Catatan penulis: Panduan lengkap cara memanggil model kimi-k2.5 melalui platform APIYI dengan mengaktifkan parameter enable_thinking, nikmati harga stabil di bawah 80% dari harga resmi. Dilengkapi dengan contoh kode lengkap untuk curl, Python, dan JavaScript.

Mode berpikir (thinking) pada Kimi K2.5 adalah salah satu fitur dengan kemampuan penalaran terkuat di antara model open-source saat ini, dengan skor benchmark matematika AIME 2025 mencapai 96,1%. Namun, banyak pengembang yang mengalami masalah yang sama saat melakukan integrasi: model tidak menampilkan proses berpikir setelah API dipanggil.
Hal ini terjadi karena pada platform APIYI, Anda perlu menyertakan parameter "enable_thinking": true secara manual untuk mengaktifkan mode berpikir tersebut. Artikel ini akan memandu Anda dari nol untuk menyelesaikan konfigurasi integrasi mode berpikir Kimi K2.5.
🎯 Nilai Utama: Setelah membaca artikel ini, Anda akan menguasai cara pemanggilan lengkap mode thinking kimi-k2.5 dan memahami cara menggunakan kemampuan ini melalui APIYI dengan harga stabil di bawah 80% dari harga resmi.
Poin Utama Mode Thinking Kimi K2.5
| Poin | Penjelasan | Nilai |
|---|---|---|
| Parameter Aktivasi | Perlu menyertakan "enable_thinking": true |
Membuka kemampuan penalaran mendalam |
| Saran temperature | Atur ke 1.0 (nilai tetap) |
Menjamin kualitas penalaran yang stabil |
| Saran max_tokens | ≥ 16000 | Memastikan konten penalaran keluar sepenuhnya |
| Keunggulan Harga | Harga grup 0,88, di bawah 80% harga resmi | Mengurangi biaya penalaran secara signifikan |
| Stabilitas | Setara dengan layanan resmi Alibaba | Jaminan keandalan tingkat perusahaan |
💡 Mulai Cepat: Daftar akun APIYI di apiyi.com, lakukan pengisian saldo, dan Anda bisa langsung memanggil kimi-k2.5. Mendukung antarmuka yang kompatibel dengan OpenAI, tanpa perlu mengubah kerangka kode yang sudah ada.
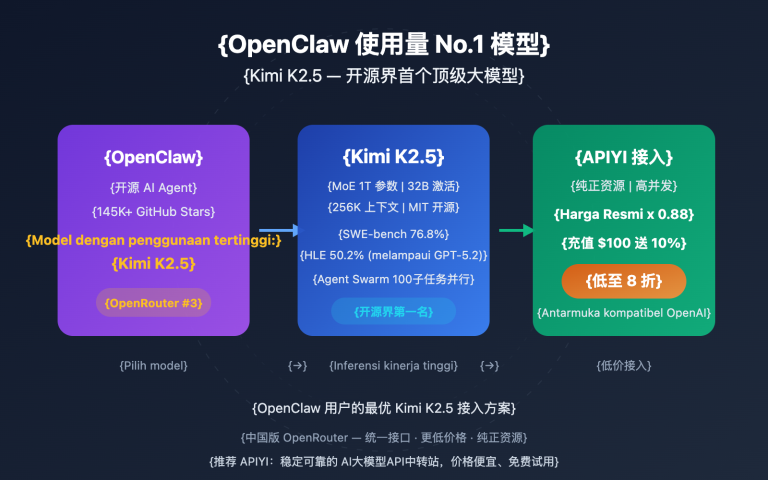
Apa itu Kimi K2.5: Unggulan Inferensi Open-Source dengan 1 Triliun Parameter
Kimi K2.5 dirilis oleh Moonshot AI pada 27 Januari 2026, dan saat ini menjadi salah satu Model Bahasa Besar multimodal dengan kemampuan inferensi terkuat di komunitas open-source.
Spesifikasi Arsitektur Inti Kimi K2.5
| Spesifikasi | Nilai | Penjelasan |
|---|---|---|
| Total Parameter | 1 Triliun (1T) | Arsitektur campuran pakar (MoE) |
| Parameter Aktif | 32 Miliar (32B) | Digunakan saat inferensi |
| Jendela Konteks | 256K token | Kemampuan pemrosesan dokumen super panjang |
| Jumlah Pakar | 384 lapisan pakar | Arsitektur ganda MLA + MoE |
| Data Pelatihan | ~15 Triliun token | Campuran teks + gambar |
| Status Open-Source | Terbuka sepenuhnya | Dapat diunduh di HuggingFace |
Kimi K2.5 menggunakan Multi-head Latent Attention (MLA) dan struktur MoE 384 pakar. Dengan tetap mempertahankan total 1 triliun parameter, model ini hanya mengaktifkan 32 miliar parameter saat inferensi, sehingga mencapai keseimbangan optimal antara performa dan biaya.
Empat Mode Operasi Kimi K2.5
K2.5 Instant → Respons instan, tanpa proses berpikir, cocok untuk tugas sederhana
K2.5 Thinking → Inferensi mendalam, menghasilkan reasoning_content, cocok untuk masalah kompleks
K2.5 Agent → Eksekusi tugas mandiri, kemampuan pemanggilan alat
K2.5 Agent Swarm → Kolaborasi multi-agen, hingga 100 sub-agen secara paralel
Platform APIYI saat ini mendukung mode K2.5 Thinking, yang diaktifkan melalui parameter enable_thinking: true untuk menghasilkan rantai penalaran yang lengkap.
💡 Saran Penggunaan: Direkomendasikan untuk mengakses kimi-k2.5 melalui APIYI apiyi.com, jalur proksi resmi Alibaba Cloud yang stabil, sehingga Anda tidak perlu khawatir akan gangguan layanan.

Tolok Ukur Performa Kimi K2.5: Data Uji Mode Berpikir
Setelah mengaktifkan mode thinking, performa penalaran kimi-k2.5 meningkat drastis. Berikut adalah data tolok ukur utamanya:
Hasil Tolok Ukur Utama
| Tolok Ukur | Skor Kimi K2.5 | Penjelasan Perbandingan |
|---|---|---|
| AIME 2025 (Penalaran Matematika) | 96,1% | Mendekati skor sempurna, kemampuan matematika tingkat atas |
| SWE-Bench Verified (Kode) | 76,8% | Level terdepan di antara model sumber terbuka |
| HLE-Full w/ tools (Agen) | Unggul 4,7 poin | Peringkat pertama untuk tugas pemanggilan alat |
| BrowseComp (Penjelajahan Web) | 60,6% / 78,4%* | *Dalam mode Agent Swarm |
| Indeks Kecerdasan Komprehensif | 47 poin | Rata-rata industri adalah 27 poin |
Catatan: Data di atas berasal dari Artificial Analysis Intelligence Index, hasil evaluasi Januari 2026.
Mode berpikir (Thinking mode) dibandingkan dengan mode standar, memberikan peningkatan signifikan sebesar 30-50% pada tugas matematika kompleks, penalaran multi-langkah, dan pembuatan kode. Konsekuensinya, konsumsi token sekitar 2-4 kali lipat dari mode standar, sehingga mengontrol max_tokens dengan bijak adalah kunci efisiensi biaya.
3 Langkah Mengaktifkan Mode Thinking Kimi K2.5 di APIYI
Langkah 1: Daftar dan Dapatkan Kunci API
Kunjungi situs resmi APIYI di apiyi.com untuk mendaftarkan akun dan selesaikan langkah berikut:
- Daftar akun dan selesaikan verifikasi email
- Masuk ke "Konsol" → "Manajemen Kunci API"
- Buat kunci API baru, salin dan simpan
🎯 Keunggulan Harga: Isi saldo 100 USD langsung dapat bonus 10 USD, harga grup 0,88 (token input), biaya penggunaan aktual lebih rendah dari diskon 20% situs resmi Kimi. APIYI menyediakan jalur stabil setingkat layanan resmi Alibaba Cloud dengan keandalan kelas perusahaan.
Langkah 2: Konfigurasi Parameter Permintaan
Kunci untuk mengaktifkan mode berpikir kimi-k2.5 terletak pada konfigurasi tiga parameter berikut:
{
"model": "kimi-k2.5",
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}
⚠️ Catatan Penting: Logika parameter platform APIYI berbeda dengan API resmi Kimi:
- Kimi Resmi: Mode berpikir aktif secara default, perlu parameter untuk menonaktifkannya
- Platform APIYI: Perlu menambahkan
"enable_thinking": truesecara manual untuk mengaktifkannya
Langkah 3: Kirim Permintaan dan Parsing Konten Berpikir
Berikut adalah contoh pemanggilan lengkap, termasuk aktivasi mode berpikir dan parsing respons.
Contoh curl (Cara verifikasi tercepat)
curl --location 'https://api.apiyi.com/v1/chat/completions' \
--header "Authorization: Bearer sk-KUNCI_API_ANDA" \
--header 'Content-Type: application/json' \
--data '{
"model": "kimi-k2.5",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Jelaskan dengan langkah-langkah: Mengapa 0.1 + 0.2 di komputer tidak sama dengan 0.3?"
}
],
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}'
Contoh Python (Direkomendasikan untuk lingkungan produksi)
from openai import OpenAI
client = OpenAI(
api_key="sk-KUNCI_API_ANDA",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Analisis kompleksitas waktu kode ini dan berikan saran optimasi:\n\ndef find_duplicates(arr):\n result = []\n for i in range(len(arr)):\n for j in range(i+1, len(arr)):\n if arr[i] == arr[j] and arr[i] not in result:\n result.append(arr[i])\n return result"
}
],
extra_body={
"enable_thinking": True
},
temperature=1.0,
max_tokens=16000
)
# Parsing konten berpikir (jika ada)
message = response.choices[0].message
# Output proses berpikir (bidang reasoning_content)
if hasattr(message, 'reasoning_content') and message.reasoning_content:
print("=== Proses Berpikir ===")
print(message.reasoning_content)
print()
# Output jawaban akhir
print("=== Jawaban Akhir ===")
print(message.content)
Buka contoh lengkap JavaScript / Node.js
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'sk-KUNCI_API_ANDA',
baseURL: 'https://api.apiyi.com/v1',
});
async function callKimiThinking(userMessage) {
const response = await client.chat.completions.create({
model: 'kimi-k2.5',
messages: [
{
role: 'system',
content: 'You are a helpful assistant.',
},
{
role: 'user',
content: userMessage,
},
],
// Kirim parameter enable_thinking melalui extra_body
// @ts-ignore
enable_thinking: true,
temperature: 1.0,
max_tokens: 16000,
});
const message = response.choices[0].message;
// Ekstrak proses berpikir
const reasoningContent = message.reasoning_content;
if (reasoningContent) {
console.log('=== Proses Berpikir ===');
console.log(reasoningContent);
console.log();
}
// Ekstrak jawaban akhir
console.log('=== Jawaban Akhir ===');
console.log(message.content);
return {
thinking: reasoningContent,
answer: message.content,
};
}
// Contoh penggunaan
callKimiThinking('Buktikan langkah demi langkah: Bahwa bilangan prima itu tak terhingga (Pembuktian Euclid)');
💡 Tips Integrasi: Ganti
base_urlpada kode di atas menjadihttps://api.apiyi.com/v1. Parameter lainnya sepenuhnya kompatibel dengan OpenAI SDK, sehingga tidak perlu mempelajari hal baru. APIYI apiyi.com mendukung pemanggilan semua model utama dengan satu Kunci API.
Penjelasan Parameter Utama: Konfigurasi Tepat Agar Tidak Salah Langkah
Tabel Perbandingan Konfigurasi Parameter
| Parameter | Nilai Rekomendasi | Penjelasan | Contoh Salah |
|---|---|---|---|
model |
"kimi-k2.5" |
Pengenal model | Jangan tulis kimi-k2 atau kimi-k2.5-thinking |
enable_thinking |
true |
Aktifkan mode berpikir (khusus APIYI) | Tanpa parameter ini, konten penalaran tidak akan muncul |
temperature |
1.0 |
Nilai tetap yang direkomendasikan resmi | Mengatur ke 0.7 dsb. akan membuat kualitas tidak stabil |
max_tokens |
≥ 16000 |
Pastikan output lengkap | Terlalu kecil akan memotong konten penalaran |
stream |
false (uji awal) |
Mendukung streaming/non-streaming | Streaming memerlukan penanganan tambahan pada kolom reasoning |
Penjelasan Struktur Respons API
{
"choices": [
{
"message": {
"role": "assistant",
"content": "Konten jawaban akhir...",
"reasoning_content": "Proses berpikir model, mencakup penalaran langkah demi langkah..."
}
}
],
"usage": {
"prompt_tokens": 150,
"completion_tokens": 3200,
"total_tokens": 3350
}
}
Kolom reasoning_content berisi konten rantai pemikiran yang lengkap, biasanya 3-5 kali lebih panjang dari kolom content, dan merupakan data inti untuk memahami proses pengambilan keputusan model.
🎯 Saran Pengendalian Biaya: Dalam mode thinking, konsumsi token sekitar 2-4 kali lipat dari mode biasa. Kami menyarankan untuk mengakses melalui APIYI apiyi.com, harga grup 0,88 dapat sangat mengurangi biaya penalaran, dan isi ulang 100 USD juga akan mendapatkan bonus kredit 10 USD.
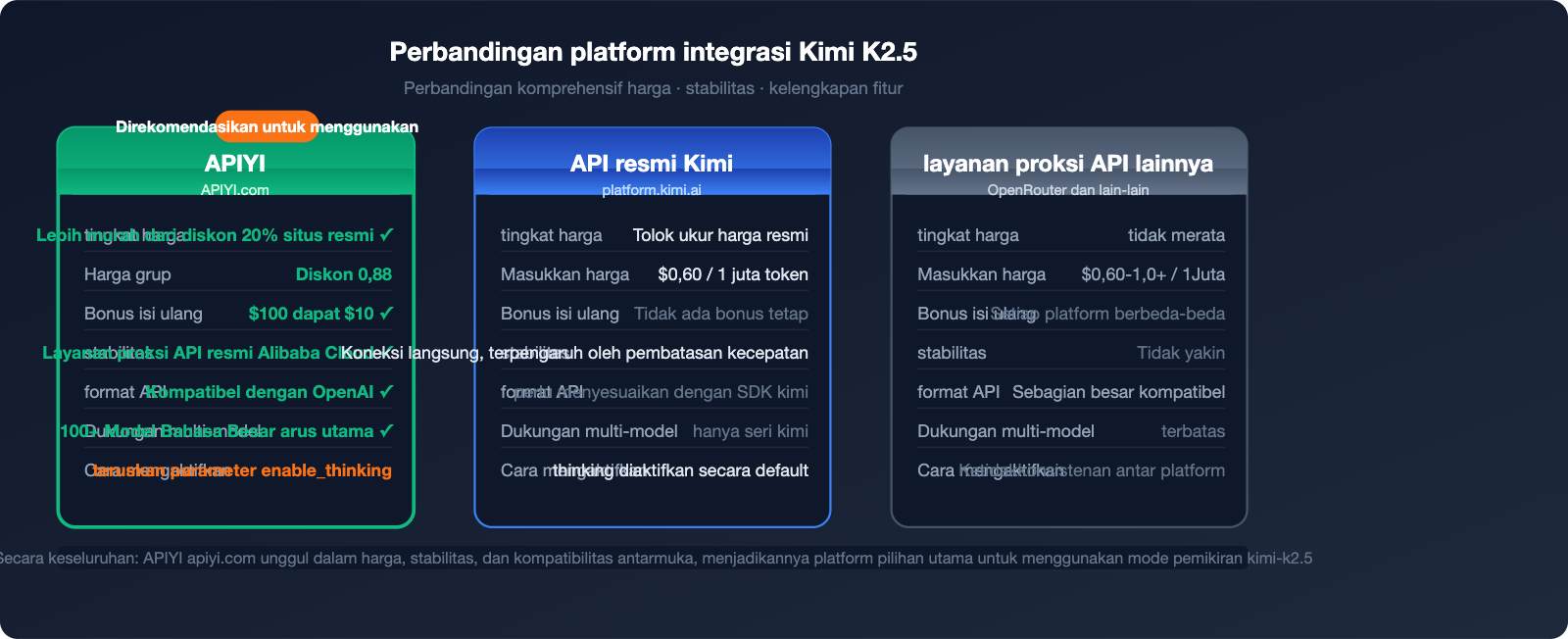
APIYI vs Situs Resmi: Perbandingan Harga dan Stabilitas
Ringkasan Perbandingan Platform
| Dimensi Perbandingan | APIYI (apiyi.com) | API Resmi Kimi | Platform Layanan Proksi Lain |
|---|---|---|---|
| Tingkat Harga | Di bawah 80% harga resmi (harga grup 0.88) | Harga resmi | Bervariasi |
| Stabilitas | Setara dengan layanan resmi Alibaba Cloud | Koneksi langsung, terpengaruh limitasi | Tidak pasti |
| Promo Isi Saldo | Isi $100 bonus $10 | Tidak ada bonus tetap | Beragam |
| Kompatibilitas API | Format OpenAI, kompatibel 100% | Perlu adaptasi SDK Kimi | Sebagian besar kompatibel |
| Dukungan Model | 100+ model populer | Hanya seri Kimi | Terbatas |
| Dukungan Bisnis | CS eksklusif + Faktur | Dukungan standar | Terbatas |
Contoh Perhitungan Keunggulan Harga APIYI
Sebagai contoh, penggunaan 1000 kali pemanggilan model kimi-k2.5 thinking per bulan (rata-rata 3000 token input + 5000 token output per pemanggilan):
Biaya token input:
Harga resmi sekitar $0,60/1M → 1000x × 3000 token = 3M token → $1,80
Harga grup APIYI diskon 0,88 → sekitar $1,58
Biaya token output (termasuk reasoning):
Harga resmi sekitar $2,50/1M → 1000x × 5000 token = 5M token → $12,50
Harga grup APIYI diskon 0,88 → sekitar $11,00
Penghematan bulanan: sekitar $1,72 + bonus isi saldo mencakup tambahan sekitar 10% biaya
💡 Diskon Aktual: "Di bawah 80%" dari APIYI berasal dari dua kombinasi—diskon harga grup (0,88) + bonus isi saldo (isi 100 dapat 10, yaitu tambahan 10% anggaran). Biaya komprehensif aktual sekitar 79-80% dari harga resmi.
Skenario Penggunaan Terbaik Mode Thinking Kimi K2.5
Skenario yang Disarankan Mengaktifkan Thinking
1. Penalaran Matematika Kompleks
# Cocok untuk mode thinking
petunjuk = "Tolong buktikan Teorema Terakhir Fermat untuk kasus n=3, dan berikan langkah-langkah detailnya"
2. Debugging dan Optimasi Kode
# Cocok untuk mode thinking
petunjuk = """
Kode berikut memiliki bug konkurensi tersembunyi, tolong temukan dan perbaiki:
[Tempel kode multi-thread yang kompleks]
"""
3. Analisis Logika Multi-Langkah
# Cocok untuk mode thinking
petunjuk = "Analisis celah logika dalam rencana bisnis ini, dan urutkan berdasarkan prioritas"
4. Penurunan Masalah Ilmiah
# Cocok untuk mode thinking
petunjuk = "Turunkan rumus tingkat energi atom hidrogen dari prinsip dasar mekanika kuantum"
Skenario yang Tidak Perlu Mengaktifkan Thinking
# Skenario berikut menggunakan mode biasa (tanpa enable_thinking), dapat menghemat 50-70% biaya token
# Tanya jawab sederhana
"Bagaimana cuaca hari ini?" # Tidak perlu penalaran
# Terjemahan teks
"Tolong terjemahkan konten berikut ke bahasa Inggris:..." # Tidak perlu penalaran
# Format output
"Format data JSON berikut agar mudah dibaca" # Tidak perlu penalaran
# Penulisan kreatif
"Tulis sebuah puisi tentang musim semi" # Tidak perlu penalaran mendalam
🎯 Saran Penggunaan: Disarankan untuk beralih mode secara dinamis berdasarkan kompleksitas tugas. Melalui akses APIYI apiyi.com, Anda dapat menggunakan satu kunci API yang sama untuk memanggil kimi-k2.5 (mode thinking) dan model ringan lainnya secara fleksibel, serta mencampurnya sesuai kebutuhan.
Streaming Output: Menangani Respons Real-time dalam Mode Thinking
Saat menggunakan streaming output dalam mode thinking, Anda perlu menangani fragmen tambahan dari reasoning_content secara khusus:
from openai import OpenAI
client = OpenAI(
api_key="sk-kunci_API_Anda",
base_url="https://api.apiyi.com/v1"
)
# Contoh pemanggilan streaming
stream = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "user", "content": "Tolong analisis kompleksitas waktu kasus terburuk dari algoritma quicksort"}
],
extra_body={"enable_thinking": True},
temperature=1.0,
max_tokens=16000,
stream=True
)
thinking_buffer = []
answer_buffer = []
is_thinking = True
for chunk in stream:
delta = chunk.choices[0].delta
# Memproses aliran konten pemikiran
if hasattr(delta, 'reasoning_content') and delta.reasoning_content:
thinking_buffer.append(delta.reasoning_content)
print(delta.reasoning_content, end='', flush=True)
# Memproses aliran jawaban akhir
elif delta.content:
if is_thinking:
print("\n\n=== Jawaban Akhir ===\n")
is_thinking = False
answer_buffer.append(delta.content)
print(delta.content, end='', flush=True)
print() # Baris baru
💡 Poin Penting Streaming:
reasoning_contentdancontentadalah kolom independen dalam streaming. Biasanya,reasoning_contentakan diselesaikan terlebih dahulu sebelumcontentmuncul. Anda perlu memantau data tambahan dari kedua kolom tersebut secara terpisah.
Pertanyaan Umum (FAQ)
Q1: Tidak ada kolom reasoning_content setelah pemanggilan, apakah mode berpikir tidak aktif?
A: Silakan periksa tiga hal berikut:
- Apakah parameter
"enable_thinking": truetelah dikirim dengan benar? - Apakah
max_tokenssudah diatur ke 16000 atau lebih? - Apakah pemanggilan Python SDK menggunakan
extra_body={"enable_thinking": True}?
Disarankan untuk melakukan pengujian langsung dengan curl terlebih dahulu guna memastikan format parameter sudah benar sebelum mengintegrasikannya ke dalam kode. Layanan pelanggan APIYI di apiyi.com siap memberikan dukungan teknis.
Q2: Konsumsi token terlalu tinggi dalam mode thinking, bagaimana cara mengontrol biaya?
A: Anda dapat melakukan optimasi dari sisi berikut:
- Matikan mode thinking untuk tugas sederhana (jangan kirim parameter
enable_thinking). - Turunkan
max_tokenssecara proporsional (minimal 8000, namun berisiko memotong penalaran yang kompleks). - Lakukan pemisahan tugas: gunakan kimi-k2.5 thinking untuk penalaran kompleks, dan gunakan model ringan seperti gpt-4o-mini untuk tugas sederhana.
- Manfaatkan harga grup (0.88) di APIYI apiyi.com untuk menekan biaya dasar.
Q3: Apakah temperature harus diatur ke 1.0?
A: Sangat disarankan untuk mengaturnya ke 1.0, karena ini adalah parameter suhu terbaik untuk mode thinking kimi-k2.5. Pengaturan yang terlalu rendah (misalnya 0.7) akan membuat model terlalu konservatif saat menalar, sehingga kualitas menurun; pengaturan yang terlalu tinggi (misalnya 1.5) dapat menghasilkan rantai penalaran yang tidak koheren. Menggunakan 1.0 adalah pilihan yang paling aman.
Q4: Apakah kimi-k2.5 di APIYI sama persis dengan versi resmi?
A: Ya. APIYI menggunakan jalur resmi Alibaba Cloud, sehingga bobot dan kemampuan model benar-benar identik dengan kimi resmi. Perbedaannya hanya terletak pada cara pengiriman parameter: versi resmi mengaktifkan thinking secara default, sedangkan di APIYI Anda perlu mengirim enable_thinking: true secara manual. Ini adalah perbedaan standar pada layanan proksi API dan tidak memengaruhi kualitas output model.
Ringkasan: Poin Utama Mode Berpikir Kimi K2.5
| Poin Kunci | Penjelasan |
|---|---|
| Parameter Aktivasi | Wajib menyertakan "enable_thinking": true |
| Pengaturan Suhu | Gunakan temperature: 1.0 secara tetap |
| Anggaran token | max_tokens ≥ 16000 |
| Kolom Respons | Konten pemikiran ada di reasoning_content, jawaban di content |
| Alamat Akses | https://api.apiyi.com/v1 (kompatibel dengan OpenAI) |
| Diskon Harga | Lebih murah 20% dari harga resmi, isi saldo $100 dapat bonus $10 |
Kimi K2.5 menunjukkan performa luar biasa pada tolok ukur utama seperti penalaran matematika AIME (96,1%) dan pembuatan kode (SWE-Bench 76,8%). Mode berpikir ini sangat cocok untuk menangani tugas kompleks yang memerlukan penalaran multi-langkah.
🎯 Coba Sekarang: Kunjungi situs resmi APIYI di apiyi.com, daftar akun untuk mendapatkan kunci API, dan Anda bisa menyelesaikan integrasi mode berpikir kimi-k2.5 dalam waktu kurang dari 5 menit. Isi saldo 100 USD dan nikmati bonus 10 USD. Jika digabungkan dengan diskon grup, biaya keseluruhan jauh lebih hemat dibandingkan harga resmi Kimi.
Artikel ditulis oleh tim teknis APIYI | Sumber data: Dokumentasi resmi Moonshot AI dan laporan evaluasi Artificial Analysis (Januari 2026)
Untuk dukungan teknis, silakan kunjungi pusat bantuan APIYI: help.apiyi.com