Gemini 3.1 Pro Preview hat die Denkstufe „medium“ hinzugefügt. Dies ist einer der größten Unterschiede zum Vorgänger Gemini 3 Pro. Ab sofort können Sie die Argumentationstiefe des Modells präzise zwischen den drei Stufen low, medium und high steuern, wobei der High-Modus die Deep Think Mini-Fähigkeiten aktiviert.
Kernvorteil: Nach der Lektüre dieses Artikels werden Sie die vollständige Konfiguration des Parameters thinkingLevel beherrschen und lernen, wie Sie das optimale Gleichgewicht zwischen Qualität, Geschwindigkeit und Kosten finden.

Vollständige Unterstützungsmatrix der Gemini 3.1 Pro Denkstufen
Zuerst der Gesamtüberblick: Verschiedene Gemini-Modelle unterstützen unterschiedliche Denkstufen.
| Denkstufe | Gemini 3.1 Pro | Gemini 3 Pro | Gemini 3 Flash | Erläuterung |
|---|---|---|---|---|
| minimal | ❌ Nicht unterstützt | ❌ Nicht unterstützt | ✅ Unterstützt | Nahezu deaktiviertes Denken, nur von Flash unterstützt |
| low | ✅ Unterstützt | ✅ Unterstützt | ✅ Unterstützt | Schnelle Antwort, geringste Kosten |
| medium | ✅ Neu unterstützt | ❌ Nicht unterstützt | ✅ Unterstützt | Ausgewogene Argumentation, das Kern-Upgrade von 3.1 Pro |
| high | ✅ Unterstützt (Standard) | ✅ Unterstützt (Standard) | ✅ Unterstützt (Standard) | Tiefste Argumentation, aktiviert Deep Think Mini |
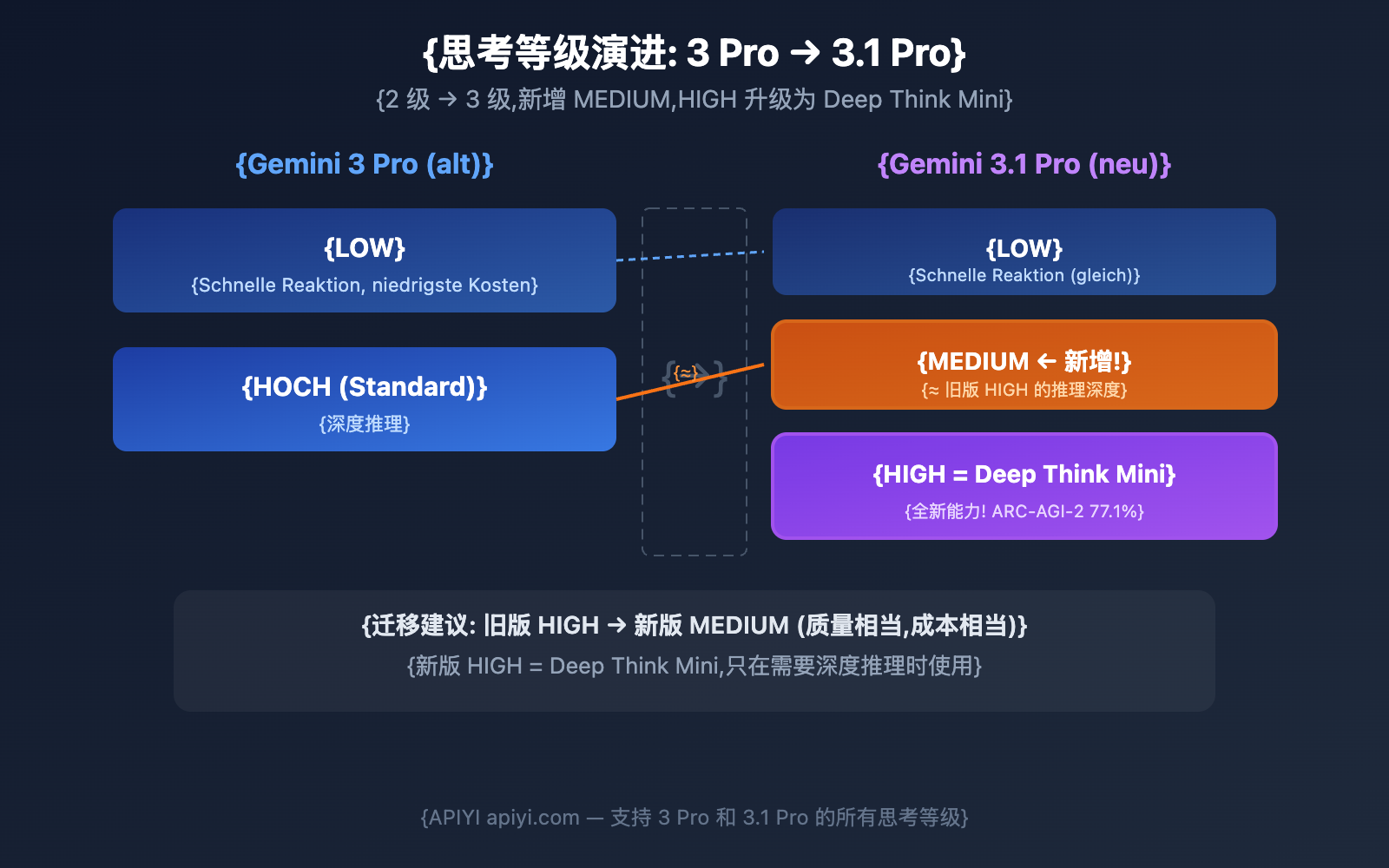
Entscheidende Änderungen: Upgrade der Denkstufen von 3 Pro auf 3.1 Pro
| Vergleich | Gemini 3 Pro | Gemini 3.1 Pro |
|---|---|---|
| Verfügbare Stufen | low, high (nur 2 Stufen) | low, medium, high (3 Stufen) |
| Standardstufe | high | high |
| Bedeutung des High-Modus | Tiefe Argumentation | Deep Think Mini (stärker) |
| Denken deaktivierbar | Nein | Nein |
Zentrale Erkenntnis: Die High-Argumentationstiefe von Gemini 3 Pro entspricht in etwa der Stufe medium von Gemini 3.1 Pro. Das „high“ von 3.1 Pro ist das völlig neue Deep Think Mini, dessen Argumentationstiefe die der vorherigen Generation weit übertrifft.
🎯 Migrationsempfehlung: Wenn Sie bisher den High-Modus von Gemini 3 Pro genutzt haben, empfehlen wir beim Wechsel zu 3.1 Pro zunächst die Stufe medium (um eine ähnliche Qualität und Kostenstruktur beizubehalten). Aktivieren Sie high nur dann, wenn Sie eine besonders tiefe Argumentation benötigen. APIYI (apiyi.com) unterstützt alle Gemini-Modelle und Denkstufen gleichzeitig.
Gemini 3.1 Pro Thinking Level API-Konfigurationsmethoden
Aufruf über APIYI (OpenAI-kompatibles Format)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche Schnittstelle von APIYI
)
# LOW-Modus: Schnelle Antwort
response_low = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "Übersetze diesen englischen Text ins Chinesische: Hello World"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 1024}
}
)
# MEDIUM-Modus: Ausgewogene Inferenz (Neu!)
response_med = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "Prüfe diesen Code auf potenzielle Speicherlecks"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 8192}
}
)
# HIGH-Modus: Deep Think Mini
response_high = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "Beweise: Für alle positiven Ganzzahlen n ist n^3-n durch 6 teilbar"}],
extra_body={
"thinking": {"type": "enabled", "budget_tokens": 32768}
}
)
Nativer Aufruf über das Google SDK
from google import genai
from google.genai import types
client = genai.Client()
# Verwendung des thinkingLevel-Parameters
response = client.models.generate_content(
model="gemini-3.1-pro-preview",
contents="Deine Eingabeaufforderung",
config=types.GenerateContentConfig(
thinking_config=types.ThinkingConfig(
thinking_level="MEDIUM" # "LOW" / "MEDIUM" / "HIGH"
)
),
)
# Anzeige des Thinking-Token-Verbrauchs
print(f"Thinking-Token: {response.usage_metadata.thoughts_token_count}")
print(f"Output-Token: {response.usage_metadata.candidates_token_count}")
REST-API-Aufruf
POST https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent
{
"contents": [{"parts": [{"text": "Deine Eingabeaufforderung"}]}],
"generationConfig": {
"thinkingConfig": {
"thinkingLevel": "MEDIUM"
}
}
}
⚠️ Wichtiger Hinweis:
thinkingLevelundthinkingBudgetkönnen nicht gleichzeitig verwendet werden, andernfalls wird ein 400-Fehler zurückgegeben. Für Gemini 3+ Modelle wirdthinkingLevelempfohlen, für Gemini 2.5 ModellethinkingBudget.
Detaillierter Vergleich der 3 Thinking-Level von Gemini 3.1 Pro
LOW: Am schnellsten und günstigsten
| Dimension | Details |
|---|---|
| Inferenztiefe | Minimale Thinking-Token, dennoch besser als Modelle ohne Thinking-Funktion |
| Antwortgeschwindigkeit | Sekundenbereich (am schnellsten) |
| Kosten | Am niedrigsten (wenige Thinking-Token → weniger Output-Token → geringere Kosten) |
| Anwendungsbereiche | Autovervollständigung, Klassifizierung, strukturierte Datenextraktion, einfache Übersetzungen, Zusammenfassungen |
| Nicht geeignet für | Komplexe Inferenz, mathematische Beweise, mehrstufiges Debugging |
MEDIUM: Die ausgewogene Wahl (Neu)
| Dimension | Details |
|---|---|
| Inferenztiefe | Mittlere Anzahl an Thinking-Token, entspricht etwa dem High-Level des alten 3.0 Pro |
| Antwortgeschwindigkeit | Mittlere Latenz |
| Kosten | Mittel |
| Anwendungsbereiche | Code-Reviews, Dokumentenanalyse, tägliches Programmieren, Standard-API-Aufrufe, Q&A |
| Nicht geeignet für | Mathematik auf IMO-Niveau, extrem komplexe mehrstufige Inferenz |
HIGH: Deep Think Mini (Standard)
| Dimension | Details |
|---|---|
| Inferenztiefe | Maximale Inferenz, aktiviert die Deep Think Mini Fähigkeiten |
| Antwortgeschwindigkeit | Kann mehrere Minuten dauern (IMO-Aufgaben ~8 Min.) |
| Kosten | Am höchsten (große Mengen an Thinking-Token werden zum Output-Preis abgerechnet) |
| Anwendungsbereiche | Komplexes Debugging, Algorithmen-Design, mathematische Beweise, Forschungsaufgaben, Agent-Workflows |
| Besondere Fähigkeiten | Thought Signatures (Denksignaturen) bewahren die Inferenz-Kontinuität über API-Aufrufe hinweg |
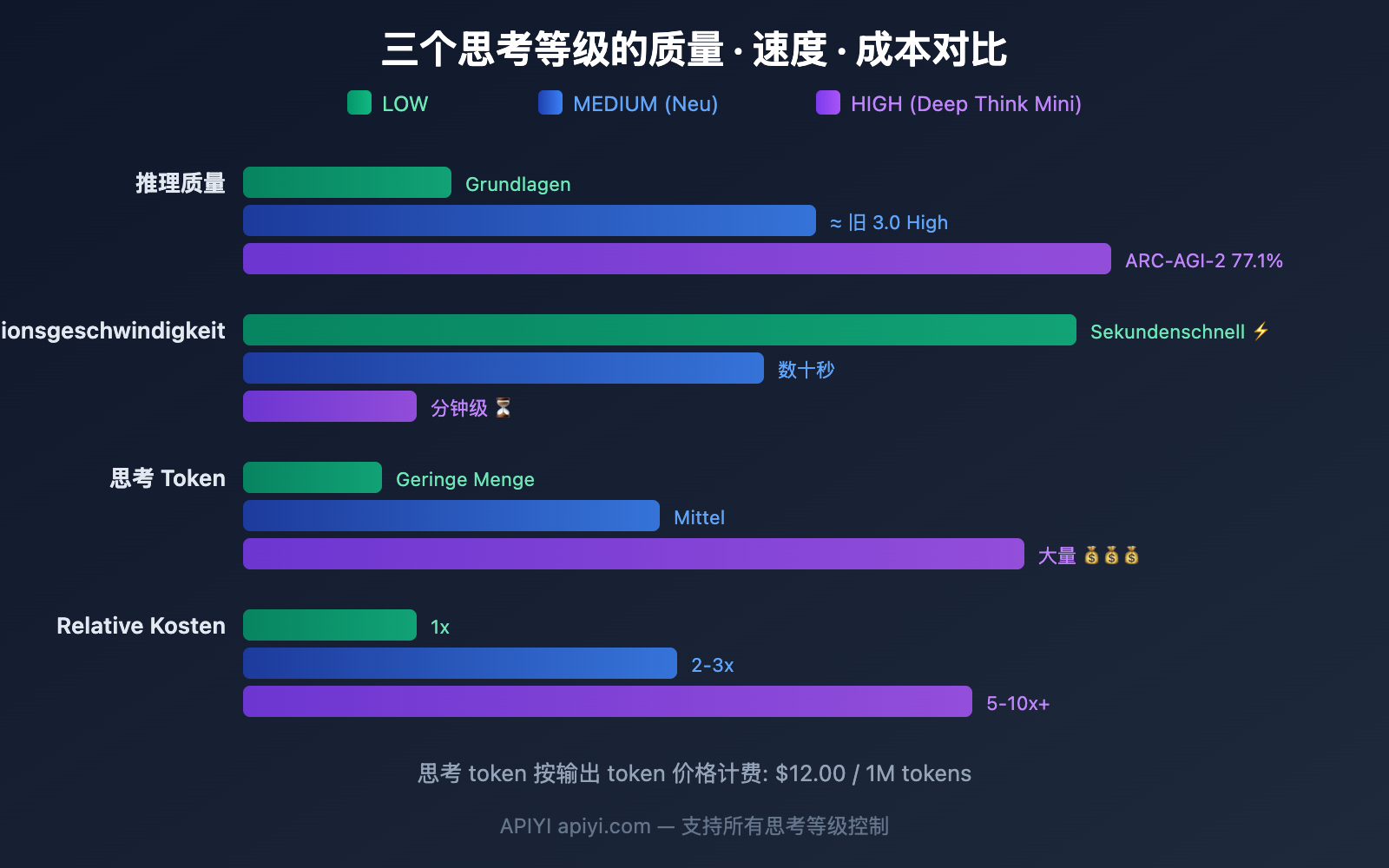
Gemini 3.1 Pro Thinking Token Abrechnungsregeln
Das Verständnis der Abrechnung ist entscheidend für die Wahl der richtigen Thinking-Stufe.
Kernprinzipien der Abrechnung
| Abrechnungsposten | Beschreibung |
|---|---|
| Werden Thinking-Token berechnet? | Ja, sie werden zum gleichen Preis wie Output-Token abgerechnet. |
| Preis pro Output-Token | $12.00 / 1 Mio. Token (inklusive Thinking-Token) |
| Abrechnungsgrundlage | Basierend auf der vollständigen internen Reasoning-Kette, nicht nur auf der Zusammenfassung. |
| Thinking-Zusammenfassung | Die API gibt nur eine Zusammenfassung des Denkprozesses zurück, berechnet wird jedoch die vollständige Anzahl der Thinking-Token. |
Offizielle Erklärung von Google:
"Thinking models generate full thoughts to improve the quality of the final response, and then output summaries to provide insight into the thought process. Pricing is based on the full thought tokens the model needs to generate to create a summary, despite only the summary being output from the API."
Kostenschätzung für die drei Stufen
| Stufe | Geschätzte Thinking-Token | Bei 1.000 Aufrufen | Monatlicher Kostentrend |
|---|---|---|---|
| LOW | ~500-2K / Aufruf | $6-24 | Niedrigst |
| MEDIUM | ~2K-8K / Aufruf | $24-96 | Mittel |
| HIGH | ~8K-32K+ / Aufruf | $96-384+ | Höher, mehr bei komplexen Aufgaben |
💰 Kostenoptimierung: Nicht jede Anfrage benötigt HIGH. Wenn Sie 80 % der täglichen Aufgaben auf LOW oder MEDIUM setzen und nur 20 % der komplexen Aufgaben mit HIGH bearbeiten, können Sie Ihre API-Ausgaben um 50–70 % senken. Über die Plattform APIYI (apiyi.com) lässt sich dies flexibel konfigurieren.
Leitfaden zur Auswahl der Gemini 3.1 Pro Thinking-Stufe nach Aufgabentyp
Empfehlungen für detaillierte Szenarien
| Aufgabentyp | Empfohlene Stufe | Grund | Erwartete Latenz |
|---|---|---|---|
| Einfache Übersetzung | LOW | Kein Reasoning erforderlich | < 5 Sek. |
| Textklassifizierung | LOW | Mustererkennungsaufgabe | < 5 Sek. |
| Zusammenfassungen | LOW | Informationskomprimierung, kein Reasoning | < 10 Sek. |
| Autovervollständigung | LOW | Latenzempfindlich | < 3 Sek. |
| Code-Review | MEDIUM | Erfordert moderate Analyse | 10-30 Sek. |
| Dokumenten-Q&A | MEDIUM | Verstehen + Antworten | 10-30 Sek. |
| Tägliches Coding | MEDIUM | Routinemäßige Codegenerierung | 15-40 Sek. |
| Bug-Analyse | MEDIUM | Reasoning mittlerer Komplexität | 20-40 Sek. |
| Komplexes Debugging | HIGH | Mehrstufige Reasoning-Kette | 1-5 Min. |
| Mathematische Beweise | HIGH | Deep Think Mini | 3-8 Min. |
| Algorithmus-Design | HIGH | Tiefgehendes Reasoning | 2-5 Min. |
| Recherche & Analyse | HIGH | Mehrdimensionale Tiefenanalyse | 2-5 Min. |
| Agent-Workflows | HIGH | Thinking-Signatur für Kontinuität | Je nach Aufgabe |
Dynamische Stufenauswahl: Best Practice Code
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI Einheitliche Schnittstelle
)
# Automatische Auswahl der Thinking-Stufe basierend auf dem Aufgabentyp
THINKING_CONFIG = {
"simple": {"type": "enabled", "budget_tokens": 1024}, # LOW
"medium": {"type": "enabled", "budget_tokens": 8192}, # MEDIUM
"complex": {"type": "enabled", "budget_tokens": 32768}, # HIGH
}
def smart_think(prompt, complexity="medium"):
"""Setzt die Thinking-Stufe automatisch basierend auf der Aufgabenkomplexität"""
return client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking": THINKING_CONFIG[complexity]}
)
# Einfache Übersetzung → LOW
resp1 = smart_think("Übersetze: Good morning", "simple")
# Code-Review → MEDIUM
resp2 = smart_think("Überprüfe die Sicherheit dieses Codes: ...", "medium")
# Mathematischer Beweis → HIGH (Deep Think Mini)
resp3 = smart_think("Beweise einen Spezialfall der Riemannschen Vermutung", "complex")
Gemini 3.1 Pro vs 3 Pro: Evolution der Denkstufen
Wo Deep Think Mini wirklich glänzt
Der durch den HIGH-Modus von Gemini 3.1 Pro aktivierte Deep Think Mini ist das absolute Highlight dieses Upgrades.
Was ist Deep Think Mini?
Deep Think Mini ist kein eigenständiges Modell, sondern ein spezieller Reasoning-Modus von Gemini 3.1 Pro unter der Denkstufe HIGH. Google beschreibt es als eine „Mini-Version von Gemini Deep Think“ – Googles dediziertem Schwergewicht für logisches Schlussfolgern (mit einem ARC-AGI-2 Score von 84,6 %).
Deep Think Mini im Praxistest
| Testkriterium | Deep Think Mini (3.1 Pro HIGH) | Gemini 3 Pro HIGH | Steigerung |
|---|---|---|---|
| ARC-AGI-2 | 77,1 % | 31,1 % | +148 % |
| IMO Mathe-Aufgaben | Gelöst in ~8 Min. | Nicht lösbar | Von „unmöglich“ zu „möglich“ |
| Komplexe Planung | Benchmark +40-60 % | Im Vergleich zu Gemini 2.5 Pro | Signifikante Steigerung |
Thought Signatures (Denksignaturen)
Deep Think Mini führt eine einzigartige Technologie ein: Thought Signatures. Dabei handelt es sich um verschlüsselte, manipulationssichere Darstellungen von Zwischenzuständen des Reasonings.
In Agent-Workflows erstreckt sich das Reasoning des Modells oft über mehrere API-Aufrufe. Thought Signatures ermöglichen es, den Reasoning-Kontext eines vorherigen Aufrufs an den nächsten zu übergeben, wodurch die Kontinuität des Denkprozesses gewahrt bleibt. Dies ist besonders wichtig für mehrstufige Agent-Aufgaben.
Für welche Aufgaben lohnt sich Deep Think Mini?
| Wann sich HIGH (Deep Think Mini) lohnt | Wann sich HIGH nicht lohnt |
|---|---|
| Reasoning auf Mathe-Wettbewerbsniveau | Einfache Grundrechenarten |
| Komplexes Bug-Debugging über mehrere Dateien | Syntax-Fehlerbehebung |
| Algorithmen-Design und -Optimierung | CRUD-Code-Generierung |
| Methodik-Analyse wissenschaftlicher Arbeiten | Zusammenfassungen von Artikeln |
| Mehrstufige, lange Agent-Aufgaben | Single-Turn Q&A |
| Tiefgehende Sicherheitsanalysen von Schwachstellen | Formatkonvertierungen |
💡 Praktischer Tipp: Die enorme Leistungsfähigkeit von Deep Think Mini hat ihren Preis – sowohl bei der Latenz als auch bei den Kosten. Wir empfehlen, HIGH nur für Aufgaben zu nutzen, die wirklich „tiefes Nachdenken“ erfordern. Für den Alltag reicht MEDIUM völlig aus. Über APIYI (apiyi.com) lässt sich dies flexibel pro Request steuern.
thinkingLevel vs. thinkingBudget: Nicht verwechseln
Google verwendet zwei verschiedene Parameter zur Steuerung des Denkprozesses (Reasoning), die für unterschiedliche Modellserien gelten:
| Parameter | Anwendbare Modelle | Werttyp | Beschreibung |
|---|---|---|---|
| thinkingLevel | Gemini 3+ (3 Flash, 3 Pro, 3.1 Pro) | Enum: MINIMAL/LOW/MEDIUM/HIGH | Empfohlen für die Gemini 3-Serie |
| thinkingBudget | Gemini 2.5 (Pro, Flash, Flash Lite) | Ganzzahl: 0-32768 | Gilt für die 2.5-Serie |
⚠️ Beide Parameter können nicht gleichzeitig verwendet werden! Die gleichzeitige Übergabe führt zu einem 400-Fehler.
| Szenario | Richtiges Vorgehen | Falsches Vorgehen |
|---|---|---|
| Aufruf von Gemini 3.1 Pro | Nutze thinkingLevel: "MEDIUM" |
Nutze thinkingBudget: 8192 |
| Aufruf von Gemini 2.5 Pro | Nutze thinkingBudget: 8192 |
Nutze thinkingLevel: "MEDIUM" |
| Beide Parameter übergeben | — | 400-Fehler ❌ |
🎯 Merkhilfe: Gemini 3-Serie → thinkingLevel (String-Level), Gemini 2.5-Serie → thinkingBudget (Anzahl der Token als Zahl). APIYI (apiyi.com) unterstützt beide Parameterformate.
Häufig gestellte Fragen
Q1: Welches Level ist voreingestellt, wenn thinkingLevel nicht gesetzt wird?
Standardmäßig ist dies HIGH. Das bedeutet: Wenn Sie den Wert nicht aktiv setzen, nutzt jeder Aufruf die volle Reasoning-Kapazität von Deep Think Mini und verbraucht die maximale Anzahl an Thinking-Tokens. Es wird empfohlen, das Level je nach tatsächlichem Bedarf der Aufgabe anzupassen, um Kosten zu sparen. Über APIYI (apiyi.com) lässt sich dies flexibel auf Anfrageebene steuern.
Q2: Wie werden Thinking-Tokens abgerechnet? Sind sie teuer?
Thinking-Tokens werden zum gleichen Preis wie Output-Tokens abgerechnet (12,00 $ / 1 Mio. Tokens). Im HIGH-Modus kann eine komplexe Anfrage über 30.000 Thinking-Tokens verbrauchen, was etwa 0,36 $ kostet. Im LOW-Modus benötigt dieselbe Anfrage vielleicht nur 1.000 Thinking-Tokens (ca. 0,012 $). Der Kostenunterschied kann also beim 30-fachen liegen.
Q3: Entspricht MEDIUM bei 3.1 Pro dem HIGH bei 3.0 Pro?
Im Grunde ja. Google beschreibt MEDIUM bei 3.1 Pro als „ausgewogenes Denken, geeignet für die meisten Aufgaben“, was der Positionierung von HIGH bei 3.0 Pro entspricht. Wenn Sie von 3.0 Pro auf 3.1 Pro migrieren, können Sie durch den Wechsel von HIGH zu MEDIUM eine ähnliche Qualität und Kostenstruktur beibehalten. Über APIYI (apiyi.com) können Sie beide Versionen parallel aufrufen und vergleichen.
Q4: Kann man die Thinking-Funktion ausschalten?
Bei Gemini 3.1 Pro lässt sich das Denken nicht vollständig deaktivieren. Die niedrigste Einstellung ist LOW, wobei immer noch grundlegendes Reasoning stattfindet. Wenn Sie eine Antwort komplett ohne Reasoning benötigen, sollten Sie den MINIMAL-Modus von Gemini 3 Flash in Betracht ziehen.
Häufige Missverständnisse zu den Gemini 3.1 Pro Thinking Levels
| Missverständnis | Fakt |
|---|---|
| „Die Stufe HIGH liefert die beste Antwortqualität und sollte immer verwendet werden“ | HIGH bietet bei einfachen Aufgaben eine ähnliche Qualität wie MEDIUM, kostet aber 5-10 Mal mehr. |
| „Die Reasoning-Fähigkeiten der Stufe LOW sind sehr schlecht“ | LOW ist immer noch besser als Modelle ohne Reasoning; es werden lediglich weniger Thinking-Token verwendet. |
| „MEDIUM ist eine neue Funktion und könnte instabil sein“ | Die Reasoning-Tiefe von MEDIUM entspricht in etwa der Stufe HIGH der alten Version 3.0 Pro und ist bereits umfassend validiert. |
| „Thinking-Token werden nicht berechnet“ | Sie werden berechnet! Die Abrechnung erfolgt zum gleichen Preis wie bei Output-Token ($12/MTok). |
| „Man kann das Reasoning bei 3.1 Pro ausschalten“ | Nein, die niedrigste Stufe ist LOW, was immer noch ein Basis-Reasoning beinhaltet. |
| „thinkingLevel und thinkingBudget können zusammen verwendet werden“ | Nein! Die gleichzeitige Verwendung führt zu einem 400-Fehler. |
| „Bei hohen Stufen ist die Latenz zwar höher, aber das Ergebnis wird sofort zurückgegeben“ | Der HIGH-Modus kann mehrere Minuten benötigen, bevor die Antwort beginnt – das ist mehr als nur eine kurze Verzögerung. |
Zusammenfassung: Schnellcheck zur Wahl des Gemini 3.1 Pro Thinking Levels
| Stufe | Kurzbeschreibung | Anwendungsfälle | Relative Kosten |
|---|---|---|---|
| LOW | Am schnellsten & günstigsten | Übersetzung, Klassifizierung, Zusammenfassung, Vervollständigung | 1x |
| MEDIUM | Die ausgewogene Wahl (Neu) | Coding, Review, Analyse, Q&A | 2-3x |
| HIGH | Deep Think Mini | Mathematik, Debugging, Forschung, Agents | 5-10x+ |
Kernempfehlungen:
- MEDIUM für die tägliche Entwicklung — Gute Qualität, angemessene Kosten, entspricht der Stufe HIGH der alten Version.
- LOW für einfache Aufgaben — Spart über 70 % der Kosten für Thinking-Token.
- HIGH für tiefgehendes Reasoning — Die Fähigkeiten von „Deep Think Mini“ sind einzigartig, aber achten Sie auf die Kosten.
- Standard ist HIGH — Wenn nichts eingestellt wird, ist der teuerste Modus aktiv. Denken Sie daran, dies aktiv anzupassen.
Es wird empfohlen, die Thinking-Levels je nach Aufgabentyp dynamisch über die Plattform APIYI (apiyi.com) zu wechseln, um das optimale Gleichgewicht zwischen Qualität und Kosten zu erreichen.
Referenzen
-
Google AI Dokumentation: Gemini Thinking-Konfigurationsleitfaden
- Link:
ai.google.dev/gemini-api/docs/thinking - Beschreibung: Vollständige Dokumentation für den Parameter
thinkingLevel
- Link:
-
Google AI Dokumentation: Gemini 3.1 Pro Modellseite
- Link:
ai.google.dev/gemini-api/docs/models/gemini-3.1-pro-preview - Beschreibung: Unterstützungsmatrix für Thinking-Level und wichtige Hinweise
- Link:
-
Gemini API Preisgestaltungsseite: Abrechnungsinformationen für Thinking-Token
- Link:
ai.google.dev/gemini-api/docs/pricing - Beschreibung: Thinking-Token werden zum Preis von Output-Token abgerechnet
- Link:
-
VentureBeat: Deep Think Mini – Ein ausführlicher Testbericht
- Link:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Beschreibung: Praxisdaten zur Lösung einer IMO-Aufgabe (Internationale Mathematik-Olympiade) in 8 Minuten
- Link:
-
Offizieller Google Blog: Gemini 3.1 Pro Veröffentlichungsankündigung
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Beschreibung: Offizielle Vorstellung des dreistufigen Thinking-Systems und Deep Think Mini
- Link:
📝 Autor: APIYI Team | Für technischen Austausch besuchen Sie APIYI apiyi.com
📅 Aktualisiert am: 20. Februar 2026
🏷️ Schlagworte: Gemini 3.1 Pro Thinking-Level, thinkingLevel, Deep Think Mini, LOW MEDIUM HIGH, API-Aufruf, Reasoning-Steuerung