Gemini 3.1 Pro Preview ha añadido el nivel de pensamiento medium, una de las mayores diferencias respecto a su predecesor Gemini 3 Pro. Ahora puedes controlar con precisión la profundidad de razonamiento del modelo entre tres niveles: low, medium y high; siendo el modo high el que activa la capacidad de Deep Think Mini.
Valor principal: Al terminar de leer este artículo, dominarás el método de configuración completo del parámetro thinkingLevel y aprenderás a encontrar el equilibrio óptimo entre calidad, velocidad y coste.

Matriz de soporte completa de niveles de pensamiento en Gemini 3.1 Pro
Veamos primero el panorama general: los diferentes modelos de Gemini admiten distintos niveles de pensamiento.
| Nivel de pensamiento | Gemini 3.1 Pro | Gemini 3 Pro | Gemini 3 Flash | Descripción |
|---|---|---|---|---|
| minimal | ❌ No soportado | ❌ No soportado | ✅ Soportado | Casi desactiva el pensamiento, solo en Flash |
| low | ✅ Soportado | ✅ Soportado | ✅ Soportado | Respuesta rápida, coste mínimo |
| medium | ✅ Nuevo soporte | ❌ No soportado | ✅ Soportado | Razonamiento equilibrado, mejora clave de 3.1 Pro |
| high | ✅ Soportado (por defecto) | ✅ Soportado (por defecto) | ✅ Soportado (por defecto) | Razonamiento más profundo, activa Deep Think Mini |
Cambios clave: Evolución de los niveles de pensamiento de 3 Pro a 3.1 Pro
| Comparativa | Gemini 3 Pro | Gemini 3.1 Pro |
|---|---|---|
| Niveles disponibles | low, high (solo 2 niveles) | low, medium, high (3 niveles) |
| Nivel por defecto | high | high |
| Significado del modo high | Razonamiento profundo | Deep Think Mini (más potente) |
| ¿Se puede desactivar el pensamiento? | No | No |
Concepto fundamental: La profundidad de razonamiento del modo high en Gemini 3 Pro es aproximadamente equivalente al modo medium de Gemini 3.1 Pro. Por su parte, el modo high de 3.1 Pro es el nuevo Deep Think Mini, con una profundidad de razonamiento que supera con creces a la generación anterior.
🎯 Sugerencia de migración: Si antes usabas el modo high de Gemini 3 Pro, al cambiar a 3.1 Pro te recomendamos empezar con medium (para mantener una calidad y coste similares), y activar high solo cuando necesites un razonamiento realmente profundo. APIYI (apiyi.com) es compatible con todos los modelos de Gemini y sus niveles de pensamiento.
Cómo configurar los niveles de pensamiento de Gemini 3.1 Pro vía API
Llamada a través de APIYI (formato compatible con OpenAI)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
# Modo LOW: Respuesta rápida
response_low = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "Traduce este texto al español: Hello World"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 1024}
}
)
# Modo MEDIUM: Razonamiento equilibrado (¡Nuevo!)
response_med = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "Revisa si este código tiene riesgos de fuga de memoria"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 8192}
}
)
# Modo HIGH: Deep Think Mini
response_high = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "Demuestra: Para todo entero positivo n, n^3-n es divisible por 6"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 32768}
}
)
Llamada nativa a través del SDK de Google
from google import genai
from google.genai import types
client = genai.Client()
# Uso del parámetro thinkingLevel
response = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents="tu indicación",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level="MEDIUM" # "LOW" / "MEDIUM" / "HIGH"
)
),
)
# Ver el consumo de tokens de pensamiento
print(f"Tokens de pensamiento: {response.usage_metadata.thoughts_token_count}")
print(f"Tokens de salida: {response.usage_metadata.candidates_token_count}")
Llamada vía REST API
POST https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent
{
"contents": [{"parts": [{"text": "tu indicación"}]}],
"generationConfig": {
"thinkingConfig": {
"thinkingLevel": "MEDIUM"
}
}
}
⚠️ Recordatorio importante:
thinkingLevelythinkingBudgetno pueden usarse al mismo tiempo; de lo contrario, se devolverá un error 400. Se recomienda usarthinkingLevelpara los modelos Gemini 3+, ythinkingBudgetpara los modelos Gemini 2.5.
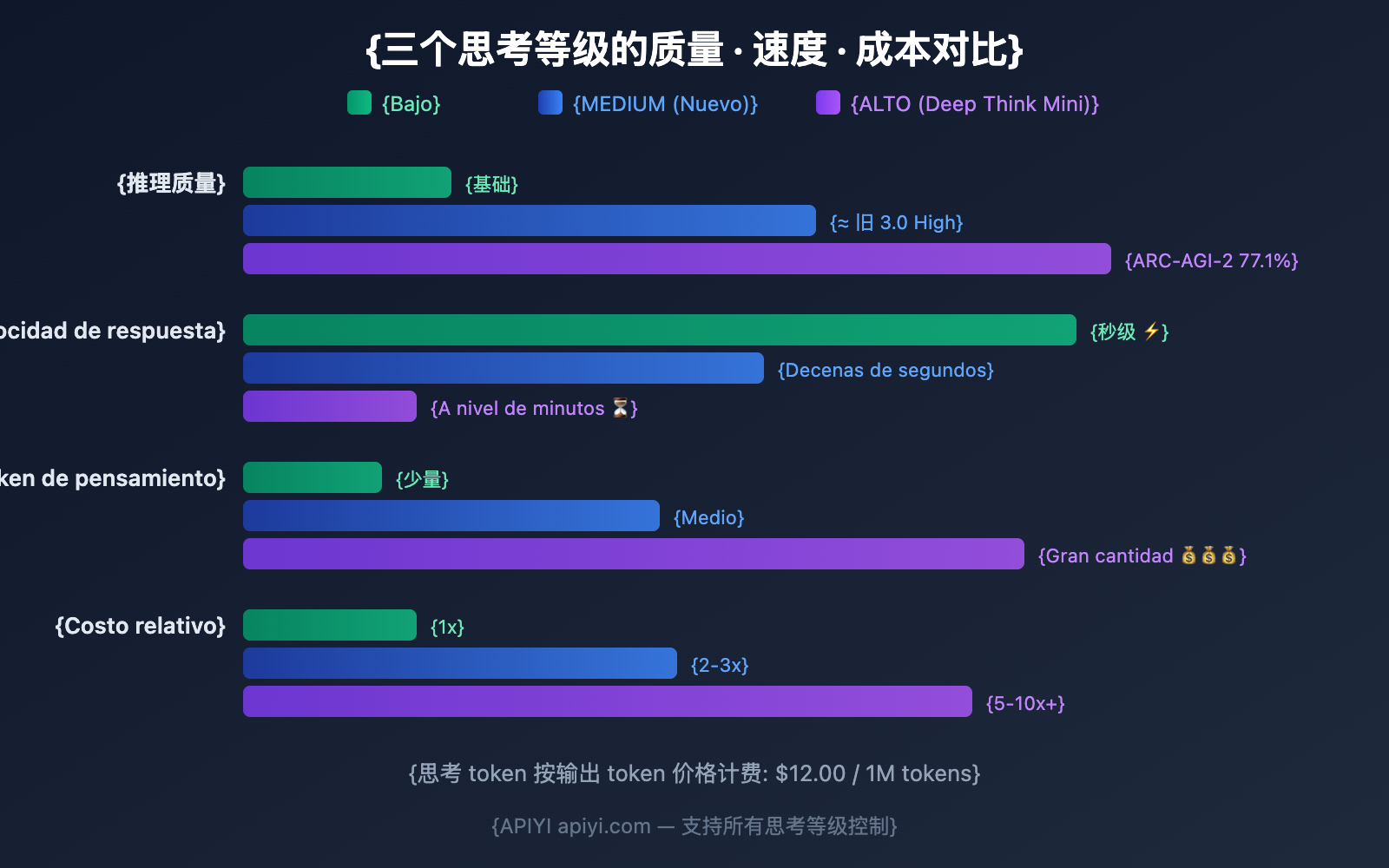
Comparativa detallada de los 3 niveles de pensamiento de Gemini 3.1 Pro
LOW: El más rápido y económico
| Dimensión | Detalles |
|---|---|
| Profundidad de razonamiento | Mínima cantidad de tokens de pensamiento, pero sigue siendo superior a los modelos sin razonamiento |
| Velocidad de respuesta | Nivel de segundos (el más rápido) |
| Costo | El más bajo (pocos tokens de pensamiento → pocos tokens de salida → menor costo) |
| Casos de uso | Autocompletado, clasificación, extracción de datos estructurados, traducciones simples, resúmenes |
| No apto para | Razonamiento complejo, demostraciones matemáticas, depuración de varios pasos |
MEDIUM: El equilibrio preferido (Nuevo)
| Dimensión | Detalles |
|---|---|
| Profundidad de razonamiento | Tokens de pensamiento moderados, similar al nivel "high" del antiguo 3.0 Pro |
| Velocidad de respuesta | Latencia media |
| Costo | Medio |
| Casos de uso | Revisión de código, análisis de documentos, programación diaria, llamadas a API estándar, preguntas y respuestas |
| No apto para | Matemáticas nivel IMO, razonamiento multietapa extremadamente complejo |
HIGH: Deep Think Mini (Predeterminado)
| Dimensión | Detalles |
|---|---|
| Profundidad de razonamiento | Maximiza el razonamiento, activa las capacidades de Deep Think Mini |
| Velocidad de respuesta | Puede requerir varios minutos (aprox. 8 minutos para problemas IMO) |
| Costo | El más alto (gran cantidad de tokens de pensamiento facturados a precio de salida) |
| Casos de uso | Depuración compleja, diseño de algoritmos, demostraciones matemáticas, tareas de investigación, flujos de trabajo de Agentes |
| Capacidad especial | Firmas de pensamiento (thought signatures) para mantener la continuidad del razonamiento entre llamadas a la API |
Reglas de facturación de tokens de pensamiento en Gemini 3.1 Pro
Entender cómo se factura es fundamental para elegir el nivel de pensamiento adecuado.
Principios básicos de facturación
| Concepto de facturación | Descripción |
|---|---|
| ¿Se cobran los tokens de pensamiento? | Sí, se facturan al mismo precio que los tokens de salida. |
| Precio por token de salida | $12.00 / 1M de tokens (incluyendo los tokens de pensamiento). |
| Base de facturación | Se factura según la cadena de razonamiento interna completa, no solo el resumen. |
| Resumen del pensamiento | La API solo devuelve un resumen del pensamiento, pero se cobra por el número total de tokens de pensamiento generados. |
Explicación oficial de Google:
"Los modelos de pensamiento generan pensamientos completos para mejorar la calidad de la respuesta final y luego emiten resúmenes para ofrecer una visión del proceso de pensamiento. El precio se basa en los tokens de pensamiento completos que el modelo necesita generar para crear un resumen, a pesar de que solo se emita el resumen desde la API."
Estimación de costos para los tres niveles
| Nivel | Tokens de pensamiento estimados | Por cada 1,000 llamadas | Tendencia de costo mensual |
|---|---|---|---|
| LOW | ~500-2K / llamada | $6-24 | El más bajo |
| MEDIUM | ~2K-8K / llamada | $24-96 | Medio |
| HIGH | ~8K-32K+ / llamada | $96-384+ | Alto; más en tareas complejas |
💰 Optimización de costos: No todas las solicitudes necesitan el nivel HIGH. Configurar el 80% de las tareas diarias en LOW o MEDIUM y reservar el nivel HIGH solo para el 20% de las tareas complejas puede reducir tus gastos de API entre un 50% y un 70%. Puedes configurar esto de forma flexible a través de la plataforma APIYI (apiyi.com).
Guía de correspondencia: Tipos de tareas y niveles de pensamiento en Gemini 3.1 Pro
Recomendaciones por escenario detallado
| Tipo de tarea | Nivel recomendado | Motivo | Latencia esperada |
|---|---|---|---|
| Traducción simple | LOW | No requiere razonamiento profundo | < 5 segundos |
| Clasificación de texto | LOW | Tarea de coincidencia de patrones | < 5 segundos |
| Extracción de resúmenes | LOW | Compresión de información, no razonamiento | < 10 segundos |
| Autocompletado | LOW | Sensible a la latencia | < 3 segundos |
| Revisión de código | MEDIUM | Requiere un análisis moderado | 10-30 segundos |
| QA de documentos | MEDIUM | Comprensión + Respuesta | 10-30 segundos |
| Programación diaria | MEDIUM | Generación de código convencional | 15-40 segundos |
| Análisis de errores (Bugs) | MEDIUM | Razonamiento de complejidad media | 20-40 segundos |
| Depuración compleja | HIGH | Cadena de razonamiento de múltiples pasos | 1-5 minutos |
| Demostración matemática | HIGH | Deep Think Mini | 3-8 minutos |
| Diseño de algoritmos | HIGH | Razonamiento profundo | 2-5 minutos |
| Análisis de investigación | HIGH | Análisis profundo multidimensional | 2-5 minutos |
| Flujos de trabajo de Agentes | HIGH | Mantiene la continuidad de la firma de pensamiento | Según la tarea |
Selección dinámica de nivel: Código de mejores prácticas
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
# Selección automática del nivel de pensamiento según el tipo de tarea
THINKING_CONFIG = {
"simple": {"type": "enabled", "budget_tokens": 1024}, # LOW
"medium": {"type": "enabled", "budget_tokens": 8192}, # MEDIUM
"complex": {"type": "enabled", "budget_tokens": 32768}, # HIGH
}
def smart_think(prompt, complexity="medium"):
"""Configura automáticamente el nivel de pensamiento según la complejidad de la tarea"""
return client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking": THINKING_CONFIG[complexity]}
)
# Traducción simple → LOW
resp1 = smart_think("Traduce: Good morning", "simple")
# Revisión de código → MEDIUM
resp2 = smart_think("Revisa la seguridad de este código: ...", "medium")
# Demostración matemática → HIGH (Deep Think Mini)
resp3 = smart_think("Demuestra un caso especial de la hipótesis de Riemann", "complex")
Gemini 3.1 Pro vs 3 Pro: Evolución de los niveles de pensamiento

¿Qué hace que Deep Think Mini sea tan potente?
El Deep Think Mini, activado por el modo HIGH de Gemini 3.1 Pro, es el aspecto más destacado de esta actualización.
¿Qué es Deep Think Mini?
Deep Think Mini no es un modelo independiente, sino un modo de razonamiento especial de Gemini 3.1 Pro bajo el nivel de pensamiento HIGH. Google lo describe como una "versión mini de Gemini Deep Think", siendo Deep Think el modelo de razonamiento pesado especializado de Google (con una puntuación de 84.6% en ARC-AGI-2).
Rendimiento real de Deep Think Mini
| Prueba | Deep Think Mini (3.1 Pro HIGH) | Gemini 3 Pro HIGH | Mejora |
|---|---|---|---|
| ARC-AGI-2 | 77.1% | 31.1% | +148% |
| Problemas de la OIM | Resuelto en ~8 min | Incapaz de resolver | De imposible a posible |
| Tareas de planificación compleja | Mejora del 40-60% | Comparado con Gemini 2.5 Pro | Mejora significativa |
Firmas de pensamiento (Thought Signatures)
Deep Think Mini introduce una tecnología única: las firmas de pensamiento (thought signatures). Se trata de representaciones cifradas y a prueba de manipulaciones de los estados de razonamiento intermedio.
En los flujos de trabajo de Agentes, el razonamiento del modelo suele abarcar múltiples llamadas a la API. Las firmas de pensamiento permiten pasar el contexto de razonamiento de una llamada a la siguiente, manteniendo la continuidad del razonamiento. Esto es crucial para tareas de Agentes de múltiples pasos.
¿Para qué tareas vale la pena usar Deep Think Mini?
| Vale la pena usar HIGH (Deep Think Mini) | No vale la pena usar HIGH |
|---|---|
| Razonamiento matemático de nivel de competición | Operaciones aritméticas simples |
| Depuración de bugs complejos en varios archivos | Corrección de errores de sintaxis |
| Diseño y optimización de algoritmos | Generación de código CRUD |
| Análisis de metodología en artículos académicos | Resumen de artículos |
| Tareas largas de Agentes multietapa | Preguntas y respuestas de una sola ronda |
| Análisis profundo de vulnerabilidades de seguridad | Conversión de formatos |
💡 Consejo práctico: El poder de Deep Think Mini tiene un precio: la latencia y el coste son elevados. Se recomienda usar HIGH solo en tareas que realmente requieran "pensamiento profundo"; para tareas cotidianas, MEDIUM es suficiente. A través de APIYI (apiyi.com), puedes alternar de forma flexible en cada solicitud.
thinkingLevel vs thinkingBudget: No los confundas
Google tiene dos parámetros para controlar el razonamiento (thinking), aplicables a diferentes series de modelos:
| Parámetro | Modelos compatibles | Tipo de valor | Descripción |
|---|---|---|---|
| thinkingLevel | Gemini 3+ (3 Flash, 3 Pro, 3.1 Pro) | Enumeración: MINIMAL/LOW/MEDIUM/HIGH | Recomendado para la serie Gemini 3 |
| thinkingBudget | Gemini 2.5 (Pro, Flash, Flash Lite) | Entero: 0-32768 | Aplicable a la serie 2.5 |
⚠️ ¡No puedes usar ambos parámetros al mismo tiempo! Si envías los dos, recibirás un error 400.
| Escenario | Forma correcta | Forma incorrecta |
|---|---|---|
| Usar Gemini 3.1 Pro | Usar thinkingLevel: "MEDIUM" |
Usar thinkingBudget: 8192 |
| Usar Gemini 2.5 Pro | Usar thinkingBudget: 8192 |
Usar thinkingLevel: "MEDIUM" |
| Enviar ambos parámetros | — | Error 400 ❌ |
🎯 Regla mnemotécnica: Serie Gemini 3 →
thinkingLevel(niveles de texto), Serie Gemini 2.5 →thinkingBudget(número de tokens). APIYI (apiyi.com) soporta ambos formatos de parámetros.
Preguntas frecuentes
Q1: ¿Cuál es el nivel por defecto si no se configura thinkingLevel?
Por defecto es HIGH. Esto significa que, si no lo configuras manualmente, cada llamada usará toda la capacidad de razonamiento de Deep Think Mini, consumiendo el máximo de tokens de pensamiento. Se recomienda ajustar el nivel según las necesidades reales de la tarea para ahorrar costes. A través de APIYI (apiyi.com), puedes controlar esto de forma flexible en cada solicitud.
Q2: ¿Cómo se cobran los tokens de pensamiento? ¿Son caros?
Los tokens de pensamiento se facturan al mismo precio que los tokens de salida ($12.00 / 1M de tokens). En modo HIGH, una solicitud compleja puede consumir más de 30,000 tokens de pensamiento, con un coste de unos $0.36. En cambio, la misma solicitud en modo LOW podría consumir solo 1,000 tokens, costando unos $0.012. La diferencia puede ser de hasta 30 veces.
Q3: ¿Es el MEDIUM de 3.1 Pro lo mismo que el HIGH de 3.0 Pro?
Básicamente, sí. Google describe el nivel MEDIUM de 3.1 Pro como un "razonamiento equilibrado, adecuado para la mayoría de las tareas", lo cual coincide con el posicionamiento del nivel HIGH en 3.0 Pro. Si vas a migrar de 3.0 Pro a 3.1 Pro, cambiar HIGH por MEDIUM te permitirá mantener una calidad y un coste similares. A través de APIYI (apiyi.com), puedes llamar a ambas versiones simultáneamente para compararlas.
Q4: ¿Se puede desactivar la función de pensamiento?
En Gemini 3.1 Pro no se puede desactivar el pensamiento por completo. El nivel mínimo es LOW, que sigue realizando un razonamiento básico. Si necesitas una respuesta sin ningún tipo de razonamiento, considera usar el modo MINIMAL de Gemini 3 Flash.
Errores comunes sobre los niveles de razonamiento de Gemini 3.1 Pro
| Error | Realidad |
|---|---|
| «El nivel HIGH ofrece la mejor calidad y debería usarse siempre» | En tareas sencillas, la calidad de HIGH es similar a la de MEDIUM, pero el costo es entre 5 y 10 veces mayor. |
| «El nivel LOW tiene una capacidad de razonamiento muy pobre» | LOW sigue siendo superior a los modelos que no razonan en absoluto; simplemente genera menos tokens de pensamiento. |
| «MEDIUM es una función nueva y podría ser inestable» | La profundidad de razonamiento de MEDIUM es aproximadamente igual al nivel HIGH de la versión anterior 3.0 Pro, y ya ha sido plenamente validada. |
| «Los tokens de pensamiento no se cobran» | ¡Sí se cobran! Se facturan al mismo precio que los tokens de salida ($12/MTok). |
| «Se puede desactivar el razonamiento en 3.1 Pro» | No se puede; el nivel mínimo permitido es LOW, que aún mantiene un razonamiento básico. |
«thinkingLevel y thinkingBudget pueden usarse juntos» |
¡No! Usarlos al mismo tiempo devolverá un error 400. |
| «Configurar un nivel alto aumenta la latencia, pero el resultado se devuelve de inmediato» | El modo HIGH puede tardar varios minutos antes de empezar a responder; no es solo un pequeño retraso momentáneo. |
Resumen: Guía rápida para elegir el nivel de razonamiento de Gemini 3.1 Pro
| Nivel | En una frase | Casos de uso ideales | Costo relativo |
|---|---|---|---|
| LOW | El más rápido y económico | Traducción, clasificación, resúmenes, completado | 1x |
| MEDIUM | La opción equilibrada (Nuevo) | Programación, revisión, análisis, Q&A | 2-3x |
| HIGH | Deep Think Mini | Matemáticas, depuración, investigación, Agentes | 5-10x+ |
Recomendaciones clave:
- Usa MEDIUM para el desarrollo diario: Ofrece buena calidad a un costo razonable y es equivalente al antiguo nivel HIGH.
- Usa LOW para tareas sencillas: Te permite ahorrar más del 70% en los costos de tokens de pensamiento.
- Usa HIGH para razonamiento profundo: Las capacidades de Deep Think Mini son únicas, pero vigila de cerca el costo.
- El valor predeterminado es HIGH: Si no especificas un nivel, se usará el modo más caro por defecto; recuerda ajustarlo manualmente.
Te recomendamos cambiar dinámicamente el nivel de razonamiento según el tipo de tarea a través de la plataforma APIYI (apiyi.com) para lograr el equilibrio óptimo entre calidad y costo.
Referencias
-
Documentación de Google AI: Guía de configuración de pensamiento de Gemini
- Enlace:
ai.google.dev/gemini-api/docs/thinking - Descripción: Documentación completa del parámetro
thinkingLevel.
- Enlace:
-
Documentación de Google AI: Página del modelo Gemini 3.1 Pro
- Enlace:
ai.google.dev/gemini-api/docs/models/gemini-3.1-pro-preview - Descripción: Matriz de soporte de niveles de pensamiento y notas importantes.
- Enlace:
-
Página de precios de la API de Gemini: Detalles de facturación de los tokens de pensamiento
- Enlace:
ai.google.dev/gemini-api/docs/pricing - Descripción: Los tokens de pensamiento se facturan al mismo precio que los tokens de salida.
- Enlace:
-
VentureBeat: Experiencia profunda con Deep Think Mini
- Enlace:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Descripción: Datos de pruebas reales donde se resolvió un problema de la IMO en 8 minutos.
- Enlace:
-
Blog oficial de Google: Anuncio de lanzamiento de Gemini 3.1 Pro
- Enlace:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Descripción: Presentación oficial del sistema de pensamiento de tres niveles y de Deep Think Mini.
- Enlace:
📝 Autor: APIYI Team | Para intercambio técnico, visita APIYI apiyi.com
📅 Fecha de actualización: 20 de febrero de 2026
🏷️ Palabras clave: Niveles de pensamiento de Gemini 3.1 Pro, thinkingLevel, Deep Think Mini, LOW MEDIUM HIGH, llamadas a la API, control de razonamiento