2026年4月,中国大陸の開発者コミュニティで最も話題になったコーディングモデルは、GLM-5.1とClaude Sonnet 4.6の2つでした。前者はZ.ai(旧智譜AI)がMITライセンスで公開したばかりのモデルで、SWE-Bench Proにおいて58.4ポイントを記録し、Claude Opus 4.6、GPT-5.4、Gemini 3.1 Proをすべて追い抜いて、一気にオープンソースコーディングモデルの頂点に立ちました。後者はAnthropicが「ミドルレンジモデルにおけるフラッグシップレベル」と称するモデルで、SWE-bench Verifiedで79.6%という、Opus 4.6の80.8%に迫るスコアを叩き出しました。しかも価格はOpusの数分の一で、Sonnetシリーズとしては初めて1Mトークンのコンテキストウィンドウが開放されています。
では、本題に入りましょう。GLM-5.1とClaude Sonnet 4.6、実際のプログラミング現場で本当に強いのはどちらでしょうか? これは一言で答えられる問題ではありません。両者の強みは大きく異なります。GLM-5.1は「産業レベルのリアルなコード修正」ベンチマークでSonnet 4.6を上回っていますが、サードパーティの総合評価ではSonnetが平均スコアで巻き返しています。本記事では、**6つの側面(コードベンチマーク、知識、価格、コンテキスト、エージェントの長距離タスク、エコシステムの互換性)**から両者の真の違いを解き明かし、ビジネスシーン別の明確な選定アドバイスを提供します。

GLM-5.1 vs Claude Sonnet 4.6 コアデータ一覧
比較を始める前に、両者の重要な事実を並べた表をご覧ください。すべてのデータはBenchLM、Z.ai、Anthropic、およびサードパーティの評価プラットフォームの公開情報に基づいています。
| 項目 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| 開発元 | Z.ai(旧智譜AI) | Anthropic |
| リリース日 | 2026-04-07(オープンソース) | 2026年初頭 |
| アーキテクチャ | 754B MoE / 40B アクティブ | 非公開(中型Sonnetレベル) |
| ライセンス | ✅ MIT | ❌ クローズドソース |
| コンテキストウィンドウ | 200K(一部プラットフォームでは203K) | 200K → 1M(beta) |
| SWE-bench Verified | 77.8% | 79.6% |
| SWE-Bench Pro | 58.4 ⭐(OSS #1, Opus 4.6を追い抜き) | Opus 4.6よりやや低い |
| BenchLM 総合コーディング平均 | 58.4 | 66.4 |
| BenchLM 知識平均 | 52.3 | 73.7 |
| BenchLM 合計スコア | 79 | 80 |
| 入力価格 ($/M) | $1.00(Z.ai直接) | $3.00 |
| 出力価格 ($/M) | $3.20(Z.ai直接) | $15.00 |
| エージェント長距離タスク | 単一タスク約8時間 | Claude Code 70%のユーザー選好率 |
| APIYI接続 | ✅ 利用可能 https://api.apiyi.com/v1 |
✅ 利用可能 |
| 対応ツール | Claude Code / Cline / Cursor / OpenClaw | 上記 + Anthropicネイティブエコシステム |
🎯 迅速な判断のためのアドバイス: 両者の違いは「どちらが強いか」ではなく「どのシーンで強いか」です。今すぐ横断的な比較を行いたい場合、APIYI (apiyi.com) ではGLM-5.1とClaude Sonnet 4.6の両方が利用可能です。
modelフィールドを変更するだけで、同じ業務コード内で両者を切り替えることができ、15分以内にどんなベンチマークよりも正確な判断を自分のタスクで下すことができます。
GLM-5.1 と Claude Sonnet 4.6 の核心的な違い:同じカテゴリーのモデルではない
まず明確にしておくべき事実は、GLM-5.1 と Claude Sonnet 4.6 は厳密には「同じクラス」のモデルではなく、設計目標に体系的な違いがあるという点です。
モデルのポジショニングの違い
| 次元 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| メーカーの位置付け | 「最先端オープンソース + 長期Agentコーディング」 | 「ミドルレンジフラッグシップ・コスパ最強」 |
| パラメータ規模 | 大規模言語モデル(754B MoE) | 中型モデル(パラメータ非公開) |
| 学習目標 | コーディング + Agent + 数学的推論 | 汎用 + コーディング + 知識 + 安全性 |
| ビジネスモデル | MITオープンソース + Z.ai 自社API | クローズドサブスクリプション + API |
| 主な競合モデル | Claude Opus 4.6 / GPT-5.4 | Claude Opus 4.5 / GPT-5 / Sonnet 4.5 |
注目すべきは、Z.ai の内部評価において、GLM-5.1 は実は Sonnet 4.6 ではなく Claude Opus 4.6 をターゲットにしているという点です。つまり、「コーディング能力の上限」を純粋に比較するなら、GLM-5.1 の比較対象は Sonnet ではなく Opus であるべきです。しかし、「価格・総合能力・実用性」の3点を考慮すると、Sonnet 4.6 はミドルレンジ市場における非常に強力なライバルであるため、両者を比較することには依然として非常に高いエンジニアリング的価値があります。
サードパーティによる総合評価の現状
2026年4月に BenchLM が発表した暫定ランキングによると:
- 総合スコア: Claude Sonnet 4.6 = 80, GLM-5.1 = 79(1点差、ほぼ互角)
- コーディング平均スコア: Claude Sonnet 4.6 = 66.4, GLM-5.1 = 58.4(Sonnet 4.6 が8点リード)
- 知識平均スコア: Claude Sonnet 4.6 = 73.7, GLM-5.1 = 52.3(Sonnet 4.6 が21.4点リード、最大の差)
しかし、別の特定ベンチマークでは状況が完全に逆転します:
- SWE-Bench Pro(実際の産業用コード修正):GLM-5.1 = 58.4 ⭐、Claude Opus 4.6 の 57.3 と GPT-5.4 の 57.7 を上回り、Sonnet 4.6 も当然下回っています。
- SWE-bench Verified: Claude Sonnet 4.6 = 79.6%, GLM-5.1 = 77.8%、わずか1.8ポイント差
これらの数値を照らし合わせると、最初の結論が導き出せます。GLM-5.1 は「Sonnet 4.6 を完全に凌駕する」怪物ではありませんが、「難易度の高い産業用コード修正」という項目では確かに1位を獲得しており、一方で Sonnet 4.6 はより広範な総合コーディング評価において均衡の取れたリードを保っているということです。
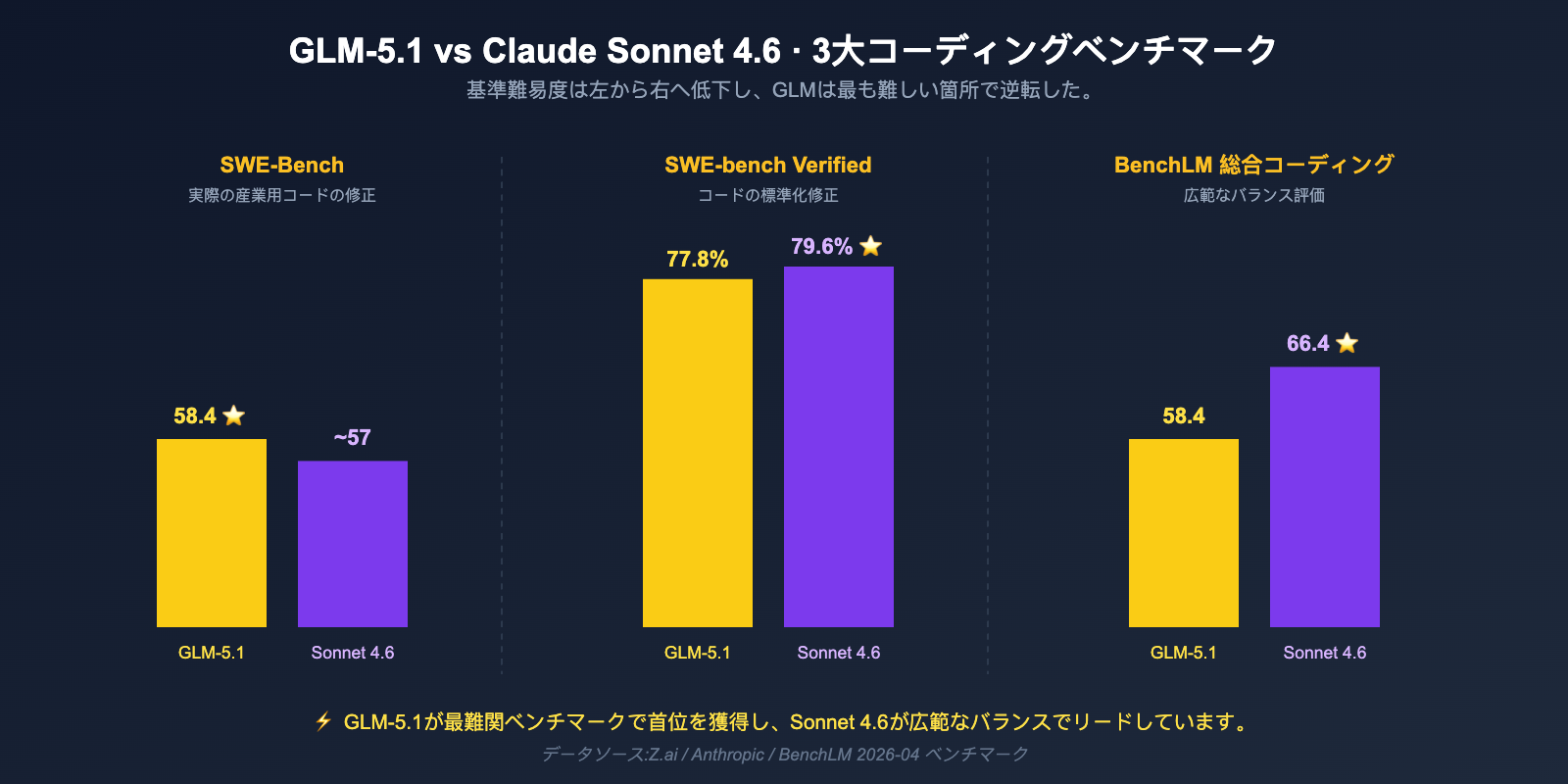
次元1:コードベンチマーク比較 — GLM-5.1 と Sonnet 4.6 の真の差
コード能力は今回の比較の核心であり、ベンチマークの数値で最も誤解を招きやすい部分でもあります。関連するすべてのベンチマークを1つの表にまとめ、エンジニアの視点から解説します。
コード関連ベンチマークの完全対照表
| ベンチマーク | GLM-5.1 | Claude Sonnet 4.6 | リード側 | 差 |
|---|---|---|---|---|
| SWE-Bench Pro | 58.4 | < 57.3 | GLM-5.1 | ~1+ 点 |
| SWE-bench Verified | 77.8% | 79.6% | Sonnet 4.6 | 1.8% |
| BenchLM コーディング平均 | 58.4 | 66.4 | Sonnet 4.6 | 8 点 |
| OSWorld(エージェントデスクトップ) | 非公開 | 72.5% | Sonnet 4.6 | — |
| Claude Code ユーザー選好率 | 未参加 | 70%(Sonnet 4.5対比)、59%(Opus 4.5対比) | Sonnet 4.6 | — |
| 8時間長期タスク | ✅ 公式の強み | Claude Code 長期タスク対応済 | ほぼ互角 | — |
エンジニア視点での解釈
この表をじっくり読み解くと、産業用ベンチマークの愛好家でなくても理解できる結論がいくつか見えてきます:
- 「実際のレポジトリのバグを修正する」仕事の場合:GLM-5.1 は SWE-Bench Pro で1位を獲得しています。これは「現場のエンジニアの日常」に非常に近いベンチマークであり、GLM-5.1 が Coding Agent のコアエンジンとして最適であることを意味します。
- 「標準的なコード修正 + 汎用プログラミング」の仕事の場合:Sonnet 4.6 は SWE-bench Verified でわずかに高く、BenchLM の総合コーディングスコアでも明らかにリードしており、「広さ」においてより安定しています。
- Claude Code / Cursor 内での長期タスクの場合:Sonnet 4.6 の70%というユーザー選好率は、実際の開発フローで検証済みであることを示しています。GLM-5.1 の8時間長期タスク能力は Z.ai の主要なセールスポイントですが、実際に自分で実行して効果を確認する必要があります。
- 「知識集約型タスク」(ドキュメント検索、設計、技術調査)を含む仕事の場合:Sonnet 4.6 の 73.7 に対し GLM-5.1 は 52.3 と、明らかな差があります。
なぜこのような「ベンチマークの食い違い」が起きるのか
多くの読者が疑問に思うでしょう。「同じ『コーディング能力』なのに、なぜあるベンチマークでは GLM-5.1 が強く、別のベンチマークでは Sonnet 4.6 が強いのか?」その答えはベンチマーク設計の違いにあります。
- SWE-Bench Pro は「難易度が極めて高い実際の産業用コード修正」に偏っており、タスクの品質基準が高く、数も少ないため、モデルの「長期推論 + ツール呼び出し」能力を極限まで要求します。これこそが GLM-5.1 の強みです。
- SWE-bench Verified は「人間が検証した標準的なコード修正タスクセット」であり、「日常的な開発シーンの平均レベル」に近いため、モデルの「広さ + 安定性」がより要求されます。これは Sonnet 4.6 の得意分野です。
- BenchLM 総合コーディング平均 は複数のベンチマークを重み付け平均しており、「あらゆるタスクに対応できる」ミドルレンジフラッグシップにとって有利に働きます。
この違いを理解すれば、孤立した数値に惑わされることはなくなります。
🎯 ベンチマーク選定のアドバイス:一つのベンチマークだけで結論を出さないでください。最も現実的な方法は、チームで最も頻繁に行う5〜10個の実際のコーディングタスクを内部ベンチマークセットとしてまとめ、APIYI (apiyi.com) を通じて GLM-5.1 と Claude Sonnet 4.6 の両方を呼び出し、自分のデータでどちらが業務スタイルに合っているかを検証することです。
维度二:知識と推論 — Sonnet 4.6 の圧倒的な優位性
コード生成の面では「一長一短」と言えますが、知識・推論・汎用的な理解という側面では、Sonnet 4.6 が圧倒的に優位です。
| 項目 | GLM-5.1 | Claude Sonnet 4.6 | 差分 |
|---|---|---|---|
| BenchLM 知識スコア | 52.3 | 73.7 | 21.4 ポイント |
| 長文ドキュメント理解 | 強 | より強力(1M コンテキスト活用時) | |
| 自然言語ライティング | 中国語は優秀 | 多言語で安定 | |
| 安全性とコンプライアンス推論 | 中程度 | 明らかに強力(Anthropicの強み) |
この結果から、以下のシナリオでは Sonnet 4.6 がより確実な選択肢となります。
- 技術調査レポート、設計ドキュメント、アーキテクチャ案の作成
- 言語をまたぐドキュメントの要約やコンプライアンス分析
- 「コードとビジネスの両方を理解する必要がある」複合的なタスク
- 顧客対応など、より厳格な安全ガードレールが求められるコンテンツ生成
GLM-5.1 が知識の面でやや劣っているのは「学習不足」というわけではなく、学習データと目標が「コーディング+数学+ツール利用」に特化しているためであり、汎用的な知識という点では Sonnet 4.6 ほどバランスが取れていないというだけのことです。
维度三:価格比較 — GLM-5.1 の切り札
もし一つだけ選ぶなら、価格こそが Sonnet 4.6 に対する GLM-5.1 の最も強力な武器です。
トークン単価の直接比較
| 項目 | GLM-5.1(Z.ai 直接調達) | Claude Sonnet 4.6 | GLM-5.1 のコストメリット |
|---|---|---|---|
| 入力 ($/M) | $1.00 | $3.00 | 3倍安い |
| 出力 ($/M) | $3.20 | $15.00 | 約4.7倍安い |
| 総合(2:1の比率) | ~$1.73 | ~$7.00 | 約4倍安い |
いくつか注意点があります:
- サードパーティプラットフォーム(BenchLMなど)の GLM-5.1 価格は、転売手数料が含まれるため若干高め(入力$1.40 / 出力$4.40)ですが、Z.ai 公式の直接調達価格は $1.00 / $3.20 です。
- Sonnet 4.6 の $3 / $15 という価格は Anthropic の公式価格であり、Opus 4.6 よりもすでに5倍安く、ミドルレンジ市場では「コストパフォーマンスの王様」と言えます。
- それでもなお、GLM-5.1 の出力トークンにおける優位性は4〜5倍あり、「入力よりも出力が多い」コード生成タスクにおいては非常に大きな意味を持ちます。
実際のコスト例
差をより直感的に理解するために、「日常的なコーディングエージェント」の典型的なタスク(入力5Kトークン、出力20Kトークン、1日平均1000回呼び出し)を想定してみましょう。
| モデル | 1日の入力コスト | 1日の出力コスト | 1日の合計 | 1ヶ月の合計 |
|---|---|---|---|---|
| GLM-5.1 | $5 | $64 | $69 | ~$2,070 |
| Claude Sonnet 4.6 | $15 | $300 | $315 | ~$9,450 |
差額:Sonnet 4.6 の月間コストは GLM-5.1 の約4.5倍となります。
「1日平均1000回のエージェント呼び出し」を行う中規模SaaSの場合、トークンコストだけで月間約7000ドルもの差が出ます。これはエンジニアをもう半人雇えるほどの金額です。
🎯 コスト最適化のアドバイス:すでに Claude Sonnet 4.6 を利用しているチームには、まず APIYI (apiyi.com) 上で 20% のトラフィック を GLM-5.1 に振り分けて A/B テストを行うことをお勧めします。もし結果が許容範囲内であれば、「重要度の低いビジネスコード生成」をすべて GLM-5.1 に移行し、「顧客対応」などの重要な呼び出しのみ Sonnet 4.6 を残すという運用に切り替えることで、全体的な品質を落とすことなく請求額を大幅に削減できるはずです。
维度 4:コンテキストウィンドウ — Sonnet 4.6 の反撃
価格面では GLM-5.1 が完勝ですが、コンテキストウィンドウという点では、Sonnet 4.6 が主導権を握り返しました。
| 項目 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| 標準コンテキスト | 200K (一部プラットフォームで 203K) | 200K |
| Beta コンテキスト | — | 1M トークン (beta) |
| 最大出力 | 128K | 低め |
| コンテキスト圧縮 | なし | ✅ 古いコンテキストを自動圧縮 |
1M トークンは Sonnet 4.6 の象徴的なアップグレードです。これは、中規模なコードリポジトリ全体を一度にプロンプトに詰め込めることを意味しており、RAG(検索拡張生成)による検索の手間を省けます。「リポジトリ全体の再構築 / ファイルをまたいだバグ特定 / コードベース全体の理解」といったタスクにおいて、2026 年 4 月時点の Sonnet 4.6 はほぼ代替不可能な存在と言えます。
GLM-5.1 の 200K も日常的なシーンの 90% はカバーできていますが、「超長文コンテキスト」を必要とする極限の環境では一歩譲る形となります。
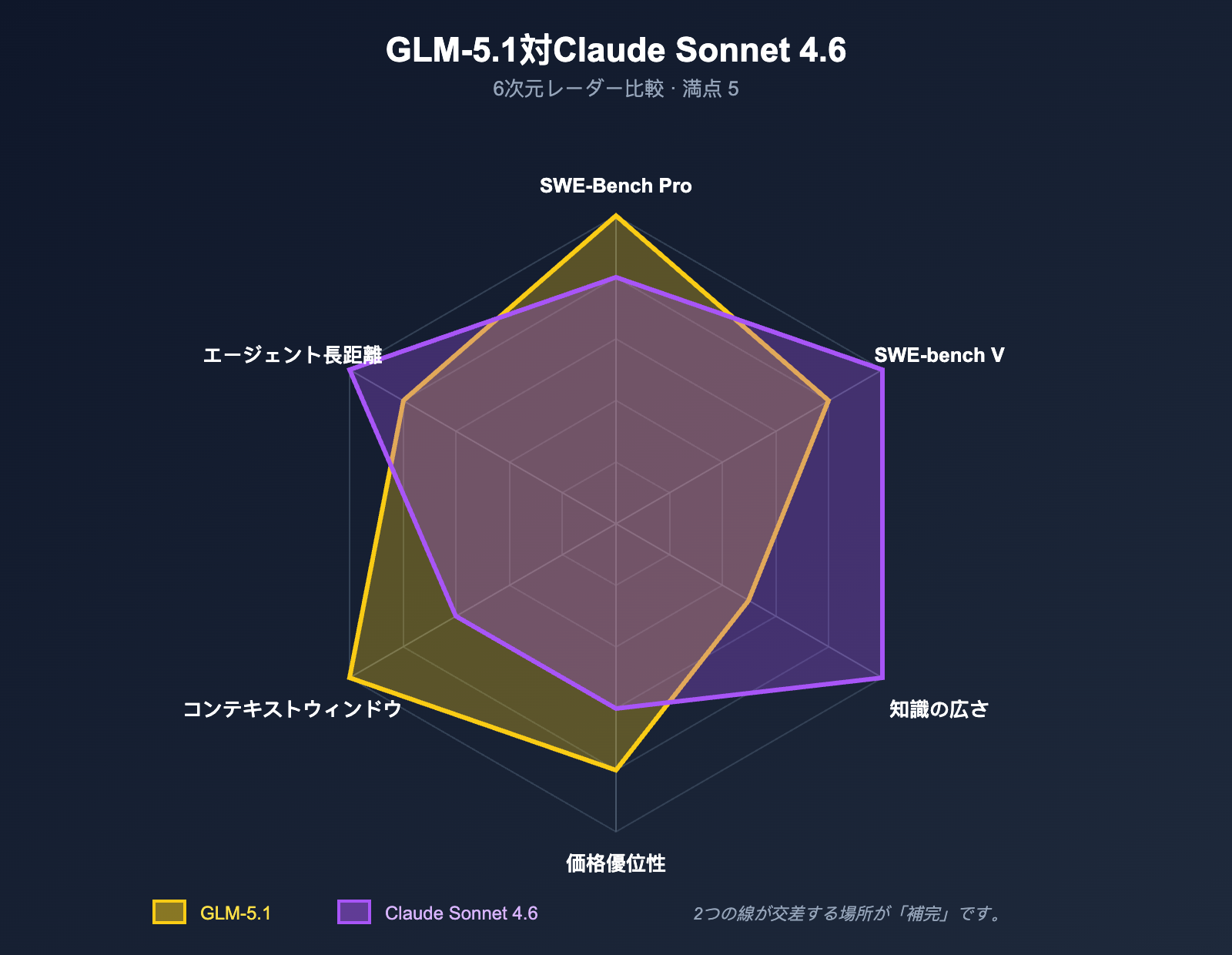
维度 5:Agent 長期タスク — 2 つのアプローチの対決
5 つ目の次元は Agent の長期タスク実行能力です。これは 2026 年の主要なコーディングモデルすべてがしのぎを削っている分野です。
両者の「長期」へのアプローチの違い
- GLM-5.1: Z.ai は「単一タスクで 8 時間の継続稼働」を掲げています。計画 → 実行 → テスト → 修正 → 二次最適化 というエンドツーエンドのサイクルを重視し、モデル自体の推論深度とツール呼び出しの安定性で勝負しています。
- Claude Sonnet 4.6: Anthropic は「Claude Code の実戦体験」を重視しています。Sonnet 4.5 ユーザーの 70% が内部テストで Sonnet 4.6 を支持しており、エンジニアリングされた Claude Code ワークフロー + 1M コンテキスト + コンテキスト圧縮を強みとしています。
まとめると以下の通りです:
| アプローチ | 核心的な強み | 適したシーン |
|---|---|---|
| GLM-5.1 | モデルの推論深度 + ツール呼び出しの安定性 | バックグラウンドの自動化 Agent / 無人タスク |
| Sonnet 4.6 | Claude Code ワークフロー + 1M コンテキスト | 開発者の対話型コーディング / IDE 統合 |
「バックグラウンドで Agent を動かして機能を開発させる」といった無人タスクを行うなら、GLM-5.1 の 8 時間の長期実行能力が最適です。一方、「エンジニアが IDE 上でモデルと対話しながらコードを書く」のであれば、Sonnet 4.6 の Claude Code 統合体験の方が成熟しています。
维度六: エコシステムの互換性 — Sonnet 4.6 のツールチェーンにおける優位性
最後の比較項目はエコシステムです。この点において Sonnet 4.6 は依然として明確なリードを保っていますが、GLM-5.1 も急速に追い上げています。
| 维度 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Claude Code 互換 | ✅(OpenAI 互換入口) | ✅ ネイティブ |
| Cline / Cursor | ✅(OpenAI 互換入口) | ✅ ネイティブ |
| OpenClaw | ✅ | ✅ |
| Anthropic ツール呼び出し | OpenAI スタイル | ✅ ネイティブ |
| サードパーティ Agent フレームワーク | 大半が OpenAI 互換をサポート | 大半が Anthropic ネイティブをサポート |
| デプロイの柔軟性 | ✅ MIT 自社ホスティング / APIYI / Z.ai 自社運営 | APIYI / Anthropic 公式 |
特筆すべきは、APIYI (apiyi.com) が OpenAI / Claude Native / Gemini Native の3種類のネイティブ形式をすべてサポートしている点です。つまり、どのスタイルの SDK を使って GLM-5.1 や Sonnet 4.6 を呼び出す場合でも、同じ API キーで完結します。これは両者の比較テストにおいて非常に実用的なポイントです。テストのたびに、認証、監視、請求の仕組みをそれぞれ2セットずつ管理する必要はありません。
シナリオ別の最終選定アドバイス
これら6つの側面を統合し、ビジネスシナリオに応じた具体的なモデル選定アドバイスをまとめました。
シナリオ対照表
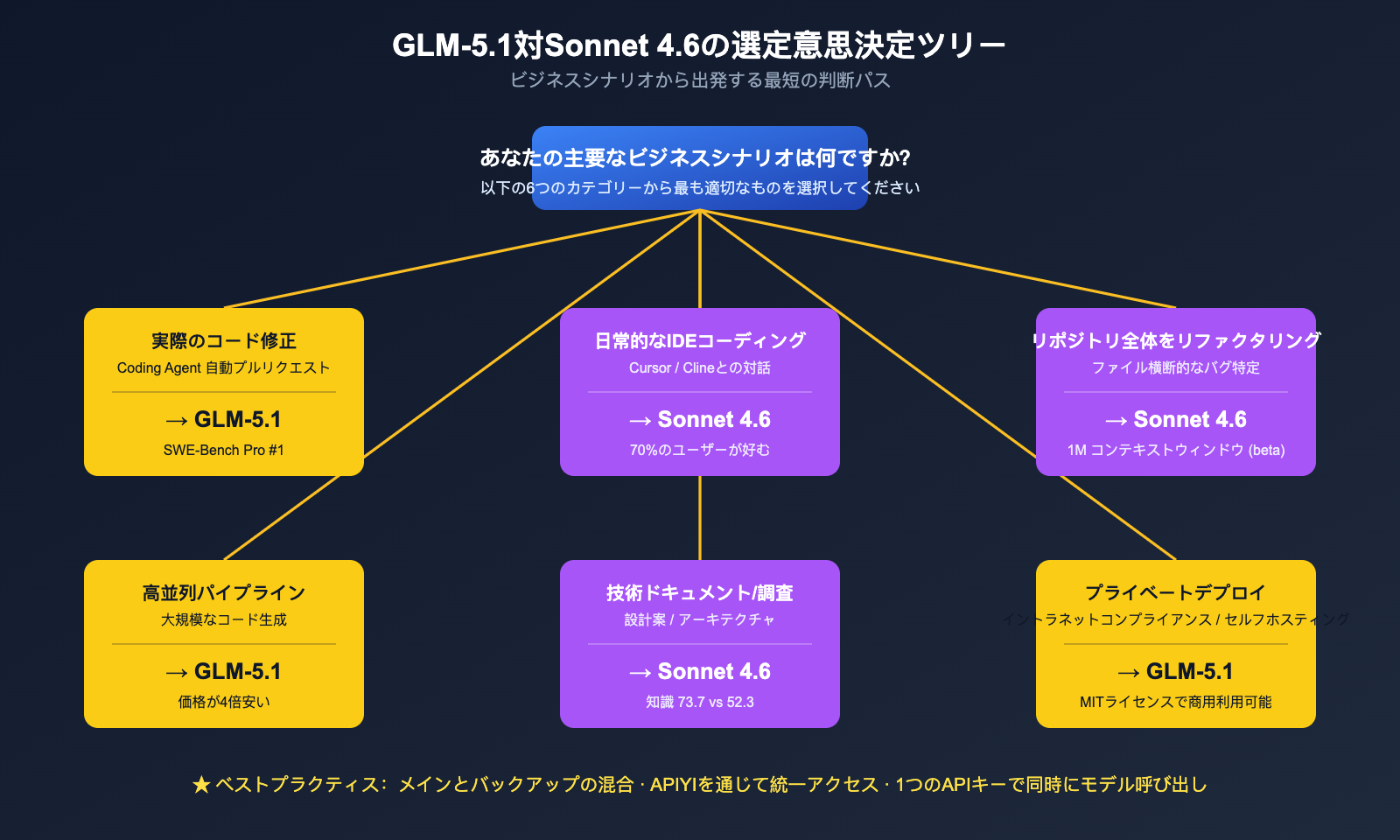
| ビジネスシナリオ | 推奨モデル | 主な理由 |
|---|---|---|
| 実際の産業用コード修正(Agent による自動 PR) | GLM-5.1 | SWE-Bench Pro 世界1位 + 8時間の長文脈 |
| Cursor / Cline での日常的な IDE コーディング | Claude Sonnet 4.6 | Claude Code ユーザーの利用率 70%、ワークフローが成熟 |
| リポジトリ全体の再構築 / ファイル横断的なバグ特定 | Claude Sonnet 4.6 | 1M コンテキストウィンドウ(beta)が最大の武器 |
| 標準的なコード生成 + 高並列呼び出し | GLM-5.1 | 4倍のコスト効率、パイプライン生産に最適 |
| 技術調査 / 設計ドキュメント / アーキテクチャ設計 | Claude Sonnet 4.6 | 知識の均等スコア 73.7 vs 52.3 で大幅リード |
| 数学的推論 / アルゴリズムコンテスト形式 | GLM-5.1 | AIME 2026 95.3 + GPQA-Diamond 86.2 |
| 顧客向け SaaS 内のコード生成モジュール | Sonnet 4.6(主) + GLM-5.1(バックアップ) | Sonnet をメインに、GLM で補完しコスト削減と品質維持を両立 |
| プライベートデプロイ / 社内ネットワーク準拠 | GLM-5.1 | MIT ライセンス + 自社ホスティング可能 |
| 日本語コーディングの対話 | GLM-5.1 | 国産モデルは日本語のプロンプトにより適している |
| 高難易度の推論 + 長いツール呼び出しチェーン | 引き分け、要自前テスト | 両者とも対応可能、差は5%以内 |
推奨されるハイブリッド戦略
多くの中規模チームに対しては、どちらか一方を選ぶのではなく、「メイン・サブのハイブリッド運用」を推奨します。
- 主力モデル: 業務のメインシナリオに合わせて1つ選定します(コード修正なら GLM-5.1、IDE 統合なら Sonnet 4.6)。
- バックアップモデル: もう一方を登録し、重要な業務の A/B テストや段階的な切り替えに活用します。
- 統合アクセス層: APIYI (apiyi.com) を通じて同じ API キーで両方を呼び出せば、ビジネスコード側の
modelフィールドを書き換えるだけで済み、認証ロジックを2つ管理する必要はありません。 - コスト監視: APIYI のコンソールで両モデルの請求額を個別に確認し、定期的にどちらが業務上の「費用対効果」が高いかを判断して、トラフィック比率を動的に調整します。
🎯 ハイブリッド戦略の導入アドバイス: APIYI (apiyi.com) 上では、同じ API キーを使って GLM-5.1 と Claude Sonnet 4.6 をシームレスに切り替えられます。ビジネスコードの変更は文字列を1つ変えるだけです。まずは「重要度の低いコード生成」のトラフィックの70%を GLM-5.1 に切り替え、「顧客向け + 高難易度推論」の30%を Sonnet 4.6 に残すことをお勧めします。これにより、GLM-5.1 の価格優位性を享受しつつ、重要なシナリオでの安定性も確保できます。
GLM-5.1 vs Claude Sonnet 4.6 よくある質問(FAQ)
Q1: GLM-5.1 は本当にコーディング能力で Claude Sonnet 4.6 を超えたのですか?
一部は超えていますが、一部はまだ及びません。 実際の産業用コード修正を評価する最も難易度の高いベンチマーク「SWE-Bench Pro」において、GLM-5.1 は 58.4 を記録し世界1位となりました。これは Claude Opus 4.6 の 57.3 や GPT-5.4 の 57.7 を上回っており、当然 Sonnet 4.6 も超えています。 しかし、標準化されたコード修正を評価する「SWE-bench Verified」では、Sonnet 4.6 が 79.6% で、GLM-5.1 の 77.8% を約 1.8 ポイント上回っています。また、BenchLM の総合コーディング平均点でも、Sonnet 4.6 が 66.4 で、GLM-5.1 の 58.4 を約 8 点リードしています。結論として、GLM-5.1 は「難易度の頂点」で Sonnet 4.6 を凌駕しましたが、「広範なバランス」ではまだ後塵を拝しています。
Q2: GLM-5.1 は Claude Sonnet 4.6 よりどれくらい安いですか?
Z.ai 公式の直接調達価格に基づくと、GLM-5.1 は入力 $1.00 / 出力 $3.20 ですが、Claude Sonnet 4.6 は入力 $3.00 / 出力 $15.00 です。入力は 3 倍、出力は約 4.7 倍安くなります。「1日あたり1000回のコーディングエージェント呼び出し + 入力 5K / 出力 20K」という典型的なシナリオでは、Sonnet 4.6 の月額料金は GLM-5.1 の約 4.5 倍になります。業務内容として「入力よりも出力の量が多い」場合、GLM-5.1 のコストパフォーマンスはさらに際立ちます。
Q3: GLM-5.1 と Sonnet 4.6 では、どちらのコンテキストウィンドウが大きいですか?
Claude Sonnet 4.6 の方が大きいです。 GLM-5.1 は 200K(一部プラットフォームでは 203K と表示)、Sonnet 4.6 は 200K から最大 1M トークン(ベータ版) に対応しています。1M というコンテキストは、中規模のコードリポジトリを一度に読み込めることを意味し、「全リポジトリのリファクタリング」や「ファイル横断的なバグ特定」といったタスクにおける強力な武器となります。超長文のコンテキストが必須のタスクであれば、Sonnet 4.6 がより確実な選択肢です。
Q4: 現在 Cursor や Cline で Claude Sonnet 4.6 を使っていますが、GLM-5.1 に切り替える価値はありますか?
あなたの抱えている課題によります。「コスト」を最も重視するなら、GLM-5.1 は料金を半分以下に削減できる可能性があるため、切り替える価値は十分にあります。「日常的なコーディング体験の安定性」を重視するなら、Sonnet 4.6 はユーザーの 70% から支持されており、Claude Code のワークフローで広く検証済みであるため、移行によるリスクの方がメリットを上回る可能性があります。最も賢明な方法は、APIYI (apiyi.com) を使ってトラフィックの 20% を GLM-5.1 に割り当てて A/B テストを行い、1週間様子を見てから比率を拡大するか決めることです。
Q5: GLM-5.1 と Sonnet 4.6 はどちらも APIYI で呼び出せますか?
はい、どちらも利用可能です。 APIYI (apiyi.com) は OpenAI / Claude Native / Gemini Native の 3 つのネイティブフォーマットをサポートしています。OpenAI SDK の base_url を https://api.apiyi.com/v1 に変更し、model を glm-5.1 と claude-sonnet-4-6(または類似のID)で切り替えるだけで、同じコード内で両方を実行でき、横断的な比較効率が非常に高くなります。
Q6: 個人開発者として、どちらを選ぶべきですか?
もし一つしか選べないなら、まずは自分のワークフローを確認してください。コーディングエージェント、バックエンドの自動化、大量のコード生成がメインなら GLM-5.1 を選びましょう。IDE 内でのインタラクティブなプログラミング、全リポジトリのリファクタリング、顧客向けのコンテンツ生成がメインなら Sonnet 4.6 がおすすめです。もし難しい二択をしたくないのであれば、両方を接続し、APIYI で一元管理するのが 2026 年のデベロッパーにとってのベストプラクティスです。 特定のベンダーに縛られることなく、モデルの選定に合わせて自動的にコストが最適化されます。
まとめ: GLM-5.1 vs Claude Sonnet 4.6 の最終判断
6 つの比較軸を統合すると、GLM-5.1 vs Claude Sonnet 4.6 の最終判断は次のようにまとめられます。「GLM-5.1 は『難易度の高い産業用コード修正』『価格』『国産オープンソース』『長距離エージェント』の 4 点で構造的な優位性があり、Claude Sonnet 4.6 は『広範なバランス』『知識の深さ』『1M コンテキスト』『IDE ワークフローの成熟度』の 4 点でリードを保っています。」 両者は「どちらかが取って代わる」関係ではなく、異なるビジネスシナリオを補完し合うツールです。
2026 年中盤以降の中国大陸の開発チームにとって、最も賢い戦略は「どちらか一方」ではなく 「メイン・サブの併用 + 統合アクセス層」 です。コストに敏感なタスクや長距離の自動化、プライベートなコンプライアンスが必要な部分には GLM-5.1 を、ユーザー向けの複雑なコンテキストや技術文書作成には Sonnet 4.6 を割り当てます。APIYI のような API 中継サービスを使って両者を同じ API キーの下で管理し、実際の利用データに基づいてトラフィック比率を動的に調整すれば、品質を犠牲にすることなく月額料金を大幅に圧縮できます。
🎯 最終アドバイス: GLM-5.1 と Claude Sonnet 4.6 は、どちらも APIYI (apiyi.com) で利用可能です。 今すぐ apiyi.com で API キーを作成し、OpenAI SDK の
base_urlをhttps://api.apiyi.com/v1に変更して、同じコードで 5 つの GLM-5.1 タスクを実行し、同じプロンプトで 5 つの Sonnet 4.6 タスクを実行して、この記事の 6 つの結論を自分の手で検証してみてください。どんな評価レポートも実測には勝てません。この 30 分間の検証が、2026 年最強の 2 つのコーディングモデルに対する確かな感覚を養ってくれるはずです。
著者: APIYI Team | AI 大規模言語モデルの導入とコーディングツールチェーンの評価に注力しています。その他のモデル比較や実戦的な呼び出し方法については、APIYI (apiyi.com) をご覧ください。