作者注:从多代理架构、编码能力、推理性能、API 定价等 7 个维度深度对比 Claude Opus 4.6 和 Grok 4.20 Beta,帮助开发者根据场景选择最适合的 AI 模型
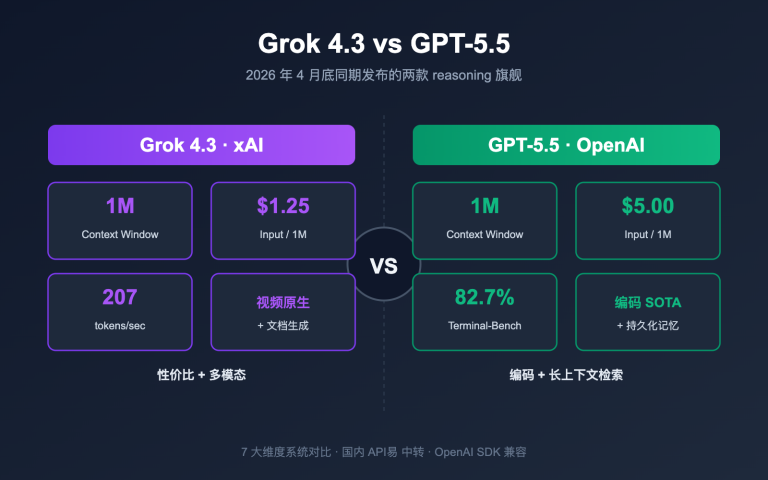
2026 年 2 月,AI 行业迎来了两款重磅模型的正面碰撞——Anthropic 在 2 月 5 日发布了 Claude Opus 4.6,xAI 紧随其后在 2 月中旬推出了 Grok 4.20(Beta)。两者都将"多代理协作"作为核心卖点,但架构思路截然不同。
核心价值: 看完本文,你将明确 Claude Opus 4.6 和 Grok 4.20 Beta 在编码、推理、实时数据、API 可用性等维度的具体差异,从而根据自己的场景做出正确选择。

Claude Opus 4.6 vs Grok 4.20 Beta 核心差异总览
| 对比维度 | Claude Opus 4.6 | Grok 4.20 Beta |
|---|---|---|
| 开发方 | Anthropic | xAI(Elon Musk) |
| 发布日期 | 2026 年 2 月 5 日(正式版) | 2026 年 2 月中旬(Beta) |
| 多代理架构 | Agent Teams(Lead + Teammates) | 4 Agents(Grok/Harper/Benjamin/Lucas) |
| 上下文窗口 | 200K 标准 / 1M Beta | 256K ~ 2M tokens |
| 最大输出 | 128K tokens | 未公布 |
| API 定价 | $5/$25 per MTok | 尚未公布(4.1 参考: $0.20/$0.50) |
| API 可用性 | ✅ 已全面开放 | ❌ 尚未开放 |
| 独家数据源 | 无 | X Firehose 实时推文数据 |
Claude Opus 4.6 vs Grok 4.20 Beta 定位差异
这两款模型虽然都主打"多代理协作",但面向的用户群体和解决的问题有本质区别:
Claude Opus 4.6 的 Agent Teams 是面向开发者的生产力工具。它让多个 Claude 实例在独立上下文中并行编码,由 Lead Agent 统筹协调,每个 Teammate 可以独立读写文件、运行测试。这是一个已经可以在实际项目中使用的成熟功能。
Grok 4.20 Beta 的 4 Agents 是面向通用问题解决的推理增强。四个具有不同专业角色的代理(研究、逻辑、创意、协调)在内部并行思考并互相验证,最终输出更准确的答案。目前仅限 SuperGrok 用户在对话界面使用。
🎯 选择建议: 如果你是开发者,需要 AI 辅助写代码、调试、处理大型项目,Claude Opus 4.6 是当前更成熟的选择,通过 API易 apiyi.com 可以直接调用。如果你更关注复杂推理、实时信息分析和多角度思考,Grok 4.20 Beta 值得关注。
Claude Opus 4.6 vs Grok 4.20 Beta 多代理架构对比
两款模型的多代理架构是最值得深入对比的核心差异。
Claude Opus 4.6 Agent Teams 架构
Claude Opus 4.6 的 Agent Teams 采用显式并行编码模式:
| 组件 | 功能说明 | 特点 |
|---|---|---|
| Lead Agent | 主协调者 | 分配任务、综合结果、统筹全局 |
| Teammates | 独立工作代理 | 各自拥有完整上下文窗口 |
| 任务列表 | 共享协作状态 | 依赖追踪、自动解锁 |
| 消息系统 | 代理间通信 | Teammates 可直接互发消息 |
Agent Teams 的关键技术特性:
- 独立上下文: 每个 Teammate 拥有独立的完整上下文窗口,不会相互干扰
- 文件级并行: 不同 Teammate 可以同时操作不同文件,实现真正的并行开发
- 实时协调: 通过共享任务列表和消息系统,Lead Agent 可以动态调整分工
- 规模化能力: 实测已支持 16 个 Agent 并行构建 Rust C 编译器
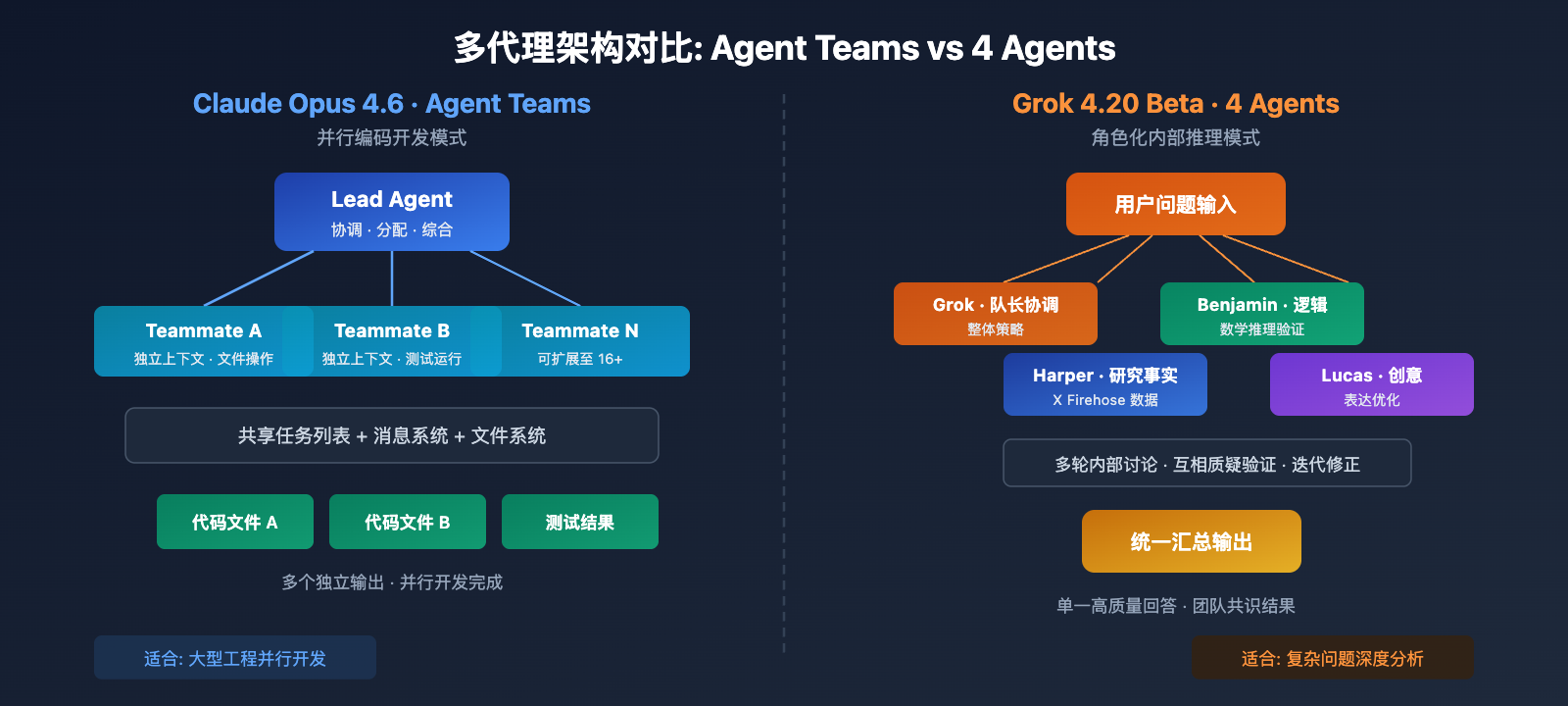
Grok 4.20 Beta 4 Agents 架构
Grok 4.20 Beta 的 4 Agents 采用角色化内部推理模式:
- Grok(队长): 整体策略制定,最终答案合成
- Harper(研究专家): 实时搜索、资料核查,接入 X Firehose 数据
- Benjamin(逻辑专家): 数学推理、编程验证、精确计算
- Lucas(创意专家): 发散思维、表达优化、用户体验
4 Agents 的核心差异在于内部多轮讨论和互评机制。Agent 之间会质疑彼此的结论,进行迭代修正,这种机制能有效降低幻觉。
Claude Opus 4.6 vs Grok 4.20 Beta 多代理架构核心区别
| 维度 | Claude Agent Teams | Grok 4 Agents |
|---|---|---|
| 协作目标 | 并行完成编码任务 | 多角度分析同一问题 |
| 代理角色 | 功能等价(都是 Claude 实例) | 角色分化(研究/逻辑/创意/协调) |
| 工作方式 | 独立上下文 + 共享文件系统 | 内部并行思考 + 多轮讨论 |
| 可扩展性 | 可扩展至 16+ 代理 | 固定 4 个专业代理 |
| 输出形式 | 各自独立输出(代码/文件) | 统一汇总输出(单一回答) |
| 适用场景 | 大型工程项目并行开发 | 复杂问题的深度分析 |
| 用户可见性 | 可观察各 Teammate 工作进度 | 仅可见最终合成输出 |
💡 技术洞察: Claude Agent Teams 更像"一个公司的多个开发团队并行做项目",而 Grok 4 Agents 更像"一个专家小组围坐讨论同一个难题"。两种架构解决的是完全不同的问题。
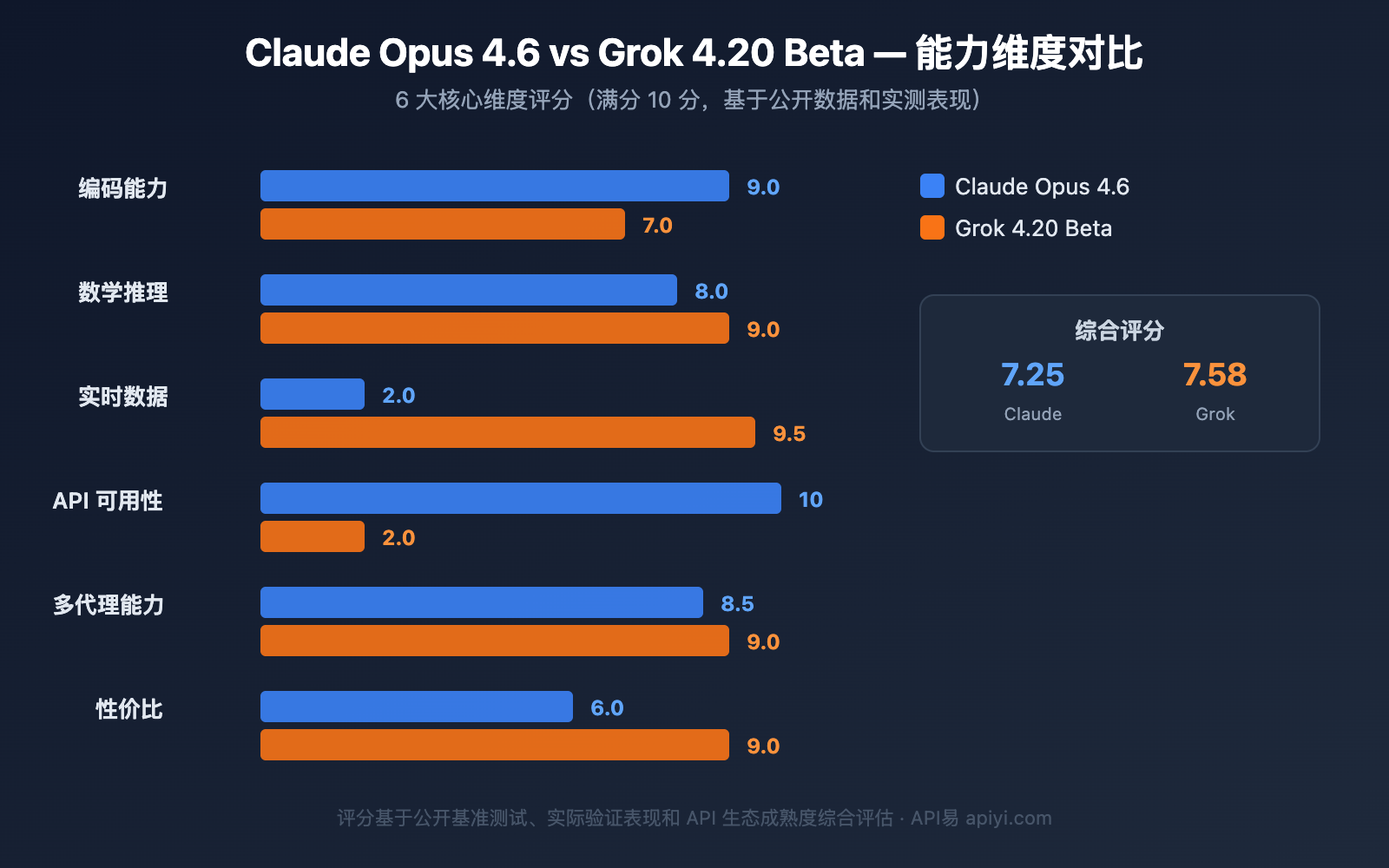
Claude Opus 4.6 vs Grok 4.20 Beta 基准性能对比
Claude Opus 4.6 已公布的基准测试成绩
Claude Opus 4.6 作为正式发布的模型,拥有完整的基准测试数据:
| 基准测试 | Claude Opus 4.6 | Claude Opus 4.5 | GPT-5.2 | 说明 |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 65.4% | 59.8% | — | Agentic 编码评估,行业最高 |
| ARC AGI 2 | 68.8% | 37.6% | 54.2% | 人类简单但 AI 困难的推理 |
| GDPval-AA | +144 Elo | 基准线 | 对照组 | 经济价值知识工作任务 |
| OSWorld | 72.7% | 66.3% | — | 计算机使用能力 |
| Humanity's Last Exam | 行业领先 | — | — | 复杂多学科推理 |
Claude Opus 4.6 在编码领域的表现尤为突出——在 Terminal-Bench 2.0 上取得了行业最高分,被评价为"tasteful coder"(有品味的编码者),特别擅长:
- 大型代码库的导航和理解
- 代码审查和 Bug 检测
- 前端开发从设计到功能实现
- 持续性 Agentic 编码任务
Grok 4.20 Beta 已验证的实际表现
Grok 4.20 Beta 尚无完整基准测试数据(仍在 Beta 阶段),但其实际表现已在特定领域得到验证:
- Alpha Arena 交易竞赛: 所有参赛 AI 中唯一盈利(平均回报 12.11%,峰值 50%)
- 数学研究: 帮助数学家 Paata Ivanisvili 在 Bellman 函数领域取得新发现,约 5 分钟推导出 U(p,q) 的精确公式
- 工程编码: Elon Musk 公开认可"开始正确回答开放式工程问题"
- 实时数据处理: 依托 X Firehose 实现毫秒级市场情绪分析
Claude Opus 4.6 vs Grok 4.20 Beta API 可用性与定价
对于开发者来说,API 可用性和成本是选择模型的关键因素。
Claude Opus 4.6 API 定价详情
| 项目 | 定价 | 说明 |
|---|---|---|
| 标准输入 | $5 / MTok | 200K 上下文内 |
| 标准输出 | $25 / MTok | 最大 128K tokens |
| 长上下文输入 | $10 / MTok | 超过 200K 时自动切换 |
| 长上下文输出 | $37.50 / MTok | 1M Beta 模式 |
| Prompt Caching | 最高节省 90% | 重复提示词缓存 |
| Batch 处理 | 节省 50% | 异步批量请求 |
| Fast 模式 | $30/$150 per MTok | 2.5 倍速度 |
Claude Opus 4.6 的 API 已经在所有主要平台上线:claude.ai、Anthropic API、Azure、AWS Bedrock 等。
Grok 4.20 Beta API 状态
Grok 4.20 Beta 的 API 尚未开放。参考 Grok 4.1 的定价:
- 输入: $0.20 / MTok
- 输出: $0.50 / MTok
如果 Grok 4.20 保持类似的定价策略,其 API 成本将显著低于 Claude Opus 4.6。但考虑到 4 Agents 架构需要运行四个并行代理,实际定价可能会有所上浮。
💰 成本建议: Claude Opus 4.6 已通过 API易 apiyi.com 上线,开发者可以直接获取 API Key 开始调用。平台提供灵活计费和免费测试额度,支持 Prompt Caching 等降本功能。Grok 4.20 API 一旦开放,API易也将在第一时间接入。
Claude Opus 4.6 vs Grok 4.20 Beta 适用场景推荐
选 Claude Opus 4.6 的场景
- 专业编码开发: Agent Teams 并行编码是当前最强的 AI 辅助开发方案,特别适合大型项目
- 前端工程: 被评为"tasteful coder",从设计稿到功能代码的转换精准度行业领先
- 代码审查和调试: 在大型代码库中操作更可靠,Bug 检测能力提升显著
- 企业级知识工作: GDPval-AA 评估中超越 GPT-5.2(+144 Elo),适合金融、法律等领域
- 需要立即可用的 API: 已全面开放 API,支持所有主流云平台
选 Grok 4.20 Beta 的场景
- 实时信息分析: X Firehose 数据接入是独家优势,适合舆情监控、市场分析
- 金融交易策略: Alpha Arena 竞赛中唯一盈利的 AI,实时数据+量化分析的最佳组合
- 数学和科学研究: 已验证辅助前沿数学研究的能力,适合需要严谨推理的学术场景
- 需要多角度深度分析: 4 Agents 的内部讨论机制适合复杂决策和战略规划
- 预算敏感场景: 参考 Grok 4.1 定价,API 成本可能远低于 Claude Opus 4.6
Claude Opus 4.6 vs Grok 4.20 Beta 决策矩阵
| 你的需求 | 推荐选择 | 原因 |
|---|---|---|
| 写代码、做项目 | Claude Opus 4.6 | Agent Teams + Terminal-Bench 最高分 |
| 实时市场分析 | Grok 4.20 Beta | X Firehose 独家数据源 |
| 数学/科学推理 | Grok 4.20 Beta | Bellman 函数级别的验证 |
| 企业知识工作 | Claude Opus 4.6 | GDPval-AA 行业领先 |
| 立即需要 API | Claude Opus 4.6 | 已全面开放,API易已上线 |
| 控制 API 成本 | Grok 4.20 Beta | 参考定价显著更低 |
| 前端开发 | Claude Opus 4.6 | "Tasteful coder" 评价 |
| 复杂战略决策 | Grok 4.20 Beta | 4 Agents 多角度分析 |
🚀 快速体验: 想要对比两款模型的实际表现?推荐通过 API易 apiyi.com 获取 Claude Opus 4.6 的 API Key,先行体验编码和推理能力。Grok 4.20 API 上线后,也可在同一平台快速切换对比。
常见问题
Q1: Claude Opus 4.6 的 Agent Teams 和 Grok 4.20 的 4 Agents 哪个更强?
两者不是同类技术,无法直接比较"强弱"。Claude Agent Teams 是并行编码工具,让多个 AI 实例同时写不同模块的代码,适合软件开发场景。Grok 4 Agents 是推理增强机制,让四个专业代理从不同角度分析同一问题,适合复杂决策场景。选择取决于你的使用场景,而非绝对性能。
Q2: 现在能用 API 调用这两个模型吗?
Claude Opus 4.6 的 API 已全面开放,可通过 API易 apiyi.com 获取 API Key 直接调用,支持标准 OpenAI 兼容接口。Grok 4.20 Beta 的 API 尚未开放,目前只能通过 SuperGrok 订阅($30/月)在 grok.com 对话界面使用。API易平台将在 Grok 4.20 API 开放后第一时间接入。
Q3: 这两个模型的 API 成本差距大吗?
差距非常显著。Claude Opus 4.6 标准定价为 $5/$25 per MTok(输入/输出),而 Grok 4.1 的参考定价为 $0.20/$0.50 per MTok,Grok 的 API 成本约为 Claude 的 2%-4%。不过,Claude 提供 Prompt Caching(最高节省 90%)和 Batch 处理(节省 50%)等降本方案,实际使用成本可以大幅降低。通过 API易 apiyi.com 平台调用还可以获得更灵活的计费方式。
Q4: 如果预算有限,应该优先选哪个?
如果你的核心需求是编码开发,Claude Opus 4.6 尽管单价更高,但编码质量和 Agent Teams 带来的效率提升可以弥补成本差距。如果你的需求侧重信息分析和推理,可以先使用 SuperGrok 订阅($30/月不限量对话)体验 Grok 4.20 Beta,等 API 上线后再评估切换。两款模型最终通过 API易 apiyi.com 都可以在同一平台管理和调用。
总结
Claude Opus 4.6 vs Grok 4.20 Beta 的核心结论:
- 多代理架构路线不同: Claude Agent Teams 做"并行开发团队",Grok 4 Agents 做"专家讨论小组"——两者互补而非替代
- 编码选 Claude,推理选 Grok: Claude Opus 4.6 在 Terminal-Bench 和 ARC AGI 2 上领先,Grok 4.20 在数学研究和实时分析上有独家优势
- API 成熟度差距明显: Claude Opus 4.6 已全面可用,Grok 4.20 仍在 Beta,API 尚未开放
- 成本考量: Grok API 参考价格远低于 Claude,但 Claude 的 Prompt Caching 可缩小差距
- 实时数据是 Grok 独家护城河: X Firehose 数据在金融交易和舆情分析场景中不可替代
对于大多数开发者,建议先用 Claude Opus 4.6 满足编码和日常需求,同时关注 Grok 4.20 API 的上线进展,在特定场景(实时分析、数学推理)中补充使用。
推荐通过 API易 apiyi.com 统一管理 API 调用,平台已支持 Claude Opus 4.6,Grok 4.20 上线后也将第一时间接入,方便在同一接口下快速切换和成本对比。
📚 参考资料
-
Anthropic 官方 – Claude Opus 4.6 发布公告: 模型功能和基准测试详情
- 链接:
anthropic.com/news/claude-opus-4-6 - 说明: Claude Opus 4.6 的官方发布信息和技术细节
- 链接:
-
Claude API 定价文档: 完整的 API 定价和计费规则
- 链接:
platform.claude.com/docs/en/about-claude/pricing - 说明: 包含标准定价、长上下文溢价、Prompt Caching 等详细信息
- 链接:
-
xAI 官方发布记录: Grok 系列版本更新
- 链接:
docs.x.ai/developers/release-notes - 说明: xAI 官方的模型更新和 API 发布记录
- 链接:
-
xAI 模型定价: Grok API 官方定价
- 链接:
docs.x.ai/developers/models - 说明: Grok 各版本 API 的详细定价信息
- 链接:
作者: APIYI Team
技术交流: 欢迎在评论区分享你对 Claude Opus 4.6 和 Grok 4.20 Beta 的使用体验,更多模型对比和 API 接入方案可访问 API易 apiyi.com 技术社区