description: 阿里巴巴通义千问 Qwen3.5-Omni 原生多模态模型深度解析:详解 Thinker-Talker MoE 架构、256K 上下文、音视频编码及 Audio-Visual Vibe Coding 涌现能力。
作者注:详解阿里通义千问 Qwen3.5-Omni 原生多模态模型的 Thinker-Talker MoE 架构、256K 上下文、音视频编码能力以及 Audio-Visual Vibe Coding 涌现能力
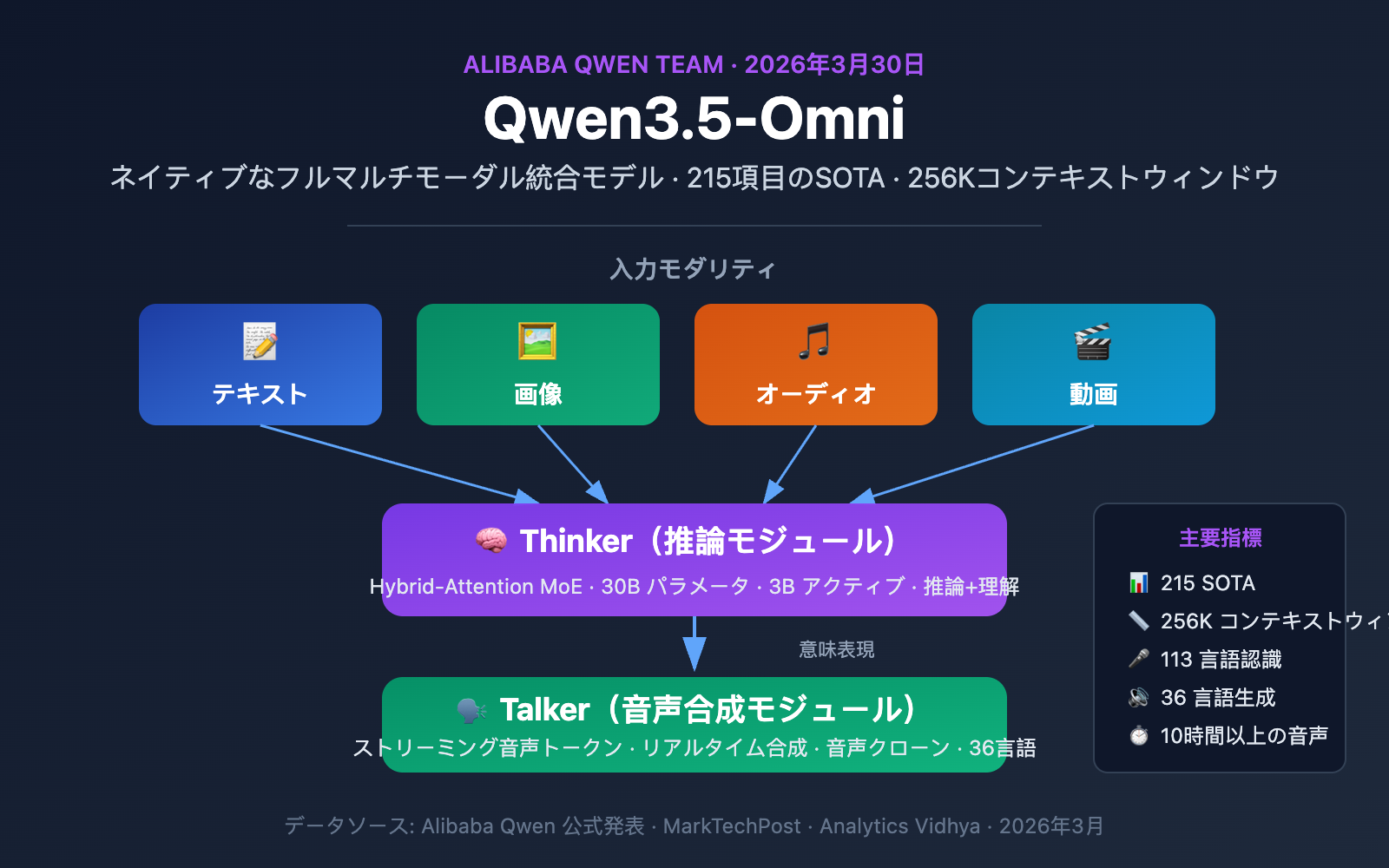
阿里巴巴通义千问团队于 2026 年 3 月 30 日正式发布了 Qwen3.5-Omni,这是一款在单一计算管道内同时处理文本、图像、音频和视频四种模态的原生多模态统一模型。作为阿里 3-4 月密集发布攻势的组成部分,Qwen3.5-Omni 在 215 项基准测试中达到 SOTA,标志着中国 AI 厂商在全模态大模型领域的重要突破。
核心价值: 3 分钟了解 Qwen3.5-Omni 的 Thinker-Talker 架构设计、三种模型变体的选择策略,以及 Audio-Visual Vibe Coding 涌现能力。
Qwen3.5-Omni 多模态模型核心信息
Qwen3.5-Omni 关键参数速览
| 参数项 | 详情 |
|---|---|
| 发布日期 | 2026 年 3 月 30 日 |
| 发布方 | 阿里巴巴通义千问(Qwen)团队 |
| 架构 | Thinker-Talker + Hybrid-Attention MoE |
| 模型变体 | Plus(30B-A3B MoE)、Flash(轻量 MoE)、Light(稠密模型/开放权重) |
| 上下文窗口 | 256K Token |
| 音频容量 | 10+ 小时连续音频 |
| 视频容量 | 400+ 秒 720p 视频(1 FPS 采样) |
| 语音识别 | 113 种语言和方言(前代仅 19 种) |
| 语音生成 | 36 种语言(前代仅 10 种) |
| 训练数据 | 超过 1 亿小时音视频数据 |
| 基准成绩 | 215 项音频/视频理解基准达到 SOTA |
Qwen3.5-Omni 模型定位
Qwen3.5-Omni 的核心意义在于原生多模态——这不是一个文本模型外接音频和视频模块的拼装方案,而是从头开始在超过 1 亿小时音视频数据上预训练的统一模型。所有模态在同一个计算管道中处理,这意味着模型可以真正理解音频和视频中的语义信息,而非简单地将音视频转录为文本后再处理。
同时,Qwen3.5-Omni 是阿里在 2026 年 3-4 月密集发布的系列模型之一。仅数天后的 4 月 2 日,阿里又发布了面向企业级应用的 Qwen3.6-Plus 模型(支持 100 万 Token 上下文,主攻代理式编程),显示出阿里在大模型领域的强劲投入。
title: Qwen3.5-Omni Thinker-Talker アーキテクチャの詳細解説
description: Qwen3.5-Omniの革新的なThinker-Talkerアーキテクチャ、MoE設計、およびAPI活用ガイドを詳しく解説。マルチモーダルAIの構築に役立つ情報を提供します。
Qwen3.5-Omni Thinker-Talker アーキテクチャの詳細解説
Thinker-Talker デュアルモジュール設計
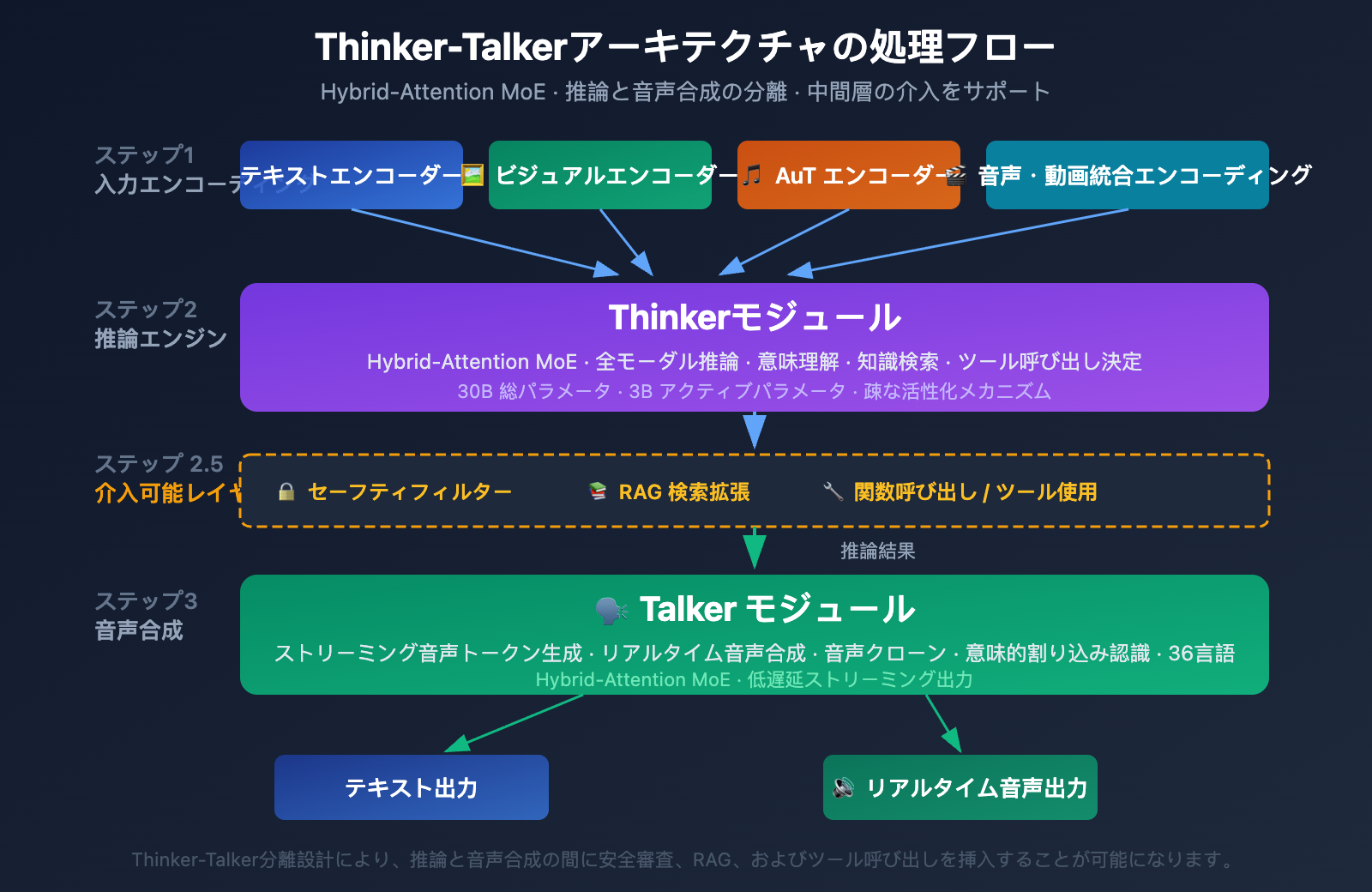
Qwen3.5-Omni は、Qwen2.5-Omni で初めて導入された独自の Thinker-Talker デュアルモジュールアーキテクチャを採用しています。3.5 バージョンでは、両方のモジュールに Hybrid-Attention MoE(混合注意力エキスパート混合)アーキテクチャが採用されるという大幅なアップグレードが行われました。
Thinker モジュール(思考者):
- すべての入力モダリティ(テキスト、画像、音声、動画)を処理
- 推論および理解タスクを実行
- 内部的な推論表現を生成
- ネイティブの Audio Transformer(AuT)エンコーダーを使用して音声を処理
- 構造化された意味表現を出力
Talker モジュール(表現者):
- Thinker からの推論表現を受け取る
- 意味表現をストリーミング音声トークンに変換
- リアルタイムの音声合成をサポート
- 自然な音声表現(抑揚、感情、間など)を実現
Thinker-Talker アーキテクチャのエンジニアリング価値
この分離型設計がもたらす核心的な利点は中間介入の可能性です。外部システム(RAG 検索パイプライン、安全フィルター、関数呼び出しなど)が、Thinker の出力と Talker の合成の間で介入できます。これは以下を意味します。
- 企業は音声出力前に安全審査を追加できる
- 開発者は推論結果に基づいてツール呼び出しをトリガーできる
- RAG システムは回答前に知識検索結果を補足できる
MoE 疎結合活性化メカニズム
Hybrid-Attention MoE 設計の核心は**疎結合活性化(Sparse Activation)**です。モデルは各トークンを処理する際に一部のパラメータのみを活性化します(総パラメータ 30B に対して、アクティブなのはわずか 3B)。このメカニズムにより、モデルは高いキャパシティを維持しながら、単一推論の計算コストを許容範囲内に抑えることができ、リアルタイムアプリケーション(音声対話など)において極めて重要となります。
🎯 開発アドバイス: Qwen3.5-Omni の Thinker-Talker 分離アーキテクチャは、マルチステップの AI ワークフロー構築に最適です。独自のアプリケーションにマルチモーダル機能を統合したい場合は、APIYI (apiyi.com) プラットフォームを通じて、Qwen3.5-Omni と他の主要なマルチモーダルモデルの効果の違いを素早くテストできます。
Qwen3.5-Omni 3つのモデルバリエーション比較
Plus / Flash / Light 選択ガイド
Qwen3.5-Omni は、異なるシナリオに対応する 3 つのモデルバリエーションを提供しています。
| バリエーション | アーキテクチャタイプ | パラメータ規模 | 利用方法 | 適用シナリオ |
|---|---|---|---|---|
| Plus | MoE(30B-A3B) | 総 30B / アクティブ 3B | API(DashScope) | 最高品質の推論、複雑なマルチモーダルタスク |
| Flash | 軽量 MoE | より少ないパラメータ | API(DashScope) | 低遅延シナリオ、リアルタイム対話 |
| Light | 密結合モデル | 小規模 | オープンウェイト(HuggingFace) | ローカルデプロイ、エッジデバイス |
選択のアドバイス:
- 最高の結果を追求する → Plus バリエーションを選択(215 のベンチマークテストで最高スコアを記録)
- 低遅延を追求する → Flash バリエーションを選択(リアルタイム音声対話やストリーミング対話に最適)
- ローカルデプロイが必要 → Light バリエーションを選択(オープンウェイトでローカル GPU 上で実行可能)
Qwen3.5-Omni API 接続方法
Qwen3.5-Omni の API は標準的な /v1/chat/completions 形式に従っており、modalities パラメータで出力タイプを指定します。
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI を通じて統合接続
)
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "この動画の内容を分析してください"},
{"type": "video_url", "video_url": {"url": "https://example.com/video.mp4"}}
]
}
]
)
マルチモーダル入力の完全なサンプルを表示
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 画像 + 音声 + テキストのマルチモーダル入力
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "画像と音声の説明に基づいて分析レポートを作成してください"},
{
"type": "image_url",
"image_url": {"url": "data:image/png;base64,..."}
},
{
"type": "input_audio",
"input_audio": {
"data": base64.b64encode(audio_bytes).decode(),
"format": "wav"
}
}
]
}
],
max_tokens=2000
)
# テキストの回答を取得
print(response.choices[0].message.content)
# 音声出力がリクエストされている場合、音声データを取得
if hasattr(response.choices[0].message, 'audio'):
audio_data = response.choices[0].message.audio
print(f"音声フォーマット: {audio_data.format}")
💡 接続のヒント: Qwen3.5-Omni の API は OpenAI SDK 形式と互換性があります。すでに OpenAI SDK ベースのコードをお持ちの場合は、
base_urlとmodelパラメータを変更するだけで素早く切り替えが可能です。APIYI (apiyi.com) プラットフォームを通じて、Qwen3.5-Omni や GPT-4o などのモデルのマルチモーダル効果を同時にテストできます。
Qwen3.5-Omni ベンチマーク性能分析
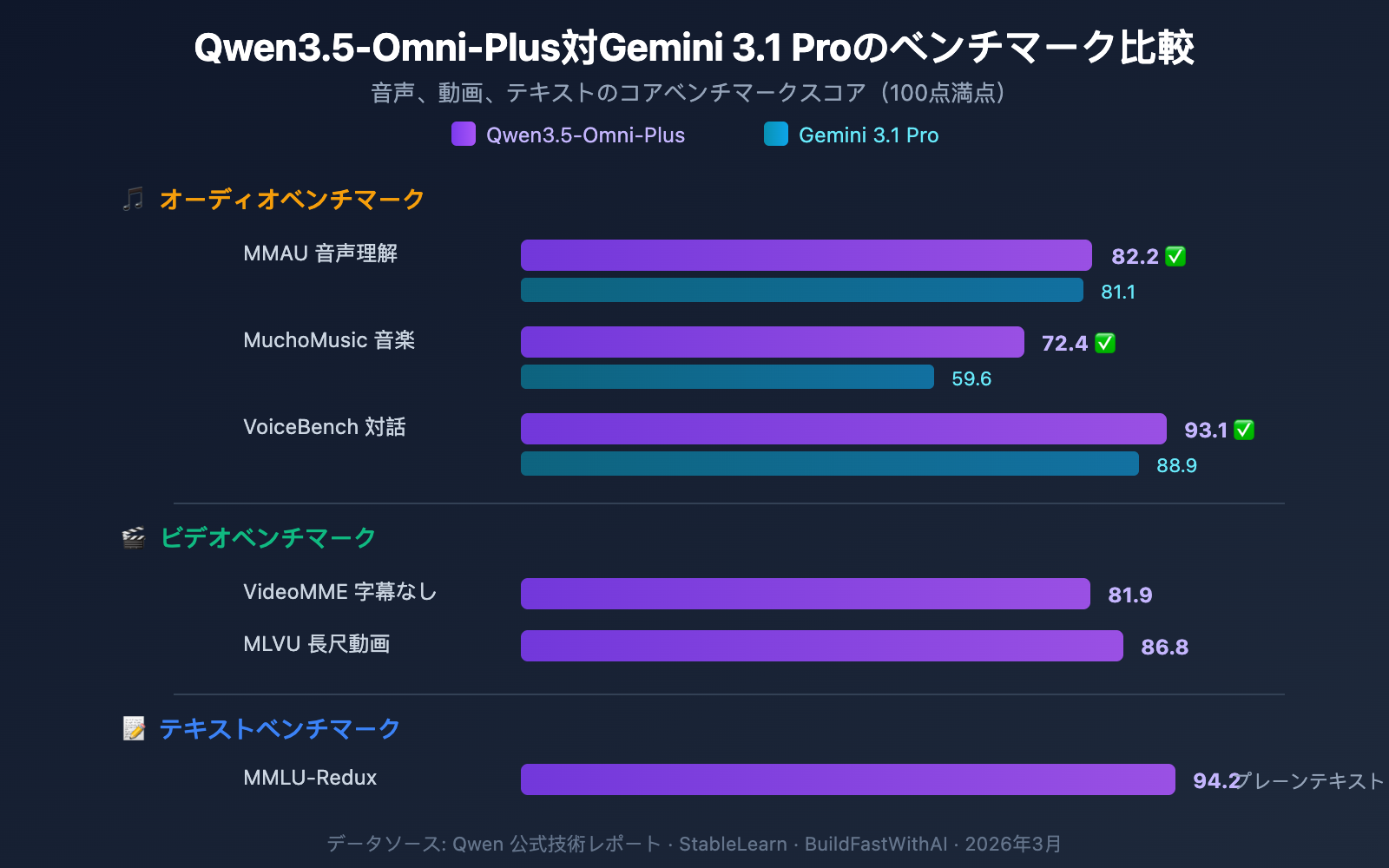
音声理解能力
Qwen3.5-Omni-Plus は、音声関連のベンチマークにおいて Google Gemini 3.1 Pro を全面的に上回っています。
| ベンチマーク | Qwen3.5-Omni-Plus | Gemini 3.1 Pro | 勝者 |
|---|---|---|---|
| MMAU 音声理解 | 82.2 | 81.1 | Qwen |
| MuchoMusic 音楽理解 | 72.4 | 59.6 | Qwen(+21%) |
| VoiceBench 対話 | 93.1 | 88.9 | Qwen |
特に音楽理解(MuchoMusic)において、Qwen3.5-Omni は 21% という大きな差をつけて優位に立っています。
視覚および動画能力
| ベンチマーク | Qwen3.5-Omni-Plus | 説明 |
|---|---|---|
| MMMU-Pro | 73.9 | マルチモーダル理解で最高スコア |
| RealWorldQA | 84.1 | 実世界ビジュアル質問応答 |
| VideoMME(字幕なし) | 81.9 | 動画マルチモーダル理解 |
| MLVU | 86.8 | 長尺動画理解 |
| MVBench | 79.0 | 多次元動画ベンチマーク |
| LVBench | 71.2 | 長尺動画ベンチマーク |
テキスト推論能力の維持
Qwen3.5-Omni は、全モーダル能力を獲得しながらも、テキスト推論性能はほとんど低下していません。
| ベンチマーク | Qwen3.5-Omni-Plus | Qwen3.5-Plus(テキストのみ) | 差分 |
|---|---|---|---|
| MMLU-Redux | 94.2 | 94.3 | -0.1 |
| C-Eval | 92.0 | 92.3 | -0.3 |
| IFEval | 89.7 | 89.7 | 0 |
これは、Qwen3.5-Omni を選択してもテキスト推論の品質が犠牲にならないことを意味します。つまり、1つのモデルでテキストとマルチモーダルの両方のシナリオをカバーできるのです。
🎯 選定のアドバイス: Qwen3.5-Omni は音声や音楽の理解において明確な強みを持っています。音声対話や音声分析を含むアプリケーションを開発している場合は、このモデルを優先的に検討することをお勧めします。APIYI (apiyi.com) を通じて、具体的なシナリオにおける Qwen3.5-Omni と GPT-4o のパフォーマンスの違いを素早く比較できます。
Qwen3.5-Omni の 3 つの差別化能力
能力 1: Audio-Visual Vibe Coding
Qwen3.5-Omni は、通義千問(Qwen)チームが「Audio-Visual Vibe Coding」と呼ぶ創発的能力を示しています。これは、モデルが動画を視聴し、音声指示を聞くことで、この能力のために特別に訓練されることなく、実行可能なコードを記述できるというものです。
実際のテストでは、モデルは以下のことが可能です。
- 手書きのスケッチ(カメラで撮影)を実行可能な React Web ページに変換する
- 動画のデモと口頭での説明に基づいて機能コードを記述する
- ビジュアルデザインの意図を理解し、それに対応するフロントエンド実装を生成する
この能力は、迅速なプロトタイプ開発やローコード開発のシナリオにおいて非常に価値があります。
能力 2: セマンティックな割り込み認識
従来の音声対話システムは、ユーザーの「うん」「あ」といった応答的なフィードバックと、真の割り込み意図を区別できませんでした。Qwen3.5-Omni は、ネイティブな Turn-Taking Intent Recognition(ターン交代の意図認識) を導入しており、以下を区別できます。
- 応答フィードバック(Backchanneling): 「うん」「はい」など、意味的な割り込み意図のないフィードバック
- セマンティックな割り込み(Semantic Interruption): ユーザーが対話を引き継ぐ明確な意図がある場合
これにより、Qwen3.5-Omni の音声対話体験は、より人間に近い交流を実現しています。
能力 3: 音声クローン
ユーザーが音声録音をアップロードすると、Qwen3.5-Omni はその音声の特徴を学習してクローンを作成し、その後のすべての音声出力でそのクローン音声を使用します。クローンされた音声は、多言語シナリオにおいても自然さと安定性を維持します。
description: アリババの最新AI戦略における「Qwen3.5-Omni」の立ち位置を解説。モデルのリリーススケジュール、オープンソースからクローズドソースへの戦略転換、そしてAPIYIを活用した効率的な開発手法について紹介します。
アリババのAI攻勢におけるQwen3.5-Omniの立ち位置
アリババ 2026年3月〜4月のAIモデルリリーススケジュール
| リリース日 | モデル | 位置付け | 主な特徴 |
|---|---|---|---|
| 3月30日 | Qwen3.5-Omni | ネイティブ・フルモーダルモデル | テキスト/画像/音声/動画の統合処理 |
| 4月2日 | Qwen3.6-Plus | エンタープライズ向けエージェントモデル | 100万トークンのコンテキスト、エージェント型プログラミング |
| 継続更新 | Qwen3-TTS | 音声合成 | オープンソースTTSシリーズ、音声クローン対応 |
この高密度なリリーススケジュールは、アリババが大規模言語モデルの能力構築を全方位で推進していることを示しています。Qwen3.5-Omniはマルチモーダルな認識と理解をカバーし、Qwen3.6-Plusはエンタープライズレベルのコード生成とエージェント能力をカバーしており、両者は相互補完的な関係にあります。
注目すべきは、Qwen3.5-OmniのPlusおよびFlashバリアントがクローズドソースのAPI形式でリリースされた点です。これは、これまでオープンソースを主軸としてきたアリババの戦略からの転換を意味します。WinBuzzerなどのメディアは、これが商業的な圧力下でアリババが利益を重視していることの表れだと分析しており、Bloombergの報道でも「アリババ、利益重視で3つ目のクローズドソースAIモデルを投入」と報じられています。
💰 コストに関するアドバイス: Qwen3.5-Omniを製品に統合することを検討している場合は、まずAPIYI (apiyi.com) プラットフォームの無料枠を利用して概念実証(PoC)を行い、モデルの性能を確認してから本番環境へ導入することをお勧めします。当プラットフォームはQwen、GPT、Claude、Geminiなど全シリーズのモデルをサポートしており、さまざまなシナリオに合わせて柔軟に選択可能です。
よくある質問
Q1: Qwen3.5-Omniはオープンソースですか、それともクローズドソースですか?
Qwen3.5-Omniには3つのバリアントがあります。PlusとFlashは現在、Alibaba Cloud DashScope APIを通じてのみ提供されるクローズドソースですが、LightバリアントのウェイトはHuggingFaceで公開されており、ダウンロード可能です(オープンソース)。前世代のQwen3-OmniはApache 2.0ライセンスで完全にオープンソース化されていましたが、3.5バージョンのPlus/FlashバリアントはAPIオンリーのモデルに移行しました。ローカル環境へのデプロイが必要な場合は、Lightバリアントを選択してください。
Q2: Qwen3.5-OmniとGPT-4oを比較するとどうですか?
音声理解や音楽理解の面では、Qwen3.5-Omni-PlusがGPT-4oを明確にリードしています。動画理解については、それぞれに強みがあります。テキスト推論の面では、Qwen3.5-Omniは自社の純テキストモデルであるQwen3.5-Plusとほぼ同等の性能です。APIYI (apiyi.com) プラットフォームを利用して、実際のアプリケーションシナリオで比較テストを行うことをお勧めします。シナリオによってパフォーマンスに大きな差が出る可能性があるためです。
Q3: Qwen3.5-Omni APIを素早く使い始めるには?
Qwen3.5-OmniのAPIは標準的なOpenAI SDK形式と互換性があるため、導入は非常に簡単です。openai SDKをインストールし、対応するAPIキーとbase_urlを設定するだけで呼び出し可能です。APIYI (apiyi.com) を通じて無料のテスト枠を取得し、本記事のコード例を使ってマルチモーダル呼び出しの効果をすぐに検証してみてください。
まとめ
Qwen3.5-Omni マルチモーダルモデルの主要ポイント:
- ネイティブな全モーダル対応: テキスト、画像、音声、動画の4つのモーダルを単一のパイプラインで統合処理。継ぎ接ぎではない真の統合モデルです。
- Thinker-Talker アーキテクチャ: 推論と音声合成を分離し、中間層での介入やツール呼び出しをサポートします。
- 3つのバリエーション: Plus(最高性能)、Flash(低遅延)、Light(オープンウェイトでローカルデプロイ可能)から選択可能です。
- 215項目のSOTA達成: 音声理解や音楽理解の分野で、Gemini 3.1 Proを大幅にリードしています。
- 創発的能力: 「Audio-Visual Vibe Coding」により、動画と音声を通じてモデルがコードを記述することが可能です。
Qwen3.5-Omniは、マルチモーダルAIにおける重要な進歩を象徴しています。テキスト、視覚、音声、動画の4つを1つのモデルでカバーしつつ、テキスト推論能力もほとんど損なわれていません。マルチモーダル機能を必要とする開発者にとって、真剣に検討すべき選択肢と言えるでしょう。
Qwen3.5-Omniやその他の主要なマルチモーダルモデルを素早くテストするには、APIYI (apiyi.com) がおすすめです。無料枠が提供されており、統一されたAPIインターフェースを通じて簡単に比較・選定が行えます。
📚 参考資料
-
MarkTechPost レポート: Qwen3.5-Omni リリース詳細
- リンク:
marktechpost.com/2026/03/30/alibaba-qwen-team-releases-qwen3-5-omni-a-native-multimodal-model-for-text-audio-video-and-realtime-interaction - 説明: 詳細な技術分析とアーキテクチャの解説
- リンク:
-
Qwen3-Omni GitHub リポジトリ: オープンソースコードとモデルウェイト
- リンク:
github.com/QwenLM/Qwen3-Omni - 説明: 前世代 Qwen3-Omni の完全なコードとドキュメント
- リンク:
-
Analytics Vidhya 詳細解説: Qwen3.5-Omni 技術レポート分析
- リンク:
analyticsvidhya.com/blog/2026/03/qwen3-5-omni-ai-model - 説明: 音声クローンや Vibe Coding などの能力を網羅した詳細分析
- リンク:
-
eWeek レポート: アリババの最先端マルチモーダルモデルとしての Qwen3.5-Omni
- リンク:
eweek.com/news/qwen3-5-omni-alibaba-multimodal-ai-launch - 説明: 業界視点からの分析と競合製品との比較
- リンク:
-
HuggingFace モデルページ: Qwen3-Omni-30B-A3B-Instruct
- リンク:
huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct - 説明: モデルウェイトのダウンロードと技術仕様
- リンク:
著者: APIYI 技術チーム
技術交流: マルチモーダルAIの応用実践について、ぜひコメント欄で議論しましょう。その他のAI開発資料については、APIYI docs.apiyi.com ドキュメントセンターをご覧ください。