最近、AIアプリケーションを開発していて最も頭を悩ませることは何でしょうか?おそらく、このようなシナリオではないでしょうか。プロンプトを17回も修正し、いくつかのテストケースで改善したと感じてリリースした途端、ユーザーから全く予想もしなかったエッジケースを突かれ、一撃で崩壊してしまう――。これこそが、OpenAIが2025年10月に公開したCookbook記事『Building resilient prompts using an evaluation flywheel(評価フライホイールを用いたレジリエントなプロンプトの構築)』が解決しようとしている問題です。
OpenAIのエンジニアであるNeel Kapse氏と、コミュニティで著名な機械学習教育者であるHamel Husain氏は、この記事の中でEvaluation Flywheel(評価フライホイール)という核心的な概念を提唱しました。社会学の定性研究における成熟した手法論を応用し、AIアプリケーション開発を「プロンプトを書いては祈る(prompt-and-pray)」という状態から、「エンジニアリングの規律」へと引き上げるものです。本稿では、このOpenAI評価フライホイールのフレームワークを最も分かりやすい視点で解説し、皆さんのAIプロジェクトにどう導入すべきかのアドバイスをお届けします。
🎯 クイックガイド: このCookbookでは、実際の「アパート賃貸アシスタントAI」をデモケースとして、失敗分析から自動評価(Grader)、CI統合までの全ワークフローを網羅しています。記事内で言及されているEvals APIやPrompt OptimizerツールはOpenAIプラットフォームの高度な機能ですが、APIYI(apiyi.com)のようなOpenAI公式中継サービスを通じて直接呼び出すことが可能です。国内のエンジニアも、Cookbookのプロセスをそのままなぞることで実装を完了できます。
アパート賃貸アシスタントの事例:エッジケースに打ちのめされたAIアプリケーション
Cookbookで取り上げられている事例は非常に身近なものです。入居希望者の質問(部屋の広さ、内見予約、設備紹介など)に回答するAIアシスタントです。一見すると普通のカスタマーサポート用チャットボットですが、実際に本番環境へ投入すると、その失敗の仕方は多岐にわたります。
記事で挙げられている失敗例は非常に代表的で、誰もが共感できるものばかりです。
| 失敗の種類 | 具体的な現象 | 結果 |
|---|---|---|
| スケジュールエラー | 存在しない内見枠を提案した | ユーザーが空振りし、クレームが急増 |
| ステータスの混乱 | 予約変更時に元の予定を消し忘れた | 同一時間帯の二重予約が発生し、営業管理が混乱 |
| レイアウト崩壊 | 設備リストがテキストの塊になった | ユーザー体験が悪化し、情報が伝わらない |
| リンク切れ | 間取り図のリンクが404エラー | ユーザーが競合他社へ流出 |
| データドリフト | 回答した営業時間が実際のデータと異なる | ユーザーへの誤解を招き、法的リスクが発生 |
AIアプリケーションを開発したことがある方なら、これらがプロンプト作成時に意図的に無視されたものではなく、そもそも発生するとは思いもしなかった事象であると理解できるはずです。Fractionalチームは、関連する「レシート検査」の事例において、この現象を的確にまとめています。「ハッピーパス(正常系)をいくつか試すだけでは、本番環境のロングテールなバグを捕まえることはできない。必ず『失敗の収集 → パターンの帰納 → 自動測定』という体系的なループを構築しなければならない」と。
このループこそが、評価フライホイールが解決しようとしている核心的な課題なのです。
OpenAI評価フライホイールの核心定義:プロンプト・アンド・プレイに代わるエンジニアリングの規律
OpenAIのクックブックでは、評価フライホイールを非常に簡潔に定義しています。それは、**「構造化されたエンジニアリングの規律によって、当てずっぽう(プロンプト・アンド・プレイ)を置き換える、継続的な反復プロセス」**です。このプロセスは3つの段階で構成されており、本物の車輪のように回転し続けることで、システムは回転するたびに堅牢性を増していきます。
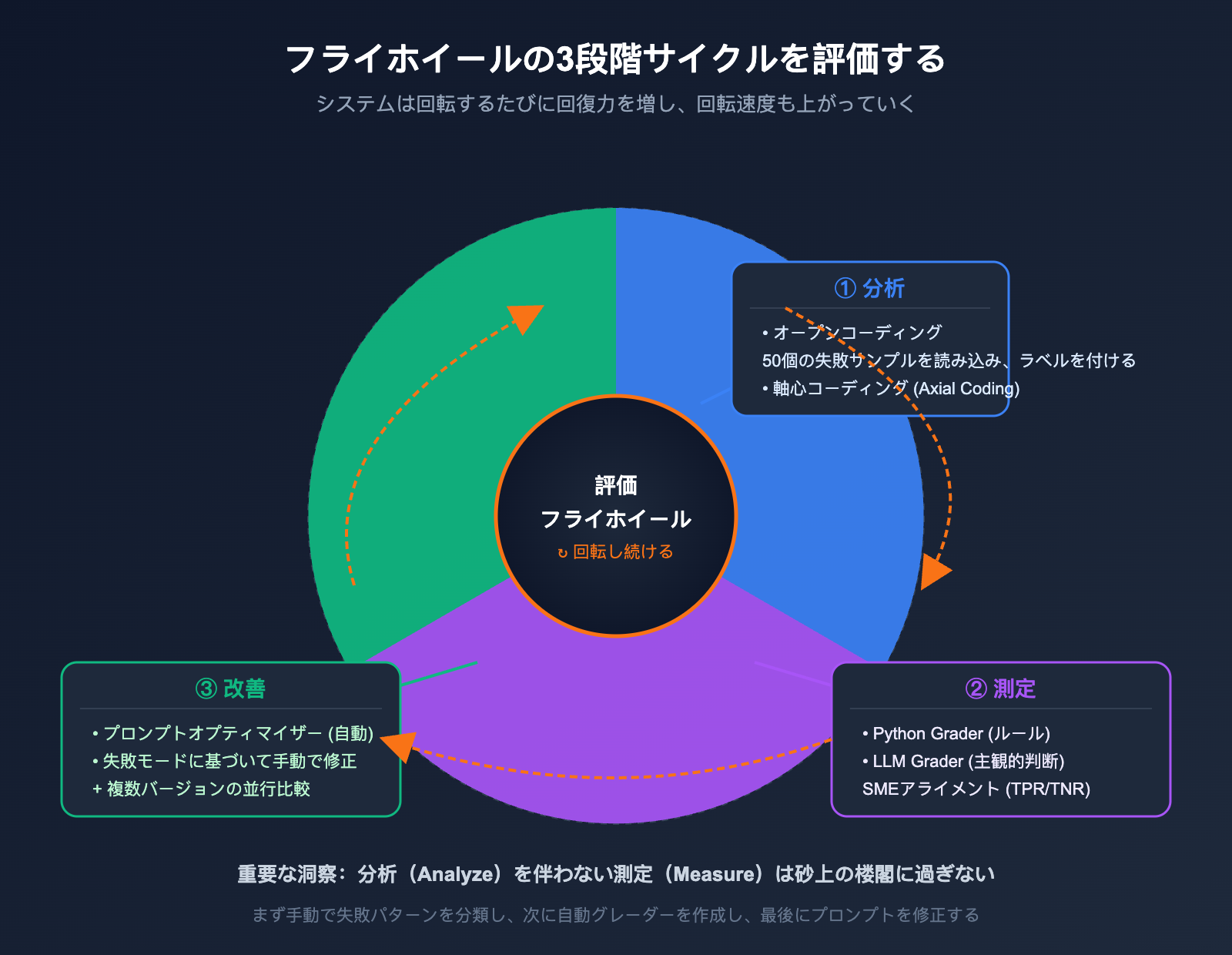
3つの段階の役割は非常に明確で、それぞれが特定の課題を解決します。
| 段階 | 核心的な問い | 主な活動 | 出力物 |
|---|---|---|---|
| Analyze (分析) | 「なぜ失敗したのか?」 | 失敗サンプルを人間が読み、パターンを帰納する | 失敗分類リスト + 割合 |
| Measure (度量) | 「失敗の深刻度は?」 | グレーダーを作成し、データセットを実行する | 定量指標 + ベースライン |
| Improve (改善) | 「どう修正するか?」 | プロンプトを修正し、評価を再実行する | 新バージョン + 指標比較 |
多くのチームが Analyze 段階を飛ばして自動評価に飛びつきますが、これが評価フライホイールが失敗する最も一般的な原因です。定性分析を欠いた自動測定は砂上の楼閣に過ぎません。なぜなら、自分が何を測定しているのかを理解できていないからです。これこそが、このクックブックの最も核心的な洞察であり、一般的な評価(Evals)チュートリアルとの違いです。
💡 類推による理解: 評価フライホイールは、プロダクトマネージャーにはおなじみの PDCA サイクルに似ていますが、プロンプトエンジニアリングに応用することで具体的な方法論が裏付けられています。Analyze は「問題の発見」、Measure は「問題の定量化」、Improve は「問題の修正」に対応しており、どれ一つ欠けてもいけません。apiyi.com で OpenAI Evals API を利用して評価を実行する際は、まず Analyze 段階をしっかりと固めてから測定を開始することをお勧めします。
OpenAI評価フライホイール第1段階:Analyze(分析)の2ステップアノテーション法
Analyze 段階は、評価フライホイールの中で最も見過ごされがちですが、最も重要な部分です。クックブックでは、非常に専門的な手法を紹介しています。それは、**「Open Coding(オープンコーディング) → Axial Coding(軸コーディング)」**という手法です。これは社会学の定性研究から生まれた手法で、数十年にわたる検証を経て、非構造化テキストデータを分析するための最も成熟したパラダイムの一つとなっています。
**第1ステップの Open Coding(オープンコーディング)**の作業は非常にシンプルです。50件の失敗サンプルを読み、分類をあらかじめ想定することなく、それぞれの失敗に対して直接、説明的なラベルを貼っていきます。例えば:
- 「存在しない内見時間を提案した」
- 「設備リストがテキストの塊になっている」
- 「予約変更時に元の予約がキャンセルされていない」
- 「その物件のものではないサイズを回答した」
- 「間取り図のリンクが開けない」
このステップでは、あえて分類の整然さを追求しないことが重要です。何が見えたかを正直に記述するだけで十分です。Open Coding は読書ノートを書くようなもので、思考を自由に広げてください。早すぎる分類は、エッジケース(境界的なパターン)に対する感度を失わせる原因となります。
**第2ステップの Axial Coding(軸コーディング)**で初めて構造化を行います。第1ステップで作成したバラバラのラベルを、意味のある高次な分類に統合します。クックブックで示されている分類例は以下の通りです:
- 内見スケジュール関連の問題(統合:誤った時間、キャンセル漏れ、二重予約) → 失敗全体の35%
- フォーマットエラー(統合:レイアウト崩れ、リンク切れ) → 失敗全体の10%
- データの正確性関連(統合:営業時間の間違い、サイズの間違い) → 失敗の数%
Axial Coding は目次を整理するようなもので、失敗の「地形図」を明確に把握できるようにします。「35%」という数字は、ROI(投資対効果)が最も高いため、どのカテゴリを優先的に修正すべきかを即座に教えてくれます。
| アノテーション方法 | 目標 | 心構え | 出力 |
|---|---|---|---|
| Open Coding | 発見 (Discovery) | 自由に、分類を想定しない | 50以上の説明的ラベル |
| Axial Coding | 構造化 (Structure) | 帰納し、分類を構築する | 5-8個の高次な失敗カテゴリ |
🔧 実務上のアドバイス: 国内のエンジニアが Analyze 段階を行う際は、本番環境のログを OpenAI 互換 API(例:apiyi.com)経由で Evals API プラットフォームのデータセットアノテーション画面に直接取り込むと、バックエンドを自作する必要がありません。Open Coding には Feedback 型のアノテーション列を、Axial Coding には Label 型のアノテーション列を使用すれば、クックブックと全く同じプロセスを実現できます。
OpenAI 評価フライホイール第2段階:Measure(測定)における2種類のグレーダー選定
Analyze(分析)段階で「失敗がどのようなものか」を把握したら、Measure(測定)段階ではそれらの失敗を自動検知コードに変換する必要があります。OpenAIのクックブックでは、エンジニアが最も混同しやすい2種類のグレーダー(評価器)の選定ガイドラインが示されています。
| グレーダーの種類 | 適用シーン | メリット | デメリット |
|---|---|---|---|
| Pythonグレーダー | 決定論的ルール(文字列、正規表現、API検証) | 結果が安定、幻覚なし、追加コストゼロ | 主観的な次元の評価は困難 |
| LLMグレーダー | 主観的判断(フォーマットの美しさ、意味の整合性、推論品質) | 柔軟、コード化しにくい次元も評価可能 | SMEによるアライメント検証が必要、トークンコストが発生 |
アパート検索アシスタントを例に挙げると、それぞれのグレーダーには適した役割があります。
- 「推奨時間は実際の空き状況と一致しているか?」 → Pythonグレーダー(データベースやAPIを確認)
- 「設備リストのレイアウトは見やすいか?」 → LLMグレーダー(0〜10点で採点)
- 「間取り図のリンクはアクセス可能か?」 → Pythonグレーダー(HEADリクエスト)
- 「回答のトーンはブランドイメージに合っているか?」 → LLMグレーダー(評価基準に基づく採点)
クックブックでは、非常に重要なエンジニアリングプラクティスが強調されています。それは、LLMグレーダーは必ずSME(Subject Matter Expert:領域専門家)によるアライメント検証を行うことです。GPT-4oのスコアを盲信してはいけません。具体的な手法としては、データをトレーニング用・検証用・テスト用に分割し、以下の2つの指標を同時にチェックします。
- High TPR(True Positive Rate:真陽性率): 実際の失敗を正しく捉えられているか
- High TNR(True Negative Rate:真陰性率): 本来正しいサンプルを誤って失敗と判定していないか
単に正解率(Accuracy)だけを見ていると、ベースラインの高さに惑わされてしまいます。必ずこれら2つの指標でアライメントを確認してください。これが「LLM-as-Judge(評価者としてのLLM)」を「なんとなく動いている」状態から「本当に機能する」状態へと引き上げる分水嶺となります。
📊 検証プロセス: SMEが100件のサンプルを正解データ(Ground Truth)として作成 → LLMグレーダーが同じサンプルを採点 → TPR/TNRを算出 → 両方の指標が基準を満たすまでグレーダーのプロンプトを調整。このプロセスは、OpenAI公式プロトコルに完全準拠しているAPIYIのEvalsプラットフォームでネイティブにサポートされています。
OpenAI 評価フライホイール第3段階:Improve(改善)における二重軌道実験
第3段階では、いよいよプロンプトの修正に着手します。クックブックでは、並行して進めるべき2つの改善パスが提示されています。これらは二者択一ではなく、組み合わせて使用するものです。
パス1:プロンプトオプティマイザーによる自動最適化
OpenAIプラットフォームには「Prompt Optimizer」ツールが組み込まれています。失敗サンプルセットと元のプロンプトを与えると、一連の書き換え戦略(Few-shotの追加、Chain-of-Thoughtの導入、指示順序の調整など)を自動的に試行し、作成したグレーダー上で改善効果を評価してくれます。このパスの利点は手間がかからないことであり、初期の探索段階に適しています。
パス2:失敗パターンに基づく手動プロンプト修正
Analyze段階で特定した具体的な失敗パターンに基づき、エンジニアが手動でプロンプトを修正します。例えば:
- 内見スケジュールの誤り → プロンプトに「利用可能なスケジュールを確認する」という強制ステップを追加
- レイアウトの崩れ → XMLタグを使用して出力フォーマットを明確に指定
- 予約変更の未キャンセル → 「予約をキャンセルしてから再予約する」というステートマシン的な指示を追加
手動パスの利点は精度が高いことです。どの修正がどの失敗パターンに対応しているかを把握できるため、デバッグ時に確信を持って作業できます。
両方のパスを実行し終えると、複数のプロンプト候補が手元に残ります。ここでImprove段階の最も重要なステップが始まります。同じグレーダーセットを使用して、同一データセット上で全バージョンをテストし、最も指標が良いものを選定することです。このステップを飛ばしてはいけません。人間は自分が修正したプロンプトに対して「自己満足」というバイアスを抱きやすいため、唯一それを修正できるのは数値データだけだからです。
すべてのバージョンを実行し終えると、フライホイールが1周します。すると、システムが向上したことで、より深いエッジケースが露呈し、新たな失敗パターンが見つかるはずです。そうなれば、再びAnalyze段階に戻って次のサイクルを開始します。これこそが「フライホイール」という言葉の真髄です。止まることなく回転し続け、回るたびに高速化し、強靭になっていくのです。
韧性プロンプト (Resilient Prompt) と脆弱なプロンプトの根本的な違い
記事タイトルにある resilient prompt(韧性プロンプト)は非常に重要な概念です。クックブックでは次のように定義されています:あらゆる入力に対して高品質な応答を生成できるプロンプト。言葉にすると簡単ですが、実際には非常に高いエンジニアリング基準が求められます。

靭性と脆弱性の違いは、主に5つの側面で現れます:
| 比較項目 | 脆弱なプロンプト | 靭性プロンプト |
|---|---|---|
| 入力の堅牢性 | 単語を変えるだけで崩壊 | 同義語への書き換えにも安定 |
| エッジケース | 異常な出力やハルシネーション | 適切なフォールバックや人へのエスカレーション |
| 可観測性 | ブラックボックスで原因不明 | Graderによる詳細な特定が可能 |
| 本番環境への適合 | デモと本番の乖離 | 完全な評価サイクルを経て導入 |
| 進化性 | Aの修正がBを壊す | 自動回帰テストによる保護 |
エンジニアの直感では「プロンプトはそれなりに動けばいい」と思われがちですが、本番環境では0.1%の確率で問題が発生します。0.1%は小さく見えますが、100万回の呼び出しがあれば1000件の事故を意味します。靭性プロンプトのエンジニアリング価値は、80%を90%にすることではなく、99%を99.9%に引き上げることにあります。
🚀 接続のヒント: プロンプトを99.9%の靭性まで高めるには、評価サイクルを自動化する必要があります。そのためには、OpenAI Evals APIとPrompt Optimizerツールの安定した利用が不可欠です。APIYI.comのようなOpenAI公式互換APIプラットフォームを利用することをお勧めします。インターフェースは公式と完全に同期しており、国内のIDCノードにより、長時間の評価タスクでも接続が切れることはありません。
OpenAI評価フライホイールのCI/CD統合と本番モニタリング
クックブックの最後で強調されているのは、評価フライホイールを日常的なエンジニアリングの規律にすることです。具体的には以下の2つのステップで実現します。
ステップ1:CI/CD統合
GraderスイートをCIパイプラインに接続し、プロンプトが変更されるたびに自動で評価を実行します。指標が閾値を超えて低下した場合、PRのマージを自動的にブロックします。このステップにより、「評価」は研究活動から日常的な開発業務へと変わり、プロンプトが真にエンジニアリングの領域に入ったことを示します。
| CI閾値タイプ | 推奨設定 | 説明 |
|---|---|---|
| 全体精度 | 低下 ≤ 1% | 全体的な回帰を防止 |
| 主要Grader | 低下 ≤ 0.5% | 優先度の高い失敗モードを厳格に管理 |
| 新モード検出 | 警告(ブロックはしない) | 新たな問題の発見を促進 |
| 遅延 P95 | 増加 ≤ 10% | コストとユーザー体験を制御 |
ステップ2:本番モニタリング
CIだけでなく、本番環境でも継続的にサンプリングを行い、CIセットに含まれていない「野生の失敗モード」を発見します。これらの新しいパターンは評価セットに戻され、フライホイールを次の回転へと押し進めます。
具体的な手法として、本番ログを一定の割合(例:1%)でサンプリングし、同じGraderで評価します。指標に異常が見つかった場合は、人間が分析を行います。新しく発見された失敗モードは、「Open Coding」や「Axial Coding」を経てテストセットに追加され、フライホイールが再び回転します。
このサイクルにより、プロンプトシステムは常に靭性を高め続けることができ、デプロイして終わりという停滞を防げます。これこそが、クックブックがすべてのAIエンジニアに残した核心的なエンジニアリングの規律です。
OpenAIの評価フライホイール:国内開発者向けの5つの実践的ヒント
OpenAIのCookbookを読み込み、日本の開発者にとって直接的な指針となる5つのヒントを抽出しました。
ヒント1:Measure(測定)からではなく、Analyze(分析)から始める
多くのチームがいきなり評価ツール(grader)を導入し、指標を追いかけますが、人間による分析のステップを飛ばしてしまいがちです。その結果、graderが測定しているのは「真の失敗パターン」ではなく、数字上は綺麗でもユーザーからの苦情が止まらないという事態に陥ります。50件の人手によるオープンコーディング(Open Coding)を行うまでは、自動評価を始めないでください。
ヒント2:オープンコーディングの段階でGPTを使わない
オープンコーディングは必ず人間が行う必要があります。なぜなら、GPTは帰納的な処理を行う際、学習データに含まれる偏見でラベルを汚染してしまう可能性があるからです。LLMを介入させるのは、アキシャルコーディング(Axial Coding)を経てgraderを実装する段階からで十分です。分析における「発見」のプロセスは、人間が独占すべき領域です。
ヒント3:LLM GraderよりもPython Graderを優先する
決定論的なルールでカバーできるのであれば、LLM Graderを使う必要はありません。理由は3つあります。安定していること、安価であること、そして専門家(SME)による調整が不要であることです。LLM Graderは、主観的でルールベースではカバーできない領域のために取っておきましょう。
ヒント4:指標をビジネスインパクトと紐付ける
「スケジューリングの問題が35%」「フォーマットの問題が10%」といった数字は、それだけでは意味がありません。「ユーザー離脱率」や「苦情率」に換算して初めて、意思決定の材料になります。指標そのものに価値はなく、それが引き起こすビジネス上の結果にこそ価値があります。
ヒント5:フライホイールを一度限りのプロジェクトにせず、自動化する
フライホイールを一度回すだけではROI(投資対効果)は限定的かもしれませんが、長期的な複利効果は非常に大きいです。graderをCIタスクに組み込み、本番環境のサンプリングを定期実行し、新たな問題の検知を自動アラート化することで、フライホイールを24時間自動で回し続けましょう。
OpenAI評価フライホイールを国内で再現するためのPythonコード構成
Cookbookでは主にOpenAI PlatformのUIワークフローが紹介されていますが、Evals APIのプログラム呼び出しでも同様のことが可能です。以下のPythonコードは、コードベースのワークフローを好む国内開発者向けに、Evals APIを使用してgraderを作成し、評価を実行する骨組みを示しています。
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # OpenAI官転ゲートウェイに切り替え
api_key="あなたのAPIYIキー"
)
# 1. 評価タスクの作成 (graderの集合を定義)
eval_cfg = await client.evals.create(
name="leasing_assistant_v1",
data_source_config={
"type": "stored_completions",
"metadata": {"version": "v1"}
},
testing_criteria=[
{ # Python Graderの例
"type": "string_check",
"name": "tour_time_valid",
"input": "{{sample.output}}",
"operation": "eq",
"reference": "{{item.expected_time}}"
},
{ # LLM Graderの例
"type": "score_model",
"name": "format_quality",
"model": "gpt-4o",
"input": "{{sample.output}}",
"instructions": "出力のフォーマットの明確さを0〜10で採点してください"
}
]
)
# 2. 評価の実行 (run)
run = await client.evals.runs.create(
eval_id=eval_cfg.id,
name="baseline_run",
data_source={"type": "completions"}
)
# 3. 評価結果の取得
result = await client.evals.runs.retrieve(eval_id=eval_cfg.id, run_id=run.id)
print(f"合格率: {result.report_url}")
このコードには3つの重要なポイントがあります。1つ目はbase_urlの切り替えで、これが国内から長時間にわたる評価タスクを安定して実行できるかを左右します。2つ目はtesting_criteria配列で、すべてのgraderを配列として設定し、一度に実行できます。3つ目はEvals APIが非同期である点です。大規模なデータセットでの評価には数分から数十分かかる可能性があるため、プログラム内で待機やリトライの処理を適切に実装してください。
OpenAI 評価フライホイール FAQ
Q1: 評価フライホイールと LangSmith や Weights & Biases といった評価プラットフォームには違いがありますか?
位置付けが異なります。LangSmith は主に「評価のツール化」を解決するものであり、評価フライホイールは「評価の方法論」を解決するものです。前者は「どう実装するか」を教え、後者は「どう考えるか」を教えます。両者は組み合わせて使用することができ、ツールを使って方法論を運用するのが理想的です。
Q2: 50 個の失敗サンプルで十分ですか?少なすぎませんか?
オープンコーディング(Open Coding)の段階であれば 50 個で十分です。目標は統計的な網羅ではなく、パターンの発見にあるからです。測定(Measure)段階で必要なサンプル数は失敗率に依存します。失敗率が 5% なら、安定した指標の信頼区間を得るには 1000 件のサンプルが必要ですが、失敗率が 30% であれば 200 件で十分です。
Q3: プロンプトオプティマイザー(Prompt Optimizer)による自動最適化は、手動修正を完全に代替できますか?
いいえ、できません。自動ツールは既知の評価基準(grader)に基づいた局所的な最適化には優れていますが、「顧客が各回答を 80 文字以内と要求している」といった暗黙のビジネス制約を理解するのは苦手です。手動修正と自動最適化を組み合わせるのがベストプラクティスです。
Q4: 国内から OpenAI の API を呼び出すのは安定していますか?
OpenAI に直接接続して長時間かかるタスク(評価は通常数分から数時間かかります)を実行すると、接続がリセットされることがよくあります。国内のデータセンターノード向けに長時間の接続が最適化されている APIYI(apiyi.com)のような OpenAI API 中継サービスを利用することをお勧めします。これにより、評価タスクの中断率を大幅に低減できます。
Q5: 評価フライホイールはどのような規模のチームに適していますか?
1 人のプロジェクトから 100 人のチームまで適用可能です。違いはフライホイールを回す頻度だけです。1 人のプロジェクトなら 2 週間で 1 回転するかもしれませんが、大規模なチームであれば日次や時間単位でのイテレーションが可能です。重要なのは規模ではなく、規律を確立することです。
Q6: Hamel Husain とは何者ですか?なぜこのクックブックがこれほど注目されているのですか?
Hamel は機械学習コミュニティにおいて非常に影響力のある教育者であり、長年にわたり大規模言語モデル(LLM)アプリケーションのエンジニアリングにおけるベストプラクティスを推進してきました。このクックブックは、OpenAI が公式に定性研究手法(オープンコーディングなど)をプロンプトエンジニアリングに体系的に導入した初めての事例であるため、業界で大きな議論を呼んでいます。
まとめ
OpenAI 評価フライホイールという方法論の真の価値は、日本の AI エンジニアコミュニティに対して「プロンプトエンジニアリングをどう行えばプロフェッショナルと言えるのか」という問いに対する標準的な回答を示した点にあります。これは単なるツールではなく、プロンプト開発を「感覚に頼った職人芸」から「追跡可能なエンジニアリングの実践」へと変えるためのエンジニアリング規律です。
「分析(Analyze)→ 測定(Measure)→ 改善(Improve)」という 3 つの段階を開発プロセスに組み込むことで、あなたの AI アプリケーションは「デモとしてはそれっぽい」レベルから、「本番環境に投入し、SLA を約束できる」製品へと進化します。このアップグレードの裏側には、失敗が体系的に収集され、パターンが構造的に整理され、改善が自動測定によって検証されるという完全な閉ループが存在します。
プロンプト主導型の AI アプリケーションを開発しているなら、ぜひこのフライホイールを構築することをお勧めします。APIYI(apiyi.com)のような OpenAI API 中継プラットフォームを利用すれば、base_url を一行書き換えるだけでクックブックの全プロセスを実行でき、国内のネットワーク安定性に悩まされることもありません。
「フライホイール」を筋肉に記憶させれば、あなたのプロンプトは今日から、より強靭なものへと進化し始めるはずです。
📌 著者: APIYI Team — OpenAI / Anthropic / Google のマルチモーダル API のエンジニアリング実践事例を長期的に追跡しています。クックブックの実践解説や Evals API の接続ガイドについては、apiyi.com のドキュメントセンターをご覧ください。