很多接入 Gemini API 做识图业务的团队都遇到过同一个困惑:在 gemini.google.com 网页版上发同一张图、用同一段提示词,模型能精准识别细节、给出结构化答案;切到 gemini-3.5-flash API 上做同样的事,结果却明显粗糙,甚至漏掉关键信息。这种"网页强、API 弱"的体感差异,并不是模型本身被调弱了,而是网页版和 API 在工程层面的差距被你看见了。
本文围绕一个核心结论展开:网页版 Gemini 是一套综合 Agent,会自动做提示词优化、多步推理、工具调用与结果校验;API 调用的是裸模型,所见即所得。理解这个差距之后,6 个不止"调提示词"的 API 提升技巧就能让你的识图效果稳定追上官网体感。

为什么 Gemini API 识图效果不如网页版:Agent 与裸模型的差距
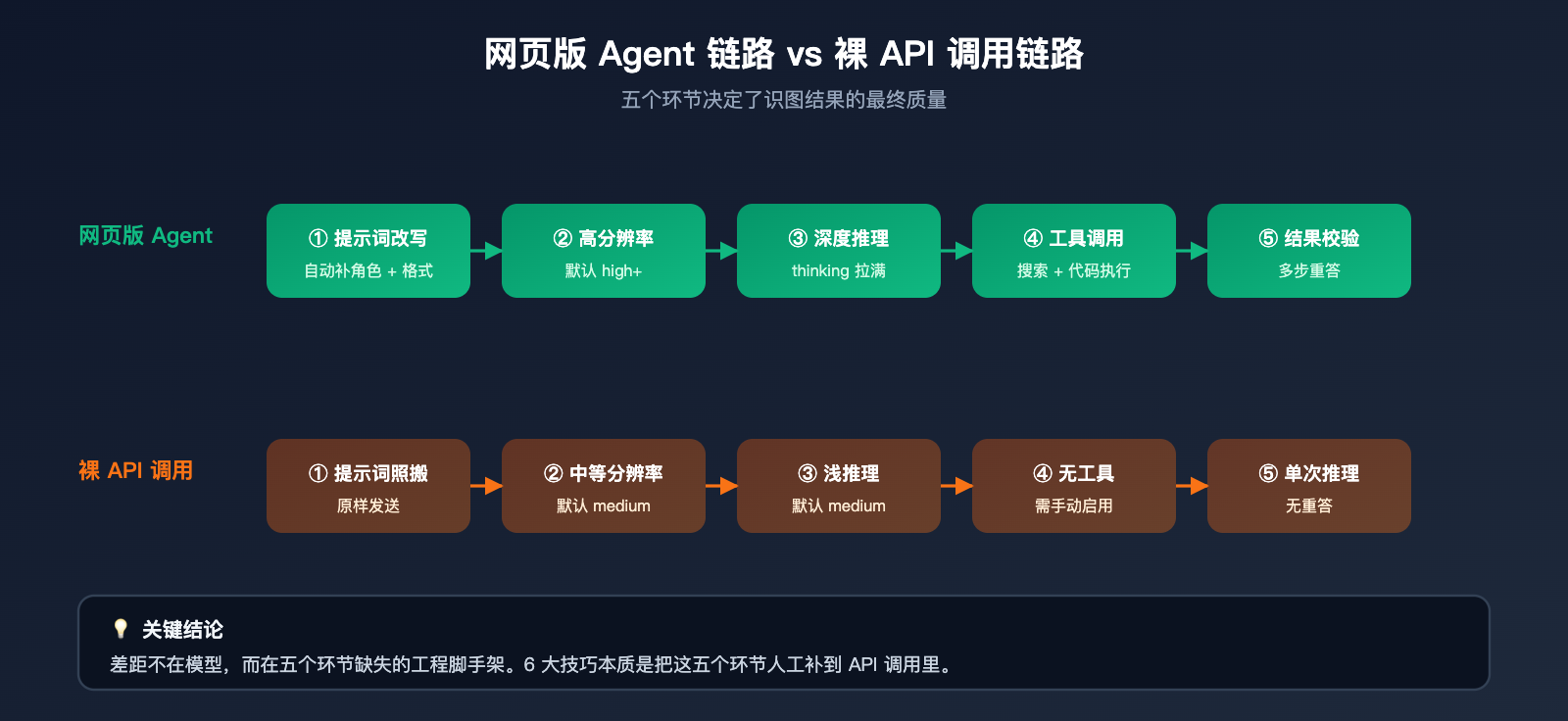
要把这个差距讲清楚,先得理解 gemini.google.com 在你提交一张图片到获得最终回答之间,到底替你做了多少事。从 Google 公开的 Agentic Vision 文档和我们在 API易(apiyi.com)上观察到的官网 vs API 响应差异看,网页版本质是一个围绕基础模型构建的产品级 Agent,它至少帮你完成了 5 件你没显式要求的事情:
- 自动改写你的提示词,把"识别这张图"补充为带角色、任务、输出格式的完整指令。
- 在内部用更高分辨率档位处理图像,确保细节不被压缩成模糊像素。
- 默认开启高强度推理预算(类似 thinking_level=high),让模型有时间"想"。
- 在需要时调用代码执行、网页搜索等内置工具做交叉验证,确认细节真实可信。
- 对输出结果做格式化与"重答"判断,遇到模糊回答会再问一遍模型。
而你直接调用 API 时,这 5 件事一件也不会自动发生。换句话说,你在调一个能力完整的"模型",但失去了一整套"工程脚手架"。下表把两种使用方式在关键链路上的差异列清楚:
| 对比维度 | gemini.google.com 网页版 | gemini-3.5-flash API |
|---|---|---|
| 提示词处理 | 自动改写、补全角色与格式 | 完全照搬用户输入 |
| 图像分辨率 | 默认高档位 | 默认中等档位,需手动调高 |
| 推理预算 | 高强度,无显式上限 | 默认中等,可手动设 thinking_level |
| 工具调用 | 默认接入搜索、代码执行 | 默认关闭,需显式启用 |
| 结果校验 | Agent 多步验证 | 单次推理,无校验 |
| 计费透明度 | 包月套餐覆盖 | 按 Token 单独计费 |
我们建议在 API易(apiyi.com)这种聚合网关上同时跑一份相同的图像与提示词,对比 gemini-3.5-flash API、Claude Opus、GPT-5.5 三家的识图结果,可以快速判断当前任务到底是被模型能力卡住,还是被工程链路卡住。
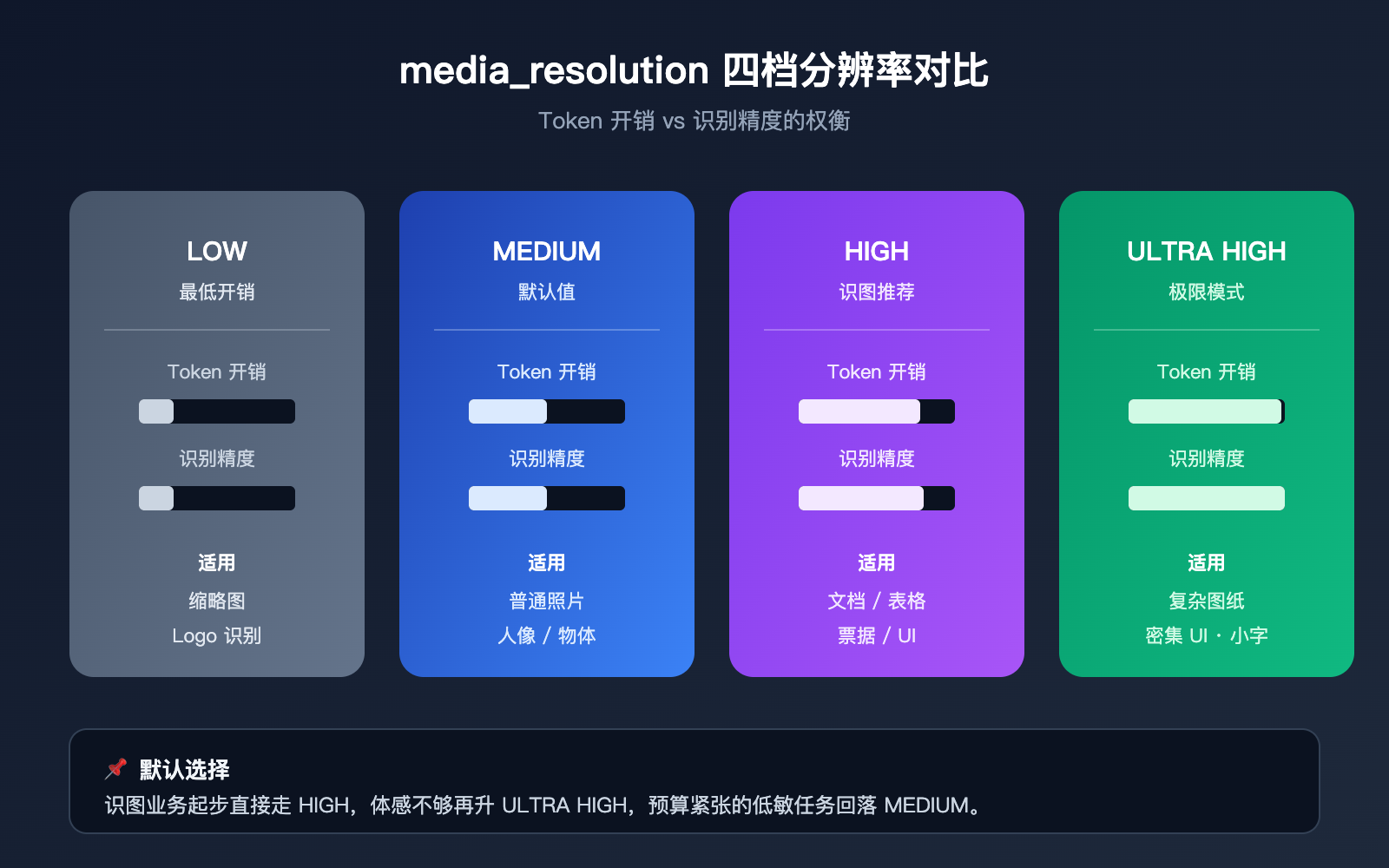
Gemini API 识图技巧一:拉高 media_resolution 参数
Gemini 3 系列开始引入 media_resolution 参数,它直接控制 API 为图像分配多少 Token 来"看"。这个参数有 low、medium、high、ultra high 四档,默认通常是 medium。对识别小字、票据、电路图、UI 截图这类细节密集的图像,medium 往往不够,模型会把图像压缩到一个粗糙的特征图,导致细节丢失。
下表给出四档的实际差异,便于你按任务类型选择:
| 分辨率档位 | Token 开销 | 适用场景 | 典型问题 |
|---|---|---|---|
| low | 最低 | 缩略图、Logo 识别 | 小字几乎全丢 |
| medium(默认) | 中等 | 普通照片、人像 | 细节模糊 |
| high | 较高 | 文档、表格、票据 | 信息基本可读 |
| ultra high | 最高 | 复杂图纸、密集 UI | 接近官网识别 |
对识图业务来说,把这个参数从 medium 调到 high 通常就能立刻把识别精度提一个档位。如果你的预算允许,且任务确实涉及小字、密集表格,直接走 ultra high 也是合理选择。
# 通过 API易调用 gemini-3.5-flash,显式指定 high 媒体分辨率
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "提取图中所有可见文字并按表格输出"],
config=types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH"
)
)
print(resp.text)
在 API易(apiyi.com)侧调用时,参数透传到底层,不会被网关二次包装,你可以放心按官方文档传值。
Gemini API 识图技巧二:显式开启 thinking_level=high
Gemini 3.5 Flash 引入了 thinking_level 参数,控制模型在产出答案之前的内部推理深度。识图任务里,"想得够久"和"想得够仔细"往往就是看清细节和看错的差距。API 默认档位偏向速度而非质量,识图业务建议主动设为 high,让模型像网页版那样有充足时间做空间推理与计数。
| thinking_level | 推荐场景 | 体感差异 |
|---|---|---|
| low | 极简对话、风格判断 | 速度快,识别粗糙 |
| medium | 普通问答 | 平均水平 |
| high(识图推荐) | 文档、票据、计数、空间推理 | 接近官网体感 |
官方文档同时强调了一个反直觉的点:用了 thinking_level=high 之后,反而要把提示词写得更直接、更简洁,避免一堆"请你一步步推理、请你考虑各种情况"的旧式 chain-of-thought 套路。这些套路是给老模型补能力的,对 Gemini 3 系列容易让它"过度分析"。
🎯 参数选型建议:把
media_resolution=HIGH与thinking_level=high作为识图任务的默认组合,写进 API易(apiyi.com)侧调用模板。后续根据业务体感再向 ultra high 或 low 两端微调,避免在每个请求里反复试参数。
Gemini API 识图技巧三:把指令写进 system_instruction 而非 user prompt
API 上的另一个常见误区是把所有内容塞进 user prompt:角色设定、任务说明、输出格式、用户提问全部混在一段文本里。这种写法等于让模型每次都重新读一遍上下文,而网页版的"系统提示词"是缓存复用的。
正确的做法是把"你的稳定指令"放进 system_instruction:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=(
"你是一名严谨的图像分析助手。"
"回答时只引用图像中明确可见的细节,不要凭空推断。"
"输出结构化的 JSON,字段固定为 entities/attributes/text。"
)
)
这样写带来两个收益:模型每次都按统一规则回答,结果更稳定;System Prompt Caching 启用后输入成本可下降 10 倍,对长期跑批的识图业务非常有价值。在 API易(apiyi.com)后台,可以按模型 ID 单独看到缓存命中率,方便观察优化效果。
Gemini API 识图技巧四:启用 code execution 让模型 "放大看图"
Google 在 Gemini 3 Flash 的 Agentic Vision 公告里给出过一个明确数据:在原生模型基础上启用代码执行工具,识图类任务平均能再拿 5%~10% 的质量提升。原理是模型可以在内部生成 Python 代码,对图片做裁剪、放大、旋转、像素读取等操作,再把处理后的子图重新喂给自己分析。这正是网页版默认在做的事。
API 默认不会开启代码执行,需要显式声明:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
tools=[types.Tool(code_execution=types.ToolCodeExecution())]
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "数出图中所有红色按钮的数量并列出位置"],
config=config
)
对计数、空间推理、密集 UI 解析这种官方公认的"代码执行加分项"任务,这是性价比最高的一档优化。我们在 API易(apiyi.com)上观察到,启用代码执行后整体延迟会有所上升,建议在异步业务里默认开启,在同步业务里按需开启。
Gemini API 识图技巧五:大图用 File API 而非 base64 内联
对于体积超过几 MB 的图像,很多团队直接用 base64 把图嵌进请求体。这种做法在小图上没问题,但当总请求大小超过 20MB 时就会触发 Gemini 的限制,部分图像会被静默压缩,识别质量自然下降。
官方给出的判定边界很清晰:
| 图像大小 | 推荐传输方式 | 原因 |
|---|---|---|
| 小于 5MB | base64 内联 | 请求轻量、调用简单 |
| 5~20MB | File API 上传 | 避免请求体积膨胀 |
| 大于 20MB | File API 必须 | base64 编码会破坏请求 |
| 跨多次复用 | File API 推荐 | 一次上传多次引用,省 Token |
File API 的另一好处是同一张图可以在多个请求里复用,省去重复上传成本。在 API易(apiyi.com)网关后,File API 的 endpoint 走的是同一组凭证,无需为图片上传单独开 Google Cloud 账号。
Gemini API 识图技巧六:自己搭一条 Agent 链路做多步验证
走完前 5 个技巧后,你的单次 API 调用已经接近官网体感了。但网页版还有一招杀手锏:多步验证。它会在生成回答后用第二次推理校验关键事实,遇到不确定的回答会再做一次"重答"。这个能力 API 上没有现成开关,需要你自己搭一条简单的 Agent 链路。
一个最小可用的两步链路是:
- 第一次调用:让 gemini-3.5-flash 生成结构化识别结果(JSON 输出)。
- 第二次调用:把第一次的结果与原图同时回灌,问模型"基于这张图,下列结论是否每条都成立?"
如果第二次调用挑出任何"不成立"的字段,再触发第三次"重答"。这套链路在 API易(apiyi.com)上可以直接用同一份 base_url 与 API Key 串起来,不需要额外服务。对识别准确率要求高的业务(合同识别、医疗影像辅助标注、安全合规审查)来说,多步验证是把准确率从 90% 推到 98% 的关键一步。
| 任务类型 | 建议链路 | 单步参数 |
|---|---|---|
| 通用识图问答 | 单步 | high + thinking_high |
| 文档抽取 | 单步 + JSON 校验 | ultra high + thinking_high |
| 复杂计数 | 两步 + code execution | high + thinking_high + tools |
| 高准确率业务 | 三步链路(识别 → 校验 → 重答) | ultra high + thinking_high + tools |
实战参数模板:把 6 个技巧串成一次可复用调用
为了方便你直接套用,下面给一份"识图任务默认模板",已经把前面 6 个技巧串到位,适合大多数业务的起点:
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
SYSTEM = (
"你是严谨的图像分析助手。仅引用图像中明确可见的内容,"
"不要凭空推断。输出严格 JSON,字段 entities/attributes/text。"
)
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=SYSTEM,
tools=[types.Tool(code_execution=types.ToolCodeExecution())],
response_mime_type="application/json"
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "按 SYSTEM 要求识别这张图"],
config=config
)
print(resp.text)
实际部署时建议在 API易(apiyi.com)侧把模板抽成统一的 SDK 调用层,业务方只传图与提问,参数由网关统一注入,避免每个业务都重新踩一遍坑。

常见问题 FAQ:Gemini API 识图与网页版差距答疑
Q1:把这些参数都打开后,API 还会比网页版差吗?
绝大多数业务能追平官网,但少数高难度任务(极小字、低光照、特殊艺术风格图)仍可能略差,因为网页版还会调用未公开的内部增强 Pipeline。对这类场景,可以在 API易(apiyi.com)上用其他厂商的视觉模型做横向对照,找到最适合的工作模型。
Q2:thinking_level=high 会让成本翻倍吗?
会增加内部推理 Token 用量,但只对输出阶段产生影响,且识图业务的整体成本里图像 Token 通常更占大头。把 thinking 调到 high 带来的准确率提升远大于增加的成本,特别是在替代人工复核的业务里。
Q3:base_url 怎么改?我用的是 Google 官方 SDK。
google-genai SDK 支持通过 http_options={"base_url": "https://api.apiyi.com"} 把请求转到 API易(apiyi.com)网关。Key 用 API易后台生成的即可,不需要单独的 Google Cloud 项目。
Q4:可以只优化提示词解决问题吗?
只调提示词的天花板很明显,无法覆盖分辨率、推理深度、工具调用这些"模型外"的能力。本文 6 个技巧里只有第三条与提示词相关,其余 5 条都是工程层的杠杆。
Q5:网页版能识别到的"图片中文水印",API 总是漏掉怎么办?
水印类细节往往依赖高分辨率与代码执行裁剪的组合。把 media_resolution 调到 ultra high,并启用 code execution,再用两步验证链路检查,通常能稳定识别。
总结:把网页版的工程能力补到 API 调用里
回到最初的问题:为什么 Gemini API 识图效果不如网页版?答案不是模型变弱了,而是网页版自带的工程脚手架太厚。当你直接调 gemini-3.5-flash API 时,提示词改写、分辨率档位、推理预算、工具调用、结果校验全都需要你自己显式补齐。理解这一点之后,6 个技巧的本质就是"把网页版替你做的事,搬到你自己的 API 调用链里"。
实操路径很清晰:先把 media_resolution 与 thinking_level 拉满,再把指令搬进 system_instruction 并开启缓存,对复杂识图任务启用 code execution,大图统一走 File API,最后用两到三步 Agent 链路兜住高准确率业务。这套组合拳跑下来,再回到 API易(apiyi.com)后台对比命中率与延迟,多数团队都能把识图业务的"网页 vs API"差距压缩到肉眼几乎看不出来的程度。
📌 作者署名:本文由 API易(apiyi.com)技术团队整理,更多 Gemini、Claude、GPT 系列模型的接入实战与调参指南,请关注 API易帮助中心。