作者注:详解阿里通义千问 Qwen3.5-Omni 原生多模态模型的 Thinker-Talker MoE 架构、256K 上下文、音视频编码能力以及 Audio-Visual Vibe Coding 涌现能力
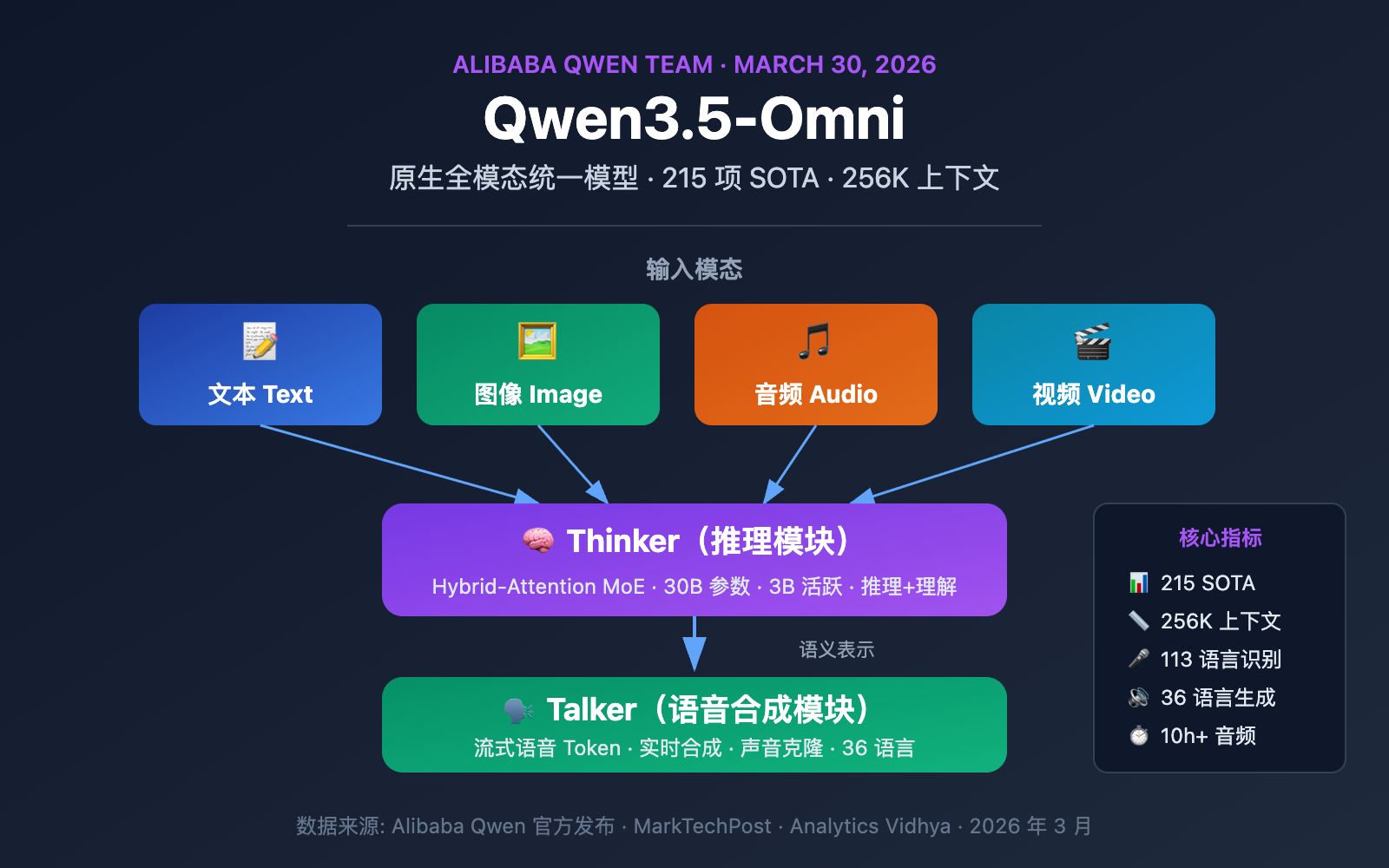
阿里巴巴通义千问团队于 2026 年 3 月 30 日正式发布了 Qwen3.5-Omni,这是一款在单一计算管道内同时处理文本、图像、音频和视频四种模态的原生多模态统一模型。作为阿里 3-4 月密集发布攻势的组成部分,Qwen3.5-Omni 在 215 项基准测试中达到 SOTA,标志着中国 AI 厂商在全模态大模型领域的重要突破。
核心价值: 3 分钟了解 Qwen3.5-Omni 的 Thinker-Talker 架构设计、三种模型变体的选择策略,以及 Audio-Visual Vibe Coding 涌现能力。
Qwen3.5-Omni 多模态模型核心信息
Qwen3.5-Omni 关键参数速览
| 参数项 | 详情 |
|---|---|
| 发布日期 | 2026 年 3 月 30 日 |
| 发布方 | 阿里巴巴通义千问(Qwen)团队 |
| 架构 | Thinker-Talker + Hybrid-Attention MoE |
| 模型变体 | Plus(30B-A3B MoE)、Flash(轻量 MoE)、Light(稠密模型/开放权重) |
| 上下文窗口 | 256K Token |
| 音频容量 | 10+ 小时连续音频 |
| 视频容量 | 400+ 秒 720p 视频(1 FPS 采样) |
| 语音识别 | 113 种语言和方言(前代仅 19 种) |
| 语音生成 | 36 种语言(前代仅 10 种) |
| 训练数据 | 超过 1 亿小时音视频数据 |
| 基准成绩 | 215 项音频/视频理解基准达到 SOTA |
Qwen3.5-Omni 模型定位
Qwen3.5-Omni 的核心意义在于原生多模态——这不是一个文本模型外接音频和视频模块的拼装方案,而是从头开始在超过 1 亿小时音视频数据上预训练的统一模型。所有模态在同一个计算管道中处理,这意味着模型可以真正理解音频和视频中的语义信息,而非简单地将音视频转录为文本后再处理。
同时,Qwen3.5-Omni 是阿里在 2026 年 3-4 月密集发布的系列模型之一。仅数天后的 4 月 2 日,阿里又发布了面向企业级应用的 Qwen3.6-Plus 模型(支持 100 万 Token 上下文,主攻代理式编程),显示出阿里在大模型领域的强劲投入。
Qwen3.5-Omni Thinker-Talker 架构详解
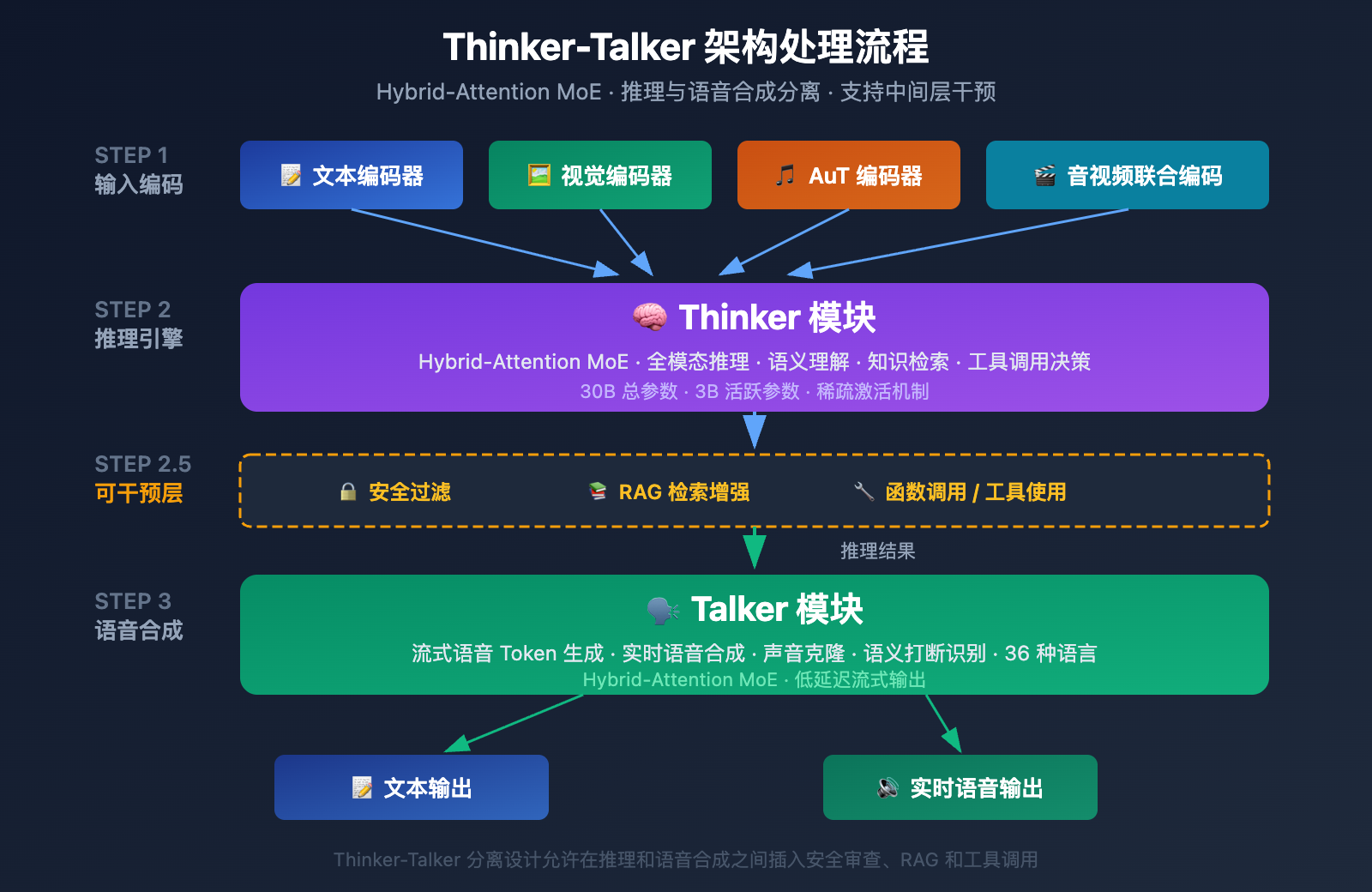
Thinker-Talker 双模块设计
Qwen3.5-Omni 采用了独特的 Thinker-Talker 双模块架构,这一设计首次在 Qwen2.5-Omni 中引入,在 3.5 版本中得到了重大升级——两个模块都采用了 Hybrid-Attention MoE(混合注意力专家混合)架构。
Thinker 模块(思考者):
- 处理所有输入模态:文本、图像、音频、视频
- 执行推理和理解任务
- 生成内部推理表示
- 使用原生 Audio Transformer(AuT)编码器处理音频
- 输出结构化的语义表示
Talker 模块(表达者):
- 接收 Thinker 的推理表示
- 将语义表示转换为流式语音 Token
- 支持实时语音合成
- 实现自然的语音表达(包括语调、情感、停顿)
Thinker-Talker 架构的工程价值
这种分离式设计带来的核心优势是中间可干预性——外部系统(RAG 检索管道、安全过滤器、函数调用)可以在 Thinker 输出和 Talker 合成之间进行干预。这意味着:
- 企业可以在语音输出前添加安全审查
- 开发者可以在推理结果基础上触发工具调用
- RAG 系统可以在回答前补充知识检索结果
MoE 稀疏激活机制
Hybrid-Attention MoE 设计的核心是稀疏激活——模型在处理每个 Token 时只激活部分参数(30B 总参数中仅 3B 活跃)。这一机制让模型在保持高容量的同时,将单次推理计算成本控制在可接受范围内,这对实时应用(如语音对话)至关重要。
🎯 开发建议: Qwen3.5-Omni 的 Thinker-Talker 分离架构非常适合构建多步骤 AI 工作流。如果你需要在自己的应用中集成多模态能力,可以通过 API易 apiyi.com 平台快速测试 Qwen3.5-Omni 和其他主流多模态模型的效果差异。
Qwen3.5-Omni 三种模型变体对比
Plus / Flash / Light 选择指南
Qwen3.5-Omni 提供三种面向不同场景的模型变体:
| 变体 | 架构类型 | 参数规模 | 可用方式 | 适用场景 |
|---|---|---|---|---|
| Plus | MoE(30B-A3B) | 30B 总参/3B 活跃 | API(DashScope) | 最高质量推理、复杂多模态任务 |
| Flash | 轻量 MoE | 更少参数 | API(DashScope) | 低延迟场景、实时对话 |
| Light | 稠密模型 | 较小规模 | 开放权重(HuggingFace) | 本地部署、边缘设备 |
选择建议:
- 追求最佳效果 → 选择 Plus 变体,在 215 项基准测试中均为最高分
- 追求低延迟 → 选择 Flash 变体,适合实时语音对话和流式交互
- 需要本地部署 → 选择 Light 变体,开放权重可在本地 GPU 上运行
Qwen3.5-Omni API 接入方式
Qwen3.5-Omni 的 API 遵循标准的 /v1/chat/completions 格式,通过 modalities 参数指定输出类型:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # 通过 API易 统一接入
)
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "请分析这段视频的内容"},
{"type": "video_url", "video_url": {"url": "https://example.com/video.mp4"}}
]
}
]
)
查看多模态输入完整示例
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 图像 + 音频 + 文本的多模态输入
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "请根据图片和语音描述生成分析报告"},
{
"type": "image_url",
"image_url": {"url": "data:image/png;base64,..."}
},
{
"type": "input_audio",
"input_audio": {
"data": base64.b64encode(audio_bytes).decode(),
"format": "wav"
}
}
]
}
],
max_tokens=2000
)
# 获取文本回复
print(response.choices[0].message.content)
# 如果请求了音频输出,获取语音数据
if hasattr(response.choices[0].message, 'audio'):
audio_data = response.choices[0].message.audio
print(f"音频格式: {audio_data.format}")
💡 接入提示: Qwen3.5-Omni 的 API 兼容 OpenAI SDK 格式。如果你已有基于 OpenAI SDK 的代码,只需修改
base_url和model参数即可快速切换。通过 API易 apiyi.com 平台可以同时测试 Qwen3.5-Omni 和 GPT-4o 等模型的多模态效果。
Qwen3.5-Omni 基准测试性能分析
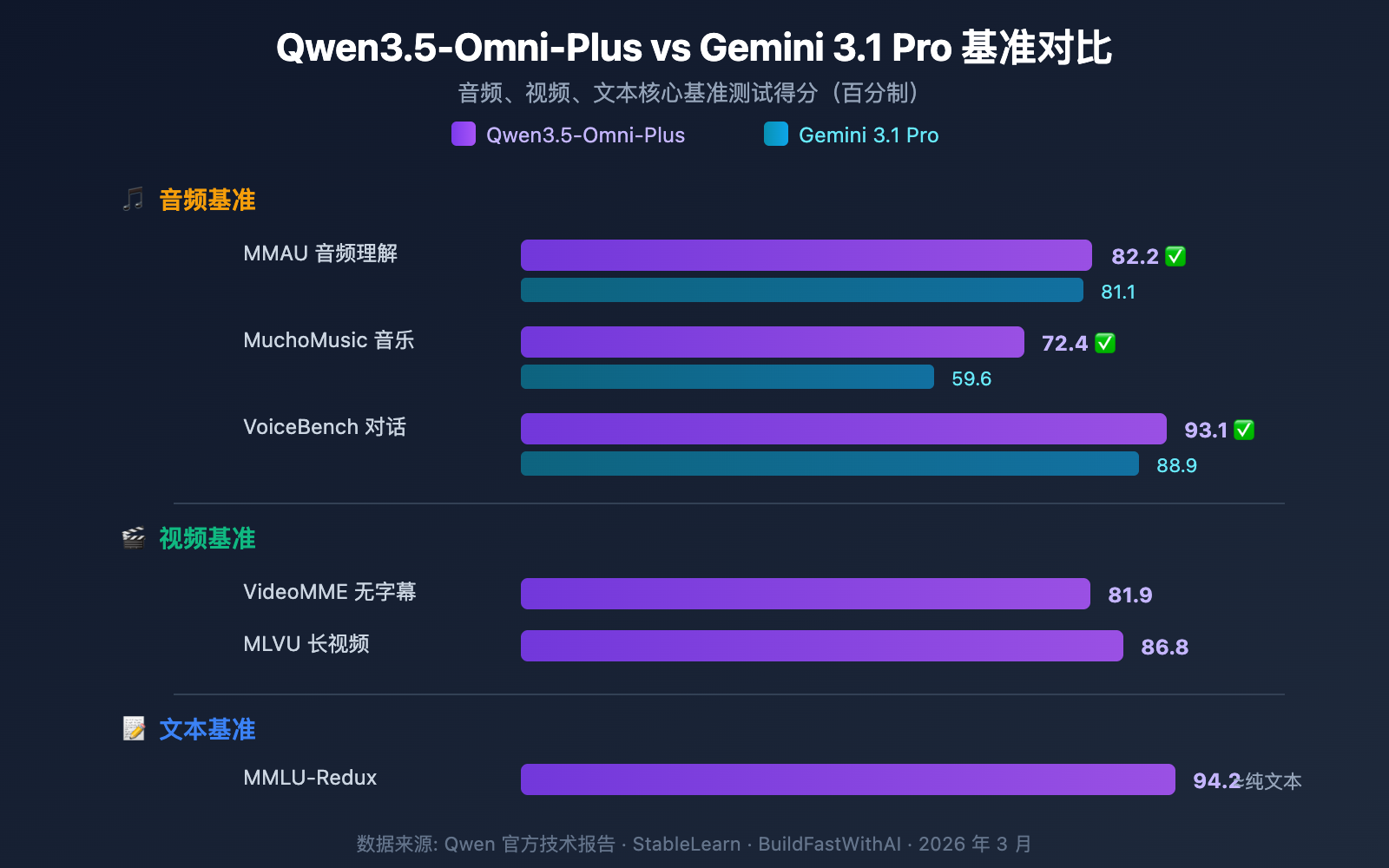
音频理解能力
Qwen3.5-Omni-Plus 在音频相关基准中全面超越 Google Gemini 3.1 Pro:
| 基准测试 | Qwen3.5-Omni-Plus | Gemini 3.1 Pro | 胜出 |
|---|---|---|---|
| MMAU 音频理解 | 82.2 | 81.1 | Qwen |
| MuchoMusic 音乐理解 | 72.4 | 59.6 | Qwen(+21%) |
| VoiceBench 对话 | 93.1 | 88.9 | Qwen |
在音乐理解(MuchoMusic)上 Qwen3.5-Omni 的优势尤为显著,领先幅度达 21%。
视觉和视频能力
| 基准测试 | Qwen3.5-Omni-Plus | 说明 |
|---|---|---|
| MMMU-Pro | 73.9 | 多模态理解最高分 |
| RealWorldQA | 84.1 | 真实世界视觉问答 |
| VideoMME(无字幕) | 81.9 | 视频多模态理解 |
| MLVU | 86.8 | 长视频理解 |
| MVBench | 79.0 | 多维度视频基准 |
| LVBench | 71.2 | 长视频基准 |
文本推理能力保持
Qwen3.5-Omni 在获得全模态能力的同时,文本推理性能几乎没有下降:
| 基准测试 | Qwen3.5-Omni-Plus | Qwen3.5-Plus(纯文本) | 差距 |
|---|---|---|---|
| MMLU-Redux | 94.2 | 94.3 | -0.1 |
| C-Eval | 92.0 | 92.3 | -0.3 |
| IFEval | 89.7 | 89.7 | 0 |
这意味着选择 Qwen3.5-Omni 不会牺牲文本推理质量——你可以用一个模型同时覆盖文本和多模态场景。
🎯 选型建议: Qwen3.5-Omni 在音频和音乐理解上优势明显,如果你的应用涉及语音交互或音频分析,建议优先考虑这个模型。可以通过 API易 apiyi.com 快速对比 Qwen3.5-Omni 和 GPT-4o 在你具体场景下的表现差异。
Qwen3.5-Omni 的 3 大差异化能力
能力 1: Audio-Visual Vibe Coding
Qwen3.5-Omni 展现了一种被通义千问团队称为「Audio-Visual Vibe Coding」的涌现能力——模型可以通过观看视频 + 听取语音指令来编写可运行的代码,而无需专门针对此能力进行训练。
在实际测试中,模型能够:
- 将手绘草图(通过摄像头拍摄)转换为可运行的 React 网页
- 根据视频演示和口头描述编写功能代码
- 理解视觉设计意图并生成对应的前端实现
这一能力对于快速原型开发和低代码场景具有显著价值。
能力 2: 语义打断识别
传统语音交互系统无法区分用户的「嗯」「啊」等回应性反馈和真正的打断意图。Qwen3.5-Omni 引入了原生的 Turn-Taking Intent Recognition(轮次接管意图识别),可以区分:
- 回应反馈(Backchanneling): 如「嗯」「对」等无语义打断意图的反馈
- 语义打断(Semantic Interruption): 用户有明确意图接管对话的情况
这使得 Qwen3.5-Omni 的语音对话体验更接近真人交流。
能力 3: 声音克隆
用户可以上传一段语音录音,Qwen3.5-Omni 会学习并克隆该声音特征,在后续所有语音输出中使用克隆的声音。克隆的声音在多语言场景下能保持自然度和稳定性。
Qwen3.5-Omni 在阿里 AI 发布攻势中的位置
阿里 2026 年 3-4 月 AI 模型发布节奏
| 发布时间 | 模型 | 定位 | 关键特性 |
|---|---|---|---|
| 3 月 30 日 | Qwen3.5-Omni | 原生全模态模型 | 文本/图像/音频/视频统一处理 |
| 4 月 2 日 | Qwen3.6-Plus | 企业级代理模型 | 100 万 Token 上下文、代理式编程 |
| 持续更新 | Qwen3-TTS | 语音合成 | 开源 TTS 系列,支持声音克隆 |
这种密集发布节奏表明阿里正在全方位推进大模型能力建设。Qwen3.5-Omni 覆盖了多模态感知与理解,Qwen3.6-Plus 覆盖了企业级代码生成和代理能力,两者形成互补。
值得注意的是,Qwen3.5-Omni 的 Plus 和 Flash 变体采用了闭源 API 发布方式,打破了阿里此前以开源为主的策略。WinBuzzer 等媒体分析认为,这反映了阿里在商业化压力下对利润的关注——Bloomberg 的报道标题直接写道「阿里推出第三款闭源 AI 模型,聚焦利润」。
💰 成本建议: 如果你正在考虑将 Qwen3.5-Omni 集成到产品中,建议先通过 API易 apiyi.com 平台的免费额度进行概念验证,确认模型效果后再投入生产部署。平台支持 Qwen、GPT、Claude、Gemini 等全系模型,便于在不同场景下灵活选择。
常见问题
Q1: Qwen3.5-Omni 是开源的还是闭源的?
Qwen3.5-Omni 分三个变体:Plus 和 Flash 目前仅通过阿里云 DashScope API 提供(闭源),Light 变体的权重开放在 HuggingFace 上可以下载(开源)。前代 Qwen3-Omni 采用 Apache 2.0 协议完全开源,但 3.5 版本的 Plus/Flash 变体转向了 API-only 模式。如果需要本地部署,可以选择 Light 变体。
Q2: Qwen3.5-Omni 和 GPT-4o 相比如何?
在音频理解和音乐理解方面,Qwen3.5-Omni-Plus 明显领先于 GPT-4o。在视频理解方面两者各有优势。在文本推理方面,Qwen3.5-Omni 与自家纯文本模型 Qwen3.5-Plus 几乎持平。建议通过 API易 apiyi.com 平台在你的具体应用场景下进行对比测试,不同场景下表现差异可能很大。
Q3: 如何快速开始使用 Qwen3.5-Omni API?
Qwen3.5-Omni 的 API 兼容标准 OpenAI SDK 格式,接入非常简单。只需安装 openai SDK,设置对应的 API Key 和 base_url,即可调用。通过 API易 apiyi.com 可以获取免费测试额度,用本文代码示例快速验证多模态调用效果。
总结
Qwen3.5-Omni 多模态模型的核心要点:
- 原生全模态: 在单一管道内统一处理文本、图像、音频、视频四种模态,非拼装方案
- Thinker-Talker 架构: 推理和语音合成分离,支持中间层干预和工具调用
- 3 种变体选择: Plus(最强)、Flash(低延迟)、Light(开放权重本地部署)
- 215 项 SOTA: 在音频理解、音乐理解方面显著领先 Gemini 3.1 Pro
- 涌现能力: Audio-Visual Vibe Coding 让模型通过视频+语音编写代码
Qwen3.5-Omni 代表了多模态 AI 的重要进展——一个模型同时覆盖文本、视觉、音频、视频四种模态,且文本推理能力几乎不打折。对于需要多模态能力的开发者,这是一个值得认真评估的选项。
推荐通过 API易 apiyi.com 快速测试 Qwen3.5-Omni 和其他主流多模态模型,平台提供免费额度和统一 API 接口,便于对比和选型。
📚 参考资料
-
MarkTechPost 报道: Qwen3.5-Omni 发布详解
- 链接:
marktechpost.com/2026/03/30/alibaba-qwen-team-releases-qwen3-5-omni-a-native-multimodal-model-for-text-audio-video-and-realtime-interaction - 说明: 详细的技术分析和架构解读
- 链接:
-
Qwen3-Omni GitHub 仓库: 开源代码和模型权重
- 链接:
github.com/QwenLM/Qwen3-Omni - 说明: 前代 Qwen3-Omni 的完整代码和文档
- 链接:
-
Analytics Vidhya 深度解读: Qwen3.5-Omni 技术报告分析
- 链接:
analyticsvidhya.com/blog/2026/03/qwen3-5-omni-ai-model - 说明: 涵盖声音克隆、Vibe Coding 等能力的详细分析
- 链接:
-
eWeek 报道: Qwen3.5-Omni 作为阿里最先进多模态模型
- 链接:
eweek.com/news/qwen3-5-omni-alibaba-multimodal-ai-launch - 说明: 行业视角的分析和竞品对比
- 链接:
-
HuggingFace 模型页: Qwen3-Omni-30B-A3B-Instruct
- 链接:
huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct - 说明: 模型权重下载和技术规格
- 链接:
作者: APIYI 技术团队
技术交流: 欢迎在评论区讨论多模态 AI 应用实践,更多 AI 开发资料可访问 API易 docs.apiyi.com 文档中心