Catatan Penulis: Penjelasan mendalam mengenai arsitektur Thinker-Talker MoE, jendela konteks 256K, kemampuan pengodean audio-video, serta kemampuan emergen Audio-Visual Vibe Coding pada model multimodal asli Qwen3.5-Omni dari Alibaba.
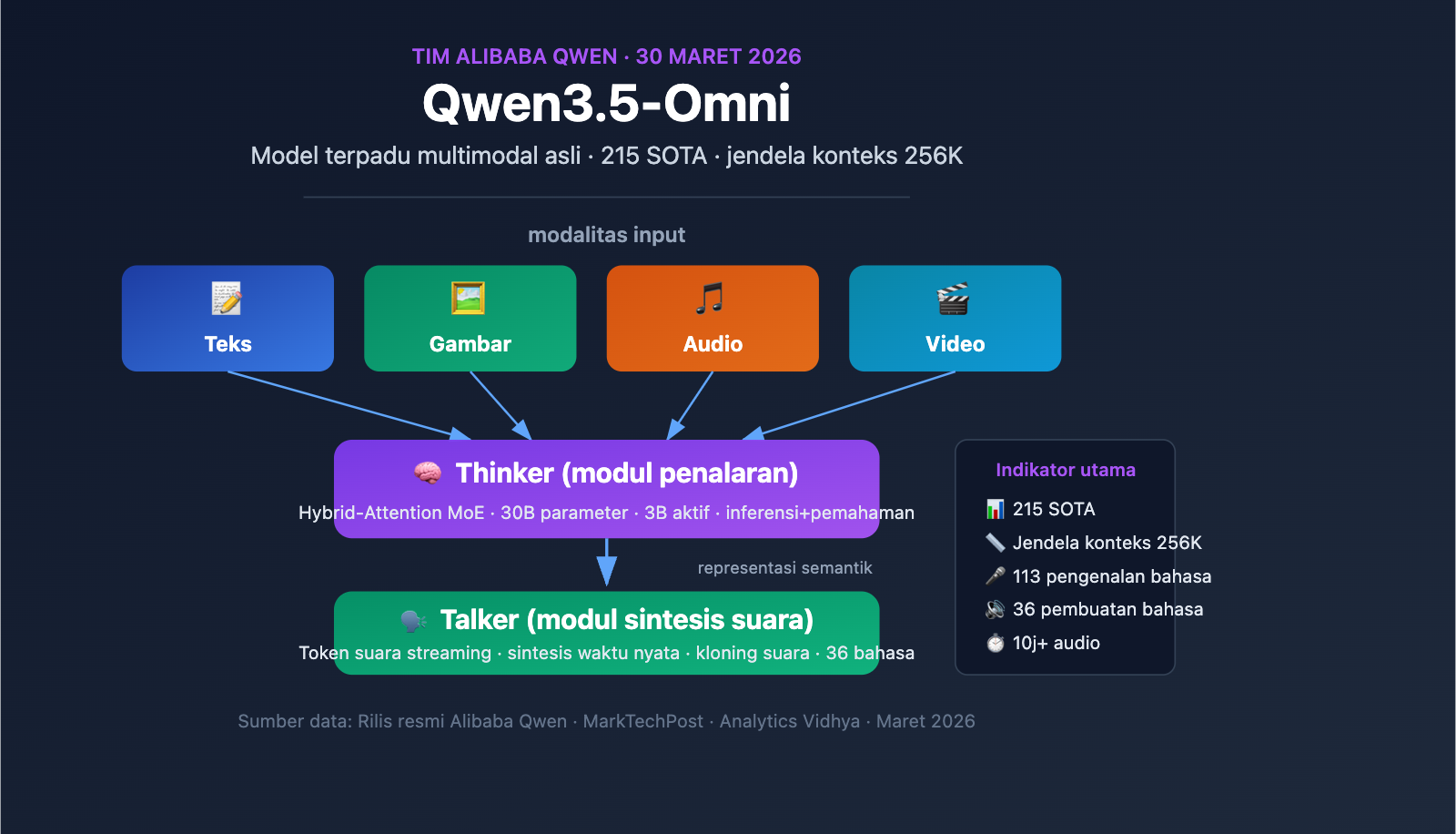
Tim Tongyi Qianwen Alibaba resmi merilis Qwen3.5-Omni pada 30 Maret 2026. Ini adalah model multimodal terpadu yang memproses teks, gambar, audio, dan video secara bersamaan dalam satu alur komputasi tunggal. Sebagai bagian dari rangkaian peluncuran intensif Alibaba selama Maret-April, Qwen3.5-Omni mencapai SOTA di 215 tolok ukur, menandai terobosan penting bagi vendor AI Tiongkok di bidang model bahasa besar (LLM) full-modal.
Nilai Utama: Pahami dalam 3 menit desain arsitektur Thinker-Talker Qwen3.5-Omni, strategi pemilihan tiga varian model, serta kemampuan emergen Audio-Visual Vibe Coding.
Informasi Inti Model Multimodal Qwen3.5-Omni
Sekilas Parameter Kunci Qwen3.5-Omni
| Parameter | Detail |
|---|---|
| Tanggal Rilis | 30 Maret 2026 |
| Penerbit | Tim Tongyi Qianwen (Qwen) Alibaba |
| Arsitektur | Thinker-Talker + Hybrid-Attention MoE |
| Varian Model | Plus (30B-A3B MoE), Flash (MoE ringan), Light (model padat/bobot terbuka) |
| Jendela Konteks | 256K Token |
| Kapasitas Audio | 10+ jam audio berkelanjutan |
| Kapasitas Video | 400+ detik video 720p (sampling 1 FPS) |
| Pengenalan Suara | 113 bahasa dan dialek (generasi sebelumnya hanya 19) |
| Pembuatan Suara | 36 bahasa (generasi sebelumnya hanya 10) |
| Data Pelatihan | Lebih dari 100 juta jam data audio-video |
| Skor Tolok Ukur | SOTA di 215 tolok ukur pemahaman audio/video |
Pemosisian Model Qwen3.5-Omni
Signifikansi utama Qwen3.5-Omni terletak pada sifat multimodal aslinya—ini bukan solusi rakitan di mana model teks disambungkan dengan modul audio dan video, melainkan model terpadu yang dilatih sejak awal pada lebih dari 100 juta jam data audio-video. Semua modalitas diproses dalam alur komputasi yang sama, yang berarti model dapat benar-benar memahami informasi semantik dalam audio dan video, alih-alih hanya mentranskripsikan audio-video menjadi teks sebelum diproses.
Pada saat yang sama, Qwen3.5-Omni adalah salah satu dari rangkaian model yang dirilis secara intensif oleh Alibaba pada Maret-April 2026. Hanya beberapa hari kemudian, pada 2 April, Alibaba merilis model Qwen3.6-Plus untuk aplikasi tingkat perusahaan (mendukung jendela konteks 1 juta Token, berfokus pada pemrograman berbasis agen), yang menunjukkan investasi kuat Alibaba di bidang model bahasa besar.
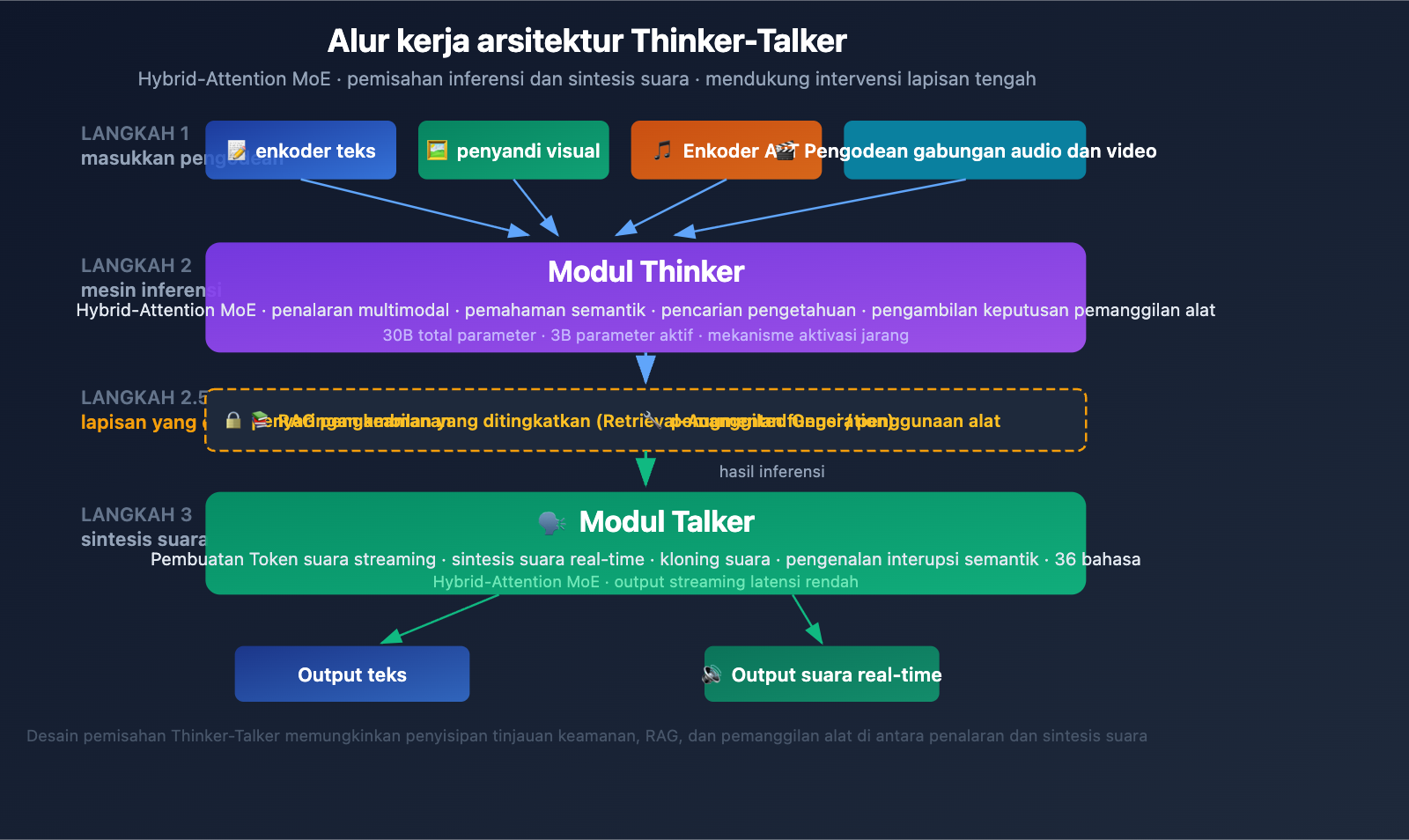
Penjelasan Mendalam Arsitektur Qwen3.5-Omni Thinker-Talker
Desain Modul Ganda Thinker-Talker
Qwen3.5-Omni mengadopsi arsitektur modul ganda Thinker-Talker yang unik. Desain ini pertama kali diperkenalkan pada Qwen2.5-Omni dan mendapatkan peningkatan signifikan pada versi 3.5—kedua modul kini menggunakan arsitektur Hybrid-Attention MoE (Mixture-of-Experts dengan atensi hibrida).
Modul Thinker (Pemikir):
- Memproses semua modalitas input: teks, gambar, audio, video
- Melakukan tugas penalaran dan pemahaman
- Menghasilkan representasi penalaran internal
- Menggunakan encoder Audio Transformer (AuT) bawaan untuk memproses audio
- Mengeluarkan representasi semantik terstruktur
Modul Talker (Penyampai):
- Menerima representasi penalaran dari Thinker
- Mengonversi representasi semantik menjadi token suara streaming
- Mendukung sintesis suara waktu nyata
- Mewujudkan ekspresi suara yang alami (termasuk intonasi, emosi, dan jeda)
Nilai Rekayasa Arsitektur Thinker-Talker
Keunggulan utama dari desain terpisah ini adalah intervensi perantara—sistem eksternal (saluran RAG, filter keamanan, pemanggilan fungsi) dapat melakukan intervensi di antara output Thinker dan sintesis Talker. Artinya:
- Perusahaan dapat menambahkan pemeriksaan keamanan sebelum output suara dihasilkan
- Pengembang dapat memicu pemanggilan alat berdasarkan hasil penalaran
- Sistem RAG dapat menambahkan hasil pencarian pengetahuan sebelum menjawab
Mekanisme Aktivasi Jarang (Sparse) MoE
Inti dari desain Hybrid-Attention MoE adalah aktivasi jarang—model hanya mengaktifkan sebagian parameter saat memproses setiap token (hanya 3B aktif dari total 30B parameter). Mekanisme ini memungkinkan model mempertahankan kapasitas tinggi sekaligus menjaga biaya komputasi inferensi tetap terkendali, yang sangat krusial untuk aplikasi waktu nyata (seperti percakapan suara).
🎯 Saran Pengembangan: Arsitektur terpisah Thinker-Talker pada Qwen3.5-Omni sangat cocok untuk membangun alur kerja AI multi-langkah. Jika Anda perlu mengintegrasikan kemampuan multimodal ke dalam aplikasi Anda, Anda dapat menguji perbedaan performa antara Qwen3.5-Omni dan model multimodal utama lainnya melalui platform APIYI apiyi.com.
Perbandingan Tiga Varian Model Qwen3.5-Omni
Panduan Pemilihan Plus / Flash / Light
Qwen3.5-Omni menyediakan tiga varian model untuk skenario yang berbeda:
| Varian | Tipe Arsitektur | Skala Parameter | Cara Akses | Skenario Penggunaan |
|---|---|---|---|---|
| Plus | MoE (30B-A3B) | 30B total/3B aktif | API (DashScope) | Penalaran kualitas tertinggi, tugas multimodal kompleks |
| Flash | MoE Ringan | Parameter lebih sedikit | API (DashScope) | Skenario latensi rendah, percakapan waktu nyata |
| Light | Model Padat | Skala lebih kecil | Bobot terbuka (HuggingFace) | Deployment lokal, perangkat edge |
Saran Pemilihan:
- Mengejar hasil terbaik → Pilih varian Plus, yang meraih skor tertinggi dalam 215 tolok ukur
- Mengejar latensi rendah → Pilih varian Flash, cocok untuk percakapan suara waktu nyata dan interaksi streaming
- Perlu deployment lokal → Pilih varian Light, bobot terbuka dapat dijalankan di GPU lokal
Cara Akses API Qwen3.5-Omni
API Qwen3.5-Omni mengikuti format standar /v1/chat/completions, dengan menentukan tipe output melalui parameter modalities:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Akses terpadu melalui APIYI
)
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Tolong analisis konten video ini"},
{"type": "video_url", "video_url": {"url": "https://example.com/video.mp4"}}
]
}
]
)
Lihat contoh lengkap input multimodal
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Input multimodal: Gambar + Audio + Teks
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Tolong buat laporan analisis berdasarkan gambar dan deskripsi suara"},
{
"type": "image_url",
"image_url": {"url": "data:image/png;base64,..."}
},
{
"type": "input_audio",
"input_audio": {
"data": base64.b64encode(audio_bytes).decode(),
"format": "wav"
}
}
]
}
],
max_tokens=2000
)
# Dapatkan balasan teks
print(response.choices[0].message.content)
# Jika output audio diminta, ambil data suara
if hasattr(response.choices[0].message, 'audio'):
audio_data = response.choices[0].message.audio
print(f"Format audio: {audio_data.format}")
💡 Tips Akses: API Qwen3.5-Omni kompatibel dengan format SDK OpenAI. Jika Anda sudah memiliki kode berbasis SDK OpenAI, cukup ubah parameter
base_urldanmodeluntuk beralih dengan cepat. Melalui platform APIYI apiyi.com, Anda dapat menguji performa multimodal Qwen3.5-Omni dan model seperti GPT-4o secara bersamaan.
Analisis Performa Benchmark Qwen3.5-Omni
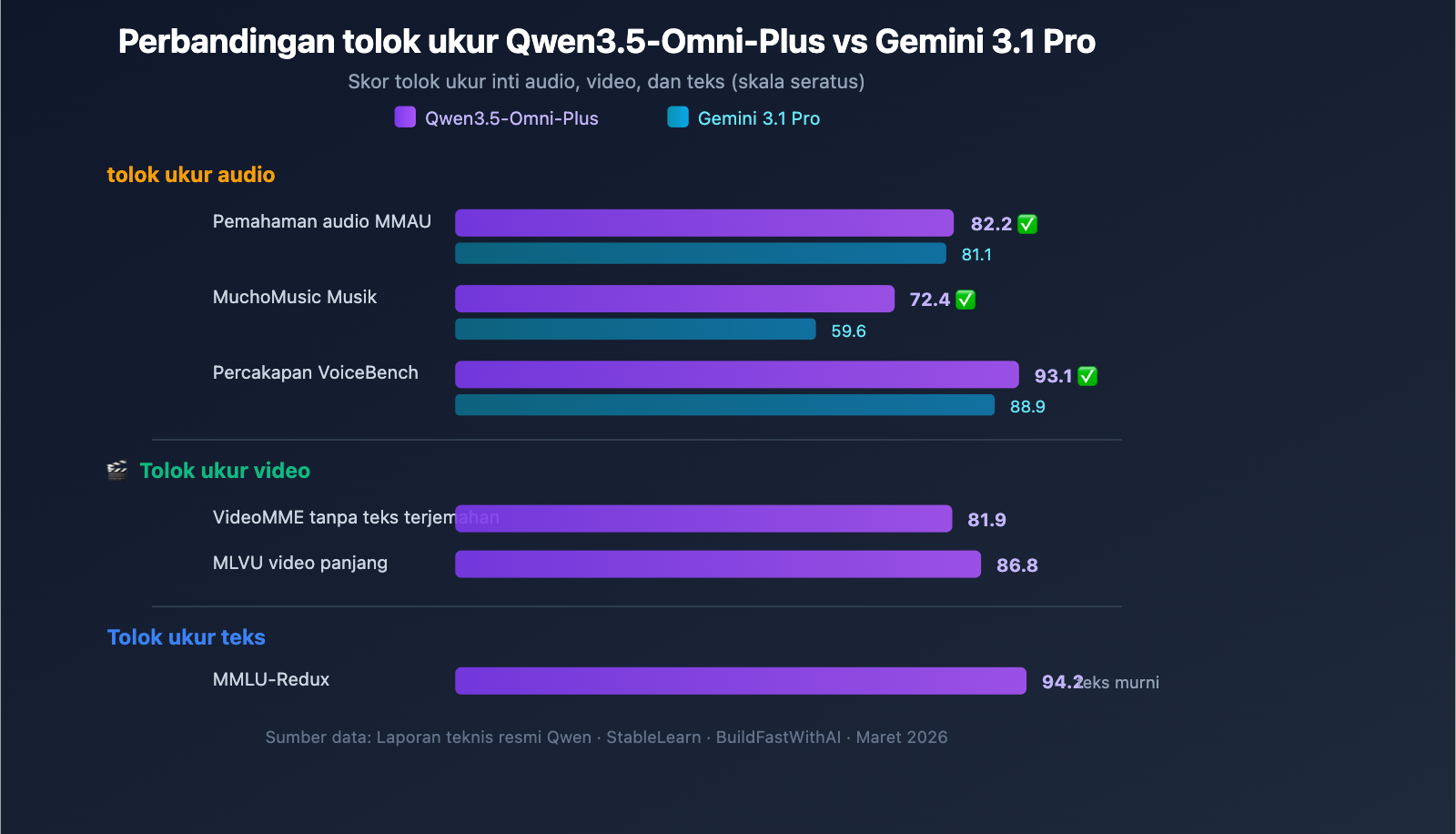
Kemampuan Pemahaman Audio
Qwen3.5-Omni-Plus mengungguli Google Gemini 3.1 Pro secara menyeluruh dalam benchmark terkait audio:
| Benchmark | Qwen3.5-Omni-Plus | Gemini 3.1 Pro | Pemenang |
|---|---|---|---|
| MMAU Pemahaman Audio | 82.2 | 81.1 | Qwen |
| MuchoMusic Pemahaman Musik | 72.4 | 59.6 | Qwen (+21%) |
| VoiceBench Percakapan | 93.1 | 88.9 | Qwen |
Keunggulan Qwen3.5-Omni pada pemahaman musik (MuchoMusic) sangat menonjol, dengan selisih mencapai 21%.
Kemampuan Visual dan Video
| Benchmark | Qwen3.5-Omni-Plus | Keterangan |
|---|---|---|
| MMMU-Pro | 73.9 | Skor tertinggi pemahaman multimodal |
| RealWorldQA | 84.1 | Tanya jawab visual dunia nyata |
| VideoMME (Tanpa subtitle) | 81.9 | Pemahaman multimodal video |
| MLVU | 86.8 | Pemahaman video durasi panjang |
| MVBench | 79.0 | Benchmark video multi-dimensi |
| LVBench | 71.2 | Benchmark video durasi panjang |
Konsistensi Penalaran Teks
Qwen3.5-Omni tetap mempertahankan performa penalaran teks yang luar biasa meskipun telah mendapatkan kemampuan multimodal penuh:
| Benchmark | Qwen3.5-Omni-Plus | Qwen3.5-Plus (Teks saja) | Selisih |
|---|---|---|---|
| MMLU-Redux | 94.2 | 94.3 | -0.1 |
| C-Eval | 92.0 | 92.3 | -0.3 |
| IFEval | 89.7 | 89.7 | 0 |
Ini berarti memilih Qwen3.5-Omni tidak akan mengorbankan kualitas penalaran teks—Anda bisa menggunakan satu model untuk menangani skenario teks maupun multimodal sekaligus.
🎯 Saran Pemilihan: Qwen3.5-Omni memiliki keunggulan nyata dalam pemahaman audio dan musik. Jika aplikasi Anda melibatkan interaksi suara atau analisis audio, kami sarankan untuk memprioritaskan model ini. Anda dapat menggunakan layanan proksi API APIYI (apiyi.com) untuk membandingkan performa Qwen3.5-Omni dan GPT-4o secara cepat dalam skenario spesifik Anda.
3 Kemampuan Diferensiasi Qwen3.5-Omni
Kemampuan 1: Audio-Visual Vibe Coding
Qwen3.5-Omni menunjukkan kemampuan emergen yang disebut oleh tim Tongyi Qianwen sebagai "Audio-Visual Vibe Coding"—model ini dapat menulis kode yang dapat dijalankan hanya dengan menonton video + mendengarkan instruksi suara, tanpa perlu pelatihan khusus untuk kemampuan ini.
Dalam pengujian nyata, model mampu:
- Mengubah sketsa tangan (yang diambil melalui kamera) menjadi halaman web React yang dapat dijalankan.
- Menulis kode fungsional berdasarkan demonstrasi video dan deskripsi lisan.
- Memahami niat desain visual dan menghasilkan implementasi frontend yang sesuai.
Kemampuan ini sangat berharga untuk pengembangan prototipe cepat dan skenario low-code.
Kemampuan 2: Pengenalan Interupsi Semantik
Sistem interaksi suara tradisional tidak dapat membedakan antara umpan balik responsif pengguna seperti "hmm" atau "oke" dengan niat interupsi yang sebenarnya. Qwen3.5-Omni memperkenalkan Turn-Taking Intent Recognition (pengenalan niat pengambilalihan giliran) asli, yang dapat membedakan antara:
- Umpan Balik (Backchanneling): Seperti "hmm", "ya", dll., yaitu umpan balik tanpa niat interupsi semantik.
- Interupsi Semantik (Semantic Interruption): Situasi di mana pengguna memiliki niat yang jelas untuk mengambil alih percakapan.
Hal ini membuat pengalaman percakapan suara Qwen3.5-Omni terasa lebih alami seperti berkomunikasi dengan manusia.
Kemampuan 3: Kloning Suara
Pengguna dapat mengunggah rekaman suara, dan Qwen3.5-Omni akan mempelajari serta mengkloning karakteristik suara tersebut untuk digunakan dalam semua output suara berikutnya. Suara hasil kloning ini tetap menjaga kealamian dan stabilitas dalam skenario multibahasa.
Posisi Qwen3.5-Omni dalam Strategi Peluncuran AI Alibaba
Jadwal Peluncuran Model AI Alibaba (Maret-April 2026)
| Waktu Rilis | Model | Penempatan | Fitur Utama |
|---|---|---|---|
| 30 Maret | Qwen3.5-Omni | Model multimodal asli | Pemrosesan terpadu teks/gambar/audio/video |
| 2 April | Qwen3.6-Plus | Model agen tingkat perusahaan | Jendela konteks 1 juta token, pemrograman berbasis agen |
| Pembaruan berkelanjutan | Qwen3-TTS | Sintesis suara | Seri TTS sumber terbuka, mendukung kloning suara |
Jadwal rilis yang padat ini menunjukkan bahwa Alibaba sedang mempercepat pengembangan kemampuan Model Bahasa Besar secara menyeluruh. Qwen3.5-Omni mencakup persepsi dan pemahaman multimodal, sementara Qwen3.6-Plus berfokus pada pembuatan kode tingkat perusahaan dan kemampuan agen, keduanya saling melengkapi.
Perlu dicatat bahwa varian Plus dan Flash dari Qwen3.5-Omni dirilis melalui API tertutup, yang menandai pergeseran dari strategi Alibaba sebelumnya yang mengutamakan sumber terbuka. Media seperti WinBuzzer menganalisis bahwa hal ini mencerminkan fokus Alibaba pada profitabilitas di tengah tekanan komersial—seperti judul laporan Bloomberg yang berbunyi "Alibaba meluncurkan model AI tertutup ketiga, fokus pada laba".
💰 Saran Biaya: Jika Anda berencana mengintegrasikan Qwen3.5-Omni ke dalam produk Anda, disarankan untuk melakukan proof-of-concept menggunakan kuota gratis dari platform APIYI (apiyi.com) terlebih dahulu untuk memastikan performa model sebelum masuk ke tahap produksi. Platform ini mendukung jajaran lengkap model seperti Qwen, GPT, Claude, dan Gemini, sehingga memudahkan Anda memilih model yang paling sesuai untuk berbagai skenario.
Pertanyaan Umum (FAQ)
Q1: Apakah Qwen3.5-Omni bersifat sumber terbuka atau tertutup?
Qwen3.5-Omni hadir dalam tiga varian: Plus dan Flash saat ini hanya tersedia melalui API DashScope Alibaba Cloud (tertutup), sedangkan bobot varian Light tersedia untuk diunduh di HuggingFace (sumber terbuka). Generasi sebelumnya, Qwen3-Omni, sepenuhnya sumber terbuka dengan lisensi Apache 2.0, namun varian Plus/Flash pada versi 3.5 beralih ke model khusus API. Jika Anda memerlukan penerapan lokal, Anda dapat memilih varian Light.
Q2: Bagaimana perbandingan Qwen3.5-Omni dengan GPT-4o?
Dalam hal pemahaman audio dan musik, Qwen3.5-Omni-Plus jelas mengungguli GPT-4o. Untuk pemahaman video, keduanya memiliki keunggulan masing-masing. Dalam penalaran teks, Qwen3.5-Omni hampir setara dengan model teks murni milik Alibaba sendiri, yaitu Qwen3.5-Plus. Kami sarankan untuk melakukan pengujian perbandingan pada skenario aplikasi spesifik Anda melalui platform APIYI (apiyi.com), karena performa bisa sangat bervariasi tergantung pada kasus penggunaannya.
Q3: Bagaimana cara cepat memulai penggunaan API Qwen3.5-Omni?
API Qwen3.5-Omni kompatibel dengan format SDK OpenAI standar, sehingga sangat mudah untuk diintegrasikan. Anda hanya perlu menginstal SDK openai, mengatur kunci API dan base_url yang sesuai, lalu Anda bisa langsung melakukan pemanggilan model. Anda bisa mendapatkan kuota uji coba gratis melalui APIYI (apiyi.com) untuk memverifikasi efek pemanggilan multimodal dengan contoh kode di artikel ini.
Ringkasan
Poin-poin utama dari model multimodal Qwen3.5-Omni:
- Multimodal Asli: Memproses teks, gambar, audio, dan video dalam satu alur kerja terpadu, bukan solusi gabungan.
- Arsitektur Thinker-Talker: Pemisahan antara penalaran dan sintesis suara, mendukung intervensi lapisan tengah dan pemanggilan alat.
- 3 Varian Pilihan: Plus (paling kuat), Flash (latensi rendah), dan Light (bobot terbuka untuk deployment lokal).
- 215 SOTA: Unggul secara signifikan dibandingkan Gemini 3.1 Pro dalam pemahaman audio dan musik.
- Kemampuan Emergent: Audio-Visual Vibe Coding memungkinkan model menulis kode melalui input video dan suara.
Qwen3.5-Omni mewakili kemajuan penting dalam AI multimodal—satu model yang mencakup empat modalitas (teks, visual, audio, video) sekaligus, dengan kemampuan penalaran teks yang hampir tidak berkurang. Bagi pengembang yang membutuhkan kapabilitas multimodal, ini adalah opsi yang layak dipertimbangkan dengan serius.
Kami merekomendasikan untuk menguji Qwen3.5-Omni dan model multimodal utama lainnya dengan cepat melalui APIYI (apiyi.com). Platform ini menyediakan kredit gratis dan antarmuka API terpadu untuk memudahkan perbandingan dan pemilihan model.
📚 Referensi
-
Laporan MarkTechPost: Penjelasan Rilis Qwen3.5-Omni
- Tautan:
marktechpost.com/2026/03/30/alibaba-qwen-team-releases-qwen3-5-omni-a-native-multimodal-model-for-text-audio-video-and-realtime-interaction - Keterangan: Analisis teknis mendalam dan interpretasi arsitektur.
- Tautan:
-
Repositori GitHub Qwen3-Omni: Kode sumber dan bobot model
- Tautan:
github.com/QwenLM/Qwen3-Omni - Keterangan: Kode lengkap dan dokumentasi untuk generasi sebelumnya, Qwen3-Omni.
- Tautan:
-
Interpretasi Mendalam Analytics Vidhya: Analisis Laporan Teknis Qwen3.5-Omni
- Tautan:
analyticsvidhya.com/blog/2026/03/qwen3-5-omni-ai-model - Keterangan: Analisis mendetail yang mencakup kloning suara, Vibe Coding, dan kemampuan lainnya.
- Tautan:
-
Laporan eWeek: Qwen3.5-Omni sebagai Model Multimodal Tercanggih Alibaba
- Tautan:
eweek.com/news/qwen3-5-omni-alibaba-multimodal-ai-launch - Keterangan: Analisis dari perspektif industri dan perbandingan dengan produk kompetitor.
- Tautan:
-
Halaman Model HuggingFace: Qwen3-Omni-30B-A3B-Instruct
- Tautan:
huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct - Keterangan: Unduhan bobot model dan spesifikasi teknis.
- Tautan:
Penulis: Tim Teknis APIYI
Diskusi Teknis: Mari berdiskusi di kolom komentar mengenai praktik penerapan AI multimodal. Untuk materi pengembangan AI lainnya, kunjungi pusat dokumentasi APIYI di docs.apiyi.com.