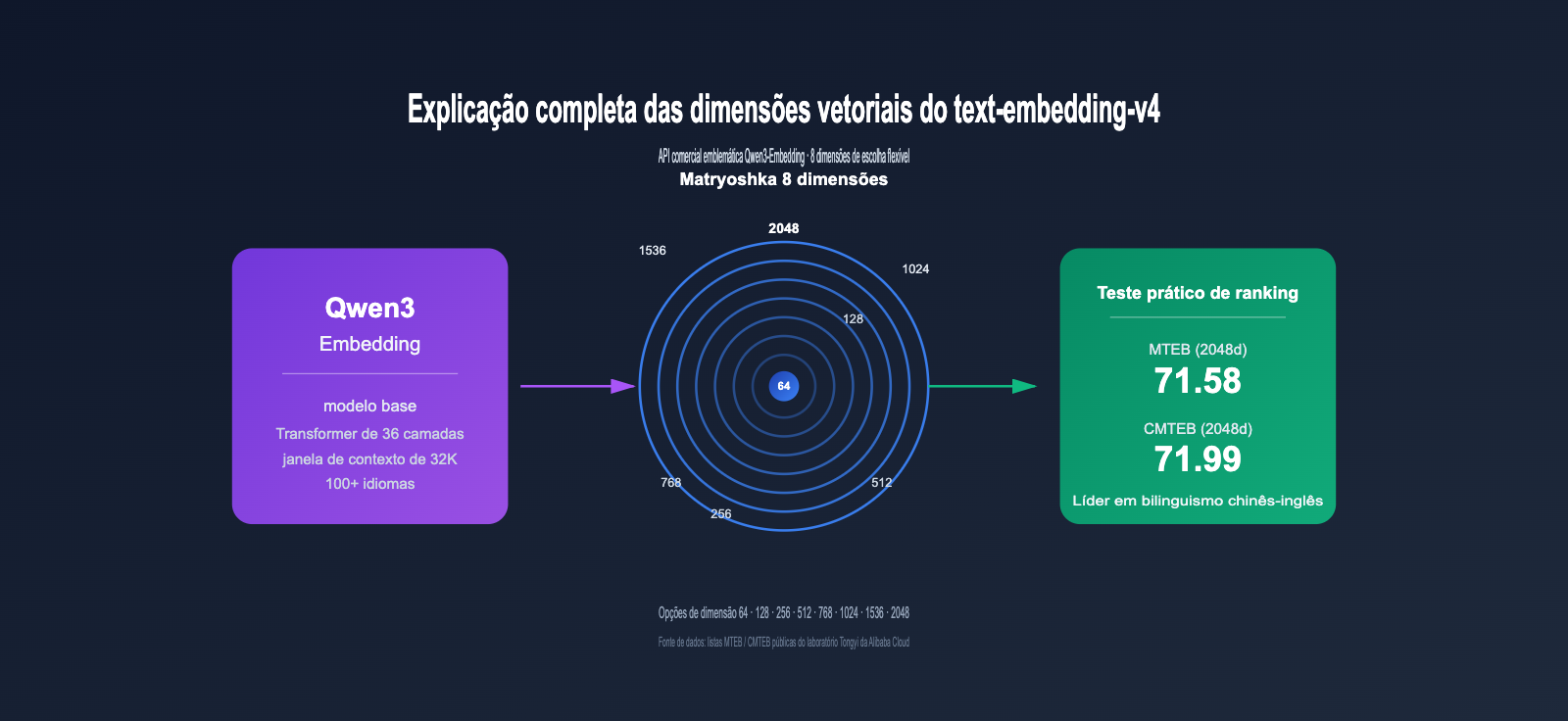
Modelos de incorporação (Embedding) tornaram-se a pedra angular de sistemas de RAG, busca semântica e sistemas de recomendação. Como a versão comercial mais recente da série Qwen3-Embedding, o text-embedding-v4 está se tornando uma das principais opções para desenvolvedores que constroem sistemas de recuperação vetorial, graças às suas 8 dimensões vetoriais opcionais (2048, 1536, 1024, 768, 512, 256, 128, 64) e resultados multilíngues líderes no MTEB.
No entanto, muitas equipes enfrentam uma dúvida comum ao implementar: O que é exatamente a dimensão vetorial? Qual a diferença entre 2048 e 64 dimensões? Como devo escolher? Escolher a dimensão errada pode, na melhor das hipóteses, desperdiçar 30 vezes o custo de armazenamento e, na pior, fazer com que a taxa de recuperação caia de 70 para 50 pontos.
Este artigo decompõe sistematicamente as diferenças entre as 8 dimensões vetoriais do text-embedding-v4 com base em dados reais do MTEB/CMTEB, fornece um framework de seleção prático e oferece exemplos completos de invocação de modelo via API.
I. O que é o text-embedding-v4: O carro-chefe comercial do Qwen3-Embedding
O text-embedding-v4 é a mais recente geração de modelos de incorporação de texto treinada pelo laboratório Tongyi da Alibaba com base no Modelo de Linguagem Grande Qwen3, disponibilizado via API pela plataforma DashScope. Ele pertence à série Qwen3-Embedding, que tem ocupado consistentemente o topo dos rankings de modelos de código aberto no MTEB multilíngue em 2026, com o Qwen3-Embedding-8B alcançando uma pontuação alta de 80,68 na subcategoria MTEB Code.
1.1 Principais características do text-embedding-v4
Comparado à versão v3, o text-embedding-v4 traz melhorias significativas nas seguintes dimensões:
| Dimensão de Capacidade | text-embedding-v3 | text-embedding-v4 | Aumento |
|---|---|---|---|
| Pontuação MTEB (1024 dim) | 63,39 | 68,36 | +4,97 |
| MTEB Retrieval (1024 dim) | 55,41 | 59,30 | +3,89 |
| Pontuação CMTEB (1024 dim) | 68,92 | 70,14 | +1,22 |
| CMTEB Retrieval (1024 dim) | 73,23 | 73,98 | +0,75 |
| Dimensão vetorial máxima | 1024 | 2048 | Dobro |
| Comprimento máximo de entrada | 8K | 32K Tokens | 4× |
| Suporte multilíngue | 50+ | 100+ | Expansão significativa |
Como se pode notar, o v4 não apenas apresenta melhorias claras em tarefas gerais (MTEB), mas também um progresso considerável em tarefas de recuperação em chinês (CMTEB) e de código. Para equipes que buscam a maior precisão de recuperação, o v4 de 2048 dimensões é a melhor escolha atual no ecossistema Alibaba.
💡 Dica de experimentação rápida: Se você deseja comparar os resultados reais entre o v3 e o v4, recomendamos usar a plataforma APIYI (apiyi.com). Ela já adaptou as especificações de interface de vários modelos de incorporação convencionais, permitindo que você alterne entre diferentes modelos com o mesmo código para uma validação rápida.
1.2 Relação entre o text-embedding-v4 e a série de código aberto Qwen3-Embedding
Muitos desenvolvedores confundem o text-embedding-v4 (API comercial) com o Qwen3-Embedding (pesos de código aberto). A relação entre eles é a seguinte:
- Série de código aberto Qwen3-Embedding: Inclui os tamanhos 0.6B / 4B / 8B, fornecendo pesos no Hugging Face para implantação local.
- text-embedding-v4: Baseado na mesma pilha tecnológica, mas com otimizações de engenharia adicionais, reforço de dados e expansão multilíngue, disponível apenas via API DashScope.
- Diferença chave: A versão de código aberto exige a construção de inferência em GPU própria; a versão API é cobrada por Token e não requer manutenção.
Para a grande maioria das pequenas e médias equipes, chamar a API é mais econômico e menos complexo em termos de engenharia do que construir uma inferência em GPU própria.
二、 O que é a dimensão do vetor: por que a diferença entre 64 e 2048 é tão grande
Para entender as 8 opções de dimensão do text-embedding-v4, precisamos primeiro esclarecer o conceito fundamental de "dimensão do vetor".
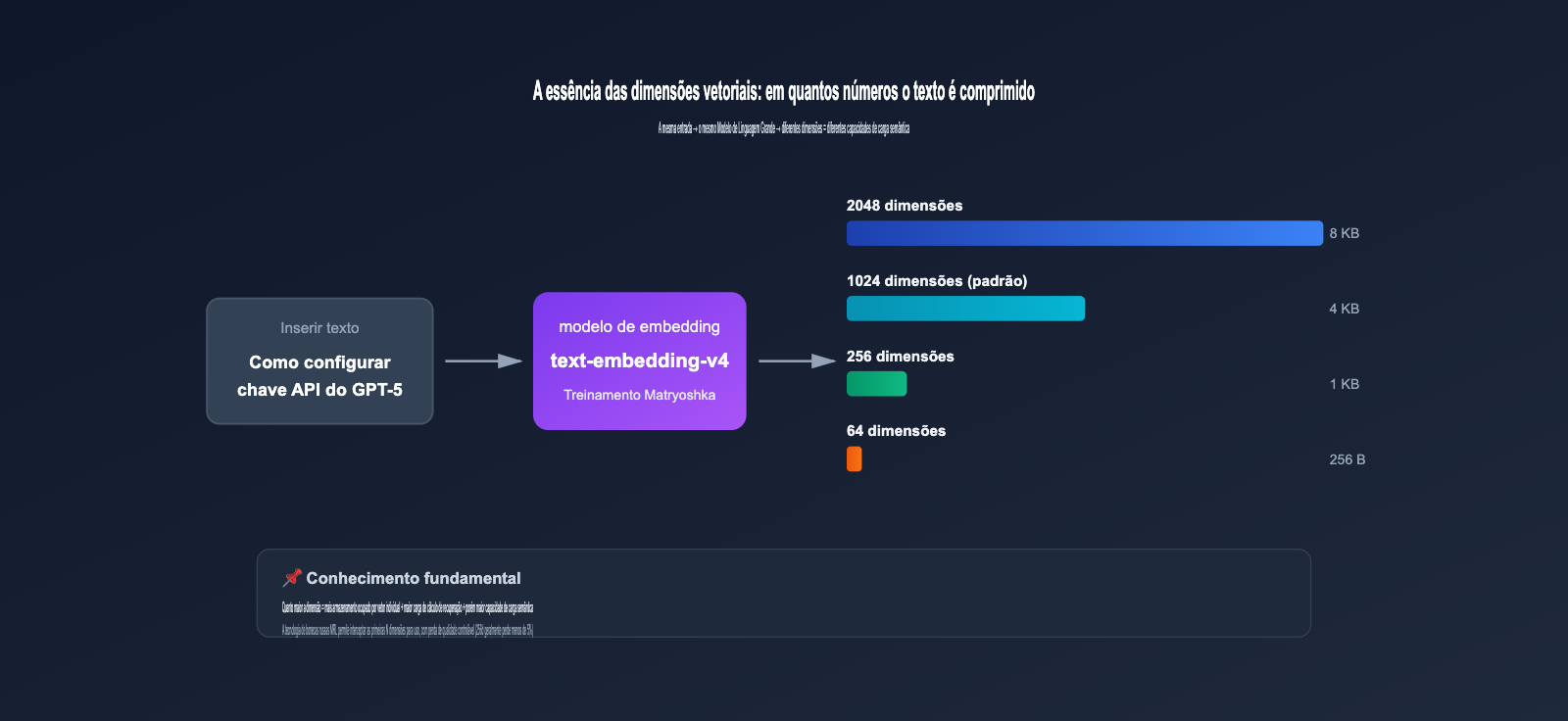
2.1 A essência da dimensão do vetor: em quantos números um texto é comprimido
Quando você insere um trecho de texto (por exemplo, "como configurar a API do GPT-5") em um modelo de embedding, o modelo gera uma sequência de números de ponto flutuante, como:
[0.0234, -0.1583, 0.7821, ..., -0.0091]
O comprimento dessa sequência de números é a dimensão do vetor. Quanto maior a dimensão, significa que:
- A informação semântica carregada é mais rica: cada dimensão pode capturar uma característica semântica sutil.
- O custo de armazenamento é maior: um vetor de 2048 dimensões (float32) ocupa 8 KB, enquanto um de 1024 ocupa 4 KB.
- O cálculo de busca é mais lento: ao dobrar a dimensão, o volume de cálculo de produto interno/cosseno também dobra aproximadamente.
2.2 Por que o text-embedding-v4 oferece 8 opções de dimensão
Isso envolve uma tecnologia fundamental: Aprendizado de Representação Matryoshka (Matryoshka Representation Learning, MRL).
Modelos de embedding tradicionais só podiam gerar uma dimensão fixa. Por exemplo, o ada-002 da OpenAI gera fixamente 1536 dimensões; ou você usa tudo, ou faz uma redução de dimensionalidade via PCA (o que causa uma perda significativa de informações).
Já a tecnologia MRL permite que o modelo, durante o treinamento, distribua as informações de acordo com um gradiente de importância em diferentes intervalos de dimensão:
- Primeiras 64 dimensões: carregam as informações semânticas mais centrais e cruciais.
- 65ª a 128ª dimensões: complementam características semânticas secundárias.
- 129ª a 256ª dimensões: continuam complementando características mais detalhadas.
- … e assim por diante até a 2048ª dimensão.
É como uma boneca russa (Matryoshka), onde cada camada é um vetor completo e independente. Você pode cortar arbitrariamente as primeiras N dimensões para usar, e a qualidade não sofrerá uma queda drástica.
🎯 Benefícios práticos do MRL: De acordo com o artigo original do MRL e vários testes, usar 256 dimensões em vez de 2048 geralmente pode proporcionar uma economia de armazenamento de cerca de 8 vezes e uma aceleração de busca de 7 a 8 vezes, mantendo a perda de precisão geralmente abaixo de 5%. Isso é algo que o PCA tradicional não consegue fazer.
III. Diferenças centrais das 8 dimensões do text-embedding-v4
A seguir, comparamos sistematicamente as 8 dimensões do text-embedding-v4 com base nos dados oficiais do MTEB / CMTEB.
3.1 Tabela de comparação de desempenho por dimensão do text-embedding-v4
| Dimensão do Vetor | MTEB | MTEB Retrieval | CMTEB | CMTEB Retrieval | Tamanho do Vetor | Cenário Recomendado |
|---|---|---|---|---|---|---|
| 2048 | 71.58 | 61.97 | 71.99 | 75.01 | 8 KB | Prioridade em precisão máxima |
| 1536 | ~70.5* | ~60.5* | ~71.2* | ~74.5* | 6 KB | Compatibilidade com ecossistema OpenAI |
| 1024 (padrão) | 68.36 | 59.30 | 70.14 | 73.98 | 4 KB | Cenários de equilíbrio geral |
| 768 | ~66.5* | ~58.0* | ~69.2* | ~73.0* | 3 KB | Compatibilidade com BGE-base |
| 512 | 64.73 | 56.34 | 68.79 | 73.33 | 2 KB | Busca de pequena/média escala |
| 256 | ~62.5* | ~55.0* | ~67.0* | ~72.0* | 1 KB | Alta vazão em larga escala |
| 128 | ~60.0* | ~52.5* | ~65.0* | ~69.5* | 512 B | Armazenamento de dados massivos |
| 64 | ~57.5* | ~46.5* | ~60.0* | ~62.5* | 256 B | Cenários de compressão extrema |
💡 Valores marcados com
*são estimativas razoáveis baseadas na lei de decaimento do MRL; valores não marcados provêm de rankings públicos oficiais.
Podemos extrair três conclusões principais da tabela:
- 1024 dimensões é a melhor relação custo-benefício: a dimensão é apenas metade de 2048, mas a perda de desempenho é pequena (MTEB cerca de -3,2 pontos), sendo a escolha padrão recomendada pela Alibaba.
- 2048 dimensões trazem ganhos claros: em comparação com 1024, o CMTEB Retrieval aumenta em 1 ponto, valendo a pena para cenários extremamente sensíveis à precisão.
- Use 64-128 dimensões com cautela: a qualidade da busca cai significativamente em dimensões baixas, sendo adequadas apenas para cenários onde "é melhor perder recall do que gastar dinheiro".
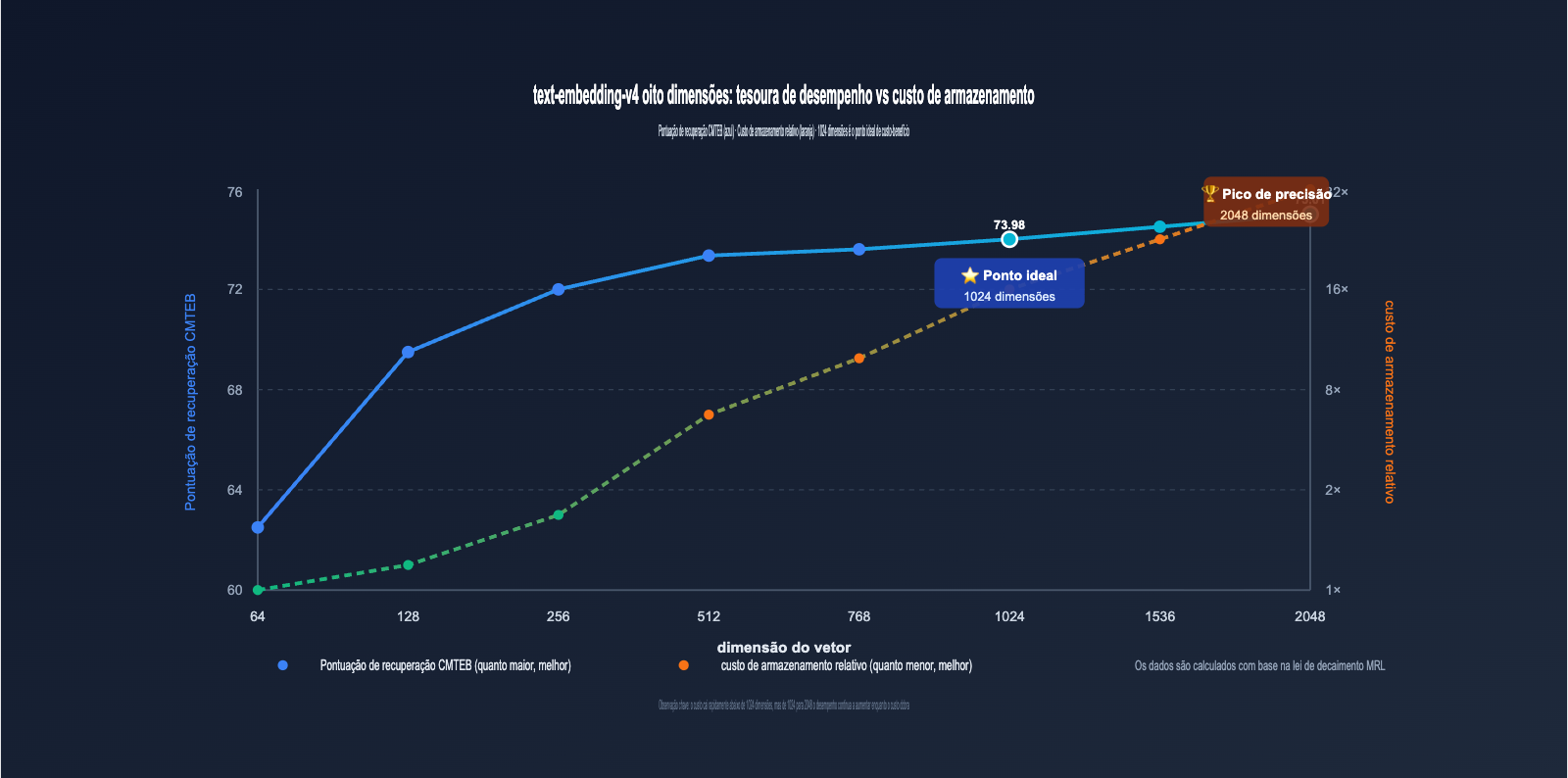
3.2 Lei de decaimento da perda de dimensão do text-embedding-v4
Ao visualizar os dados da tabela acima, podemos observar uma regra muito importante:
- 2048 → 1024 dimensões: o MTEB cai apenas 3,22 pontos (≈4,5%), mas o armazenamento cai pela metade ⭐️ Altamente recomendado.
- 1024 → 512 dimensões: o MTEB cai 3,63 pontos (≈5,3%), e o armazenamento cai pela metade novamente 👍 Aceitável.
- 512 → 256 dimensões: o MTEB cai cerca de 2 pontos (≈3,0%), e o armazenamento cai pela metade novamente ⚠️ Depende do cenário.
- 256 → 128 dimensões: o MTEB cai cerca de 2,5 pontos (≈4,0%), ainda utilizável ⚠️ Requer testes completos.
- 128 → 64 dimensões: o MTEB cai cerca de 2,5 pontos, mas o subitem Retrieval despenca 6 pontos ❌ Não recomendado para produção.
Isso mostra que a "faixa de decaimento seguro" do MRL está principalmente acima de 256 dimensões, enquanto 64 dimensões pertencem à zona de compressão extrema.
IV. O papel das dimensões vetoriais: 3 impactos fundamentais
O impacto de diferentes dimensões no sistema é abrangente, indo muito além da precisão da recuperação. Abaixo, detalhamos as 3 dimensões mais importantes.
4.1 Impacto das dimensões vetoriais na precisão da recuperação
A precisão é o impacto mais intuitivo. Tomando como exemplo um sistema RAG com 1 milhão de documentos:
- Usando 2048 dimensões: Taxa de recall Top-10 de aproximadamente 91%
- Usando 1024 dimensões: Taxa de recall Top-10 de aproximadamente 88%
- Usando 256 dimensões: Taxa de recall Top-10 de aproximadamente 84%
- Usando 64 dimensões: Taxa de recall Top-10 de aproximadamente 75%
🎯 Sugestão de escolha: Se o seu negócio é altamente sensível à taxa de recall (como em pesquisas jurídicas ou perguntas e respostas médicas), priorize 1024 ou 2048 dimensões. Recomendamos executar primeiro uma rodada de comparação entre 1024 vs 2048 na plataforma APIYI (apiyi.com) usando o mesmo conjunto de testes antes de tomar uma decisão final.
4.2 Impacto das dimensões vetoriais nos custos de armazenamento e recuperação
Este é o indicador que mais preocupa em implementações de nível empresarial. Suponha que um sistema armazene 100 milhões de vetores:
| Dimensão Vetorial | Armazenamento Total (float32) | Custo Mensal de Armazenamento (est.) | Latência de Recuperação Única (est.) |
|---|---|---|---|
| 2048 dim. | 800 GB | Alto | Lento |
| 1024 dim. | 400 GB | Médio | Médio |
| 512 dim. | 200 GB | Baixo | Rápido |
| 256 dim. | 100 GB | Baixo | Rápido |
| 128 dim. | 50 GB | Muito baixo | Muito rápido |
| 64 dim. | 25 GB | Muito baixo | Muito rápido |
Como se pode observar, ao reduzir de 2048 para 256 dimensões, o custo de armazenamento cai para 1/8 e a velocidade de recuperação pode ser de 6 a 8 vezes mais rápida (dependendo do algoritmo de índice ANN). Para escalas de dados acima de cem milhões, a escolha da dimensão afeta diretamente a ordem de grandeza dos custos de infraestrutura.
4.3 Impacto das dimensões vetoriais na compatibilidade e custos de migração
Muitas equipes que migram do OpenAI, BGE ou Cohere para o text-embedding-v4 preocupam-se com a incompatibilidade das dimensões vetoriais, o que poderia inutilizar índices antigos. As 8 opções de dimensões do v4 oferecem um caminho de migração muito amigável:
| Modelo Antigo | Dimensão Antiga | Dimensão Recomendada para text-embedding-v4 | Observações de Migração |
|---|---|---|---|
| OpenAI ada-002 | 1536 | 1536 dim. | Alinhamento de dimensão, estrutura de índice reutilizável |
| OpenAI text-embedding-3-small | 1536 | 1536 dim. | Alinhamento total |
| OpenAI text-embedding-3-large | 3072 | 2048 dim. | Ligeiramente menor, mas com precisão superior |
| BGE-large | 1024 | 1024 dim. | Alinhamento total, substituição suave |
| BGE-base | 768 | 768 dim. | Alinhamento total |
| Cohere embed-multilingual-v3 | 1024 | 1024 dim. | Alinhamento total |
| Modelo small auto-treinado | 256/512 | 256/512 dim. | Compatibilidade de dimensão |
💼 Sugestão de migração empresarial: Muitos bancos de vetores de sistemas legados (Milvus / Qdrant / pgvector) possuem tabelas criadas com dimensões fixas. Comece selecionando uma versão do text-embedding-v4 com a mesma dimensão do sistema antigo para uma substituição suave e, em seguida, faça uma atualização progressiva para dimensões maiores conforme necessário. Este é o caminho de menor resistência. Também fornecemos exemplos de código de integração para os principais bancos de dados vetoriais na documentação da APIYI (apiyi.com).
V. Primeiros passos com text-embedding-v4: Chamada de API e parâmetros de dimensão
Agora que explicamos os princípios técnicos, vamos ao código. Abaixo, apresentamos o exemplo de chamada mais conciso, cobrindo tanto o protocolo compatível com OpenAI quanto o protocolo nativo DashScope.
5.1 Chamando o text-embedding-v4 usando o protocolo compatível com OpenAI
O DashScope da Alibaba Cloud também fornece endpoints compatíveis com OpenAI, o que é ideal para equipes que já possuem integrações com OpenAI.
from openai import OpenAI
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # Ponto de acesso unificado APIYI
)
# Chamando o text-embedding-v4, especificando 1024 dimensões
response = client.embeddings.create(
model="text-embedding-v4",
input="Como configurar a dimensão vetorial do text-embedding-v4?",
dimensions=1024 # Opcional: 64/128/256/512/768/1024/1536/2048
)
vector = response.data[0].embedding
print(f"Dimensão: {len(vector)}") # Saída: Dimensão: 1024
print(f"Primeiras 5 dimensões: {vector[:5]}")
⚙️ Explicação dos parâmetros:
dimensionsé o novo parâmetro chave do v4 (suportado desde o v3, mas expandido para 8 opções no v4). Se este parâmetro for omitido, o padrão utilizado será 1024 dimensões.
5.2 Chamada em lote: Concorrência e limite de taxa do text-embedding-v4
Em ambientes de produção reais, muitas vezes é necessário processar dados em lote. O text-embedding-v4 suporta até 25 entradas por chamada:
texts = [
"O papel central das dimensões vetoriais é equilibrar precisão e custo",
"O text-embedding-v4 suporta 8 dimensões, de 64 a 2048",
"O aprendizado de representação Matryoshka é a tecnologia chave",
# ... até 25 itens
]
response = client.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=512
)
vectors = [item.embedding for item in response.data]
print(f"Número de vetores em lote: {len(vectors)}")
5.3 Codificação assimétrica para query e document
O text-embedding-v4 suporta recursos avançados não fornecidos pelo protocolo OpenAI: o uso de text_type para distinguir entre consultas de busca (query) e documentos buscados (document), melhorando ainda mais a precisão da recuperação. Este recurso requer o uso do protocolo nativo DashScope ou do encapsulamento compatível da plataforma APIYI:
# Codificação do lado do documento (ao criar o índice)
doc_response = client.embeddings.create(
model="text-embedding-v4",
input=["O text-embedding-v4 oferece 8 opções de dimensões vetoriais"],
dimensions=1024,
extra_body={"text_type": "document"}
)
# Codificação do lado da consulta (ao realizar a busca)
query_response = client.embeddings.create(
model="text-embedding-v4",
input=["Quais dimensões o v4 suporta?"],
dimensions=1024,
extra_body={"text_type": "query"}
)
💡 Valor da codificação assimétrica: Após usar a codificação diferenciada para query/document, a taxa de recall Top-1 pode geralmente aumentar de 2 a 3 pontos percentuais em cenários de busca com consultas curtas e documentos longos. Recomendamos fortemente ativar este recurso em ambientes de produção.
5.4 Integração do text-embedding-v4 com bancos de dados vetoriais
O armazenamento de vetores é uma etapa crucial na implementação de sistemas RAG. Abaixo, usamos o Qdrant, amplamente utilizado no setor, para mostrar o fluxo completo, desde o embedding de texto até o armazenamento:
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from openai import OpenAI
# Inicializar cliente
embedder = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1"
)
qdrant = QdrantClient(url="http://localhost:6333")
# Chave: a dimensão da collection deve ser consistente com as dimensões do embedding
DIMENSION = 1024
qdrant.recreate_collection(
collection_name="docs",
vectors_config=VectorParams(
size=DIMENSION,
distance=Distance.COSINE
)
)
# Embedding em lote e armazenamento
texts = ["O text-embedding-v4 é o mais recente modelo de embedding da Alibaba Tongyi", "..."]
response = embedder.embeddings.create(
model="text-embedding-v4",
input=texts,
dimensions=DIMENSION
)
points = [
PointStruct(id=i, vector=item.embedding, payload={"text": texts[i]})
for i, item in enumerate(response.data)
]
qdrant.upsert(collection_name="docs", points=points)
⚠️ Lembrete importante: O campo
sizedo banco de dados vetorial deve ser estritamente igual àsdimensions. Se desejar atualizar a dimensão posteriormente, será necessário recriar a collection e realizar um novo embedding de todos os dados.
5.5 Integração do text-embedding-v4 com LangChain / LlamaIndex
Os principais frameworks RAG já suportam a integração de embeddings via protocolo compatível com OpenAI, e a configuração é muito simples:
# Exemplo de integração com LangChain
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-v4",
openai_api_key="your-apiyi-key",
openai_api_base="https://vip.apiyi.com/v1",
dimensions=1024
)
# Integração perfeita com bancos de dados vetoriais do LangChain
vectors = embeddings.embed_documents(["doc1", "doc2"])
query_vec = embeddings.embed_query("Como escolher a dimensão?")
Ao utilizar a conexão via protocolo compatível com OpenAI, quase todos os projetos RAG baseados originalmente em OpenAI ada-002 / 3-large podem ser migrados para o text-embedding-v4 sem necessidade de alterar o código, bastando apenas modificar os parâmetros model e base_url.
VI. Estratégia de seleção de dimensões para o text-embedding-v4: 5 cenários típicos
Agora que já entendemos a teoria e a interface, vamos apresentar um framework de seleção que você pode aplicar diretamente.
6.1 Cenário A: RAG para base de conhecimento corporativa (milhões de documentos)
Requisito principal: Precisão de recuperação > Custo
Configuração recomendada:
- Dimensão: 1024 dimensões (valor padrão, melhor custo-benefício)
- Habilitar codificação assimétrica de consulta/documento
- Banco de vetores compatível: Milvus / Qdrant / pgvector
- Re-ranking: Recomendamos usar o Qwen3-Reranker
6.2 Cenário B: Busca de produtos em e-commerce (milhões de SKUs)
Requisito principal: Velocidade de busca > Precisão
Configuração recomendada:
- Dimensão: 512 dimensões (equilibrado) ou 256 dimensões (velocidade máxima)
- Use codificação de consulta para títulos de produtos e codificação de documento para detalhes
- Índice ANN recomendado: combinação de HNSW + IVF
6.3 Cenário C: Deduplicação de logs em larga escala (centenas de milhões de logs)
Requisito principal: Custo de armazenamento > Precisão
Configuração recomendada:
- Dimensão: 128 dimensões
- Use quantização binária (Binary Quantization) para comprimir em até 32 vezes
- Testes práticos mostram que a taxa de recuperação ainda se mantém acima de 85%
6.4 Cenário D: Busca de alta precisão (Jurídico / Médico)
Requisito principal: Precisão em primeiro lugar, custo não é um fator sensível
Configuração recomendada:
- Dimensão: 2048 dimensões
- Habilitar codificação assimétrica de consulta/documento
- É essencial adicionar um Reranker para reordenar os resultados
6.5 Cenário E: Dispositivos móveis / Busca local em dispositivos de borda
Requisito principal: Uso de memória < 50 MB
Configuração recomendada:
- Dimensão: 64 dimensões ou 128 dimensões
- Use quantização int8 (compressão adicional de 4 vezes)
- Adequado para bases de conhecimento locais / assistentes de perguntas e respostas offline
🎯 Dica de decisão: Os 5 cenários acima cobrem a maioria das necessidades reais. Nossa recomendação: comece com o padrão de 1024 dimensões para rodar seu conjunto de testes e, em seguida, ajuste para cima (2048) ou para baixo (512/256/128) conforme a necessidade real de precisão, custo e velocidade. A plataforma APIYI (apiyi.com) suporta a troca de parâmetros de dimensão com um clique, facilitando testes A/B rápidos.
6.6 Fluxo de decisão para seleção de dimensões
Transformamos os cenários acima em um fluxo de decisão executável:
-
Passo 1: Avalie o volume de dados
- < 1 milhão de registros → Dimensão pode ser alta (1024+)
- 1 milhão a 100 milhões → Dimensão média (256-1024)
-
100 milhões → Considere obrigatoriamente dimensões baixas (128-512)
-
Passo 2: Avalie a tolerância à precisão
- Sensível a cada 1% de taxa de recuperação → Escolha 2048
- Aceita uma queda de 5% na recuperação → Comece com 1024
- Aceita uma queda de 10% na recuperação → 256-512 é suficiente
-
Passo 3: Avalie as restrições de hardware
- Busca em GPU na nuvem → Dimensão pode ser alta
- Busca apenas em CPU → Mantenha abaixo de 1024
- Dispositivos móveis / borda → Forçar 64-256 dimensões + quantização
-
Passo 4: Execute testes práticos
- Selecione de 100 a 500 consultas reais do negócio como conjunto de avaliação
- Calcule a taxa de recuperação Top-10 em diferentes dimensões
- Escolha a menor dimensão antes do "ponto de inflexão" da taxa de recuperação
💡 Dica de eficiência: O processo acima envolve múltiplas invocações de modelo e trocas de parâmetros. Recomendamos realizar isso em uma plataforma de integração unificada para obter logs de requisição completos e monitoramento de uso, facilitando a colaboração da equipe na comparação de modelos.
VII. Comparação do text-embedding-v4 com modelos de embedding convencionais
Vamos colocar o text-embedding-v4 no mapa da indústria para facilitar sua escolha técnica.
| Modelo | Fabricante | Dimensão Máx. | Flexibilidade | MTEB Geral | Capacidade Chinês | Janela de Contexto | Preço API |
|---|---|---|---|---|---|---|---|
| text-embedding-v4 | Alibaba Tongyi | 2048 | ⭐⭐⭐⭐⭐ (8 tipos) | 71.58 | Altíssima | 32K | Médio |
| text-embedding-3-large | OpenAI | 3072 | ⭐⭐⭐⭐ (qualquer) | 64.6 | Médio | 8K | Alto |
| text-embedding-3-small | OpenAI | 1536 | ⭐⭐⭐⭐ (qualquer) | 62.3 | Médio | 8K | Baixo |
| Cohere embed-v4 | Cohere | 1536 | ⭐⭐⭐ (4 tipos) | 70.3 | Forte | 128K | Médio-Alto |
| BGE-M3 | BAAI | 1024 | ⭐⭐ (fixo) | 65.5 | Forte | 8K | Auto-hospedado |
| Voyage-3 | Voyage AI | 1024 | ⭐⭐⭐ (3 tipos) | 67.1 | Médio | 32K | Médio |
| Qwen3-Embedding-8B (Open Source) | Alibaba Tongyi | 4096 | ⭐⭐⭐⭐⭐ (qualquer) | 70.58 | Altíssima | 32K | Auto-hospedado |
Desta tabela comparativa, podemos extrair algumas conclusões importantes:
- Cenários bilíngues (Chinês/Inglês): A pontuação CMTEB de 71.99 do text-embedding-v4 ocupa o primeiro lugar entre todas as APIs comerciais.
- Flexibilidade de dimensão: As 8 dimensões recomendadas oficialmente pelo v4 são mais flexíveis que a maioria dos modelos, tornando a migração extremamente fácil.
- Custo-benefício: O preço da API do v4 está em um nível médio entre os modelos comerciais convencionais, mas sua precisão se equipara ao text-embedding-3-large da OpenAI.
📌 Dica de integração: Se sua equipe precisa usar modelos de vários fornecedores como OpenAI, Claude e Qwen simultaneamente, recomendamos o uso de um serviço proxy de API unificado como o APIYI (apiyi.com). Isso evita o gerenciamento de múltiplas chaves API e resolve problemas de acesso. A documentação também inclui exemplos de invocação paralela do v4 com outros modelos de embedding convencionais.
VIII. FAQ sobre o text-embedding-v4
Q1: Qual é a dimensão padrão do text-embedding-v4?
A dimensão padrão do text-embedding-v4 é 1024. Se você não passar explicitamente o parâmetro dimensions durante a invocação do modelo, o retorno será um vetor de 1024 dimensões. Esta é também a dimensão recomendada oficialmente pela Alibaba por oferecer o melhor custo-benefício.
Q2: Já criei um índice com 1024 dimensões, posso atualizar para 2048?
É necessário reconstruir todo o banco de vetores. O mecanismo de "boneca russa" (MRL) garante que "pegar os primeiros N elementos de um vetor de alta dimensão" equivale a um vetor de baixa dimensão, mas o inverso — "preencher com zeros para subir de baixa para alta dimensão" — não é eficaz. Ao atualizar, sugerimos:
- Manter o índice antigo de 1024 dimensões em serviço.
- Realizar um novo embedding completo dos documentos com o v4 em 2048 dimensões.
- Fazer uma transição gradual (canary deployment) para validar o ganho de precisão.
- Desativar o índice antigo após a conclusão.
Q3: O text-embedding-v4 pode ser chamado diretamente no Brasil?
O endpoint oficial do text-embedding-v4 está localizado em dashscope.aliyuncs.com (Pequim). Desenvolvedores podem utilizar o serviço diretamente. Basta registrar uma conta na Alibaba Cloud ou obter uma chave API através de plataformas de serviço proxy de API como a APIYI (apiyi.com), sem necessidade de configurações de rede adicionais.
Q4: Como escolher entre o text-embedding-v4 e a versão open source Qwen3-Embedding?
| Fator de Decisão | Escolher versão API (v4) | Escolher versão Open Source (Qwen3-Embedding-8B) |
|---|---|---|
| Sensibilidade de dados | Sensibilidade comum | Extremamente sensível (Financeiro/Saúde) |
| Volume mensal | < 1 bilhão de Tokens | > 1 bilhão de Tokens |
| Recursos de GPU | Nenhum | Possui clusters A100/H100 |
| Capacidade de engenharia | Equipes pequenas/médias | Possui equipe de MLOps |
| Sugestão geral | ✅ Recomendado: v4 API | ✅ Recomendado: Auto-hospedagem |
Q5: Se eu definir a dimensão incorretamente, o modelo retornará erro?
O text-embedding-v4 aceita apenas valores dentro de [64, 128, 256, 512, 768, 1024, 1536, 2048]. Passar outros valores (como 333 ou 500) resultará em um erro de parâmetro. Se precisar de uma dimensão não padrão, escolha a dimensão oficial mais próxima e realize o truncamento ou preenchimento posteriormente.
Q6: Como avaliar qual dimensão escolher para o meu negócio?
Recomendamos um método de três etapas:
- Estabelecer a linha de base: Execute o fluxo de negócios com a dimensão padrão de 1024 e registre a taxa de recall, latência e custos de armazenamento.
- Testar para baixo: Alterne sucessivamente para 512, 256 e 128 dimensões e observe a queda na taxa de recall.
- Encontrar o ponto ideal: Identifique a dimensão onde a "queda na taxa de recall é aceitável + redução de custo é máxima", geralmente em 256 ou 512 dimensões.
Q7: O text-embedding-v4 será disponibilizado como open source?
A estratégia atual da Alibaba é manter a versão API e a versão open source em paralelo: a API comercial do text-embedding-v4 continua sendo iterada, beneficiando-se das otimizações de engenharia e aprimoramentos de dados mais recentes; enquanto a versão open source disponibiliza a série Qwen3-Embedding para a comunidade. Ambos compartilham a mesma tecnologia, mas possuem formatos de produto distintos. Não há previsão de abertura do código do v4.
Q8: Quanto maior a dimensão, melhor?
Não. A escolha da dimensão é, essencialmente, um equilíbrio entre precisão, armazenamento e velocidade:
- Dimensão maior → Teto de precisão mais alto, mas com retornos decrescentes.
- Dimensão maior → Custos de armazenamento e busca crescem de forma linear ou superlinear.
- Dimensão maior → Em casos de "maldição da dimensionalidade", a precisão do índice ANN pode até cair.
Por experiência, 256-1024 dimensões é a faixa ideal para a maioria dos negócios. Acima de 1024, só vale a pena se houver uma necessidade clara de ganho de precisão.
Q9: Como é o desempenho do text-embedding-v4 em textos longos?
O text-embedding-v4 suporta uma entrada máxima de 32K Tokens, mas a eficácia da busca diminui conforme o comprimento do texto aumenta. Sugerimos seguir estes princípios:
- Textos curtos (< 512 Tokens): Embedding direto do parágrafo, melhor resultado.
- Comprimento médio (512-4K Tokens): Considere o uso de janelas deslizantes para segmentação.
- Documentos longos (> 4K Tokens): É obrigatório segmentar (chunk) antes do embedding; o tamanho sugerido do bloco é de 256-512 Tokens.
- Documentos super longos: Combine com busca hierárquica (primeiro grosseira, depois refinada) para aumentar a eficiência.
Q10: Posso misturar dimensões diferentes?
Não. Todos os vetores em um mesmo banco de dados ou índice devem ter a mesma dimensão, caso contrário, o cálculo de similaridade não terá sentido. Se o seu negócio realmente exige uma estratégia de "documentos de alta prioridade com 2048 dimensões + documentos comuns com 512", sugerimos criar duas coleções independentes e gerenciar a fusão dos resultados na camada de aplicação.
Q11: O parâmetro de dimensão afeta a cobrança da API?
A cobrança do text-embedding-v4 baseia-se inteiramente no número de Tokens de entrada, independentemente da dimensão de saída. Ou seja, não importa se você escolhe 64 ou 2048 dimensões, o custo para processar 1000 Tokens de entrada é o mesmo. Isso significa que você pode escolher dimensões maiores sem medo na fase de chamada da API; a diferença real de custo ocorre nas etapas de armazenamento e busca a jusante.
Q12: Como lidar com falhas de embedding ou limitação de taxa (rate limiting)?
Ao chamar o text-embedding-v4 em ambiente de produção, recomendamos implementar as seguintes práticas de robustez:
- Mecanismo de retentativa: Implemente retentativa com espera exponencial (sugerido 3 vezes) para erros 5xx.
- Tratamento de limitação: Monitore erros 429; se ocorrerem, reduza a concorrência ou alterne o canal de acesso.
- Tamanho do lote: Máximo de 25 textos por solicitação; divida automaticamente se exceder.
- Configuração de timeout: Para embeddings de textos longos, defina o timeout para 60 segundos ou mais.
- Plano de contingência: Configure um modelo reserva (como o v3 de 1024 dimensões) como fallback.
IX. Resumo: Pontos principais para a seleção de dimensões do text-embedding-v4
Revisando o conteúdo, os pontos centrais sobre as 8 dimensões do text-embedding-v4 são:
- O text-embedding-v4 é o carro-chefe comercial da série Qwen3-Embedding, com desempenho líder em cenários bilíngues (Chinês/Inglês) com MTEB 71.58 / CMTEB 71.99.
- As 8 dimensões são fruto da tecnologia Matryoshka, permitindo o uso dos primeiros N elementos com perda de qualidade controlada.
- 1024 dimensões é o valor padrão recomendado, equilibrando precisão e custo.
- 2048 dimensões são ideais para precisão extrema, oferecendo um ganho de 1 ponto no CMTEB Retrieval em comparação com 1024.
- 256-512 dimensões são ideais para escala média + sensibilidade a custos, sendo o ponto ideal para a maioria dos sistemas RAG.
- 64-128 dimensões são recomendadas apenas para dispositivos de borda ou armazenamento extremo, exigindo testes rigorosos de decaimento de recall.
- A escolha da dimensão não é definitiva, recomendamos fortemente rodar testes com seu conjunto de dados antes da decisão final.
- Ao migrar de outros modelos para o v4, priorize a versão com dimensão alinhada para uma transição suave.
🎯 Sugestão final: Se você está selecionando um modelo de embedding para um novo projeto, comece diretamente com text-embedding-v4 + 1024 dimensões; se o negócio for altamente sensível à taxa de recall, suba para 2048 dimensões e adicione um Reranker. Recomendamos o acesso via plataforma APIYI (apiyi.com), que oferece uma interface unificada compatível com OpenAI, alternância conveniente de dimensões e documentação completa, reduzindo significativamente o custo de engenharia e permitindo que sua equipe foque na otimização dos resultados de negócio em vez da adaptação da API.
A tecnologia de embedding vetorial está evoluindo rapidamente. Da era das dimensões fixas da OpenAI até o text-embedding-v4, que traz o MRL para 8 dimensões oficiais, os desenvolvedores ganharam uma flexibilidade sem precedentes. Dominar a essência e as estratégias de seleção de dimensões vetoriais é uma habilidade essencial para qualquer equipe que constrói sistemas de RAG, busca semântica ou sistemas de recomendação.
Autor: Equipe Técnica APIYI | Focados na implementação prática de modelos de linguagem grande (LLMs). Para mais conteúdos técnicos, visite APIYI em apiyi.com