Vektoreinbettungsmodelle (Embedding-Modelle) sind zum grundlegenden Fundament für RAG, semantische Suche und Empfehlungssysteme geworden. Als neueste kommerzielle Version der Qwen3-Embedding-Serie setzt text-embedding-v4 mit 8 wählbaren Vektordimensionen (2048, 1536, 1024, 768, 512, 256, 128, 64) und führenden MTEB-Ergebnissen in mehreren Sprachen neue Maßstäbe und ist für Entwickler eine der wichtigsten Optionen beim Aufbau von Vektor-Retrieval-Systemen.
Viele Teams stehen jedoch bei der Implementierung vor einer gemeinsamen Frage: Was genau ist die Vektordimension? Wie groß ist der Unterschied zwischen 2048 und 64 Dimensionen? Wie sollte ich wählen? Eine falsche Wahl kann im besten Fall die Speicherkosten um das 30-fache in die Höhe treiben und im schlimmsten Fall die Rückrufquote (Recall) von 70 auf 50 Punkte sinken lassen.
Dieser Artikel analysiert auf Basis offizieller MTEB/CMTEB-Messdaten die Unterschiede der 8 Vektordimensionen von text-embedding-v4, liefert einen praxisnahen Auswahlrahmen und stellt vollständige Beispiele für den Modellaufruf bereit.

I. Was ist text-embedding-v4: Das kommerzielle Flaggschiff von Qwen3-Embedding
text-embedding-v4 ist das neueste Text-Embedding-Modell der Alibaba Tongyi Labore, das auf dem Qwen3-Basis-Großes Sprachmodell trainiert wurde und über die DashScope-Plattform als API-Dienst bereitgestellt wird. Es gehört zur Qwen3-Embedding-Serie, die im MTEB-Ranking für mehrere Sprachen im Jahr 2026 durchgehend zu den führenden Open-Source-Modellen zählte. Qwen3-Embedding-8B erreichte im MTEB-Code-Unterbereich sogar eine Spitzenpunktzahl von 80,68.
1.1 Kernmerkmale von text-embedding-v4
Im Vergleich zur v3-Version bietet text-embedding-v4 signifikante Verbesserungen in den folgenden Bereichen:
| Leistungsmerkmal | text-embedding-v3 | text-embedding-v4 | Steigerung |
|---|---|---|---|
| MTEB Gesamtpunktzahl (1024 Dim) | 63,39 | 68,36 | +4,97 |
| MTEB Retrieval (1024 Dim) | 55,41 | 59,30 | +3,89 |
| CMTEB Gesamtpunktzahl (1024 Dim) | 68,92 | 70,14 | +1,22 |
| CMTEB Retrieval (1024 Dim) | 73,23 | 73,98 | +0,75 |
| Maximale Vektordimension | 1024 | 2048 | Verdoppelt |
| Maximale Eingabelänge | 8K | 32K Tokens | 4× |
| Mehrsprachige Unterstützung | 50+ | 100+ | Deutlich erweitert |
Wie man sieht, bietet v4 nicht nur bei allgemeinen Aufgaben (MTEB) deutliche Verbesserungen, sondern auch bei chinesischen (CMTEB) und Code-Retrieval-Aufgaben. Für Teams, die die höchste Retrieval-Präzision anstreben, ist die 2048-dimensionale v4-Variante aktuell die beste Wahl im Alibaba-Ökosystem.
💡 Empfehlung für einen schnellen Test: Wenn Sie die tatsächliche Leistung von v3 und v4 direkt vergleichen möchten, empfehlen wir den Aufruf über die Plattform APIYI (apiyi.com). Die Plattform hat die Schnittstellenspezifikationen für verschiedene gängige Embedding-Modelle vereinheitlicht, sodass Sie mit demselben Code schnell zwischen verschiedenen Modellen wechseln können.
1.2 Beziehung zwischen text-embedding-v4 und der Qwen3-Embedding Open-Source-Serie
Viele Entwickler verwechseln text-embedding-v4 (kommerzielle API) mit Qwen3-Embedding (Open-Source-Gewichte). Die Beziehung ist wie folgt:
- Qwen3-Embedding Open-Source-Serie: Umfasst die Größen 0,6B / 4B / 8B, stellt Hugging Face-Gewichte bereit und kann lokal bereitgestellt werden.
- text-embedding-v4: Basiert auf demselben Technologie-Stack, wurde jedoch durch zusätzliche technische Optimierungen, Datenverstärkung und mehrsprachige Erweiterungen ergänzt und ist ausschließlich über die DashScope-API verfügbar.
- Hauptunterschied: Die Open-Source-Version erfordert eine eigene GPU-Inferenz; die API-Version wird pro Token abgerechnet und erfordert keine Wartung.
Für die meisten kleinen und mittleren Teams ist der Aufruf der API kostengünstiger und weniger komplex als der Betrieb einer eigenen GPU-Inferenz.
2. Was ist die Vektordimension: Warum ist der Unterschied zwischen 64 und 2048 so groß?
Um die 8 Dimensionsoptionen von text-embedding-v4 zu verstehen, müssen wir zunächst das grundlegende Konzept der „Vektordimension“ klären.
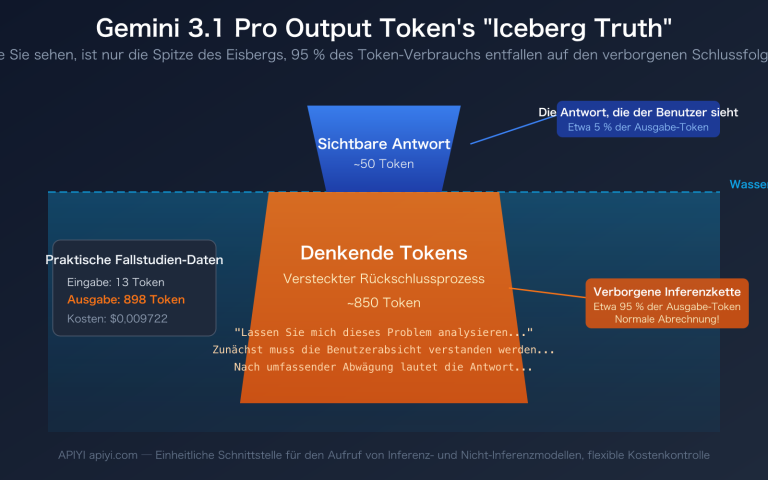
2.1 Das Wesen der Vektordimension: Wie viele Zahlen stecken in einem komprimierten Text?
Wenn Sie einen Text (z. B. „Wie konfiguriere ich die GPT-5 API?“) in ein Embedding-Modell eingeben, gibt das Modell einen Vektor aus einer Reihe von Gleitkommazahlen aus, zum Beispiel:
[0.0234, -0.1583, 0.7821, ..., -0.0091]
Die Länge dieser Zahlenreihe ist die Vektordimension. Eine höhere Dimension bedeutet:
- Reichhaltigere semantische Informationen: Jede Dimension kann ein feines semantisches Merkmal erfassen.
- Höhere Speicherkosten: Ein Vektor mit 2048 Dimensionen (float32) belegt 8 KB, während 1024 Dimensionen 4 KB belegen.
- Langsamere Suchberechnung: Wenn sich die Dimension verdoppelt, verdoppelt sich in etwa auch der Rechenaufwand für das Skalarprodukt bzw. die Kosinus-Ähnlichkeit.
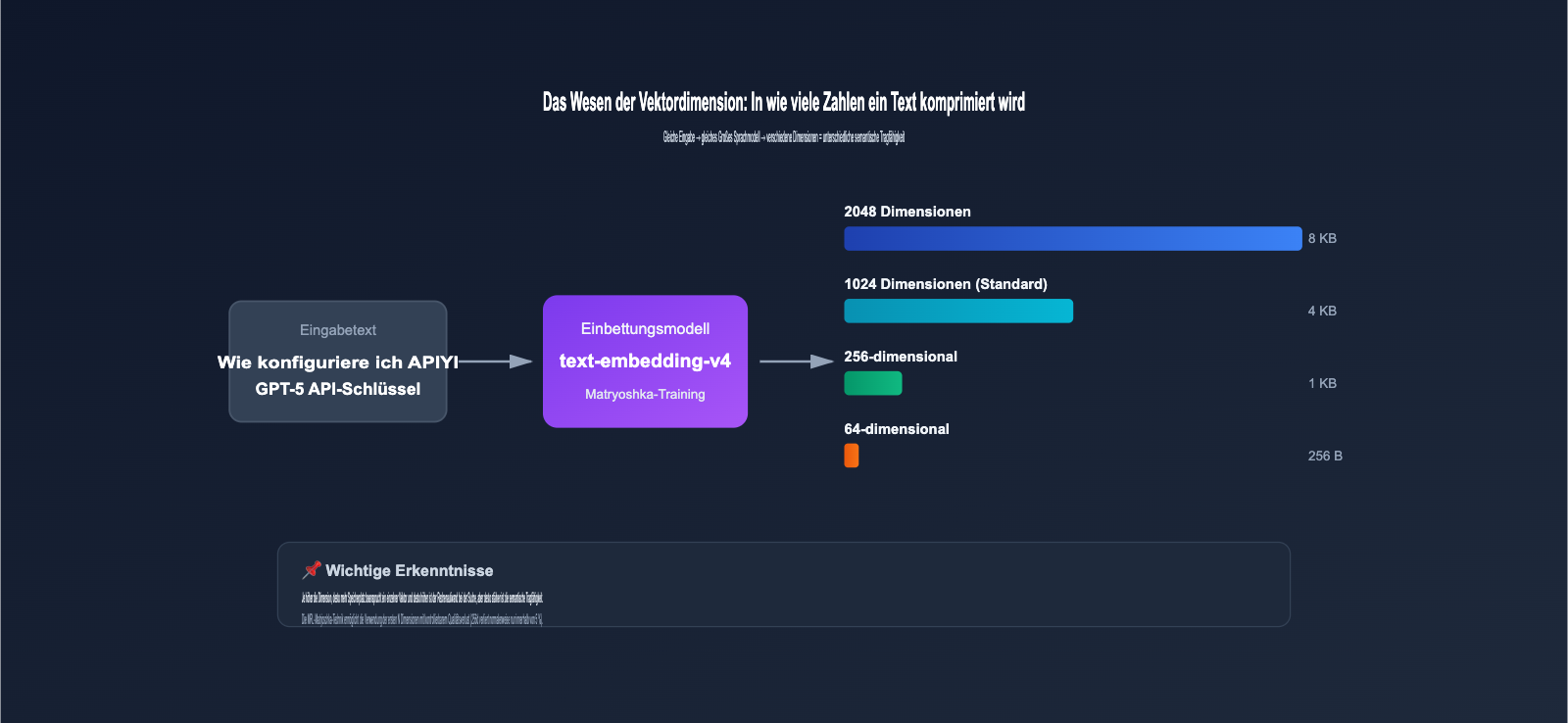
2.2 Warum bietet text-embedding-v4 8 verschiedene Dimensionen an?
Dies betrifft eine Schlüsseltechnologie – Matryoshka Representation Learning (MRL).
Traditionelle Embedding-Modelle können nur eine feste Dimension ausgeben. Zum Beispiel gibt das ada-002 von OpenAI fest 1536 Dimensionen aus; Sie müssen entweder alle verwenden oder selbst eine PCA-Dimensionsreduktion durchführen (was zu einem erheblichen Informationsverlust führt).
Die MRL-Technologie hingegen sorgt dafür, dass das Modell während des Trainings Informationen basierend auf ihrer Wichtigkeit über verschiedene Dimensionsintervalle verteilt:
- Die ersten 64 Dimensionen: Enthalten die wichtigsten und kritischsten semantischen Informationen.
- Die Dimensionen 65-128: Ergänzen sekundäre semantische Merkmale.
- Die Dimensionen 129-256: Ergänzen weitere detaillierte Merkmale.
- … und so weiter bis zur 2048. Dimension.
Es ist wie bei einer russischen Matroschka-Puppe: Jede Ebene ist ein vollständiger, unabhängig funktionierender Vektor. Sie können beliebig die ersten N Dimensionen verwenden, ohne dass die Qualität abrupt abfällt.
🎯 Der praktische Nutzen von MRL: Laut dem ursprünglichen MRL-Paper und zahlreichen Praxistests führt die Verwendung von 256 Dimensionen anstelle von 2048 in der Regel zu einer etwa 8-fachen Speicherersparnis und einer 7- bis 8-fachen Beschleunigung der Suche, während der Genauigkeitsverlust meist unter 5 % bleibt. Das ist mit herkömmlicher PCA absolut nicht erreichbar.
III. Die zentralen Unterschiede der 8 Vektordimensionen von text-embedding-v4
Basierend auf den offiziellen MTEB- / CMTEB-Ranglisten vergleichen wir im Folgenden systematisch die 8 Dimensionen von text-embedding-v4.
3.1 Vergleichstabelle der Leistungsdaten von text-embedding-v4
| Vektordimension | MTEB | MTEB Retrieval | CMTEB | CMTEB Retrieval | Einzelvektorgröße | Empfohlener Einsatzbereich |
|---|---|---|---|---|---|---|
| 2048 Dim. | 71.58 | 61.97 | 71.99 | 75.01 | 8 KB | Maximale Präzision |
| 1536 Dim. | ~70.5* | ~60.5* | ~71.2* | ~74.5* | 6 KB | OpenAI-Ökosystem-Kompatibilität |
| 1024 Dim. (Standard) | 68.36 | 59.30 | 70.14 | 73.98 | 4 KB | Ausgewogene Anwendung |
| 768 Dim. | ~66.5* | ~58.0* | ~69.2* | ~73.0* | 3 KB | BGE-base-Kompatibilität |
| 512 Dim. | 64.73 | 56.34 | 68.79 | 73.33 | 2 KB | Kleine bis mittlere Suche |
| 256 Dim. | ~62.5* | ~55.0* | ~67.0* | ~72.0* | 1 KB | Hoher Durchsatz |
| 128 Dim. | ~60.0* | ~52.5* | ~65.0* | ~69.5* | 512 B | Massenspeicherung |
| 64 Dim. | ~57.5* | ~46.5* | ~60.0* | ~62.5* | 256 B | Extreme Kompression |
💡 Werte mit
*sind vernünftige Schätzungen basierend auf dem MRL-Zerfallsgesetz; nicht markierte Werte stammen aus offiziellen öffentlichen Ranglisten.
Aus der Tabelle lassen sich drei wichtige Schlussfolgerungen ziehen:
- 1024 Dimensionen bieten das beste Preis-Leistungs-Verhältnis: Die Dimension ist nur halb so groß wie bei 2048, der Leistungsverlust ist jedoch gering (MTEB ca. -3,2 Punkte). Dies ist die von Alibaba empfohlene Standardeinstellung.
- 2048 Dimensionen bringen einen deutlichen Gewinn: Im Vergleich zu 1024 Dimensionen steigt der CMTEB-Retrieval-Wert um 1 Punkt; für präzisionskritische Szenarien ist dies eine Überlegung wert.
- Vorsicht bei 64-128 Dimensionen: Die Suchqualität sinkt bei niedrigen Dimensionen erheblich. Dies ist nur für Szenarien geeignet, in denen "Kosteneinsparung wichtiger als Vollständigkeit" ist.
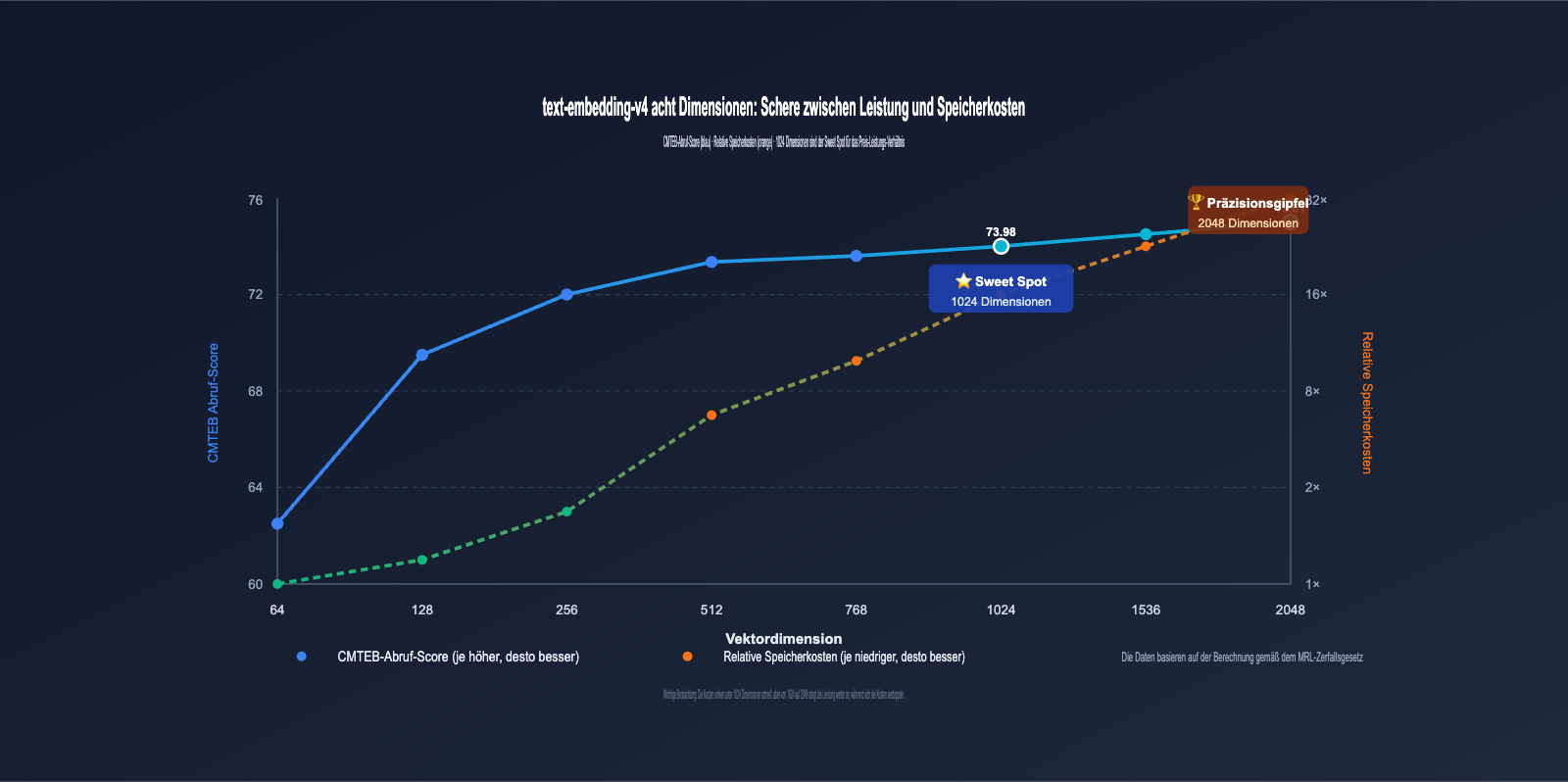
3.2 Das Zerfallsgesetz des Dimensionsverlusts bei text-embedding-v4
Visualisiert man die Daten der obigen Tabelle, lässt sich ein sehr wichtiges Muster beobachten:
- 2048 → 1024 Dimensionen: MTEB sinkt nur um 3,22 Punkte (≈4,5%), aber der Speicherbedarf halbiert sich ⭐️ Sehr empfehlenswert
- 1024 → 512 Dimensionen: MTEB sinkt um 3,63 Punkte (≈5,3%), Speicherbedarf halbiert sich erneut 👍 Akzeptabel
- 512 → 256 Dimensionen: MTEB sinkt um ca. 2 Punkte (≈3,0%), Speicherbedarf halbiert sich erneut ⚠️ Abhängig vom Szenario
- 256 → 128 Dimensionen: MTEB sinkt um ca. 2,5 Punkte (≈4,0%), weiterhin nutzbar ⚠️ Ausreichend testen
- 128 → 64 Dimensionen: MTEB sinkt um ca. 2,5 Punkte, aber der Retrieval-Teilwert bricht um 6 Punkte ein ❌ Nicht für den Produktionseinsatz empfohlen
Dies zeigt, dass sich das "sichere Zerfallsband" von MRL hauptsächlich oberhalb von 256 Dimensionen befindet; 64 Dimensionen gehören zum Bereich der extremen Kompression.
IV. Die Rolle der Vektordimension: 3 zentrale Auswirkungen
Die Auswirkungen unterschiedlicher Dimensionen auf das System sind umfassend und betreffen weit mehr als nur die Suchgenauigkeit. Im Folgenden analysieren wir die drei wichtigsten Aspekte.
4.1 Einfluss der Vektordimension auf die Suchgenauigkeit
Die Genauigkeit ist der intuitivste Faktor. Nehmen wir als Beispiel ein RAG-System mit 1 Million Dokumenten:
- 2048 Dimensionen: Top-10-Recall ca. 91 %
- 1024 Dimensionen: Top-10-Recall ca. 88 %
- 256 Dimensionen: Top-10-Recall ca. 84 %
- 64 Dimensionen: Top-10-Recall ca. 75 %
🎯 Empfehlung zur Auswahl: Wenn Ihr Anwendungsfall hochgradig recall-sensibel ist (z. B. juristische Recherche, medizinische Fragen), sollten Sie 1024 oder 2048 Dimensionen bevorzugen. Wir empfehlen, auf der Plattform APIYI (apiyi.com) zunächst einen Vergleichstest zwischen 1024 und 2048 mit Ihrem eigenen Datensatz durchzuführen, bevor Sie eine endgültige Entscheidung treffen.
4.2 Einfluss der Vektordimension auf Speicher- und Abfragekosten
Dies ist der wichtigste Indikator für den produktiven Einsatz in Unternehmen. Angenommen, ein System speichert 100 Millionen Vektoren:
| Vektordimension | Gesamtspeicher (float32) | Monatliche Speicherkosten (geschätzt) | Latenz pro Abfrage (geschätzt) |
|---|---|---|---|
| 2048 Dim. | 800 GB | Hoch | Langsam |
| 1024 Dim. | 400 GB | Mittel | Mittel |
| 512 Dim. | 200 GB | Niedriger | Schneller |
| 256 Dim. | 100 GB | Niedrig | Schnell |
| 128 Dim. | 50 GB | Sehr niedrig | Sehr schnell |
| 64 Dim. | 25 GB | Sehr niedrig | Sehr schnell |
Wie man sieht, sinken die Speicherkosten bei einer Reduzierung von 2048 auf 256 Dimensionen auf ein Achtel, während die Suchgeschwindigkeit um das 6- bis 8-fache steigen kann (abhängig vom ANN-Index-Algorithmus). Bei Datenmengen im Milliardenbereich beeinflusst die Wahl der Dimension die Infrastrukturkosten direkt um Größenordnungen.
4.3 Einfluss der Vektordimension auf Kompatibilität und Migrationskosten
Viele Teams, die von OpenAI, BGE oder Cohere auf text-embedding-v4 umsteigen, befürchten, dass inkompatible Vektordimensionen ihre alten Indizes unbrauchbar machen. Die 8 verschiedenen Dimensionen von v4 bieten hier einen sehr benutzerfreundlichen Migrationspfad:
| Altes Modell | Alte Dimension | Empfohlene Dimension für text-embedding-v4 | Migrationshinweis |
|---|---|---|---|
| OpenAI ada-002 | 1536 | 1536 Dim. | Dimensionen stimmen überein, Indexstruktur wiederverwendbar |
| OpenAI text-embedding-3-small | 1536 | 1536 Dim. | Vollständig kompatibel |
| OpenAI text-embedding-3-large | 3072 | 2048 Dim. | Etwas niedriger, aber Genauigkeit bleibt überlegen |
| BGE-large | 1024 | 1024 Dim. | Vollständig kompatibel, nahtloser Austausch |
| BGE-base | 768 | 768 Dim. | Vollständig kompatibel |
| Cohere embed-multilingual-v3 | 1024 | 1024 Dim. | Vollständig kompatibel |
| Selbst trainiertes Small-Modell | 256/512 | 256/512 Dim. | Dimensionskompatibel |
💼 Empfehlung für die Unternehmensmigration: Viele Vektordatenbanken alter Systeme (Milvus / Qdrant / pgvector) sind mit festen Dimensionen konfiguriert. Wählen Sie zunächst eine Version von
text-embedding-v4, die exakt mit der alten Dimension übereinstimmt, um einen reibungslosen Austausch zu gewährleisten, und führen Sie dann bei Bedarf schrittweise ein Upgrade auf höhere Dimensionen durch. Dies ist der Weg mit dem geringsten Widerstand. In der Dokumentation auf APIYI (apiyi.com) finden Sie zudem Beispielcode für die Anbindung gängiger Vektordatenbanken.
V. Schnelleinstieg in text-embedding-v4: API-Aufruf und Dimensionsparameter
Nachdem die technischen Grundlagen geklärt sind, kommen wir direkt zum Code. Hier sind die kompaktesten Aufrufbeispiele, die sowohl das OpenAI-kompatible Protokoll als auch das native DashScope-Protokoll abdecken.
5.1 Aufruf von text-embedding-v4 über das OpenAI-kompatible Protokoll
Alibaba DashScope bietet einen OpenAI-kompatiblen Endpunkt, was für Teams mit bestehender OpenAI-Integration am einfachsten ist.
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # APIYI einheitlicher Zugangspunkt
)
# Aufruf von text-embedding-v4, 1024 Dimensionen spezifiziert
response = client.embeddings.create(
model="text-embedding-v4",
input="Wie konfiguriere ich die Vektordimension für text-embedding-v4?",
dimensions=1024 # Optional: 64/128/256/512/768/1024/1536/2048
)
vector = response.data[0].embedding
print(f"Dimension: {len(vector)}") # Ausgabe: Dimension: 1024
print(f"Erste 5 Dimensionen: {vector[:5]}")
⚙️ Parametererklärung:
dimensionsist ein entscheidender neuer Parameter in v4. Er wurde ab v3 unterstützt, aber in v4 auf 8 Optionen erweitert. Wird der Parameter weggelassen, werden standardmäßig 1024 Dimensionen verwendet.
5.2 Batch-Aufrufe: Nebenläufigkeit und Ratenbegrenzung
In der Produktion ist die Stapelverarbeitung oft notwendig. text-embedding-v4 unterstützt bis zu 25 Eingaben pro Aufruf:
texts = [
"Die Vektordimension dient primär dem Ausgleich von Genauigkeit und Kosten",
"text-embedding-v4 unterstützt insgesamt 8 Dimensionen von 64 bis 2048",
"Matryoshka-Repräsentationslernen ist eine Schlüsseltechnologie",
# ... bis zu 25 Einträge
]
response = client.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=512
)
vectors = [item.embedding for item in response.data]
print(f"Anzahl der Batch-Vektoren: {len(vectors)}")
5.3 Asymmetrische Kodierung für Query und Dokument
text-embedding-v4 unterstützt fortgeschrittene Funktionen, die über das Standard-OpenAI-Protokoll hinausgehen: Durch den Parameter text_type kann zwischen Suchanfragen (query) und zu durchsuchenden Dokumenten (document) unterschieden werden, was die Suchgenauigkeit weiter verbessert. Diese Funktion erfordert das native DashScope-Protokoll oder die kompatible Kapselung der APIYI-Plattform:
# Kodierung der Dokumentseite (beim Indizieren)
doc_response = client.embeddings.create(
model="text-embedding-v4",
input=["text-embedding-v4 bietet 8 Vektordimensionen zur Auswahl"],
dimensions=1024,
extra_body={"text_type": "document"}
)
# Kodierung der Suchseite (bei der Abfrage)
query_response = client.embeddings.create(
model="text-embedding-v4",
input=["Welche Dimensionen unterstützt v4?"],
dimensions=1024,
extra_body={"text_type": "query"}
)
💡 Vorteil der asymmetrischen Kodierung: Durch die Unterscheidung zwischen Query und Dokument kann der Top-1-Recall bei Szenarien mit kurzen Suchanfragen und langen Dokumenten oft um weitere 2-3 Prozentpunkte gesteigert werden. Wir empfehlen, diese Funktion in der Produktion unbedingt zu aktivieren.
5.4 Anbindung von text-embedding-v4 an Vektordatenbanken
Das Speichern von Vektoren ist ein kritischer Schritt beim Aufbau eines RAG-Systems. Hier ist der vollständige Prozess von der Texteinbettung bis zum Speichern in der branchenüblichen Datenbank Qdrant:
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from openai import OpenAI
# Client initialisieren
embedder = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
qdrant = QdrantClient(url="http://localhost:6333")
# Wichtig: Die Dimension der Collection muss mit den Embedding-Dimensionen übereinstimmen
DIMENSION = 1024
qdrant.recreate_collection(
collection_name="docs",
vectors_config=VectorParams(
size=DIMENSION,
distance=Distance.COSINE
)
)
# Batch-Einbettung und Speicherung
texts = ["text-embedding-v4 ist das neueste Embedding-Modell von Alibaba Tongyi", "..."]
response = embedder.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=DIMENSION
)
points = [
PointStruct(id=i, vector=item.embedding, payload={"text": texts[i]})
for i, item in enumerate(response.data)
]
qdrant.upsert(collection_name="docs", points=points)
⚠️ Wichtiger Hinweis: Das
size-Feld der Vektordatenbank muss strikt mit dendimensionsübereinstimmen. Sollten Sie die Dimension später ändern wollen, müssen Sie die Collection neu erstellen und alle Daten erneut einbetten.
5.5 Integration von text-embedding-v4 in LangChain / LlamaIndex
Gängige RAG-Frameworks unterstützen bereits die Embedding-Anbindung über das OpenAI-kompatible Protokoll, die Konfiguration ist sehr einfach:
# Beispiel für LangChain-Integration
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-v4",
openai_api_key="your-apiyi-key",
openai_api_base="https://vip.apiyi.com/v1",
dimensions=1024
)
# Nahtlose Integration mit LangChain-Vektorspeichern
vectors = embeddings.embed_documents(["doc1", "doc2"])
query_vec = embeddings.embed_query("Wie wähle ich die Dimension?")
Durch die Anbindung über das OpenAI-kompatible Protokoll können fast alle RAG-Projekte, die ursprünglich auf OpenAI ada-002 / 3-large basieren, ohne Code-Änderungen auf text-embedding-v4 migriert werden – es müssen lediglich der Modellname und die base_url angepasst werden.
VI. Strategie zur Dimensionierung von text-embedding-v4: 5 typische Szenarien
Nachdem die Theorie und die Schnittstellen geklärt sind, folgt nun ein Framework für die Auswahl, das Sie direkt übernehmen können.
6.1 Szenario A: RAG für Unternehmenswissensdatenbanken (Millionen von Dokumenten)
Kernanforderung: Abrufgenauigkeit > Kosten
Empfohlene Konfiguration:
- Dimension: 1024 Dimensionen (Standardwert, bestes Preis-Leistungs-Verhältnis)
- Aktivierung der asymmetrischen Query/Document-Kodierung
- Vektor-Datenbank: Milvus / Qdrant / pgvector
- Reranking: Einsatz von Qwen3-Reranker empfohlen
6.2 Szenario B: E-Commerce-Produktsuche (Millionen von SKUs)
Kernanforderung: Suchgeschwindigkeit > Präzision
Empfohlene Konfiguration:
- Dimension: 512 Dimensionen (ausgewogen) oder 256 Dimensionen (maximale Geschwindigkeit)
- Produkttitel als Query kodieren, Details als Document kodieren
- ANN-Index: Kombination aus HNSW + IVF empfohlen
6.3 Szenario C: Deduplizierung massiver Protokolldaten (Milliarden von Logs)
Kernanforderung: Speicherkosten > Präzision
Empfohlene Konfiguration:
- Dimension: 128 Dimensionen
- Verwendung von Binärquantisierung (Binary Quantization) zur weiteren Komprimierung um den Faktor 32
- Testergebnisse zeigen, dass die Abrufquote weiterhin bei über 85 % liegt
6.4 Szenario D: Hochpräzise Suche (Recht / Medizin)
Kernanforderung: Präzision steht an erster Stelle, Kosten zweitrangig
Empfohlene Konfiguration:
- Dimension: 2048 Dimensionen
- Aktivierung der asymmetrischen Query/Document-Kodierung
- Zwingende Verwendung von Reranking
6.5 Szenario E: Lokale Suche auf Mobilgeräten / Edge-Geräten
Kernanforderung: Speicherauslastung < 50 MB
Empfohlene Konfiguration:
- Dimension: 64 Dimensionen oder 128 Dimensionen
- Verwendung von int8-Quantisierung (weitere 4-fache Komprimierung)
- Geeignet für lokale Wissensdatenbanken / Offline-Assistenten
🎯 Entscheidungshilfe: Diese 5 Szenarien decken die meisten gängigen Anwendungsfälle ab. Wir empfehlen: Starten Sie mit dem Standardwert von 1024 Dimensionen für Ihren Testdatensatz und passen Sie diesen je nach Bedarf (Präzision/Kosten/Geschwindigkeit) nach oben (2048) oder unten (512/256/128) an. Die Plattform APIYI (apiyi.com) unterstützt das Umschalten der Dimensionsparameter per Klick, was A/B-Tests erheblich beschleunigt.
6.6 Entscheidungsprozess für die Dimensionierung
Die oben genannten Szenarien lassen sich in einen umsetzbaren Entscheidungsprozess zusammenfassen:
-
Schritt 1: Datenvolumen bewerten
- < 1 Million Einträge → Hohe Dimensionen möglich (1024+)
- 1 Million bis 100 Millionen Einträge → Mittlere Dimensionen (256-1024)
-
100 Millionen Einträge → Niedrige Dimensionen zwingend erforderlich (128-512)
-
Schritt 2: Toleranz gegenüber Präzisionsverlusten bewerten
- Jedes Prozent Abrufquote zählt → 2048 wählen
- 5 % Abfall akzeptabel → Start mit 1024
- 10 % Abfall akzeptabel → 256-512 ausreichend
-
Schritt 3: Hardware-Einschränkungen bewerten
- Cloud-GPU-Suche → Hohe Dimensionen möglich
- Nur CPU-Suche → Begrenzung auf maximal 1024
- Mobil / Edge → Zwingend 64-256 Dimensionen + Quantisierung
-
Schritt 4: Praxistest durchführen
- 100-500 reale Suchanfragen als Testset verwenden
- Top-10-Abrufquote bei verschiedenen Dimensionen berechnen
- Die niedrigste Dimension vor dem "Knickpunkt" der Abrufquote wählen
💡 Effizienz-Tipp: Da dieser Prozess mehrere Modellaufrufe erfordert, empfiehlt sich die Nutzung einer zentralen Plattform. Dort erhalten Sie vollständige Anfrageprotokolle und Nutzungsstatistiken, was die Zusammenarbeit im Team bei der Modellauswahl erleichtert.
VII. Vergleich von text-embedding-v4 mit gängigen Embedding-Modellen
Um die technologische Einordnung zu erleichtern, vergleichen wir text-embedding-v4 mit dem Industriestandard.
| Modell | Anbieter | Max. Dimension | Flexibilität | MTEB Gesamt | Chinesisch-Fähigkeit | Kontextfenster | API-Preis |
|---|---|---|---|---|---|---|---|
| text-embedding-v4 | Alibaba Tongyi | 2048 | ⭐⭐⭐⭐⭐ (8 Typen) | 71.58 | Exzellent | 32K | Mittel |
| text-embedding-3-large | OpenAI | 3072 | ⭐⭐⭐⭐ (beliebig) | 64.6 | Mittel | 8K | Hoch |
| text-embedding-3-small | OpenAI | 1536 | ⭐⭐⭐⭐ (beliebig) | 62.3 | Mittel | 8K | Niedrig |
| Cohere embed-v4 | Cohere | 1536 | ⭐⭐⭐ (4 Typen) | 70.3 | Stark | 128K | Mittel-Hoch |
| BGE-M3 | BAAI | 1024 | ⭐⭐ (fest) | 65.5 | Stark | 8K | Selbst-Deployment |
| Voyage-3 | Voyage AI | 1024 | ⭐⭐⭐ (3 Typen) | 67.1 | Mittel | 32K | Mittel |
| Qwen3-Embedding-8B (Open Source) | Alibaba Tongyi | 4096 | ⭐⭐⭐⭐⭐ (beliebig) | 70.58 | Exzellent | 32K | Selbst-Deployment |
Aus dieser Vergleichstabelle lassen sich wichtige Schlüsse ziehen:
- Zweisprachige Szenarien (Chinesisch/Englisch): Mit einem CMTEB-Gesamtwert von 71.99 belegt text-embedding-v4 den ersten Platz unter allen kommerziellen APIs.
- Flexibilität der Dimensionen: Die 8 offiziell empfohlenen Dimensionen von v4 sind flexibler als bei den meisten anderen Modellen, was die Migration sehr einfach macht.
- Preis-Leistungs-Verhältnis: Der API-Preis von v4 liegt im Mittelfeld, bietet jedoch eine Präzision, die mit OpenAI text-embedding-3-large vergleichbar ist.
📌 Integrationshinweis: Wenn Ihr Team mehrere Modelle wie OpenAI, Claude oder Qwen gleichzeitig benötigt, empfiehlt sich die Nutzung eines API-Proxy-Dienstes wie APIYI (apiyi.com). Dies erspart die Verwaltung zahlreicher API-Schlüssel und löst Probleme beim Zugriff aus China. In der Dokumentation finden Sie zudem Beispiele für den parallelen Aufruf von v4 und anderen gängigen Embedding-Modellen.
VIII. Häufig gestellte Fragen (FAQ) zu text-embedding-v4
Q1: Was ist die Standarddimension von text-embedding-v4?
Die Standarddimension von text-embedding-v4 beträgt 1024. Wenn beim Modellaufruf der Parameter dimensions nicht explizit übergeben wird, werden Vektoren mit 1024 Dimensionen zurückgegeben. Dies ist auch die von Alibaba offiziell empfohlene Dimension für das beste Preis-Leistungs-Verhältnis.
Q2: Kann ich einen bereits mit 1024 Dimensionen erstellten Index auf 2048 Dimensionen aktualisieren?
Der gesamte Vektor-Index muss neu erstellt werden. Der MRL-Matrjoschka-Mechanismus garantiert zwar, dass "die ersten N Dimensionen eines hochdimensionalen Vektors" einem "niederdimensionalen Vektor" entsprechen, aber der umgekehrte Weg – also das Auffüllen mit Nullen von niedrig auf hoch – ist nicht effektiv. Für ein Upgrade wird empfohlen:
- Den alten 1024-Dimensionen-Index als Online-Dienst beizubehalten.
- Die Dokumente mit der 2048-Dimensionen-Variante von v4 vollständig neu einzubetten.
- Den Datenverkehr schrittweise (Canary Deployment) umzustellen, um die Genauigkeitssteigerung zu validieren.
- Nach Abschluss den alten Index abzuschalten.
Q3: Kann text-embedding-v4 direkt aus China aufgerufen werden?
Der offizielle Endpunkt von text-embedding-v4 befindet sich unter dashscope.aliyuncs.com (Peking) und ist von China aus direkt erreichbar. Entwickler in China müssen lediglich ein Alibaba-Cloud-Konto registrieren oder einen API-Proxy-Dienst wie APIYI (apiyi.com) nutzen, um einen API-Schlüssel zu erhalten. Es sind keine zusätzlichen Netzwerkkonfigurationen erforderlich.
Q4: Wie wähle ich zwischen text-embedding-v4 und der Open-Source-Version Qwen3-Embedding?
| Entscheidungsfaktor | API-Version (v4) wählen | Open-Source-Version (Qwen3-Embedding-8B) wählen |
|---|---|---|
| Datensensibilität | Normal sensibel | Extrem sensibel (Finanzen/Medizin) |
| Monatliches Volumen | < 1 Mrd. Tokens | > 1 Mrd. Tokens |
| GPU-Ressourcen im Team | Keine vorhanden | A100/H100-Cluster vorhanden |
| Engineering-Kapazität | Kleine/mittlere Teams | MLOps-Team vorhanden |
| Empfehlung | ✅ v4 API empfohlen | ✅ Selbst-Deployment empfohlen |
Q5: Gibt das Modell eine Fehlermeldung aus, wenn die Dimension falsch eingestellt ist?
text-embedding-v4 akzeptiert nur Werte aus der Menge [64, 128, 256, 512, 768, 1024, 1536, 2048]. Die Eingabe anderer Werte (z. B. 333 oder 500) führt direkt zu einem Parameterfehler. Wenn Sie nicht standardisierte Dimensionen benötigen, wählen Sie die nächstgelegene offizielle Dimension und führen Sie anschließend eine Kürzung oder Auffüllung durch.
Q6: Wie bewerte ich, welche Dimension für mein aktuelles Projekt geeignet ist?
Wir empfehlen ein Drei-Schritte-Verfahren:
- Basislinie festlegen: Führen Sie den Geschäftsprozess zunächst mit den standardmäßigen 1024 Dimensionen aus und protokollieren Sie Rückrufquote (Recall), Latenz und Speicherkosten.
- Abwärts testen: Wechseln Sie nacheinander auf 512, 256 und 128 Dimensionen und beobachten Sie den Rückgang der Rückrufquote.
- Sweet Spot finden: Identifizieren Sie die Dimension, bei der der Rückgang der Rückrufquote akzeptabel ist und die Kostenersparnis am größten ausfällt – meist liegt dieser Punkt bei 256 oder 512 Dimensionen.
Q7: Wird text-embedding-v4 als Open Source veröffentlicht?
Alibabas aktuelle Strategie sieht ein Nebeneinander von API-Version und Open-Source-Version vor: Die kommerzielle API von text-embedding-v4 wird kontinuierlich weiterentwickelt und profitiert von neuesten technischen Optimierungen und Datenanreicherungen. Die Open-Source-Versionen der Qwen3-Embedding-Serie werden der Community als Modellgewichte zur Verfügung gestellt. Beide basieren auf derselben Technologie, haben jedoch unterschiedliche Produktformen. Es ist nicht zu erwarten, dass v4 in absehbarer Zeit separat als Open Source veröffentlicht wird.
Q8: Ist eine höhere Dimension immer besser?
Nein. Die Wahl der Dimension ist im Wesentlichen ein Kompromiss zwischen Genauigkeit, Speicherbedarf und Geschwindigkeit:
- Höhere Dimension → Höhere Genauigkeitsgrenze, aber abnehmender Grenznutzen.
- Höhere Dimension → Speicher- und Abfragekosten steigen linear oder sogar überlinear.
- Höhere Dimension → Bei ANN-Indizes kann die Genauigkeit aufgrund des Fluchs der Dimensionalität sogar sinken.
Erfahrungsgemäß liegt der optimale Arbeitsbereich für die meisten Anwendungen bei 256–1024 Dimensionen. Werte über 1024 lohnen sich nur, wenn ein expliziter Bedarf an höherer Genauigkeit besteht.
Q9: Wie ist die Leistung von text-embedding-v4 bei langen Texten?
text-embedding-v4 unterstützt eine maximale Eingabelänge von 32K Tokens, jedoch sinkt die tatsächliche Abfragequalität mit zunehmender Textlänge. Wir empfehlen folgende Prinzipien:
- Kurze Texte (< 512 Tokens): Direkt als ganzer Abschnitt einbetten (beste Ergebnisse).
- Mittlere Länge (512–4K Tokens): Erwägen Sie ein Chunking mit gleitendem Fenster.
- Lange Dokumente (> 4K Tokens): Müssen in Chunks unterteilt werden; eine Chunk-Größe von 256–512 Tokens wird empfohlen.
- Sehr lange Dokumente: Kombinieren Sie dies mit einer hierarchischen Suche (zuerst grob, dann fein), um die Effizienz zu steigern.
Q10: Können verschiedene Dimensionen gemischt werden?
Nein. Alle Vektoren innerhalb einer Vektordatenbank oder eines Index müssen die gleiche Dimension aufweisen, da sonst die Ähnlichkeitsberechnung sinnlos ist. Wenn Ihre Anwendung eine Strategie wie "hochpriorisierte Dokumente mit 2048 Dimensionen + normale Dokumente mit 512 Dimensionen" erfordert, sollten Sie zwei separate Collections verwalten und die Ergebnisse auf Anwendungsebene zusammenführen.
Q11: Hat der Dimensionsparameter Auswirkungen auf die API-Abrechnung?
Die Abrechnung von text-embedding-v4 basiert ausschließlich auf der Anzahl der Eingabe-Tokens und ist unabhängig von der Ausgabedimension. Das bedeutet: Egal, ob Sie 64 oder 2048 Dimensionen wählen, die Kosten für die Verarbeitung von 1000 Eingabe-Tokens sind identisch. Sie können also bei der API-Anfrage bedenkenlos hohe Dimensionen wählen; die tatsächlichen Kostenunterschiede ergeben sich erst bei der nachgelagerten Speicherung und Abfrage.
Q12: Wie gehe ich mit Einbettungsfehlern oder Ratenbegrenzungen um?
Für den produktiven Einsatz von text-embedding-v4 empfehlen wir folgende robuste Vorgehensweisen:
- Wiederholungsmechanismus: Implementieren Sie für 5xx-Fehler ein exponentielles Backoff-Retry (empfohlen: 3 Versuche).
- Ratenbegrenzung: Überwachen Sie 429-Fehler; reduzieren Sie bei Auftreten die Parallelität oder wechseln Sie den Zugangskanal.
- Batch-Größe: Maximal 25 Texte pro Anfrage; bei mehr Texten muss automatisch in Batches unterteilt werden.
- Timeout-Einstellungen: Bei der Einbettung langer Texte sollte das Timeout auf mindestens 60 Sekunden gesetzt werden.
- Fallback-Lösung: Konfigurieren Sie ein Ersatzmodell (z. B. v3 mit 1024 Dimensionen) als Sicherheitsnetz.
IX. Fazit: Kernpunkte zur Wahl der Vektordimension für text-embedding-v4
Zusammenfassend sind dies die wichtigsten Punkte zu den 8 Vektordimensionen von text-embedding-v4:
- text-embedding-v4 ist das kommerzielle Flaggschiff der Qwen3-Embedding-Serie und führend in zweisprachigen (Chinesisch/Englisch) Szenarien (MTEB 71.58 / CMTEB 71.99).
- Die 8 Dimensionen basieren auf der Matrjoschka-Technologie (MRL), wodurch die ersten N Dimensionen mit kontrollierbarem Qualitätsverlust genutzt werden können.
- 1024 Dimensionen sind der empfohlene Standardwert für ein optimales Gleichgewicht zwischen Genauigkeit und Kosten.
- 2048 Dimensionen eignen sich für Szenarien mit höchster Präzision (1 Punkt Verbesserung bei CMTEB Retrieval gegenüber 1024).
- 256–512 Dimensionen sind ideal für mittlere Skalierung und kostenbewusste Szenarien – der "Sweet Spot" für die meisten RAG-Systeme.
- 64–128 Dimensionen sind nur für Edge-Geräte oder extreme Speicherbeschränkungen empfohlen; testen Sie hier den Rückgang der Rückrufquote gründlich.
- Die Wahl der Dimension ist keine endgültige Entscheidung; testen Sie unbedingt mit Ihren eigenen Geschäftsdaten, bevor Sie sich festlegen.
- Bei der Migration von anderen Modellen zu v4 sollten Sie bevorzugt eine dimensionskompatible Version für einen reibungslosen Wechsel wählen.
🎯 Abschließende Empfehlung: Wenn Sie ein Einbettungsmodell für ein neues Projekt auswählen, starten Sie direkt mit text-embedding-v4 + 1024 Dimensionen. Falls Ihr Unternehmen hochsensibel auf die Rückrufquote reagiert, erhöhen Sie auf 2048 Dimensionen und ergänzen Sie einen Reranker. Wir empfehlen die Anbindung über die Plattform APIYI (apiyi.com). Sie bietet eine einheitliche, OpenAI-kompatible Schnittstelle, bequeme Dimensionsumschaltung und eine vollständige Dokumentation. Dies senkt die Engineering-Kosten erheblich und lässt Ihr Team sich auf die Optimierung der Ergebnisse konzentrieren, statt auf die API-Anpassung.
Die Vektoreinbettungstechnologie entwickelt sich rasant weiter – von der Ära der fixen Dimensionen bei OpenAI bis hin zu text-embedding-v4, das MRL in 8 offiziellen Dimensionen nutzbar macht. Die Beherrschung dieser Dimensionen und Auswahlstrategien ist eine Kernkompetenz für jedes Team, das RAG-, semantische Such- oder Empfehlungssysteme aufbaut.
Autor: APIYI Technical Team | Fokus auf KI-Großmodelle in der Praxis. Weitere technische Inhalte finden Sie unter APIYI apiyi.com