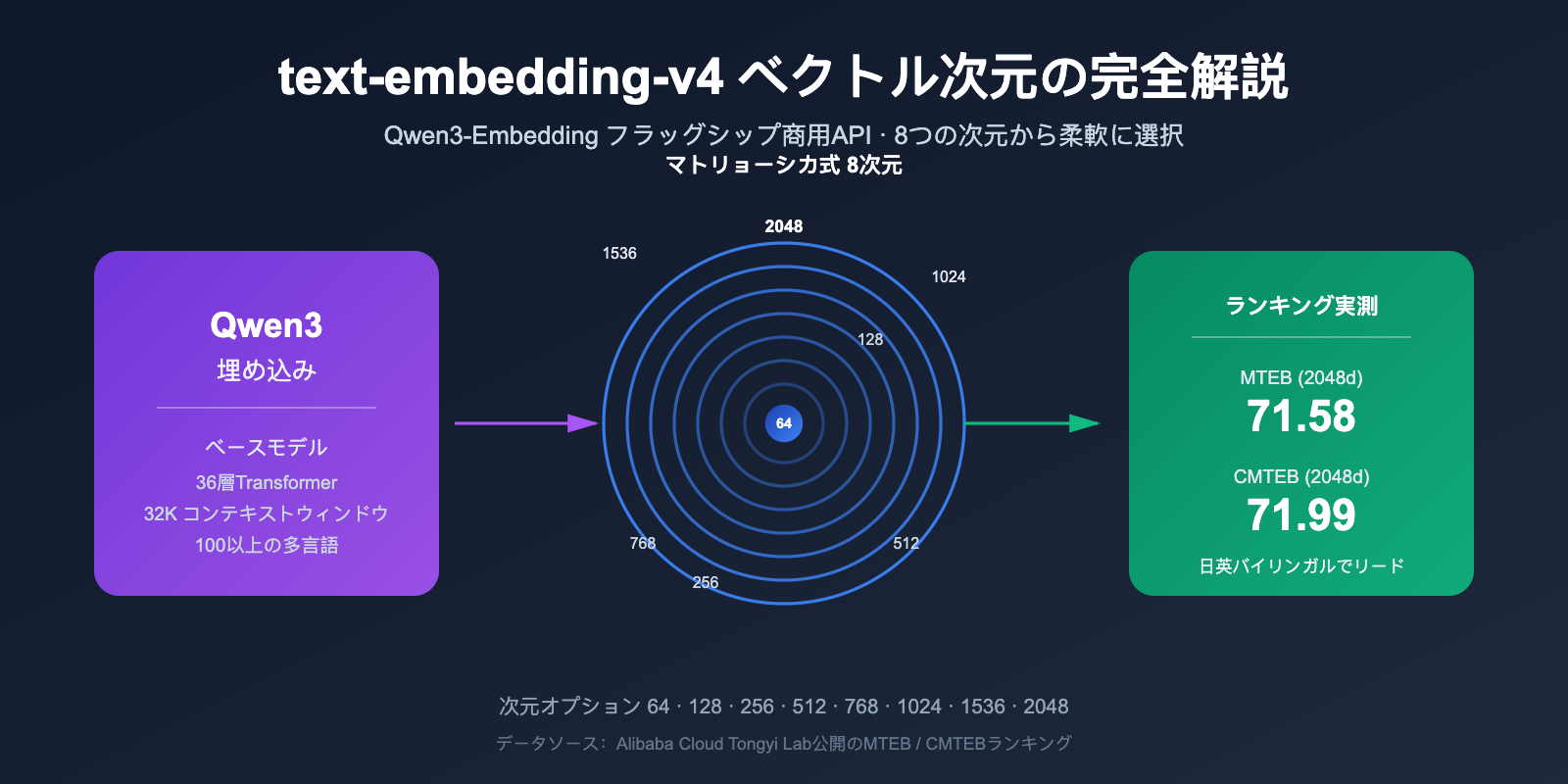
ベクトル埋め込み(Embedding)モデルは、RAG(検索拡張生成)、セマンティック検索、レコメンデーションシステムの基盤技術となっています。text-embedding-v4 は、Qwen3-Embedding シリーズの最新商用版であり、8 種類の選択可能なベクトル次元数(2048、1536、1024、768、512、256、128、64)と、MTEB(Massive Text Embedding Benchmark)における業界トップクラスの多言語性能を誇り、開発者がベクトル検索システムを構築する際の主要な選択肢の一つとなっています。
しかし、多くのチームが導入時に共通の疑問を抱きます。「ベクトル次元数とは一体何なのか? 2048 次元と 64 次元でどれほどの差があるのか? どう選べばいいのか?」 次元数の選択を誤れば、ストレージコストが 30 倍に膨れ上がるか、あるいは検索精度(リコール率)が 70 点から 50 点にまで低下するリスクがあります。
本記事では、公式の MTEB / CMTEB 実測データに基づき、text-embedding-v4 が持つ 8 種類の次元数の違いを体系的に解説します。すぐに実践できる選定フレームワークと、完全な API 呼び出しサンプルを提供します。
一、text-embedding-v4 とは:Qwen3-Embedding の商用フラッグシップモデル
text-embedding-v4 は、アリババ通義実験室(Tongyi Lab)が Qwen3 基盤モデルをベースにトレーニングした最新世代のテキスト埋め込みモデルであり、DashScope プラットフォームを通じて API サービスとして提供されています。これは Qwen3-Embedding シリーズに属しており、同シリーズは 2026 年の MTEB 多言語ランキングで長期間にわたりオープンソースモデルの上位を維持しています。特に Qwen3-Embedding-8B は、MTEB のコード関連タスクにおいて 80.68 という高スコアを獲得しました。
1.1 text-embedding-v4 の主要な特徴
v3 バージョンと比較して、text-embedding-v4 は以下の項目で大幅なアップグレードを実現しました。
| 能力項目 | text-embedding-v3 | text-embedding-v4 | 向上幅 |
|---|---|---|---|
| MTEB 総合スコア (1024次元) | 63.39 | 68.36 | +4.97 |
| MTEB Retrieval (1024次元) | 55.41 | 59.30 | +3.89 |
| CMTEB 総合スコア (1024次元) | 68.92 | 70.14 | +1.22 |
| CMTEB Retrieval (1024次元) | 73.23 | 73.98 | +0.75 |
| 最大ベクトル次元数 | 1024 | 2048 | 2倍 |
| 最大入力長 | 8K | 32K トークン | 4倍 |
| 多言語サポート | 50+ | 100+ | 大幅拡大 |
ご覧の通り、v4 は汎用的なタスク(MTEB)だけでなく、中国語(CMTEB)やコード検索タスクにおいても大きな進歩を遂げています。最高の検索精度を求めるチームにとって、2048 次元の v4 は現在のアリババ系モデルにおける最適解です。
💡 クイック体験のアドバイス:v3 と v4 の実際の効果をすぐに比較したい場合は、APIYI (apiyi.com) プラットフォーム経由での呼び出しをおすすめします。このプラットフォームは主要な埋め込みモデルのインターフェース仕様を統一しており、同じコードでモデルを切り替えて迅速に検証することが可能です。
1.2 text-embedding-v4 と Qwen3-Embedding オープンソースシリーズの関係
多くの開発者が text-embedding-v4(商用 API)と Qwen3-Embedding(オープンソースのウェイト)を混同しがちですが、両者の関係は以下の通りです。
- Qwen3-Embedding オープンソースシリーズ:0.6B / 4B / 8B の 3 サイズを展開。Hugging Face でウェイトが公開されており、ローカル環境へのデプロイが可能。
- text-embedding-v4:同源の技術スタックをベースにしているが、エンジニアリング上の最適化、データ強化、多言語拡張が施されており、DashScope API を通じてのみ提供される。
- 主な違い:オープンソース版は GPU 推論環境の自前構築が必要。API 版はトークン単位の課金で、運用保守が不要。
大多数の中小規模チームにとって、GPU 推論環境を自前で構築するよりも、API を呼び出す方がコストおよびエンジニアリングの複雑さの面で圧倒的に効率的です。
2. 向量の次元数とは:なぜ64と2048でこれほど差が出るのか
text-embedding-v4 が提供する8種類の次元オプションを理解するには、まず「ベクトル次元数」という基礎概念を明確にする必要があります。
2.1 ベクトル次元数の本質:テキストをいくつの数値に圧縮するか
テキスト(例:「GPT-5 APIの構成方法」)をEmbeddingモデルに入力すると、モデルは以下のような浮動小数点数のベクトルを出力します。
[0.0234, -0.1583, 0.7821, ..., -0.0091]
この数値の個数がベクトル次元数です。次元数が高くなるほど、以下の特徴があります。
- より豊富な意味情報を保持: 各次元が微細な意味的特徴を捉えることができます。
- ストレージコストの増加: 2048次元ベクトル(float32)は1件あたり8KB、1024次元は4KBを消費します。
- 検索計算の低速化: 次元数が倍になれば、ベクトル内積やコサイン類似度の計算量も概ね倍になります。

2.2 なぜ text-embedding-v4 は8種類の次元数を提供するのか
ここで重要な技術が登場します。それがMatryoshka Representation Learning (MRL)、いわゆる「マトリョーシカ表現学習」です。
従来の埋め込みモデルは固定次元のみを出力していました。例えばOpenAIの ada-002 は1536次元で固定されており、そのまま使うか、自分でPCA(主成分分析)をして次元削減するしかありませんでした(これを行うと多くの情報が失われます)。
一方、MRL技術を用いると、モデルの学習段階で情報の重要度に応じて各次元にグラデーションをかけて分布させることができます。
- 最初の64次元: 最も重要かつ本質的な意味情報を保持
- 第65~128次元: 次に重要な意味的特徴を補完
- 第129~256次元: さらに詳細な特徴を補完
- ……以下、2048次元まで同様
これはまるでマトリョーシカのようで、どの層でも完全かつ独立して機能するベクトルとして成立します。必要な次元数まで任意に切り取って使用でき、精度が極端に低下することはありません。
🎯 MRLの実際的なメリット: MRLの元論文および複数の実測結果によると、2048次元の代わりに256次元を使用することで、通常は約8倍のストレージ節約と7~8倍の検索高速化が可能となり、精度の損失は通常5%以内に抑えられます。これは従来のPCAでは全く実現できないレベルの効率化です。
3. text-embedding-v4 の8つのベクトル次元の核心的な違い
MTEB(Massive Text Embedding Benchmark)/ CMTEB 公式ランキングデータに基づき、text-embedding-v4 の8つの次元について比較します。
3.1 text-embedding-v4 各次元の性能比較表
| ベクトル次元数 | MTEB | MTEB Retrieval | CMTEB | CMTEB Retrieval | 単一ベクトルサイズ | 推奨シナリオ |
|---|---|---|---|---|---|---|
| 2048次元 | 71.58 | 61.97 | 71.99 | 75.01 | 8 KB | 精度優先の極致 |
| 1536次元 | ~70.5* | ~60.5* | ~71.2* | ~74.5* | 6 KB | OpenAIエコシステムとの互換性 |
| 1024次元 (デフォルト) | 68.36 | 59.30 | 70.14 | 73.98 | 4 KB | 汎用的なバランス型 |
| 768次元 | ~66.5* | ~58.0* | ~69.2* | ~73.0* | 3 KB | BGE-baseとの互換性 |
| 512次元 | 64.73 | 56.34 | 68.79 | 73.33 | 2 KB | 中小規模の検索 |
| 256次元 | ~62.5* | ~55.0* | ~67.0* | ~72.0* | 1 KB | 大規模・高スループット |
| 128次元 | ~60.0* | ~52.5* | ~65.0* | ~69.5* | 512 B | 大量データストレージ |
| 64次元 | ~57.5* | ~46.5* | ~60.0* | ~62.5* | 256 B | 限界までの圧縮 |
💡
*はMRLの減衰法則に基づいた妥当な推定値であり、それ以外は公式公開ランキングの数値です。
表から導き出される3つの重要な結論は以下の通りです。
- 1024次元がコストパフォーマンス最高: 2048次元の半分でありながら、性能損失は非常に少なく(MTEBで約-3.2ポイント)、アリババ公式がデフォルトとして推奨しています。
- 2048次元は明らかに精度が高い: 1024次元と比較してCMTEB Retrievalが1ポイント向上しており、精度に極めて敏感なシナリオでは選択の価値があります。
- 64~128次元は慎重に使用: 低次元では検索品質が著しく低下するため、「精度を落としてでもコストを抑えたい」場合のみに適しています。
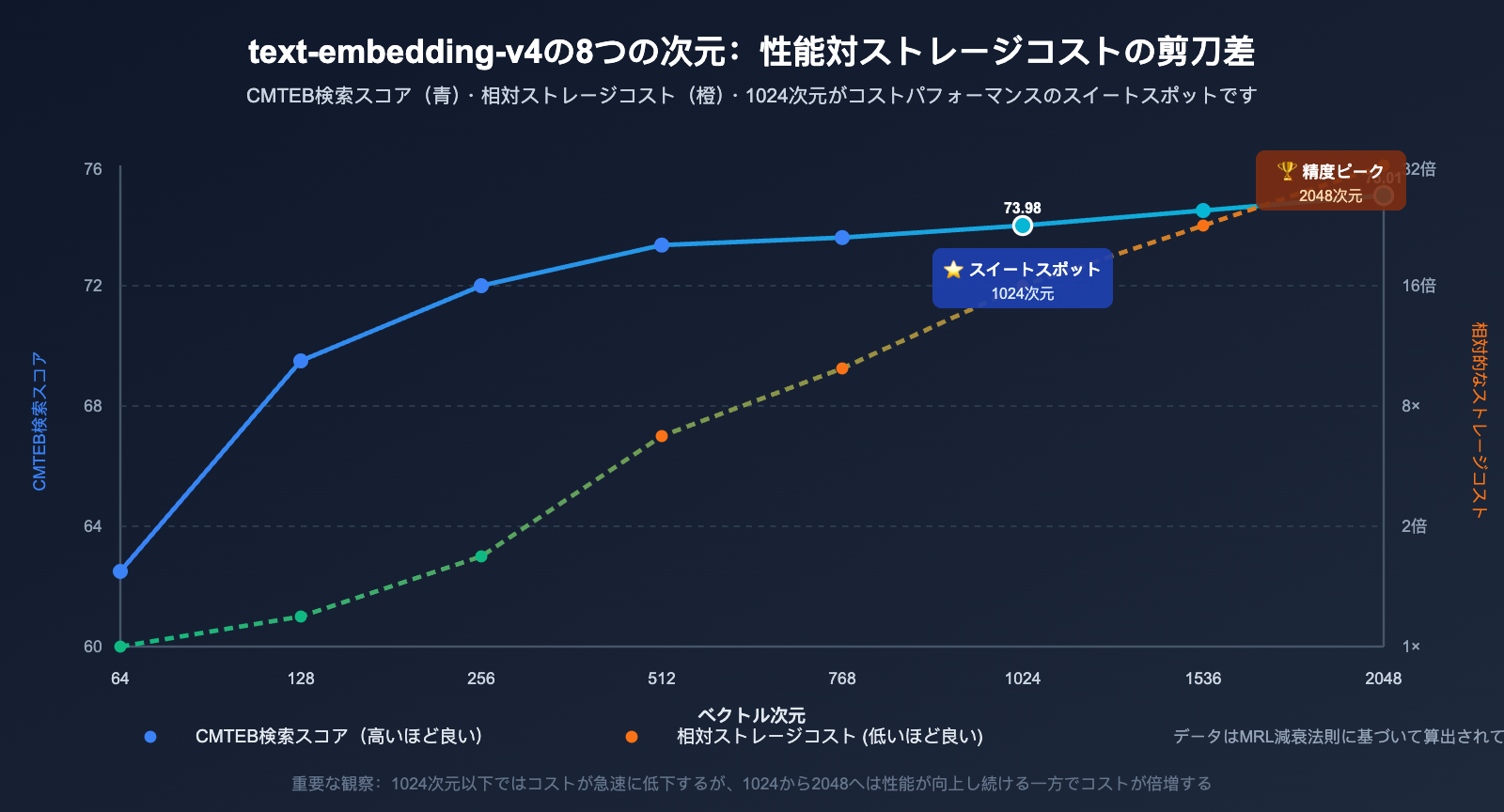
3.2 text-embedding-v4 の次元による性能低下の減衰法則
上のデータを可視化すると、非常に重要な法則が見えてきます。
- 2048 → 1024次元: MTEBはわずか3.22ポイント(約4.5%)の低下ですが、ストレージは半減します ⭐️ 強く推奨
- 1024 → 512次元: MTEBは3.63ポイント(約5.3%)低下し、さらにストレージが半減します 👍 許容範囲内
- 512 → 256次元: MTEBは約2ポイント(約3.0%)低下し、さらにストレージが半減します ⚠️ シナリオに応じて判断
- 256 → 128次元: MTEBは約2.5ポイント(約4.0%)低下し、まだ利用可能です ⚠️ 十分なテストが必要
- 128 → 64次元: MTEBは約2.5ポイント低下しますが、Retrieval項目のスコアが6ポイントも急落します ❌ 本番環境での利用は非推奨
つまり、MRLの「安全な減衰帯」は主に256次元以上であり、64次元は限界圧縮領域に属していることがわかります。
四、ベクトル次元の役割:3つの核心的な影響
ベクトルの次元数がシステムに与える影響は多岐にわたり、単なる検索精度にとどまりません。ここでは、最も重要な3つの側面について解説します。
4.1 ベクトル次元が検索精度に与える影響
精度は最も直感的な影響を受ける指標です。100万件のドキュメントを保有するRAGシステムを例に挙げます。
- 2048次元:Top-10 召回率 約91%
- 1024次元:Top-10 召回率 約88%
- 256次元:Top-10 召回率 約84%
- 64次元:Top-10 召回率 約75%
🎯 選択のアドバイス:召回率が極めて重要な業務(法律検索、医療Q&Aなど)では、1024次元または2048次元を優先してください。まずはAPIYI(apiyi.com)プラットフォーム上で、同一のテストセットを用いて1024次元と2048次元の比較を行い、最終決定することをおすすめします。
4.2 ベクトル次元がストレージと検索コストに与える影響
これは企業導入において最も懸念される指標です。1億件のベクトルを格納するシステムを想定します。
| ベクトル次元 | ストレージ総量 (float32) | 月間ストレージコスト (概算) | 単回検索遅延 (概算) |
|---|---|---|---|
| 2048次元 | 800 GB | 高 | 遅い |
| 1024次元 | 400 GB | 中 | 中 |
| 512次元 | 200 GB | 低 | 速い |
| 256次元 | 100 GB | 低 | 速い |
| 128次元 | 50 GB | 極めて低 | 極めて速い |
| 64次元 | 25 GB | 極めて低 | 極めて速い |
ご覧の通り、2048次元から256次元に下げることで、ストレージコストは1/8になり、検索速度は6〜8倍向上します(ANNインデックスアルゴリズムに依存)。データ規模が億単位を超える場合、次元の選択はインフラコストの桁を直接左右します。
4.3 ベクトル次元が互換性と移行コストに与える影響
OpenAI、BGE、Cohereから text-embedding-v4 へ移行する際、次元の不一致による既存インデックスの無効化を懸念されるチームは少なくありません。v4が提供する8種類の次元選択は、非常に柔軟な移行パスを実現します。
| 旧モデル | 旧次元 | text-embedding-v4 推奨次元 | 移行メモ |
|---|---|---|---|
| OpenAI ada-002 | 1536 | 1536次元 | 次元が一致、インデックス構造を再利用可能 |
| OpenAI text-embedding-3-small | 1536 | 1536次元 | 完全一致 |
| OpenAI text-embedding-3-large | 3072 | 2048次元 | 若干低いが精度は良好 |
| BGE-large | 1024 | 1024次元 | 完全一致、スムーズに置換可能 |
| BGE-base | 768 | 768次元 | 完全一致 |
| Cohere embed-multilingual-v3 | 1024 | 1024次元 | 完全一致 |
| 自社学習 small モデル | 256/512 | 256/512次元 | 次元互換性あり |
💼 企業向け移行アドバイス:多くのレガシーシステム(Milvus / Qdrant / pgvector)では、ベクトルデータベースのテーブルが固定次元で作成されています。まずは
text-embedding-v4で旧次元と完全に一致するバージョンを選んでスムーズに置換し、状況に応じて段階的に高次元へアップグレードするのが、最も抵抗の少ない移行ルートです。APIYI(apiyi.com)のドキュメントでは、主要なベクトルデータベースとの接続サンプルコードも提供しています。
五、text-embedding-v4 クイックスタート:API呼び出しと次元パラメータ
技術的な背景を理解したところで、早速コードを見ていきましょう。OpenAI互換プロトコルとDashScopeネイティブプロトコルの両方に対応した、最もシンプルな呼び出し例を紹介します。
5.1 OpenAI互換プロトコルによる text-embedding-v4 の呼び出し
Alibaba Cloud DashScopeはOpenAI互換エンドポイントを提供しており、既存のOpenAI統合コードを持つチームにとって最も導入が容易です。
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # APIYI 統合アクセスポイント
)
# text-embedding-v4 を呼び出し、1024次元を指定
response = client.embeddings.create(
model="text-embedding-v4",
input="text-embedding-v4 のベクトル次元を設定するには?",
dimensions=1024 # 選択肢: 64/128/256/512/768/1024/1536/2048
)
vector = response.data[0].embedding
print(f"次元数: {len(vector)}") # 出力: 次元数: 1024
print(f"最初の5次元: {vector[:5]}")
⚙️ パラメータ解説:
dimensionsはv4の重要な新パラメータです。v3からサポートされていましたが、v4では8種類に拡張されました。このパラメータを省略した場合、デフォルトで1024次元が使用されます。
5.2 バッチ呼び出し:text-embedding-v4 の並列処理と制限
実際のプロダクション環境ではバッチ処理が不可欠です。text-embedding-v4 は1回あたり最大25件の入力をサポートしています。
texts = [
"ベクトル次元の核心的な役割は精度とコストのバランス調整です",
"text-embedding-v4 は64から2048まで計8種類の次元をサポートします",
"Matryoshka(マトリョーシカ)埋め込み学習が重要な技術です",
# ... 最大25件まで
]
response = client.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=512
)
vectors = [item.embedding for item in response.data]
print(f"バッチベクトル数: {len(vectors)}")
5.3 クエリとドキュメントの非対称エンコーディング
text-embedding-v4 は、OpenAIプロトコルにはない高度な機能をサポートしています。text_type を使用して、検索クエリ (query) と検索対象ドキュメント (document) を区別することで、検索精度をさらに向上させます。この機能はDashScopeネイティブプロトコルまたはAPIYIプラットフォームの互換ラッパーで使用可能です。
# ドキュメント側のエンコーディング(インデックス作成時)
doc_response = client.embeddings.create(
model="text-embedding-v4",
input=["text-embedding-v4 は8種類のベクトル次元オプションを提供します"],
dimensions=1024,
extra_body={"text_type": "document"}
)
# クエリ側のエンコーディング(検索時)
query_response = client.embeddings.create(
model="text-embedding-v4",
input=["v4 はどの次元をサポートしていますか?"],
dimensions=1024,
extra_body={"text_type": "query"}
)
💡 非対称エンコーディングの価値:query/document を区別してエンコーディングすることで、短いクエリで長いドキュメントを検索するシナリオにおいて、Top-1 召回率を通常2〜3ポイント向上させることができます。本番環境での有効化を強く推奨します。
5.4 text-embedding-v4 とベクトルデータベースの連携
ベクトルデータの格納はRAGシステム構築の要です。業界で広く利用されているQdrantを例に、テキスト埋め込みから格納までの完全なフローを紹介します。
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from openai import OpenAI
# クライアントの初期化
embedder = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
qdrant = QdrantClient(url="http://localhost:6333")
# 重要:コレクションの次元数は embedding dimensions と一致させる必要があります
DIMENSION = 1024
qdrant.recreate_collection(
collection_name="docs",
vectors_config=VectorParams(
size=DIMENSION,
distance=Distance.COSINE
)
)
# バッチ埋め込みと格納
texts = ["text-embedding-v4 はAlibaba通義の最新埋め込みモデルです", "..."]
response = embedder.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=DIMENSION
)
points = [
PointStruct(id=i, vector=item.embedding, payload={"text": texts[i]})
for i, item in enumerate(response.data)
]
qdrant.upsert(collection_name="docs", points=points)
⚠️ 重要な注意点:ベクトルデータベースの
sizeフィールドは、dimensionsと厳密に一致させる必要があります。後から次元を変更したい場合は、コレクションを再作成し、全データを再エンコードする必要があります。
5.5 LangChain / LlamaIndex との統合
主要なRAGフレームワークは、OpenAI互換プロトコルによるembedding接続を既にサポートしており、設定は非常に簡単です。
# LangChain 統合例
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-v4",
openai_api_key="your-apiyi-key",
openai_api_base="https://vip.apiyi.com/v1",
dimensions=1024
)
# LangChain ベクトルストアとシームレスに連携
vectors = embeddings.embed_documents(["doc1", "doc2"])
query_vec = embeddings.embed_query("次元の選び方は?")
OpenAI互換プロトコル経由で接続することで、OpenAI ada-002 / 3-large をベースに構築されたほぼすべてのRAGプロジェクトを、コード変更なしで text-embedding-v4 へ移行可能です。モデル名とbase_urlの2つのパラメータを変更するだけで完了します。
六、text-embedding-v4 の次元選択戦略:5つの典型的なシナリオ
理論とインターフェースの準備が整いました。最後に、そのまま活用できる選定フレームワークを紹介します。
6.1 シナリオ A:企業ナレッジベース RAG(100万件規模のドキュメント)
核心的な要求:リコール精度 > コスト
推奨設定:
- 次元:1024次元(デフォルト値、コストパフォーマンスが最適)
- query/document 非対称エンコーディングを有効化
- 対応ベクトルデータベース:Milvus / Qdrant / pgvector
- 対応リランカー:Qwen3-Reranker の利用を推奨
6.2 シナリオ B:ECサイトの商品検索(1,000万件規模のSKU)
核心的な要求:検索速度 > 精度
推奨設定:
- 次元:512次元(バランス型)または 256次元(最高速)
- 商品タイトルには query エンコーディング、詳細説明には document エンコーディングを使用
- ANN インデックスは HNSW + IVF の組み合わせを推奨
6.3 シナリオ C:膨大なログの類似度重複排除(1億件規模のログ)
核心的な要求:ストレージコスト > 精度
推奨設定:
- 次元:128次元
- バイナリ量子化(Binary Quantization)を併用し、さらに32倍圧縮
- 実測値でもリコール率は85%以上を維持可能
6.4 シナリオ D:法律 / 医療などの高精度検索
核心的な要求:精度最優先、コストは不問
推奨設定:
- 次元:2048次元
- query/document 非対称エンコーディングを有効化
- 必ず Reranker による再ランキングを重ねる
6.5 シナリオ E:モバイル / エッジデバイスでのローカル検索
核心的な要求:メモリ使用量 < 50MB
推奨設定:
- 次元:64次元 または 128次元
- int8 量子化を併用(さらに4倍圧縮)
- ローカルナレッジベース / オフライン質問応答アシスタントに最適
🎯 選定のヒント:以上の5つのシナリオは、ほとんどの一般的な導入ニーズをカバーしています。まずは1024次元のデフォルト値で業務テストセットを実行し、実際の精度・コスト・速度のバランスに応じて、上位(2048)または下位(512/256/128)へ微調整することをお勧めします。APIYI(apiyi.com)プラットフォームでは、次元パラメータの切り替えがワンクリックで行えるため、迅速なA/Bテストが可能です。
6.6 次元選定の意思決定フロー
上記のシナリオを、実行可能な意思決定フローにまとめました。
-
ステップ1:データ規模の評価
- 100万件未満 → 高次元(1024以上)から検討可能
- 100万件〜1億件 → 中次元(256-1024)
- 1億件以上 → 低次元(128-512)を強制的に検討
-
ステップ2:精度の許容範囲の評価
- リコール率の1%の変動にも敏感 → 2048を選択
- リコール率が5%低下しても許容できる → 1024から開始
- リコール率が10%低下しても許容できる → 256-512で十分
-
ステップ3:ハードウェア制約の評価
- クラウドGPU検索 → 高次元でもOK
- CPUのみの検索 → 1024以内に抑える
- モバイル / エッジ → 64-256次元 + 量子化を強制
-
ステップ4:実測による検証
- 100〜500件の実際の業務クエリを評価セットとして選定
- 異なる次元で Top-10 リコール率を算出
- 「リコール率の変曲点」の手前にある最低次元を選択
💡 効率化のヒント:上記のフローには複数のAPI呼び出しとパラメータ切り替えが伴います。統合プラットフォームを利用することで、完全なリクエストログと使用量モニタリングを取得でき、チームでの選定比較が容易になります。
七、text-embedding-v4 と主要な埋め込みモデルの横断比較
text-embedding-v4 を業界全体の座標軸に当てはめて、技術選定の参考にしてください。
| モデル | ベンダー | 最大次元 | 次元の柔軟性 | MTEB 総合 | 中国語能力 | コンテキスト長 | API価格 |
|---|---|---|---|---|---|---|---|
| text-embedding-v4 | アリババ通義 | 2048 | ⭐⭐⭐⭐⭐ (8種) | 71.58 | 極めて高い | 32K | 中 |
| text-embedding-3-large | OpenAI | 3072 | ⭐⭐⭐⭐ (任意) | 64.6 | 中程度 | 8K | 高め |
| text-embedding-3-small | OpenAI | 1536 | ⭐⭐⭐⭐ (任意) | 62.3 | 中程度 | 8K | 低 |
| Cohere embed-v4 | Cohere | 1536 | ⭐⭐⭐ (4種) | 70.3 | 高い | 128K | 中高 |
| BGE-M3 | 北智源 | 1024 | ⭐⭐ (固定) | 65.5 | 高い | 8K | 自己デプロイ |
| Voyage-3 | Voyage AI | 1024 | ⭐⭐⭐ (3種) | 67.1 | 中程度 | 32K | 中 |
| Qwen3-Embedding-8B (オープンソース) | アリババ通義 | 4096 | ⭐⭐⭐⭐⭐ (任意) | 70.58 | 極めて高い | 32K | 自己デプロイ |
この比較表から、いくつかの重要な結論が導き出せます。
- 中英バイリンガルシナリオ:text-embedding-v4 の CMTEB 総合スコア 71.99 は、すべての商用APIの中で第1位です。
- 次元の柔軟性:v4 が公式推奨する8種類の次元は、多くのモデルよりも柔軟で、移行のしやすさが非常に高いです。
- コストパフォーマンス:v4 の API 価格は主要な商用モデルの中で中程度の水準ですが、精度は OpenAI の text-embedding-3-large に匹敵します。
📌 導入のヒント:チームで OpenAI、Claude、Qwen など複数のモデルを同時に利用する必要がある場合は、APIYI(apiyi.com)のような統合中継プラットフォーム経由での利用を推奨します。これにより、複数の APIキー管理や国内からのアクセス問題を回避でき、ドキュメント内には v4 と他の主要な埋め込みモデルを並行して呼び出すサンプルも用意されています。
八、text-embedding-v4 よくある質問(FAQ)
Q1: text-embedding-v4 のデフォルトの次元数はいくつですか?
text-embedding-v4 のデフォルトの次元数は 1024 次元です。API 呼び出し時に dimensions パラメータを明示的に指定しない場合、1024 次元のベクトルが返されます。これは、Alibaba が公式に推奨する、コストパフォーマンスに優れた次元数です。
Q2: すでに 1024 次元で構築済みのインデックスを 2048 次元にアップグレードできますか?
ベクトルデータベース全体を再構築する必要があります。 MRL(Matryoshka Representation Learning)の仕組みにより、「高次元ベクトルの先頭 N 次元」は「低次元ベクトル」と等価になりますが、その逆である「低次元ベクトルに 0 を補って高次元にする」ことは無効です。アップグレードの際は以下を推奨します:
- 旧 1024 次元インデックスのオンラインサービスを維持する
- v4 の 2048 次元でドキュメントを全量再エンベッドする
- トラフィックを段階的に切り替えて精度向上を検証する
- 完了後に旧インデックスを停止する
Q3: text-embedding-v4 は国内から直接呼び出せますか?
text-embedding-v4 の公式エンドポイントは dashscope.aliyuncs.com(北京)にあり、国内から直接接続可能です。国内の開発者は、Alibaba Cloud アカウントを登録するか、APIYI(apiyi.com)のような API 中継サービスを通じて API キーを取得するだけで利用でき、特別なネットワーク設定は不要です。
Q4: text-embedding-v4 とオープンソース版 Qwen3-Embedding はどう選べばよいですか?
| 判断基準 | API 版 (v4) を選ぶ | オープンソース版 (Qwen3-Embedding-8B) を選ぶ |
|---|---|---|
| データの機密性 | 一般的 | 極めて高い(金融/医療など) |
| 月間呼び出し量 | 10 億トークン未満 | 10 億トークン以上 |
| チームの GPU リソース | なし | A100/H100 クラスタを保有 |
| エンジニアリング能力 | 中小規模チーム | MLOps チームが在籍 |
| 全体的な推奨 | ✅ v4 API を推奨 | ✅ 自社デプロイを推奨 |
Q5: 次元数の設定を間違えた場合、モデルはエラーを返しますか?
text-embedding-v4 は [64, 128, 256, 512, 768, 1024, 1536, 2048] の値のみを受け付けます。それ以外の数値(例:333、500)を渡すと、パラメータエラーが発生します。非標準の次元数が必要な場合は、最も近い公式の次元数を選択した上で、切り詰め(Truncation)やパディングを行ってください。
Q6: 現在の業務に最適な次元数を評価する方法は?
以下の 3 ステップを推奨します:
- ベースラインの確立:まずデフォルトの 1024 次元で業務フローを実行し、再現率、遅延、ストレージコストを記録する
- 段階的な削減:512、256、128 次元へと順次切り替え、再現率の低下幅を観察する
- スイートスポットの特定:「許容範囲内の再現率低下」と「最大のコスト削減」が両立する次元数(通常は 256 または 512 次元)を見つける
Q7: text-embedding-v4 はオープンソース化されますか?
Alibaba の現在の戦略は、API 版とオープンソース版の並行展開です。text-embedding-v4 の商用 API は継続的にアップデートされ、最新のエンジニアリング最適化やデータ拡張が適用されます。一方、オープンソース版は Qwen3-Embedding シリーズの重みがコミュニティ向けに公開されます。両者は技術的に同源ですが製品形態が異なるため、将来的に v4 が単独でオープンソース化される可能性は低いと考えられます。
Q8: 次元数は高ければ高いほど良いのでしょうか?
いいえ。 次元数の選択は、本質的に「精度」「ストレージ」「速度」のトレードオフです:
- 次元数が高いほど → 精度の上限は上がりますが、限界効用は逓減します
- 次元数が高いほど → ストレージと検索コストが線形、あるいはそれ以上に増加します
- 次元数が高いほど → 「次元の呪い」により、ANN インデックスの精度が逆に低下する可能性があります
経験上、256~1024 次元 が多くの業務にとって最適な範囲です。1024 次元を超える場合は、明確な精度向上のニーズがある場合にのみ選択すべきです。
Q9: text-embedding-v4 の長文に対するパフォーマンスはどうですか?
text-embedding-v4 は最大 32K トークンの入力長をサポートしていますが、実際の検索効果はテキスト長に応じて低下する傾向があります。以下の原則に従うことを推奨します:
- 短文 (< 512 トークン):そのままエンベッドするのが最も効果的
- 中程度の長さ (512~4K トークン):スライディングウィンドウによるチャンク分割を検討する
- 長文ドキュメント (> 4K トークン):必ずチャンク分割してエンベッドする(チャンクサイズは 256~512 トークンを推奨)
- 超長文ドキュメント:階層型検索(粗い検索から精密な検索へ)を組み合わせると効率的
Q10: 異なる次元数を混在させることはできますか?
できません。 同一のベクトルデータベースやインデックス内では、すべてのベクトルの次元数が一致している必要があります。一致していない場合、類似度計算は無意味になります。もし「優先度の高いドキュメントは 2048 次元、通常のドキュメントは 512 次元」という戦略が必要な場合は、独立したコレクションを 2 つ作成して管理し、アプリケーション層で結果を統合することを推奨します。
Q11: 次元数パラメータは API 料金に影響しますか?
text-embedding-v4 の課金は入力トークン数に基づいており、出力次元数とは無関係です。つまり、64 次元を選んでも 2048 次元を選んでも、1000 トークンの入力を処理するコストは同じです。そのため、API 呼び出し段階では安心して高次元を選択できます。実際のコスト差は、主に下流のストレージおよび検索フェーズで発生します。
Q12: エンベッドの失敗やレート制限への対処法は?
本番環境で text-embedding-v4 を呼び出す際は、以下の堅牢化処理を推奨します:
- リトライメカニズム:5xx エラーに対して指数バックオフを用いたリトライを実装する(3 回推奨)
- レート制限への対応:429 エラーを監視し、発生した場合は並行数を下げるか、接続チャネルを切り替える
- バッチサイズ:1 回のリクエストにつき最大 25 テキストまで。それを超える場合は自動的にバッチ分割する
- タイムアウト設定:長文エンベッドの場合はタイムアウトを 60 秒以上に設定する
- フォールバック案:予備のモデル(v3 1024 次元など)を構成し、バックアップとして利用する
九、まとめ:text-embedding-v4 ベクトル次元選定の核心ポイント
本稿を振り返り、text-embedding-v4 の 8 つのベクトル次元に関する核心ポイントをまとめます:
- text-embedding-v4 は Qwen3-Embedding シリーズの商用フラッグシップであり、MTEB 71.58 / CMTEB 71.99 と、日中バイリンガル環境でトップクラスの性能を誇ります。
- 8 つの次元数は本質的に Matryoshka 技術の産物であり、先頭 N 次元を切り取って使用しても品質低下を制御可能です。
- 1024 次元がデフォルトの推奨値であり、精度とコストのバランスが最適です。
- 2048 次元は究極の精度が必要なシナリオ向けで、1024 次元と比較して CMTEB Retrieval が 1 ポイント向上します。
- 256~512 次元は中規模かつコスト重視のシナリオ向けで、多くの RAG システムにおける実戦的なスイートスポットです。
- 64~128 次元はエッジデバイスや極限のストレージ環境向けであり、再現率の低下を十分にテストする必要があります。
- 次元数の選択は一度きりの決定ではありません。業務テストデータで検証してから最終決定することを強く推奨します。
- 他モデルから v4 へ移行する際は、次元数が一致するバージョンを選択することでスムーズに切り替えられます。
🎯 最終アドバイス:新規プロジェクトでエンベッドモデルを選定中であれば、まずは text-embedding-v4 + 1024 次元 を起点にしてください。業務で再現率が極めて重要な場合は、2048 次元に引き上げ、Reranker を併用しましょう。APIYI(apiyi.com)プラットフォーム経由での接続を推奨します。統一された OpenAI 互換インターフェース、便利な次元数切り替え、完全なドキュメントが提供されており、エンジニアリングコストを大幅に削減し、チームが API への適応ではなく業務の最適化に注力できるようになります。
ベクトルエンベッド技術は急速に進化しています。OpenAI の固定次元時代から、text-embedding-v4 が MRL を 8 つの公式次元として実装した現在、開発者はかつてない柔軟性を手に入れました。ベクトル次元の本質と選定戦略をマスターすることは、RAG、セマンティック検索、レコメンドシステムを構築するすべてのチームにとって必須のスキルです。
著者:APIYI 技術チーム | AI 大規模言語モデルの実装に注目。その他の技術コンテンツは APIYI(apiyi.com)をご覧ください。