Model embedding telah menjadi fondasi utama bagi RAG, pencarian semantik, dan sistem rekomendasi. Sebagai versi komersial terbaru dari seri Qwen3-Embedding, text-embedding-v4 kini menjadi salah satu pilihan utama bagi pengembang dalam membangun sistem pencarian vektor, berkat 8 pilihan dimensi vektor (2048, 1536, 1024, 768, 512, 256, 128, 64) dan performa multibahasa MTEB yang unggul.
Namun, banyak tim sering menghadapi pertanyaan umum saat implementasi: Apa sebenarnya dimensi vektor itu? Seberapa besar perbedaan antara 2048 dimensi dan 64 dimensi? Bagaimana cara memilihnya? Salah memilih dimensi bisa berakibat fatal, mulai dari pemborosan biaya penyimpanan hingga 30 kali lipat, hingga penurunan tingkat recall dari 70 poin menjadi 50 poin.
Artikel ini akan membedah perbedaan 8 dimensi vektor text-embedding-v4 berdasarkan data pengujian resmi MTEB/CMTEB, memberikan kerangka kerja pemilihan yang praktis, serta menyediakan contoh pemanggilan API yang lengkap.
<!-- 维度标签 -->
<text x="0" y="-122" font-family="Arial, sans-serif" font-size="11" fill="#ffffff" text-anchor="middle" font-weight="600">2048</text>
<text x="-105" y="-105" font-family="Arial, sans-serif" font-size="10" fill="#e2e8f0" text-anchor="middle">1536</text>
<text x="105" y="-90" font-family="Arial, sans-serif" font-size="10" fill="#e2e8f0" text-anchor="middle">1024</text>
<text x="-90" y="80" font-family="Arial, sans-serif" font-size="10" fill="#cbd5e1" text-anchor="middle">768</text>
<text x="78" y="80" font-family="Arial, sans-serif" font-size="10" fill="#cbd5e1" text-anchor="middle">512</text>
<text x="-50" y="105" font-family="Arial, sans-serif" font-size="10" fill="#cbd5e1" text-anchor="middle">256</text>
<text x="55" y="-50" font-family="Arial, sans-serif" font-size="10" fill="#cbd5e1" text-anchor="middle">128</text>
<text x="0" y="3" font-family="Arial, sans-serif" font-size="9" fill="#ffffff" text-anchor="middle" font-weight="700">64</text>
<text x="0" y="-160" font-family="Arial, sans-serif" font-size="14" fill="#ffffff" text-anchor="middle" font-weight="600">Matryoshka 8 dimensi</text>
<text x="110" y="85" font-family="Arial, sans-serif" font-size="12" fill="#e2e8f0" text-anchor="middle">MTEB (2048d)</text>
<text x="110" y="115" font-family="Arial, sans-serif" font-size="28" fill="#ffffff" text-anchor="middle" font-weight="700">71.58</text>
<text x="110" y="148" font-family="Arial, sans-serif" font-size="12" fill="#e2e8f0" text-anchor="middle">CMTEB (2048d)</text>
<text x="110" y="178" font-family="Arial, sans-serif" font-size="28" fill="#ffffff" text-anchor="middle" font-weight="700">71.99</text>
<text x="110" y="205" font-family="Arial, sans-serif" font-size="11" fill="#f1f5f9" text-anchor="middle">Unggul dalam dwibahasa Mandarin dan Inggris</text>
一、Apa itu text-embedding-v4: Andalan Komersial Qwen3-Embedding
text-embedding-v4 adalah model embedding teks generasi terbaru yang dilatih oleh Alibaba Tongyi Lab berdasarkan Model Bahasa Besar Qwen3, dan disediakan sebagai layanan API melalui platform DashScope. Model ini merupakan bagian dari seri Qwen3-Embedding, yang secara konsisten menempati peringkat teratas di antara model sumber terbuka dalam papan peringkat multibahasa MTEB tahun 2026, di mana Qwen3-Embedding-8B bahkan mencetak skor tinggi 80,68 pada sub-kategori MTEB Code.
1.1 Fitur Utama text-embedding-v4
Dibandingkan dengan versi v3, text-embedding-v4 telah mengalami peningkatan signifikan dalam beberapa aspek:
| Dimensi Kemampuan | text-embedding-v3 | text-embedding-v4 | Peningkatan |
|---|---|---|---|
| Skor Komprehensif MTEB (1024 dim) | 63,39 | 68,36 | +4,97 |
| MTEB Retrieval (1024 dim) | 55,41 | 59,30 | +3,89 |
| Skor Komprehensif CMTEB (1024 dim) | 68,92 | 70,14 | +1,22 |
| CMTEB Retrieval (1024 dim) | 73,23 | 73,98 | +0,75 |
| Dimensi Vektor Maksimum | 1024 | 2048 | 2× lipat |
| Panjang Input Maksimum | 8K | 32K Token | 4× |
| Dukungan Multibahasa | 50+ | 100+ | Ekspansi signifikan |
Dapat dilihat bahwa v4 tidak hanya menunjukkan peningkatan nyata pada tugas umum (MTEB), tetapi juga kemajuan besar dalam tugas pencarian bahasa Mandarin (CMTEB) dan kode. Bagi tim yang mengejar akurasi pencarian tertinggi, v4 dengan 2048 dimensi adalah solusi terbaik dari ekosistem Alibaba saat ini.
💡 Saran Uji Coba Cepat: Jika Anda ingin segera membandingkan hasil nyata antara v3 dan v4, kami sarankan untuk memanggilnya langsung melalui platform APIYI apiyi.com. Platform ini telah mengintegrasikan spesifikasi antarmuka dari berbagai model embedding utama, sehingga Anda dapat menggunakan kode yang sama untuk beralih antar model guna melakukan verifikasi dengan cepat.
1.2 Hubungan antara text-embedding-v4 dan seri sumber terbuka Qwen3-Embedding
Banyak pengembang bingung membedakan antara text-embedding-v4 (API komersial) dan Qwen3-Embedding (bobot sumber terbuka). Berikut adalah hubungannya:
- Seri Sumber Terbuka Qwen3-Embedding: Mencakup ukuran 0,6B / 4B / 8B, menyediakan bobot Hugging Face yang dapat diterapkan secara lokal.
- text-embedding-v4: Berbasis pada tumpukan teknologi yang sama, namun telah melalui optimasi teknik tambahan, penguatan data, dan ekspansi multibahasa, serta hanya tersedia melalui API DashScope.
- Perbedaan Kunci: Versi sumber terbuka memerlukan pembangunan inferensi GPU sendiri; versi API dikenakan biaya per Token dan tidak memerlukan pemeliharaan operasional.
Bagi sebagian besar tim kecil dan menengah, menggunakan API jauh lebih hemat biaya dan tidak terlalu rumit secara teknis dibandingkan membangun inferensi GPU sendiri.
二、Apa itu dimensi vektor: Mengapa perbedaan antara 64 dan 2048 begitu besar
Untuk memahami 8 opsi dimensi pada text-embedding-v4, kita perlu menjelaskan konsep dasar "dimensi vektor" terlebih dahulu.
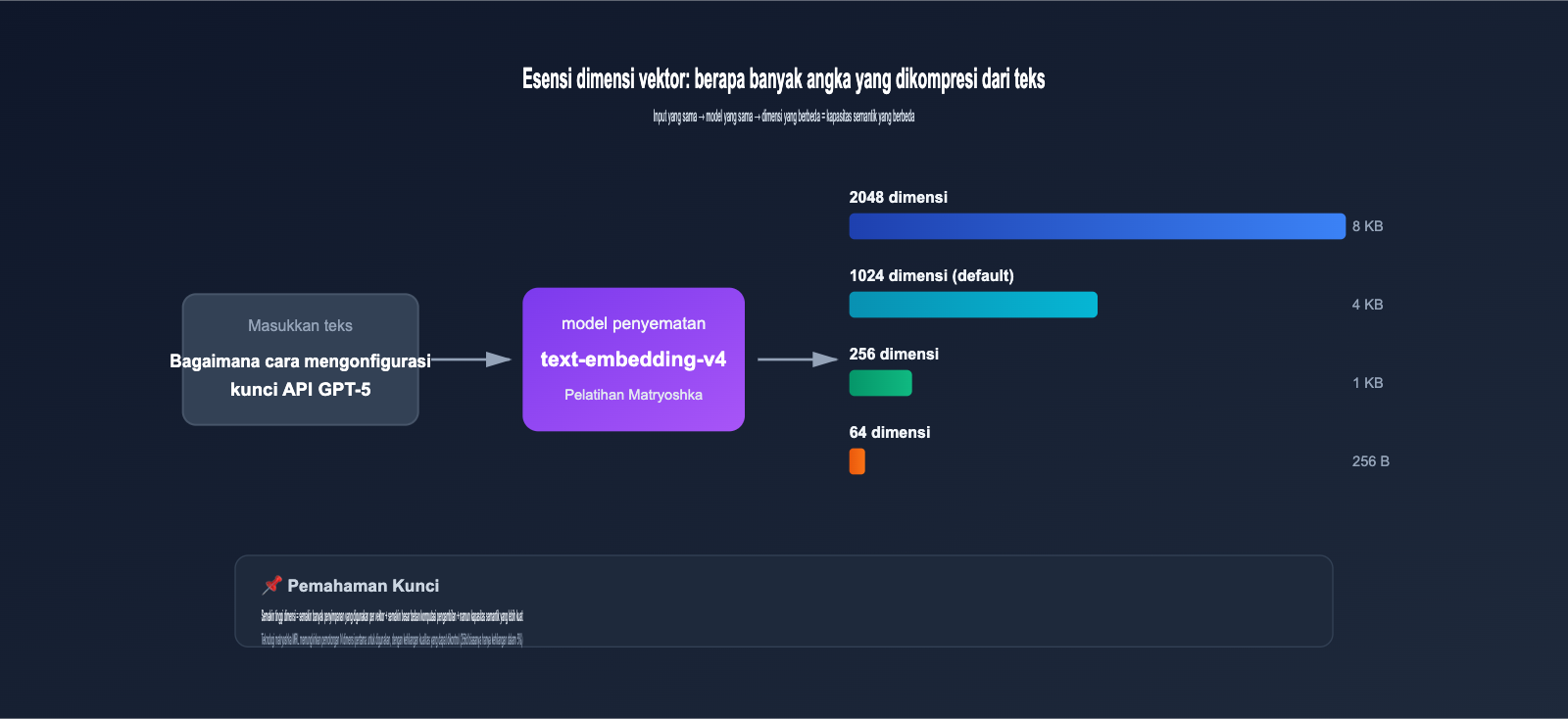
2.1 Esensi dimensi vektor: Berapa banyak angka yang dihasilkan dari kompresi teks
Saat Anda memasukkan teks (misalnya "bagaimana cara mengonfigurasi API GPT-5") ke dalam model embedding, model akan mengeluarkan deretan vektor yang terdiri dari angka floating-point, contohnya:
[0.0234, -0.1583, 0.7821, ..., -0.0091]
Panjang dari deretan angka inilah yang disebut dimensi vektor. Semakin tinggi dimensinya, berarti:
- Informasi semantik yang dibawa semakin kaya: Setiap dimensi dapat menangkap fitur semantik yang halus.
- Biaya penyimpanan lebih tinggi: 1 vektor 2048 dimensi (float32) memakan 8KB, sedangkan 1024 dimensi memakan 4KB.
- Perhitungan pencarian lebih lambat: Jika dimensi berlipat ganda, beban perhitungan inner product atau cosine similarity juga kurang lebih akan berlipat ganda.
2.2 Mengapa text-embedding-v4 menyediakan 8 opsi dimensi
Hal ini berkaitan dengan teknologi kunci—Matryoshka Representation Learning (MRL).
Model embedding tradisional hanya bisa mengeluarkan dimensi tetap. Misalnya, ada-002 dari OpenAI secara tetap mengeluarkan 1536 dimensi; Anda harus menggunakan semuanya atau melakukan reduksi dimensi PCA sendiri (yang akan menghilangkan banyak informasi).
Namun, teknologi MRL memungkinkan model untuk mendistribusikan informasi berdasarkan gradien kepentingan ke dalam interval dimensi yang berbeda selama pelatihan:
- 64 dimensi pertama: Membawa informasi semantik yang paling inti dan krusial.
- Dimensi ke 65-128: Melengkapi fitur semantik sekunder.
- Dimensi ke 129-256: Melengkapi fitur yang lebih detail.
- …dan seterusnya hingga dimensi ke 2048.
Ini seperti boneka Matryoshka, di mana setiap lapisan adalah vektor yang lengkap dan dapat bekerja secara independen. Anda dapat mengambil N dimensi pertama untuk digunakan, dan kualitasnya tidak akan turun drastis.
🎯 Manfaat nyata MRL: Berdasarkan makalah asli MRL dan berbagai pengujian, menggunakan 256 dimensi sebagai pengganti 2048 biasanya dapat menghemat penyimpanan sekitar 8 kali lipat dan mempercepat pencarian 7-8 kali lipat, dengan penurunan akurasi yang biasanya terkendali di bawah 5%. Ini adalah hal yang tidak bisa dilakukan oleh PCA tradisional.
III. Perbedaan inti dari 8 dimensi vektor text-embedding-v4
Selanjutnya, mari kita bandingkan secara sistematis 8 dimensi text-embedding-v4 berdasarkan data papan peringkat resmi MTEB/CMTEB.
3.1 Tabel perbandingan performa dimensi text-embedding-v4
| Dimensi Vektor | MTEB | MTEB Retrieval | CMTEB | CMTEB Retrieval | Ukuran Vektor Tunggal | Skenario Rekomendasi |
|---|---|---|---|---|---|---|
| 2048 Dimensi | 71.58 | 61.97 | 71.99 | 75.01 | 8 KB | Prioritas akurasi maksimal |
| 1536 Dimensi | ~70.5* | ~60.5* | ~71.2* | ~74.5* | 6 KB | Kompatibel dengan ekosistem OpenAI |
| 1024 Dimensi (Default) | 68.36 | 59.30 | 70.14 | 73.98 | 4 KB | Skenario keseimbangan umum |
| 768 Dimensi | ~66.5* | ~58.0* | ~69.2* | ~73.0* | 3 KB | Kompatibel dengan BGE-base |
| 512 Dimensi | 64.73 | 56.34 | 68.79 | 73.33 | 2 KB | Pencarian skala kecil-menengah |
| 256 Dimensi | ~62.5* | ~55.0* | ~67.0* | ~72.0* | 1 KB | Skala besar, throughput tinggi |
| 128 Dimensi | ~60.0* | ~52.5* | ~65.0* | ~69.5* | 512 B | Penyimpanan data masif |
| 64 Dimensi | ~57.5* | ~46.5* | ~60.0* | ~62.5* | 256 B | Skenario kompresi ekstrem |
💡 Nilai yang ditandai dengan
*adalah estimasi wajar berdasarkan pola peluruhan MRL; nilai tanpa tanda berasal dari papan peringkat resmi.
Kita bisa menarik tiga kesimpulan utama dari tabel tersebut:
- 1024 dimensi adalah solusi dengan efisiensi biaya terbaik: Dimensinya hanya setengah dari 2048, namun penurunan performanya sangat kecil (MTEB sekitar -3,2 poin), dan ini adalah pilihan default yang direkomendasikan secara resmi oleh Alibaba.
- 2048 dimensi memberikan peningkatan yang jelas: Dibandingkan dengan 1024 dimensi, CMTEB Retrieval meningkat 1 poin, layak dipilih untuk skenario yang sangat sensitif terhadap akurasi.
- Gunakan 64-128 dimensi dengan hati-hati: Kualitas pencarian menurun drastis pada dimensi rendah, hanya cocok untuk skenario di mana "lebih baik ada data yang terlewat daripada biaya membengkak".
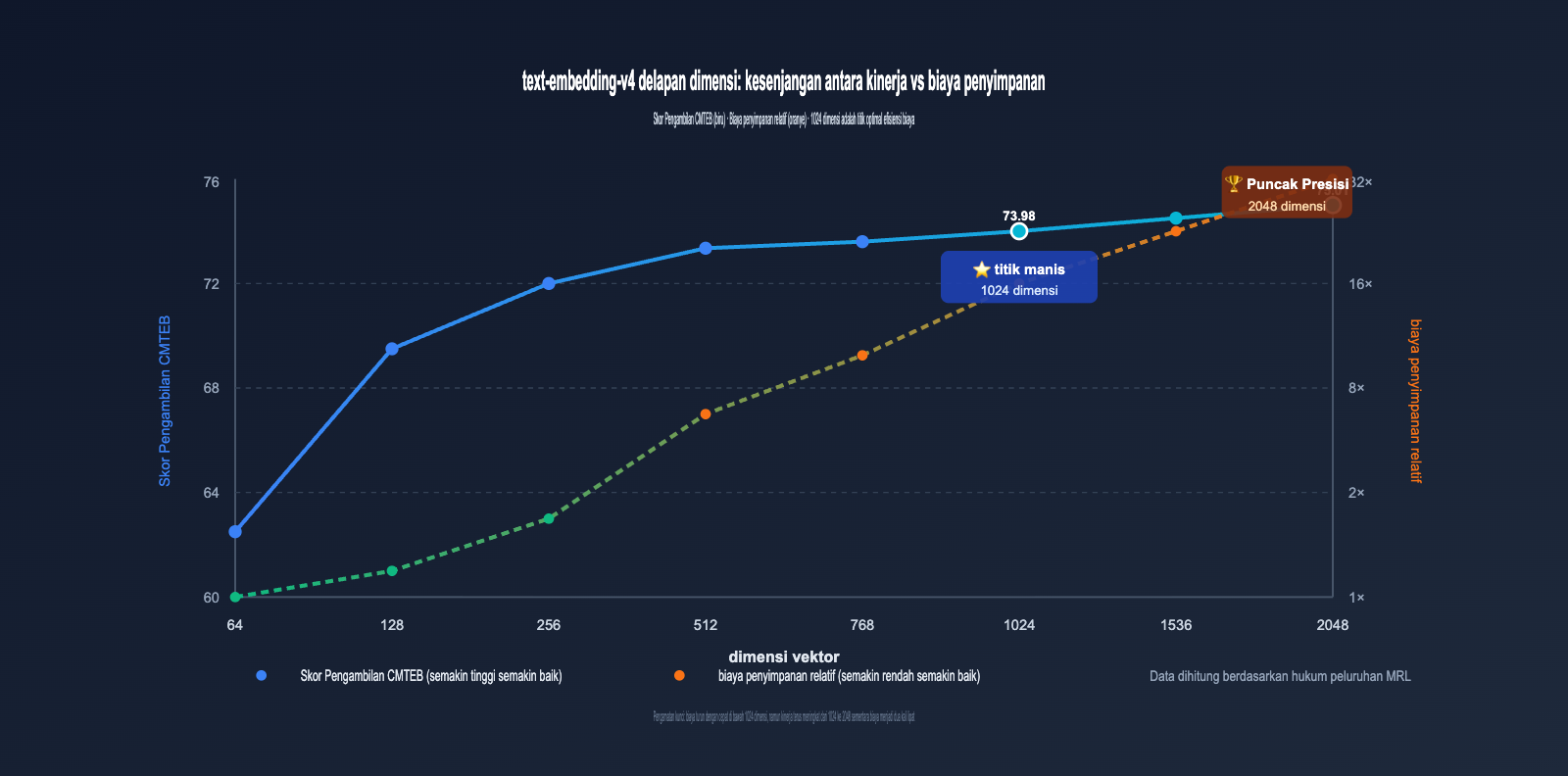
3.2 Pola peluruhan kehilangan dimensi text-embedding-v4
Dengan memvisualisasikan data di atas, kita dapat mengamati pola yang sangat penting:
- 2048 → 1024 dimensi: MTEB hanya turun 3,22 poin (≈4,5%), namun penyimpanan berkurang setengahnya ⭐️ Sangat direkomendasikan.
- 1024 → 512 dimensi: MTEB turun 3,63 poin (≈5,3%), penyimpanan berkurang setengahnya lagi 👍 Dapat diterima.
- 512 → 256 dimensi: MTEB turun sekitar 2 poin (≈3,0%), penyimpanan berkurang setengahnya lagi ⚠️ Tergantung skenario.
- 256 → 128 dimensi: MTEB turun sekitar 2,5 poin (≈4,0%), masih dapat digunakan ⚠️ Perlu pengujian menyeluruh.
- 128 → 64 dimensi: MTEB turun sekitar 2,5 poin, namun sub-item Retrieval anjlok 6 poin ❌ Tidak disarankan untuk penggunaan produksi.
Ini menunjukkan bahwa "zona peluruhan aman" MRL utamanya berada di atas 256 dimensi, sedangkan 64 dimensi termasuk dalam zona kompresi ekstrem.
Empat. Peran Dimensi Vektor: 3 Dampak Utama
Dampak dimensi yang berbeda terhadap sistem bersifat menyeluruh, bukan sekadar akurasi pencarian. Berikut adalah bedah dari 3 dimensi terpenting.
4.1 Dampak Dimensi Vektor terhadap Akurasi Pencarian
Akurasi adalah dimensi dampak yang paling intuitif. Sebagai contoh, dalam sistem RAG dengan 1 juta dokumen:
- Menggunakan 2048 dimensi: Recall Top-10 sekitar 91%
- Menggunakan 1024 dimensi: Recall Top-10 sekitar 88%
- Menggunakan 256 dimensi: Recall Top-10 sekitar 84%
- Menggunakan 64 dimensi: Recall Top-10 sekitar 75%
🎯 Saran Pemilihan: Jika bisnis Anda sangat sensitif terhadap recall (seperti pencarian hukum atau tanya jawab medis), prioritaskan 1024 atau 2048 dimensi. Kami menyarankan untuk menjalankan satu putaran perbandingan 1024 vs 2048 menggunakan set data uji yang sama di platform APIYI (apiyi.com) sebelum mengambil keputusan akhir.
4.2 Dampak Dimensi Vektor terhadap Biaya Penyimpanan dan Pencarian
Ini adalah metrik yang paling diperhatikan dalam implementasi tingkat perusahaan. Asumsikan sebuah sistem menyimpan 100 juta vektor:
| Dimensi Vektor | Total Penyimpanan (float32) | Biaya Penyimpanan Bulanan (Est.) | Latensi Pencarian Tunggal (Est.) |
|---|---|---|---|
| 2048 Dimensi | 800 GB | Tinggi | Lambat |
| 1024 Dimensi | 400 GB | Sedang | Sedang |
| 512 Dimensi | 200 GB | Rendah | Cepat |
| 256 Dimensi | 100 GB | Rendah | Cepat |
| 128 Dimensi | 50 GB | Sangat Rendah | Sangat Cepat |
| 64 Dimensi | 25 GB | Sangat Rendah | Sangat Cepat |
Dapat dilihat bahwa dengan menurunkan dari 2048 ke 256 dimensi, biaya penyimpanan turun menjadi 1/8, dan kecepatan pencarian bisa meningkat 6-8 kali lipat (tergantung pada algoritma indeks ANN). Untuk skala data di atas ratusan juta, pemilihan dimensi secara langsung memengaruhi besaran biaya infrastruktur.
4.3 Dampak Dimensi Vektor terhadap Kompatibilitas dan Biaya Migrasi
Banyak tim yang khawatir bahwa beralih dari OpenAI, BGE, atau Cohere ke text-embedding-v4 akan menyebabkan indeks lama tidak kompatibel. 8 pilihan dimensi pada v4 memberikan jalur migrasi yang sangat ramah:
| Model Lama | Dimensi Lama | Dimensi Rekomendasi text-embedding-v4 | Catatan Migrasi |
|---|---|---|---|
| OpenAI ada-002 | 1536 | 1536 dimensi | Dimensi selaras, struktur indeks dapat digunakan kembali |
| OpenAI text-embedding-3-small | 1536 | 1536 dimensi | Selaras sepenuhnya |
| OpenAI text-embedding-3-large | 3072 | 2048 dimensi | Sedikit lebih rendah namun akurasi tetap unggul |
| BGE-large | 1024 | 1024 dimensi | Selaras sepenuhnya, dapat diganti dengan mulus |
| BGE-base | 768 | 768 dimensi | Selaras sepenuhnya |
| Cohere embed-multilingual-v3 | 1024 | 1024 dimensi | Selaras sepenuhnya |
| Model small buatan sendiri | 256/512 | 256/512 dimensi | Kompatibel secara dimensi |
💼 Saran Migrasi Perusahaan: Banyak basis data vektor sistem lama (Milvus / Qdrant / pgvector) dibuat berdasarkan dimensi tetap. Mulailah dengan memilih versi
text-embedding-v4yang memiliki dimensi sama persis dengan versi lama untuk penggantian yang mulus, lalu tingkatkan secara bertahap ke dimensi lebih tinggi sesuai kebutuhan. Ini adalah jalur migrasi dengan hambatan paling minim. Kami juga menyediakan contoh kode integrasi untuk beberapa basis data vektor utama dalam dokumentasi APIYI (apiyi.com).
Lima. Memulai Cepat text-embedding-v4: Pemanggilan API dan Parameter Dimensi
Setelah membahas prinsip teknisnya, mari langsung ke kode. Berikut adalah contoh pemanggilan paling ringkas, mencakup protokol kompatibilitas OpenAI dan protokol asli DashScope.
5.1 Menggunakan Protokol Kompatibilitas OpenAI untuk Memanggil text-embedding-v4
Aliyun DashScope juga menyediakan endpoint yang kompatibel dengan OpenAI, yang paling ramah bagi tim yang sudah memiliki kode integrasi OpenAI.
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # Titik akses terpadu APIYI
)
# Memanggil text-embedding-v4, tentukan 1024 dimensi
response = client.embeddings.create(
model="text-embedding-v4",
input="Bagaimana cara mengonfigurasi dimensi vektor text-embedding-v4?",
dimensions=1024 # Opsional: 64/128/256/512/768/1024/1536/2048
)
vector = response.data[0].embedding
print(f"Dimensi: {len(vector)}") # Output: Dimensi: 1024
print(f"5 dimensi pertama: {vector[:5]}")
⚙️ Penjelasan Parameter:
dimensionsadalah parameter baru yang krusial pada v4. Parameter ini sudah didukung sejak v3, namun pada v4 diperluas hingga 8 pilihan. Jika parameter ini dilewati, secara default akan menggunakan 1024 dimensi.
5.2 Pemanggilan Batch: Konkurensi dan Pembatasan Kecepatan text-embedding-v4
Dalam lingkungan produksi yang sebenarnya, pemrosesan batch sering kali diperlukan. text-embedding-v4 mendukung maksimal 25 input dalam satu kali pemanggilan:
texts = [
"Peran inti dimensi vektor adalah menyeimbangkan akurasi dan biaya",
"text-embedding-v4 mendukung 8 jenis dimensi mulai dari 64 hingga 2048",
"Pembelajaran representasi Matryoshka adalah teknologi kunci",
# ... maksimal 25 item
]
response = client.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=512
)
vectors = [item.embedding for item in response.data]
print(f"Jumlah vektor batch: {len(vectors)}")
5.3 Pengodean Asimetris untuk query dan document
text-embedding-v4 mendukung fitur tingkat lanjut yang tidak disediakan oleh protokol OpenAI: membedakan antara kueri pencarian (query) dan dokumen yang dicari (document) melalui text_type untuk lebih meningkatkan akurasi pencarian. Fitur ini memerlukan penggunaan protokol asli DashScope atau enkapsulasi kompatibilitas platform APIYI:
# Pengodean sisi dokumen (saat membuat indeks)
doc_response = client.embeddings.create(
model="text-embedding-v4",
input=["text-embedding-v4 menyediakan 8 pilihan dimensi vektor"],
dimensions=1024,
extra_body={"text_type": "document"}
)
# Pengodean sisi kueri (saat melakukan pencarian)
query_response = client.embeddings.create(
model="text-embedding-v4",
input=["Dimensi apa saja yang didukung v4?"],
dimensions=1024,
extra_body={"text_type": "query"}
)
💡 Nilai Pengodean Asimetris: Setelah menggunakan pengodean yang membedakan query/document, untuk skenario pencarian kueri pendek pada dokumen panjang, recall Top-1 biasanya dapat meningkat sebesar 2-3 poin. Kami menyarankan untuk mengaktifkan fitur ini di lingkungan produksi.
5.4 Integrasi text-embedding-v4 dengan Basis Data Vektor
Penyimpanan vektor adalah langkah kunci dalam mengimplementasikan sistem RAG. Berikut adalah contoh menggunakan Qdrant, yang umum digunakan di industri, untuk menunjukkan alur lengkap dari embedding teks hingga penyimpanan vektor:
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from openai import OpenAI
# Inisialisasi klien
embedder = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
qdrant = QdrantClient(url="http://localhost:6333")
# Kunci: dimensi collection harus konsisten dengan dimensi embedding
DIMENSION = 1024
qdrant.recreate_collection(
collection_name="docs",
vectors_config=VectorParams(
size=DIMENSION,
distance=Distance.COSINE
)
)
# Embedding batch dan penyimpanan
texts = ["text-embedding-v4 adalah model embedding terbaru dari Alibaba Tongyi", "..."]
response = embedder.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=DIMENSION
)
points = [
PointStruct(id=i, vector=item.embedding, payload={"text": texts[i]})
for i, item in enumerate(response.data)
]
qdrant.upsert(collection_name="docs", points=points)
⚠️ Peringatan Penting: Bidang
sizepada basis data vektor harus benar-benar sama dengandimensions. Jika ingin meningkatkan dimensi di kemudian hari, Anda harus membuat ulang collection dan melakukan re-embedding secara penuh.
5.5 Integrasi LangChain / LlamaIndex dengan text-embedding-v4
Kerangka kerja RAG utama telah mendukung akses embedding protokol kompatibilitas OpenAI, konfigurasinya sangat sederhana:
# Contoh integrasi LangChain
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-v4",
openai_api_key="your-apiyi-key",
openai_api_base="https://vip.apiyi.com/v1",
dimensions=1024
)
# Integrasi mulus dengan basis data vektor LangChain
vectors = embeddings.embed_documents(["doc1", "doc2"])
query_vec = embeddings.embed_query("Bagaimana cara memilih dimensi?")
Melalui akses protokol kompatibilitas OpenAI, hampir semua proyek RAG yang awalnya berbasis OpenAI ada-002 / 3-large dapat bermigrasi ke text-embedding-v4 tanpa mengubah kode, hanya perlu mengubah dua parameter: nama model dan base_url.
VI. Strategi Pemilihan Dimensi text-embedding-v4: 5 Skenario Tipikal
Setelah memahami teori dan antarmukanya, berikut adalah kerangka kerja pemilihan yang bisa langsung Anda terapkan.
6.1 Skenario A: RAG Basis Pengetahuan Perusahaan (Jutaan Dokumen)
Kebutuhan Utama: Akurasi recall > Biaya
Konfigurasi Rekomendasi:
- Dimensi: 1024 dimensi (nilai default, rasio harga-performa terbaik)
- Aktifkan pengodean asimetris query/document
- Vector database pendukung: Milvus / Qdrant / pgvector
- Reranking pendukung: Disarankan menggunakan Qwen3-Reranker
6.2 Skenario B: Pencarian Produk E-commerce (Puluhan Juta SKU)
Kebutuhan Utama: Kecepatan pencarian > Presisi
Konfigurasi Rekomendasi:
- Dimensi: 512 dimensi (seimbang) atau 256 dimensi (kecepatan maksimal)
- Gunakan pengodean query untuk judul produk dan pengodean document untuk detail produk
- Indeks ANN disarankan menggunakan kombinasi HNSW + IVF
6.3 Skenario C: Deduplikasi Kemiripan Log dalam Jumlah Besar (Ratusan Juta Log)
Kebutuhan Utama: Biaya penyimpanan > Presisi
Konfigurasi Rekomendasi:
- Dimensi: 128 dimensi
- Gunakan Binary Quantization untuk kompresi tambahan hingga 32 kali lipat
- Hasil pengujian menunjukkan tingkat recall tetap terjaga di atas 85%
6.4 Skenario D: Pencarian Presisi Tinggi (Hukum / Medis)
Kebutuhan Utama: Presisi adalah prioritas, biaya tidak sensitif
Konfigurasi Rekomendasi:
- Dimensi: 2048 dimensi
- Aktifkan pengodean asimetris query/document
- Wajib menambahkan Reranker untuk pemeringkatan ulang
6.5 Skenario E: Pencarian Lokal di Perangkat Seluler / Edge
Kebutuhan Utama: Penggunaan memori < 50MB
Konfigurasi Rekomendasi:
- Dimensi: 64 dimensi atau 128 dimensi
- Gunakan kuantisasi int8 (kompresi tambahan 4 kali lipat)
- Cocok untuk basis pengetahuan lokal / asisten tanya jawab luring
🎯 Saran Pengambilan Keputusan: Kelima skenario di atas mencakup sebagian besar kebutuhan implementasi umum. Kami menyarankan: jalankan set pengujian bisnis Anda dengan nilai default 1024 dimensi terlebih dahulu, kemudian sesuaikan ke atas (2048) atau ke bawah (512/256/128) berdasarkan kebutuhan segitiga presisi/biaya/kecepatan Anda. Platform APIYI apiyi.com mendukung peralihan parameter dimensi dalam satu klik, sehingga memudahkan pengujian A/B yang cepat.
6.6 Alur Keputusan Pemilihan Dimensi
Berikut adalah alur keputusan yang dapat dieksekusi berdasarkan skenario di atas:
-
Langkah 1: Evaluasi Skala Data
- < 1 juta data → Dimensi bisa tinggi (1024+)
- 1 juta – 100 juta data → Dimensi menengah (256-1024)
-
100 juta data → Wajib mempertimbangkan dimensi rendah (128-512)
-
Langkah 2: Evaluasi Toleransi Presisi
- Sensitif terhadap setiap 1% tingkat recall → Pilih 2048
- Penurunan recall 5% masih bisa diterima → Mulai dari 1024
- Penurunan recall 10% masih bisa diterima → 256-512 sudah cukup
-
Langkah 3: Evaluasi Kendala Perangkat Keras
- Pencarian GPU di cloud → Dimensi bisa tinggi
- Pencarian hanya CPU → Batasi di bawah 1024
- Seluler / Edge → Wajib 64-256 dimensi + kuantisasi
-
Langkah 4: Jalankan Validasi Pengujian
- Pilih 100-500 kueri bisnis nyata sebagai set evaluasi
- Hitung tingkat recall Top-10 pada dimensi yang berbeda
- Pilih dimensi terendah sebelum mencapai "titik belok" recall
💡 Saran Efisiensi: Alur di atas melibatkan banyak pemanggilan API dan peralihan parameter. Disarankan untuk menyelesaikannya pada platform integrasi terpadu agar Anda mendapatkan log permintaan dan pemantauan penggunaan yang lengkap, sehingga memudahkan kolaborasi tim dalam melakukan perbandingan pemilihan model.
VII. Perbandingan Horizontal text-embedding-v4 dengan Model Embedding Utama
Mari kita lihat posisi text-embedding-v4 dalam koordinat industri untuk memudahkan pemilihan teknologi.
| Model | Vendor | Dimensi Maks | Fleksibilitas Dimensi | MTEB Komprehensif | Kemampuan Bahasa Mandarin | Panjang Konteks | Harga API |
|---|---|---|---|---|---|---|---|
| text-embedding-v4 | Alibaba Tongyi | 2048 | ⭐⭐⭐⭐⭐ (8 jenis) | 71.58 | Sangat Kuat | 32K | Menengah |
| text-embedding-3-large | OpenAI | 3072 | ⭐⭐⭐⭐ (bebas) | 64.6 | Menengah | 8K | Tinggi |
| text-embedding-3-small | OpenAI | 1536 | ⭐⭐⭐⭐ (bebas) | 62.3 | Menengah | 8K | Rendah |
| Cohere embed-v4 | Cohere | 1536 | ⭐⭐⭐ (4 jenis) | 70.3 | Kuat | 128K | Menengah-Tinggi |
| BGE-M3 | BAAI | 1024 | ⭐⭐ (tetap) | 65.5 | Kuat | 8K | Swakelola |
| Voyage-3 | Voyage AI | 1024 | ⭐⭐⭐ (3 jenis) | 67.1 | Menengah | 32K | Menengah |
| Qwen3-Embedding-8B (Open Source) | Alibaba Tongyi | 4096 | ⭐⭐⭐⭐⭐ (bebas) | 70.58 | Sangat Kuat | 32K | Swakelola |
Dari tabel perbandingan ini, kita bisa menarik beberapa kesimpulan utama:
- Skenario Bilingual (Mandarin-Inggris): Skor komprehensif CMTEB dari text-embedding-v4 sebesar 71.99 menempati peringkat pertama di antara semua API komersial.
- Fleksibilitas Dimensi: 8 dimensi resmi yang direkomendasikan oleh v4 jauh lebih fleksibel dibandingkan kebanyakan model lain, sehingga sangat ramah untuk migrasi.
- Rasio Harga-Performa: Harga API v4 berada di tingkat menengah di antara model komersial utama, namun presisinya setara dengan OpenAI text-embedding-3-large.
📌 Saran Integrasi: Jika tim Anda perlu menggunakan berbagai model seperti OpenAI, Claude, dan Qwen secara bersamaan, disarankan untuk mengaksesnya melalui platform layanan proksi API terpadu seperti APIYI apiyi.com. Ini dapat menghindari pengelolaan banyak kunci API dan mengatasi masalah akses di dalam negeri. Dokumentasi kami juga menyertakan contoh pemanggilan paralel v4 dengan model embedding utama lainnya.
VIII. FAQ Pertanyaan Umum text-embedding-v4
Q1: Berapa dimensi default text-embedding-v4?
Dimensi default untuk text-embedding-v4 adalah 1024 dimensi. Jika Anda tidak menyertakan parameter dimensions saat melakukan pemanggilan model, sistem akan mengembalikan vektor 1024 dimensi. Ini juga merupakan dimensi yang direkomendasikan secara resmi oleh Alibaba karena keseimbangan biaya dan performa yang optimal.
Q2: Bisakah indeks yang sudah dibuat dengan 1024 dimensi ditingkatkan ke 2048 dimensi?
Anda perlu membangun ulang seluruh basis data vektor. Mekanisme MRL (Matryoshka Representation Learning) menjamin bahwa "N dimensi pertama dari vektor berdimensi tinggi" sama dengan "vektor berdimensi rendah", namun sebaliknya, "menambahkan angka 0 ke vektor berdimensi rendah untuk mencapai dimensi tinggi" tidak akan efektif. Saat melakukan peningkatan, disarankan untuk:
- Mempertahankan layanan indeks 1024 dimensi yang lama agar tetap online.
- Melakukan embedding ulang seluruh dokumen menggunakan v4 dengan 2048 dimensi.
- Melakukan traffic switching secara bertahap untuk memverifikasi peningkatan akurasi.
- Menonaktifkan indeks lama setelah proses selesai.
Q3: Apakah text-embedding-v4 bisa dipanggil langsung di Indonesia?
Endpoint resmi text-embedding-v4 berada di dashscope.aliyuncs.com (Beijing), dan koneksinya dapat diakses langsung dari Indonesia. Pengembang di Indonesia hanya perlu mendaftarkan akun Alibaba Cloud atau menggunakan platform layanan proksi API seperti APIYI (apiyi.com) untuk mendapatkan kunci API, tanpa memerlukan konfigurasi jaringan tambahan.
Q4: Bagaimana memilih antara text-embedding-v4 vs versi open-source Qwen3-Embedding?
| Faktor Keputusan | Pilih Versi API (v4) | Pilih Versi Open-source (Qwen3-Embedding-8B) |
|---|---|---|
| Sensitivitas Data | Sensitivitas umum | Sangat sensitif (Keuangan/Medis) |
| Volume Pemanggilan Bulanan | < 1 Miliar Token | > 1 Miliar Token |
| Sumber Daya GPU Tim | Tidak ada | Memiliki klaster A100/H100 |
| Kemampuan Engineering | Tim kecil/menengah | Memiliki tim MLOps |
| Saran Keseluruhan | ✅ Disarankan pilih API v4 | ✅ Disarankan deploy mandiri |
Q5: Apakah model akan error jika pengaturan dimensi salah?
text-embedding-v4 hanya menerima nilai dalam daftar [64, 128, 256, 512, 768, 1024, 1536, 2048]. Memasukkan nilai lain (seperti 333 atau 500) akan langsung menghasilkan error parameter. Jika Anda memerlukan dimensi non-standar, pilih dimensi resmi yang paling mendekati, lalu lakukan pemotongan (truncation) atau penambahan (padding) di sisi aplikasi.
Q6: Bagaimana cara mengevaluasi dimensi mana yang harus dipilih untuk bisnis saya?
Disarankan menggunakan metode tiga langkah:
- Jalankan Baseline: Gunakan dimensi default 1024 untuk menjalankan alur bisnis, catat tingkat recall, latensi, dan biaya penyimpanan.
- Uji Penurunan: Beralihlah secara bertahap ke dimensi 512, 256, dan 128, lalu amati seberapa besar penurunan tingkat recall.
- Tentukan Titik Optimal: Temukan dimensi di mana "penurunan recall masih dapat diterima + penurunan biaya paling maksimal", biasanya berada di angka 256 atau 512 dimensi.
Q7: Apakah text-embedding-v4 akan dirilis sebagai open-source?
Strategi Alibaba saat ini adalah menjalankan versi API dan open-source secara paralel: API komersial text-embedding-v4 terus diperbarui dan mendapatkan optimasi teknik serta peningkatan data terbaru; sementara versi open-source merilis bobot seri Qwen3-Embedding untuk digunakan komunitas. Keduanya memiliki sumber teknologi yang sama namun bentuk produk yang berbeda. Saat ini, v4 tidak direncanakan untuk dirilis sebagai open-source secara terpisah.
Q8: Apakah dimensi yang lebih tinggi selalu lebih baik?
Tidak. Pemilihan dimensi pada dasarnya adalah kompromi segitiga antara akurasi, penyimpanan, dan kecepatan:
- Semakin tinggi dimensi → Batas atas akurasi semakin tinggi, namun keuntungan marginal semakin berkurang.
- Semakin tinggi dimensi → Biaya penyimpanan dan pencarian meningkat secara linear atau bahkan super-linear.
- Semakin tinggi dimensi → Akurasi indeks ANN justru bisa menurun akibat "kutukan dimensi" (curse of dimensionality).
Berdasarkan pengalaman, 256-1024 dimensi adalah area kerja terbaik untuk sebagian besar bisnis. Di atas 1024 dimensi, Anda harus memiliki kebutuhan peningkatan akurasi yang sangat spesifik agar layak digunakan.
Q9: Bagaimana performa text-embedding-v4 pada teks panjang?
text-embedding-v4 mendukung panjang input hingga 32K Token, namun efek pencarian aktual akan menurun seiring bertambahnya panjang teks. Disarankan untuk mengikuti prinsip berikut:
- Teks Pendek (< 512 Token): Lakukan embedding langsung pada seluruh paragraf, hasilnya paling optimal.
- Panjang Sedang (512-4K Token): Pertimbangkan untuk menggunakan sliding window untuk pembagian blok (chunking).
- Dokumen Panjang (> 4K Token): Wajib melakukan pembagian blok (chunking) sebelum embedding, ukuran blok yang disarankan adalah 256-512 Token.
- Dokumen Sangat Panjang: Dapat dikombinasikan dengan pencarian hierarkis (kasar dulu, baru halus) untuk meningkatkan efisiensi.
Q10: Bisakah dimensi yang berbeda digunakan bersamaan?
Tidak bisa. Semua vektor dalam satu basis data/indeks vektor yang sama harus memiliki dimensi yang konsisten, jika tidak, perhitungan kemiripan tidak akan bermakna. Jika bisnis Anda benar-benar memerlukan strategi "dokumen prioritas tinggi menggunakan 2048 dimensi + dokumen biasa menggunakan 512 dimensi", disarankan untuk membuat dua koleksi terpisah dan melakukan penggabungan hasil di lapisan aplikasi.
Q11: Apakah parameter dimensi memengaruhi penagihan API?
Penagihan text-embedding-v4 sepenuhnya didasarkan pada jumlah Token input, tidak ada hubungannya dengan dimensi output. Artinya, baik Anda memilih 64 dimensi atau 2048 dimensi, biaya untuk memproses 1000 Token input tetap sama. Ini berarti Anda dapat dengan tenang memilih dimensi tinggi pada tahap pemanggilan API, karena perbedaan biaya yang sebenarnya terutama terletak pada tahap penyimpanan dan pencarian di hilir.
Q12: Bagaimana cara menangani kegagalan embedding / limitasi rate?
Saat memanggil text-embedding-v4 di lingkungan produksi, disarankan untuk menambahkan penanganan ketahanan berikut:
- Mekanisme Retry: Implementasikan exponential backoff retry untuk error 5xx (disarankan 3 kali).
- Penanganan Limitasi: Pantau error 429, jika terjadi, kurangi konkurensi atau beralih ke saluran akses lain.
- Ukuran Batch: Maksimal 25 teks per permintaan, jika lebih harus dipecah secara otomatis.
- Pengaturan Timeout: Untuk embedding teks panjang, disarankan mengatur timeout di atas 60 detik.
- Skema Cadangan: Konfigurasikan model cadangan (seperti v3 1024 dimensi) sebagai solusi darurat.
IX. Kesimpulan: Poin Utama Pemilihan Dimensi Vektor text-embedding-v4
Meninjau kembali seluruh artikel, berikut adalah poin-poin utama mengenai 8 dimensi vektor text-embedding-v4:
- text-embedding-v4 adalah unggulan komersial dari seri Qwen3-Embedding, dengan skor MTEB 71.58 / CMTEB 71.99 yang memimpin dalam skenario bahasa Mandarin-Inggris.
- 8 jenis dimensi pada dasarnya adalah produk dari teknologi Matryoshka, yang memungkinkan penggunaan N dimensi pertama dengan kehilangan kualitas yang terkontrol.
- 1024 dimensi adalah nilai rekomendasi default, yang mencapai keseimbangan optimal antara akurasi dan biaya.
- 2048 dimensi cocok untuk skenario akurasi ekstrem, memberikan peningkatan 1 poin pada CMTEB Retrieval dibandingkan 1024 dimensi.
- 256-512 dimensi cocok untuk skala menengah + skenario sensitif biaya, yang merupakan titik optimal praktis bagi sebagian besar sistem RAG.
- 64-128 dimensi hanya disarankan untuk perangkat edge / skenario penyimpanan ekstrem, dan memerlukan pengujian penuh terhadap penurunan tingkat recall.
- Pemilihan dimensi bukanlah keputusan sekali jadi, sangat disarankan untuk menjalankan set pengujian bisnis sebelum membuat keputusan akhir.
- Saat bermigrasi dari model lain ke v4, prioritaskan versi dengan dimensi yang selaras untuk transisi yang mulus.
🎯 Saran Akhir: Jika Anda sedang memilih model embedding untuk proyek baru, mulailah dengan text-embedding-v4 + 1024 dimensi sebagai titik awal. Jika bisnis Anda sangat sensitif terhadap tingkat recall, naikkan ke 2048 dimensi dan tambahkan Reranker. Kami menyarankan untuk mengakses melalui platform APIYI (apiyi.com) yang menyediakan antarmuka kompatibel dengan OpenAI, kemudahan perpindahan dimensi, serta dokumentasi integrasi lengkap. Hal ini dapat secara signifikan menurunkan biaya rekayasa, sehingga tim Anda dapat fokus pada optimasi hasil bisnis daripada adaptasi API.
Teknologi embedding vektor berkembang pesat, dari era dimensi tetap OpenAI hingga hari ini di mana text-embedding-v4 menghadirkan MRL ke dalam 8 dimensi resmi, memberikan fleksibilitas yang belum pernah ada sebelumnya bagi pengembang. Menguasai esensi dimensi vektor dan strategi pemilihan adalah kemampuan wajib bagi setiap tim yang membangun RAG / pencarian semantik / sistem rekomendasi.
Penulis: Tim Teknis APIYI | Fokus pada implementasi praktis model bahasa besar AI, untuk konten teknis lainnya silakan kunjungi APIYI apiyi.com