2-5분 |
| 에이전트 워크플로우 | HIGH | 사고 서명의 연속성 유지 | 작업에 따라 다름 |
동적 등급 선택: 베스트 프랙티스 코드
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
# 작업 유형에 따라 사고 등급 자동 선택
THINKING_CONFIG = {
"simple": {"type": "enabled", "budget_tokens": 1024}, # LOW
"medium": {"type": "enabled", "budget_tokens": 8192}, # MEDIUM
"complex": {"type": "enabled", "budget_tokens": 32768}, # HIGH
}
def smart_think(prompt, complexity="medium"):
"""작업 복잡도에 따라 사고 등급을 자동으로 설정합니다."""
return client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking": THINKING_CONFIG[complexity]}
)
# 간단한 번역 → LOW
resp1 = smart_think("번역해줘: Good morning", "simple")
# 코드 리뷰 → MEDIUM
resp2 = smart_think("이 코드의 보안성을 검토해줘: ...", "medium")
# 수학 증명 → HIGH (Deep Think Mini)
resp3 = smart_think("리만 가설의 특정 사례를 증명해줘", "complex")
Gemini 3.1 Pro vs 3 Pro: 추론 단계 진화 비교

Deep Think Mini, 도대체 무엇이 그렇게 강력할까요?
Gemini 3.1 Pro의 HIGH 모드에서 활성화되는 Deep Think Mini는 이번 업데이트의 가장 큰 핵심입니다.
Deep Think Mini란 무엇인가요?
Deep Think Mini는 독립된 모델이 아니라, Gemini 3.1 Pro의 HIGH 추론 단계(Thinking Level)에서 작동하는 특수 추론 모드입니다. 구글은 이를 'Gemini Deep Think의 미니 버전'이라고 설명합니다. 참고로 Deep Think는 구글의 전용 고성능 추론 모델(ARC-AGI-2 점수 84.6%)입니다.
Deep Think Mini 실제 성능 테스트 결과
| 테스트 항목 | Deep Think Mini (3.1 Pro HIGH) | Gemini 3 Pro HIGH | 향상 폭 |
|---|---|---|---|
| ARC-AGI-2 | 77.1% | 31.1% | +148% |
| IMO 수학 문제 | ~8분 만에 해결 | 해결 불가 | 해결 불가능에서 가능으로 |
| 복잡한 계획 작업 | 벤치마크 40-60% 향상 | Gemini 2.5 Pro 대비 | 괄목할 만한 향상 |
추론 시그니처 (Thought Signatures)
Deep Think Mini에는 **추론 시그니처(thought signatures)**라는 독특한 기술이 도입되었습니다. 이는 암호화되어 변조가 불가능한 중간 추론 상태를 나타냅니다.
에이전트(Agent) 워크플로우에서 모델의 추론은 여러 번의 API 호출에 걸쳐 이루어지는 경우가 많습니다. 추론 시그니처는 이전 호출의 추론 컨텍스트를 다음 호출로 전달하여 추론의 연속성을 유지해 줍니다. 이는 다단계 에이전트 작업에서 특히 중요합니다.
어떤 작업에 Deep Think Mini를 사용해야 할까요?
| HIGH 모드(Deep Think Mini) 권장 | HIGH 모드 비권장 (기본 모드 권장) |
|---|---|
| 수학 경시 수준의 추론 | 단순 사칙연산 |
| 여러 파일에 걸친 복잡한 버그 디버깅 | 단순 문법 오류 수정 |
| 알고리즘 설계 및 최적화 | 단순 CRUD 코드 생성 |
| 학술 논문 방법론 분석 | 단순 문서 요약 |
| 다단계 에이전트 장기 작업 | 단발성 질의응답 |
| 보안 취약점 심층 분석 | 단순 형식 변환 |
💡 실용적인 팁: Deep Think Mini의 강력함에는 대가가 따릅니다. 지연 시간(Latency)과 비용이 모두 높기 때문이죠. 따라서 정말 '깊은 생각'이 필요한 작업에만 HIGH 모드를 사용하고, 일상적인 작업에는 MEDIUM으로도 충분합니다. **APIYI(apiyi.com)**를 이용하면 각 요청마다 유연하게 모드를 전환하며 사용할 수 있습니다.
thinkingLevel vs thinkingBudget: 헷갈리지 마세요
구글에는 사고 과정을 제어하는 두 가지 파라미터가 있으며, 모델 시리즈에 따라 다르게 적용됩니다.
| 파라미터 | 적용 모델 | 값 타입 | 설명 |
|---|---|---|---|
| thinkingLevel | Gemini 3+ (3 Flash, 3 Pro, 3.1 Pro) | 열거형(Enum): MINIMAL/LOW/MEDIUM/HIGH | Gemini 3 시리즈 권장 |
| thinkingBudget | Gemini 2.5 (Pro, Flash, Flash Lite) | 정수: 0-32768 | 2.5 시리즈에 적용 |
⚠️ 두 파라미터를 동시에 사용할 수 없습니다! 동시에 입력하면 400 에러가 반환됩니다.
| 상황 | 올바른 방법 | 잘못된 방법 |
|---|---|---|
| Gemini 3.1 Pro 호출 시 | thinkingLevel: "MEDIUM" 사용 |
thinkingBudget: 8192 사용 |
| Gemini 2.5 Pro 호출 시 | thinkingBudget: 8192 사용 |
thinkingLevel: "MEDIUM" 사용 |
| 두 파라미터 모두 전달 시 | — | 400 에러 발생 ❌ |
🎯 간단 요약: Gemini 3 시리즈 → thinkingLevel (문자열 등급), Gemini 2.5 시리즈 → thinkingBudget (숫자 토큰 수). APIYI(apiyi.com)는 두 가지 파라미터 형식을 모두 지원합니다.
자주 묻는 질문 (FAQ)
Q1: thinkingLevel을 설정하지 않으면 기본값은 무엇인가요?
기본값은 HIGH입니다. 즉, 별도로 설정하지 않으면 매 호출 시 Deep Think Mini의 모든 추론 능력을 사용하며, 가장 많은 사고 토큰을 소비하게 됩니다. 작업의 실제 필요에 따라 적절한 등급을 설정하여 비용을 절감하는 것이 좋습니다. APIYI(apiyi.com)를 사용하면 요청 단위로 유연하게 제어할 수 있습니다.
Q2: 사고 토큰은 어떻게 과금되나요? 많이 비싼가요?
사고 토큰은 출력 토큰과 동일한 가격으로 과금됩니다 ($12.00 / 1M tokens). HIGH 모드에서 복잡한 요청 하나가 3만 개 이상의 사고 토큰을 소비할 경우 비용은 약 $0.36입니다. 반면, LOW 모드에서 동일한 요청이 1,000개의 사고 토큰만 소비한다면 비용은 약 $0.012입니다. 비용 차이가 최대 30배까지 날 수 있습니다.
Q3: 3.1 Pro의 MEDIUM이 3.0 Pro의 HIGH와 같나요?
기본적으로 동일합니다. 구글의 설명에 따르면 3.1 Pro의 MEDIUM은 "대부분의 작업을 처리하기에 적합한 균형 잡힌 사고"를 제공하며, 이는 3.0 Pro의 HIGH가 지향하는 바와 일치합니다. 3.0 Pro에서 3.1 Pro로 마이그레이션할 때 HIGH를 MEDIUM으로 변경하면 비슷한 품질과 비용을 유지할 수 있습니다. APIYI(apiyi.com)를 통해 두 버전을 동시에 호출하며 비교해 보세요.
Q4: 사고 기능을 완전히 끌 수 있나요?
Gemini 3.1 Pro는 사고 기능을 완전히 끌 수 없습니다. 가장 낮은 설정인 LOW로 설정하더라도 기초적인 추론은 수행됩니다. 사고 과정이 전혀 없는 응답이 필요하다면 Gemini 3 Flash의 MINIMAL 모드를 고려해 보세요.
Gemini 3.1 Pro 사고 등급(Thinking Level)에 대한 흔한 오해
| 오해 | 사실 |
|---|---|
| 「HIGH 등급이 품질이 가장 좋으니 항상 써야 한다」 | HIGH는 간단한 작업에서 MEDIUM과 품질이 비슷하지만, 비용은 5~10배 더 비쌉니다. |
| 「LOW 등급은 추론 능력이 매우 떨어진다」 | LOW도 사고 기능이 아예 없는 모델보다는 훨씬 뛰어나며, 단지 사고 토큰(Thinking Token) 수가 적을 뿐입니다. |
| 「MEDIUM은 신기능이라 불안정할 수 있다」 | MEDIUM의 추론 깊이는 이전 버전인 3.0 Pro의 HIGH와 비슷하며, 이미 충분히 검증되었습니다. |
| 「사고 토큰은 과금되지 않는다」 | 과금됩니다! 출력 토큰과 동일한 가격($12/MTok)으로 청구됩니다. |
| 「3.1 Pro의 사고 기능을 끌 수 있다」 | 끌 수 없습니다. 최소 설정이 LOW이며, 여전히 기초적인 추론을 수행합니다. |
| 「thinkingLevel과 thinkingBudget을 함께 쓸 수 있다」 | 안 됩니다! 동시에 사용하면 400 에러가 반환됩니다. |
| 「높은 등급을 설정하면 지연 시간은 길어지지만 결과는 즉시 반환된다」 | HIGH 모드는 결과 반환을 시작하기까지 몇 분이 걸릴 수도 있습니다. 단순히 잠깐 지연되는 수준이 아닙니다. |
요약: Gemini 3.1 Pro 사고 등급 선택 가이드
| 등급 | 한 줄 요약 | 추천 시나리오 | 상대적 비용 |
|---|---|---|---|
| LOW | 가장 빠르고 저렴함 | 번역, 분류, 요약, 문장 완성 | 1x |
| MEDIUM | 밸런스형 추천 (신규) | 코딩, 코드 리뷰, 분석, 질의응답 | 2-3x |
| HIGH | Deep Think Mini 급 성능 | 수학, 디버깅, 심층 연구, 에이전트 | 5-10x+ |
핵심 제안:
- 일상적인 개발에는 MEDIUM — 품질이 훌륭하고 비용이 합리적이며, 이전 버전의 HIGH와 동등한 수준입니다.
- 간단한 작업에는 LOW — 사고 토큰 비용을 70% 이상 절약할 수 있습니다.
- 심층 추론에는 HIGH — Deep Think Mini의 능력은 독보적이지만, 비용이 많이 드니 주의하세요.
- 기본 설정은 HIGH — 별도로 설정하지 않으면 가장 비싼 모드로 작동하므로, 상황에 맞춰 직접 조정하는 것이 좋습니다.
작업 유형에 따라 사고 등급을 동적으로 전환하여 품질과 비용의 최적의 균형을 맞추고 싶다면, APIYI(apiyi.com) 플랫폼을 이용해 보시는 것을 추천드려요.
참고 자료
-
Google AI 문서: Gemini 사고(Thinking) 설정 가이드
- 링크:
ai.google.dev/gemini-api/docs/thinking - 설명: thinkingLevel 파라미터에 대한 상세 문서입니다.
- 링크:
-
Google AI 문서: Gemini 3.1 Pro 모델 페이지
- 링크:
ai.google.dev/gemini-api/docs/models/gemini-3.1-pro-preview - 설명: 사고 등급 지원 매트릭스와 주의 사항을 확인할 수 있습니다.
- 링크:
-
Gemini API 요금 페이지: 사고 토큰 과금 안내
- 링크:
ai.google.dev/gemini-api/docs/pricing - 설명: 사고 토큰은 출력 토큰 가격을 기준으로 요금이 청구됩니다.
- 링크:
-
VentureBeat: Deep Think Mini 심층 체험기
- 링크:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - 설명: IMO(국제수학올림피아드) 문제를 8분 만에 풀어낸 실제 테스트 데이터를 확인할 수 있습니다.
- 링크:
-
Google 공식 블로그: Gemini 3.1 Pro 출시 공지
- 링크:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - 설명: 3단계 사고 시스템과 Deep Think Mini에 대한 공식 소개 내용입니다.
- 링크:
📝 작성자: APIYI Team | 기술 교류는 APIYI(apiyi.com)를 방문해 주세요.
📅 업데이트 날짜: 2026년 2월 20일
🏷️ 키워드: Gemini 3.1 Pro 사고 등급, thinkingLevel, Deep Think Mini, LOW MEDIUM HIGH, API 호출, 추론 제어