Авторское примечание: подробный разбор нативной мультимодальной модели Qwen3.5-Omni от Alibaba: архитектура Thinker-Talker MoE, контекстное окно 256K, возможности кодирования аудио и видео, а также эмерджентные способности Audio-Visual Vibe Coding.
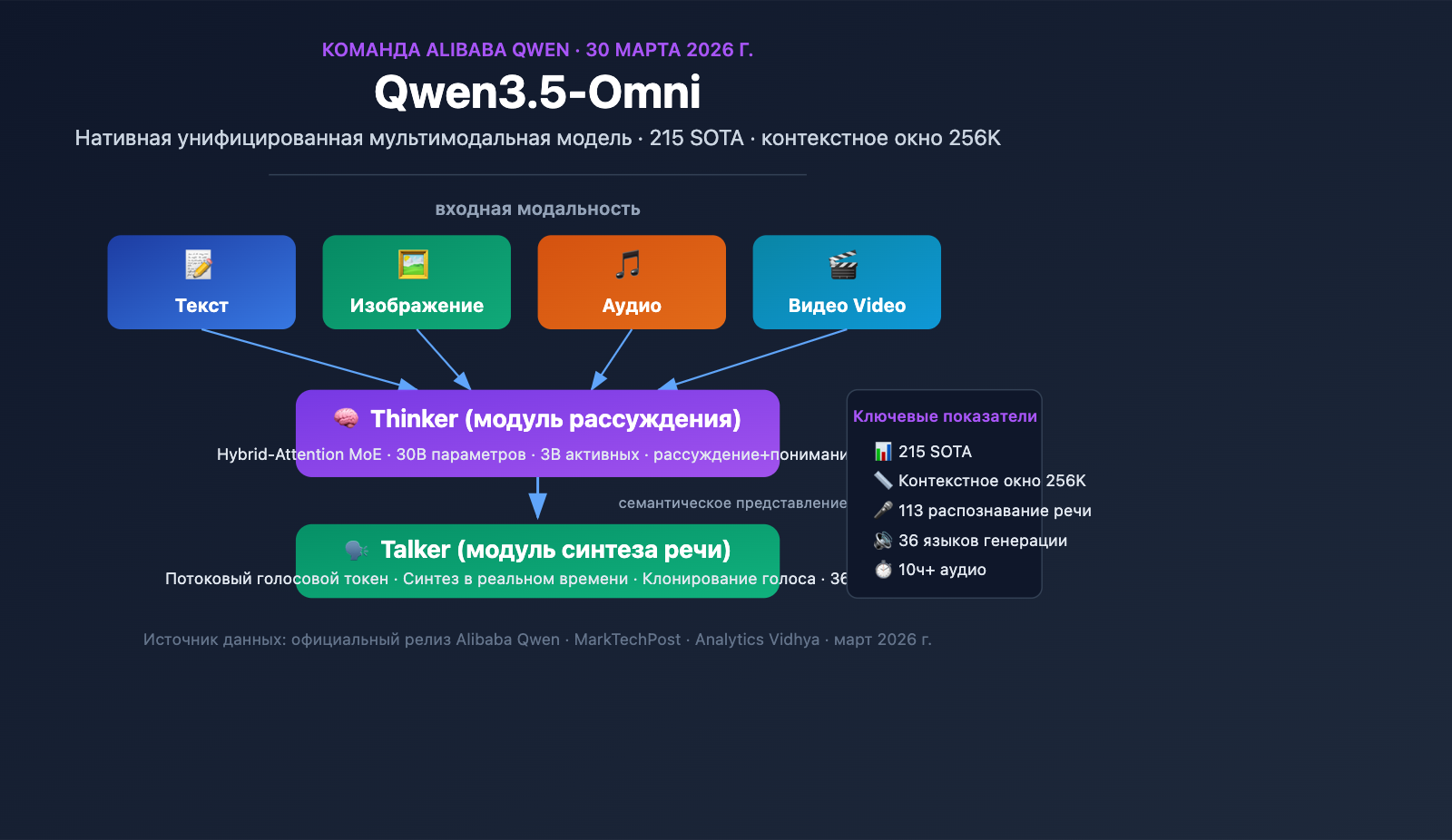
Команда Alibaba Qwen официально представила Qwen3.5-Omni 30 марта 2026 года. Это нативная мультимодальная модель, способная одновременно обрабатывать текст, изображения, аудио и видео в рамках единого вычислительного конвейера. Как часть масштабной серии релизов Alibaba в марте-апреле, Qwen3.5-Omni достигла уровня SOTA в 215 бенчмарках, что стало важным прорывом для китайских AI-разработчиков в области полнофункциональных больших языковых моделей.
Ключевые моменты: 3 минуты на изучение архитектуры Thinker-Talker в Qwen3.5-Omni, стратегии выбора между тремя вариантами модели и эмерджентных способностей Audio-Visual Vibe Coding.
Основные сведения о мультимодальной модели Qwen3.5-Omni
Краткий обзор ключевых параметров Qwen3.5-Omni
| Параметр | Детали |
|---|---|
| Дата выпуска | 30 марта 2026 г. |
| Разработчик | Команда Alibaba Tongyi Qianwen (Qwen) |
| Архитектура | Thinker-Talker + Hybrid-Attention MoE |
| Варианты модели | Plus (30B-A3B MoE), Flash (легкая MoE), Light (плотная модель/открытые веса) |
| Контекстное окно | 256 тыс. токенов |
| Объем аудио | 10+ часов непрерывного аудио |
| Объем видео | 400+ секунд видео 720p (частота дискретизации 1 FPS) |
| Распознавание речи | 113 языков и диалектов (в предыдущей версии — всего 19) |
| Генерация речи | 36 языков (в предыдущей версии — всего 10) |
| Данные обучения | Более 100 млн часов аудио- и видеоданных |
| Бенчмарки | SOTA в 215 тестах на понимание аудио/видео |
Позиционирование модели Qwen3.5-Omni
Ключевая особенность Qwen3.5-Omni заключается в нативной мультимодальности. Это не просто текстовая модель, к которой «прикрутили» аудио- и видеомодули, а единая система, обученная с нуля на массиве данных объемом более 100 млн часов аудио и видео. Все модальности обрабатываются в рамках одного вычислительного конвейера. Это означает, что модель по-настоящему понимает семантическую информацию в аудио и видео, а не просто транскрибирует их в текст для последующей обработки.
Кроме того, Qwen3.5-Omni стала частью серии моделей, которые Alibaba интенсивно выпускала в марте-апреле 2026 года. Уже 2 апреля, всего через несколько дней, компания представила модель Qwen3.6-Plus для корпоративных задач (с поддержкой контекстного окна в 1 млн токенов и упором на агентное программирование), что демонстрирует серьезные амбиции Alibaba в сфере больших языковых моделей.
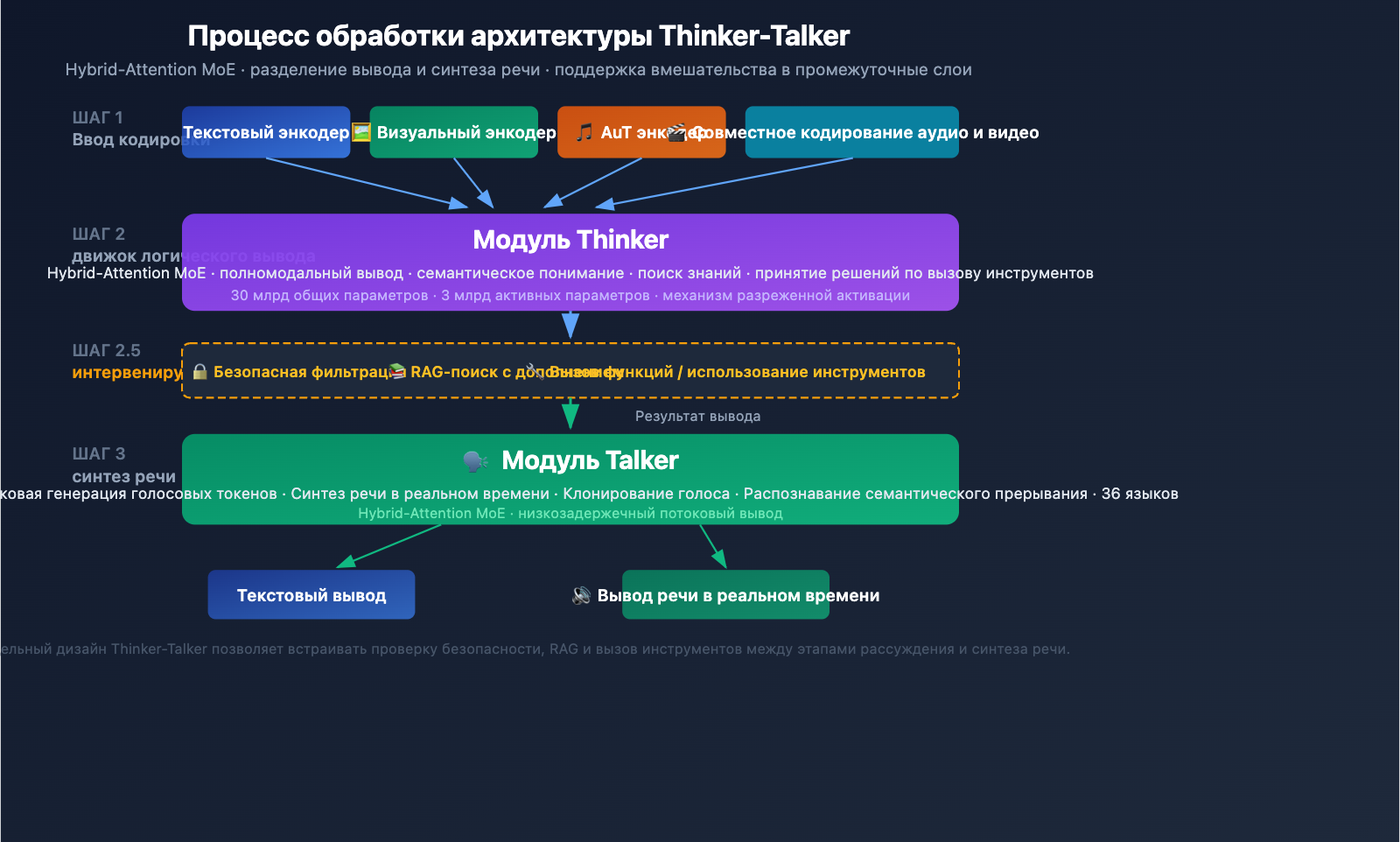
Подробный разбор архитектуры Qwen3.5-Omni Thinker-Talker
Двухмодульный дизайн Thinker-Talker
В Qwen3.5-Omni реализована уникальная двухмодульная архитектура Thinker-Talker. Впервые представленная в Qwen2.5-Omni, в версии 3.5 она получила серьезное обновление: оба модуля теперь используют архитектуру Hybrid-Attention MoE (смесь экспертов с гибридным вниманием).
Модуль Thinker (Мыслитель):
- Обрабатывает все входные модальности: текст, изображения, аудио, видео.
- Выполняет задачи логического вывода и понимания.
- Генерирует внутренние представления для рассуждений.
- Использует нативный кодировщик Audio Transformer (AuT) для обработки аудио.
- Выдает структурированные семантические представления.
Модуль Talker (Выразитель):
- Получает семантические представления от Thinker.
- Преобразует их в потоковые аудио-токены.
- Поддерживает синтез речи в реальном времени.
- Обеспечивает естественную передачу речи (включая интонацию, эмоции и паузы).
Инженерная ценность архитектуры Thinker-Talker
Ключевое преимущество такой раздельной архитектуры — возможность вмешательства в промежуточный процесс. Внешние системы (конвейеры RAG, фильтры безопасности, вызовы функций) могут «вклиниться» между выводом Thinker и синтезом Talker. Это означает, что:
- Компании могут добавить проверку безопасности перед выводом аудио.
- Разработчики могут инициировать вызов инструментов на основе результатов логического вывода.
- Системы RAG могут дополнить ответ результатами поиска знаний перед его озвучкой.
Механизм разреженной активации MoE
Основа дизайна Hybrid-Attention MoE — это разреженная активация: при обработке каждого токена модель задействует лишь часть параметров (всего 3 активных параметра из 30 млрд). Этот механизм позволяет модели сохранять высокую емкость, удерживая вычислительные затраты на один запрос в разумных пределах, что критически важно для приложений реального времени (например, голосовых диалогов).
🎯 Совет для разработчиков: Раздельная архитектура Thinker-Talker в Qwen3.5-Omni идеально подходит для создания многошаговых AI-рабочих процессов. Если вам нужно интегрировать мультимодальные возможности в свои приложения, вы можете быстро протестировать и сравнить эффективность Qwen3.5-Omni с другими популярными мультимодальными моделями через платформу APIYI apiyi.com.
Сравнение трех вариантов модели Qwen3.5-Omni
Руководство по выбору: Plus / Flash / Light
Qwen3.5-Omni представлена в трех вариантах для разных сценариев использования:
| Вариант | Тип архитектуры | Объем параметров | Способ доступа | Сценарий использования |
|---|---|---|---|---|
| Plus | MoE (30B-A3B) | 30 млрд всего / 3 млрд активных | API (DashScope) | Максимальное качество, сложные мультимодальные задачи |
| Flash | Легковесная MoE | Меньше параметров | API (DashScope) | Низкая задержка, диалоги в реальном времени |
| Light | Плотная модель | Меньший масштаб | Открытые веса (HuggingFace) | Локальное развертывание, периферийные устройства |
Рекомендации по выбору:
- Нужен лучший результат → Выбирайте вариант Plus, он показал лучшие баллы в 215 бенчмарках.
- Нужна минимальная задержка → Выбирайте вариант Flash, он идеально подходит для голосовых диалогов и потокового взаимодействия.
- Требуется локальный запуск → Выбирайте вариант Light, открытые веса позволяют запускать модель на локальных GPU.
Подключение API Qwen3.5-Omni
API Qwen3.5-Omni следует стандартному формату /v1/chat/completions, тип вывода задается через параметр modalities:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Единый доступ через APIYI
)
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Проанализируй содержание этого видео"},
{"type": "video_url", "video_url": {"url": "https://example.com/video.mp4"}}
]
}
]
)
Посмотреть полный пример мультимодального ввода
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Мультимодальный ввод: изображение + аудио + текст
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Составь аналитический отчет на основе изображения и голосового описания"},
{
"type": "image_url",
"image_url": {"url": "data:image/png;base64,..."}
},
{
"type": "input_audio",
"input_audio": {
"data": base64.b64encode(audio_bytes).decode(),
"format": "wav"
}
}
]
}
],
max_tokens=2000
)
# Получение текстового ответа
print(response.choices[0].message.content)
# Если запрашивался аудиовывод, получаем данные аудио
if hasattr(response.choices[0].message, 'audio'):
audio_data = response.choices[0].message.audio
print(f"Формат аудио: {audio_data.format}")
💡 Совет по подключению: API Qwen3.5-Omni совместимо с форматом OpenAI SDK. Если у вас уже есть код на базе OpenAI SDK, просто измените параметры
base_urlиmodelдля быстрого переключения. Через платформу APIYI apiyi.com вы можете одновременно тестировать мультимодальные возможности Qwen3.5-Omni, GPT-4o и других моделей.
Анализ производительности Qwen3.5-Omni в бенчмарках
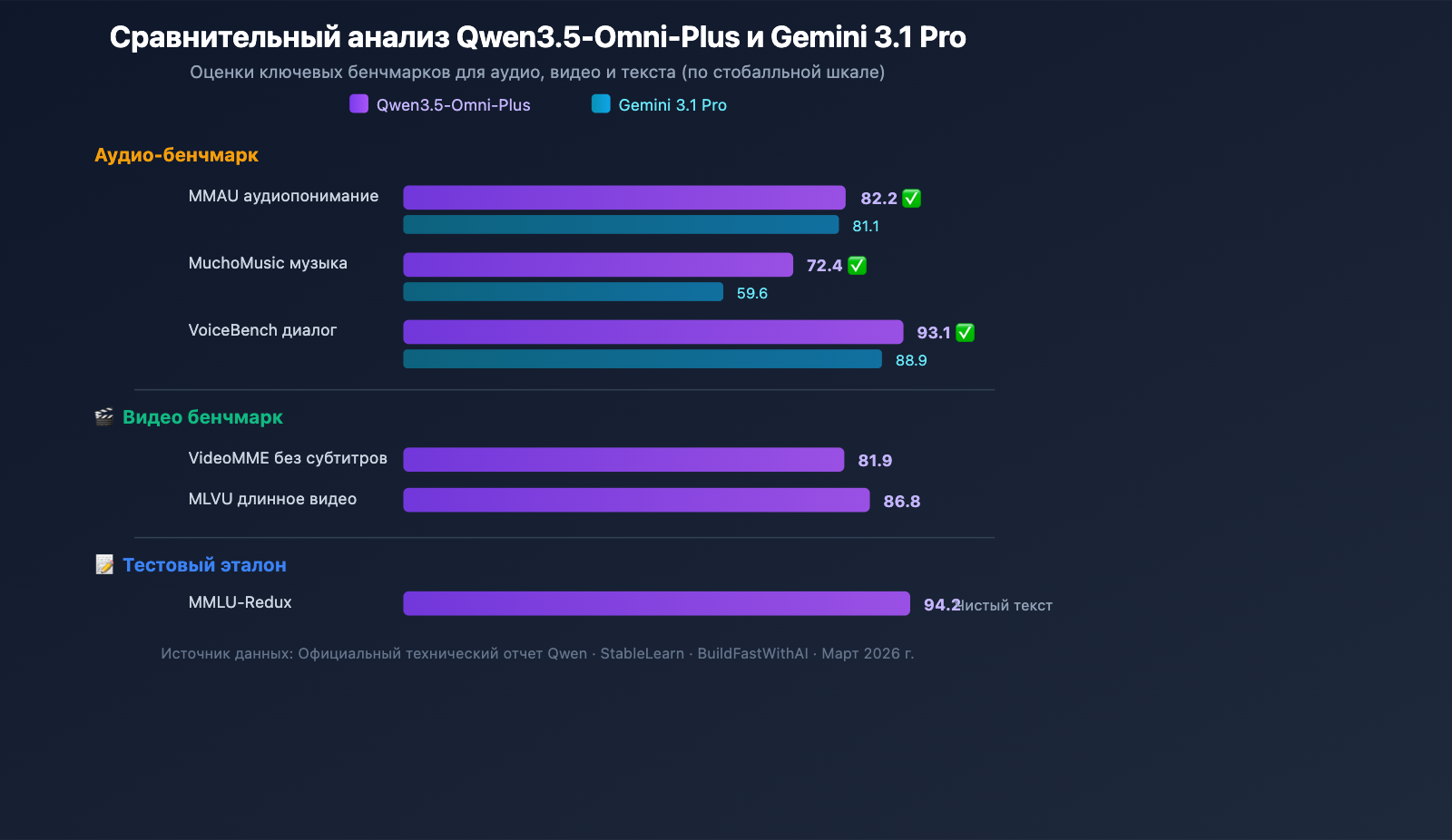
Возможности понимания аудио
Qwen3.5-Omni-Plus превосходит Google Gemini 3.1 Pro по всем ключевым аудио-бенчмаркам:
| Бенчмарк | Qwen3.5-Omni-Plus | Gemini 3.1 Pro | Лидер |
|---|---|---|---|
| MMAU (аудио) | 82.2 | 81.1 | Qwen |
| MuchoMusic (музыка) | 72.4 | 59.6 | Qwen (+21%) |
| VoiceBench (диалог) | 93.1 | 88.9 | Qwen |
Особенно впечатляет преимущество Qwen3.5-Omni в понимании музыки (MuchoMusic) — отрыв составляет целых 21%.
Визуальные и видеовозможности
| Бенчмарк | Qwen3.5-Omni-Plus | Описание |
|---|---|---|
| MMMU-Pro | 73.9 | Лучший результат в мультимодальном понимании |
| RealWorldQA | 84.1 | Визуальные вопросы по реальному миру |
| VideoMME (без субтитров) | 81.9 | Мультимодальное понимание видео |
| MLVU | 86.8 | Понимание длинных видео |
| MVBench | 79.0 | Многомерный видео-бенчмарк |
| LVBench | 71.2 | Бенчмарк для длинных видео |
Сохранение навыков текстового рассуждения
Qwen3.5-Omni получил полноценные мультимодальные возможности, при этом производительность в текстовых задачах практически не изменилась:
| Бенчмарк | Qwen3.5-Omni-Plus | Qwen3.5-Plus (текст) | Разница |
|---|---|---|---|
| MMLU-Redux | 94.2 | 94.3 | -0.1 |
| C-Eval | 92.0 | 92.3 | -0.3 |
| IFEval | 89.7 | 89.7 | 0 |
Это значит, что при переходе на Qwen3.5-Omni вы не жертвуете качеством текстовых рассуждений — одна модель теперь эффективно покрывает как текстовые, так и мультимодальные сценарии.
🎯 Совет по выбору: Qwen3.5-Omni показывает отличные результаты в анализе аудио и музыки. Если ваш проект связан с голосовым взаимодействием или обработкой звука, рекомендуем присмотреться именно к этой модели. С помощью сервиса-прокси API APIYI (apiyi.com) можно быстро сравнить работу Qwen3.5-Omni и GPT-4o в ваших реальных задачах.
3 ключевые особенности Qwen3.5-Omni
Возможность 1: Audio-Visual Vibe Coding
Qwen3.5-Omni демонстрирует так называемую «эмерджентную способность», которую команда Qwen называет «Audio-Visual Vibe Coding». Модель способна писать рабочий код, просто просматривая видео и слушая голосовые инструкции, причем без специального обучения под эту задачу.
В ходе тестов модель показала, что может:
- Превращать нарисованные от руки эскизы (снятые на камеру) в работающие React-страницы.
- Писать функциональный код на основе видеодемонстрации и устных описаний.
- Понимать визуальные дизайнерские решения и генерировать соответствующий фронтенд.
Эта функция невероятно полезна для быстрого прототипирования и low-code разработки.
Возможность 2: Распознавание семантических прерываний
Традиционные системы голосового взаимодействия не умеют отличать обычные реакции пользователя вроде «угу» или «ага» от реального намерения прервать бота. Qwen3.5-Omni внедряет нативную функцию Turn-Taking Intent Recognition (распознавание намерения перехватить инициативу), которая различает:
- Обратную связь (Backchanneling): реакции типа «угу», «да», которые не несут намерения прервать диалог.
- Семантическое прерывание (Semantic Interruption): ситуации, когда пользователь явно хочет взять управление диалогом на себя.
Благодаря этому голосовое общение с Qwen3.5-Omni ощущается гораздо естественнее, почти как разговор с живым человеком.
Возможность 3: Клонирование голоса
Пользователи могут загрузить аудиозапись, и Qwen3.5-Omni изучит и скопирует характеристики этого голоса, чтобы использовать его во всех последующих голосовых ответах. Клонированный голос сохраняет естественность и стабильность даже при смене языка.
Место Qwen3.5-Omni в AI-стратегии Alibaba
График релизов AI-моделей Alibaba (март–апрель 2026 г.)
| Дата релиза | Модель | Позиционирование | Ключевые особенности |
|---|---|---|---|
| 30 марта | Qwen3.5-Omni | Нативная мультимодальная модель | Единая обработка текста/изображений/аудио/видео |
| 2 апреля | Qwen3.6-Plus | Корпоративная агентная модель | Контекстное окно 1 млн токенов, агентное программирование |
| Постоянно | Qwen3-TTS | Синтез речи | Серия open-source TTS, поддержка клонирования голоса |
Такой плотный график релизов показывает, что Alibaba активно развивает возможности своих больших языковых моделей по всем фронтам. Qwen3.5-Omni закрывает потребности в мультимодальном восприятии и понимании, а Qwen3.6-Plus — в корпоративной генерации кода и агентных функциях, дополняя друг друга.
Важно отметить, что версии Plus и Flash модели Qwen3.5-Omni выпущены через закрытый API, что отходит от прежней стратегии Alibaba, ориентированной на open-source. Аналитики, включая WinBuzzer, считают, что это отражает фокус компании на прибыли в условиях коммерческого давления — заголовок Bloomberg прямо гласит: «Alibaba запускает третью закрытую AI-модель, фокусируясь на прибыли».
💰 Совет по затратам: Если вы планируете интегрировать Qwen3.5-Omni в свой продукт, рекомендуем сначала провести проверку концепции (PoC) с помощью бесплатных лимитов на платформе APIYI (apiyi.com), чтобы убедиться в качестве работы модели перед запуском в продакшн. Платформа поддерживает всю линейку моделей, включая Qwen, GPT, Claude и Gemini, что позволяет гибко выбирать решение для разных задач.
Часто задаваемые вопросы
Q1: Qwen3.5-Omni — это модель с открытым или закрытым исходным кодом?
Qwen3.5-Omni представлена в трех вариантах: Plus и Flash на данный момент доступны только через API Alibaba Cloud DashScope (закрытый код), в то время как веса версии Light открыты и доступны для скачивания на HuggingFace (открытый код). Предыдущее поколение Qwen3-Omni было полностью открытым по лицензии Apache 2.0, однако в версии 3.5 варианты Plus/Flash перешли на модель API-only. Если вам нужно локальное развертывание, выбирайте версию Light.
Q2: Как Qwen3.5-Omni соотносится с GPT-4o?
В задачах понимания аудио и музыки Qwen3.5-Omni-Plus заметно опережает GPT-4o. В области понимания видео у обеих моделей есть свои сильные стороны. Что касается текстовых рассуждений, Qwen3.5-Omni практически не уступает специализированной текстовой модели Qwen3.5-Plus. Рекомендуем провести сравнительное тестирование в ваших конкретных сценариях использования через платформу APIYI apiyi.com, так как производительность может сильно варьироваться в зависимости от задачи.
Q3: Как быстро начать работу с API Qwen3.5-Omni?
API Qwen3.5-Omni совместимо со стандартным форматом OpenAI SDK, поэтому подключение очень простое. Достаточно установить SDK openai, настроить соответствующие API-ключ и base_url, и можно приступать к вызовам. Через APIYI apiyi.com можно получить бесплатные тестовые лимиты и быстро проверить возможности мультимодальных вызовов с помощью примеров кода из этой статьи.
Итоги
Ключевые особенности мультимодальной модели Qwen3.5-Omni:
- Нативная полнофункциональная мультимодальность: унифицированная обработка текста, изображений, аудио и видео в рамках одного конвейера, а не сборка из разных компонентов.
- Архитектура Thinker-Talker: разделение процессов рассуждения и синтеза речи, поддержка вмешательства на промежуточных этапах и вызова инструментов.
- Три варианта на выбор: Plus (максимальная мощность), Flash (низкая задержка), Light (открытые веса для локального развертывания).
- 215 показателей SOTA: значительное преимущество над Gemini 3.1 Pro в понимании аудио и музыки.
- Эмерджентные способности: технология Audio-Visual Vibe Coding позволяет модели писать код на основе видео и голосовых команд.
Qwen3.5-Omni представляет собой важный шаг в развитии мультимодального ИИ — одна модель одновременно охватывает текст, визуальные данные, аудио и видео, при этом возможности текстовых рассуждений практически не снижаются. Для разработчиков, которым нужны мультимодальные возможности, это вариант, заслуживающий самого пристального внимания.
Рекомендуем использовать APIYI apiyi.com для быстрого тестирования Qwen3.5-Omni и других популярных мультимодальных моделей. Платформа предоставляет бесплатные лимиты и унифицированный API, что упрощает сравнение и выбор подходящего решения.
📚 Справочные материалы
-
Обзор MarkTechPost: Подробности релиза Qwen3.5-Omni
- Ссылка:
marktechpost.com/2026/03/30/alibaba-qwen-team-releases-qwen3-5-omni-a-native-multimodal-model-for-text-audio-video-and-realtime-interaction - Описание: Глубокий технический анализ и разбор архитектуры.
- Ссылка:
-
Репозиторий Qwen3-Omni на GitHub: Исходный код и веса модели
- Ссылка:
github.com/QwenLM/Qwen3-Omni - Описание: Полный код и документация к предыдущей версии Qwen3-Omni.
- Ссылка:
-
Глубокий разбор от Analytics Vidhya: Анализ технического отчета Qwen3.5-Omni
- Ссылка:
analyticsvidhya.com/blog/2026/03/qwen3-5-omni-ai-model - Описание: Детальный разбор возможностей, включая клонирование голоса, Vibe Coding и другие функции.
- Ссылка:
-
Репортаж eWeek: Qwen3.5-Omni как самая передовая мультимодальная модель Alibaba
- Ссылка:
eweek.com/news/qwen3-5-omni-alibaba-multimodal-ai-launch - Описание: Анализ с точки зрения индустрии и сравнение с конкурентами.
- Ссылка:
-
Страница модели на HuggingFace: Qwen3-Omni-30B-A3B-Instruct
- Ссылка:
huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct - Описание: Скачивание весов модели и технические спецификации.
- Ссылка:
Автор: Техническая команда APIYI
Техническое обсуждение: Приглашаем обсудить практическое применение мультимодального ИИ в комментариях. Больше материалов по разработке ИИ можно найти в документации APIYI по адресу docs.apiyi.com.