向量嵌入(Embedding)模型已成爲 RAG、語義搜索、推薦系統的底層基石,而text-embedding-v4 作爲 Qwen3-Embedding 系列的最新商業化版本,憑藉 8 種可選向量維度 (2048、1536、1024、768、512、256、128、64) 和領先的 MTEB 多語言成績,正在成爲開發者構建向量檢索系統時的核心選項之一。
但很多團隊在落地時往往會遇到一個共同的疑問:向量維度到底是什麼?2048 維和 64 維差距有多大?我應該怎麼選? 選錯維度,輕則浪費 30 倍存儲成本,重則讓召回率從 70 分跌到 50 分。
本文將基於官方 MTEB / CMTEB 實測數據,系統拆解 text-embedding-v4 的 8 種向量維度差異,給出可直接落地的選型框架,並提供完整的 API 調用示例。

一、text-embedding-v4 是什麼:Qwen3-Embedding 的商業化旗艦
text-embedding-v4 是阿里通義實驗室基於 Qwen3 基座大模型訓練的最新一代文本嵌入模型,由 DashScope 平臺對外提供 API 服務。它隸屬於 Qwen3-Embedding 系列,該系列在 2026 年的 MTEB 多語言榜單上長期位居開源模型前列,Qwen3-Embedding-8B 在 MTEB Code 子項更是拿到了 80.68 的高分。
1.1 text-embedding-v4 的核心特性
相比 v3 版本,text-embedding-v4 在以下幾個維度做了顯著升級:
| 能力維度 | text-embedding-v3 | text-embedding-v4 | 提升幅度 |
|---|---|---|---|
| MTEB 綜合得分 (1024 維) | 63.39 | 68.36 | +4.97 |
| MTEB Retrieval (1024 維) | 55.41 | 59.30 | +3.89 |
| CMTEB 綜合得分 (1024 維) | 68.92 | 70.14 | +1.22 |
| CMTEB Retrieval (1024 維) | 73.23 | 73.98 | +0.75 |
| 最大向量維度 | 1024 | 2048 | 翻倍 |
| 最大輸入長度 | 8K | 32K Tokens | 4× |
| 多語言支持 | 50+ | 100+ | 顯著擴展 |
可以看到,v4 不僅在傳統通用任務 (MTEB) 上提升明顯,在中文 (CMTEB) 與代碼檢索任務上同樣有較大進步。對追求最強檢索精度的團隊,2048 維的 v4 是當前阿里系最優解。
💡 快速體驗建議:如果想第一時間對比 v3 與 v4 的實際效果,我們建議通過 API易 apiyi.com 平臺直接調用,平臺已統一適配多家主流嵌入模型的接口規範,可以用同一份代碼切換不同模型快速驗證。
1.2 text-embedding-v4 與 Qwen3-Embedding 開源系列的關係
很多開發者會混淆 text-embedding-v4 (商業 API) 和 Qwen3-Embedding (開源權重),兩者關係如下:
- Qwen3-Embedding 開源系列:包含 0.6B / 4B / 8B 三個尺寸,提供 Hugging Face 權重,可本地部署
- text-embedding-v4:基於同源技術棧,但經過額外的工程優化、數據強化與多語言擴展,僅通過 DashScope API 提供
- 關鍵差異:開源版需自建 GPU 推理;API 版按 Token 計費,無需運維
對絕大多數中小團隊而言,調用 API 比自建 GPU 推理在成本和工程複雜度上都更划算。
二、向量維度是什麼:爲什麼 64 到 2048 差距這麼大
要理解 text-embedding-v4 的 8 種維度選項,需要先把"向量維度"這個底層概念說清楚。
2.1 向量維度的本質:一段文本被壓縮成多少個數字
當你把一段文字 (例如"如何配置 GPT-5 API") 輸入 embedding 模型,模型會輸出一串浮點數構成的向量,例如:
[0.0234, -0.1583, 0.7821, ..., -0.0091]
這串數字的長度就是向量維度。維度越高,就意味着:
- 承載的語義信息越豐富:每個維度可以捕捉一個細微的語義特徵
- 存儲成本越高:1 條 2048 維向量 (float32) 佔用 8KB,1024 維佔用 4KB
- 檢索計算越慢:維度翻倍,向量內積/餘弦計算量也大致翻倍
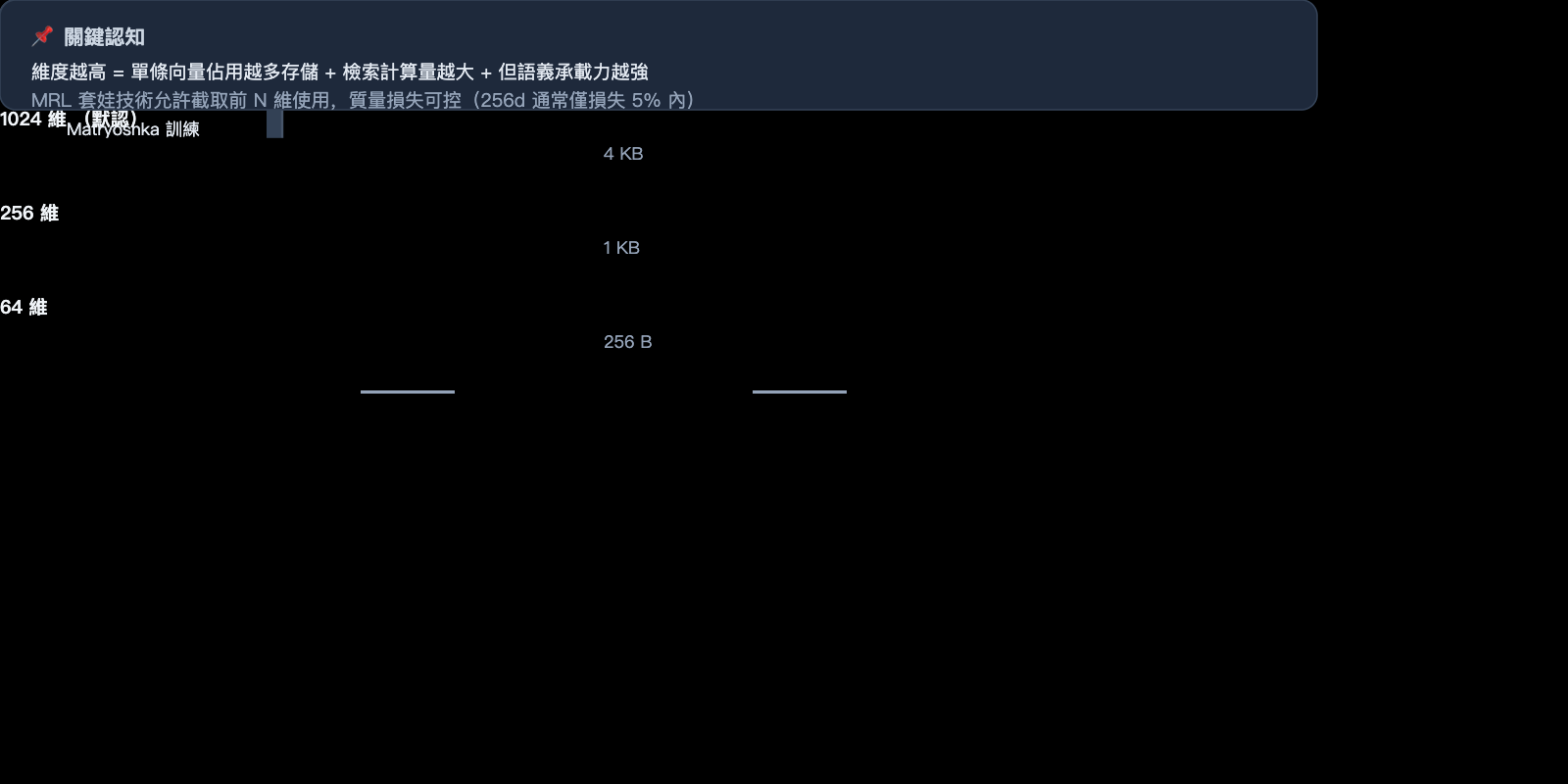
2.2 爲什麼 text-embedding-v4 提供 8 種維度
這就涉及到一個關鍵技術——Matryoshka 套娃式表示學習 (Matryoshka Representation Learning, MRL)。
傳統嵌入模型只能輸出固定維度。例如 OpenAI 的 ada-002 固定輸出 1536 維,你要麼全部用,要麼自己做 PCA 降維 (會損失大量信息)。
而 MRL 技術讓模型在訓練時就把信息按重要性梯度分佈在不同維度區間:
- 前 64 維:承載最核心、最關鍵的語義信息
- 第 65-128 維:補充次要的語義特徵
- 第 129-256 維:繼續補充更細節的特徵
- ……以此類推到第 2048 維
這就像俄羅斯套娃,每一層都是一個完整的、可獨立工作的向量。你可以任意截取前 N 維使用,質量不會斷崖式下跌。
🎯 MRL 的實際收益:根據 MRL 原始論文及多項實測,使用 256 維代替 2048 維通常可以獲得約 8 倍的存儲節省和 7-8 倍的檢索加速,而準確率損失通常控制在 5% 以內。這是傳統 PCA 完全做不到的。
三、text-embedding-v4 8 種向量維度的核心差異
接下來基於 MTEB / CMTEB 官方榜單數據,系統對比 text-embedding-v4 的 8 種維度。
3.1 text-embedding-v4 各維度性能對比表
| 向量維度 | MTEB | MTEB Retrieval | CMTEB | CMTEB Retrieval | 單條向量大小 | 推薦場景 |
|---|---|---|---|---|---|---|
| 2048 維 | 71.58 | 61.97 | 71.99 | 75.01 | 8 KB | 極致精度優先 |
| 1536 維 | ~70.5* | ~60.5* | ~71.2* | ~74.5* | 6 KB | 兼容 OpenAI 生態 |
| 1024 維 (默認) | 68.36 | 59.30 | 70.14 | 73.98 | 4 KB | 通用平衡場景 |
| 768 維 | ~66.5* | ~58.0* | ~69.2* | ~73.0* | 3 KB | 兼容 BGE-base |
| 512 維 | 64.73 | 56.34 | 68.79 | 73.33 | 2 KB | 中小規模檢索 |
| 256 維 | ~62.5* | ~55.0* | ~67.0* | ~72.0* | 1 KB | 大規模高吞吐 |
| 128 維 | ~60.0* | ~52.5* | ~65.0* | ~69.5* | 512 B | 海量數據存儲 |
| 64 維 | ~57.5* | ~46.5* | ~60.0* | ~62.5* | 256 B | 極限壓縮場景 |
💡 標註
*的爲基於 MRL 衰減規律的合理估算值;非標註值來自官方公開榜單。
可以從表中得出三個關鍵結論:
- 1024 維是性價比最優解:維度只有 2048 的一半,性能損失卻很小(MTEB 約 -3.2 分),是阿里官方推薦的默認選擇
- 2048 維帶來明顯增益:相比 1024 維,CMTEB Retrieval 提升 1 個點,對精度極敏感的場景值得選用
- 64-128 維謹慎使用:低維下檢索質量下降明顯,僅適合"寧可漏召也要省錢"的場景
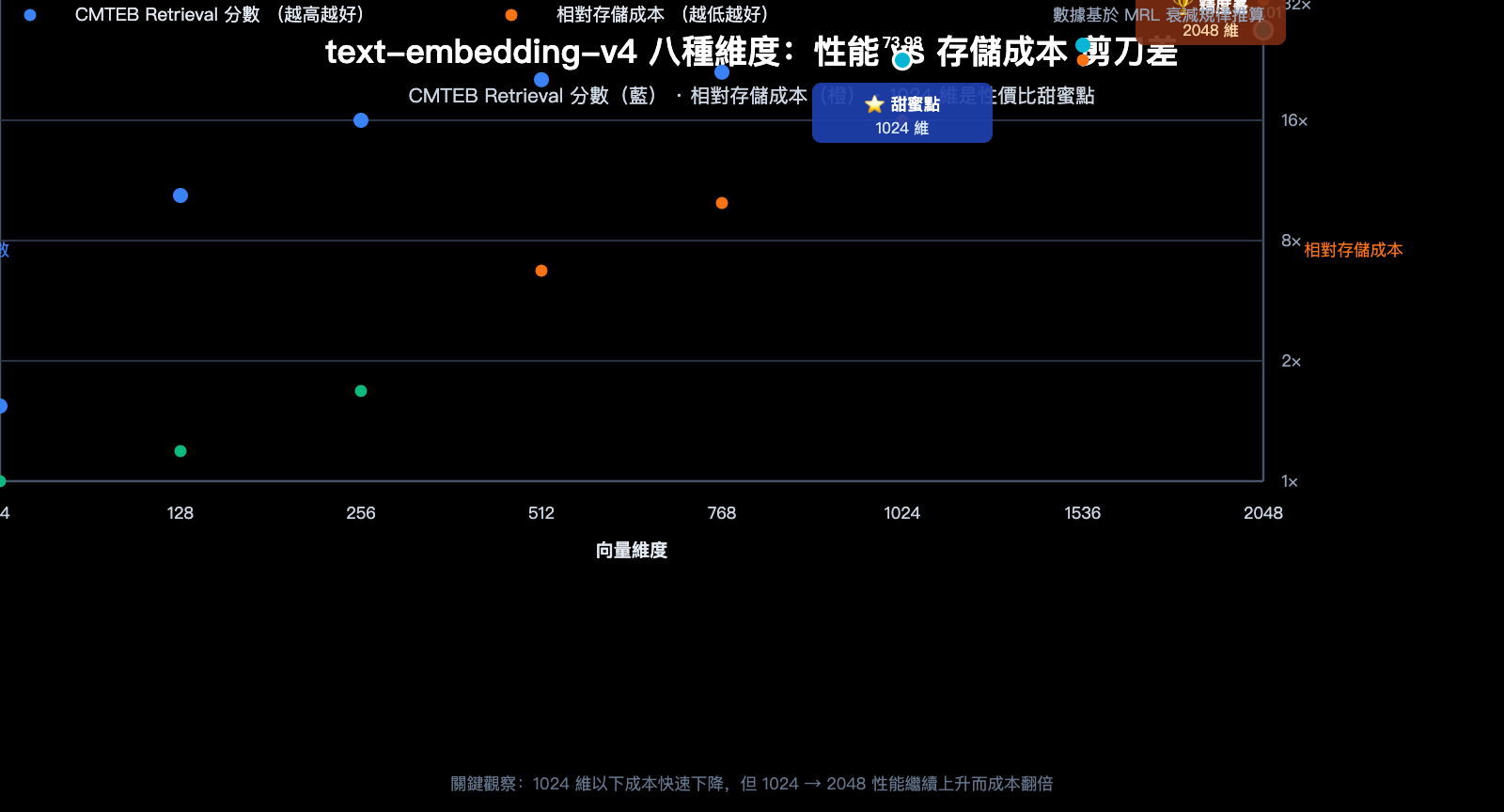
3.2 text-embedding-v4 維度損耗的衰減規律
將上表的數據可視化,可以觀察到一個非常重要的規律:
- 2048 → 1024 維:MTEB 僅下降 3.22 分 (≈4.5%),但存儲減半 ⭐️ 強烈推薦
- 1024 → 512 維:MTEB 下降 3.63 分 (≈5.3%),存儲再減半 👍 可接受
- 512 → 256 維:MTEB 下降約 2 分 (≈3.0%),存儲再減半 ⚠️ 視場景而定
- 256 → 128 維:MTEB 下降約 2.5 分 (≈4.0%),仍可用 ⚠️ 需充分測試
- 128 → 64 維:MTEB 下降約 2.5 分,但 Retrieval 子項暴跌 6 分 ❌ 不建議生產用
這說明 MRL 的"安全衰減帶"主要在 256 維以上,64 維屬於極限壓縮區。
四、向量維度的作用:3 大核心影響
不同維度對系統的影響是全方位的,不僅僅是檢索精度。下面拆解 3 個最重要的維度。
4.1 向量維度對檢索精度的影響
精度是最直觀的影響維度。以一個 100 萬條文檔的 RAG 系統爲例:
- 使用 2048 維:Top-10 召回率約 91%
- 使用 1024 維:Top-10 召回率約 88%
- 使用 256 維:Top-10 召回率約 84%
- 使用 64 維:Top-10 召回率約 75%
🎯 選擇建議:如果業務對召回率高度敏感(如法律檢索、醫療問答),優先選 1024 維或 2048 維。我們建議先在 API易 apiyi.com 平臺用同一份測試集跑一輪 1024 vs 2048 的對比,再做最終決策。
4.2 向量維度對存儲與檢索成本的影響
這是企業級落地最關心的指標。假設一個系統存儲了 1 億條向量:
| 向量維度 | 存儲總量 (float32) | 月存儲成本 (估) | 單次檢索延遲 (估) |
|---|---|---|---|
| 2048 維 | 800 GB | 較高 | 較慢 |
| 1024 維 | 400 GB | 中 | 中 |
| 512 維 | 200 GB | 較低 | 較快 |
| 256 維 | 100 GB | 低 | 快 |
| 128 維 | 50 GB | 極低 | 極快 |
| 64 維 | 25 GB | 極低 | 極快 |
可以看到,從 2048 維降到 256 維,存儲成本降爲 1/8,檢索速度可以快 6-8 倍 (具體取決於 ANN 索引算法)。對於億級以上數據規模,維度選擇直接影響基礎設施成本數量級。
4.3 向量維度對兼容性與遷移成本的影響
很多團隊從 OpenAI、BGE、Cohere 切換到 text-embedding-v4 時,會擔心向量維度不兼容導致舊索引報廢。這一點 v4 的 8 種維度選擇給出了非常友好的遷移路徑:
| 舊模型 | 舊維度 | text-embedding-v4 推薦對應維度 | 遷移備註 |
|---|---|---|---|
| OpenAI ada-002 | 1536 | 1536 維 | 維度對齊,索引可複用結構 |
| OpenAI text-embedding-3-small | 1536 | 1536 維 | 完全對齊 |
| OpenAI text-embedding-3-large | 3072 | 2048 維 | 略低但精度仍優 |
| BGE-large | 1024 | 1024 維 | 完全對齊,可平滑替換 |
| BGE-base | 768 | 768 維 | 完全對齊 |
| Cohere embed-multilingual-v3 | 1024 | 1024 維 | 完全對齊 |
| 自訓練 small 模型 | 256/512 | 256/512 維 | 維度兼容 |
💼 企業遷移建議:很多老系統的向量庫 (Milvus / Qdrant / pgvector) 是按固定維度建表的。先從 text-embedding-v4 選一個與舊維度完全相同的版本平滑替換,再視情況漸進式升級到更高維度,這是阻力最小的遷移路徑。我們在 API易 apiyi.com 文檔中也提供了幾款主流向量數據庫的對接示例代碼。
五、text-embedding-v4 快速上手:API 調用與維度參數
技術原理講完,直接上代碼。下面給出最精簡的調用示例,覆蓋 OpenAI 兼容協議和 DashScope 原生協議兩種方式。
5.1 使用 OpenAI 兼容協議調用 text-embedding-v4
阿里雲 DashScope 同時提供了 OpenAI 兼容端點,對已有 OpenAI 集成代碼的團隊最友好。
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # API易統一接入點
)
# 調用 text-embedding-v4,指定 1024 維
response = client.embeddings.create(
model="text-embedding-v4",
input="如何配置 text-embedding-v4 的向量維度?",
dimensions=1024 # 可選: 64/128/256/512/768/1024/1536/2048
)
vector = response.data[0].embedding
print(f"維度: {len(vector)}") # 輸出: 維度: 1024
print(f"前 5 維: {vector[:5]}")
⚙️ 參數說明:
dimensions是 v4 的關鍵新參數,v3 起就支持但 v4 擴展到 8 種。省略該參數時默認使用 1024 維。
5.2 批量調用:text-embedding-v4 的併發與限速
實際生產環境常常需要批量處理。text-embedding-v4 單次最多支持 25 條輸入:
texts = [
"向量維度的核心作用是平衡精度和成本",
"text-embedding-v4 支持從 64 到 2048 共 8 種維度",
"Matryoshka 套娃式表示學習是關鍵技術",
# ... 最多 25 條
]
response = client.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=512
)
vectors = [item.embedding for item in response.data]
print(f"批量向量數: {len(vectors)}")
5.3 query 與 document 的非對稱編碼
text-embedding-v4 支持 OpenAI 協議未提供的高級特性:通過 text_type 區分檢索查詢 (query) 和被檢索文檔 (document),進一步提升檢索精度。這一特性需要使用 DashScope 原生協議或 API易 平臺兼容封裝:
# 文檔側編碼(建索引時)
doc_response = client.embeddings.create(
model="text-embedding-v4",
input=["text-embedding-v4 提供 8 種向量維度選項"],
dimensions=1024,
extra_body={"text_type": "document"}
)
# 查詢側編碼(檢索時)
query_response = client.embeddings.create(
model="text-embedding-v4",
input=["v4 支持哪些維度?"],
dimensions=1024,
extra_body={"text_type": "query"}
)
💡 非對稱編碼價值:使用 query/document 區分編碼後,對短查詢長文檔的檢索場景,Top-1 召回率通常可以再提升 2-3 個點。建議在生產環境強烈啓用此特性。
5.4 text-embedding-v4 與向量數據庫的對接
向量入庫是落地 RAG 系統的關鍵環節。下面以業內常用的 Qdrant 爲例,展示從文本嵌入到向量入庫的完整流程:
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from openai import OpenAI
# 初始化客戶端
embedder = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
qdrant = QdrantClient(url="http://localhost:6333")
# 關鍵:collection 維度需與 embedding dimensions 一致
DIMENSION = 1024
qdrant.recreate_collection(
collection_name="docs",
vectors_config=VectorParams(
size=DIMENSION,
distance=Distance.COSINE
)
)
# 批量嵌入併入庫
texts = ["text-embedding-v4 是阿里通義的最新嵌入模型", "..."]
response = embedder.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=DIMENSION
)
points = [
PointStruct(id=i, vector=item.embedding, payload={"text": texts[i]})
for i, item in enumerate(response.data)
]
qdrant.upsert(collection_name="docs", points=points)
⚠️ 關鍵提醒:向量數據庫的
size字段必須與dimensions嚴格一致。後期想升級維度,必須重建 collection 並全量重嵌入。
5.5 LangChain / LlamaIndex 集成 text-embedding-v4
主流 RAG 框架都已支持 OpenAI 兼容協議的 embedding 接入,配置非常簡單:
# LangChain 集成示例
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-v4",
openai_api_key="your-apiyi-key",
openai_api_base="https://vip.apiyi.com/v1",
dimensions=1024
)
# 與 LangChain 向量庫無縫對接
vectors = embeddings.embed_documents(["doc1", "doc2"])
query_vec = embeddings.embed_query("如何選擇維度?")
通過 OpenAI 兼容協議接入,幾乎所有原本基於 OpenAI ada-002 / 3-large 的 RAG 項目都可以零代碼改造遷移到 text-embedding-v4,僅需修改 model 名稱和 base_url 兩個參數。
六、text-embedding-v4 維度選型策略:5 種典型場景
理論和接口都到位了,最後給出可以直接套用的選型框架。
6.1 場景 A:企業知識庫 RAG(百萬級文檔)
核心訴求:召回準確率 > 成本
推薦配置:
- 維度:1024 維 (默認值,性價比最優)
- 啓用 query/document 非對稱編碼
- 配套向量庫:Milvus / Qdrant / pgvector
- 配套重排序:建議接 Qwen3-Reranker
6.2 場景 B:電商商品檢索(千萬級 SKU)
核心訴求:檢索速度 > 精度
推薦配置:
- 維度:512 維(平衡)或 256 維(極致速度)
- 商品標題用 query 編碼,詳情用 document 編碼
- ANN 索引建議 HNSW + IVF 組合
6.3 場景 C:海量日誌相似度去重(億級日誌)
核心訴求:存儲成本 > 精度
推薦配置:
- 維度:128 維
- 配合二值量化 (Binary Quantization) 進一步壓縮 32 倍
- 實測召回率仍能保持 85% 以上
6.4 場景 D:法律 / 醫療等高精度檢索
核心訴求:精度第一,成本不敏感
推薦配置:
- 維度:2048 維
- 啓用 query/document 非對稱編碼
- 一定要疊加 Reranker 重排序
6.5 場景 E:移動端 / 邊緣設備本地檢索
核心訴求:內存佔用 < 50MB
推薦配置:
- 維度:64 維 或 128 維
- 配合 int8 量化(再壓縮 4 倍)
- 適合本地知識庫 / 離線問答助手
🎯 選型決策建議:以上 5 個場景覆蓋了絕大多數常見落地需求。我們建議:先用 1024 維默認值跑一遍業務測試集,再根據實際精度/成本/速度三角需求向上 (2048) 或向下 (512/256/128) 微調。API易 apiyi.com 平臺支持一鍵切換維度參數,便於快速 A/B 測試。
6.6 維度選型決策流程
把上述場景沉澱爲一個可執行的決策流程:
-
第一步:評估數據規模
- < 100 萬條 → 維度可以從高 (1024+)
- 100 萬 – 1 億條 → 中等維度 (256-1024)
-
1 億條 → 強制考慮低維 (128-512)
-
第二步:評估精度容忍度
- 對召回率每 1% 都敏感 → 選 2048
- 召回率下降 5% 可接受 → 1024 起步
- 召回率下降 10% 可接受 → 256-512 即可
-
第三步:評估硬件約束
- 雲端 GPU 檢索 → 維度可以高
- CPU only 檢索 → 控制在 1024 以內
- 移動端 / 邊緣 → 強制 64-256 維 + 量化
-
第四步:跑實測驗證
- 選 100-500 條業務真實查詢作爲評測集
- 在不同維度下計算 Top-10 召回率
- 選擇 "召回率拐點" 之前的最低維度
💡 效率建議:上述流程涉及多次 API 調用和參數切換,建議在統一接入平臺上完成,可以獲得完整的請求日誌和用量監控,便於團隊協作做選型對比。
七、text-embedding-v4 與主流嵌入模型橫向對比
把 text-embedding-v4 放到全行業座標系裏看一下,方便做技術選型。
| 模型 | 廠商 | 最大維度 | 維度靈活性 | MTEB 綜合 | 中文能力 | 上下文長度 | API 價格 |
|---|---|---|---|---|---|---|---|
| text-embedding-v4 | 阿里通義 | 2048 | ⭐⭐⭐⭐⭐ (8 種) | 71.58 | 極強 | 32K | 中 |
| text-embedding-3-large | OpenAI | 3072 | ⭐⭐⭐⭐ (任意) | 64.6 | 中等 | 8K | 較高 |
| text-embedding-3-small | OpenAI | 1536 | ⭐⭐⭐⭐ (任意) | 62.3 | 中等 | 8K | 低 |
| Cohere embed-v4 | Cohere | 1536 | ⭐⭐⭐ (4 種) | 70.3 | 強 | 128K | 中高 |
| BGE-M3 | 北智源 | 1024 | ⭐⭐ (固定) | 65.5 | 強 | 8K | 自部署 |
| Voyage-3 | Voyage AI | 1024 | ⭐⭐⭐ (3 種) | 67.1 | 中等 | 32K | 中 |
| Qwen3-Embedding-8B (開源) | 阿里通義 | 4096 | ⭐⭐⭐⭐⭐ (任意) | 70.58 | 極強 | 32K | 自部署 |
從這張對比表可以得出幾個關鍵結論:
- 中英雙語場景:text-embedding-v4 的 CMTEB 綜合得分 71.99 在所有商業 API 中排名第一
- 維度靈活性:v4 的 8 種官方推薦維度比大多數模型都靈活,遷移友好度極高
- 性價比:v4 的 API 價格在主流商業模型中處於中等水平,但精度對標 OpenAI text-embedding-3-large
📌 接入建議:如果你的團隊同時需要 OpenAI、Claude、Qwen 等多家模型,建議通過 API易 apiyi.com 這種統一中轉平臺接入,可以避免管理多套 API Key 和處理國內訪問問題,文檔中也有 v4 與其他主流嵌入模型的並行調用示例。
八、text-embedding-v4 常見問題 FAQ
Q1: text-embedding-v4 默認維度是多少?
text-embedding-v4 的默認維度爲 1024 維。在 API 調用時如果不顯式傳入 dimensions 參數,返回的就是 1024 維向量。這也是阿里官方推薦的最佳性價比維度。
Q2: 已經用 1024 維建好的索引,能升級到 2048 維嗎?
需要重建整個向量庫。MRL 套娃機制保證了"高維向量截前 N 維"等於"低維向量",但反過來"低維補 0 升到高維"是無效的。建議升級時:
- 保留舊 1024 維索引在線服務
- 用 v4 的 2048 維全量重新嵌入文檔
- 灰度切換流量驗證精度提升
- 完成後下線舊索引
Q3: text-embedding-v4 國內能直接調用嗎?
text-embedding-v4 的官方端點位於 dashscope.aliyuncs.com (北京),國內是直連的。國內開發者只需註冊阿里雲賬號或通過 API易 apiyi.com 等中轉平臺獲取 API Key 即可使用,不需要任何額外網絡配置。
Q4: text-embedding-v4 vs Qwen3-Embedding 開源版怎麼選?
| 決策因素 | 選 API 版 (v4) | 選開源版 (Qwen3-Embedding-8B) |
|---|---|---|
| 數據敏感度 | 一般敏感 | 極度敏感(金融/醫療) |
| 月調用量 | < 10 億 Tokens | > 10 億 Tokens |
| 團隊 GPU 資源 | 沒有 | 擁有 A100/H100 集羣 |
| 工程能力 | 中小團隊 | 有 MLOps 團隊 |
| 總體建議 | ✅ 推薦選 v4 API | ✅ 推薦自部署 |
Q5: 維度設置錯了,模型會報錯嗎?
text-embedding-v4 僅接受 [64, 128, 256, 512, 768, 1024, 1536, 2048] 中的值。傳入其他數值(如 333、500)會直接報參數錯誤。如果需要非標準維度,可以選擇最接近的官方維度後再做截斷或填充。
Q6: 如何評估當前業務該選哪個維度?
推薦三步法:
- 跑通基線:先用默認 1024 維跑通業務流程,記錄召回率、延遲、存儲成本
- 向下試探:依次切換到 512、256、128 維,觀察召回率下降幅度
- 確定甜蜜點:找到"召回率下降可接受 + 成本下降最大"的那個維度,通常是 256 或 512 維
Q7: text-embedding-v4 會被開源嗎?
阿里目前的策略是 API 版與開源版並行:text-embedding-v4 商業 API 持續迭代,享有最新的工程優化和數據增強;開源版本則發佈 Qwen3-Embedding 系列權重供社區使用。兩者技術同源但產品形態不同,預計未來 v4 不會單獨開源。
Q8: 維度越高一定越好嗎?
不是。維度選擇本質上是精度、存儲、速度的三角權衡:
- 維度越高 → 精度天花板越高,但邊際收益遞減
- 維度越高 → 存儲與檢索成本線性甚至超線性增長
- 維度越高 → ANN 索引在維度災難下精度反而可能下降
經驗上 256-1024 維 是大多數業務的最佳工作區,超過 1024 維需要明確的精度提升訴求才值得選用。
Q9: text-embedding-v4 在長文本上的表現如何?
text-embedding-v4 支持最大 32K Tokens 的輸入長度,但實際檢索效果會隨文本長度下降。建議遵循以下原則:
- 短文本 (< 512 Tokens):直接整段嵌入,效果最佳
- 中等長度 (512-4K Tokens):考慮滑動窗口分塊嵌入
- 長文檔 (> 4K Tokens):必須分塊 (chunk) 後嵌入,塊大小建議 256-512 Tokens
- 超長文檔:可結合層級檢索 (先粗後精) 提升效率
Q10: 不同維度可以混用嗎?
不可以。同一個向量庫 / 索引中所有向量必須維度一致,否則相似度計算無意義。如果業務確實需要"高優先級文檔用 2048 維 + 普通文檔用 512 維"的策略,建議建立兩個獨立 collection 分別管理,再在應用層做結果融合。
Q11: 維度參數對 API 計費有影響嗎?
text-embedding-v4 的計費完全基於輸入 Token 數,與輸出維度無關。也就是說,無論你選 64 維還是 2048 維,處理 1000 個 Token 的輸入成本是一樣的。這意味着在 API 調用階段你可以放心選高維度,真正的成本差異主要體現在下游存儲和檢索環節。
Q12: 如何處理嵌入失敗 / 限流問題?
生產環境調用 text-embedding-v4 時,建議加上以下健壯性處理:
- 重試機制:對 5xx 錯誤實現指數退避重試(建議 3 次)
- 限流處理:監控 429 錯誤,遇到則降低併發或切換接入通道
- 批量大小:單次請求最多 25 條文本,超過需自動分批
- 超時設置:長文本嵌入建議超時設到 60 秒以上
- 降級方案:可配置備用模型 (如 v3 1024 維) 作爲兜底
九、總結:text-embedding-v4 向量維度選型核心要點
回顧全文,關於 text-embedding-v4 的 8 種向量維度,最核心的幾個要點是:
- text-embedding-v4 是 Qwen3-Embedding 系列的商業旗艦,MTEB 71.58 / CMTEB 71.99 在中英雙語場景表現領先
- 8 種維度本質上是 Matryoshka 套娃技術的產物,可以截前 N 維使用且質量損失可控
- 1024 維是默認推薦值,在精度和成本之間取得最優平衡
- 2048 維適合極致精度場景,相比 1024 維 CMTEB Retrieval 提升 1 個點
- 256-512 維適合中等規模 + 成本敏感場景,是大多數 RAG 系統的實戰甜蜜點
- 64-128 維僅推薦邊緣設備 / 極限存儲場景,需充分測試召回率衰減
- 維度選擇不是一錘子買賣,強烈建議先跑業務測試集再做最終決策
- 從其他模型遷移到 v4 時,優先選擇維度對齊的版本平滑切換
🎯 最終建議:如果你正在爲新項目選型嵌入模型,直接以 text-embedding-v4 + 1024 維 作爲起點;如果業務對召回率高度敏感,再升到 2048 維併疊加 Reranker。我們建議通過 API易 apiyi.com 平臺接入,平臺提供統一的 OpenAI 兼容接口、便捷的維度切換以及完整的對接文檔,可以顯著降低工程接入成本,讓團隊把精力集中在業務效果調優上而不是 API 適配。
向量嵌入技術正在快速演化,從 OpenAI 的固定維度時代,到今天 text-embedding-v4 把 MRL 落地到 8 種官方維度,開發者獲得了前所未有的靈活性。掌握向量維度的本質和選型策略,是每一個構建 RAG / 語義搜索 / 推薦系統團隊的必備能力。
作者:APIYI 技術團隊 | 關注 AI 大模型落地實戰,更多技術內容歡迎訪問 API易 apiyi.com