Catatan Penulis: Perbandingan Gemini 3.1 Pro dan Claude Sonnet 4.6 dari 5 dimensi utama: coding, penalaran, multimodal, pekerjaan pengetahuan, dan harga. Membantu Anda memilih model mutakhir dengan rasio performa-harga (price-to-performance) terbaik.
Lanskap model AI pada Februari 2026 menunjukkan situasi yang menarik: persaingan sesungguhnya bukan lagi soal "siapa yang terkuat", melainkan "siapa raja rasio performa-harga". Gemini 3.1 Pro dari Google (rilis 19 Februari) dan Claude Sonnet 4.6 dari Anthropic (rilis 17 Februari) diluncurkan hampir bersamaan dengan harga yang bersaing dan performa yang diklaim mendekati level flagship—pilihan bagi pengembang belum pernah sesulit ini.
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami perbedaan nyata antara kedua model dalam hal coding, penalaran, multimodal, dan pekerjaan pengetahuan, serta model mana yang harus dipilih untuk skenario spesifik Anda.

Perbandingan Parameter Dasar Gemini 3.1 Pro vs Claude Sonnet 4.6
Posisi kedua model ini sangat mirip—keduanya adalah "pemain tangguh dengan performa mendekati flagship, namun harga jauh di bawah flagship", tetapi dengan pendekatan teknis yang sangat berbeda.
| Dimensi Parameter | Gemini 3.1 Pro | Claude Sonnet 4.6 | Penjelasan Perbandingan |
|---|---|---|---|
| Tanggal Rilis | 19.02.2026 | 17.02.2026 | Hanya selisih 2 hari |
| Jendela Konteks | 1 Juta (Standar) | 200K Standar / 1 Juta Beta | Gemini punya konteks sejuta secara native |
| Output Maksimal | 64K token | 64K token | Sama persis |
| Harga Input | $2/juta Token | $3/juta Token | ✅ Gemini lebih murah 33% |
| Harga Output | $12/juta Token | $15/juta Token | ✅ Gemini lebih murah 20% |
| Harga Input Konteks Panjang | $4 (>200K) | $3 (Tetap) | ⚠️ Sonnet lebih murah untuk konteks panjang |
| Harga Output Konteks Panjang | $18 (>200K) | $15 (Tetap) | ⚠️ Sonnet lebih murah untuk konteks panjang |
| Modalitas Input | Teks, Gambar, Audio, Video, PDF | Teks, Gambar, PDF | ✅ Multimodal Gemini lebih lengkap |
| Mode Penalaran | Tiga level berpikir (Low/Med/High) | Berpikir adaptif (dinamis) | Filosofi desain berbeda |
| Caching Petunjuk | Mendukung | Baca cache hanya $0.30/juta (Hemat 90%) | ✅ Cache Sonnet lebih hemat |
🎯 Detail Kunci Harga: Dalam skenario reguler di bawah 200K, Gemini 3.1 Pro lebih murah ($2/$12 vs $3/$15). Namun, begitu jendela konteks melebihi 200K, harga Gemini naik menjadi $4/$18, malah jadi lebih mahal dibanding $3/$15 milik Sonnet 4.6. Rata-rata panjang jendela konteks Anda secara langsung menentukan mana yang lebih menguntungkan.
Perbandingan Benchmark Lengkap Gemini 3.1 Pro vs Sonnet 4.6
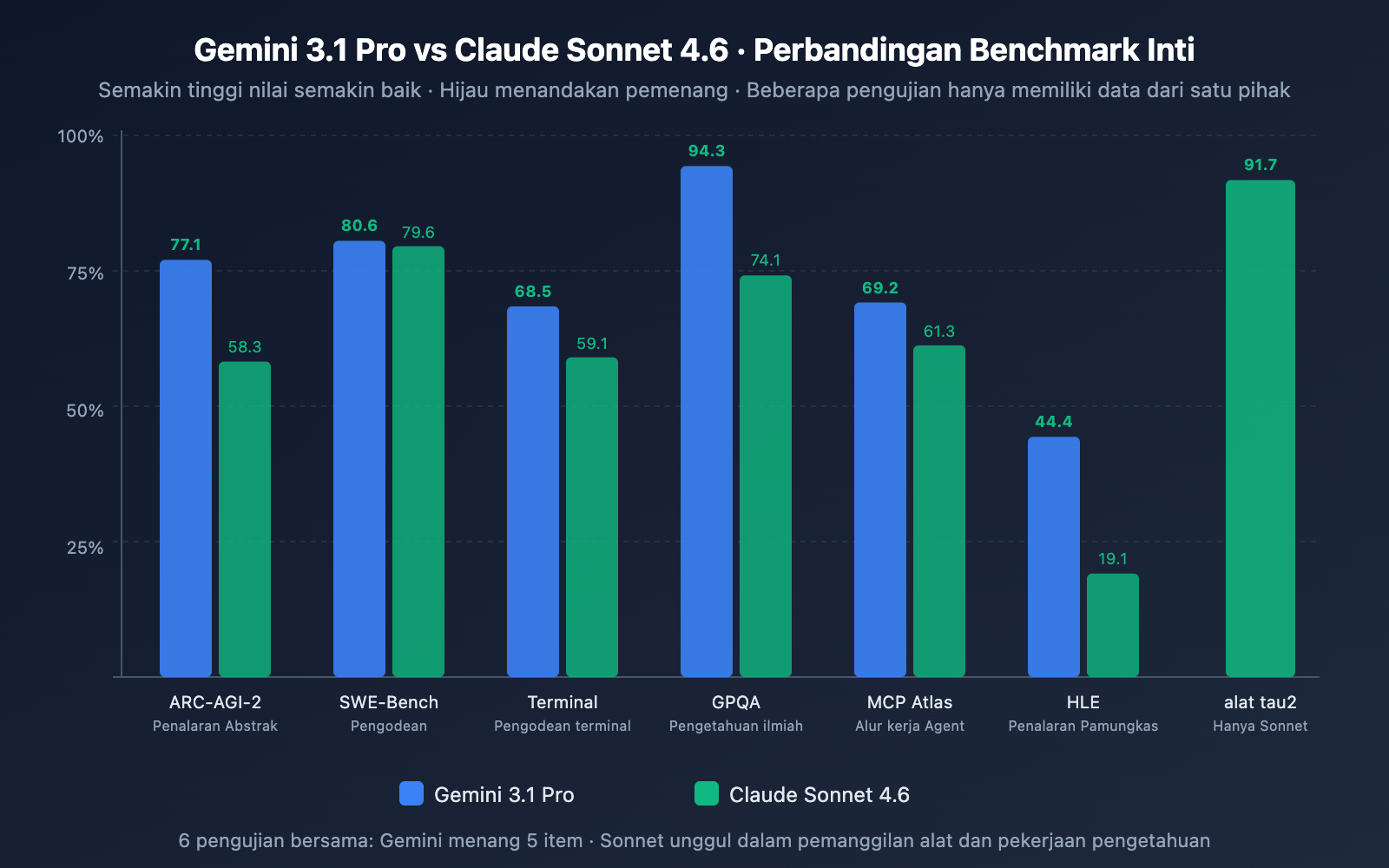
Perbandingan Kemampuan Pemrograman
| Tes Pemrograman | Gemini 3.1 Pro | Claude Sonnet 4.6 | Pemenang |
|---|---|---|---|
| SWE-Bench Verified | 80,6% | 79,6% | ✅ Gemini unggul 1,0 poin |
| SWE-Bench Pro | 54,2% | 42,7% | ✅ Gemini unggul 11,5 poin |
| Terminal-Bench 2.0 | 68,5% | 59,1% | ✅ Gemini unggul 9,4 poin |
Analisis: Gemini 3.1 Pro unggul di ketiga pengujian pemrograman. Terutama di SWE-Bench Pro (tugas kode nyata yang lebih kompleks) dengan selisih 11,5 poin, dan Terminal-Bench (pemrograman lingkungan terminal) dengan selisih 9,4 poin. Namun, perlu dicatat bahwa Sonnet 4.6 mencapai tingkat kesalahan 0% dalam pengujian internal pengeditan kode produksi Replit dan terpilih sebagai model dasar coding Agent untuk GitHub Copilot—pengalaman pemrograman di dunia nyata mungkin lebih dekat daripada hasil benchmark.
Perbandingan Kemampuan Penalaran
| Tes Penalaran | Gemini 3.1 Pro | Claude Sonnet 4.6 | Pemenang |
|---|---|---|---|
| ARC-AGI-2 (Penalaran Abstrak) | 77,1% | 58,3% | ✅ Gemini unggul 18,8 poin |
| GPQA Diamond (Sains) | 94,3% | 74,1% | ✅ Gemini unggul 20,2 poin |
| HLE (Penalaran Tingkat Lanjut) | 44,4% | 19,1% | ✅ Gemini unggul 25,3 poin |
| MATH-500 | – | 97,8% | Kemampuan matematika Sonnet menonjol |
Analisis: Kemampuan penalaran adalah dimensi dengan perbedaan terbesar di antara keduanya. Gemini 3.1 Pro memimpin jauh di ARC-AGI-2, GPQA Diamond, dan HLE, dengan selisih mulai dari 18 hingga 25 poin. Perlu dijelaskan bahwa skor penalaran Gemini 3.1 Pro diperoleh dalam mode 'High' pada sistem berpikir tiga tingkatnya, sementara pemikiran adaptif Sonnet 4.6 tidak sedalam Opus 4.6 dalam hal kedalaman penalaran. Jika penalaran murni adalah kebutuhan utama Anda, Gemini 3.1 Pro memiliki keunggulan yang jelas.
Perbandingan Pekerjaan Pengetahuan & Kemampuan Agent
| Tes | Gemini 3.1 Pro | Claude Sonnet 4.6 | Pemenang |
|---|---|---|---|
| GDPval-AA Elo (Pekerjaan Pengetahuan) | 1.317 | 1.633 | ✅ Sonnet unggul 316 poin |
| Finance Agent (Analisis Keuangan) | – | 63,3% | Data Sonnet menonjol |
| OSWorld (Kontrol Sistem Operasi) | – | 72,5% | Data Sonnet menonjol |
| MCP Atlas (Alur Kerja Multi-langkah) | 69,2% | 61,3% | ✅ Gemini unggul 7,9 poin |
| tau2-bench Retail (Pemanggilan Alat) | – | 91,7% | Data Sonnet menonjol |
Analisis: Di sini terjadi pembalikan terbesar. Pada GDPval-AA (simulasi pekerjaan pengetahuan tingkat ahli yang nyata), Sonnet 4.6 dengan 1.633 Elo tidak hanya jauh melampaui Gemini 3.1 Pro (1.317), tetapi bahkan melampaui model unggulan mereka sendiri, Opus 4.6 (1.559). Ini berarti dalam skenario pekerjaan pengetahuan bernilai tinggi seperti analisis riset, penulisan laporan, dan strategi bisnis, Sonnet 4.6 adalah model dengan performa terbaik saat ini—termasuk dibandingkan Opus 4.6 yang 5 kali lebih mahal.
Saran Pemilihan Skenario untuk Gemini 3.1 Pro vs Sonnet 4.6
Kelebihan dan kekurangan kedua model ini sangat saling melengkapi, sehingga memilih skenario yang tepat jauh lebih penting daripada sekadar menentukan "mana yang lebih baik".

Skenario Memilih Gemini 3.1 Pro
- Pemrograman Algoritma dan Kompetisi: LiveCodeBench Elo 2.887, memimpin jauh dalam pengodean berbasis algoritma.
- Penalaran Kompleks dan Riset Ilmiah: ARC-AGI-2 77,1%, GPQA Diamond 94,3%. Kemampuan penalaran murninya berada di level yang berbeda dibandingkan Sonnet 4.6.
- Pemrosesan Multimodal: Mendukung video (1 jam) dan audio (8,4 jam) secara asli, fitur yang tidak didukung oleh Sonnet 4.6.
- Alur Kerja MCP Agent: MCP Atlas 69,2% (unggul 7,9 poin), jauh lebih andal saat membangun sistem Agent multi-langkah.
- Pemanggilan Frekuensi Tinggi dengan Konteks Pendek: Untuk penggunaan di bawah 200K, harga $2/$12 menjadikannya pilihan yang lebih ekonomis di antara keduanya.
Skenario Memilih Claude Sonnet 4.6
- Pekerjaan Pengetahuan Tingkat Ahli: GDPval-AA 1.633 Elo adalah skor tertinggi di antara semua model saat ini. Sangat unggul untuk laporan riset, analisis keuangan, dan strategi bisnis.
- Pengeditan Kode Produksi: Mencatat tingkat kesalahan 0% dalam pengujian lingkungan produksi Replit, dan dipilih oleh GitHub Copilot sebagai basis Agent pengodean.
- Tool Use dan Computer Use: tau2-bench 91,7%, OSWorld 72,5%. Memiliki akurasi sangat tinggi dalam operasi otomatisasi dan pemanggilan fungsi.
- Skenario Jendela Konteks Panjang: Saat melebihi 200K konteks, harga Sonnet 4.6 ($3/$15) lebih murah dibandingkan Gemini ($4/$18).
- Aplikasi Tingkat Perusahaan: Penyelarasan keamanan yang lebih matang, Prompt Caching (biaya baca hanya $0,30/juta Token, hemat 90%), dan harga setengah untuk pemrosesan batch.
Akses Cepat API Gemini 3.1 Pro dan Claude Sonnet 4.6
Contoh Minimalis
Melalui platform APIYI, kedua model menggunakan antarmuka yang seragam:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Gemini 3.1 Pro - Lebih kuat dalam penalaran dan multimodal
response = client.chat.completions.create(
model="gemini-3.1-pro",
messages=[{"role": "user", "content": "Analisis kompleksitas waktu kode ini dan optimalkan"}]
)
print(response.choices[0].message.content)
Lihat contoh pemanggilan Sonnet 4.6 dan peralihan otomatis berdasarkan skenario
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Claude Sonnet 4.6 - Lebih kuat untuk pekerjaan berbasis pengetahuan dan pemanggilan alat
response = client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[{"role": "user", "content": "Tulis laporan analisis pasar Q1, termasuk perbandingan kompetitor dan saran pertumbuhan"}]
)
print(response.choices[0].message.content)
# Perutean otomatis berdasarkan skenario
def route_model(prompt, task_type="general"):
model_map = {
"reasoning": "gemini-3.1-pro",
"multimodal": "gemini-3.1-pro",
"algorithm": "gemini-3.1-pro",
"knowledge": "claude-sonnet-4-6",
"production_code": "claude-sonnet-4-6",
"tool_call": "claude-sonnet-4-6",
"general": "gemini-3.1-pro",
}
return client.chat.completions.create(
model=model_map.get(task_type, "gemini-3.1-pro"),
messages=[{"role": "user", "content": prompt}]
)
Saran: Melalui platform APIYI (apiyi.com), Anda dapat mengakses kedua model secara bersamaan dan beralih hanya dengan satu kunci API yang sama. Platform ini menyediakan kuota uji coba gratis, sangat disarankan untuk membandingkan hasilnya langsung dalam skenario penggunaan Anda.
Perbandingan Biaya Mendalam: Gemini 3.1 Pro vs Sonnet 4.6
Estimasi biaya bulanan berdasarkan tiga skenario penggunaan tipikal:
| Skenario Penggunaan | Konsumsi Token Rata-rata per Bulan | Gemini 3.1 Pro | Claude Sonnet 4.6 | Pihak yang Lebih Murah |
|---|---|---|---|---|
| Penggunaan Ringan (5 juta input + 1 juta output) | 6 juta | $22 | $30 | Gemini hemat 27% |
| Penggunaan Menengah (20 juta input + 5 juta output) | 25 juta | $100 | $135 | Gemini hemat 26% |
| Penggunaan Berat Konteks Panjang (50 juta input >200K + 10 juta output) | 60 juta | $380 | $300 | ⚠️ Sonnet hemat 21% |
🎯 Kesimpulan Biaya: Dalam penggunaan reguler, Gemini 3.1 Pro lebih murah sekitar 26%-27%. Namun, jika Anda sering menggunakan konteks panjang di atas 200K (seperti analisis seluruh basis kode atau pemrosesan dokumen panjang), Sonnet 4.6 justru menjadi lebih murah—karena harga konteks panjang Gemini naik menjadi $4/$18, sementara Sonnet tetap di $3/$15. Ditambah lagi dengan fitur Prompt Caching milik Sonnet (biaya baca hanya $0,30/juta Token), biaya aktualnya bisa 30%-50% lebih rendah lagi.
Mengakses melalui platform APIYI (apiyi.com) memungkinkan Anda menikmati harga diskon tambahan, yang semakin menekan biaya penggunaan kedua model tersebut.
Pertanyaan yang Sering Diajukan
Q1: GDPval-AA Sonnet 4.6 lebih tinggi dari Opus 4.6 milik mereka sendiri, apakah ini normal?
Memang benar demikian. Sonnet 4.6 berhasil meraih 1.633 Elo pada GDPval-AA, melampaui Opus 4.6 yang berada di angka 1.559. Anthropic telah mengonfirmasi data ini secara resmi. Kemungkinan penyebabnya adalah Sonnet 4.6 dioptimalkan secara khusus untuk skenario pekerjaan pengetahuan (knowledge work) perusahaan, sementara Opus 4.6 lebih dititikberatkan pada penalaran umum dan pemrosesan jendela konteks yang panjang. Tingkat preferensi pengembang terhadap Sonnet 4.6 juga mencapai 70% (dibandingkan Sonnet 4.5) dan 59% (dibandingkan Opus 4.5).
Q2: Model mana yang lebih cocok untuk membuat AI Agent?
Tergantung pada jenis Agent-nya. Jika itu adalah Agent alur kerja multi-langkah berbasis MCP, Gemini 3.1 Pro unggul dengan skor MCP Atlas 69,2% (memimpin 7,9 poin). Jika itu adalah Agent yang intensif melakukan pemanggilan alat (seperti OpenClaw), Sonnet 4.6 dengan skor tau2-bench 91,7% jauh lebih andal. Sedangkan untuk Agent kategori Computer Use (mengendalikan browser dan desktop), skor OSWorld 72,5% milik Sonnet 4.6 adalah salah satu hasil terbaik saat ini. Kedua model ini dapat langsung diakses dan diuji melalui platform APIYI apiyi.com.
Q3: Saya sekarang menggunakan Sonnet 4.5, apakah sebaiknya upgrade ke Sonnet 4.6 atau pindah ke Gemini 3.1 Pro?
Jika Anda puas dengan pengalaman pekerjaan pengetahuan dan pengkodean di Sonnet 4.5, langsung upgrade ke Sonnet 4.6 adalah pilihan paling aman—kompatibilitas API terjaga, harga tetap sama, dan performa meningkat secara menyeluruh (SWE-Bench naik dari 77,2% ke 79,6%, ARC-AGI-2 melonjak dari 13,6% ke 58,3%, meningkat 4,3 kali lipat). Namun, jika kebutuhan inti Anda lebih ke arah penalaran, multimodal, atau pengkodean algoritma, Gemini 3.1 Pro memiliki keunggulan signifikan di bidang tersebut. Disarankan untuk mencoba kedua model tersebut melalui platform APIYI apiyi.com.
Kesimpulan
Kesimpulan utama perbandingan Gemini 3.1 Pro vs Claude Sonnet 4.6:
- Pilih Gemini 3.1 Pro untuk penalaran dan multimodal: Unggul 18,8 poin di ARC-AGI-2, unggul 20,2 poin di GPQA Diamond, dukungan video/audio asli, dan lebih murah untuk jendela konteks pendek.
- Pilih Claude Sonnet 4.6 untuk pekerjaan pengetahuan dan pengkodean produksi: Skor GDPval-AA 1.633 Elo adalah yang tertinggi di antara semua model (termasuk Opus 4.6), tingkat kesalahan 0% di Replit, dan menjadi pilihan utama untuk GitHub Copilot.
- Sonnet lebih hemat untuk skenario jendela konteks panjang: Saat jendela konteks melebihi 200K, harga Sonnet adalah $3/$15 vs Gemini $4/$18. Ditambah dengan fitur caching petunjuk, Anda bisa menghemat lagi sebesar 30%-50%.
Kedua model ini adalah model garis depan dengan rasio performa-harga terbaik di bulan Februari 2026. Strategi terbaik adalah menggunakannya secara campuran sesuai dengan skenario kebutuhan. Direkomendasikan untuk mengakses keduanya melalui APIYI apiyi.com secara bersamaan, sehingga Anda bisa beralih antar model sesuai kebutuhan hanya dengan satu kunci API yang sama.
📚 Referensi
-
Pengumuman Rilis Claude Sonnet 4.6: Blog Resmi Anthropic
- Tautan:
anthropic.com/news/claude-sonnet-4-6 - Deskripsi: Pengenalan fitur lengkap Sonnet 4.6, data benchmark, dan fitur pemikiran adaptif.
- Tautan:
-
Blog Resmi Gemini 3.1 Pro: Pengumuman Rilis Google DeepMind
- Tautan:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - Deskripsi: Sistem pemikiran tiga tingkat Gemini 3.1 Pro dan data performa lengkap.
- Tautan:
-
Perbandingan Uji Langsung Tom's Guide: Uji coba 7 tantangan Gemini 3.1 Pro vs Sonnet 4.6
- Tautan:
tomsguide.com/ai/i-tested-gemini-3-1-pro-vs-claude-sonnet-4-6-in-7-tough-challenges-and-there-was-one-clear-winner - Deskripsi: Perbandingan performa nyata dalam skenario tugas yang sebenarnya.
- Tautan:
-
Papan Peringkat Artificial Analysis: Platform evaluasi model independen pihak ketiga
- Tautan:
artificialanalysis.ai/leaderboards/models - Deskripsi: Data perbandingan horizontal yang objektif untuk performa, kecepatan, dan harga.
- Tautan:
Penulis: Tim Teknis
Diskusi Teknis: Jangan ragu untuk berbagi pengalaman penggunaan Anda di kolom komentar. Untuk informasi lebih lanjut mengenai model AI, kunjungi APIYI apiyi.com