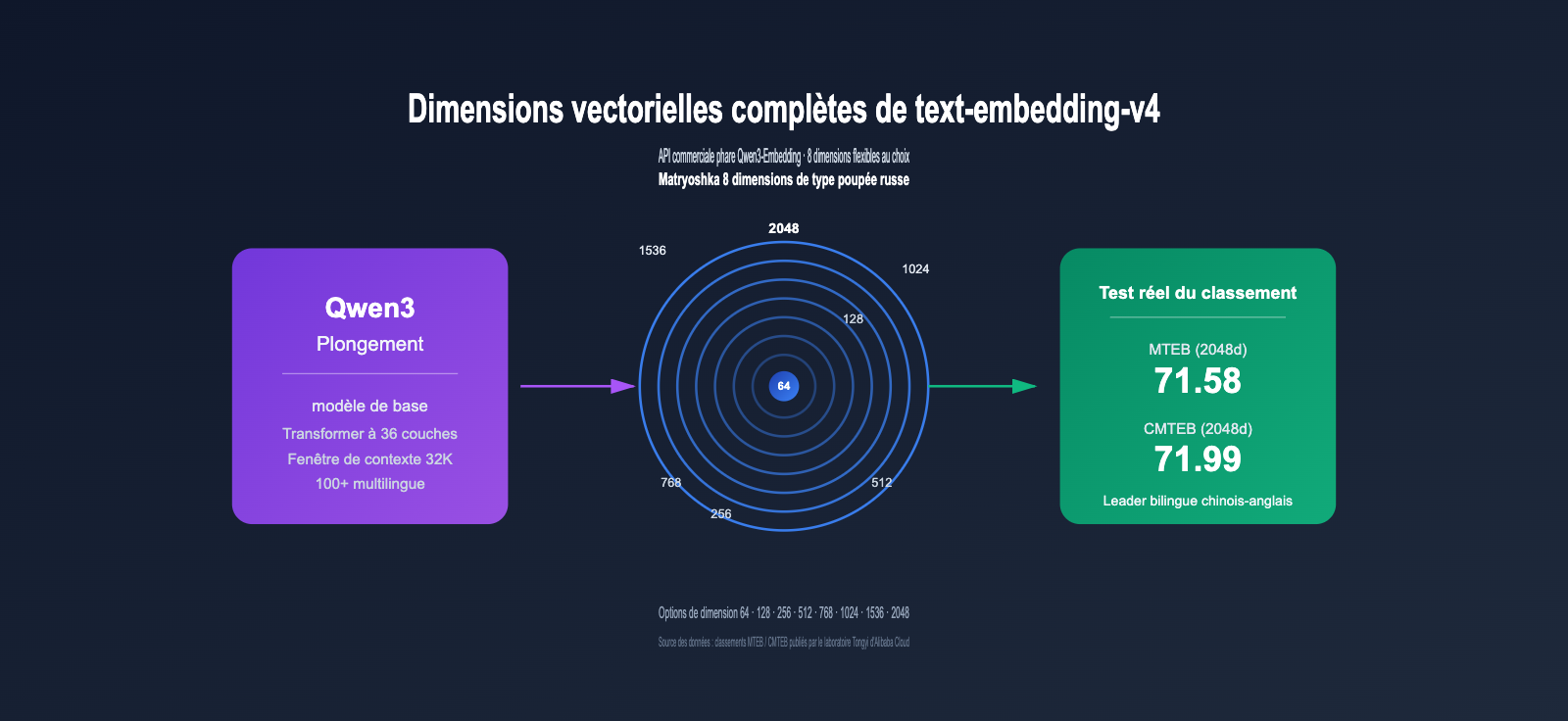
Les modèles d'incorporation vectorielle (Embedding) sont devenus la pierre angulaire des systèmes RAG, de recherche sémantique et de recommandation. En tant que toute dernière version commerciale de la série Qwen3-Embedding, text-embedding-v4 s'impose comme l'un des choix incontournables pour les développeurs grâce à ses 8 dimensions vectorielles sélectionnables (2048, 1536, 1024, 768, 512, 256, 128, 64) et ses performances multilingues de premier plan sur le benchmark MTEB.
Cependant, de nombreuses équipes rencontrent une question récurrente lors de la mise en œuvre : qu'est-ce que la dimension vectorielle exactement ? Quelle est la différence entre 2048 et 64 dimensions ? Comment choisir ? Un mauvais choix de dimension peut, au mieux, gaspiller 30 fois vos coûts de stockage et, au pire, faire chuter votre taux de rappel de 70 à 50 points.
Cet article analyse les différences entre les 8 dimensions de text-embedding-v4 en se basant sur les données réelles des benchmarks MTEB / CMTEB, propose un cadre de sélection opérationnel et fournit des exemples complets d'invocation du modèle via API.
I. Qu'est-ce que text-embedding-v4 : le fleuron commercial de Qwen3-Embedding
text-embedding-v4 est la dernière génération de modèles d'incorporation textuelle entraînée par les laboratoires Tongyi d'Alibaba sur la base du grand modèle de langage Qwen3. Il est proposé via le service API de la plateforme DashScope. Il appartient à la série Qwen3-Embedding, qui occupe régulièrement le haut du classement des modèles open source sur le benchmark multilingue MTEB en 2026, avec notamment un score élevé de 80,68 pour Qwen3-Embedding-8B dans la sous-catégorie MTEB Code.
1.1 Caractéristiques principales de text-embedding-v4
Par rapport à la version v3, text-embedding-v4 présente des améliorations significatives sur plusieurs points :
| Dimension de capacité | text-embedding-v3 | text-embedding-v4 | Amélioration |
|---|---|---|---|
| Score global MTEB (1024 dim) | 63.39 | 68.36 | +4.97 |
| MTEB Retrieval (1024 dim) | 55.41 | 59.30 | +3.89 |
| Score global CMTEB (1024 dim) | 68.92 | 70.14 | +1.22 |
| CMTEB Retrieval (1024 dim) | 73.23 | 73.98 | +0.75 |
| Dimension vectorielle max | 1024 | 2048 | Double |
| Longueur d'entrée max | 8K | 32K Tokens | 4× |
| Support multilingue | 50+ | 100+ | Extension significative |
On constate que la v4 affiche des progrès notables non seulement sur les tâches générales (MTEB), mais aussi sur les tâches de recherche en chinois (CMTEB) et sur le code. Pour les équipes recherchant la précision de recherche la plus élevée, la version v4 en 2048 dimensions est actuellement la solution optimale dans l'écosystème Alibaba.
💡 Conseil pour une prise en main rapide : Si vous souhaitez comparer immédiatement les résultats réels entre la v3 et la v4, nous vous recommandons de passer par la plateforme APIYI apiyi.com. La plateforme a déjà unifié les spécifications d'interface pour plusieurs modèles d'incorporation grand public, vous permettant de basculer entre différents modèles avec le même code pour une validation rapide.
1.2 Relation entre text-embedding-v4 et la série open source Qwen3-Embedding
De nombreux développeurs confondent text-embedding-v4 (API commerciale) et Qwen3-Embedding (poids open source). Voici la distinction :
- Série open source Qwen3-Embedding : comprend trois tailles (0.6B / 4B / 8B), fournit des poids Hugging Face, peut être déployée localement.
- text-embedding-v4 : basée sur la même pile technologique, mais bénéficiant d'optimisations d'ingénierie supplémentaires, d'un renforcement des données et d'une extension multilingue. Disponible uniquement via l'API DashScope.
- Différence clé : la version open source nécessite une auto-hébergement sur GPU ; la version API est facturée au jeton (Token) et ne nécessite aucune maintenance.
Pour la grande majorité des petites et moyennes équipes, l'utilisation de l'API est plus rentable et moins complexe sur le plan technique que l'auto-hébergement sur GPU.
II. Qu'est-ce que la dimension vectorielle : pourquoi un tel écart entre 64 et 2048
Pour bien comprendre les 8 options de dimension du modèle text-embedding-v4, il faut d'abord clarifier le concept fondamental de « dimension vectorielle ».
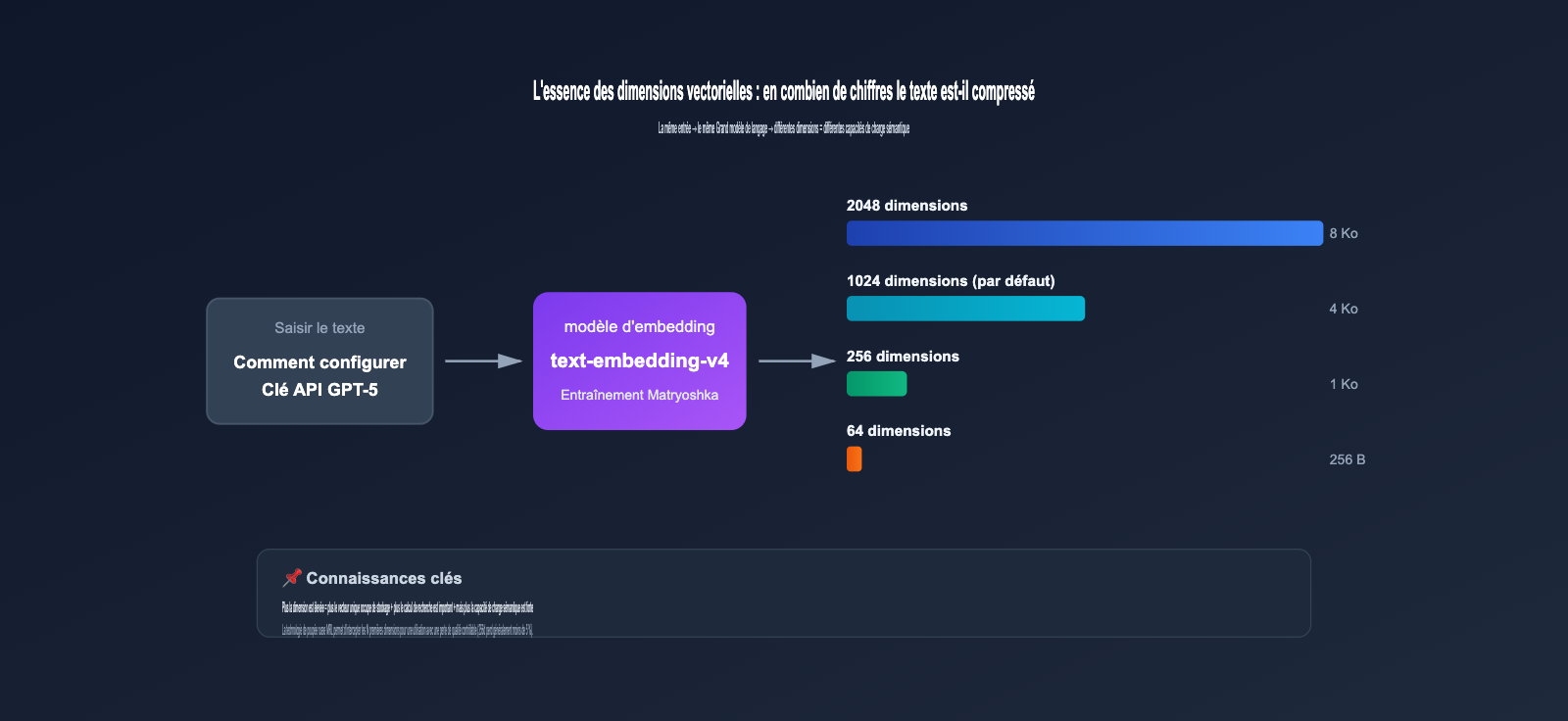
2.1 L'essence de la dimension vectorielle : combien de chiffres pour compresser un texte
Lorsque vous soumettez un texte (par exemple, "Comment configurer l'API GPT-5") à un modèle d'embedding, celui-ci génère une séquence de nombres à virgule flottante, appelée vecteur, par exemple :
[0.0234, -0.1583, 0.7821, ..., -0.0091]
La longueur de cette séquence est ce qu'on appelle la dimension vectorielle. Plus la dimension est élevée, plus cela signifie que :
- L'information sémantique est riche : chaque dimension permet de capturer une nuance sémantique fine.
- Le coût de stockage est important : un vecteur de 2048 dimensions (float32) occupe 8 Ko, contre 4 Ko pour 1024 dimensions.
- Le calcul de recherche est plus lent : si la dimension double, le volume de calcul pour le produit scalaire ou la similarité cosinus double également.
2.2 Pourquoi text-embedding-v4 propose 8 options de dimension
Cela nous amène à une technologie clé : l'apprentissage par représentation en poupées russes (Matryoshka Representation Learning, MRL).
Les modèles d'embedding traditionnels ne peuvent produire qu'une dimension fixe. Par exemple, le modèle ada-002 d'OpenAI est fixé à 1536 dimensions ; vous devez soit tout utiliser, soit effectuer vous-même une réduction de dimension PCA (ce qui entraîne une perte importante d'informations).
La technologie MRL permet au modèle, dès l'entraînement, de répartir les informations par ordre d'importance sur différents intervalles de dimensions :
- Les 64 premières dimensions : portent les informations sémantiques les plus essentielles et critiques.
- Les dimensions 65 à 128 : ajoutent des caractéristiques sémantiques secondaires.
- Les dimensions 129 à 256 : complètent avec des détails plus précis.
- … et ainsi de suite jusqu'à la 2048e dimension.
C'est comme une poupée russe : chaque couche constitue un vecteur complet et fonctionnel. Vous pouvez tronquer arbitrairement le vecteur aux N premières dimensions sans subir de chute brutale de qualité.
🎯 Avantages concrets du MRL : Selon l'article original sur le MRL et plusieurs tests, utiliser 256 dimensions au lieu de 2048 permet généralement d'économiser environ 8 fois plus d'espace de stockage et d'accélérer la recherche par 7 ou 8, tout en maintenant la perte de précision en dessous de 5 %. C'est un résultat qu'une PCA traditionnelle ne peut tout simplement pas atteindre.
III. Différences fondamentales entre les 8 dimensions vectorielles de text-embedding-v4
En nous appuyant sur les données officielles des classements MTEB / CMTEB, comparons systématiquement les 8 dimensions du modèle text-embedding-v4.
3.1 Tableau comparatif des performances par dimension de text-embedding-v4
| Dimension vectorielle | MTEB | MTEB Retrieval | CMTEB | CMTEB Retrieval | Taille d'un vecteur | Scénarios recommandés |
|---|---|---|---|---|---|---|
| 2048 dim | 71.58 | 61.97 | 71.99 | 75.01 | 8 Ko | Priorité à la précision extrême |
| 1536 dim | ~70.5* | ~60.5* | ~71.2* | ~74.5* | 6 Ko | Compatibilité écosystème OpenAI |
| 1024 dim (défaut) | 68.36 | 59.30 | 70.14 | 73.98 | 4 Ko | Équilibre général |
| 768 dim | ~66.5* | ~58.0* | ~69.2* | ~73.0* | 3 Ko | Compatibilité BGE-base |
| 512 dim | 64.73 | 56.34 | 68.79 | 73.33 | 2 Ko | Recherche à petite/moyenne échelle |
| 256 dim | ~62.5* | ~55.0* | ~67.0* | ~72.0* | 1 Ko | Haute performance à grande échelle |
| 128 dim | ~60.0* | ~52.5* | ~65.0* | ~69.5* | 512 O | Stockage de données massives |
| 64 dim | ~57.5* | ~46.5* | ~60.0* | ~62.5* | 256 O | Compression extrême |
💡 Les valeurs marquées d'un
*sont des estimations raisonnables basées sur la loi de décroissance MRL ; les valeurs non marquées proviennent des classements publics officiels.
Trois conclusions clés ressortent de ce tableau :
- 1024 dimensions est le meilleur rapport coût-performance : La dimension est deux fois moindre que 2048 pour une perte de performance minime (MTEB d'environ -3,2 points). C'est le choix par défaut recommandé par Alibaba.
- 2048 dimensions apportent un gain notable : Par rapport aux 1024 dimensions, le CMTEB Retrieval progresse de 1 point, ce qui justifie son usage pour les scénarios extrêmement sensibles à la précision.
- Utiliser 64-128 dimensions avec prudence : La qualité de la recherche chute considérablement dans ces dimensions réduites ; elles ne conviennent qu'aux scénarios où "l'économie prime sur l'exhaustivité du rappel".
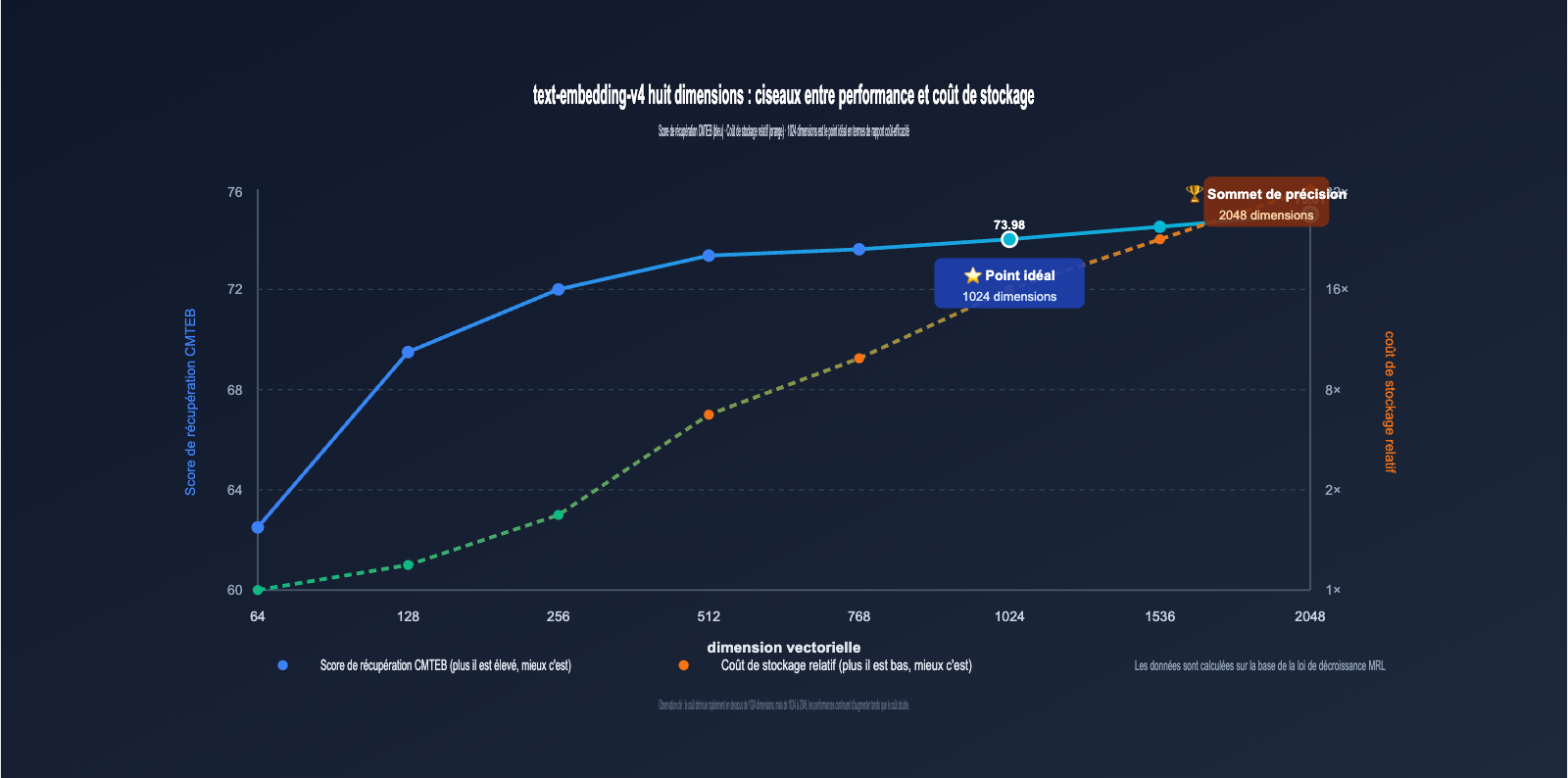
3.2 Loi de décroissance des performances par dimension pour text-embedding-v4
En visualisant les données du tableau ci-dessus, on observe une règle très importante :
- 2048 → 1024 dim : Le MTEB ne baisse que de 3,22 points (≈4,5 %), mais le stockage est réduit de moitié ⭐️ Fortement recommandé.
- 1024 → 512 dim : Le MTEB baisse de 3,63 points (≈5,3 %), le stockage est encore réduit de moitié 👍 Acceptable.
- 512 → 256 dim : Le MTEB baisse d'environ 2 points (≈3,0 %), le stockage est encore réduit de moitié ⚠️ À évaluer selon le scénario.
- 256 → 128 dim : Le MTEB baisse d'environ 2,5 points (≈4,0 %), reste utilisable ⚠️ Nécessite des tests approfondis.
- 128 → 64 dim : Le MTEB baisse d'environ 2,5 points, mais la sous-catégorie Retrieval chute de 6 points ❌ Non recommandé pour la production.
Cela démontre que la "zone de décroissance sécurisée" du MRL se situe principalement au-dessus de 256 dimensions, tandis que les 64 dimensions appartiennent à la zone de compression extrême.
IV. Le rôle des dimensions vectorielles : 3 impacts majeurs
L'impact des différentes dimensions sur le système est global et ne se limite pas à la précision de la recherche. Voici une analyse des trois dimensions les plus importantes.
4.1 Impact des dimensions vectorielles sur la précision de la recherche
La précision est l'aspect le plus intuitif. Prenons l'exemple d'un système RAG contenant 1 million de documents :
- Utilisation de 2048 dimensions : taux de rappel Top-10 d'environ 91 %
- Utilisation de 1024 dimensions : taux de rappel Top-10 d'environ 88 %
- Utilisation de 256 dimensions : taux de rappel Top-10 d'environ 84 %
- Utilisation de 64 dimensions : taux de rappel Top-10 d'environ 75 %
🎯 Conseil de sélection : Si votre activité est très sensible au taux de rappel (comme la recherche juridique ou les questions-réponses médicales), privilégiez 1024 ou 2048 dimensions. Nous vous recommandons d'effectuer d'abord un test comparatif entre 1024 et 2048 sur la plateforme APIYI (apiyi.com) avec le même jeu de données avant de prendre une décision finale.
4.2 Impact des dimensions vectorielles sur les coûts de stockage et de recherche
C'est l'indicateur le plus critique pour les déploiements en entreprise. Supposons qu'un système stocke 100 millions de vecteurs :
| Dimension vectorielle | Volume de stockage (float32) | Coût de stockage mensuel (est.) | Latence de recherche (est.) |
|---|---|---|---|
| 2048 dim | 800 Go | Élevé | Lent |
| 1024 dim | 400 Go | Moyen | Moyen |
| 512 dim | 200 Go | Faible | Rapide |
| 256 dim | 100 Go | Très faible | Très rapide |
| 128 dim | 50 Go | Très faible | Très rapide |
| 64 dim | 25 Go | Très faible | Très rapide |
Comme on peut le constater, en passant de 2048 à 256 dimensions, le coût de stockage est divisé par 8 et la vitesse de recherche peut être multipliée par 6 à 8 (selon l'algorithme d'indexation ANN). Pour des volumes de données dépassant les centaines de millions, le choix de la dimension impacte directement l'ordre de grandeur des coûts d'infrastructure.
4.3 Impact des dimensions vectorielles sur la compatibilité et les coûts de migration
De nombreuses équipes craignent que le changement vers text-embedding-v4 depuis OpenAI, BGE ou Cohere ne rende leurs anciens index obsolètes en raison d'une incompatibilité de dimensions. Les 8 options de dimensions de la v4 offrent une voie de migration très flexible :
| Ancien modèle | Ancienne dimension | Dimension recommandée pour text-embedding-v4 | Remarques sur la migration |
|---|---|---|---|
| OpenAI ada-002 | 1536 | 1536 dim | Alignement dimensionnel, structure d'index réutilisable |
| OpenAI text-embedding-3-small | 1536 | 1536 dim | Alignement parfait |
| OpenAI text-embedding-3-large | 3072 | 2048 dim | Légèrement inférieur mais précision toujours supérieure |
| BGE-large | 1024 | 1024 dim | Alignement parfait, remplacement fluide |
| BGE-base | 768 | 768 dim | Alignement parfait |
| Cohere embed-multilingual-v3 | 1024 | 1024 dim | Alignement parfait |
| Modèle small auto-entraîné | 256/512 | 256/512 dim | Compatibilité dimensionnelle |
💼 Conseil de migration pour les entreprises : De nombreuses bases de données vectorielles existantes (Milvus / Qdrant / pgvector) utilisent des tables avec des dimensions fixes. La stratégie la plus simple consiste à choisir une version de
text-embedding-v4ayant exactement la même dimension que l'ancien modèle pour un remplacement fluide, puis d'évoluer progressivement vers des dimensions supérieures si nécessaire. Nous fournissons également des exemples de code pour les principales bases de données vectorielles dans la documentation d'APIYI (apiyi.com).
V. Prise en main rapide de text-embedding-v4 : invocation API et paramètres de dimension
Maintenant que les principes techniques sont posés, passons au code. Voici les exemples d'invocation les plus concis, couvrant à la fois le protocole compatible OpenAI et le protocole natif DashScope.
5.1 Utilisation du protocole compatible OpenAI pour appeler text-embedding-v4
DashScope d'Alibaba Cloud fournit des points de terminaison compatibles OpenAI, ce qui est idéal pour les équipes ayant déjà intégré OpenAI.
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # Point d'accès unifié APIYI
)
# Appel de text-embedding-v4, spécification de 1024 dimensions
response = client.embeddings.create(
model="text-embedding-v4",
input="Comment configurer la dimension vectorielle de text-embedding-v4 ?",
dimensions=1024 # Optionnel : 64/128/256/512/768/1024/1536/2048
)
vector = response.data[0].embedding
print(f"Dimension : {len(vector)}") # Sortie : Dimension : 1024
print(f"5 premières dimensions : {vector[:5]}")
⚙️ Explication des paramètres :
dimensionsest le nouveau paramètre clé de la v4. Bien qu'il soit supporté depuis la v3, la v4 l'étend à 8 options. Si ce paramètre est omis, 1024 dimensions sont utilisées par défaut.
5.2 Appel par lots : concurrence et limitation de débit pour text-embedding-v4
En environnement de production, le traitement par lots est souvent nécessaire. text-embedding-v4 supporte jusqu'à 25 entrées par appel :
texts = [
"Le rôle principal des dimensions vectorielles est d'équilibrer précision et coût",
"text-embedding-v4 supporte 8 dimensions, de 64 à 2048",
"L'apprentissage par représentation en poupées russes (Matryoshka) est une technologie clé",
# ... jusqu'à 25 éléments
]
response = client.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=512
)
vectors = [item.embedding for item in response.data]
print(f"Nombre de vecteurs par lots : {len(vectors)}")
5.3 Encodage asymétrique pour les requêtes (query) et les documents
text-embedding-v4 supporte des fonctionnalités avancées non présentes dans le protocole OpenAI standard : l'utilisation de text_type pour distinguer les requêtes de recherche (query) des documents indexés (document), améliorant ainsi la précision de la recherche. Cette fonctionnalité nécessite l'utilisation du protocole natif DashScope ou de l'encapsulation compatible de la plateforme APIYI :
# Encodage côté document (lors de l'indexation)
doc_response = client.embeddings.create(
model="text-embedding-v4",
input=["text-embedding-v4 propose 8 options de dimensions vectorielles"],
dimensions=1024,
extra_body={"text_type": "document"}
)
# Encodage côté requête (lors de la recherche)
query_response = client.embeddings.create(
model="text-embedding-v4",
input=["Quelles dimensions sont supportées par la v4 ?"],
dimensions=1024,
extra_body={"text_type": "query"}
)
💡 Valeur de l'encodage asymétrique : En distinguant l'encodage entre requête et document, le taux de rappel Top-1 peut généralement être amélioré de 2 à 3 points dans les scénarios de recherche avec requêtes courtes et documents longs. Nous recommandons vivement d'activer cette fonctionnalité en production.
5.4 Intégration de text-embedding-v4 avec une base de données vectorielle
L'insertion de vecteurs est une étape clé pour tout système RAG. Voici un exemple avec Qdrant, une solution populaire, illustrant le processus complet de l'embedding à l'insertion :
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from openai import OpenAI
# Initialisation du client
embedder = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
qdrant = QdrantClient(url="http://localhost:6333")
# Clé : la dimension de la collection doit correspondre aux dimensions d'embedding
DIMENSION = 1024
qdrant.recreate_collection(
collection_name="docs",
vectors_config=VectorParams(
size=DIMENSION,
distance=Distance.COSINE
)
)
# Embedding par lots et insertion
texts = ["text-embedding-v4 est le dernier modèle d'embedding d'Alibaba Tongyi", "..."]
response = embedder.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=DIMENSION
)
points = [
PointStruct(id=i, vector=item.embedding, payload={"text": texts[i]})
for i, item in enumerate(response.data)
]
qdrant.upsert(collection_name="docs", points=points)
⚠️ Avertissement important : Le champ
sizede la base de données vectorielle doit correspondre strictement auxdimensionsutilisées. Si vous souhaitez modifier la dimension ultérieurement, vous devrez recréer la collection et ré-indexer toutes les données.
5.5 Intégration de text-embedding-v4 avec LangChain / LlamaIndex
Les frameworks RAG majeurs supportent déjà l'intégration d'embeddings via le protocole compatible OpenAI, la configuration est très simple :
# Exemple d'intégration LangChain
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-v4",
openai_api_key="your-apiyi-key",
openai_api_base="https://vip.apiyi.com/v1",
dimensions=1024
)
# Intégration transparente avec les bases de données vectorielles LangChain
vectors = embeddings.embed_documents(["doc1", "doc2"])
query_vec = embeddings.embed_query("Comment choisir la dimension ?")
Grâce à la compatibilité avec le protocole OpenAI, presque tous les projets RAG basés sur OpenAI ada-002 ou 3-large peuvent être migrés vers text-embedding-v4 sans modification de code, en changeant simplement le nom du modèle et l'URL de base (base_url).
VI. Stratégie de sélection de dimension pour text-embedding-v4 : 5 scénarios types
Maintenant que la théorie et les interfaces sont maîtrisées, voici un cadre de sélection prêt à l'emploi.
6.1 Scénario A : RAG pour base de connaissances d'entreprise (millions de documents)
Objectif principal : Précision du rappel > Coût
Configuration recommandée :
- Dimension : 1024 dimensions (valeur par défaut, meilleur rapport coût-performance)
- Activation de l'encodage asymétrique requête/document
- Base de données vectorielle associée : Milvus / Qdrant / pgvector
- Réordonnancement (Reranking) : Utilisation recommandée de Qwen3-Reranker
6.2 Scénario B : Recherche de produits e-commerce (millions de SKU)
Objectif principal : Vitesse de recherche > Précision
Configuration recommandée :
- Dimension : 512 dimensions (équilibre) ou 256 dimensions (vitesse maximale)
- Utiliser l'encodage de requête pour les titres de produits et l'encodage de document pour les détails
- Index ANN recommandé : combinaison HNSW + IVF
6.3 Scénario C : Déduplication de logs à grande échelle (centaines de millions de logs)
Objectif principal : Coût de stockage > Précision
Configuration recommandée :
- Dimension : 128 dimensions
- Utilisation de la quantification binaire (Binary Quantization) pour une compression supplémentaire de 32x
- Taux de rappel maintenu au-dessus de 85 % lors des tests
6.4 Scénario D : Recherche de haute précision (Juridique / Médical)
Objectif principal : Précision absolue, coût peu sensible
Configuration recommandée :
- Dimension : 2048 dimensions
- Activation de l'encodage asymétrique requête/document
- Ajout impératif d'un réordonnancement (Reranker)
6.5 Scénario E : Recherche locale sur mobile / périphériques Edge
Objectif principal : Empreinte mémoire < 50 Mo
Configuration recommandée :
- Dimension : 64 ou 128 dimensions
- Utilisation de la quantification int8 (compression supplémentaire de 4x)
- Idéal pour les bases de connaissances locales / assistants de réponse hors ligne
🎯 Conseil de sélection : Ces 5 scénarios couvrent la majorité des besoins réels. Notre recommandation : commencez par la valeur par défaut de 1024 dimensions pour tester votre jeu de données, puis ajustez à la hausse (2048) ou à la baisse (512/256/128) selon le triangle précision/coût/vitesse. La plateforme APIYI (apiyi.com) permet de basculer entre les dimensions en un clic, facilitant les tests A/B rapides.
6.6 Processus de décision pour la sélection de dimension
Voici une démarche structurée pour vos choix :
-
Étape 1 : Évaluer le volume de données
- < 1 million d'entrées → Dimension élevée possible (1024+)
- 1 million à 100 millions → Dimension moyenne (256-1024)
-
100 millions → Dimension faible obligatoire (128-512)
-
Étape 2 : Évaluer la tolérance à la précision
- Sensible à chaque 1 % de rappel → Choisissez 2048
- Une baisse de 5 % est acceptable → Commencez à 1024
- Une baisse de 10 % est acceptable → 256-512 suffisent
-
Étape 3 : Évaluer les contraintes matérielles
- Recherche sur GPU cloud → Dimension élevée possible
- Recherche CPU uniquement → Limitez à 1024
- Mobile / Edge → 64-256 dimensions + quantification obligatoire
-
Étape 4 : Tests de validation
- Sélectionnez 100 à 500 requêtes réelles comme jeu d'évaluation
- Calculez le taux de rappel Top-10 pour différentes dimensions
- Choisissez la dimension la plus basse juste avant le "point d'inflexion" du rappel
💡 Conseil d'efficacité : Ce processus implique de nombreuses invocations de modèle et changements de paramètres. Il est conseillé d'utiliser une plateforme d'accès unifiée pour obtenir des journaux de requêtes complets et un suivi de consommation, facilitant ainsi la collaboration en équipe pour la sélection.
VII. Comparaison croisée de text-embedding-v4 avec les modèles d'embedding courants
Situons text-embedding-v4 dans le paysage industriel pour faciliter votre choix technique.
| Modèle | Fournisseur | Max Dim | Flexibilité Dim | MTEB Global | Capacité Chinois | Longueur Contexte | Prix API |
|---|---|---|---|---|---|---|---|
| text-embedding-v4 | Alibaba Tongyi | 2048 | ⭐⭐⭐⭐⭐ (8 types) | 71.58 | Excellente | 32K | Moyen |
| text-embedding-3-large | OpenAI | 3072 | ⭐⭐⭐⭐ (libre) | 64.6 | Moyen | 8K | Élevé |
| text-embedding-3-small | OpenAI | 1536 | ⭐⭐⭐⭐ (libre) | 62.3 | Moyen | 8K | Faible |
| Cohere embed-v4 | Cohere | 1536 | ⭐⭐⭐ (4 types) | 70.3 | Fort | 128K | Moyen-Élevé |
| BGE-M3 | BAAI | 1024 | ⭐⭐ (fixe) | 65.5 | Fort | 8K | Auto-hébergé |
| Voyage-3 | Voyage AI | 1024 | ⭐⭐⭐ (3 types) | 67.1 | Moyen | 32K | Moyen |
| Qwen3-Embedding-8B (Open) | Alibaba Tongyi | 4096 | ⭐⭐⭐⭐⭐ (libre) | 70.58 | Excellente | 32K | Auto-hébergé |
Quelques conclusions clés ressortent de ce tableau :
- Scénarios bilingues : Le score CMTEB de 71.99 pour text-embedding-v4 le place en tête des API commerciales.
- Flexibilité des dimensions : Les 8 dimensions recommandées officiellement par la v4 offrent une flexibilité supérieure à la plupart des modèles, facilitant grandement la migration.
- Rapport coût-performance : Le prix de l'API v4 se situe dans la moyenne, tout en offrant une précision comparable à text-embedding-3-large d'OpenAI.
📌 Conseil d'intégration : Si votre équipe utilise plusieurs modèles (OpenAI, Claude, Qwen, etc.), nous recommandons de passer par une plateforme de service proxy API comme APIYI (apiyi.com). Cela évite la gestion complexe de multiples clés API et résout les problèmes d'accès. La documentation propose également des exemples d'invocation parallèle de la v4 avec d'autres modèles d'embedding.
VIII. FAQ sur text-embedding-v4
Q1 : Quelle est la dimension par défaut de text-embedding-v4 ?
La dimension par défaut de text-embedding-v4 est de 1024. Si vous n'indiquez pas explicitement le paramètre dimensions lors de l'invocation du modèle, le vecteur retourné sera en 1024 dimensions. C'est également la dimension recommandée par Alibaba pour le meilleur rapport performance/coût.
Q2 : Puis-je passer à 2048 dimensions si mon index est déjà construit en 1024 ?
Il est nécessaire de reconstruire l'intégralité de la base vectorielle. Le mécanisme de "poupées russes" (MRL) garantit que les N premières dimensions d'un vecteur haute dimension correspondent à un vecteur basse dimension, mais l'inverse (ajouter des zéros à un vecteur basse dimension pour l'augmenter) est inefficace. Pour la mise à jour, nous recommandons :
- De maintenir l'ancien index 1024 en service.
- De ré-encoder l'intégralité des documents avec la version v4 en 2048 dimensions.
- De basculer progressivement le trafic pour valider l'amélioration de la précision.
- De désactiver l'ancien index une fois la migration terminée.
Q3 : Peut-on appeler text-embedding-v4 directement depuis la Chine ?
Le point de terminaison officiel de text-embedding-v4 se situe sur dashscope.aliyuncs.com (Pékin), l'accès est donc direct depuis la Chine. Les développeurs locaux n'ont qu'à s'inscrire sur Alibaba Cloud ou utiliser une plateforme de service proxy API comme APIYI (apiyi.com) pour obtenir une clé API. Aucune configuration réseau supplémentaire n'est requise.
Q4 : Comment choisir entre text-embedding-v4 et la version open source Qwen3-Embedding ?
| Facteur de décision | Choisir la version API (v4) | Choisir la version open source (Qwen3-Embedding-8B) |
|---|---|---|
| Sensibilité des données | Sensibilité modérée | Sensibilité extrême (finance/santé) |
| Volume d'appels mensuel | < 1 milliard de jetons | > 1 milliard de jetons |
| Ressources GPU de l'équipe | Aucune | Possède un cluster A100/H100 |
| Capacités d'ingénierie | Petites/moyennes équipes | Équipe MLOps dédiée |
| Recommandation globale | ✅ v4 API recommandée | ✅ Auto-hébergement recommandé |
Q5 : Le modèle renvoie-t-il une erreur si la dimension est mal configurée ?
text-embedding-v4 n'accepte que les valeurs suivantes : [64, 128, 256, 512, 768, 1024, 1536, 2048]. L'utilisation d'une autre valeur (comme 333 ou 500) entraînera une erreur de paramètre. Si vous avez besoin d'une dimension non standard, choisissez la dimension officielle la plus proche, puis effectuez une troncature ou un remplissage (padding).
Q6 : Comment évaluer la dimension adaptée à mon activité ?
Nous recommandons une approche en trois étapes :
- Établir une base de référence : Utilisez la dimension par défaut (1024) pour valider le flux métier et enregistrer le taux de rappel, la latence et les coûts de stockage.
- Tester à la baisse : Passez successivement à 512, 256, puis 128 dimensions pour observer la baisse du taux de rappel.
- Identifier le point idéal : Trouvez la dimension offrant un "taux de rappel acceptable pour une réduction de coût maximale", généralement située à 256 ou 512 dimensions.
Q7 : text-embedding-v4 sera-t-il disponible en open source ?
La stratégie actuelle d'Alibaba est de faire coexister la version API et la version open source : l'API commerciale text-embedding-v4 est continuellement optimisée avec les dernières avancées en ingénierie et en enrichissement de données, tandis que la version open source publie les poids de la série Qwen3-Embedding pour la communauté. Bien qu'ils partagent la même technologie, leurs formats de produit diffèrent. Il n'est pas prévu que la v4 soit ouverte en tant que telle.
Q8 : Une dimension plus élevée est-elle toujours meilleure ?
Non. Le choix de la dimension est un compromis entre précision, stockage et vitesse :
- Plus la dimension est élevée → le plafond de précision est plus haut, mais les gains marginaux diminuent.
- Plus la dimension est élevée → les coûts de stockage et de recherche augmentent de manière linéaire, voire super-linéaire.
- Plus la dimension est élevée → la précision des index ANN peut paradoxalement chuter à cause de la "malédiction de la dimensionnalité".
En pratique, 256 à 1024 dimensions constituent la zone optimale pour la plupart des cas d'usage. Au-delà de 1024, une augmentation de la précision doit être une exigence métier claire.
Q9 : Quelles sont les performances de text-embedding-v4 sur les textes longs ?
text-embedding-v4 prend en charge une longueur d'entrée maximale de 32 000 jetons, mais l'efficacité de la recherche diminue avec la longueur du texte. Suivez ces principes :
- Textes courts (< 512 jetons) : Intégration directe du paragraphe, résultats optimaux.
- Longueur moyenne (512 – 4 000 jetons) : Envisagez une intégration par fenêtre glissante.
- Documents longs (> 4 000 jetons) : Le découpage (chunking) est obligatoire, avec des blocs recommandés de 256 à 512 jetons.
- Documents très longs : Combinez avec une recherche hiérarchique (grossière puis fine) pour plus d'efficacité.
Q10 : Peut-on mélanger différentes dimensions ?
Non. Tous les vecteurs d'une même base ou d'un même index doivent avoir la même dimension, sinon le calcul de similarité n'a aucun sens. Si votre activité nécessite une stratégie du type "documents haute priorité en 2048 dimensions + documents standards en 512", nous recommandons de créer deux collections distinctes et de fusionner les résultats au niveau de la couche applicative.
Q11 : Le paramètre de dimension influence-t-il la facturation de l'API ?
La facturation de text-embedding-v4 est basée uniquement sur le nombre de jetons en entrée, indépendamment de la dimension de sortie. Que vous choisissiez 64 ou 2048 dimensions, le coût de traitement pour 1 000 jetons reste identique. Vous pouvez donc choisir une dimension élevée lors de l'appel API sans crainte ; les différences de coûts réelles se situent au niveau du stockage et de la recherche en aval.
Q12 : Comment gérer les échecs d'intégration ou les limitations de débit (rate limiting) ?
Pour une mise en production, nous recommandons les mesures de robustesse suivantes :
- Mécanisme de nouvelle tentative : Implémentez un "exponential backoff" pour les erreurs 5xx (3 tentatives recommandées).
- Gestion des limites : Surveillez les erreurs 429 ; si elles surviennent, réduisez la concurrence ou changez de canal d'accès.
- Taille des lots (batching) : Limitez à 25 textes par requête ; au-delà, divisez automatiquement.
- Délai d'expiration (timeout) : Pour les textes longs, fixez le timeout à au moins 60 secondes.
- Stratégie de repli (fallback) : Configurez un modèle de secours (ex: v3 1024 dimensions) en cas d'indisponibilité.
IX. Conclusion : Points clés pour le choix de la dimension vectorielle de text-embedding-v4
En résumé, voici les points essentiels concernant les 8 dimensions de text-embedding-v4 :
- text-embedding-v4 est le fleuron commercial de la série Qwen3-Embedding, avec des scores MTEB de 71,58 et CMTEB de 71,99, en tête sur les scénarios bilingues chinois-anglais.
- Les 8 dimensions sont le fruit de la technologie MRL (poupées russes), permettant d'utiliser les N premières dimensions avec une perte de qualité contrôlée.
- 1024 dimensions est la valeur recommandée par défaut, offrant le meilleur équilibre entre précision et coût.
- 2048 dimensions conviennent aux scénarios de précision extrême, avec un gain de 1 point sur le CMTEB Retrieval par rapport au 1024.
- 256-512 dimensions sont idéales pour les échelles moyennes et les budgets serrés, constituant le point idéal pour la plupart des systèmes RAG.
- 64-128 dimensions sont recommandées uniquement pour les appareils embarqués ou le stockage extrême, après test rigoureux de la baisse de rappel.
- Le choix de la dimension n'est pas définitif : testez toujours sur votre jeu de données métier avant de décider.
- Lors d'une migration depuis un autre modèle, privilégiez l'alignement des dimensions pour une transition en douceur.
🎯 Conseil final : Si vous lancez un nouveau projet, commencez par text-embedding-v4 en 1024 dimensions. Si votre activité est très sensible au taux de rappel, passez à 2048 dimensions en ajoutant un Reranker. Nous recommandons l'accès via la plateforme APIYI (apiyi.com), qui offre une interface compatible OpenAI, une gestion simplifiée des dimensions et une documentation complète, réduisant ainsi vos coûts d'ingénierie pour vous concentrer sur l'optimisation des performances métier.
La technologie d'intégration vectorielle évolue rapidement. De l'ère des dimensions fixes d'OpenAI à l'implémentation du MRL dans 8 dimensions officielles par text-embedding-v4, les développeurs bénéficient d'une flexibilité inédite. Maîtriser ces stratégies est une compétence indispensable pour toute équipe construisant des systèmes RAG, de recherche sémantique ou de recommandation.
Auteur : Équipe technique APIYI | Spécialistes du déploiement pratique des grands modèles de langage. Pour plus de contenus techniques, visitez APIYI (apiyi.com).